Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第九章-サポートベクターマシン【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Search
Ringa_hyj
July 22, 2020
Technology
0
170
第九章-サポートベクターマシン【数学嫌いと学ぶデータサイエンス・統計的学習入門】
第九章【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Ringa_hyj
July 22, 2020
Tweet
Share
More Decks by Ringa_hyj
See All by Ringa_hyj
Catching up with the tidymodels.[Japan.R 2021 LT]
ringa_hyj
3
800
多次元尺度法MDS
ringa_hyj
0
250
因子分析(仮)
ringa_hyj
0
120
階層、非階層クラスタリング
ringa_hyj
0
89
tidymodels紹介「モデリング過程料理で表現できる説」
ringa_hyj
0
400
深層学習をつかった画像スタイル変換の話と今までの歴史
ringa_hyj
0
370
正準相関分析(仮)
ringa_hyj
0
100
対応分析
ringa_hyj
0
120
2020-11-15-第1回-統計学勉強会
ringa_hyj
0
700
Other Decks in Technology
See All in Technology
組織に自動テストを書く文化を根付かせる戦略(2024冬版) / Building Automated Test Culture 2024 Winter Edition
twada
PRO
13
3.7k
多領域インシデントマネジメントへの挑戦:ハードウェアとソフトウェアの融合が生む課題/Challenge to multidisciplinary incident management: Issues created by the fusion of hardware and software
bitkey
PRO
2
100
ブラックフライデーで購入したPixel9で、Gemini Nanoを動かしてみた
marchin1989
1
530
Google Cloud で始める Cloud Run 〜AWSとの比較と実例デモで解説〜
risatube
PRO
0
100
OpenAIの蒸留機能(Model Distillation)を使用して運用中のLLMのコストを削減する取り組み
pharma_x_tech
4
560
継続的にアウトカムを生み出し ビジネスにつなげる、 戦略と運営に対するタイミーのQUEST(探求)
zigorou
0
540
【re:Invent 2024 アプデ】 Prompt Routing の紹介
champ
0
140
生成AIをより賢く エンジニアのための RAG入門 - Oracle AI Jam Session #20
kutsushitaneko
4
220
KubeCon NA 2024 Recap / Running WebAssembly (Wasm) Workloads Side-by-Side with Container Workloads
z63d
1
250
権威ドキュメントで振り返る2024 #年忘れセキュリティ2024
hirotomotaguchi
2
740
Microsoft Azure全冠になってみた ~アレを使い倒した者が試験を制す!?~/Obtained all Microsoft Azure certifications Those who use "that" to the full will win the exam! ?
yuj1osm
2
110
20241214_WACATE2024冬_テスト設計技法をチョット俯瞰してみよう
kzsuzuki
3
450
Featured
See All Featured
Making the Leap to Tech Lead
cromwellryan
133
9k
[RailsConf 2023] Rails as a piece of cake
palkan
53
5k
StorybookのUI Testing Handbookを読んだ
zakiyama
27
5.3k
Agile that works and the tools we love
rasmusluckow
328
21k
Faster Mobile Websites
deanohume
305
30k
Rebuilding a faster, lazier Slack
samanthasiow
79
8.7k
Build The Right Thing And Hit Your Dates
maggiecrowley
33
2.4k
Being A Developer After 40
akosma
87
590k
Product Roadmaps are Hard
iamctodd
PRO
49
11k
Become a Pro
speakerdeck
PRO
26
5k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
33
1.9k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
247
1.3M
Transcript
日本一の数学嫌いと学ぶ データサイエンス ~入門~ @Ringa_hyj
@Ringa_hyj 日本一の数学嫌いと学ぶ データサイエンス ~第九章:サポートベクターマシン~
対象視聴者: 数式や記号を見ただけで 教科書を閉じたくなるレベル , , C , ,
サポートベクターマシン ・マージン最大化分類器 ・サポートベクター分類器 ・サポートベクターマシン ・ロジスティック回帰との関係
マージン最大化分類器
・サポートベクターマシン概要 1990年代から登場したSVMの手法 まず、完全に線形分離可能な場合としての マージン最大化分類木 完全分離でなくとも許す サポートベクター分類木 さらに非線形に拡張したサポートベクターマシン の順で説明する 一般的にはどれもまとめてサポートベクターマシン SVM
と呼ばれる
・マージン最大化分類器 マージン最大化分類器 線形分離が複数次元である場合、分離は線でなく面であり、3次元以上は超平面と呼ばれる p次元で、超平面は p-1次元の平坦なアフィン部分空間(原点を通らない部分空間)である p次元の分離線は β0 + β1X1 +
β2X2 ・・・ βpXp = 0 であり、この直線に対して、Xを当てはめたとき、0以上か0以下かで分類する β0 + β1X1 + β2X2 ・・・ βpXp > 0 ※yi = 1 β0 + β1X1 + β2X2 ・・・ βpXp < 0 ※yi = -1 つまり yi(β0 + β1X1 + β2X2 ・・・ βpXp) >0 という式で表現できる
・マージン最大化分類器 完全分離可能な2クラスの場合、それぞれを-1,1に対応させる -1,1に出力できるような関数をを用いて回帰していくことで分離できる ただし、完全分離可能な場合、分離線は複数引くことができてしまう。
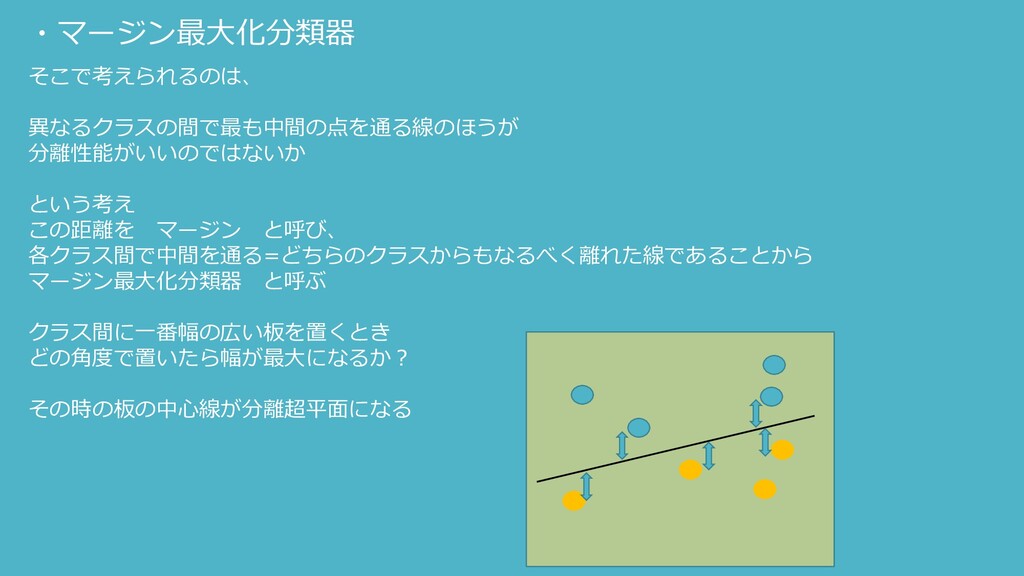
・マージン最大化分類器 そこで考えられるのは、 異なるクラスの間で最も中間の点を通る線のほうが 分離性能がいいのではないか という考え この距離を マージン と呼び、 各クラス間で中間を通る=どちらのクラスからもなるべく離れた線であることから マージン最大化分類器
と呼ぶ クラス間に一番幅の広い板を置くとき どの角度で置いたら幅が最大になるか? その時の板の中心線が分離超平面になる
・マージン最大化分類器 次元数pが大きいと過学習しやすい マージン最大化を考える時に、クラス間で近い点を採用して考える。 板にいくつかのデータ点が接することになる。 この時のデータ点を板を支える「サポート」ことから「サポートベクトル」と呼ぶ 完全分離可能なマージン最大化分類器の場合、 サポートベクトルの位置が変われば分類面も変わるが、 サポートベクトル以外の点は計算に関与しないので関わらない。
・マージン最大化分類器 p変数 n観測値 のデータ行列がある クラスラベルは1,-1 マージン最大化分類器の定式化は max ⅈⅈ ⅇ 0
~ =1 2 = 1 0 + 1 1 + ⋯ + ≥ ただし 係数に制約があり Mは「0を超える正の値」であれば分離平面を作ることができる。 ただし、M=0ということは、分離平面上にデータ点が乗ってしまうことであり 汎化性の面からこれは避けたいという話をした そこで点と線の距離がMだけは離れるように、Mを最大化していく。 制約付き最大化で解けば良い
サポートベクター分類器
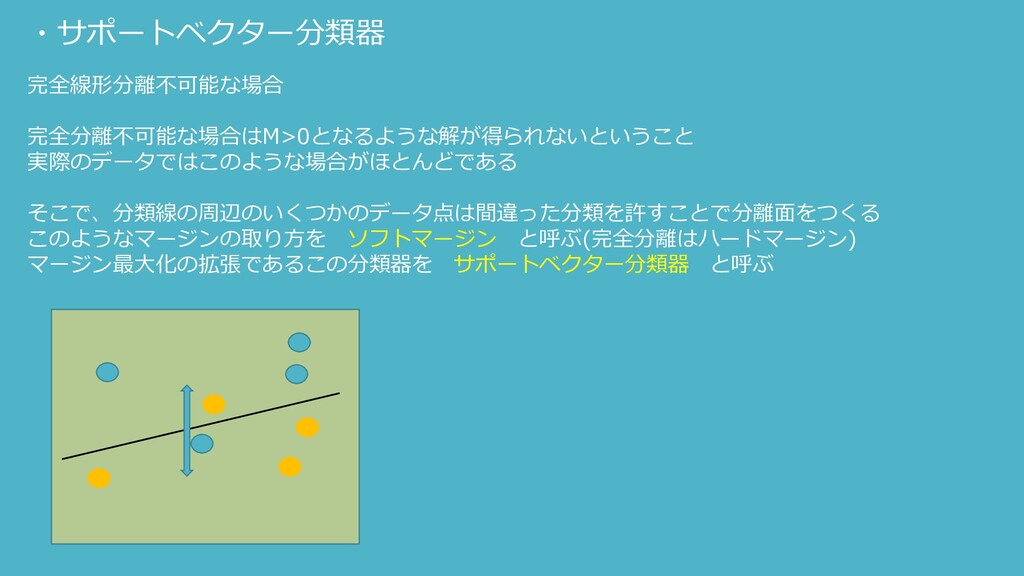
・サポートベクター分類器 完全線形分離不可能な場合 完全分離不可能な場合はM>0となるような解が得られないということ 実際のデータではこのような場合がほとんどである そこで、分類線の周辺のいくつかのデータ点は間違った分類を許すことで分離面をつくる このようなマージンの取り方を ソフトマージン と呼ぶ(完全分離はハードマージン) マージン最大化の拡張であるこの分類器を サポートベクター分類器
と呼ぶ
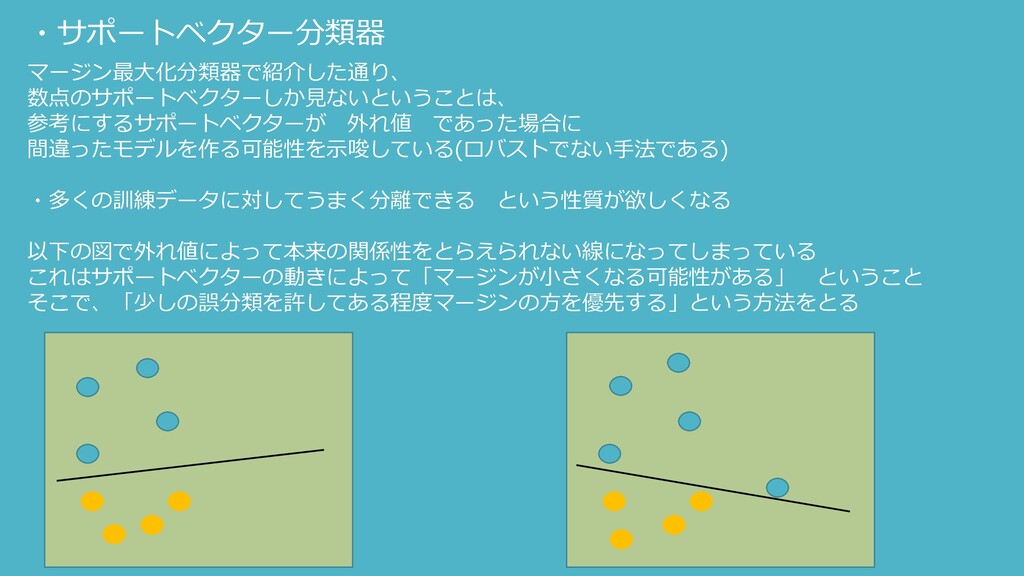
・サポートベクター分類器 マージン最大化分類器で紹介した通り、 数点のサポートベクターしか見ないということは、 参考にするサポートベクターが 外れ値 であった場合に 間違ったモデルを作る可能性を示唆している(ロバストでない手法である) ・多くの訓練データに対してうまく分離できる という性質が欲しくなる 以下の図で外れ値によって本来の関係性をとらえられない線になってしまっている
これはサポートベクターの動きによって「マージンが小さくなる可能性がある」 ということ そこで、「少しの誤分類を許してある程度マージンの方を優先する」という方法をとる
・サポートベクター分類器 Cはチューニングパラメタ εはスラックス変数 εi=0のとき正しいクラスに分離できている。 εi>0のときマージン内の?誤った側である ※i番目観測地はマージンに違反する という εi>1のとき分離平面の誤った側になる max ⅈⅈ
ⅇ 0 ~ ε 1 ~ε ただし 係数に制約があり =1 2 = 1 0 + 1 1 + ⋯ + ≥ (1 − ε ) ε i ≥0 =1 ε 2 ≤ C
・サポートベクター分類器 Cはスラックス変数の合計値を制限している マージンと平面の誤ったサンプルをどの程度許容するかである C=0でマージン最大化分類器となる C>0ならば、超平面の向こう側に超えていい個数は最高でC個である (平面を超えるとε>1のため) Cは交差検証により決められ、Cが大きくなるとマージンも大きくなっていく この分類器はマージン上、マージンに違反するもの のみに影響して学習される 他のデータ点は学習に必要がない
Cが大きければ分類線は適当になり Cが小さければ分類線は敏感に過学習する バイアス バリアンス のトレードオフに関係するパラメタである。
サポートベクターマシン
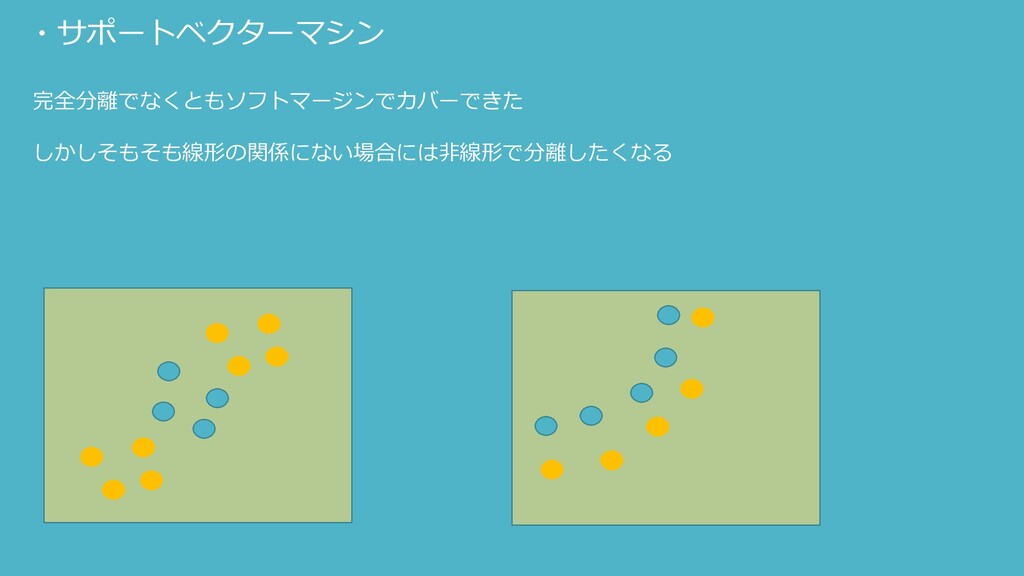
・サポートベクターマシン 完全分離でなくともソフトマージンでカバーできた しかしそもそも線形の関係にない場合には非線形で分離したくなる
・サポートベクターマシン 識別境界を次数を上げた多項式モデルにしてやることを考える 多項式モデルなのでp個の変数Xは2p個に増え、係数も2p個になる 0 + =1 1 +
=1 2 ⅈ 2 ≥ (1-εi ) max ⅈⅈ ⅇ 0 11 ~1 12 ~2 ε 1 ~ε =1 k=1 2 2 = 1 ε i ≥0 =1 ε 2 ≤ C 多項式にすることで使用できる変数が増えた(特徴量空間を広げた) 扱うパラメタも増え、計算量も増える
・サポートベクターマシン 2つのr次元ベクトルa,bの内積 <a,b> = Σ i=1~r a i b i
線形のサポートベクター分類器を内積を使って表現すると , ’ = =1 ’ = 0 + =1 , αはn個のパラメタである。 サポートベクター以外では0が入り、サポートベクターの時のみ0以上となる そのため、本来n個すべてに対して計算する必要はなく、 サポートベクターのデータ集合 S の時のみに計算すればいいので 以下のようにも表示する = 0 + ∊ ,
このKによる変換関数を「カーネル関数」と呼ぶ。 カーネルに相当する変換は内積に限らない 内積は類似度を表していると考えられる 以下の場合カーネル関数はd次多項式カーネルと呼ばれる このような非線形カーネルを使った分類局面をつくる場合を サポートベクターマシン と呼ぶ。d=1の時、サポートベクター分類器に等価 ・サポートベクターマシン 内積をKという関数で一般化して表すと =
, ’ = =1 ’ K(X i , X i’ ) = (1 + =1 ’ ) d K(X i , X i’ ) = 0 + ∊ K(, )
・サポートベクターマシン 他にもいろいろとカーネルの候補は存在するが、有名なカーネルとして 「動径基底関数(RBF)カーネル」が存在する K(X i , X i’ ) =
ⅇxp − =1 − ′ 2 γは正の定数 2次の多項式カーネルでは、単純な二次曲線がマージンとなり分離するが RBFカーネルでは特定のクラスを円形に囲うことができる。
・サポートベクターマシン 変数(特徴量)を増やしてサポートベクターマシンにかけるのと、 カーネル関数を使ってからサポートベクターマシンにかけるの どう違うのか? もしも特徴量を増やす方法だと、保持しておくメモリも必要となる このように明示的に拡大された特徴量空間での計算はコストが大変にかかる ちなみに RBFカーネルは明示的に拡大することができず、無限次元に拡大したものを表現している
ロジスティック回帰との関係
・ロジスティック回帰との関係 サポートベクター分類器は1990年代の登場期には謎めいた理論により 旧来のロジスティック回帰や線形判別と異なるように見えた。 しかし、古典的モデルと理論的につながりがあることが分かった。 サポートベクター分類器は以下のように 損失関数L(X,Y,β) と罰則関数λP(β) によって表現ができることが分かった =1
max 0,1 − + =1 2 minimize β0~βp λが大きいときβたちは小さくなり、マージンに違反する値が多く許される これはCに相当していることがわかる 対して線形回帰で見たRidgeやLassoの場合のコスト関数は以下である , , = ා =1 − 0 − =1 2
・ロジスティック回帰との関係 罰則関数はL1,L2を使うのがRidgeやLassoであった 今一度損失関数を書きならべる =1 max 0,1 − =1
max 0,1 − β 0 + β 1 1 + ・・・ + β = 0 + ∊ K(, ) K(X i , X i’ ) = (1 + =1 ’ ) d サポートベクターマシンの損失関数(ヒンジロス関数) より書き下すと
・ロジスティック回帰との関係 ロジスティック関数は二乗による誤差の計算を行う SVMのヒンジロス関数は1以下の時には損失が0になる 0 + 1 1 + ⋯ +
≥ 1 これはマージンよりも 正しい側に分類されている 観測値は無視することに相当する? 損失関数が似ていることから SVMとロジスティックは似た結果となる クラスがうまく分かれる場合はSVM 混在した領域があるとき ロジスティックがうまく働く SVM発表の当初、C=1のように決め打ち定数でいいと考えられていたが 損失関数と罰則で表せることが分かってから、 Cがバイアス・バリアンスに関係するとわかった
・カーネル法について カーネル関数を使った特徴量の拡張はSVMだけでなく ロジスティック回帰やほかの手法にも使える しかし、歴史的背景から非線形カーネルの活用場面はSVMで主に使われる SVMは回帰にも使える 今回は説明しない
None
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}