Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMのプロダクト装着と独自モデル開発
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Recruit
PRO
March 06, 2025
Technology
850
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLMのプロダクト装着と独自モデル開発
2025/2/20に開催したRecruit Tech Conference 2025の桐生と王の資料です
Recruit
PRO
March 06, 2025
More Decks by Recruit
See All by Recruit
双方向推薦システムにおける長期的マッチング最大化に向けた代理目的関数の設計と実証
recruitengineers
PRO
0
90
就職⽀援サービスにおけるキャリアアドバイザーのシフトスケジューリング
recruitengineers
PRO
1
170
Model Routerを使った逐次LLM選択による毀損低減効果の検証
recruitengineers
PRO
1
58
ストリーム処理基盤のFlink移行検証と適材適所の実践
recruitengineers
PRO
2
100
AI 時代の Platform Engineering
recruitengineers
PRO
2
450
巨大プラットフォームを進化させる「第3のROI」
recruitengineers
PRO
2
3.6k
データ戦略を加速させる プラットフォーム エンジニアリングと進化的アーキテクチャ
recruitengineers
PRO
2
110
まなび領域における生成AI活用事例
recruitengineers
PRO
2
320
AI時代にエンジニアはどう成長すれば良いのか?
recruitengineers
PRO
1
570
Other Decks in Technology
See All in Technology
Claude Codeとハーネスについて考えてみる
oikon48
18
8.7k
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
0
2.4k
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
3.5k
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
400
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
550
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
740
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
390
最近評価が難しくなった
maroon8021
0
250
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1.5k
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
330
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
250
AIで政治は変わるのか? — 中高生と考えたAI時代の民主主義(東海高校サタデープログラム)
eitarosuda
0
400
Featured
See All Featured
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Designing Powerful Visuals for Engaging Learning
tmiket
1
440
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
670
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.7k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
The Cost Of JavaScript in 2023
addyosmani
55
10k
The Curious Case for Waylosing
cassininazir
1
430
Transcript
LLMのプロダクト装着と独自モデル開発 RECRUIT TECH CONFERENCE 2025 R&Dの取り組みとモデルの使い分け戦略 桐生 佳介 株式会社リクルート データ推進室 王 啓航
株式会社リクルート データ推進室
桐生 佳介 DIY・エレキギター・エフェクター製作・精密射撃 経歴 / Career 2023年にリクルートにキャリア採用入社。 主に自然言語処理分野のR&Dを担当し、 言語モデルの開発や、それらを用いた事業PoCを推進。 Open
LLMの分散並列学習・Fine-Tuning・性能評価・ 推論高速化などLLM周辺の技術要素に強み。 Hugging Face にRoBERTaベースで開発した 誤字脱字検出モデルを公開中↓ 🤗 趣味 / Hobbies データ推進室 データテクノロジーユニット データテクノロジーラボ部 R&Dグループ
2023年にリクルートにキャリア採用入社。 OCR,NLP,レコメンドシステムなどの開発経験 現在、主にレコメンドシステム・LLM周辺技術の開発を 担当。 王 啓航 遊戯王・ポケカ・Kaggle 経歴 / Career
趣味 / Hobbies データ推進室 HR領域データソリューションユニット HRデータソリューション部 中途データサイエンスグループ
Agenda 1. 独自LLM開発の意義 (桐生) 2. 独自LLM開発の大変さと工夫点 (桐生) 3. LLM評価の重要性 (王)
4. プロダクト装着時の評価方法 (王)
Agenda 1. 独自LLM開発の意義 (桐生) 2. 独自LLM開発の大変さと工夫点 (桐生) 3. LLM評価の重要性 (王)
4. プロダクト装着時の評価方法 (王)
独自LLM開発の意義 Whale LM Project • Closed/Openにこだわらず、LLMの高度活用に向けたR&Dと施策実行を担うチーム • 直近はLLMの出力結果に対する評価手法についての話題がホット
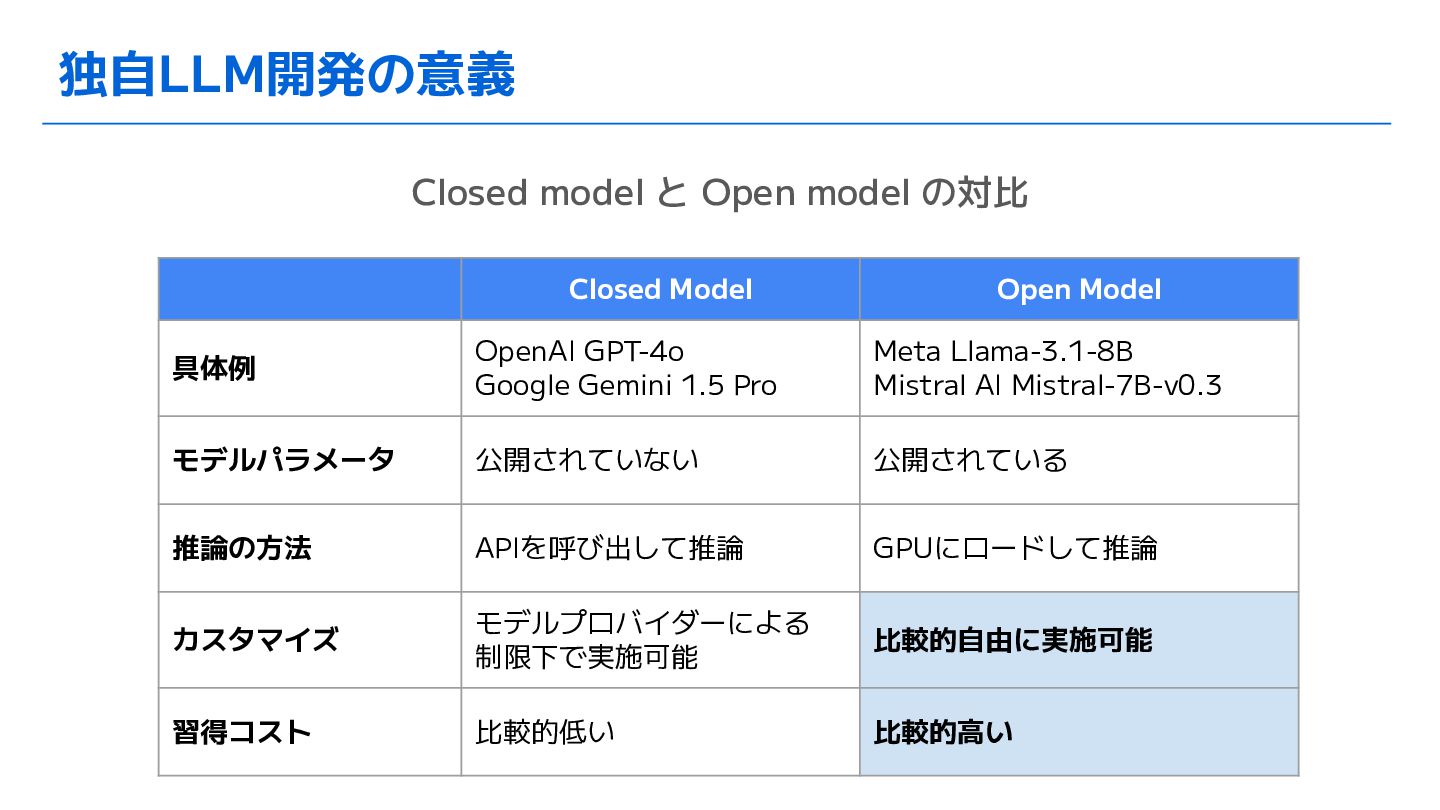
独自LLM開発の意義 Closed model と Open model の対比 Closed Model Open
Model 具体例 OpenAI GPT-4o Google Gemini 1.5 Pro Meta Llama-3.1-8B Mistral AI Mistral-7B-v0.3 モデルパラメータ 公開されていない 公開されている 推論の方法 APIを呼び出して推論 GPUにロードして推論 カスタマイズ モデルプロバイダーによる 制限下で実施可能 比較的自由に実施可能 習得コスト 比較的低い 比較的高い
独自LLM開発の意義 Open modelでLLMを開発する意義は? • 現状、LLM のプロダクト活用は Closed model の利用が基本 •
一方で3B程度の SLM(Small Language Model)で優秀なモデルが出てきている ◦ e.g. Microsoft Phi, Google Gemma, PFN Plamo 2 • 特定タスクに絞った高速推論 や On-device での推論を見据えて Open model の開発ノウハウを蓄積し、手札を増やしておくことに意義 • モデルの評価手法を確立することは Open/Closed 関係なく重要
Agenda 1. 独自LLM開発の意義 (桐生) 2. 独自LLM開発の大変さと工夫点 (桐生) 3. LLM評価の重要性 (王)
4. プロダクト装着時の評価方法 (王)
独自LLM開発の大変さと工夫点 Open modelを利用した独自LLM開発の大まかな流れ ベースモデル 選定 継続 事前学習 指示 チューニング 推論環境
デプロイ モデル 評価
独自LLM開発の大変さと工夫点 ベースモデル多すぎ問題 ベースモデル 選定 継続 事前学習 指示 チューニング 推論環境 デプロイ
モデル 評価 • 公開されている Open model が多すぎて、どれを選べば良いかわからない! ◦ LLMのリーダーボードである程度のあたりをつける ▪ e.g. Nejumi LLMリーダーボード3, open-japanese-llm-leaderboard ◦ 自前でベンチマークを流してスコアを計測する ◦ 実際に推論してみてモデルの地頭や性質を探る ◦ Tokenizerの処理効率を確認する
独自LLM開発の大変さと工夫点 事前学習わからないことだらけ問題 ベースモデル 選定 継続 事前学習 指示 チューニング 推論環境 デプロイ
モデル 評価 • 事前学習関連の情報が少なく手探りの開発になりがち ◦ デファクトスタンダードの事前学習フレームワークを利用する ◦ フレームワークのコードや Issue を読む、論文を読む ▪ 社外コミュニティへの参画で効率的に情報収集 ◦ とにかく予備実験を回してパフォーマンスチューニングをした ▪ Model Parallelism、Batch Size、I/O Optimization ..
独自LLM開発の大変さと工夫点 継続事前学習データ集め大変問題 ベースモデル 選定 継続 事前学習 指示 チューニング 推論環境 デプロイ
モデル 評価 • 事前学習用のドメインコーパス収集が大変 ◦ あらかじめ社内で使えるテキストデータの収集を呼びかけておく ◦ 金融庁が公開している決算短信情報(EDINET)などを活用 ◦ WEBコーパスからターゲットドメインと親和性の高いコーパスを選定 ▪ Wikipedia全ページを文ベクトルに変換→コサイン類似度でランキング
独自LLM開発の大変さと工夫点 指示チューニングデータの品質担保問題 ベースモデル 選定 継続 事前学習 指示 チューニング 推論環境 デプロイ
モデル 評価 • 良質な指示チューニング用データを用意するのが大変 ◦ 指示チューニングデータは量より質が重要 ◦ 事例データについて、良質な Input/Output にフィルタリング ▪ ユーザFBのラベルを活用 ▪ 品質スコアリング用の言語モデルを訓練して活用 ◦ 特定のビジネスタスクにおいて7Bモデルで GPT-3.5-Turbo を上回る性能を実現
独自LLM開発の大変さと工夫点 推論フェーズも考えること多い問題 ベースモデル 選定 継続 事前学習 指示 チューニング 推論環境 デプロイ
モデル 評価 • 推論を楽にしたい! ◦ クラウドベンダーが提供しているマネージドサービスを使ってみる ◦ Throughput 保証の有無などで課金体系が変わるのでお財布と相談 • 推論を速くしたい! ◦ 推論高速化フレームワークを利用 (e.g. vllm, TensorRT-LLM) ◦ モデルを量子化してGPUメモリを効率的に利用しバッチ推論
Agenda 1. 独自LLM開発の意義 (桐生) 2. 独自LLM開発の大変さと工夫点 (桐生) 3. LLM評価の重要性 (王)
4. プロダクト装着時の評価方法 (王)
意思決定のためのモデル評価 ベースモデル 選定 継続 事前学習 指示 チューニング 推論環境 デプロイ モデル
評価 • 業務指標やリスク評価を実現するために、モデルの評価が重要 • 評価を通じて、目標達成に向けた以下の活動が可能になる: ◦ モデル選定 ◦ プロンプト改善 ◦ モデルのファインチューニング LLM評価の重要性
• 人での評価 ◦ 専門家による評価のため、正確性が保たれている ◦ 人評価のため、スケールアップが大変 • 機械による評価 ◦ スケールアップが簡単
◦ 人評価と比べると正確性が悪化する可能性がある ◦ 場合によって汎用手法ではなく、独自の評価モデルの構築が必要 LLM評価の重要性 主要な評価手法:人評価と機械評価
LLM評価の重要性 • キーワードから職務要約を作成するタスクのエンハンス ◦ タスク概要 ◦ 機械評価を導入する目的: ▪ Promptの最適化を行い、より自然で適切な職務要約を生成する ▪
生成文の品質向上を通じて、ユーザーのフィードバック評価を改善する 事例から見る機械評価 ユーザー キーワード 入力 職務要約 生成 ユーザー フィードバック モデル 改善
• キーワードから職務要約を作成するタスクのエンハンス ◦ 評価モデルの作り方: ▪ 実際にプロダクトで取得したユーザー フィードバックを正解ラベルとして扱う ▪ DeBERTaをFine-tuningし、分類の確率をスコアとする ◦
正当性確認: ▪ 人が修正した文章と生成文章のスコアを比較、正当性を確認 ▪ A/B テストで実際フィードバック指標をオンラインでモニタリングする ◦ 結果: ▪ オフラインでスコアを通じてPrompt を正しい方向で改善できた ▪ モデル評価スコアと相関し、フィードバックが大幅改善できた LLM評価の重要性 事例から見る機械評価
Agenda 1. 独自LLM開発の意義 (桐生) 2. 独自LLM開発の大変さと工夫点 (桐生) 3. LLM評価の重要性 (王)
4. プロダクト装着時の評価方法 (王)
• 概要 ◦ 汎用手法とカスタマイズモデルの使い分け ◦ 汎用手法とカスタマイズモデル ▪ 汎用手法の例 ▪ カスタマイズモデルの例:
GBDT,BERT,LLM ◦ 評価特化の内部ライブラリの紹介 ▪ whalify-lib プロダクト装着時の評価方法 実際にプロダクトに装着時に、評価方法の使い方の紹介
汎用手法 特性: • そのまま利用できる • 必ずビジネスKPIに直結しない 適用例: • 一部対象タスク(例 要約生成) •
短期導入や既存基準でカバーできる場面 プロダクト装着時の評価方法 使い分け カスタマイズモデル 特性: • ビジネスKPIに合わせた評価目標を設定可能 • 高度なモデル選定・実験・データ収集が必要 適用例: • 特定KPIに最適化された評価基準が必要な場合
プロダクト装着時の評価方法 • 例えば:サマリ系のタスクの評価 ◦ ROUGE Score ▪ 生成テキストと参照テキストの一致度を測定。 ◦ BERTScore
▪ BERTなどの言語モデルで計算したトークン埋め込みの類似性を測定 汎用的な評価方法
プロダクト装着時の評価方法 • Learning Agency Lab - Automated Essay Scoring 2.0
◦ 人間が書いた論文を採点するコンペ ▪ 上位解法:GBDT系&BERT系 • LMSYS - Chatbot Arena Human Preference Predictions ◦ LLMの出力どれが人の好みの出力かを予測するコンペ ▪ 上位解法:LLM コンペから学んだ自然言語の評価手法
GBDT系による評価 • LightGBMモデル ◦ 高速のツリーモデル、分類・回帰・ランキングなどの課題を解決できる ◦ 直接自然言語をモデルに入れるのが難しい、自ら特徴量の設計が必要 • よくある特徴量設計 ◦
TF- IDF ▪ 各文書中に含まれる各単語が「その文書内でどれくらい重要か」を表す尺度で、具体的 には「(ある文書における、ある単語の出現頻度)×(ある単語の文書間でのレア度)」 ◦ 単語の数、文章の長さ、段落の数 ◦ ほかのモデルの評価スコア(流暢さ、文法など) プロダクト装着時の評価方法
BERT系による評価 • DeBERTa ◦ そのまま自然言語使えるため、特徴量の設計が不要 ◦ 特にDeBERTa v3がコンペでよく使われる ◦ 事前学習モデルのため、ダウンストリームタスクに合わせてFTが必要
▪ 文章と正解ラベルがあれば分類、回帰ができる プロダクト装着時の評価方法
LLMによる評価 • LLM-as-a-Judge ◦ Promptを設計して、LLMを使って、LLMの生成文を評価する ◦ Logitを利用し、生成タスクを分類タスクに置き換える ▪ Logit biasを設定して、特定のTokenのlogitを利用
• 例:Yes,NoのToken +100にして、logprobsを確率に変換 ▪ 対応可能なモデル: • OpenAI • 各オープンモデル(Qwen系,Llama系,Gemma系...) プロダクト装着時の評価方法
内部での評価用ライブラリ開発 whalify-lib • 目的:評価をこのライブラリ内で完結 • 内容 ◦ ビジネスKPIを踏まえた成果物の評価 ◦ 流暢さ、正しさ、類似度、リスク
◦ LLM-as-a-Judgeなど プロダクト装着時の評価方法
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}