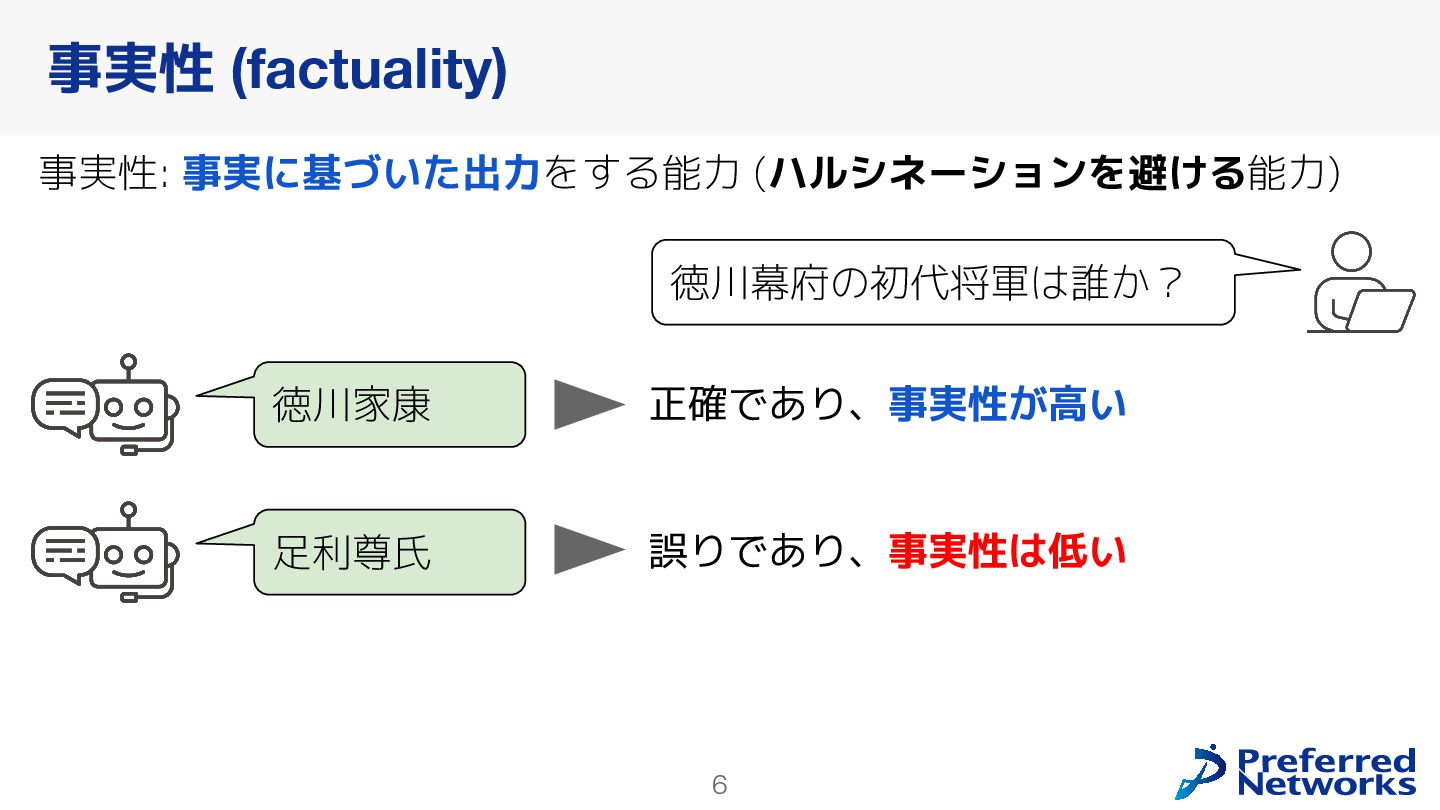
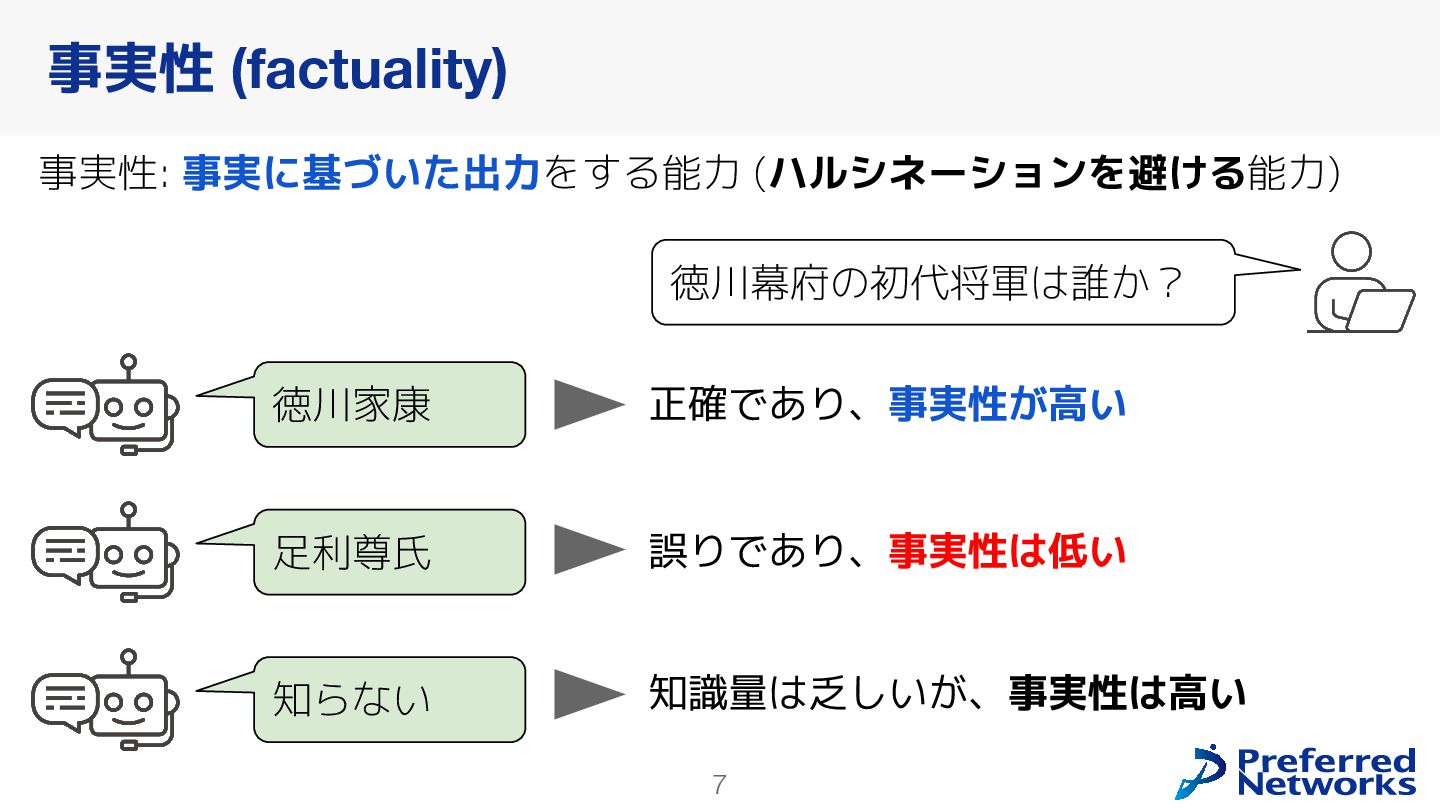
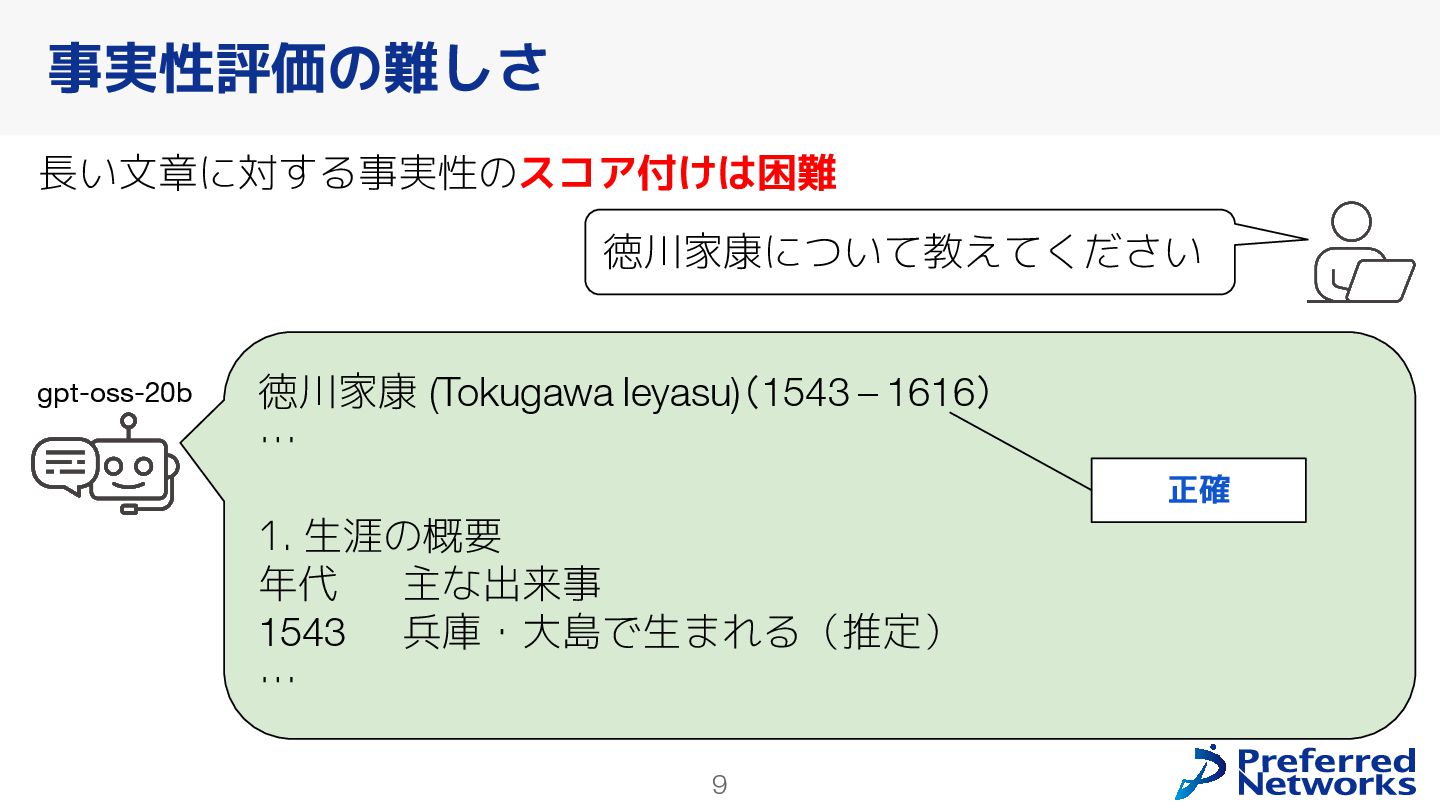
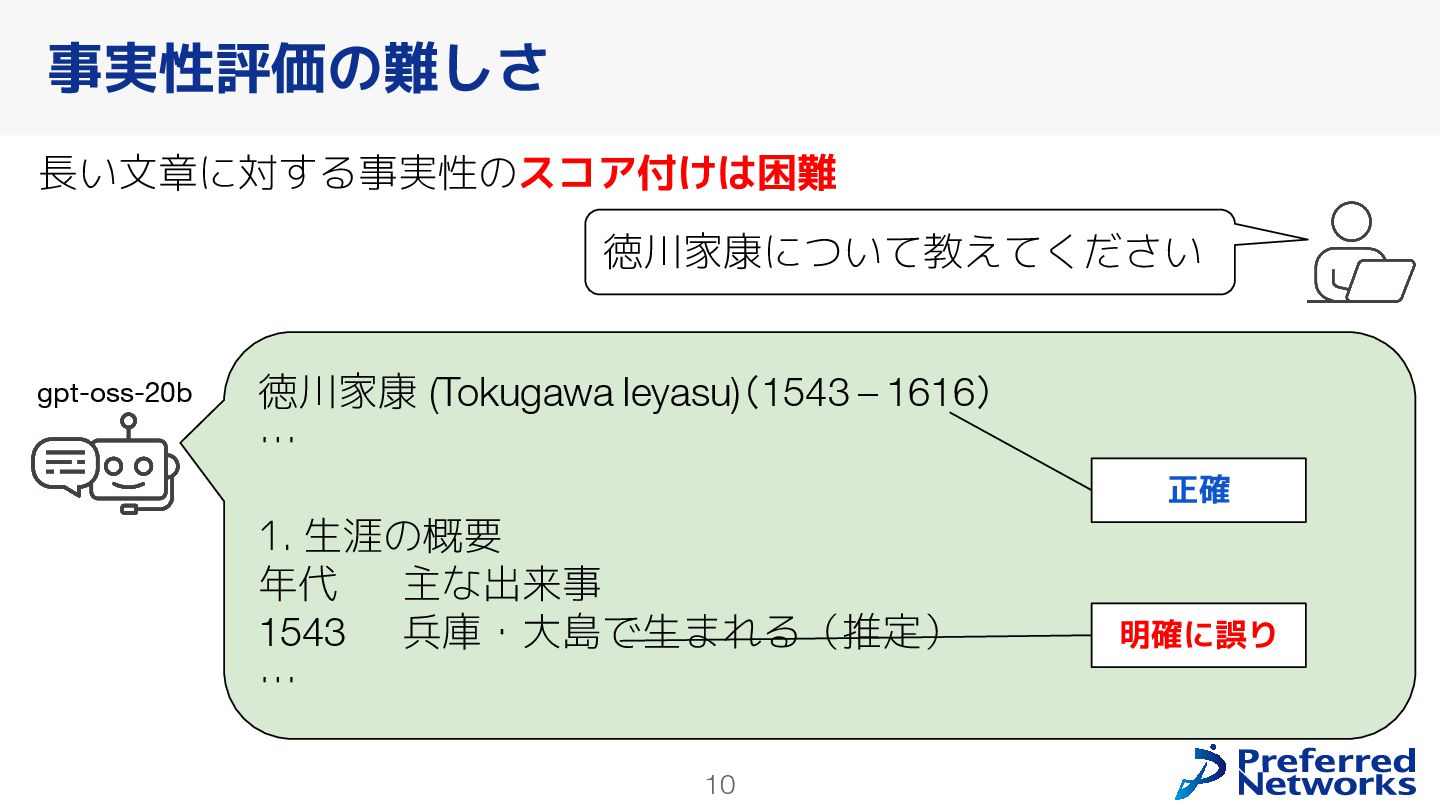
本報告では,大規模言語モデル(LLM)の日本語における事実に基づく回答能力(事実性)を評価するベンチマーク「Japanese SimpleQA」の構築と既存モデルの振る舞いについて述べる.Japanese SimpleQAは,短文で特定の事実について問う3000問の日本語質問応答からなるベンチマークである.SimpleQAと同様に,(1)最新のLLMにとっても高難度であり,(2)時間経過による正答の変化がなく,(3)別解が存在しない,質問応答で構成されている.この設計により,「モデルが自己の知識をどの程度正確に認識しているか」を評価できる.Japanese SimpleQAを用い,既存LLMの事実性や,RAGによる事実性の向上効果を明らかにした.構築したベンチマークは https://github.com/pfnet-research/japanese-simpleqa/ で公開している.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
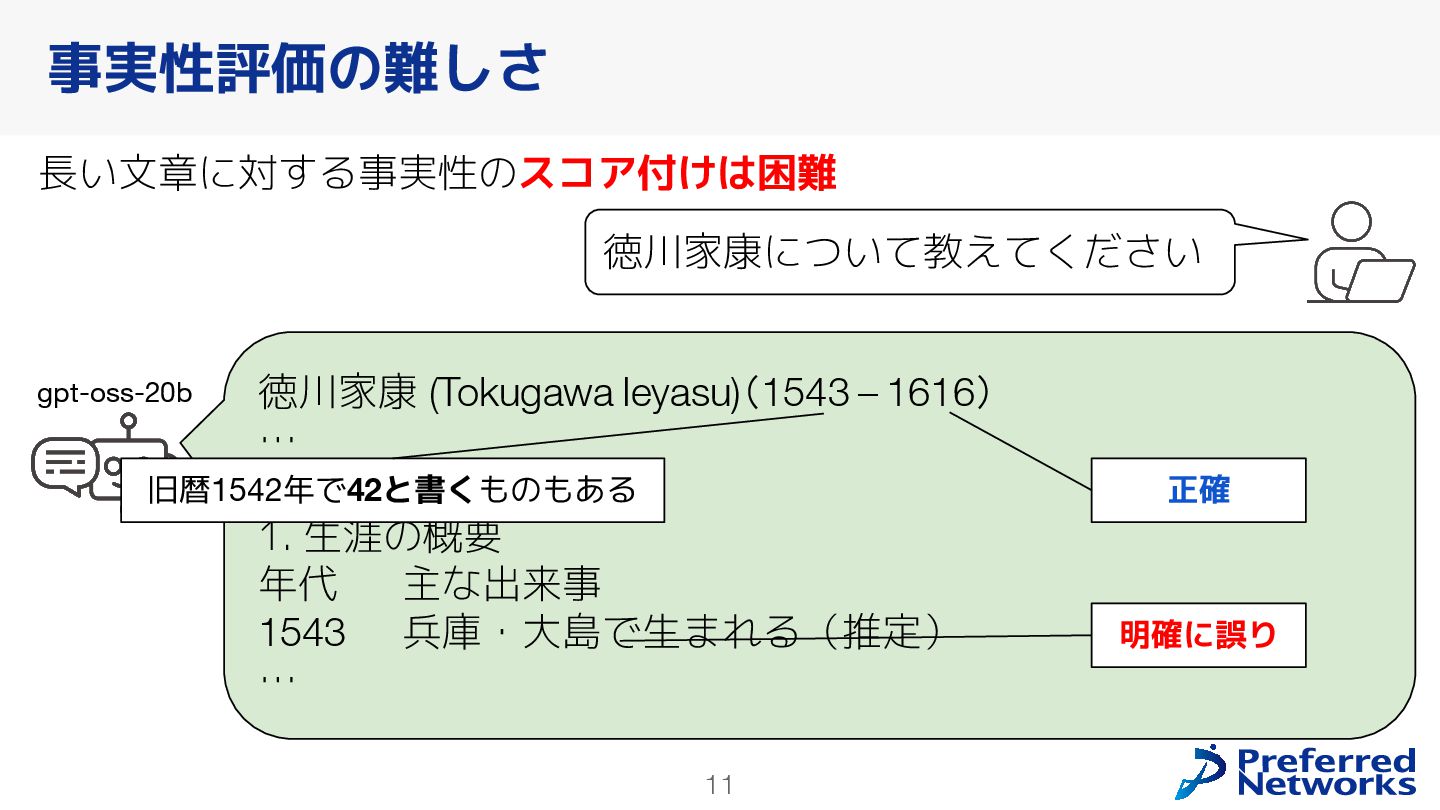{kind=link}
{kind=link}
![13 Q&Aの形式を制限することで事実性を短い時間で評価 SimpleQA [Measuring short-form factuality in large language models]](https://files.speakerdeck.com/presentations/9512ecda22264c35b894d61c0a635857/slide_12.jpg){kind=link}
![14 Q&Aの形式を制限することで事実性を短い時間で評価 SimpleQA [Measuring short-form factuality in large language models]](https://files.speakerdeck.com/presentations/9512ecda22264c35b894d61c0a635857/slide_13.jpg){kind=link}
![15 Q&Aの形式を制限することで事実性を短い時間で評価 SimpleQA [Measuring short-form factuality in large language models]](https://files.speakerdeck.com/presentations/9512ecda22264c35b894d61c0a635857/slide_14.jpg){kind=link}
![16 Q&Aの形式を制限することで事実性を短い時間で評価 SimpleQA [Measuring short-form factuality in large language models]](https://files.speakerdeck.com/presentations/9512ecda22264c35b894d61c0a635857/slide_15.jpg){kind=link}
![17 Q&Aの形式を制限することで事実性を短い時間で評価 SimpleQA [Measuring short-form factuality in large language models]](https://files.speakerdeck.com/presentations/9512ecda22264c35b894d61c0a635857/slide_16.jpg){kind=link}
![18 Q&Aの形式を制限することで事実性を短い時間で評価 SimpleQA [Measuring short-form factuality in large language models]](https://files.speakerdeck.com/presentations/9512ecda22264c35b894d61c0a635857/slide_17.jpg){kind=link}
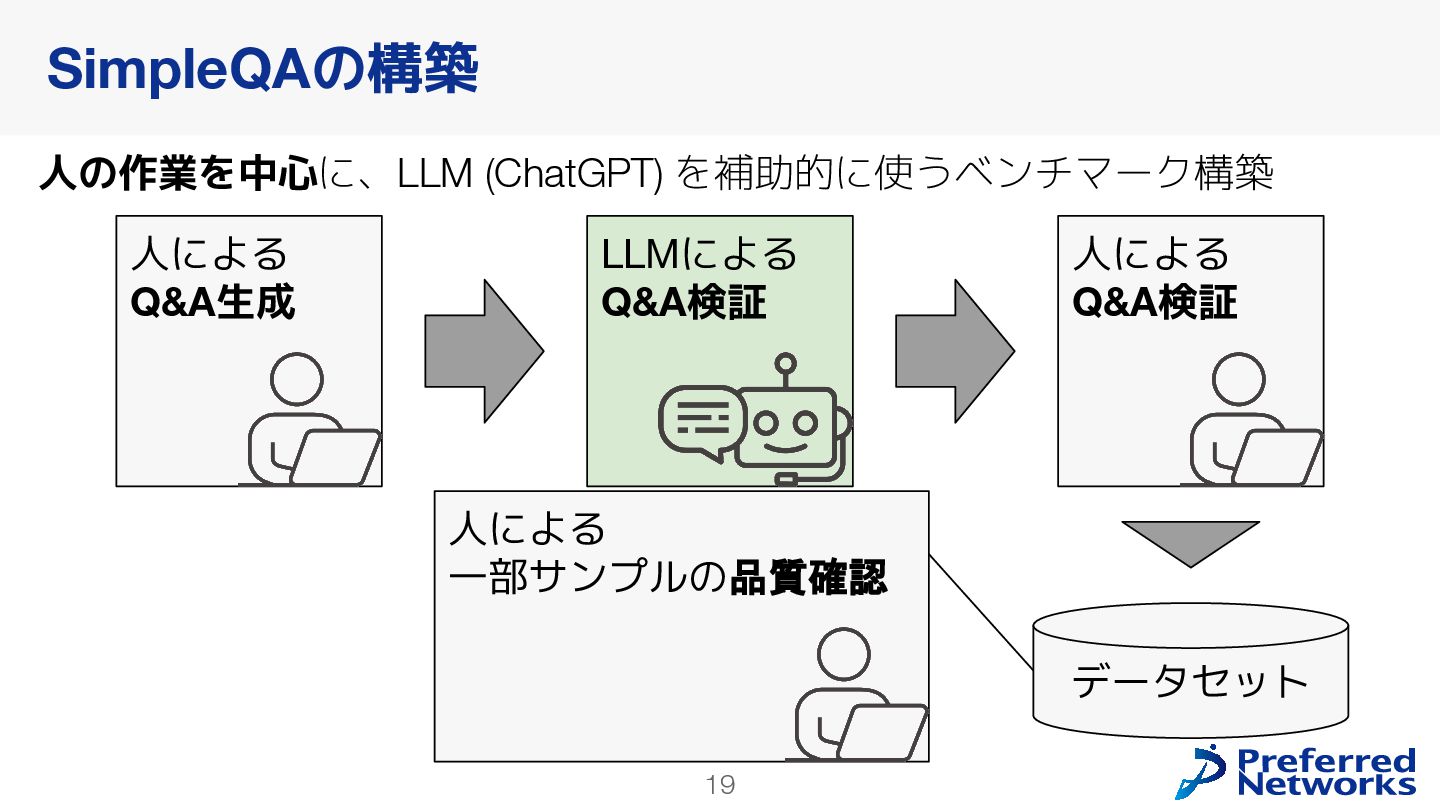{kind=link}
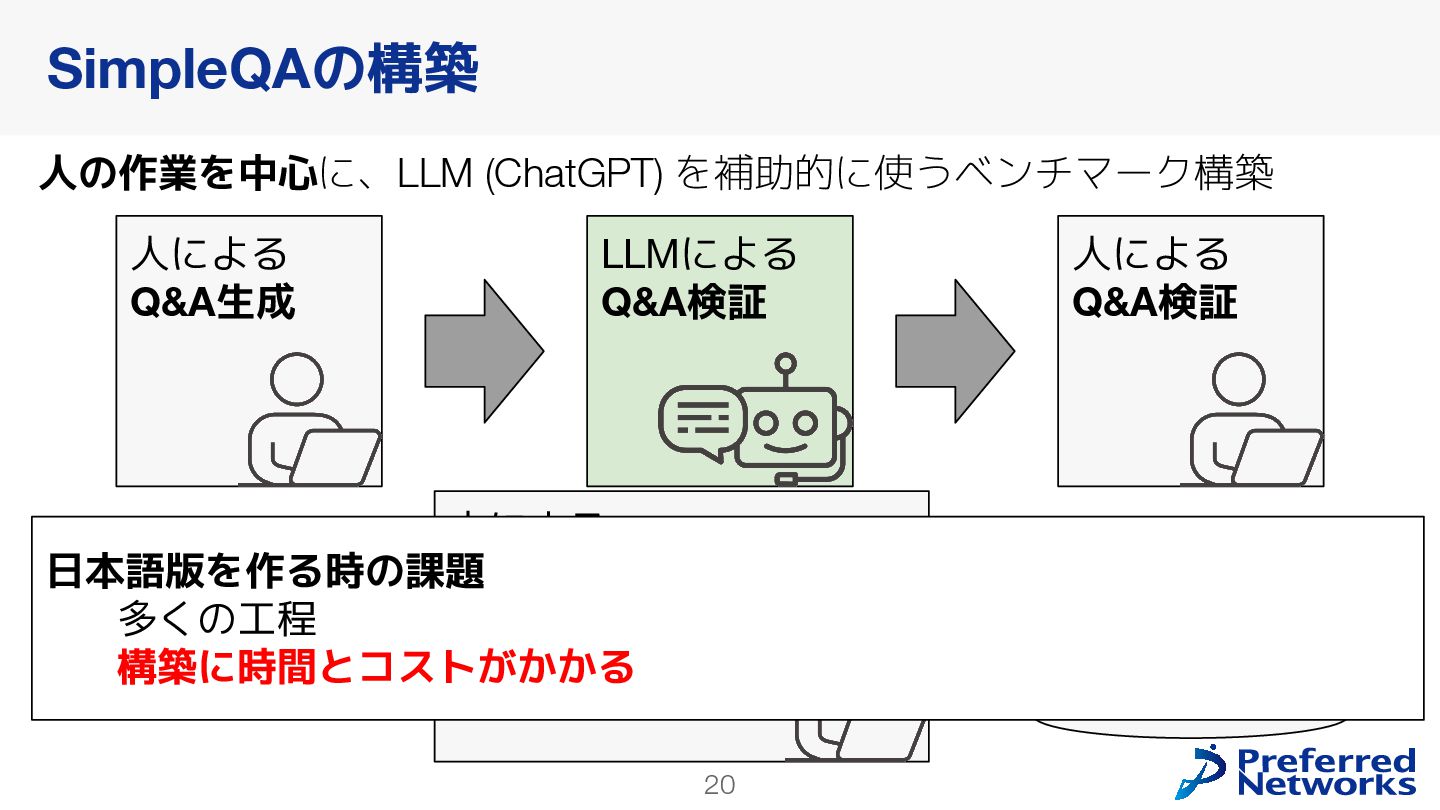{kind=link}
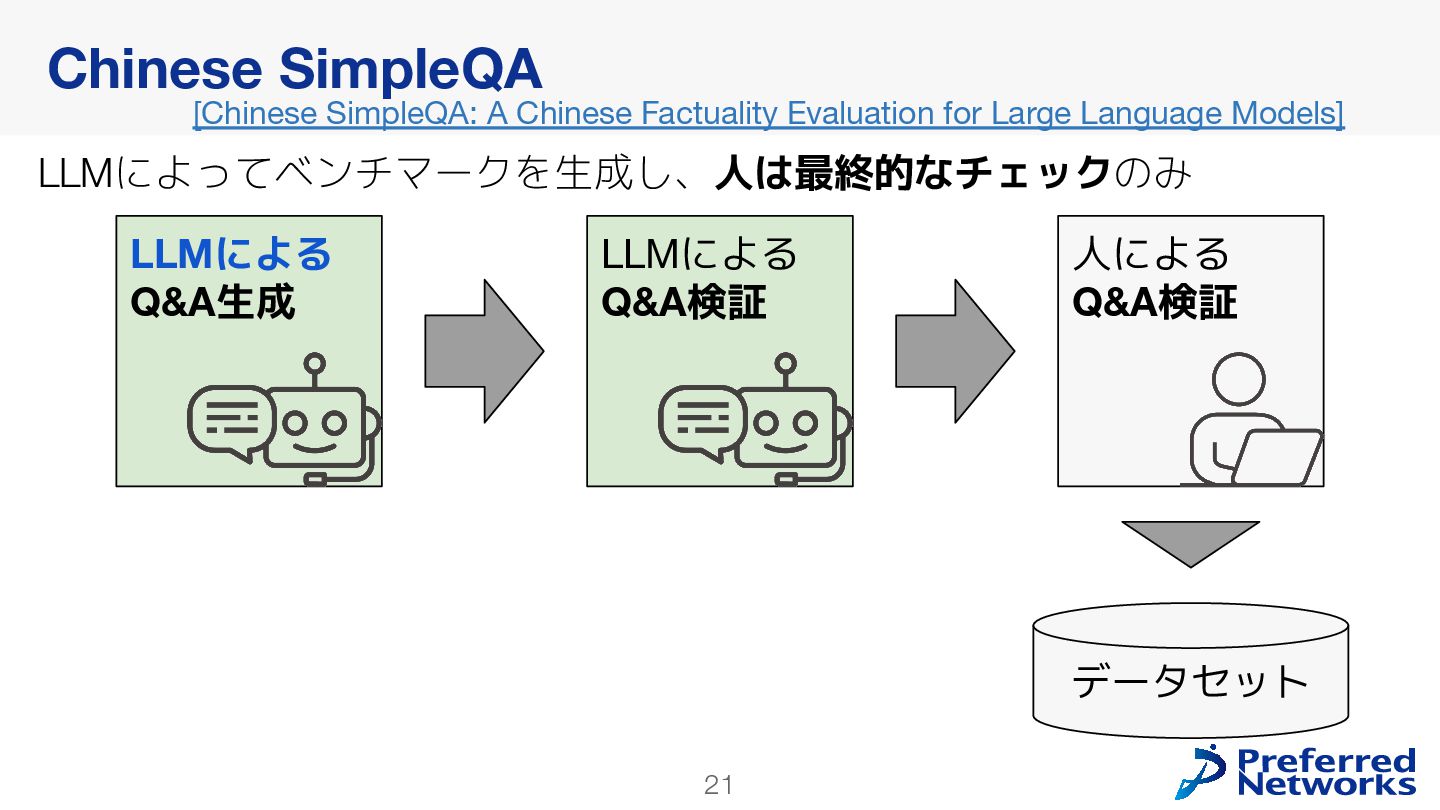{kind=link}
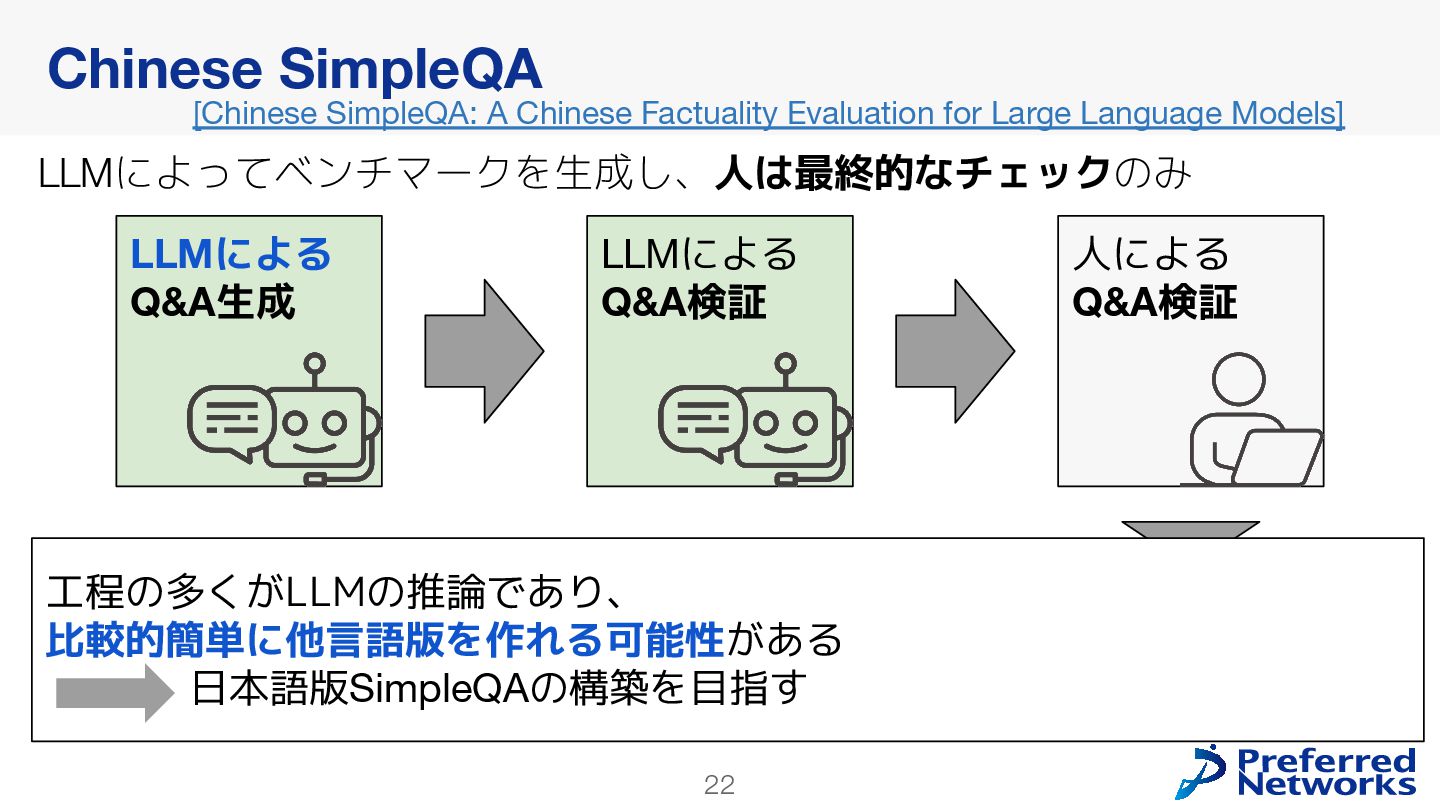{kind=link}
{kind=link}
{kind=link}
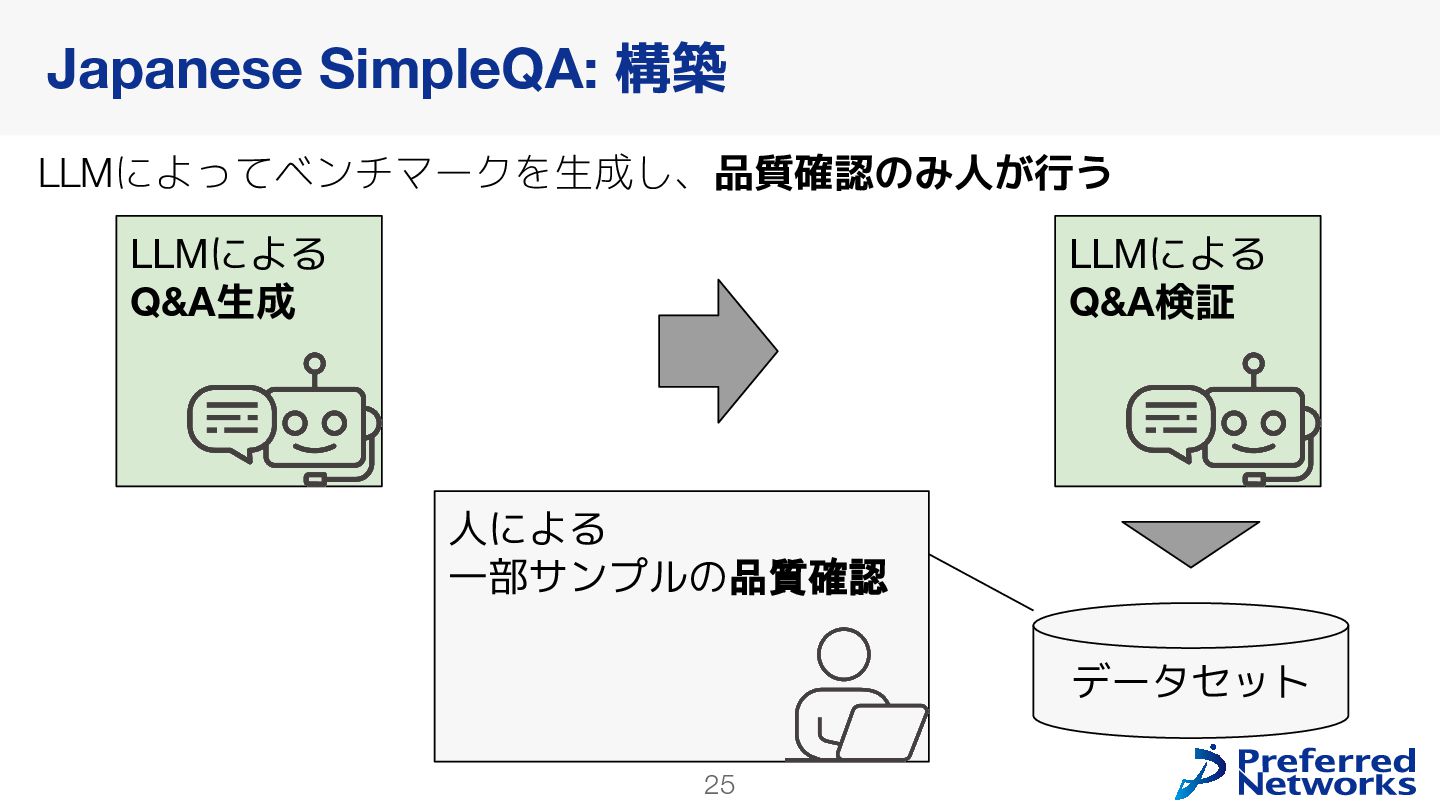{kind=link}
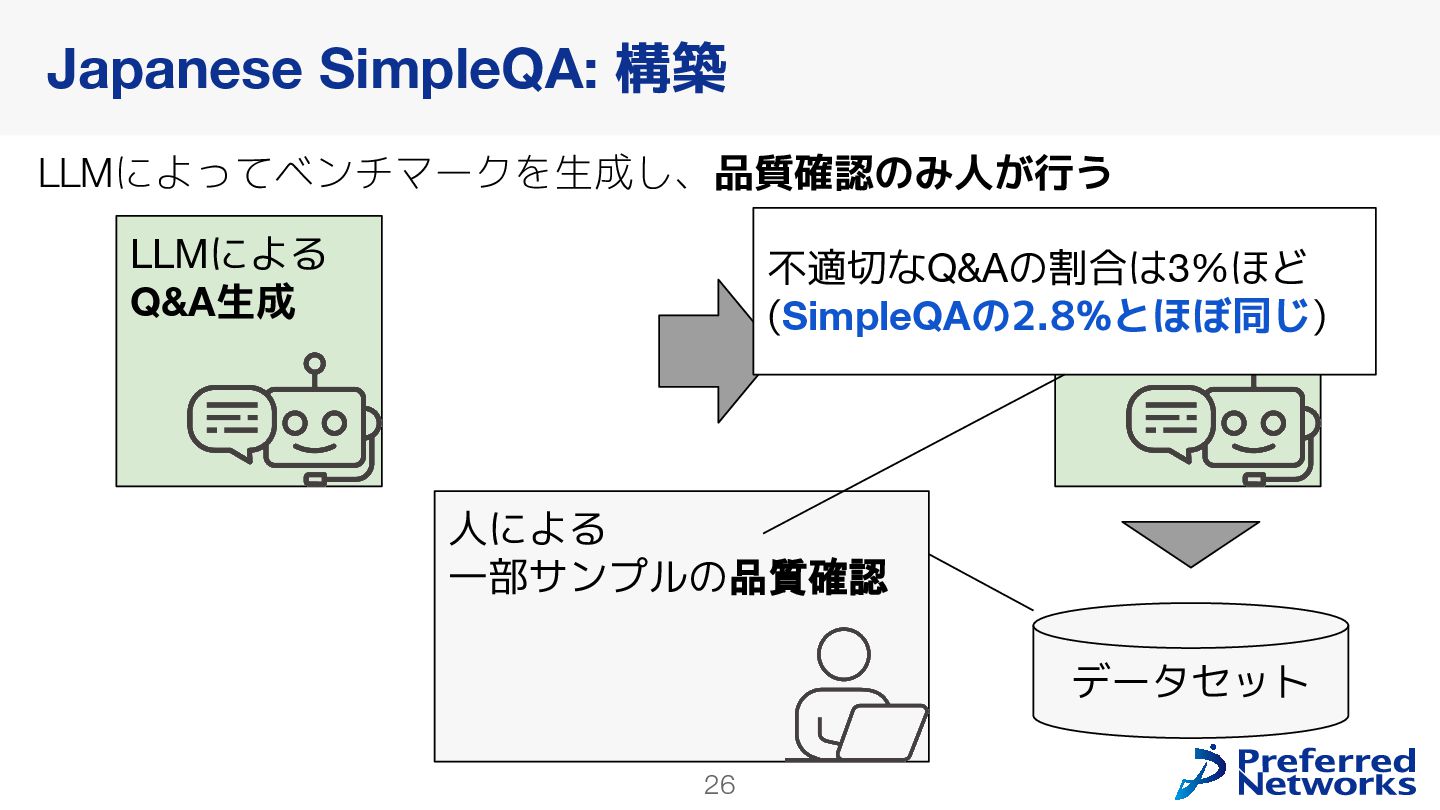{kind=link}
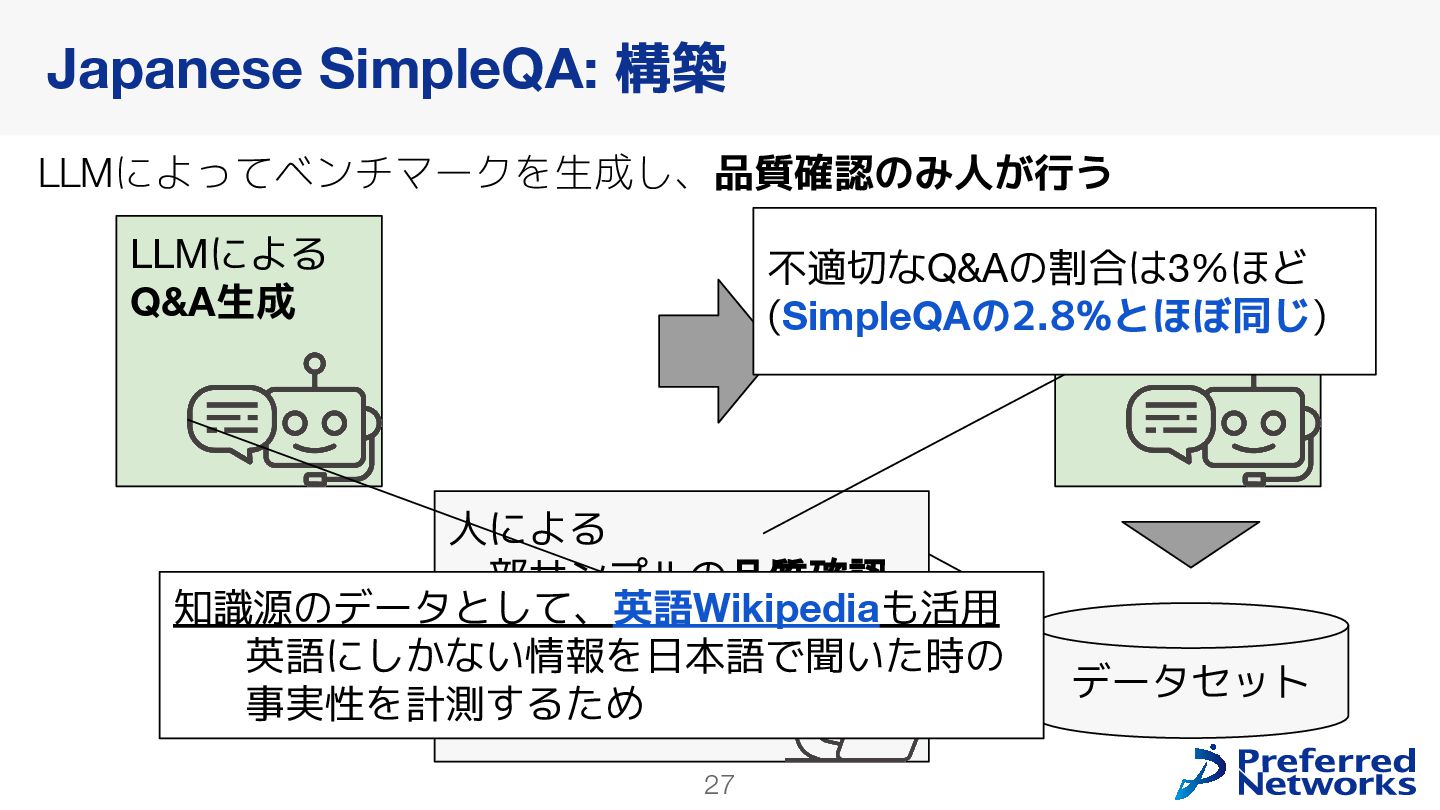{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
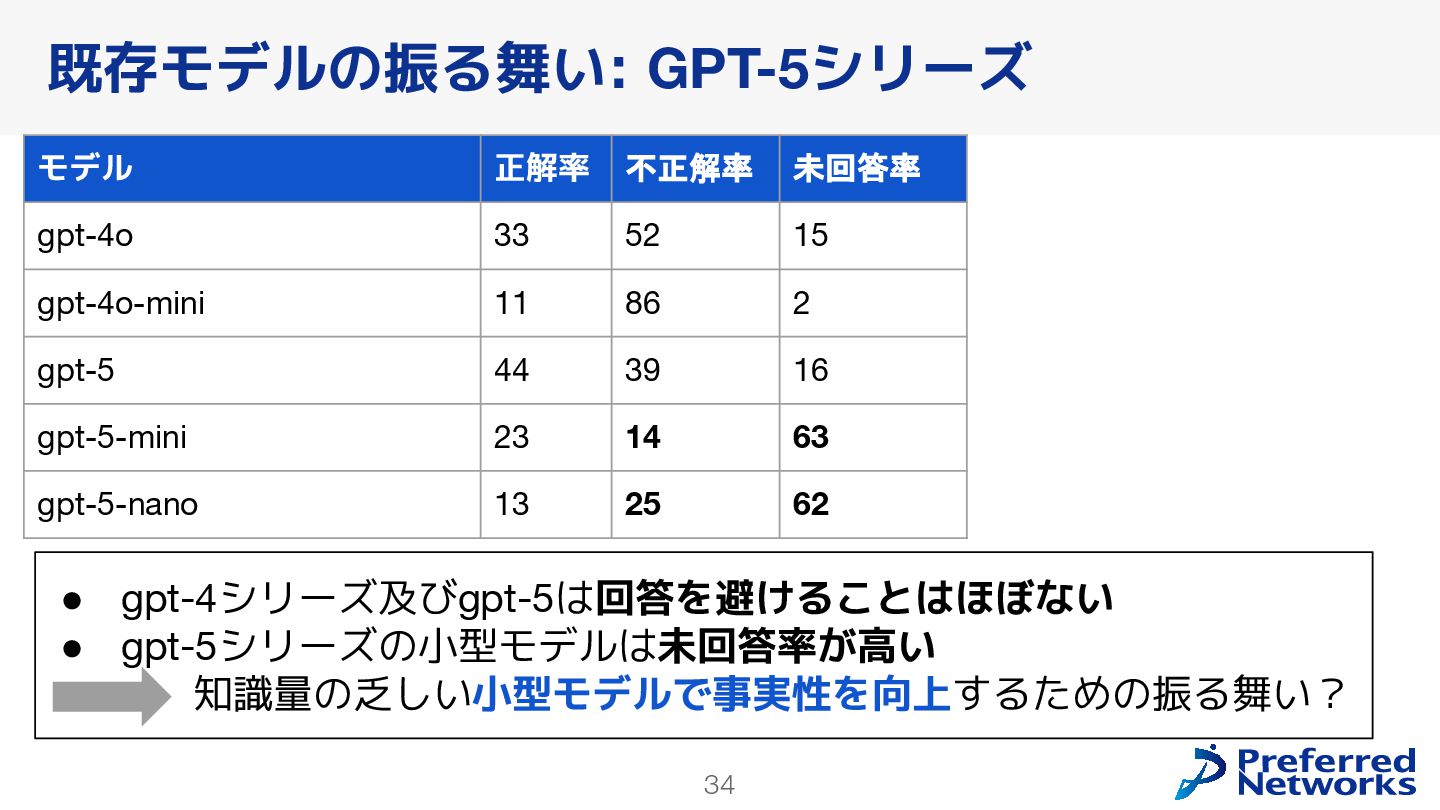{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}