Liyanage, PhD Co-authors: Nelum Attanayake, Zijian(Jack) Luo, and Rahul Gopinath, PhD School of Computer Science, University of Sydney, Australia Registered Report - ICSME 2025 Auckland, New Zealand September 2025
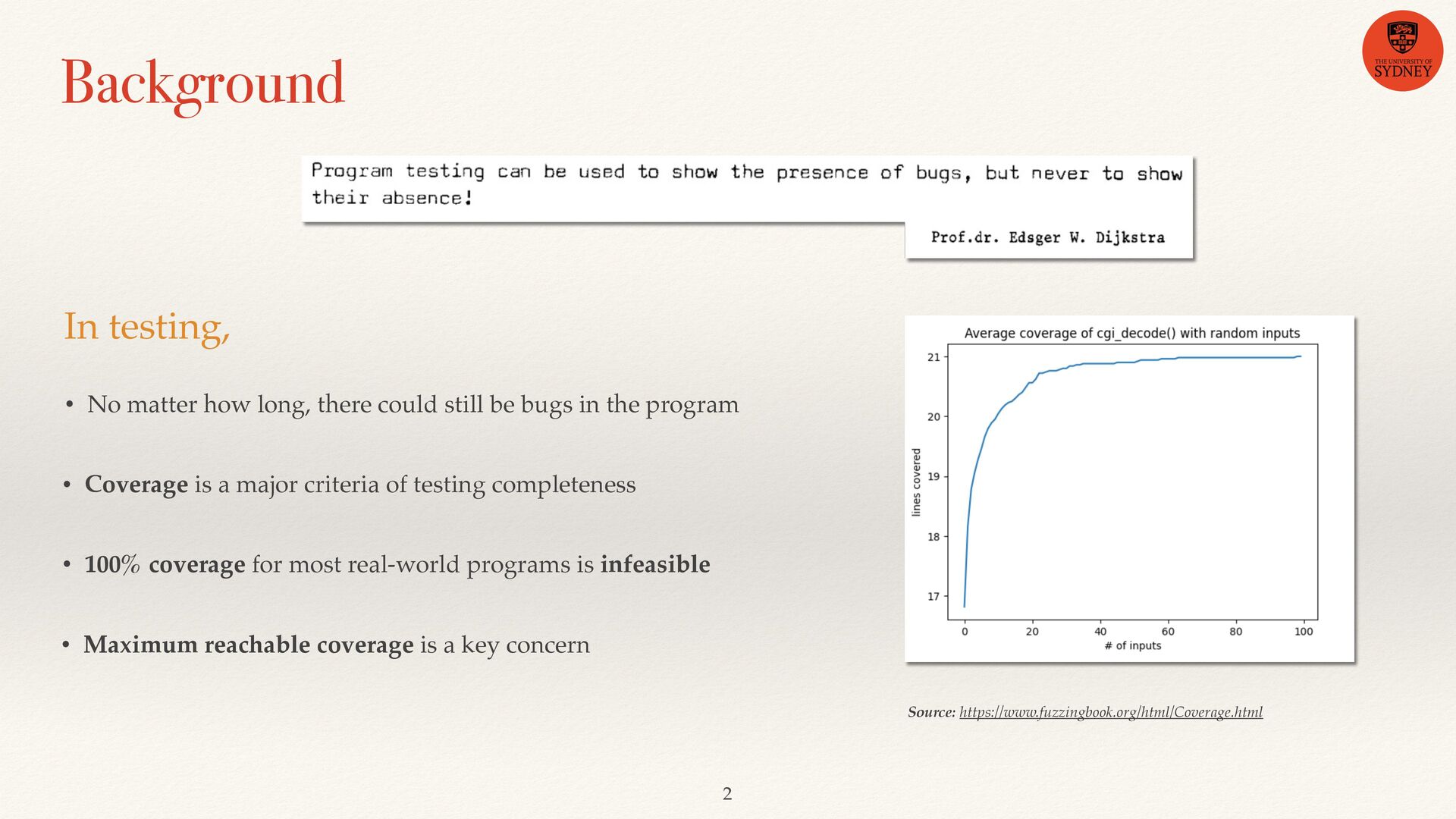
could still be bugs in the program • 100% coverage for most real-world programs is infeasible • Maximum reachable coverage is a key concern • Coverage is a major criteria of testing completeness Source: https://www.fuzzingbook.org/html/Coverage.html
statistical sampling process (STADS, 2018) [1] • AKA species richness estimators since borrowed from Ecology • Proposed a suite of statistical estimators for maximum reachable coverage[2,3] Maximum reachability estimation in fuzzing Fuzzing [1] Böhme, M. (2018). STADS: Software testing as species discovery. ACM Transactions on Software Engineering and Methodology (TOSEM), 27(2), 1-52. [2] Liyanage, D., Böhme, M., Tantithamthavorn, C., & Lipp, S. (2023, May). Reachable coverage: Estimating saturation in fuzzing. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) (pp. 371-383). IEEE. [3] Kuznetsov, K., Gambi, A., Dhiddi, S., Hess, J., & Gopinath, R. (2024). Empirical Evaluation of Frequency Based Statistical Models for Estimating Killable Mutants. In 2024 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM) (pp. 61–71). ACM.
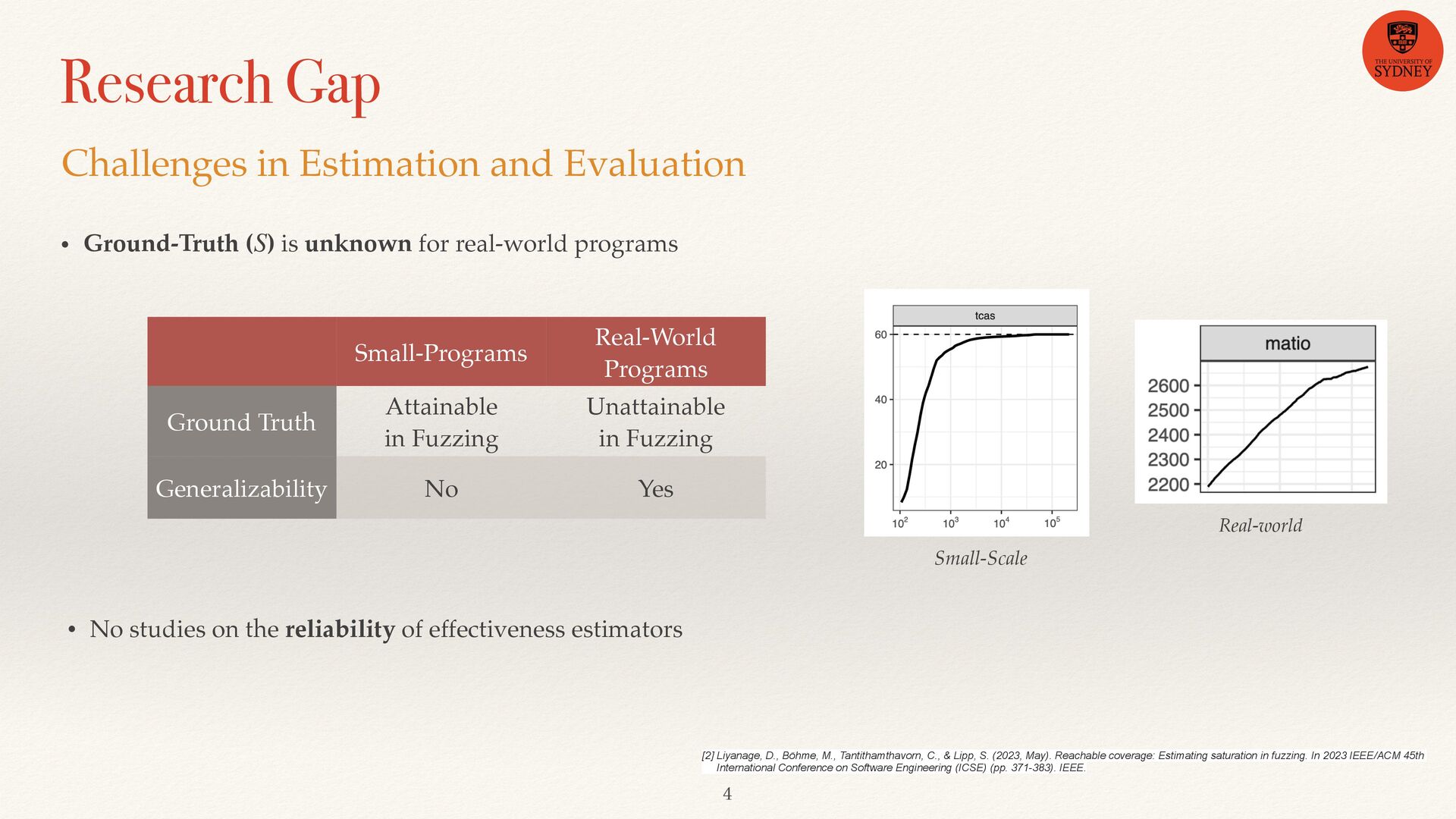
real-world programs S Challenges in Estimation and Evaluation [2] Liyanage, D., Böhme, M., Tantithamthavorn, C., & Lipp, S. (2023, May). Reachable coverage: Estimating saturation in fuzzing. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) (pp. 371-383). IEEE. • No studies on the reliability of effectiveness estimators Small-Programs Real-World Programs Ground Truth Attainable in Fuzzing Unattainable in Fuzzing Generalizability No Yes Real-world Small-Scale
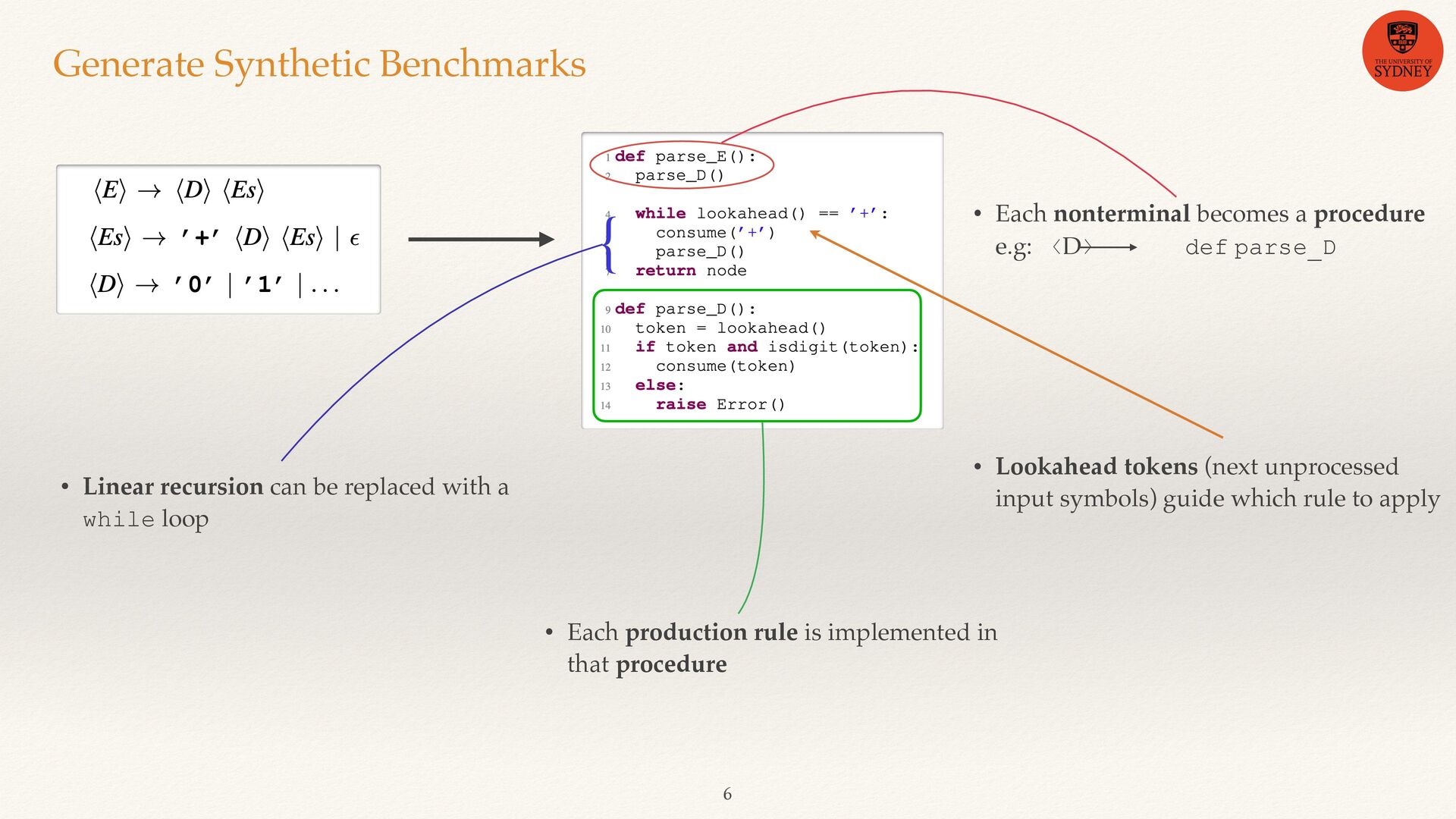
• These parsers has complexity comparable to real-world programs • Any control- fl ow can be represented as context-free LL(1) grammar • The reverse of this is also true i.e. Converting LL(1) grammar to recursive descent parser
e.g: 〈D〉 def parse_D • Each production rule is implemented in that procedure • Linear recursion can be replaced with a while loop { • Lookahead tokens (next unprocessed input symbols) guide which rule to apply
of non-terminals # of procedures # and length of production rules Branching complexity Depth and type of recursion Direct, indirect, linear recursion Unreachable nonterminals or dead code Partially unreachable programs These parser programs will be our ground-truth subjects • Grammar has reachability property parser procedures are reachable • Expansion rules Reachable inputs
• Sampling Unit - All the inputs generated within a time interval (STADS) • Previous research only used constant interval size [2] (i.e. 15 mins) t=0 t=r t=2r t=3r t=4r … Interval Size = r { Estimators should not depend on the sampling unit We evaluate estimator reliability by varying sampling unit size r [2] Liyanage, D., Böhme, M., Tantithamthavorn, C., & Lipp, S. (2023, May). Reachable coverage: Estimating saturation in fuzzing. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) (pp. 371-383). IEEE.
Programs 100 Generated Parsers average 100k LoC 10-20 programs from Fuzzbench Campaign Length # of Trials ~100 trials of 24hr Fuzzing campaigns ~30 trials of 7-day Fuzzing campaigns Initial Seed Corpus Well-formed valid inputs Established seeds from Fuzzbench[4] Evaluation Metrics • Mean-bias • Variance • Con fi dence Intervals • Welch’s t-test or non-parametric test [4] Metzman, J., Szekeres, L., Simon, L., Sprabery, R., & Arya, A. (2021, August). Fuzzbench: an open fuzzer benchmarking platform and service. In Proceedings of the 29th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering (pp. 1393-1403).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}