Fast Forward, pause,… Friend Request Transaction Network message Fault … User Generated (Web, Social & Mobile) ….. Internet of Things / M2M Scientific Computing
Goldberg (Crowdsourcing) Randy Katz (Systems) *Michael Franklin (Databases) Dave Patterson (Systems) Armando Fox (Systems) *Ion Stoica (Systems) *Mike Jordan (Machine Learning) Scott Shenker (Networking) Organized for Collaboration:"
+ AMP Lab + Intel Cluster" @TCGA: 5 PB = 20 cancers x 1000 genomes" • Sequencing costs (150X) Big Data David Patterson, “Computer Scientists May Have What It Takes to Help Cure Cancer,” New York Times, 12/5/2011 $0.1 $1.0 $10.0 $100.0 $1,000.0 $10,000.0 $100,000.0 2001 - 2014 $K per genome • See Dave Patterson’s Talk: Thursday 3-4, BDT205
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
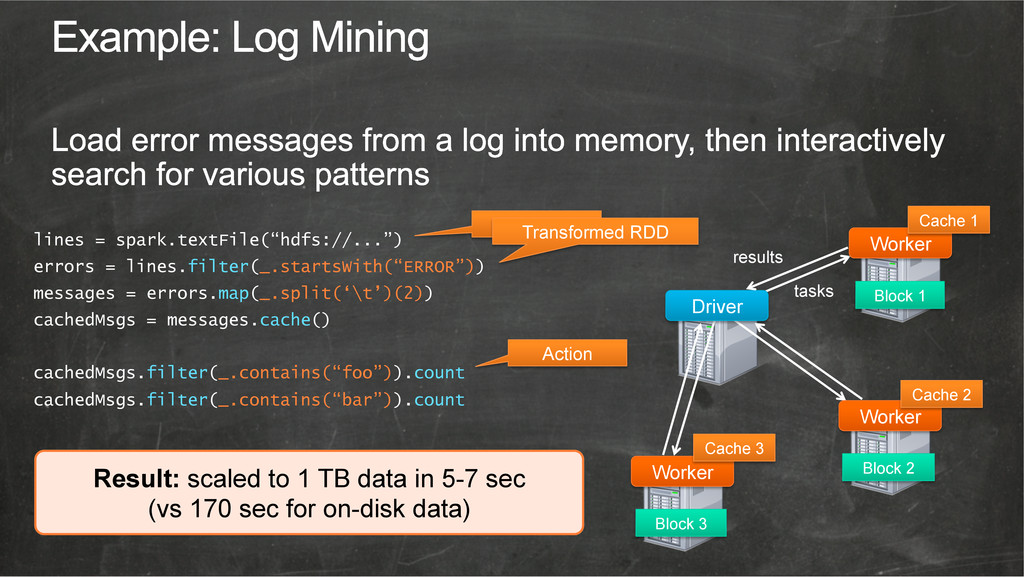{kind=link}
{kind=link}
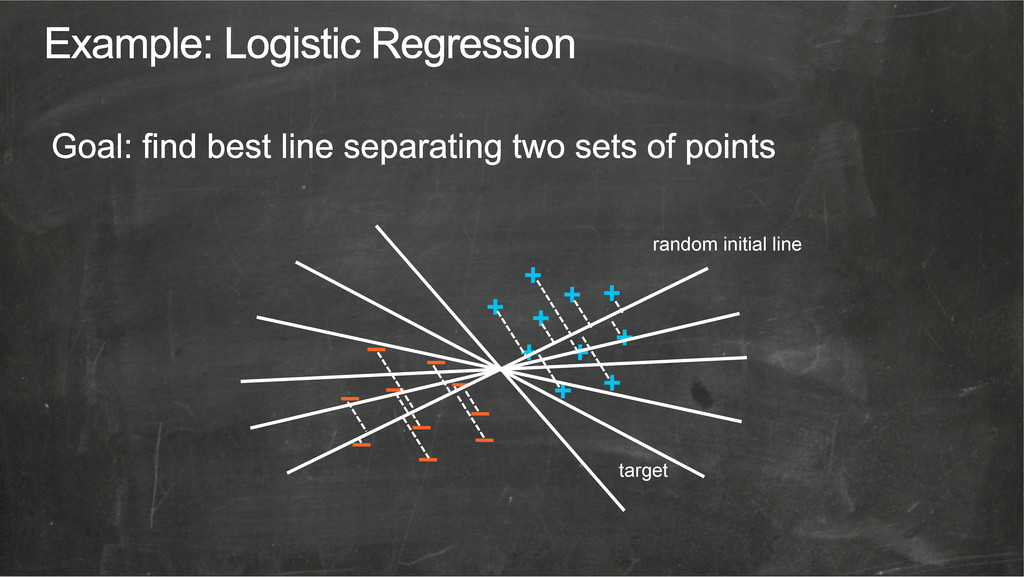{kind=link}
{kind=link}
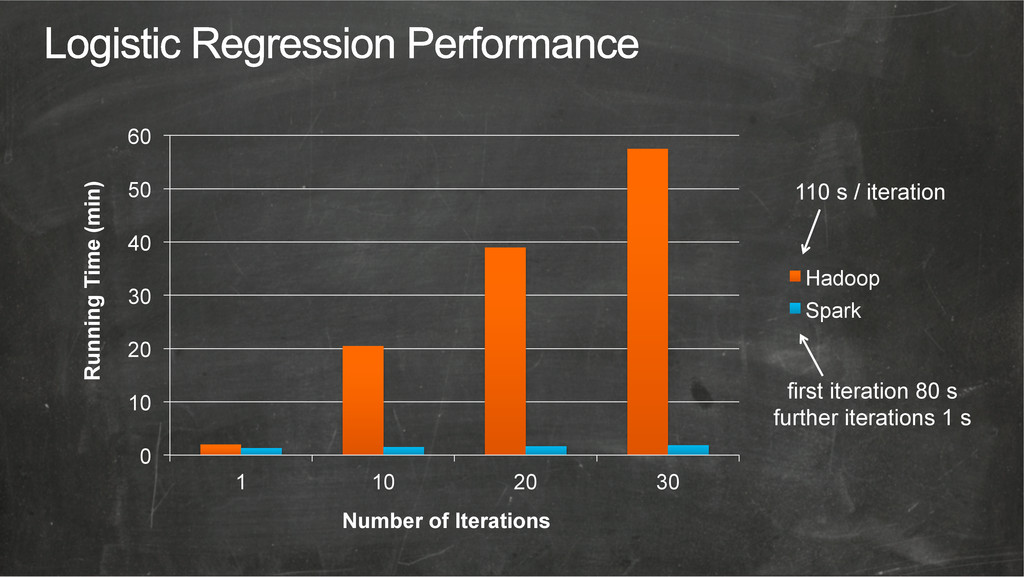{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
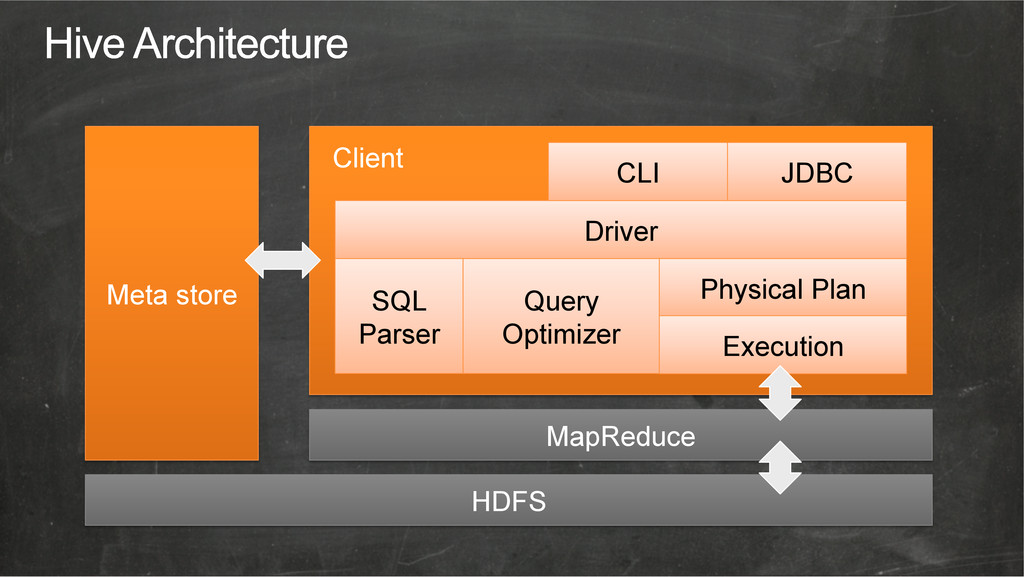{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}