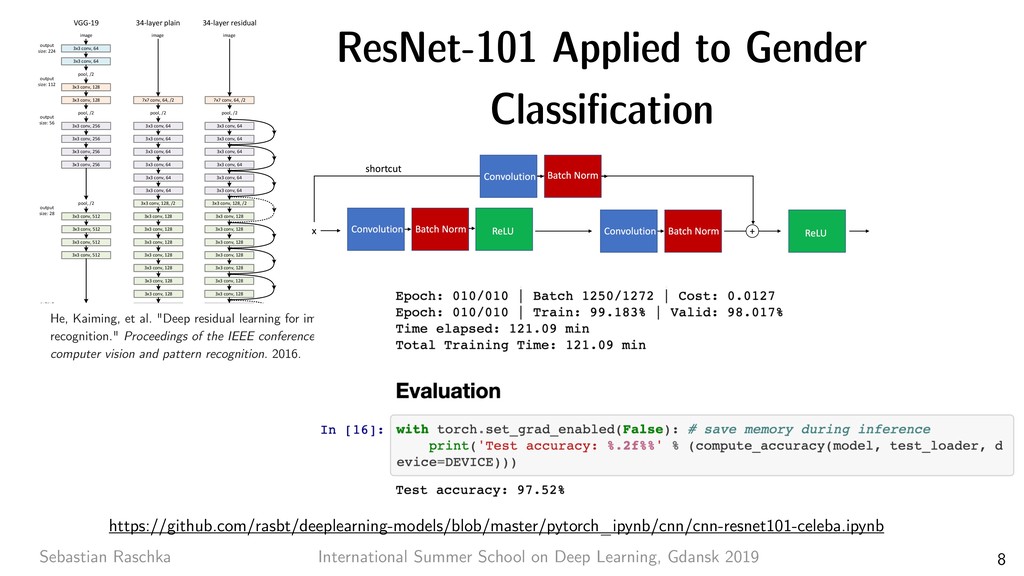
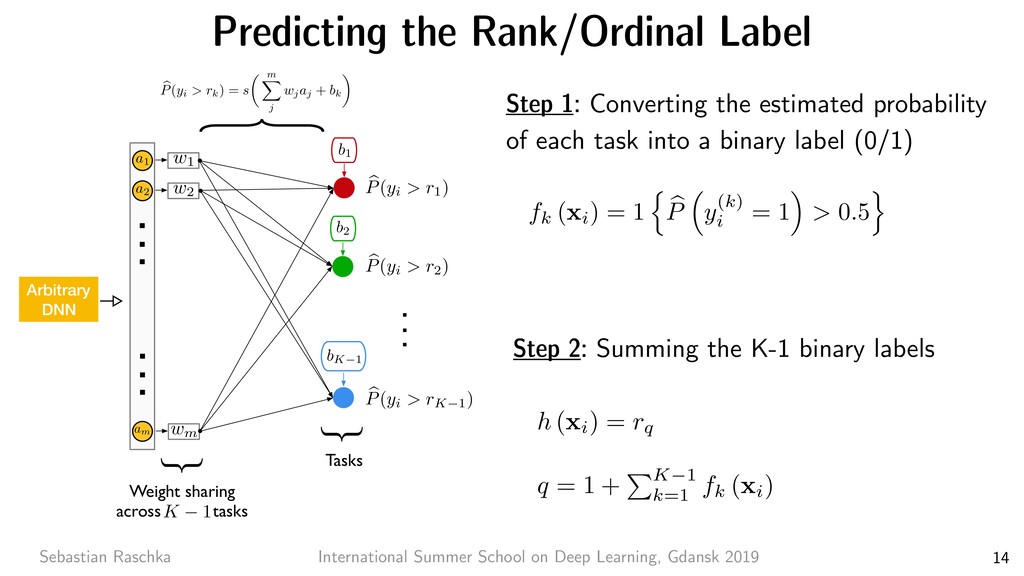
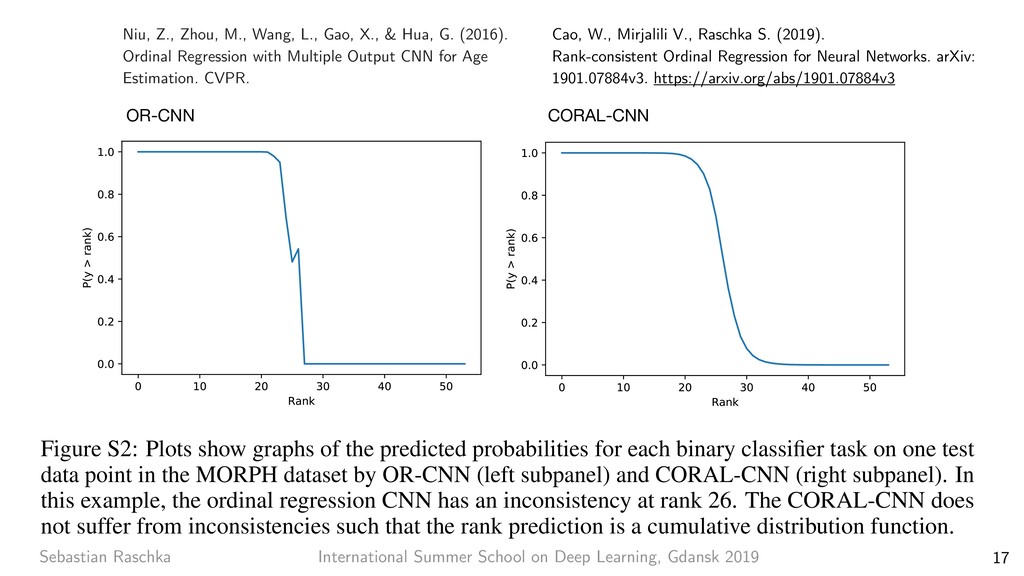
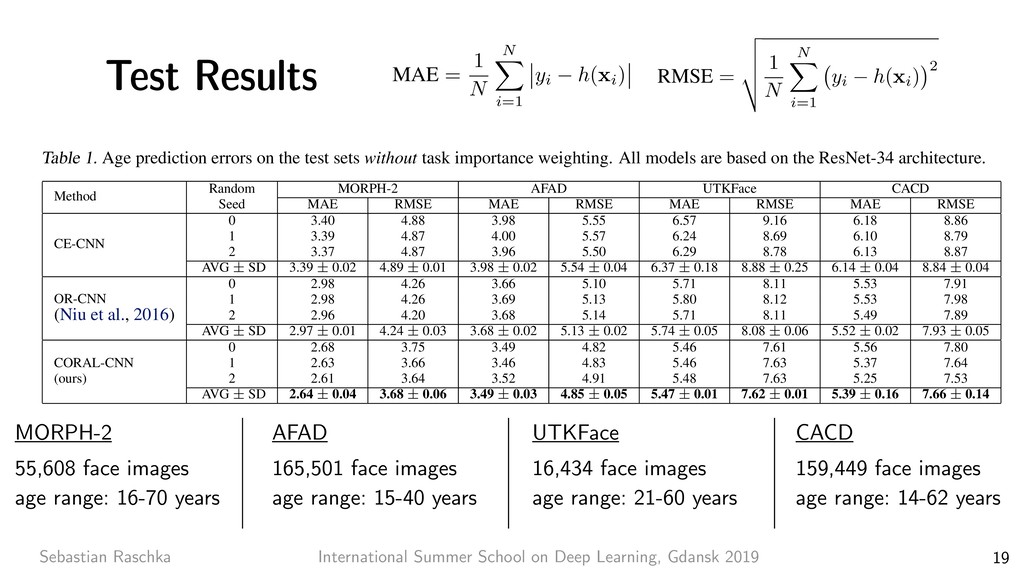
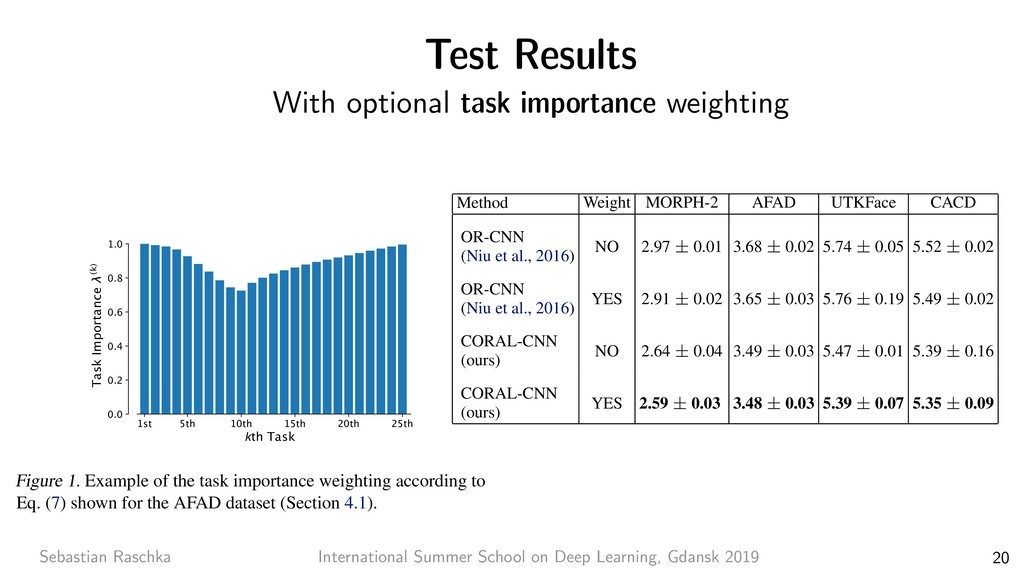
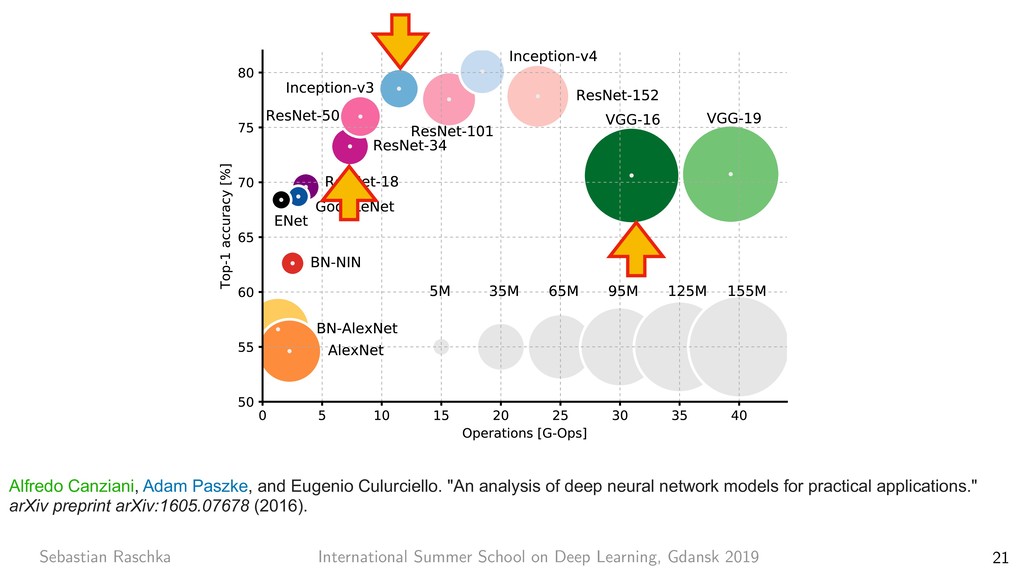
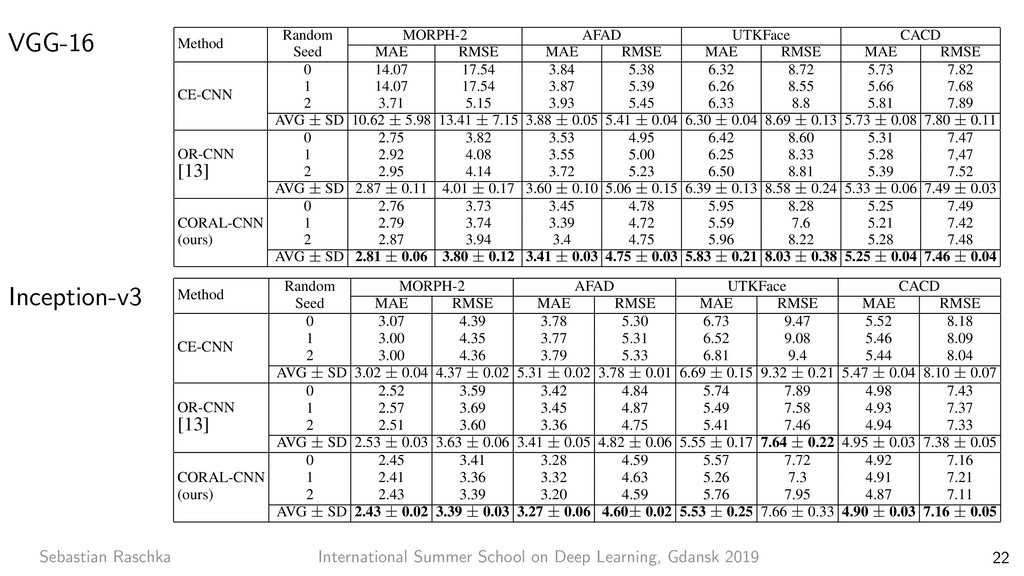
8 7x7 conv, 64, /2 pool, /2 3x3 conv, 64 3x3 conv, 64 3x3 conv, 64 3x3 conv, 64 3x3 conv, 64 3x3 conv, 64 3x3 conv, 128, /2 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 256, /2 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 512, /2 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 avg pool fc 1000 image 3x3 conv, 512 3x3 conv, 64 3x3 conv, 64 pool, /2 3x3 conv, 128 3x3 conv, 128 pool, /2 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 pool, /2 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 pool, /2 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 pool, /2 fc 4096 fc 4096 fc 1000 image output size: 112 output size: 224 output size: 56 output size: 28 output size: 14 output size: 7 output size: 1 VGG-19 34-layer plain 7x7 conv, 64, /2 pool, /2 3x3 conv, 64 3x3 conv, 64 3x3 conv, 64 3x3 conv, 64 3x3 conv, 64 3x3 conv, 64 3x3 conv, 128, /2 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 128 3x3 conv, 256, /2 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 256 3x3 conv, 512, /2 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 3x3 conv, 512 avg pool fc 1000 image 34-layer residual Residual Network. Based on the above plain network, we insert shortcut connections (Fig. 3, right) which turn the network into its counterpart residual version. The identity shortcuts (Eqn.(1)) can be directly used when the input and output are of the same dimensions (solid line shortcuts in Fig. 3). When the dimensions increase (dotted line shortcuts in Fig. 3), we consider two options: (A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter; (B) The projection shortcut in Eqn.(2) is used to match dimensions (done by 1×1 convolutions). For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2. 3.4. Implementation Our implementation for ImageNet follows the practice in [21, 40]. The image is resized with its shorter side ran- domly sampled in [256, 480] for scale augmentation [40]. A 224×224 crop is randomly sampled from an image or its horizontal flip, with the per-pixel mean subtracted [21]. The standard color augmentation in [21] is used. We adopt batch normalization (BN) [16] right after each convolution and before activation, following [16]. We initialize the weights as in [12] and train all plain/residual nets from scratch. We use SGD with a mini-batch size of 256. The learning rate starts from 0.1 and is divided by 10 when the error plateaus, and the models are trained for up to 60 × 104 iterations. We use a weight decay of 0.0001 and a momentum of 0.9. We do not use dropout [13], following the practice in [16]. In testing, for comparison studies we adopt the standard 10-crop testing [21]. For best results, we adopt the fully- convolutional form as in [40, 12], and average the scores at multiple scales (images are resized such that the shorter side is in {224, 256, 384, 480, 640}). 4. Experiments 4.1. ImageNet Classification We evaluate our method on the ImageNet 2012 classifi- cation dataset [35] that consists of 1000 classes. The models are trained on the 1.28 million training images, and evalu- ated on the 50k validation images. We also obtain a final result on the 100k test images, reported by the test server. We evaluate both top-1 and top-5 error rates. Plain Networks. We first evaluate 18-layer and 34-layer He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. ResNet-101 Applied to Gender Classification https://github.com/rasbt/deeplearning-models/blob/master/pytorch_ipynb/cnn/cnn-resnet101-celeba.ipynb
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}