Share
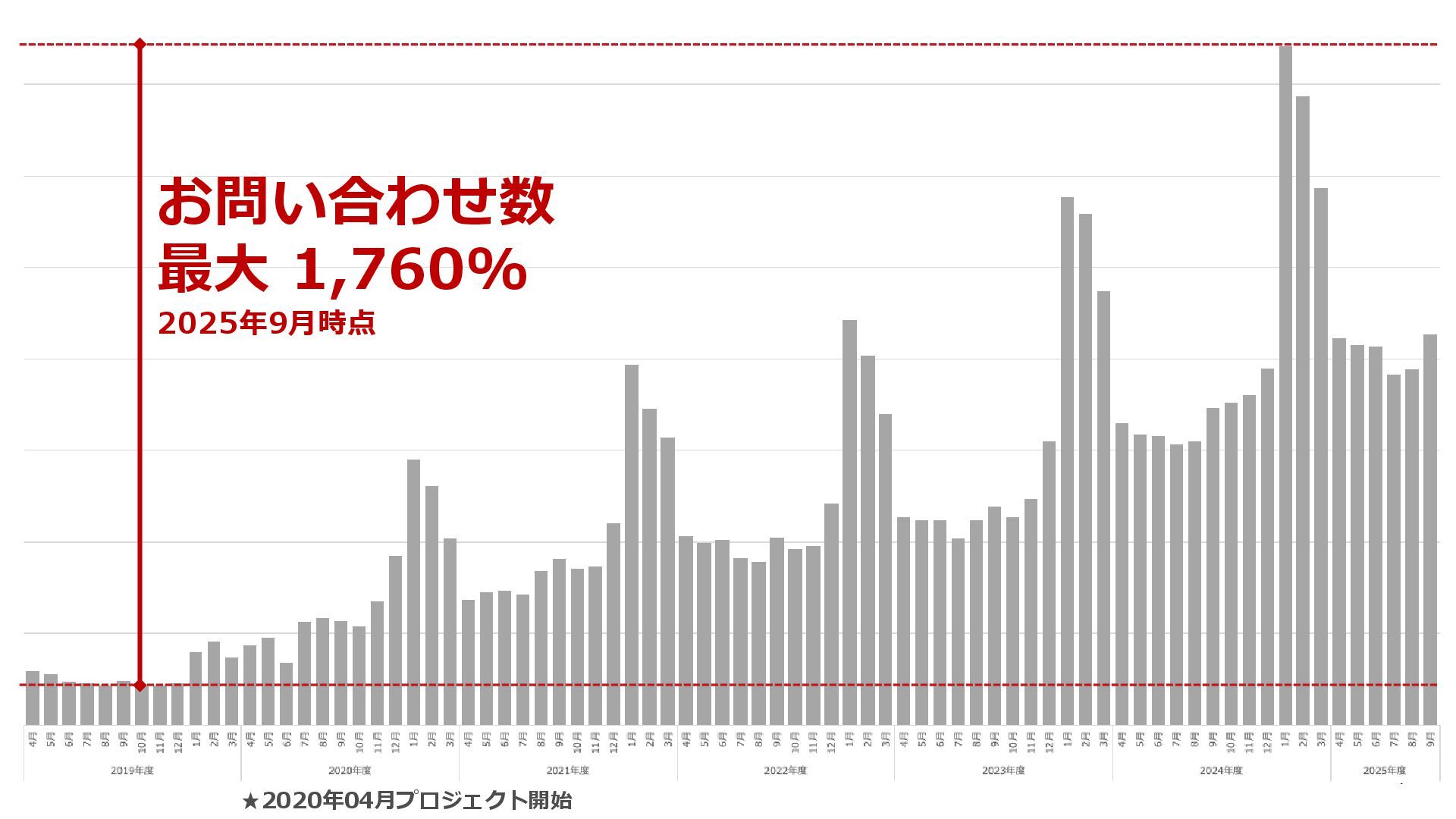
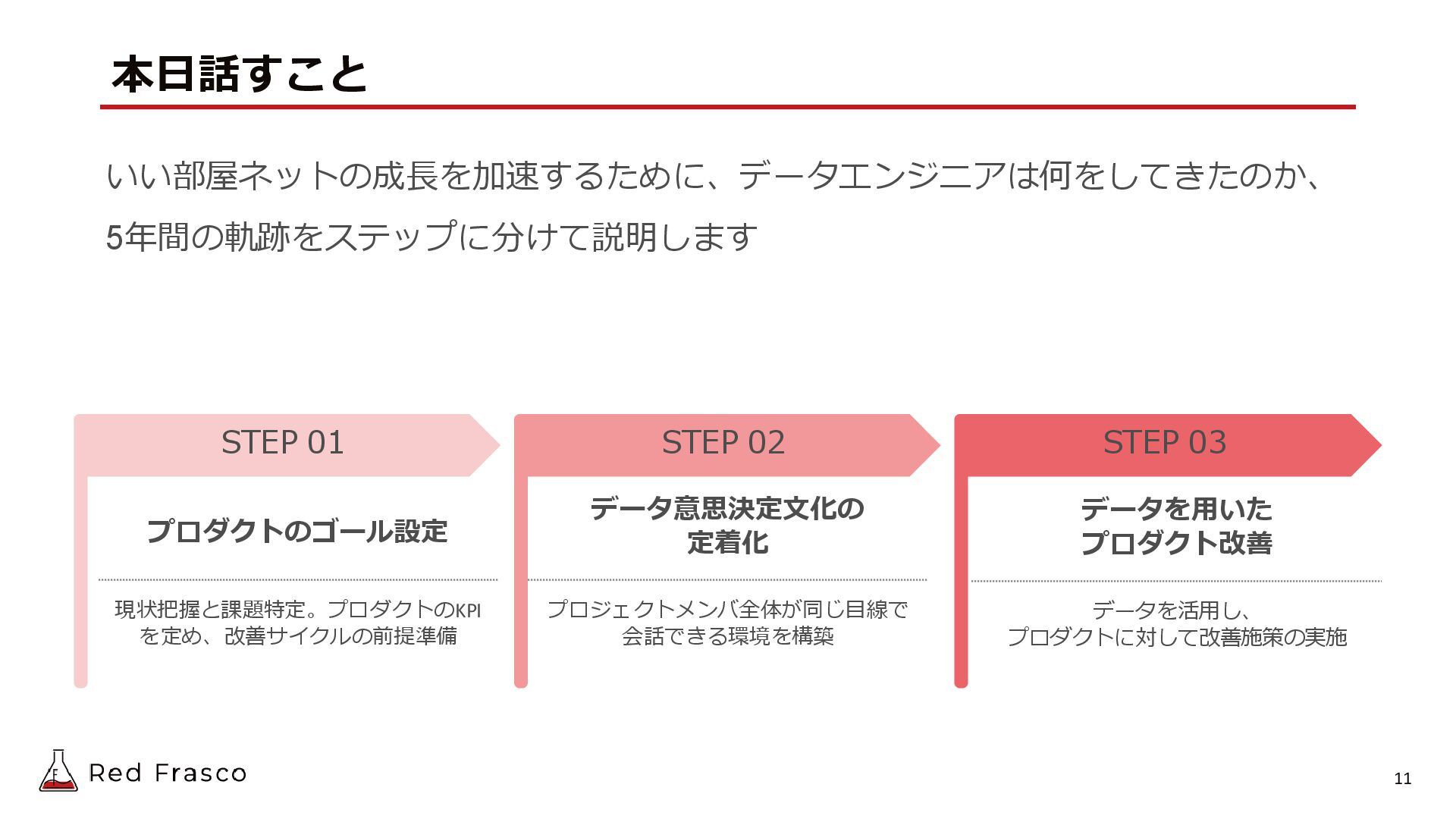
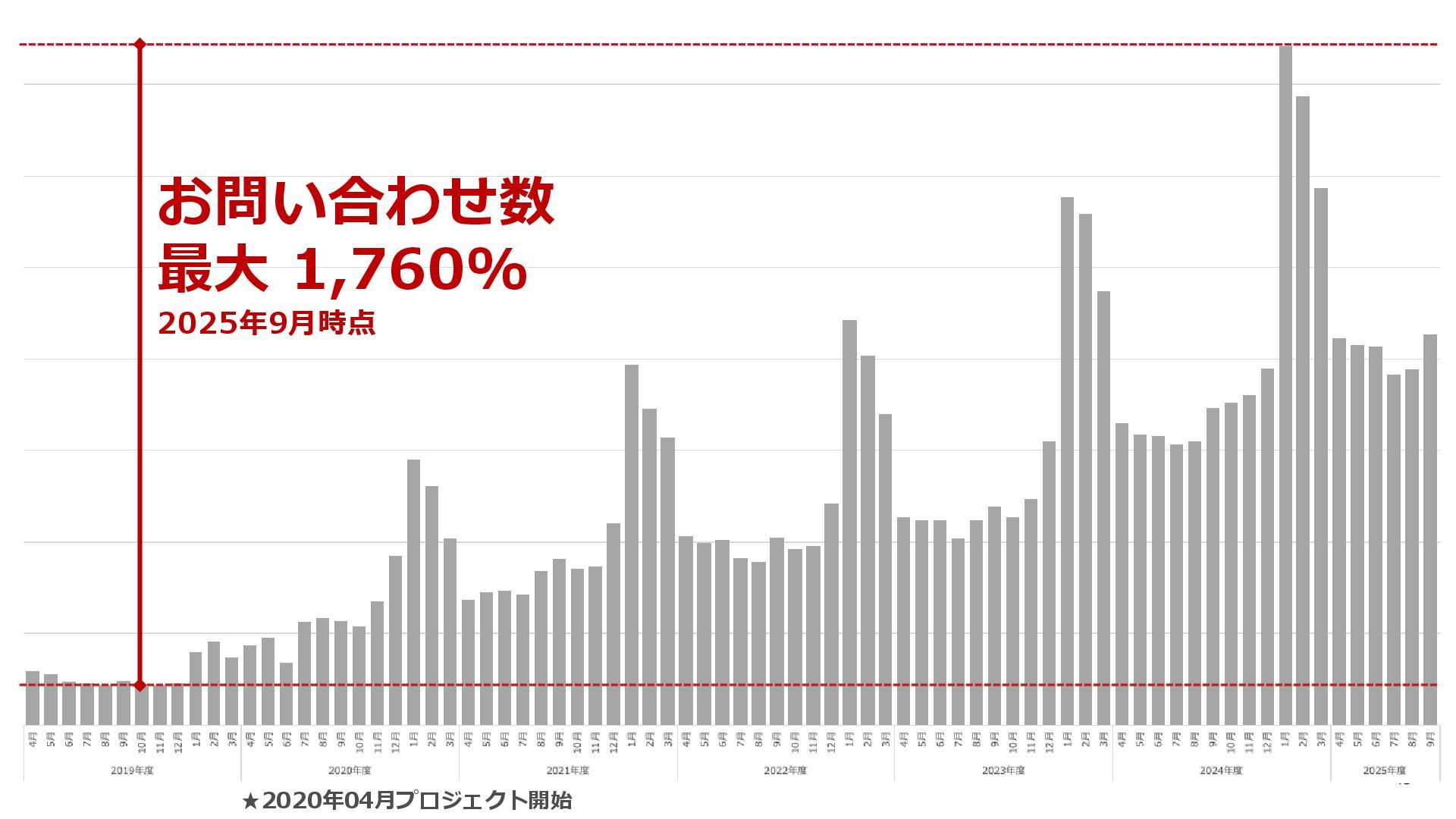
2025/11/6に開催されたData Engineering Summitの登壇資料です。 「いい部屋ネット」の成長を加速するために、Red Frascoのデータエンジニアは何をしてきたのか、5年間の軌跡をステップに分けて説明します。
参考URL:https://data-engineering-summit.findy-tools.io/2025
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
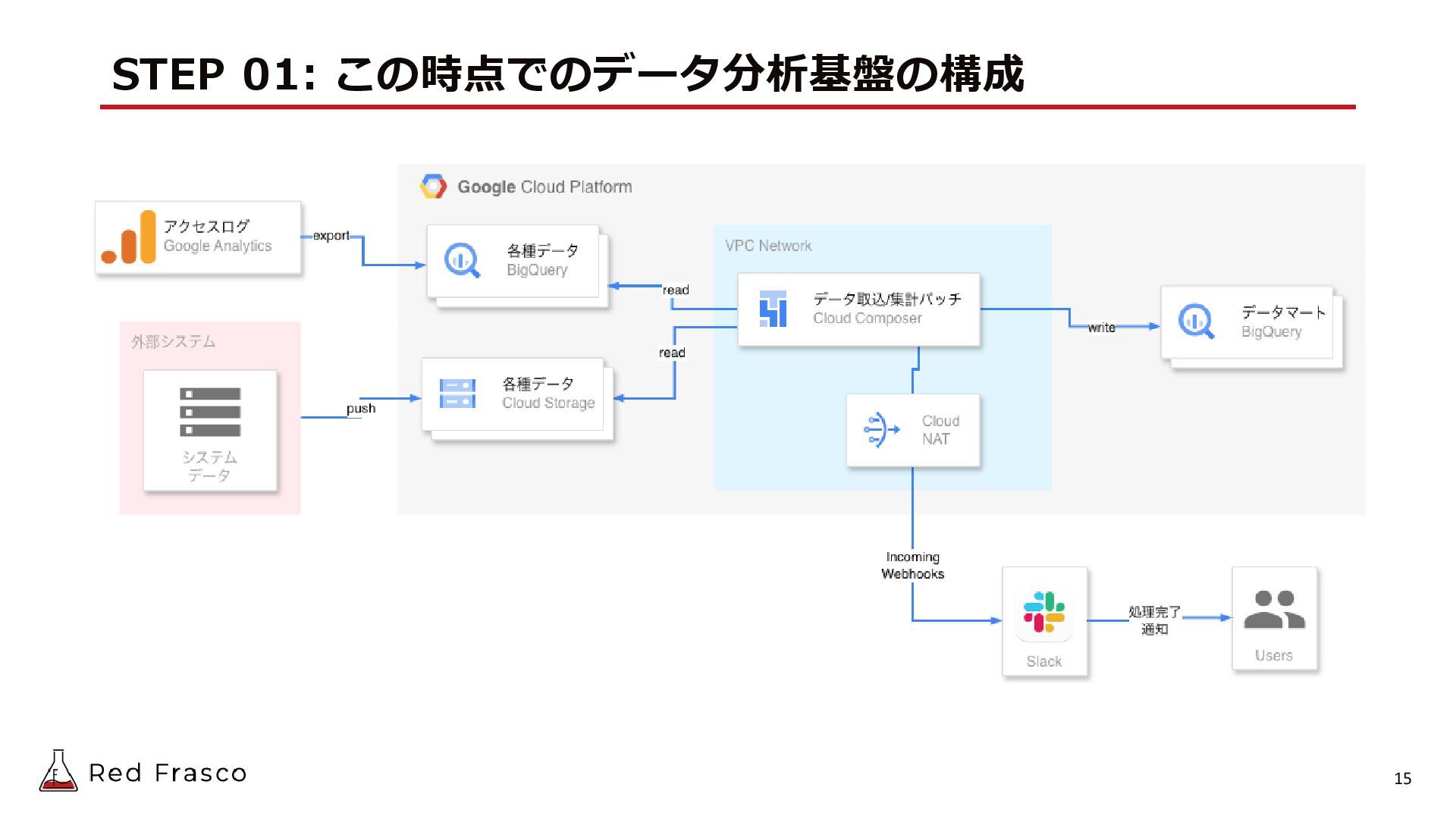{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
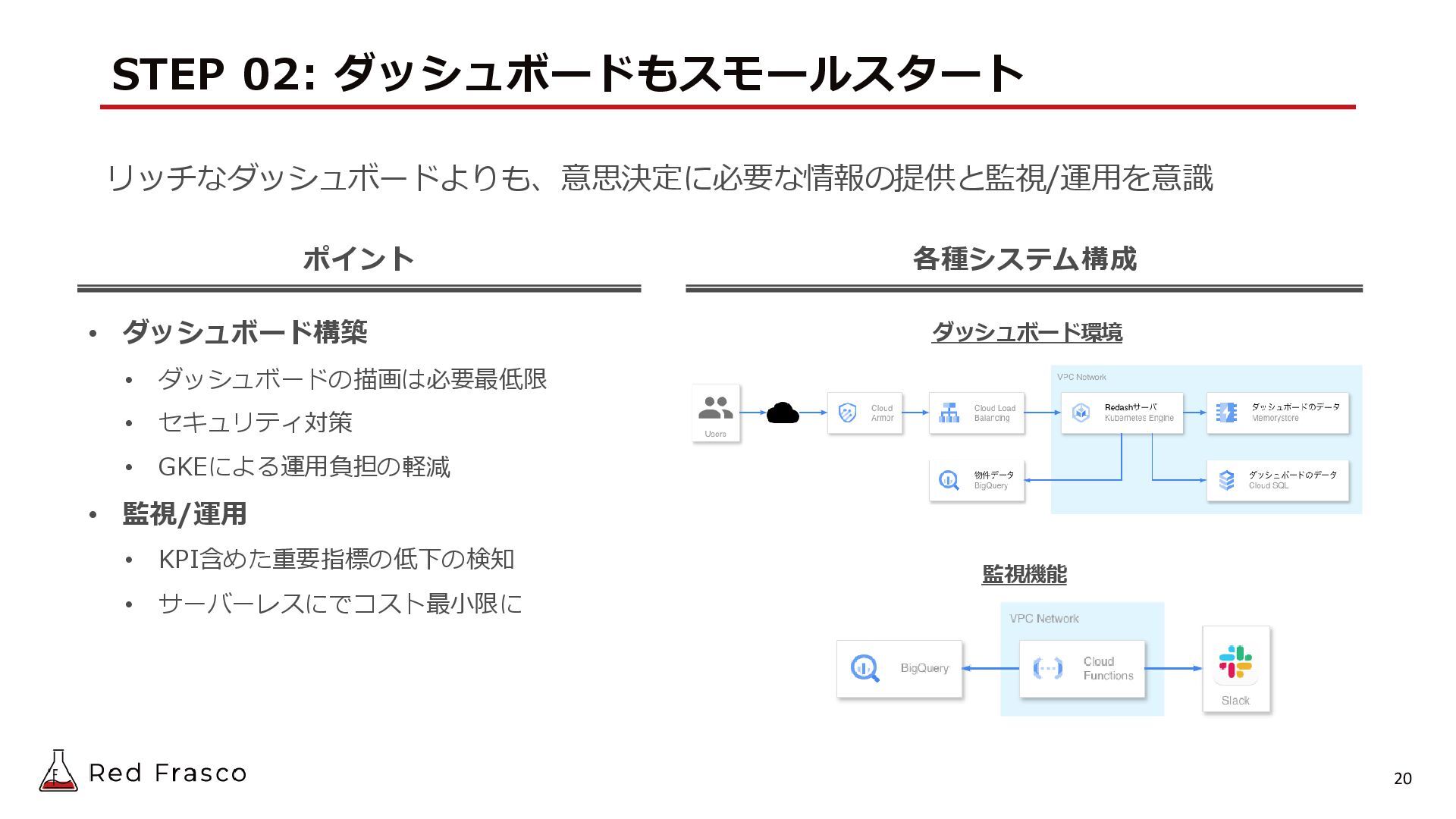{kind=link}
{kind=link}
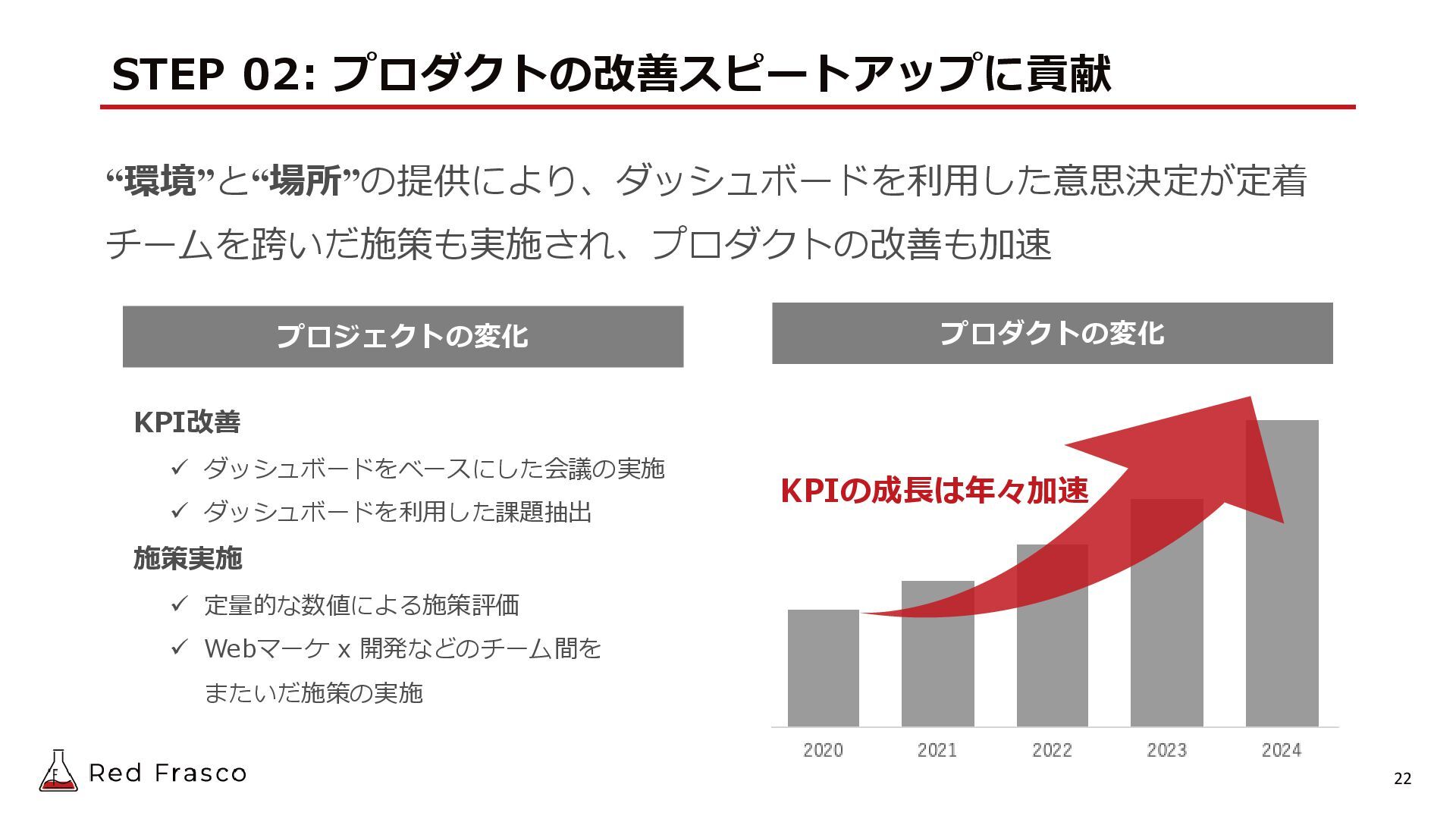{kind=link}
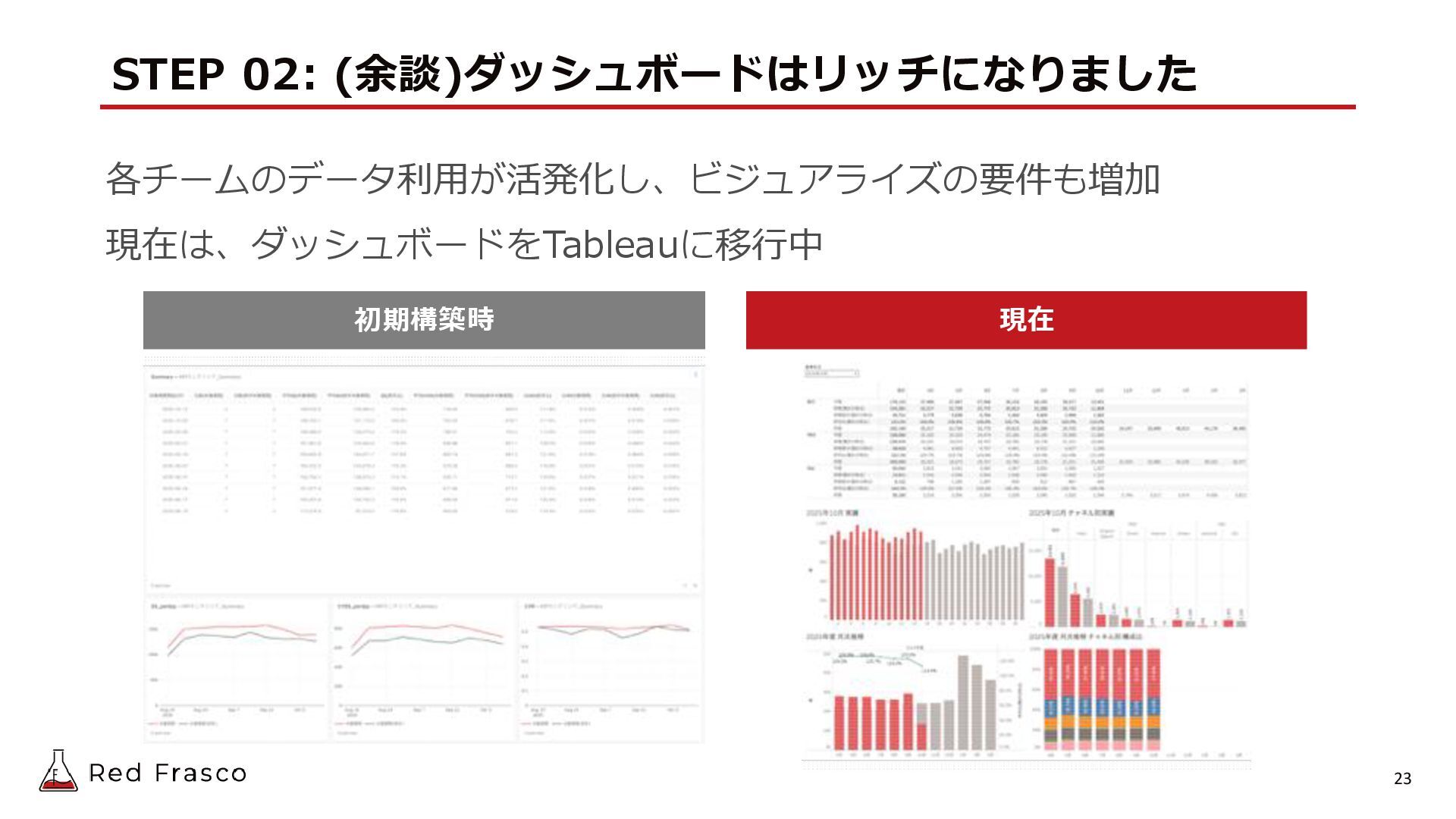{kind=link}
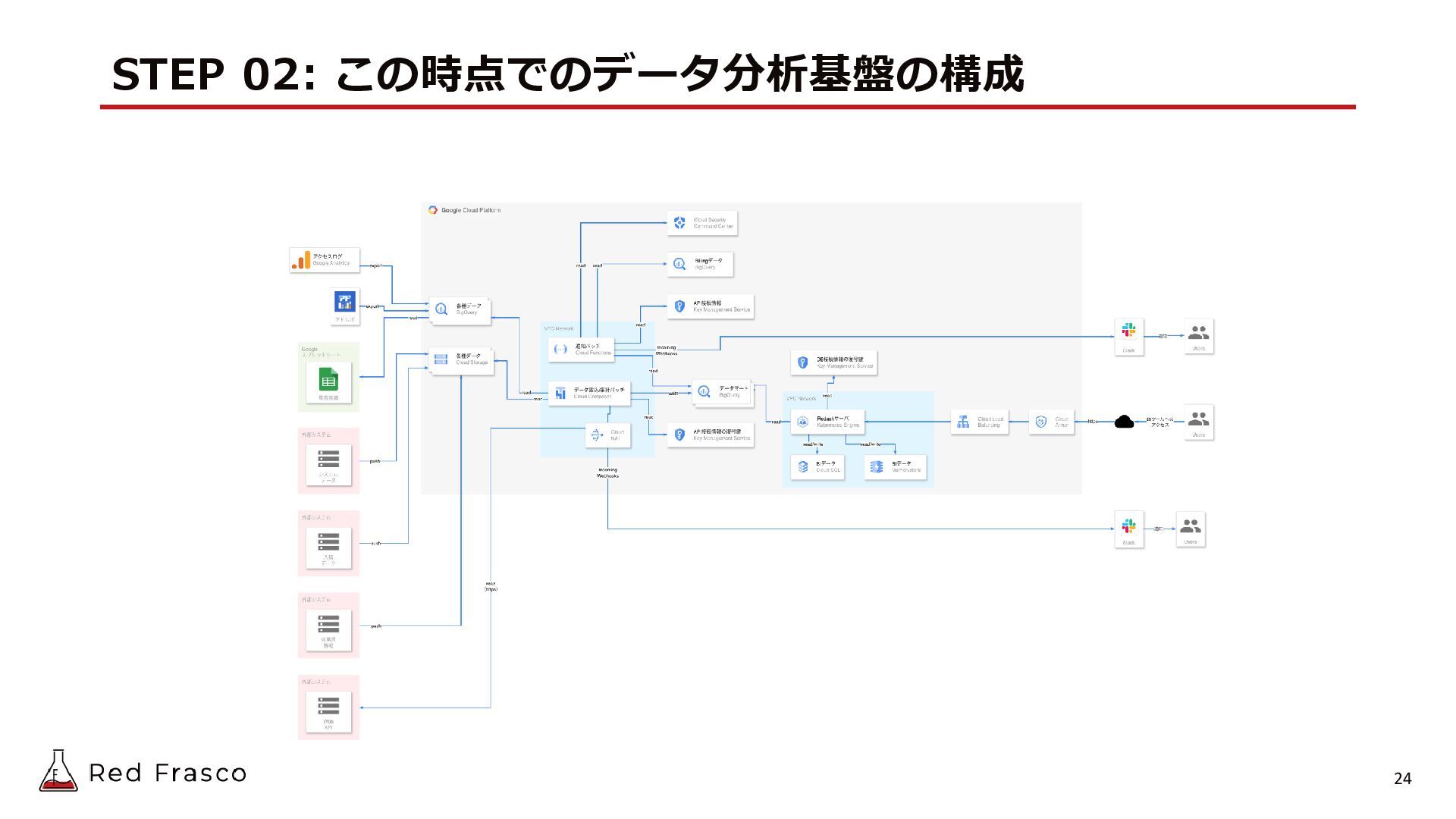{kind=link}
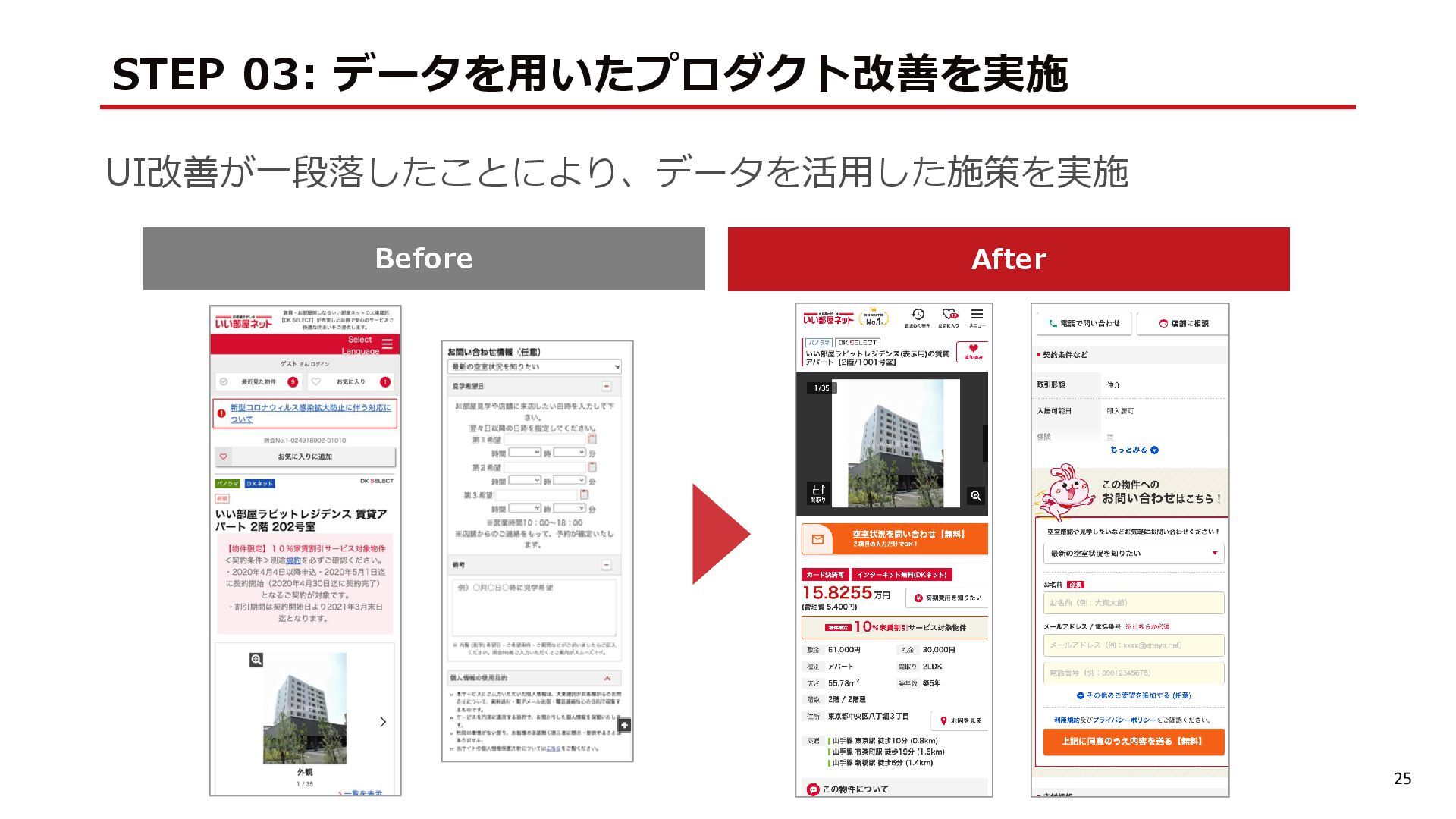{kind=link}
{kind=link}
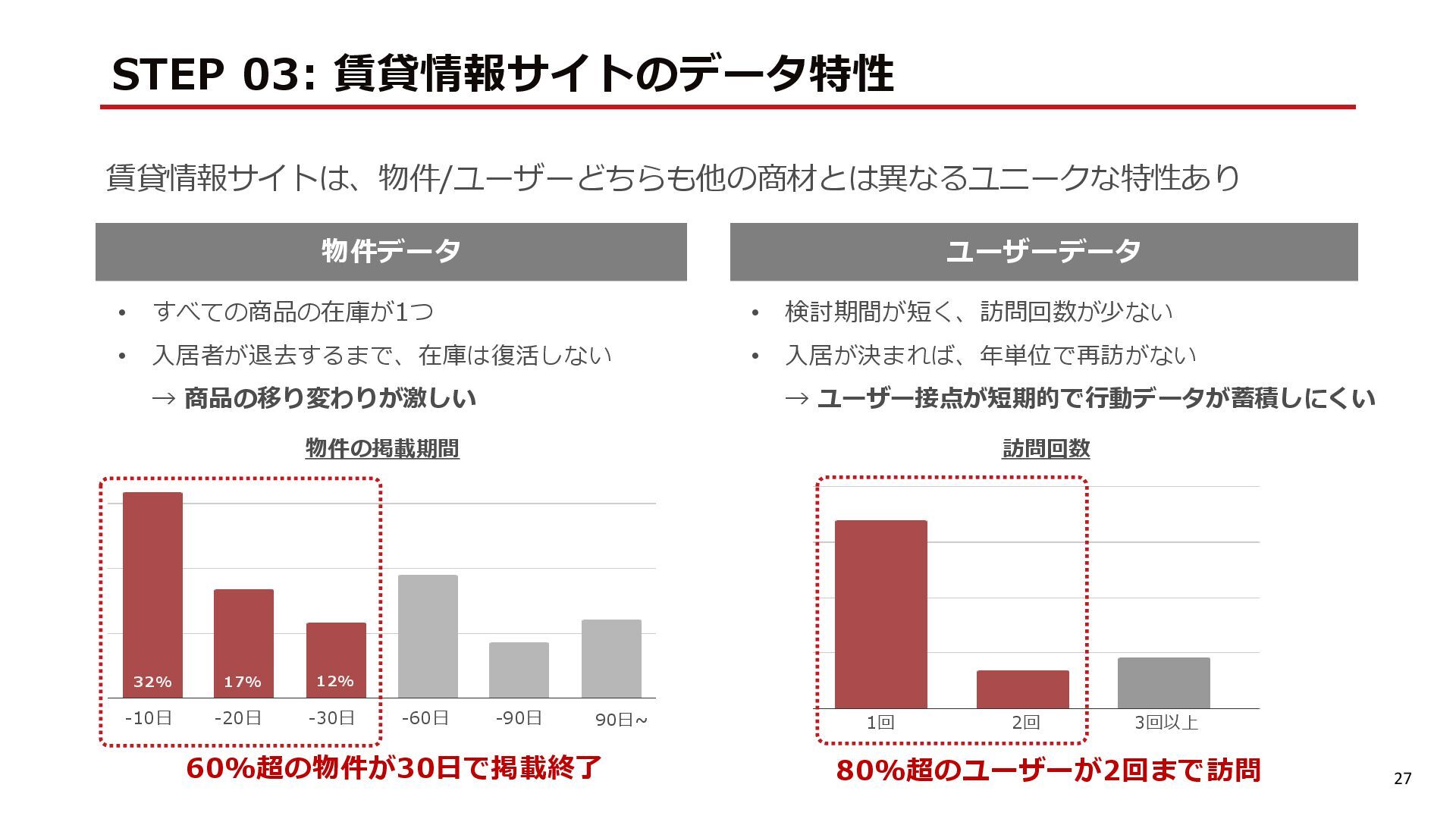{kind=link}
{kind=link}
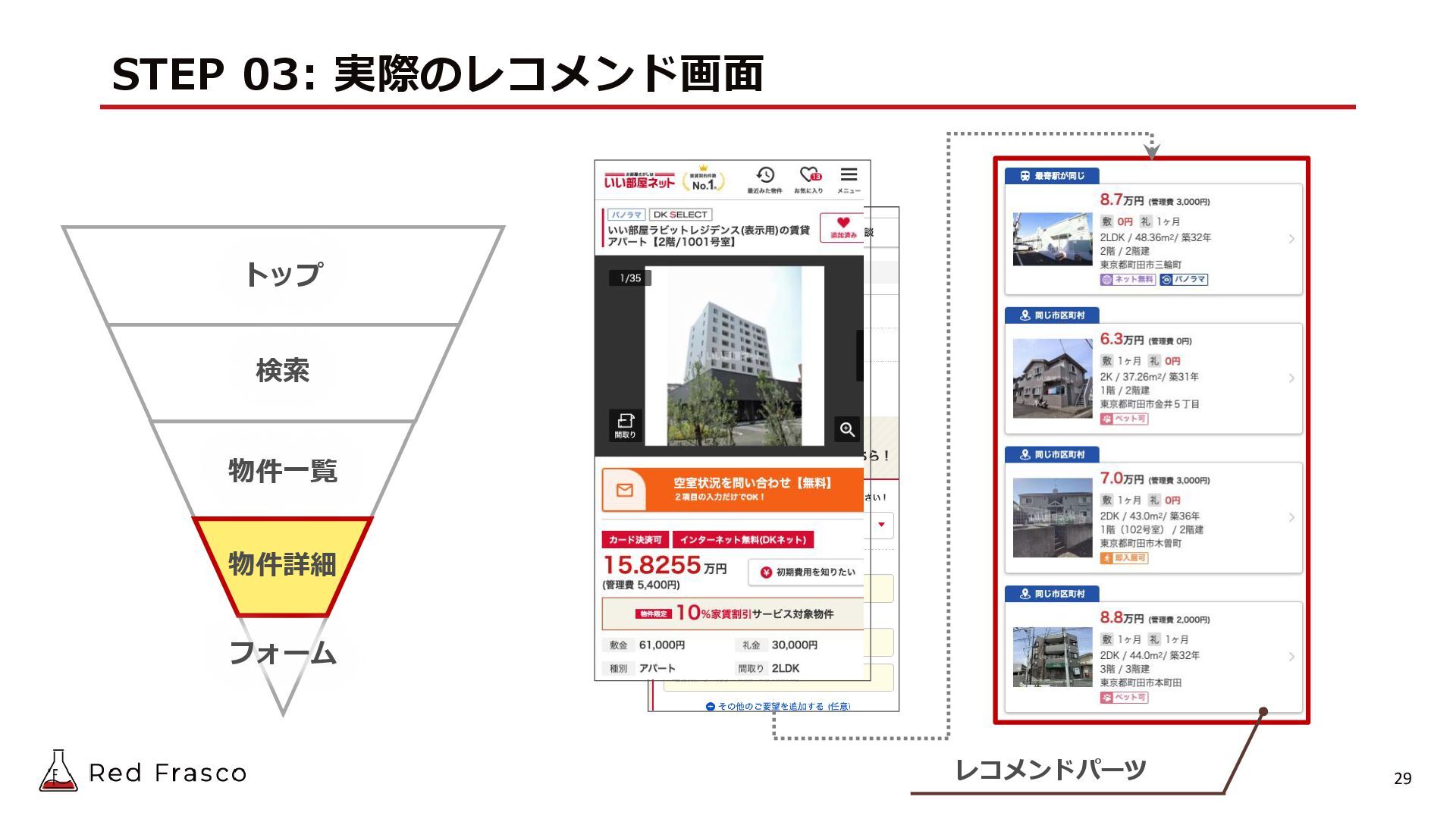{kind=link}
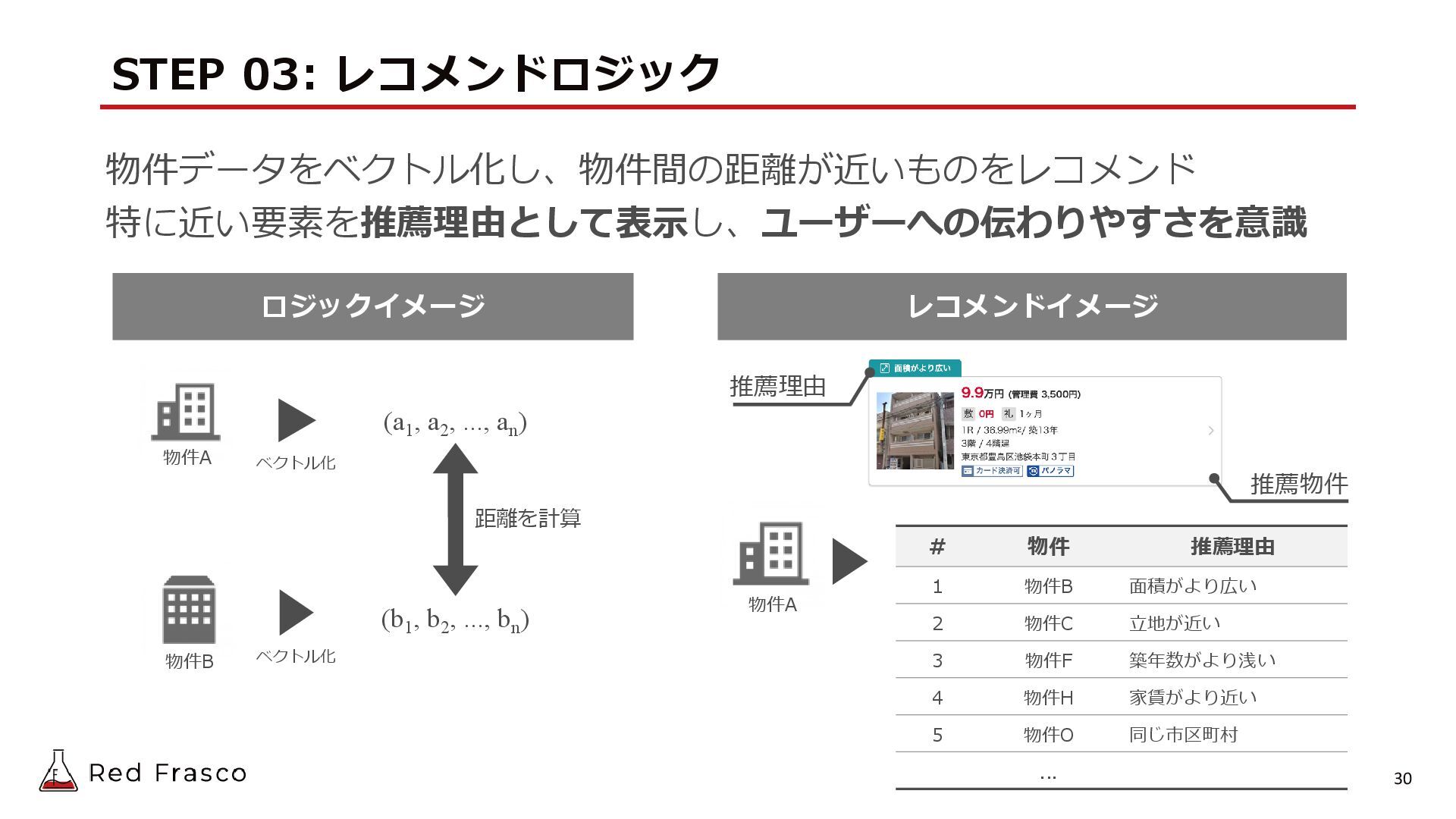{kind=link}
{kind=link}
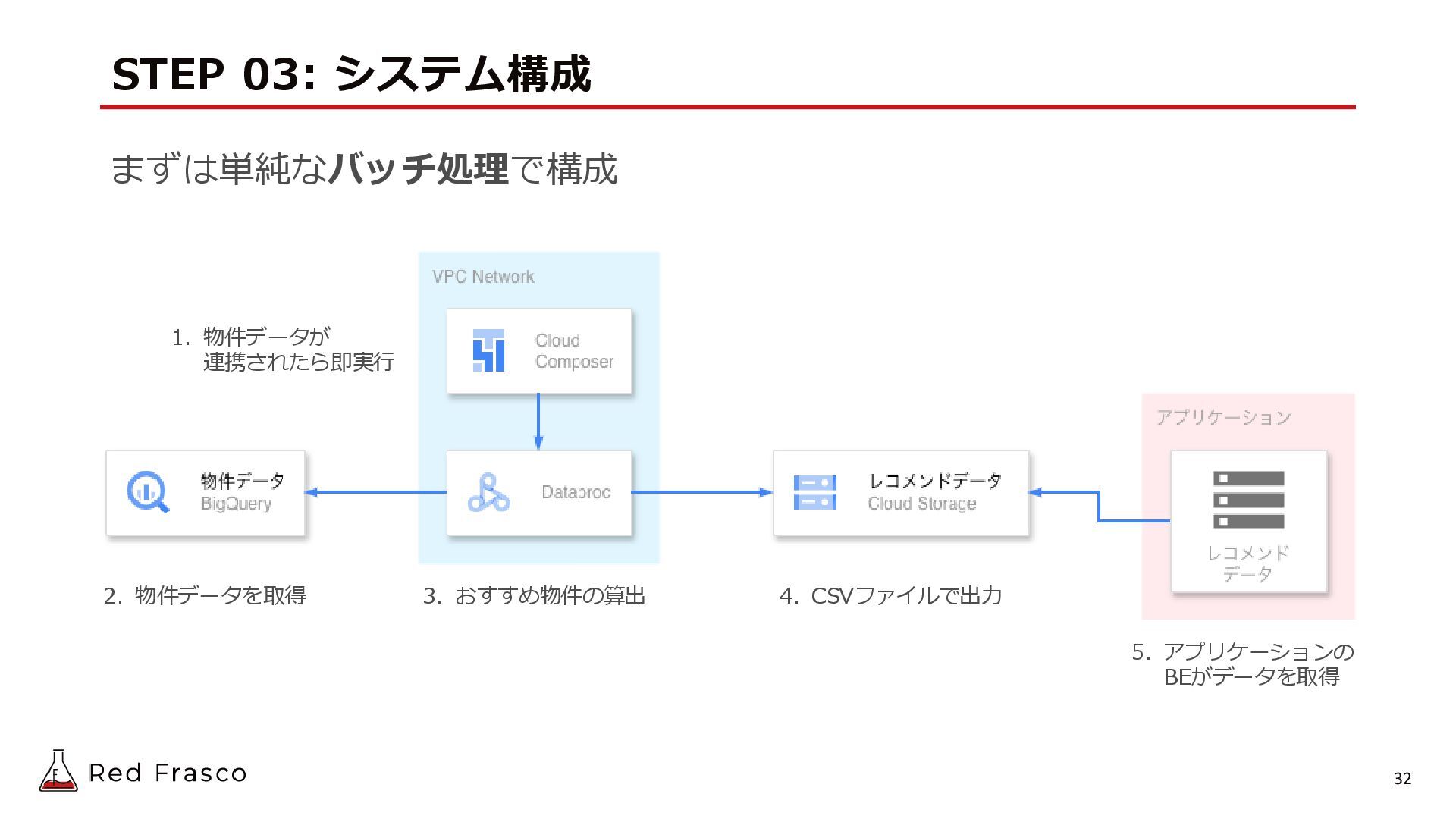{kind=link}
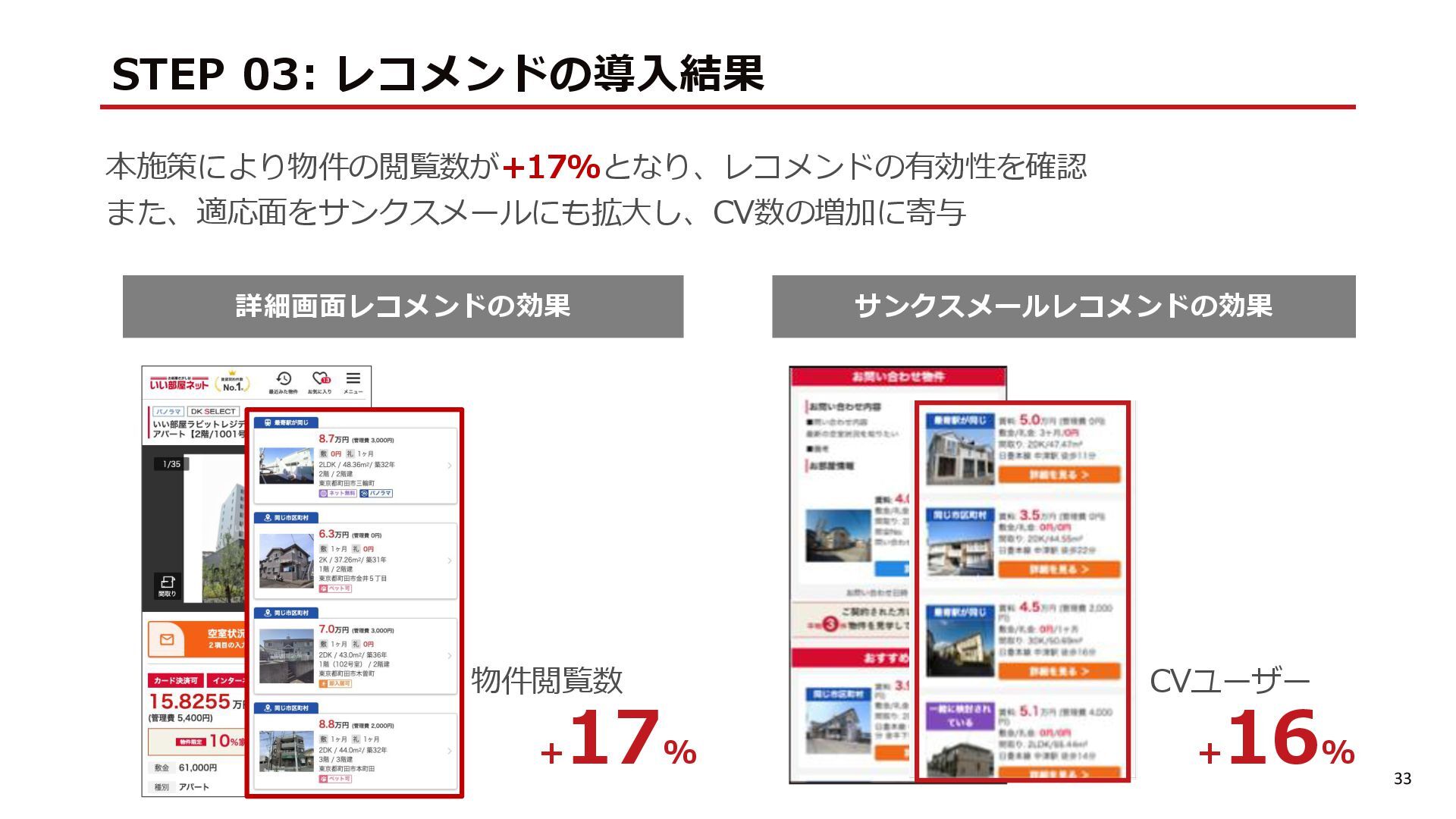{kind=link}
{kind=link}
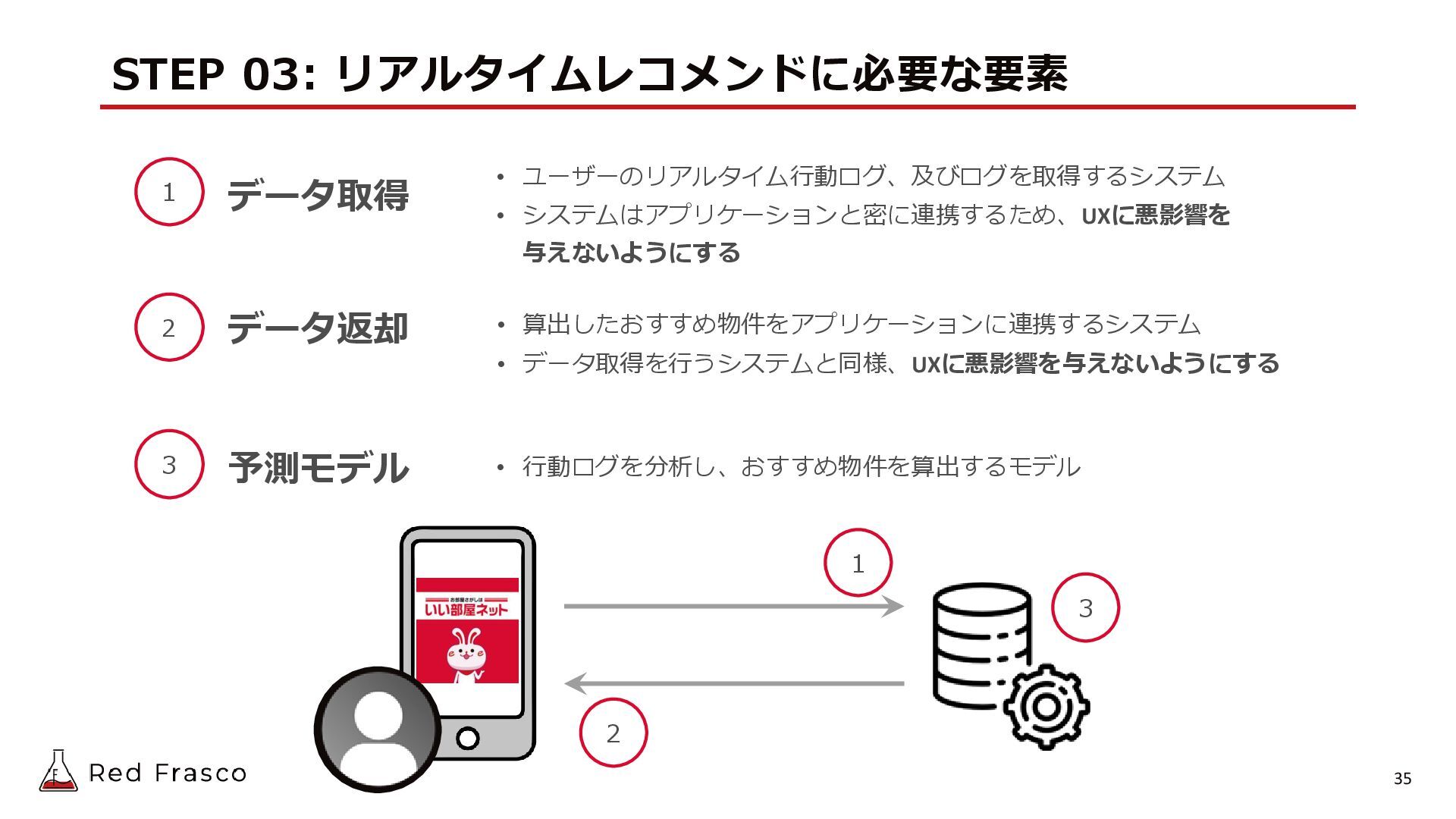{kind=link}
{kind=link}
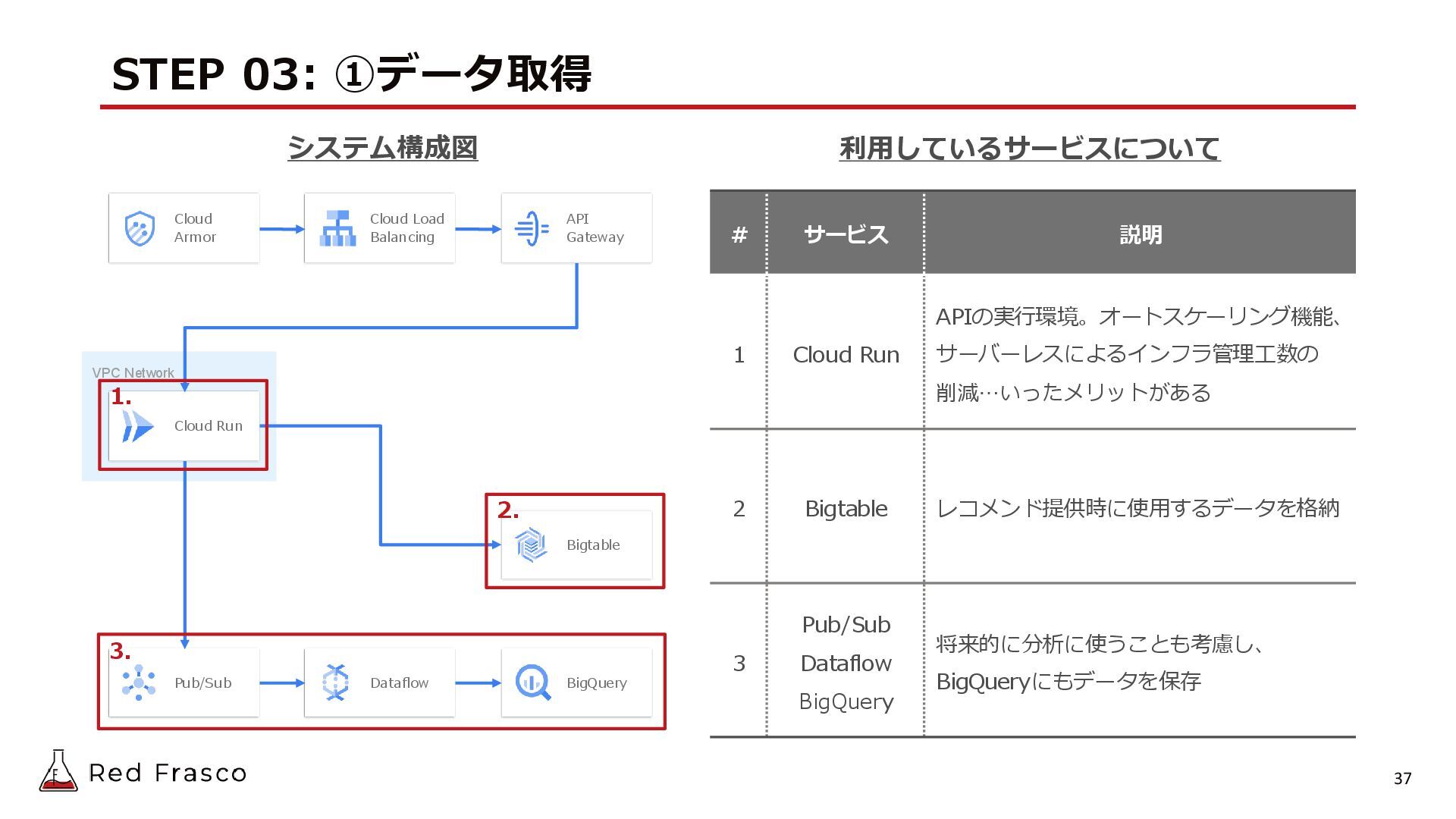{kind=link}
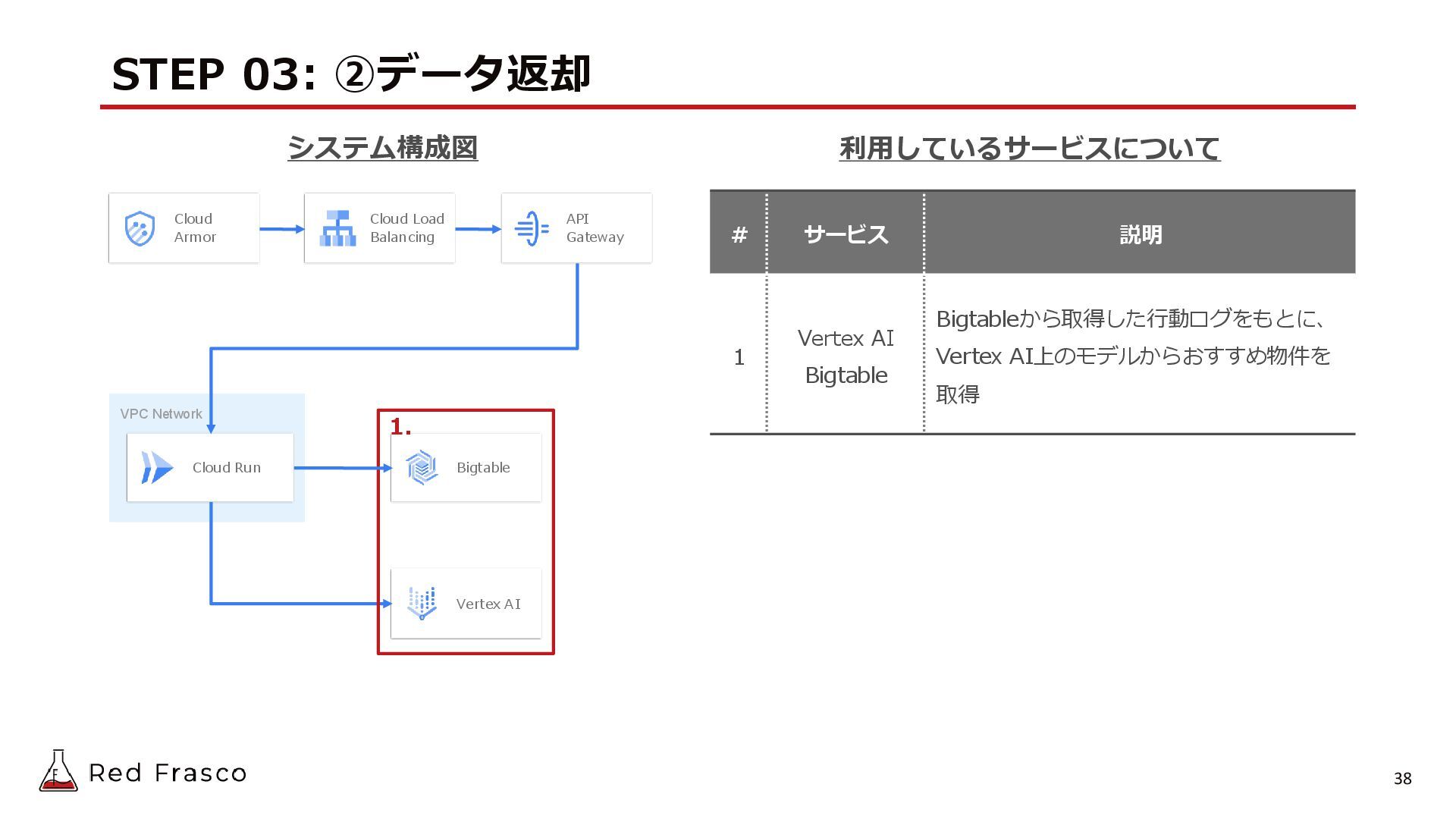{kind=link}
{kind=link}
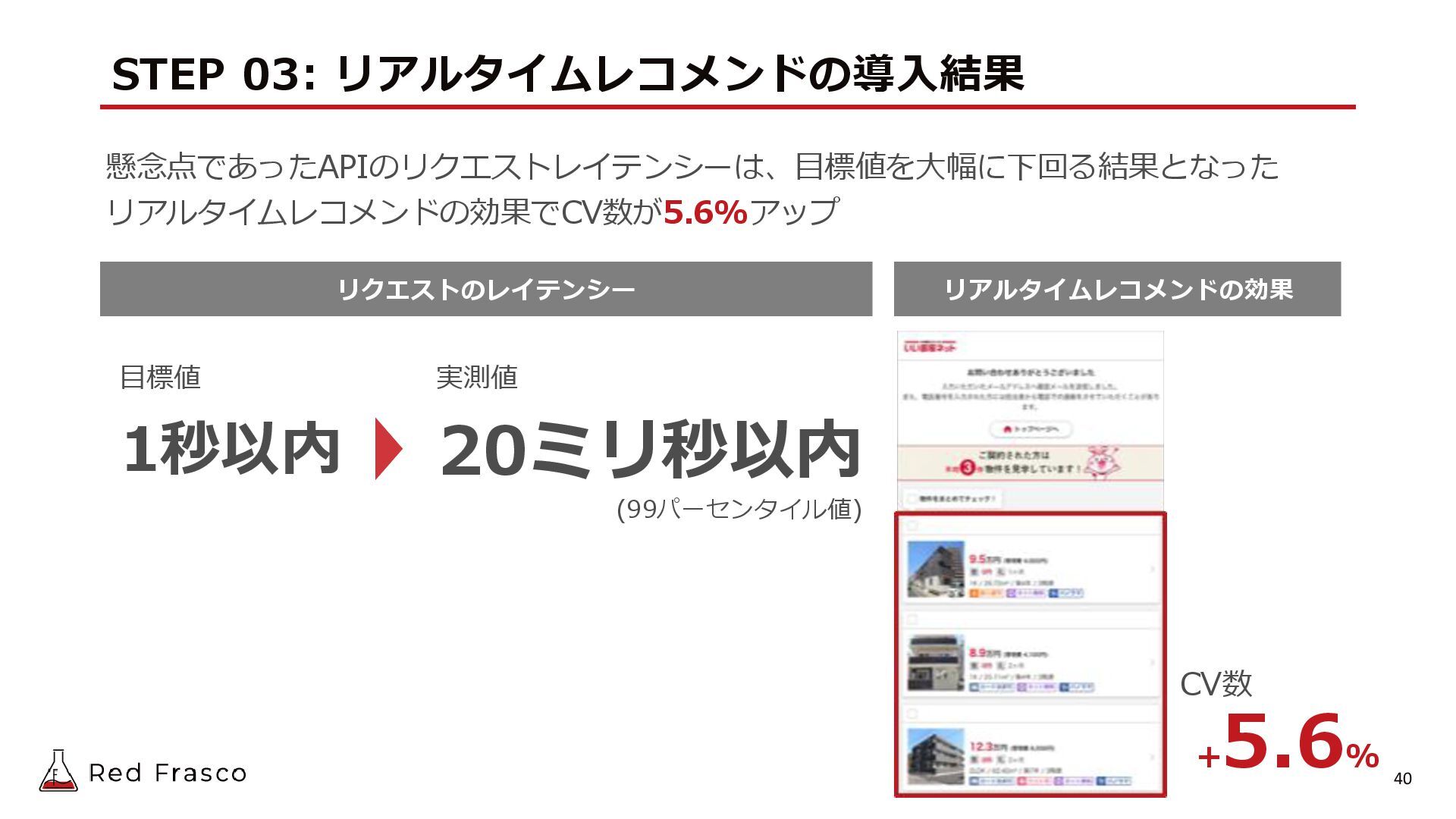{kind=link}
{kind=link}
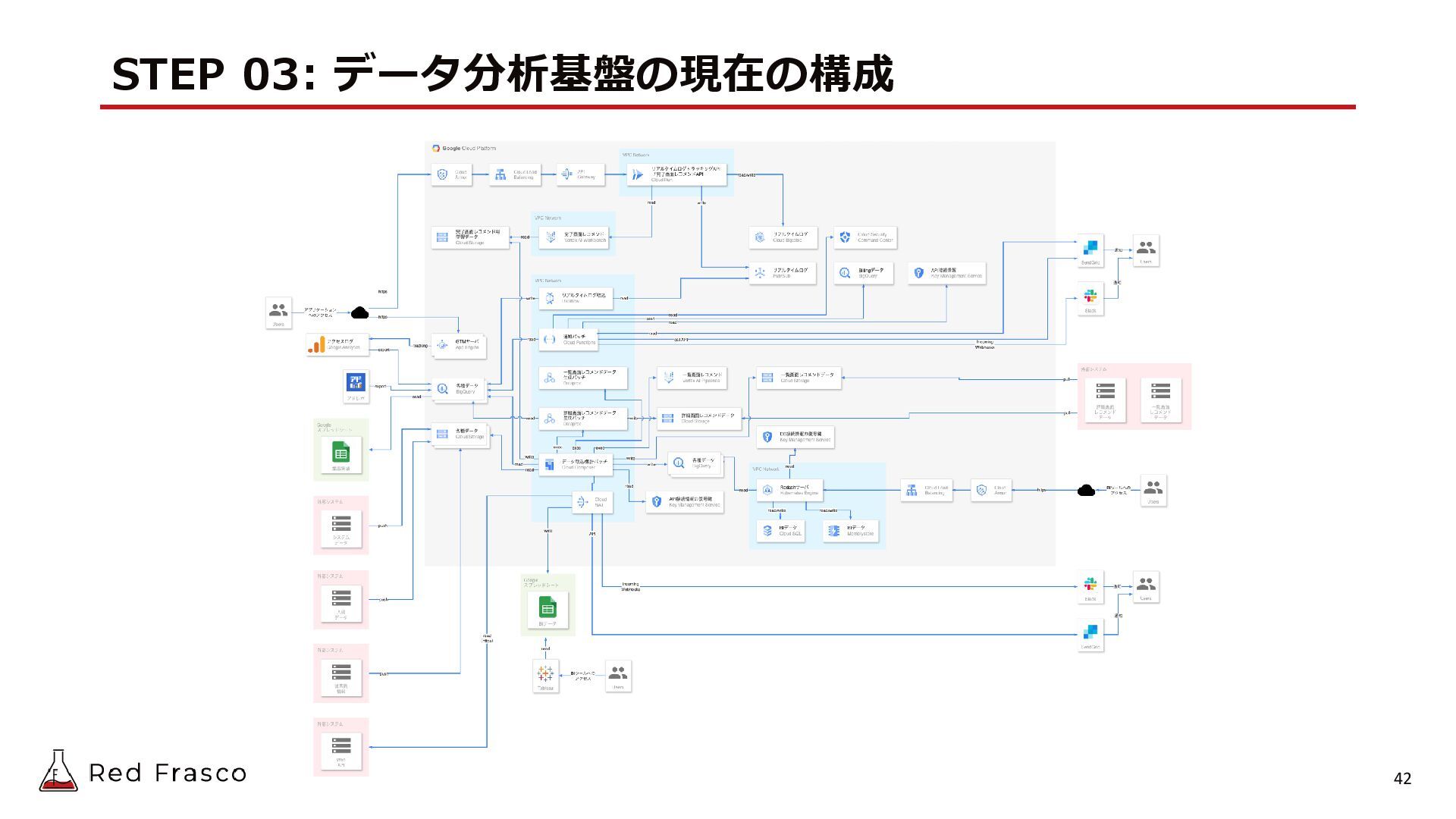{kind=link}
{kind=link}
{kind=link}
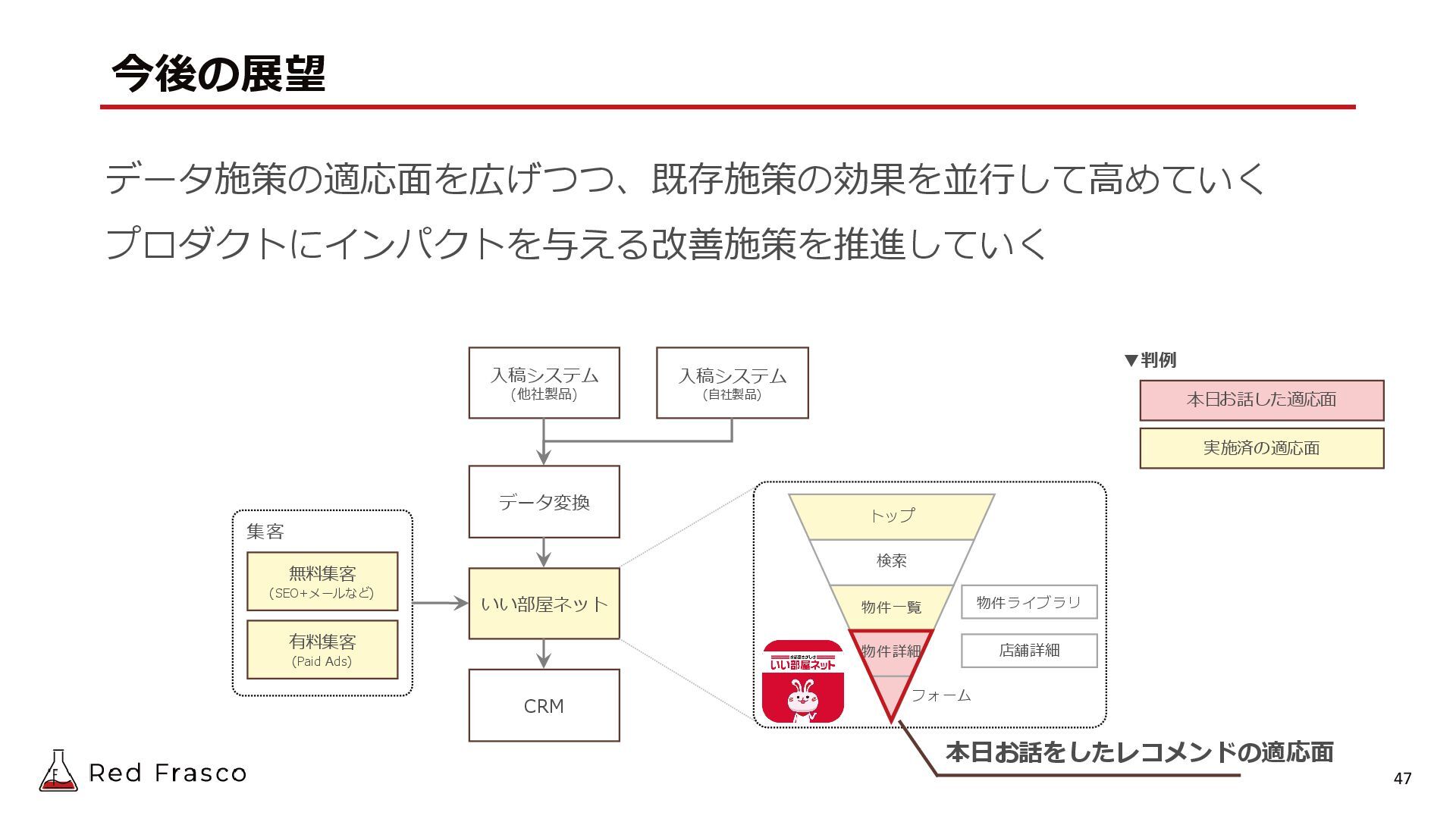
{kind=link}
{kind=link}
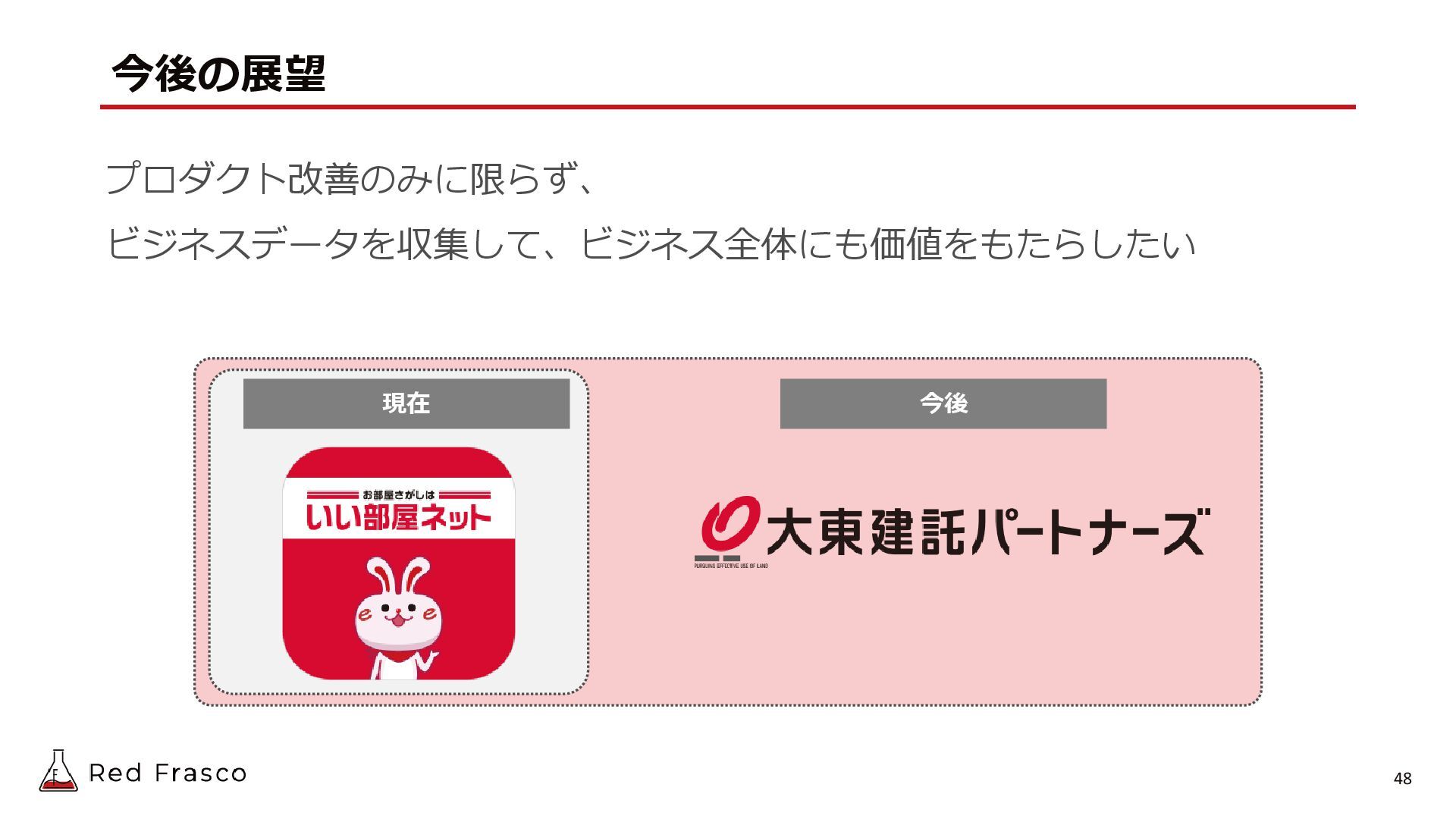
{kind=link}
{kind=link}
{kind=link}
{kind=link}