Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
気になった論文20本をまとめて紹介します@NeurIPS論文読み会
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Recruit
PRO
February 28, 2023
Business
2.3k
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
気になった論文20本をまとめて紹介します@NeurIPS論文読み会
2023年2月28日に、「NeurIPS論文読み会」で発表した、本田志温の資料です。
Recruit
PRO
February 28, 2023
More Decks by Recruit
See All by Recruit
開発が速く安くなった後の話 AI時代のソフトウェアエンジニアリング組織論 #devsumi
recruitengineers
PRO
4
1k
双方向推薦システムにおける長期的マッチング最大化に向けた代理目的関数の設計と実証
recruitengineers
PRO
0
100
就職⽀援サービスにおけるキャリアアドバイザーのシフトスケジューリング
recruitengineers
PRO
1
180
Model Routerを使った逐次LLM選択による毀損低減効果の検証
recruitengineers
PRO
1
63
ストリーム処理基盤のFlink移行検証と適材適所の実践
recruitengineers
PRO
2
110
AI 時代の Platform Engineering
recruitengineers
PRO
2
460
巨大プラットフォームを進化させる「第3のROI」
recruitengineers
PRO
2
3.6k
データ戦略を加速させる プラットフォーム エンジニアリングと進化的アーキテクチャ
recruitengineers
PRO
2
110
まなび領域における生成AI活用事例
recruitengineers
PRO
2
320
Other Decks in Business
See All in Business
サステナブルな成長を支えるセルフマネジメントの技術/Self Management skill for growth
ikuodanaka
1
280
会社紹介資料/Idein株式会社
ideininc
0
120
現実は、会話から生まれる。〜 1on1とチームの場を繋ぐ、社会構成主義的実践 〜
emi0726
1
340
5年間コードを書かなかったVPoEが なぜ現場に戻ったのか?
gessy0129
1
270
FABRIC TOKYO会社紹介資料 / We are hiring(2026年06月17日更新)
yuichirom
39
410k
01_全社_FLUX採用ピッチ資料_Ver.5.4
flux
11
220k
セーフィー株式会社(Safie Inc.) 会社紹介資料
safie_recruit
7
460k
BizDev視点で見る、Snowflake最新動向!/ snowflake-trend
finanori
1
220
エムスリーキャリア Work Support採用資料 / M3C Work Support
m3c
0
14k
Advanced:マルチエージェントの設計と運用(Claude Code)
forest8810
0
220
Sprocket会社紹介資料_20260701
sprocket
0
220
ネクストビートコーポレートガイド/corporate-guide
nextbeat
3
87k
Featured
See All Featured
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Skip the Path - Find Your Career Trail
mkilby
1
160
Git: the NoSQL Database
bkeepers
PRO
432
67k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
How to make the Groovebox
asonas
2
2.3k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
820
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Documentation Writing (for coders)
carmenintech
77
5.4k
Transcript
© Recruit Co., Ltd. All Rights Reserved 気になった論文20本を まとめて紹介します @NeurIPS
2022 論文読み会 2022/2/28 株式会社リクルート 本田志温
© Recruit Co., Ltd. All Rights Reserved 自己紹介 本田 志温(@shion_honda)
プロダクトオーナー @新規事業開発室 機械学習エンジニア @データ推進室 2020年入社で、NeurIPSには3年連続で参 加させていただいています! プライベート:最近は執筆が多め 『画像生成AIのしくみ』 『画像生成AIのしくみ』 hippocampus-garden.com/
© Recruit Co., Ltd. All Rights Reserved おことわり • 元ネタはRecruit
Data Blogの『NeurIPS 2022 参加報告 後編』です • 元ネタは自分の興味(深層学習の性質や基盤モデル)に偏っています ◦ 特に統計的学習理論、強化学習、グラフ、音声、プライバシー、因果推論あたりは手薄です • 本資料はさらに、貢献がわかりやすいものに偏っています
© Recruit Co., Ltd. All Rights Reserved 発表する内容 • 深層学習とニューラルネットワーク
• 大規模言語モデル • 強化学習 • コンピュータビジョン • データセットとベンチマーク
© Recruit Co., Ltd. All Rights Reserved 発表する内容 • 深層学習とニューラルネットワーク
• 大規模言語モデル • 強化学習 • コンピュータビジョン • データセットとベンチマーク 未知の挙動の報告や、既知の現象に 対する理論的な説明を紹介します
© Recruit Co., Ltd. All Rights Reserved grokking現象を説明する仮説:過学習から表現学習への相転移 [Power22] [Liu22]
Transformerに剰余計算を学習させたときの 埋め込み(表現)をPCAで2次元にプロットした図 grokking:過学習してしばらく経って から、急に汎化誤差が下がり始める (正解率が上がり始める)現象 ※一定の条件下で発生 grokkingを説明する仮説を提案。 「学習は初期化→過学習→表現学習という順で進む。 grokkingとは過学習から表現学習への相転移である。」 grokking
© Recruit Co., Ltd. All Rights Reserved データを適切に選ぶことで、スケーリング則の冪関数の壁を突破 従来のスケーリング則:データセットの サイズと損失は冪関数の関係(両対数
プロットで直線) ※一定の条件下で成立 データを倍々で増やしても、得られる 性能向上は逓減していく … 有益なサンプルのみを選ぶことで効率を改善する 「データが不十分なときは簡単なサンプルのみを、十分なとき は難しいサンプルのみを残す」 ※決定境界から遠い(近い)サンプルが簡単(難しい) 一部は指数関数まで改善! [Sorscher22] [Kaplan20]
© Recruit Co., Ltd. All Rights Reserved 最適化器ではAdamとSGDがまだまだ現役 Adamの収束性を改善する手法( AdaBoundなど)
がいろいろ考案されてきたが … Adamはβ1とβ2を適切に選べば必ず収束する とい うことを理論的に証明。 選び方: 1. β2をなるべく大きく取る 2. β1をβ1<√β2の範囲で選ぶ [Zhang22] SGDのハイパーパラメータ (学習率αやモメンタム 係数μ)をHyperSGDで最適化すると、収束が頑健 になる [Chandra22]
© Recruit Co., Ltd. All Rights Reserved NNへの攻撃は、敵対的入力だけではない データセット復元:画像分類モデルから訓練サンプ ルを復元
[Haim22] 「手製の」バックドア攻撃 :学習済みモデル(よく使 われるオープンソースモデルなど)の重みを直接 編集して悪い挙動を仕込む [Hong22] 復元画像 実際の画像 敵対的入力は有名だが、攻撃方法は他にもある [Goodfellow14]
© Recruit Co., Ltd. All Rights Reserved 発表する内容 • 深層学習とニューラルネットワーク
• 大規模言語モデル • 強化学習 • コンピュータビジョン • データセットとベンチマーク 大規模言語モデルを活用して多様なタ スクを解く方法や、計算を効率化するた めの手法を紹介します
© Recruit Co., Ltd. All Rights Reserved LLMに思考過程を記述させると、難しい問題も解けるようになる GPT-3の従来の使い方 具体例に思考の連鎖
(chain of thought)を入れる 回答を ”Let’s think step by step” で始める(だけ!) [Wei22] [Kojima22]
© Recruit Co., Ltd. All Rights Reserved LLMに数学やプログラミングの問題を解かせる 数学 プログラミング
[Lewkowycz22] [Le22]
© Recruit Co., Ltd. All Rights Reserved LLMを改造して、画像や動画を処理させる Flamingo:LLMの各層の前で画像に関する情報を入力できるように改造したもの [Alayrac22]
NFNet Chinchilla
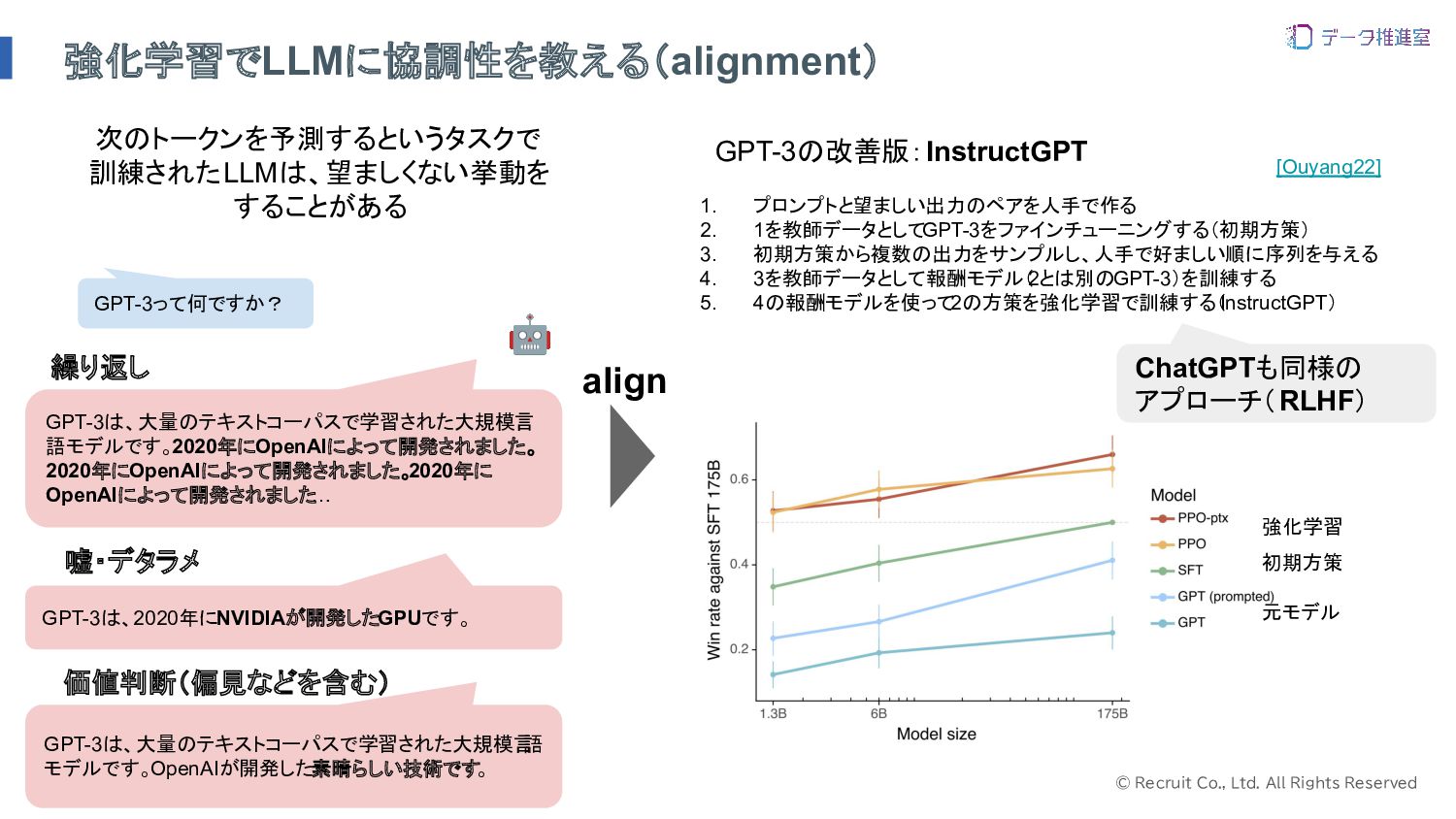
© Recruit Co., Ltd. All Rights Reserved 強化学習でLLMに協調性を教える(alignment) 1. プロンプトと望ましい出力のペアを人手で作る
2. 1を教師データとしてGPT-3をファインチューニングする(初期方策) 3. 初期方策から複数の出力をサンプルし、人手で好ましい順に序列を与える 4. 3を教師データとして報酬モデル( 2とは別のGPT-3)を訓練する 5. 4の報酬モデルを使って 2の方策を強化学習で訓練する( InstructGPT) GPT-3は、大量のテキストコーパスで学習された大規模言 語モデルです。2020年にOpenAIによって開発されました。 2020年にOpenAIによって開発されました。 2020年に OpenAIによって開発されました … GPT-3は、2020年にNVIDIAが開発したGPUです。 🤖 GPT-3って何ですか? 次のトークンを予測するというタスクで 訓練されたLLMは、望ましくない挙動を することがある 繰り返し 嘘・デタラメ GPT-3は、大量のテキストコーパスで学習された大規模言 語 モデルです。OpenAIが開発した素晴らしい技術です 。 価値判断(偏見などを含む) align GPT-3の改善版:InstructGPT ChatGPTも同様の アプローチ(RLHF) 強化学習 初期方策 元モデル [Ouyang22]
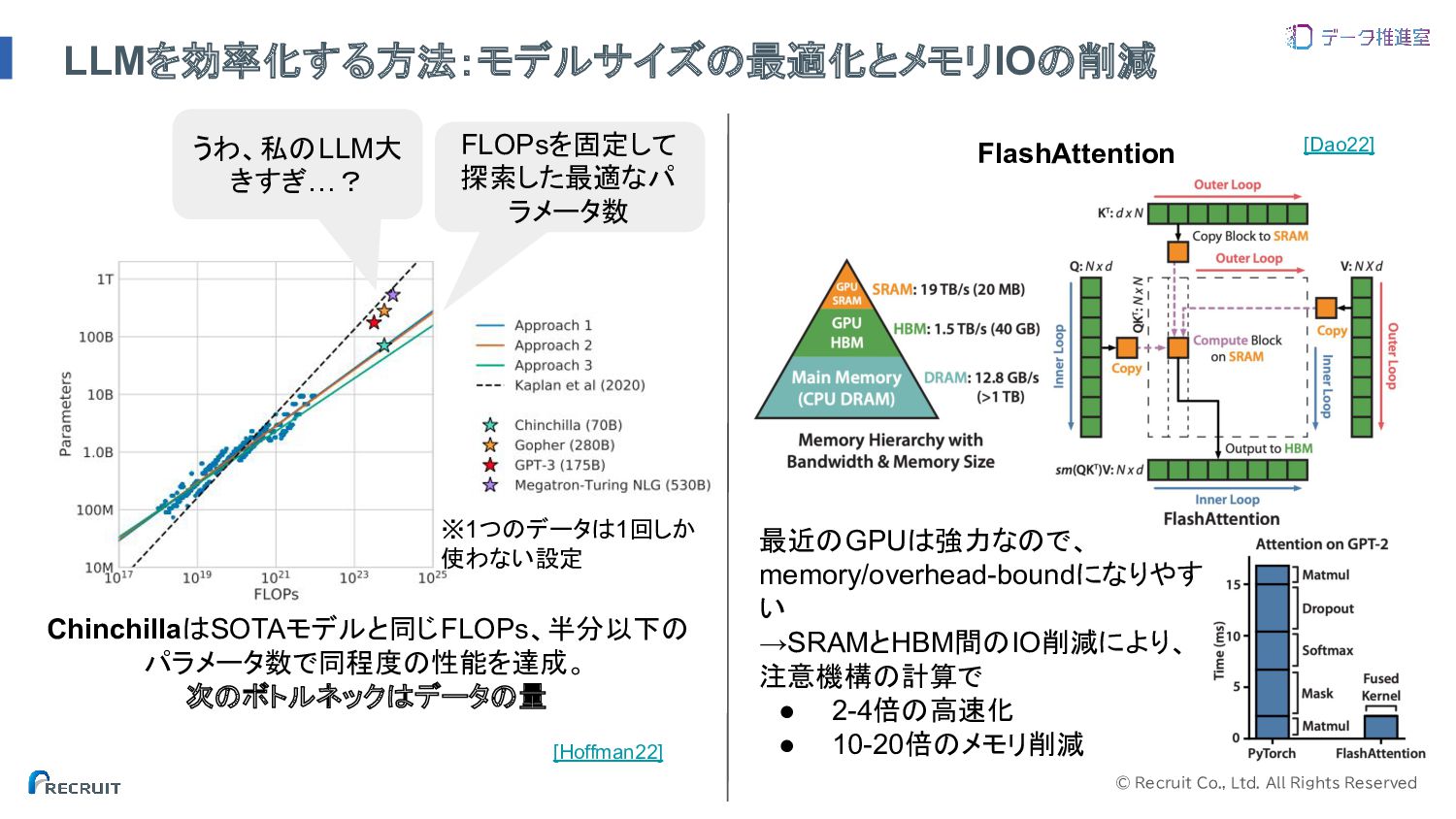
© Recruit Co., Ltd. All Rights Reserved LLMを効率化する方法:モデルサイズの最適化とメモリIOの削減 FLOPsを固定して 探索した最適なパ
ラメータ数 うわ、私のLLM大 きすぎ…? ChinchillaはSOTAモデルと同じFLOPs、半分以下の パラメータ数で同程度の性能を達成。 次のボトルネックはデータの量 [Hoffman22] FlashAttention [Dao22] 最近のGPUは強力なので、 memory/overhead-boundになりやす い →SRAMとHBM間のIO削減により、 注意機構の計算で • 2-4倍の高速化 • 10-20倍のメモリ削減 ※1つのデータは1回しか 使わない設定
© Recruit Co., Ltd. All Rights Reserved 発表する内容 • 深層学習とニューラルネットワーク
• 大規模言語モデル • 強化学習 • コンピュータビジョン • データセットとベンチマーク オフライン強化学習の設定で Transformerが強みを発揮してい るという話をします
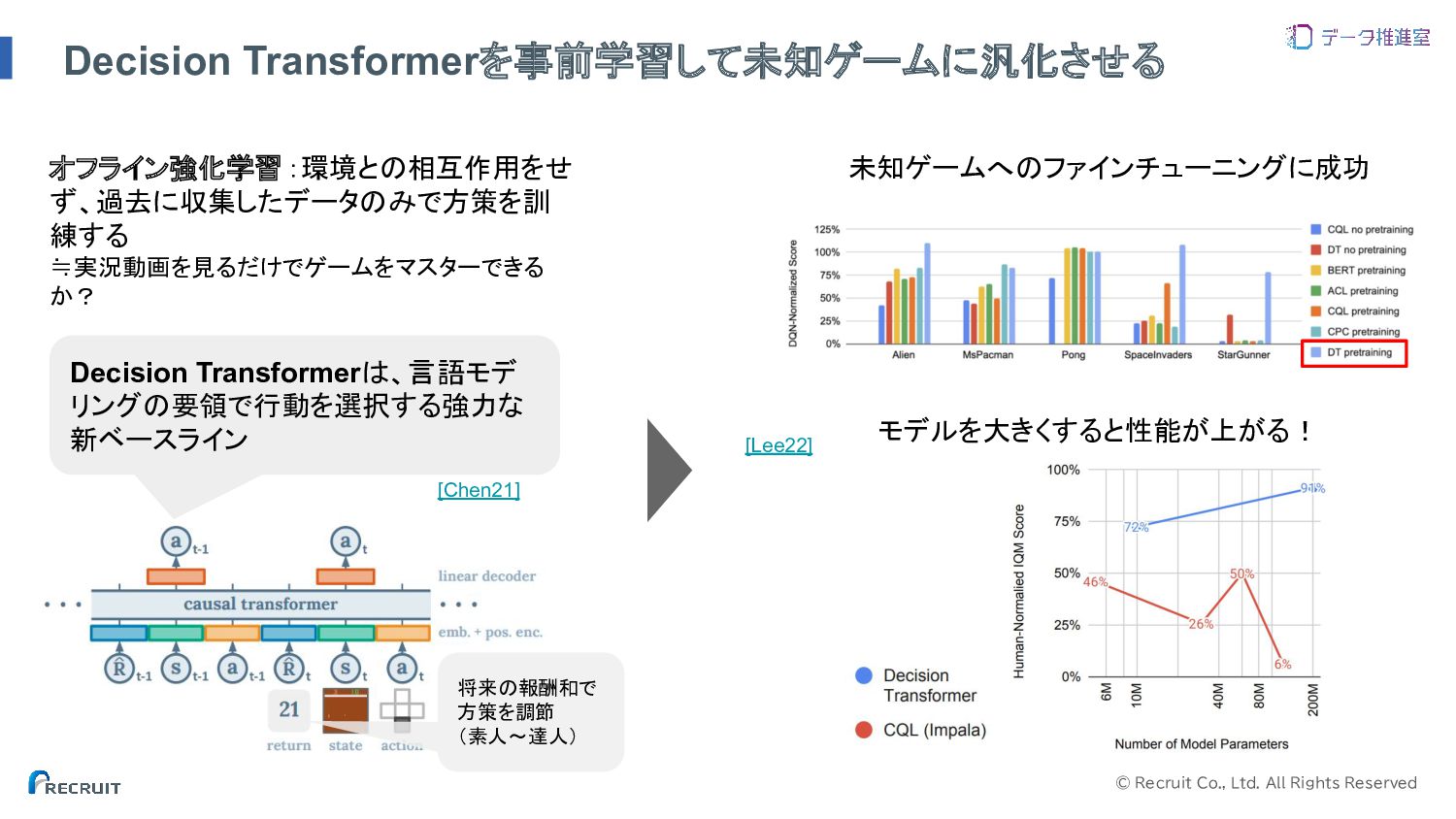
© Recruit Co., Ltd. All Rights Reserved Decision Transformerを事前学習して未知ゲームに汎化させる オフライン強化学習:環境との相互作用をせ
ず、過去に収集したデータのみで方策を訓 練する ≒実況動画を見るだけでゲームをマスターできる か? Decision Transformerは、言語モデ リングの要領で行動を選択する強力な 新ベースライン 将来の報酬和で 方策を調節 (素人〜達人) 未知ゲームへのファインチューニングに成功 モデルを大きくすると性能が上がる! [Lee22] [Chen21]
© Recruit Co., Ltd. All Rights Reserved 発表する内容 • 深層学習とニューラルネットワーク
• 大規模言語モデル • 強化学習 • コンピュータビジョン • データセットとベンチマーク コンテキスト内学習と拡散モデルを取り 上げます
© Recruit Co., Ltd. All Rights Reserved 画像でもコンテキスト内学習を実現 通常のコンテキスト内学習では、タ スク説明を自然言語で行う
[Brown20] visual prompting:画像の入出力ペアだけでタスクを説明 多様な画像出力タスクを解ける [Bar22] ※ちなみに、訓練データはarXivのコンピュータビジョンの論文から集め た9万枚の図
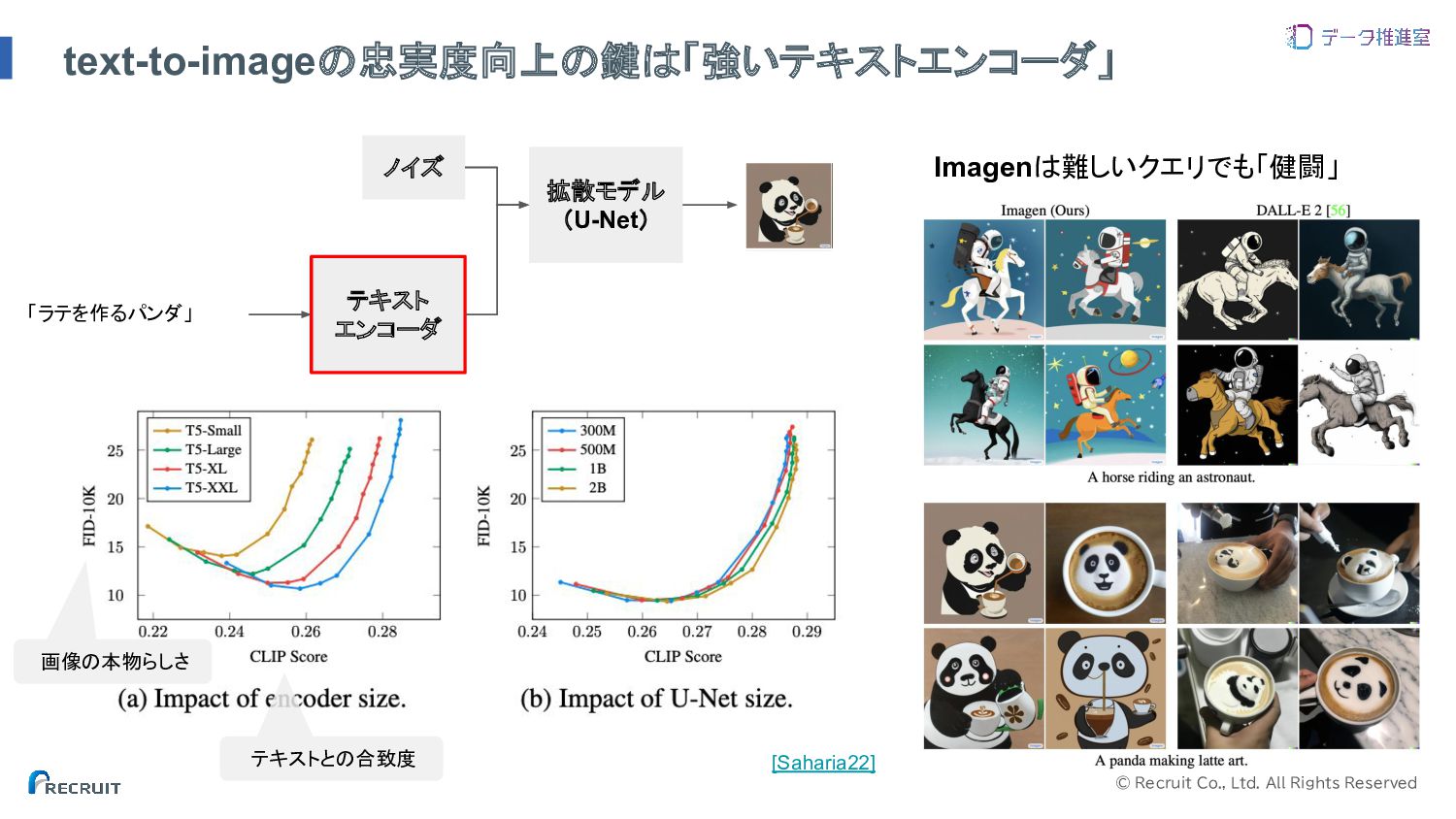
© Recruit Co., Ltd. All Rights Reserved text-to-imageの忠実度向上の鍵は「強いテキストエンコーダ」 Imagenは難しいクエリでも「健闘」 テキストとの合致度
画像の本物らしさ テキスト エンコーダ 拡散モデル (U-Net) 「ラテを作るパンダ」 ノイズ [Saharia22]
© Recruit Co., Ltd. All Rights Reserved 発表する内容 • 深層学習とニューラルネットワーク
• 大規模言語モデル • 強化学習 • コンピュータビジョン • データセットとベンチマーク Data-centric AIの時代に重要性が増す データセット及びベンチマーク作成の研 究を紹介します
© Recruit Co., Ltd. All Rights Reserved Embodied AIの研究を加速させるデータセットとベンチマーク ここ数年で大きく発展した「与えられた情報」を処理する
AIと比較して、Embodied AIには伸びしろがある ※Embodied AI:身体性を持ち、物理世界との相互作用から何らかの能力を獲得するエージェント まずはデータや環境が必要 MineDojo:Minecraftを元にした、オープンエンドな使 い方ができるフレームワーク ※wikiやプレイ動画も付属 ProcTHOR:相互作用可能な「家」を自動で生成するフ レームワーク [Fan22] [Deitke22]
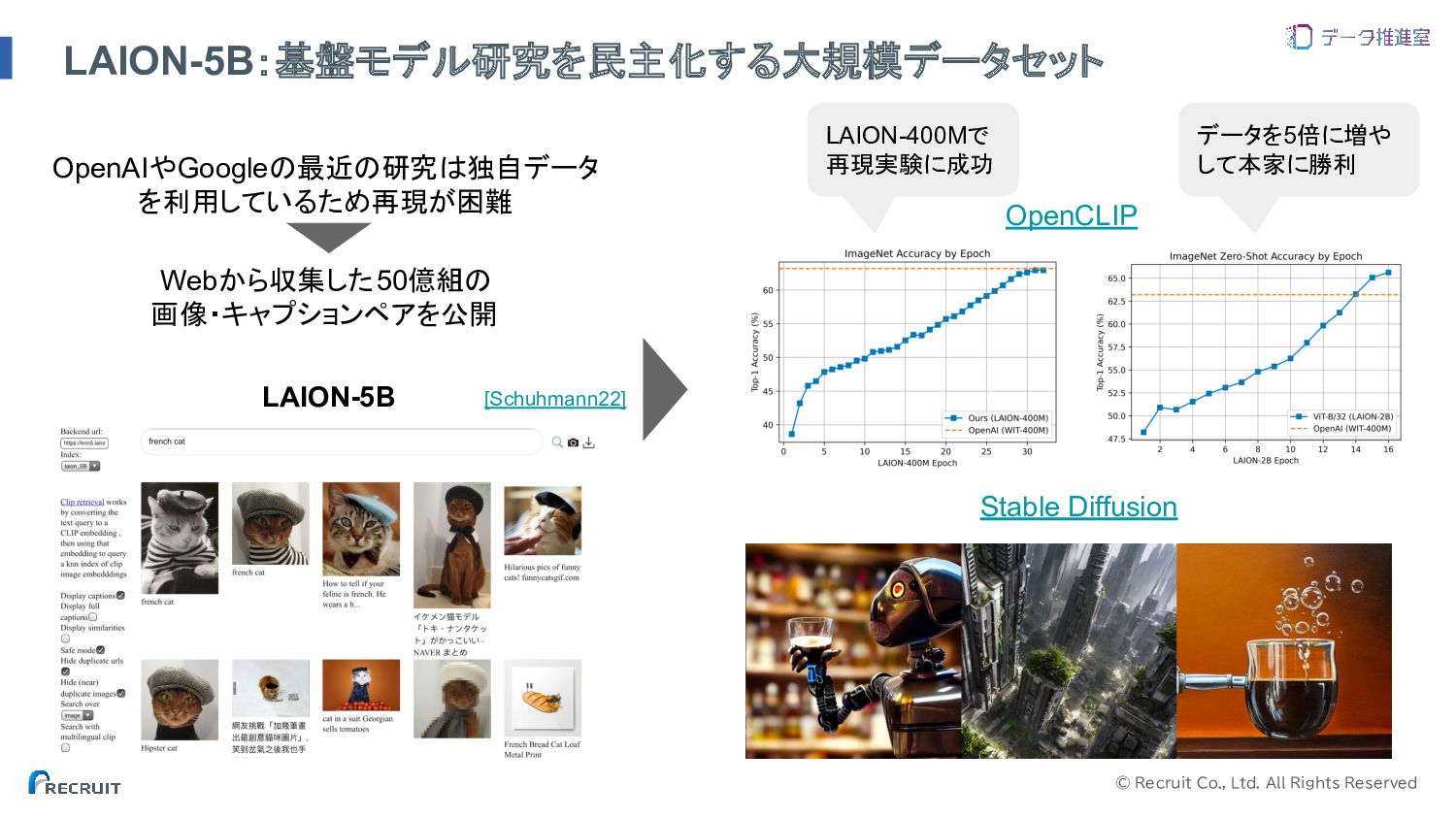
© Recruit Co., Ltd. All Rights Reserved LAION-5B:基盤モデル研究を民主化する大規模データセット OpenCLIP Stable
Diffusion データを5倍に増や して本家に勝利 LAION-400Mで 再現実験に成功 OpenAIやGoogleの最近の研究は独自データ を利用しているため再現が困難 Webから収集した50億組の 画像・キャプションペアを公開 LAION-5B [Schuhmann22]
© Recruit Co., Ltd. All Rights Reserved おまけ:個人的な展望 大規模言語モデルや基盤モデルの今後は? •
画像や動画から視覚的な知識を獲得する ◦ 例:Flamingo • 「Web上の情報を調べてまとめる」という純粋な情 報処理において人間を超える ◦ 例:Bing Chat • 行動計画や意思決定も実用レベルに達し始める ◦ 例:Language Models as Zero-Shot Planners 次のフロンティアは? • 音声や動画、3D、そしてマルチモーダル • 強化学習×基盤モデル • Embodied AI 基礎技術(スケールするモデル)と 材料(データ セットや強化学習のリッチな環境)が揃いつつある
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© Recruit Co., Ltd. All Rights Reserved grokking現象を説明する仮説:過学習から表現学習への相転移 [Power22] [Liu22]](https://files.speakerdeck.com/presentations/3fcf52f689374e49a9cb3e2cd6ca3bd6/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© Recruit Co., Ltd. All Rights Reserved LLMを改造して、画像や動画を処理させる Flamingo:LLMの各層の前で画像に関する情報を入力できるように改造したもの [Alayrac22]](https://files.speakerdeck.com/presentations/3fcf52f689374e49a9cb3e2cd6ca3bd6/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}