RecSys2020論文読み会での論文紹介資料です。
https://connpass.com/event/189192/
紹介論文:
C. Hansen, C. Hansen, L. Maystre, R. Mehrotra, B. Brost, F. Tomasi, M. Lalmas, Contextual and Sequential User Embeddings for Large-Scale Music Recommendation, In Proceedings of the 14th ACM conference on Recommender systems, pp.53-62, 2020.
{kind=link}
![背景 Spotifyなどオンライン音楽ストリーミングサービスの普及により, ユーザは膨大な楽曲にアクセス可能に 他の推薦ドメインとは異なり,楽曲は短く,よく他の楽曲とセットで聴取される ➢ セッション*にはユーザの直近の聴取履歴にある楽曲が現れることが多く [Anderson+2014],セッションのシーケンスからユーザの嗜好変化に関する情報の抽出 が可能 ➢ 楽曲間の関連性や嗜好はコンテキスト**に大きく依存[Park+2019]](https://files.speakerdeck.com/presentations/b818bafac40f4f5bbd5d8d24a4021f41/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
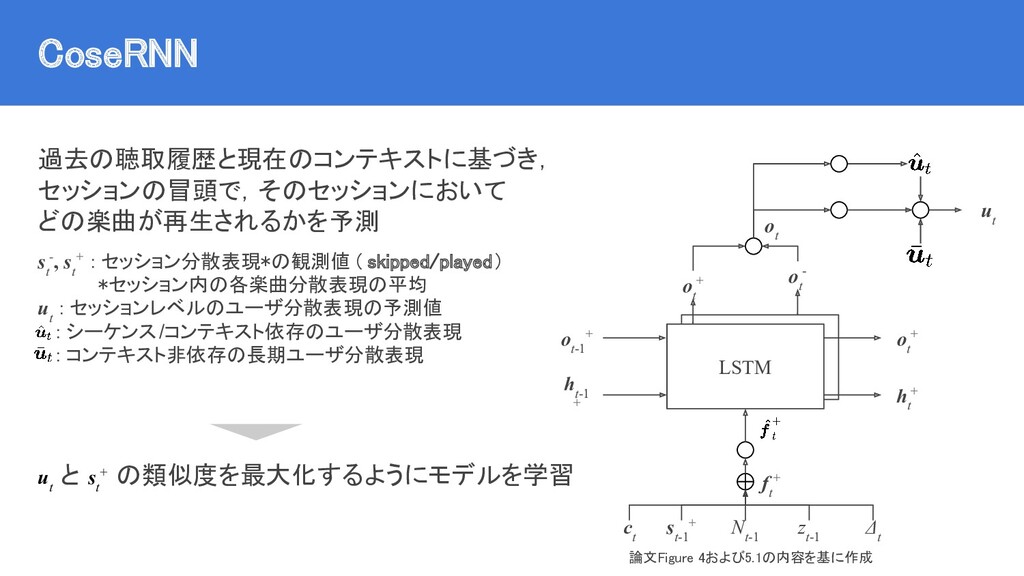{kind=link}
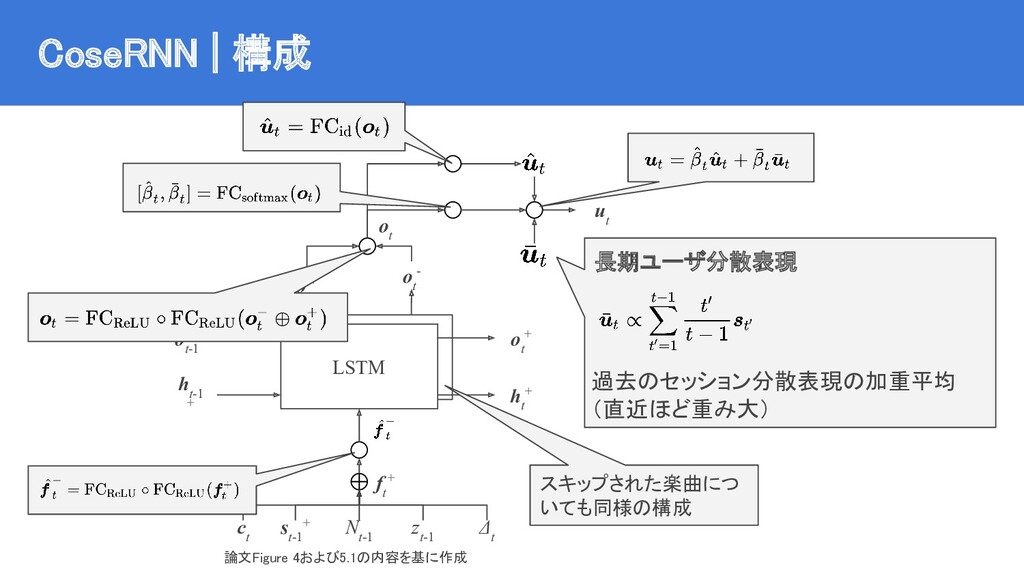{kind=link}
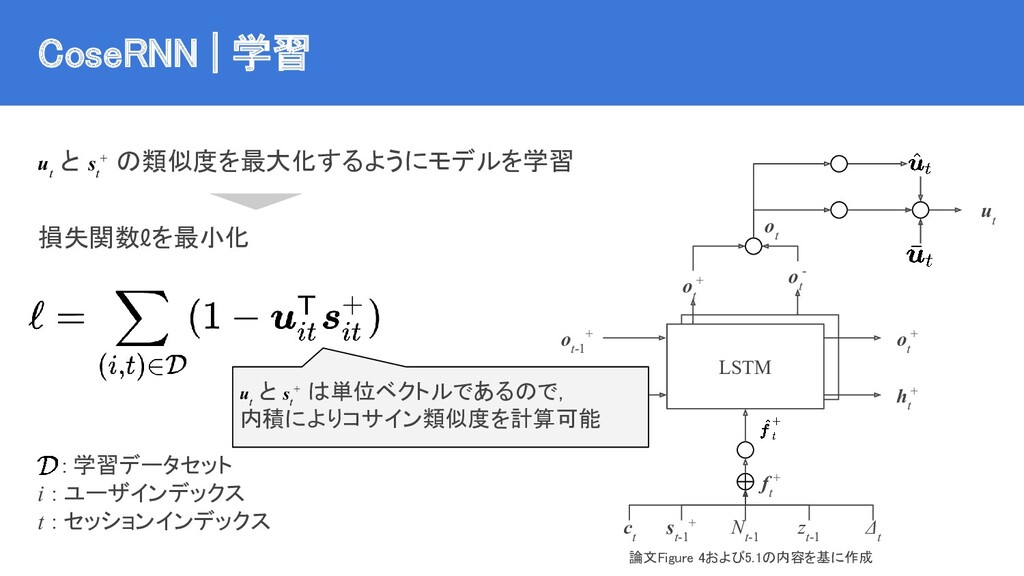{kind=link}
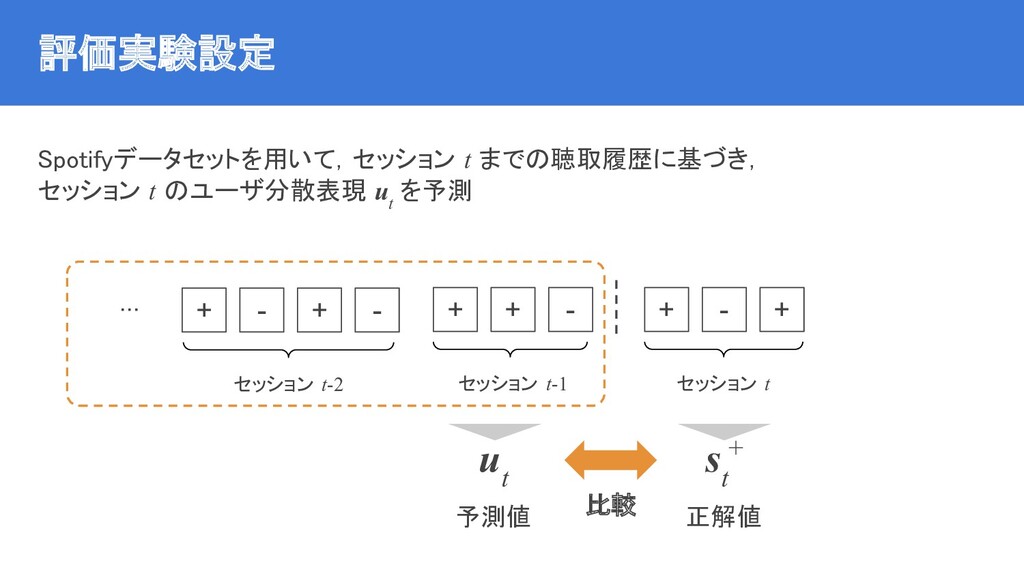{kind=link}
{kind=link}
{kind=link}
{kind=link}
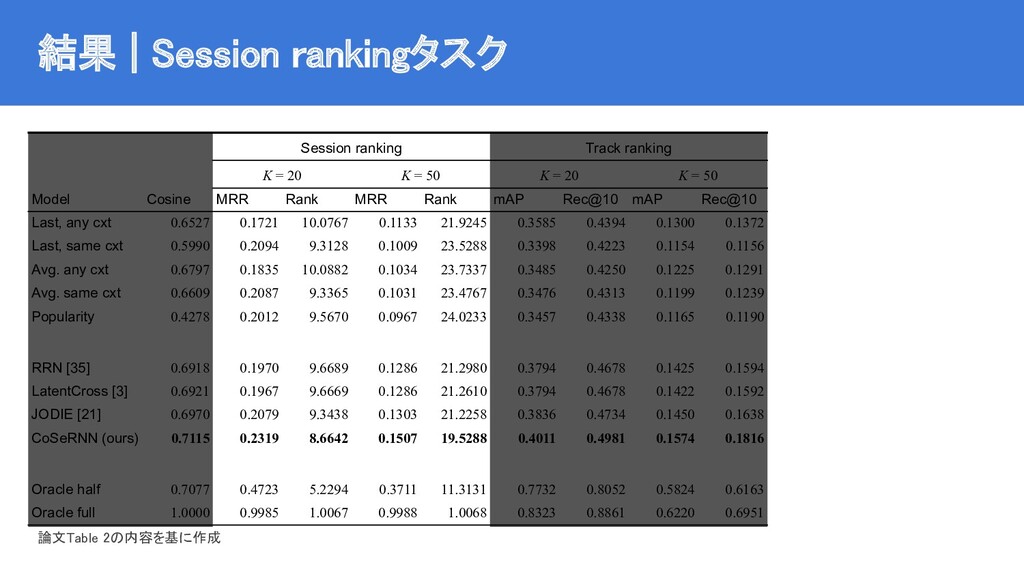
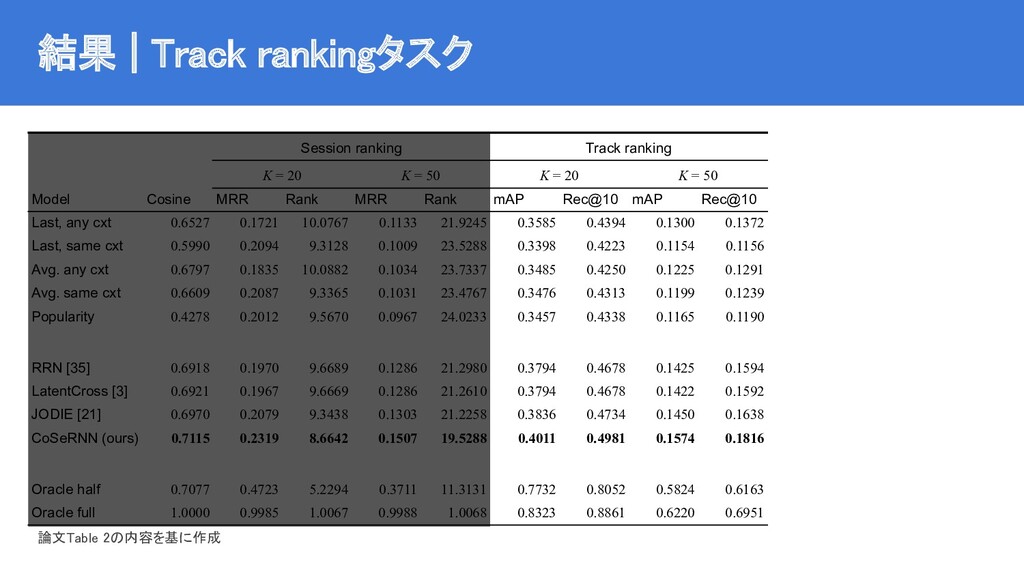
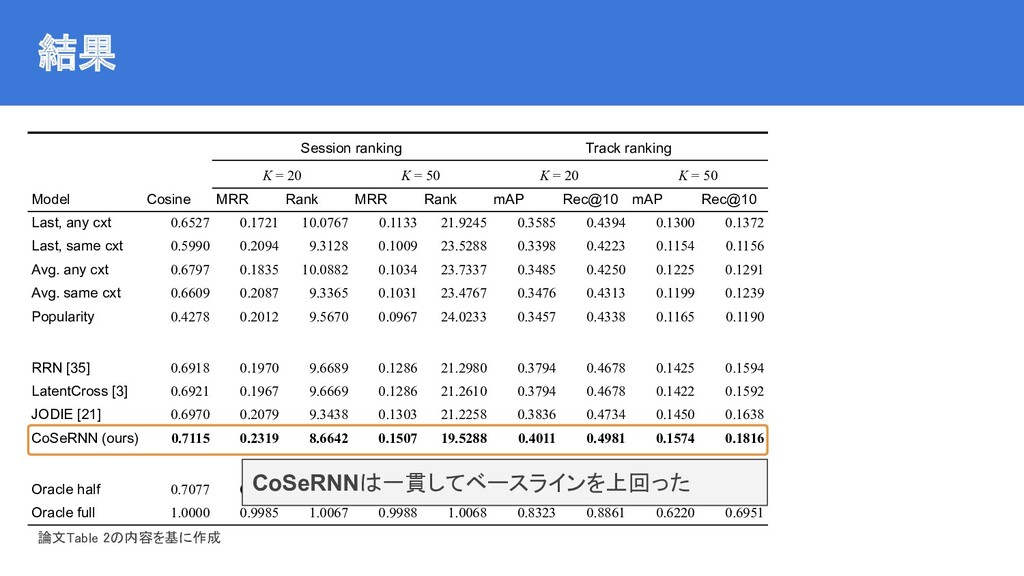
![ベースライン | state-of-the-art手法 JODIE [Kumar+2019] RRN [Wu+2017] LatentCross [Beutel+2018] コンテキストおよびシーケンスを考慮したモデル](https://files.speakerdeck.com/presentations/b818bafac40f4f5bbd5d8d24a4021f41/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
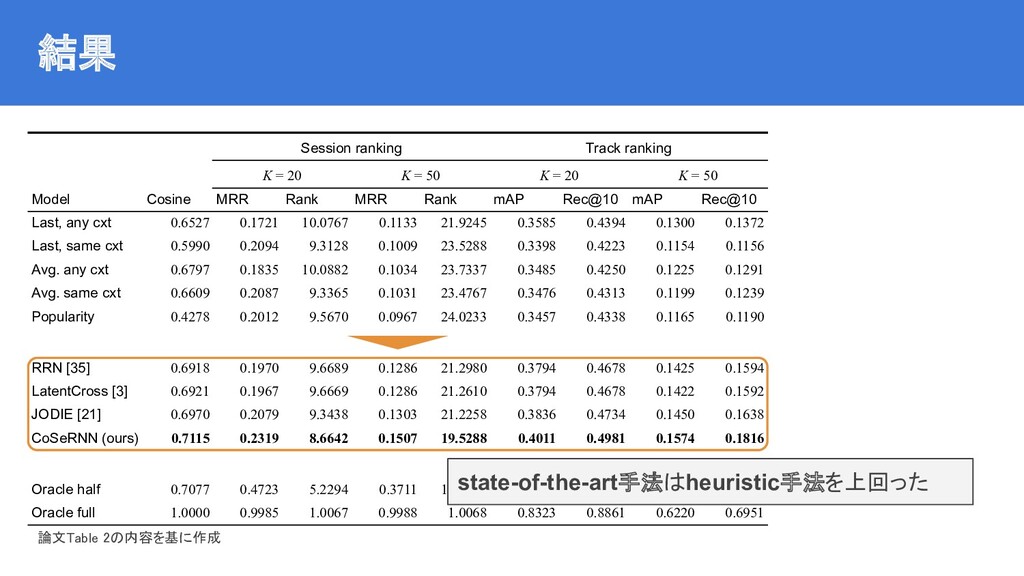{kind=link}
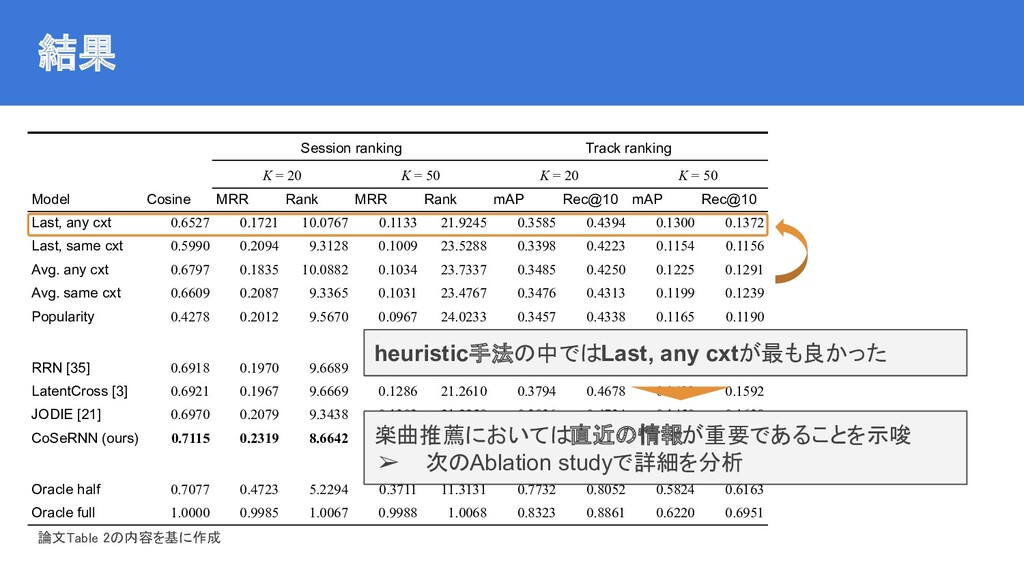{kind=link}
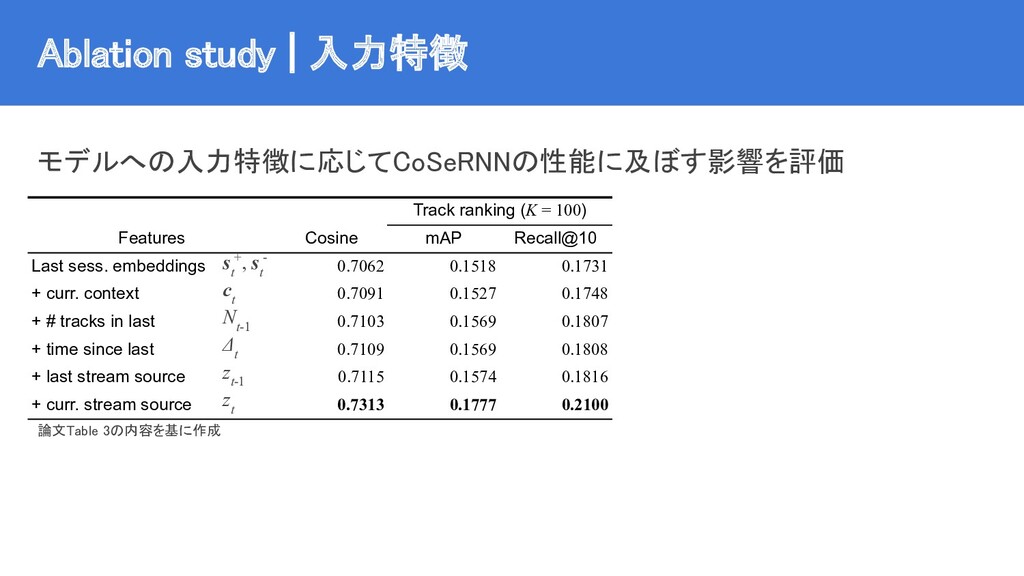{kind=link}
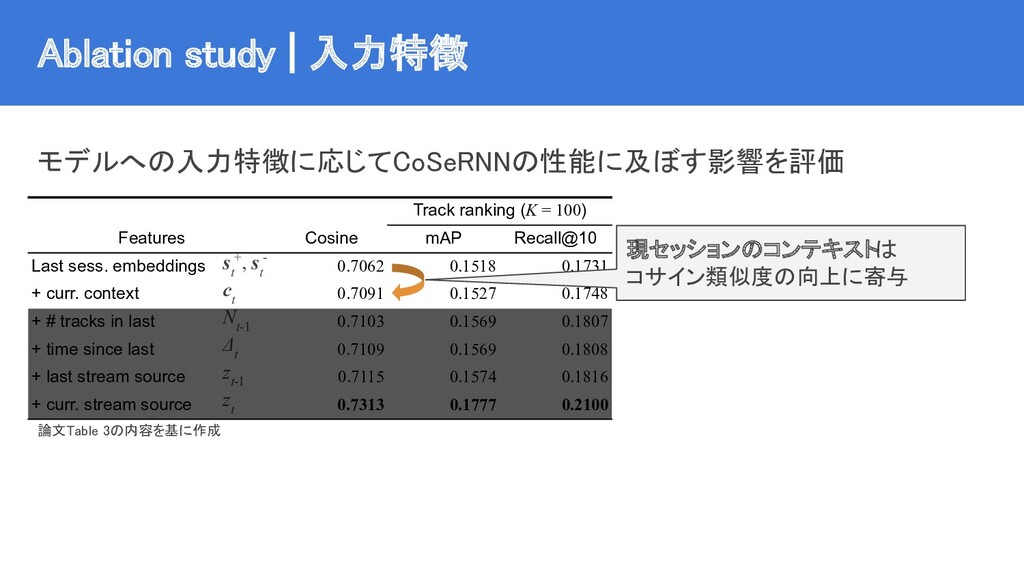{kind=link}
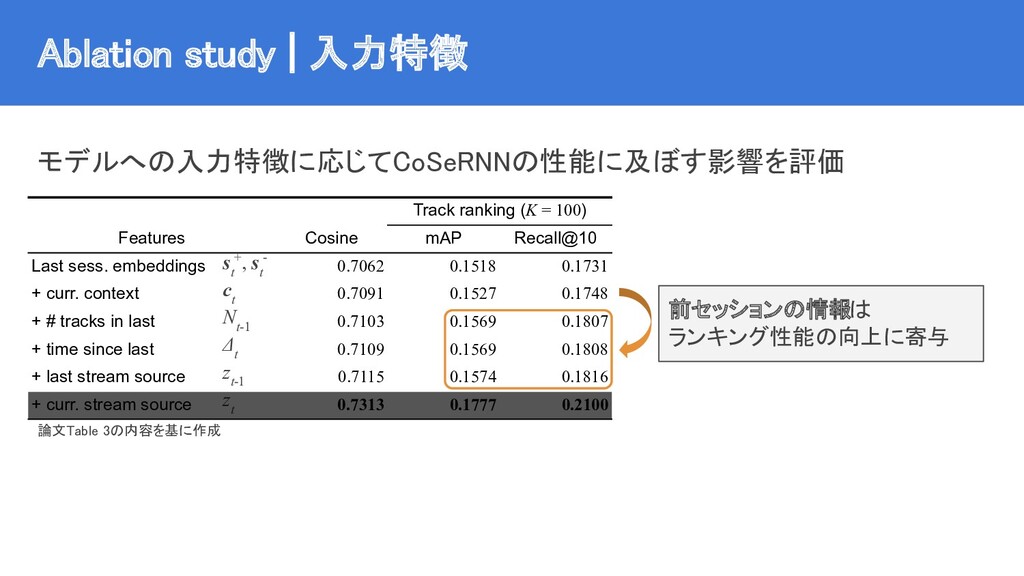{kind=link}
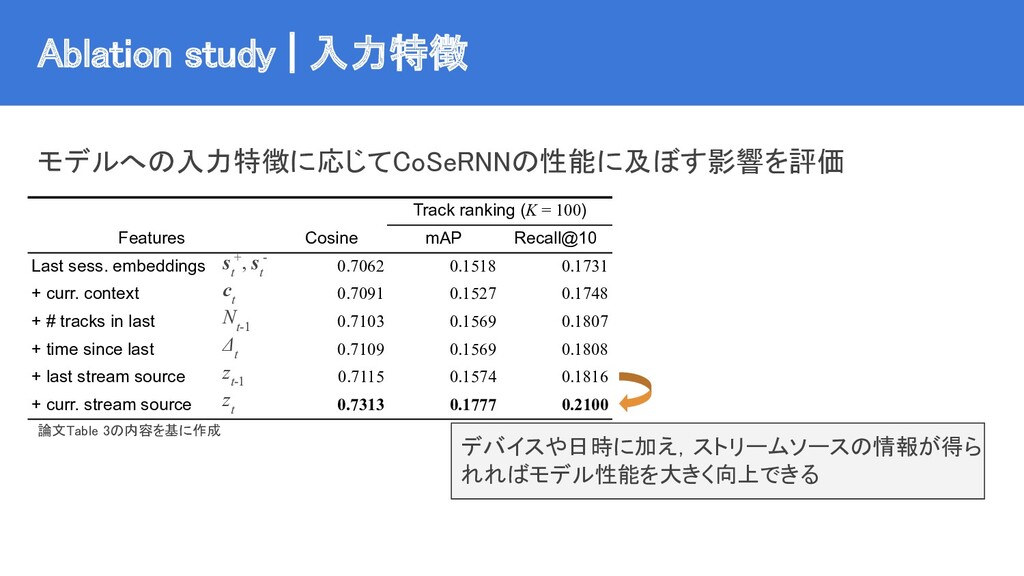{kind=link}
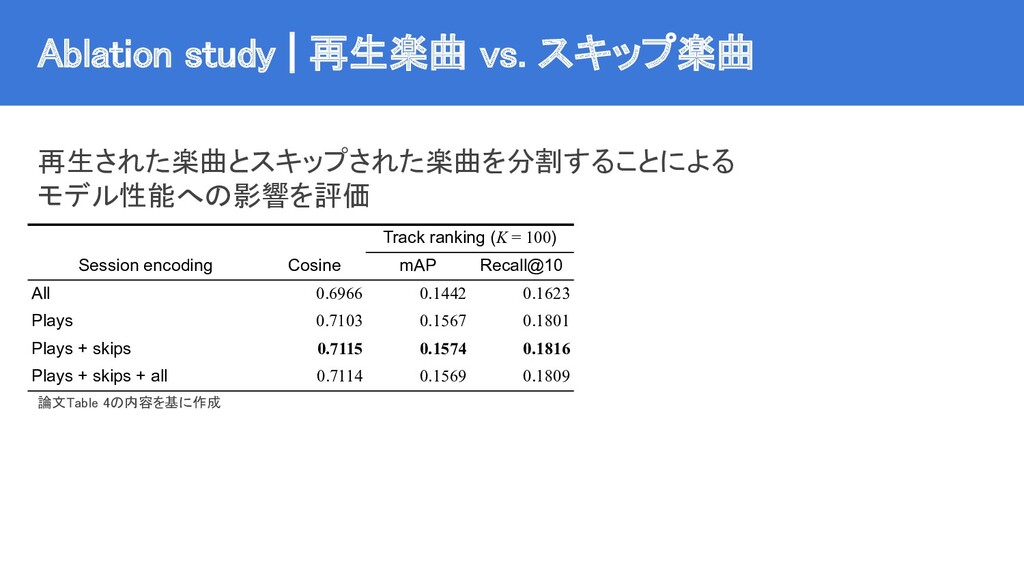{kind=link}
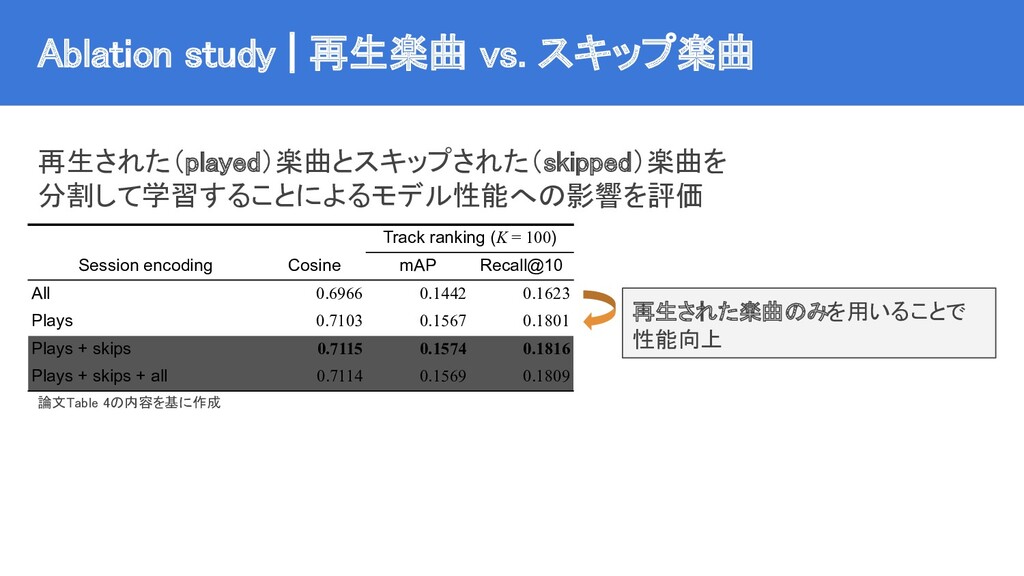{kind=link}
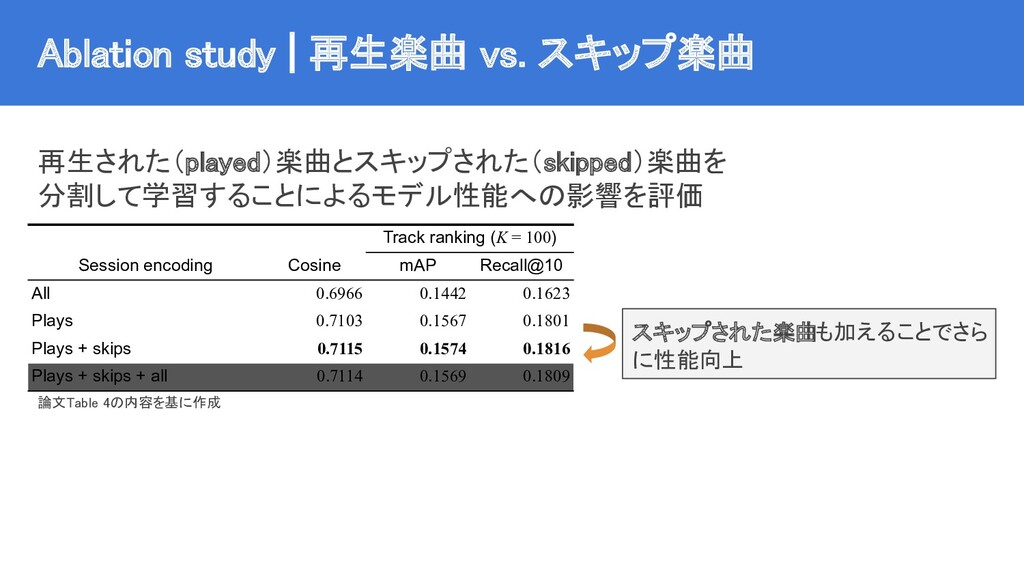{kind=link}
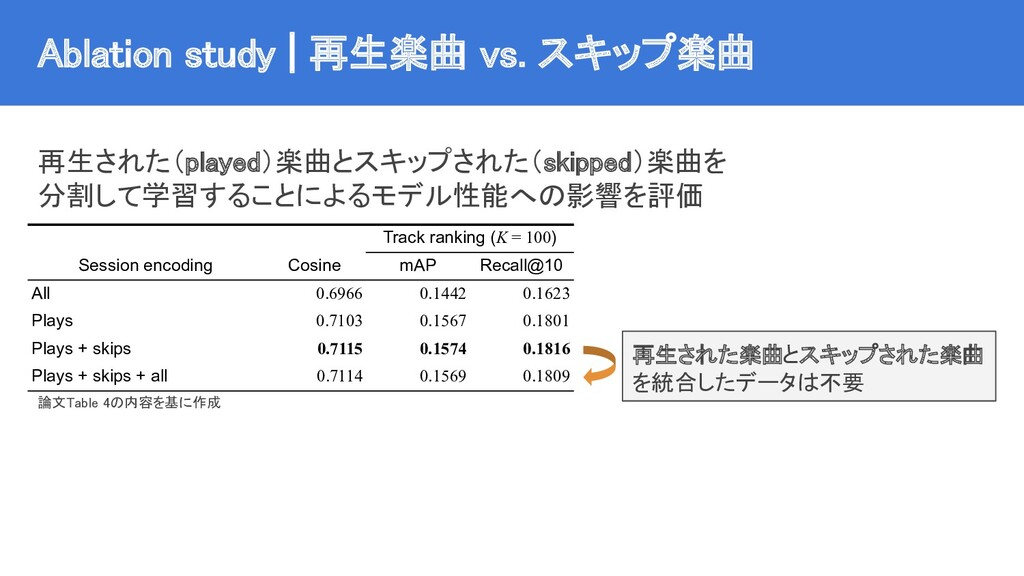{kind=link}
{kind=link}