práctica : Son registros numéricos, textuales, visuales o auditivos que capturan eventos, comportamientos o características de un sistema, proceso o población. Ejemplos: Ventas diarias, sensores de máquinas, comentarios en redes sociales, imágenes satelitales, registros médicos, etc. Tipos de datos • Estructurados: Organizados en tablas o bases de datos (ej: hojas de Excel, SQL). Caso gerencial: Reportes de ventas por región, inventarios en tiempo real. • No estructurados: Textos, imágenes, videos, audios (ej: correos, fotos de productos defectuosos). Caso gerencial: Análisis de opiniones de clientes en reseñas online. • Semi-estructurados: JSON, XML, logs (ej: datos de sensores IoT en manufactura). Rol en la ciencia de datos • Combustible para modelos: Sin datos, no hay machine learning, pronósticos ni automatización. • Fuente de verdad: Permiten validar hipótesis o intuiciones con evidencia cuantitativa. • Base para innovación: Detectar oportunidades ocultas (ej: tendencias de consumo en retail). Datos vs. Información • Los datos son crudos (ej: "100 unidades vendidas en Lima el 10/05"). • La información es el dato contextualizado (ej: "Las ventas en Lima cayeron un 20% respecto al mes anterior").
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
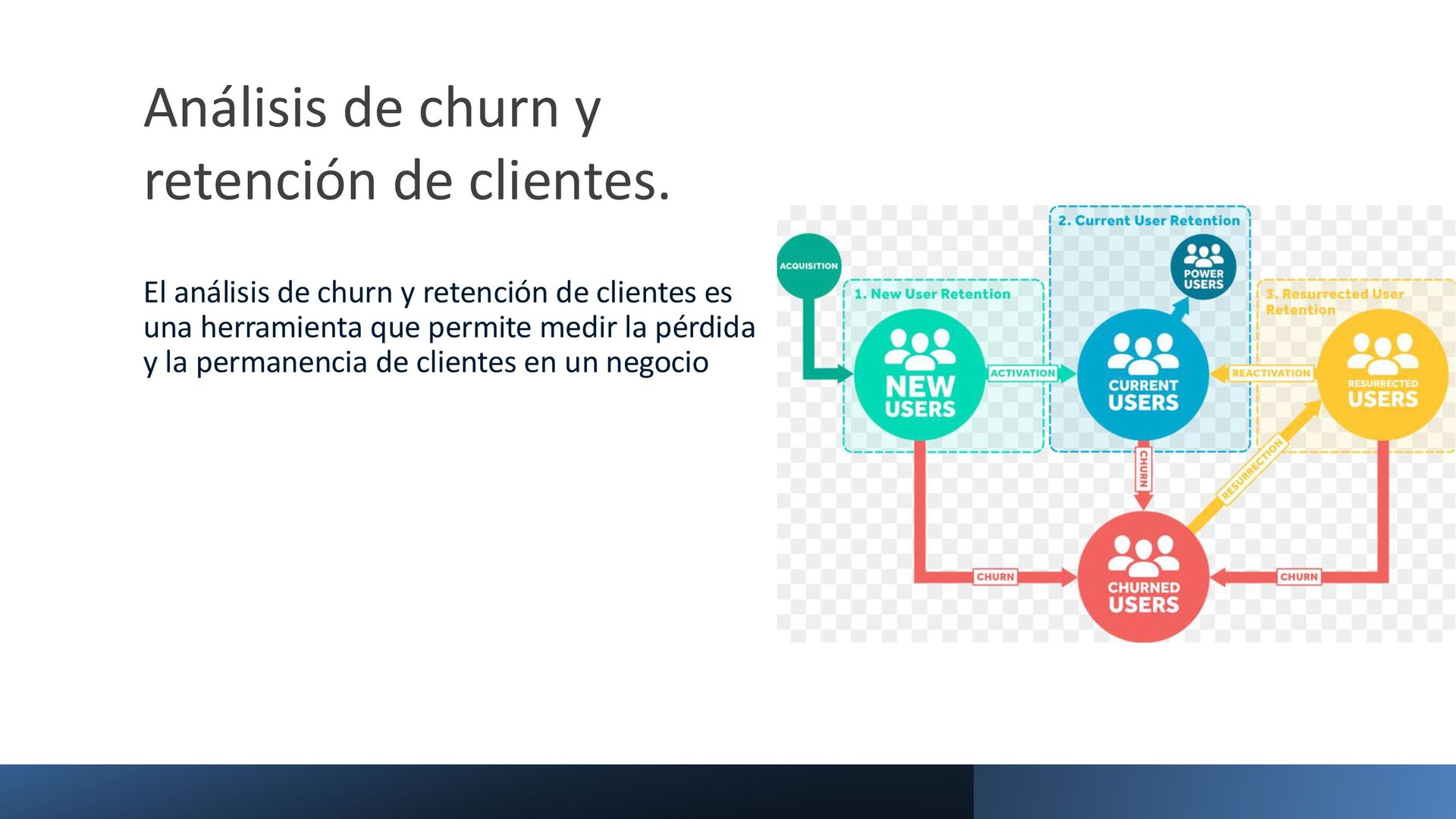{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
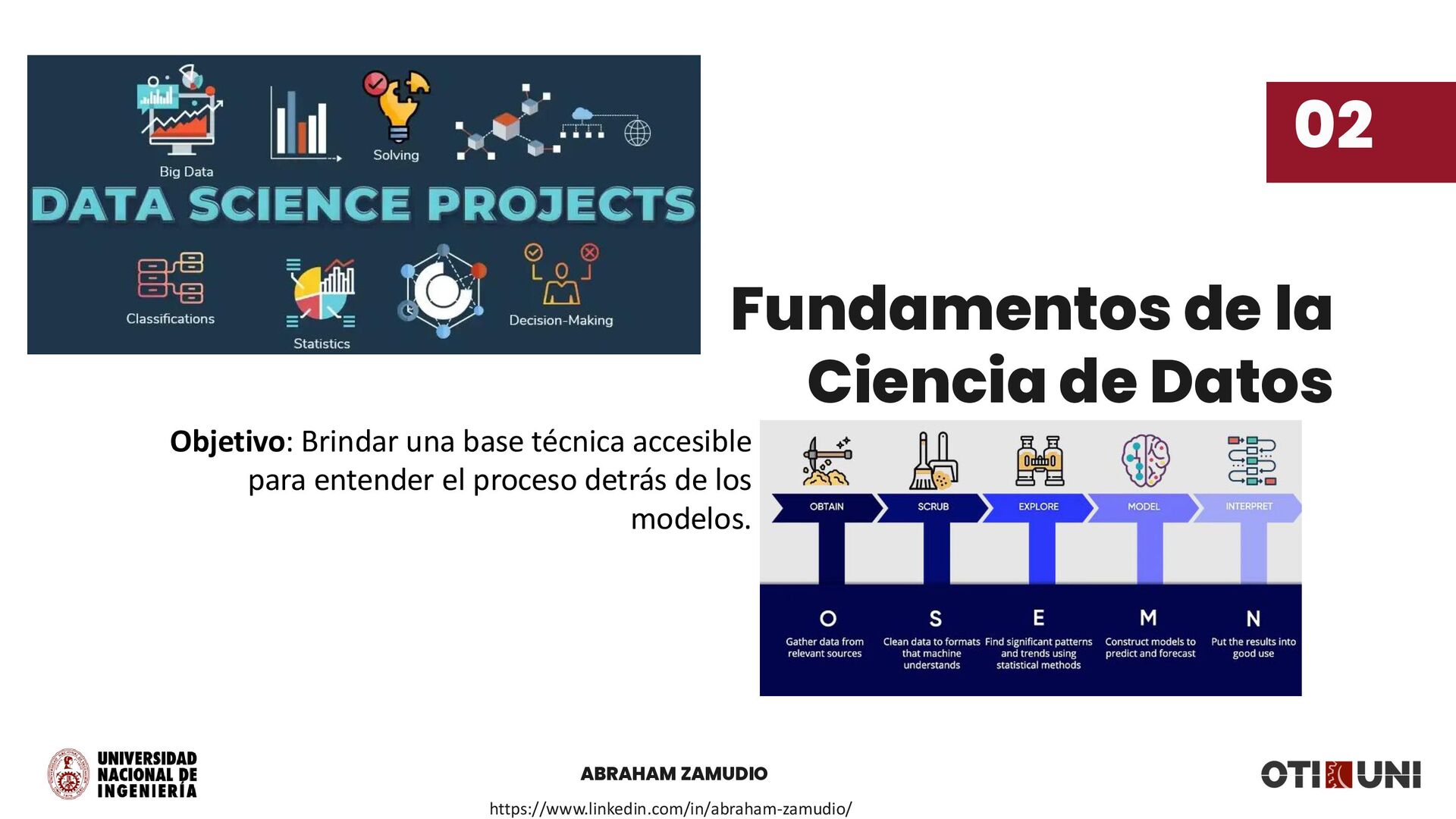{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
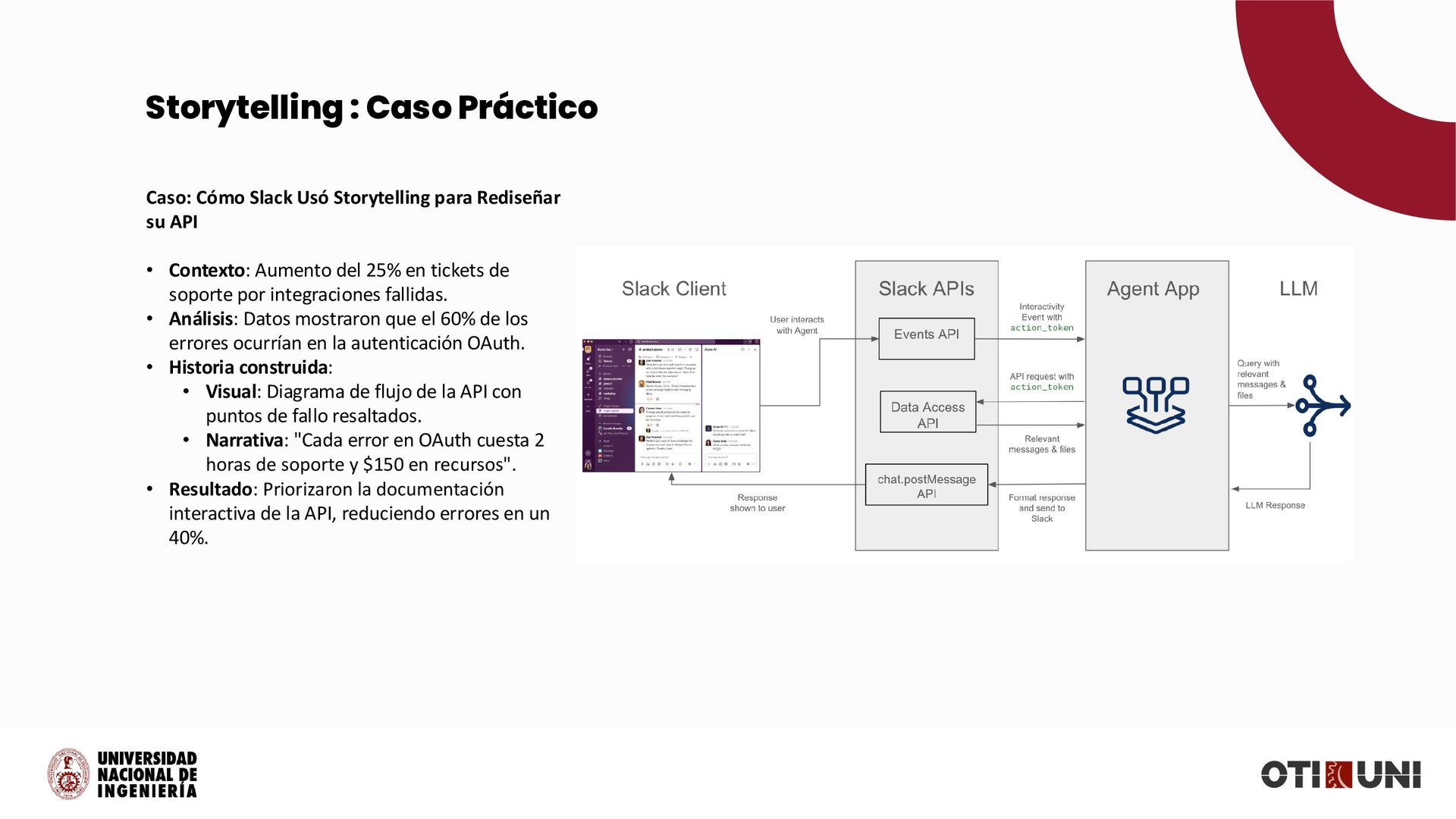{kind=link}
{kind=link}
{kind=link}