• A low-cost, scalable storage infrastructure • Scale-out, parallel computation framework • Where Hadoop struggles • Not interactive / real-time – designed for batch • Limited computation flexibility of MapReduce (e.g., just map and reduce) • Workflows consist of stitching together disjoint systems
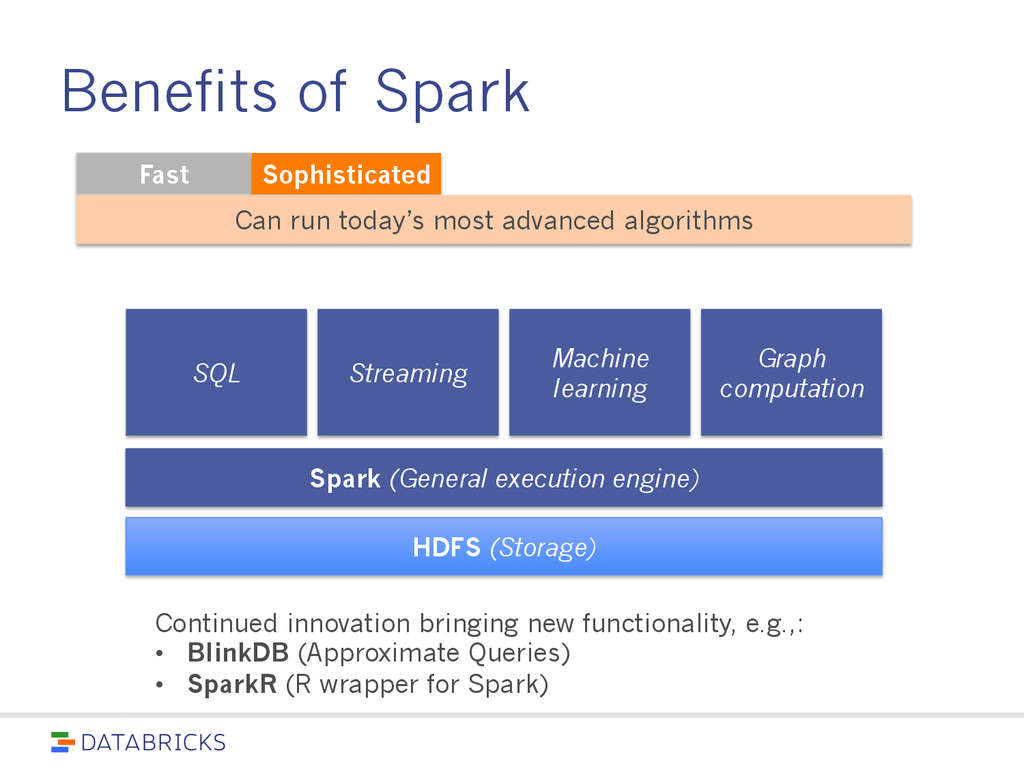
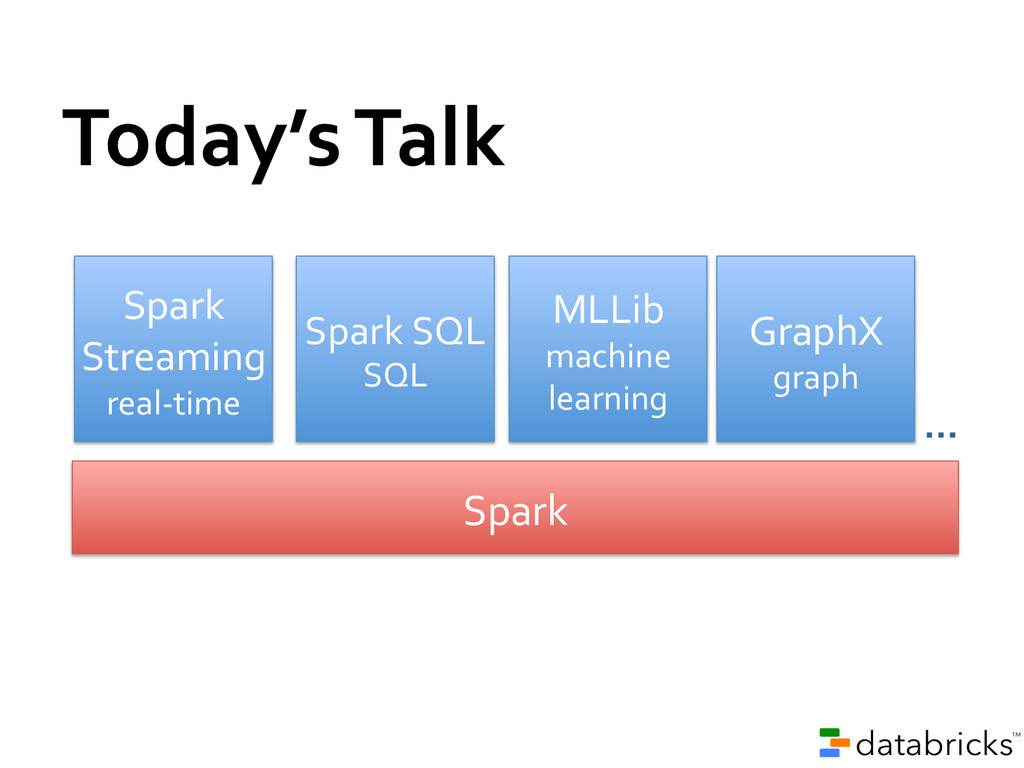
learning Spark (General execution engine) Graph computation Continued innovation bringing new functionality, e.g.,: • BlinkDB (Approximate Queries) • SparkR (R wrapper for Spark) Can run today’s most advanced algorithms
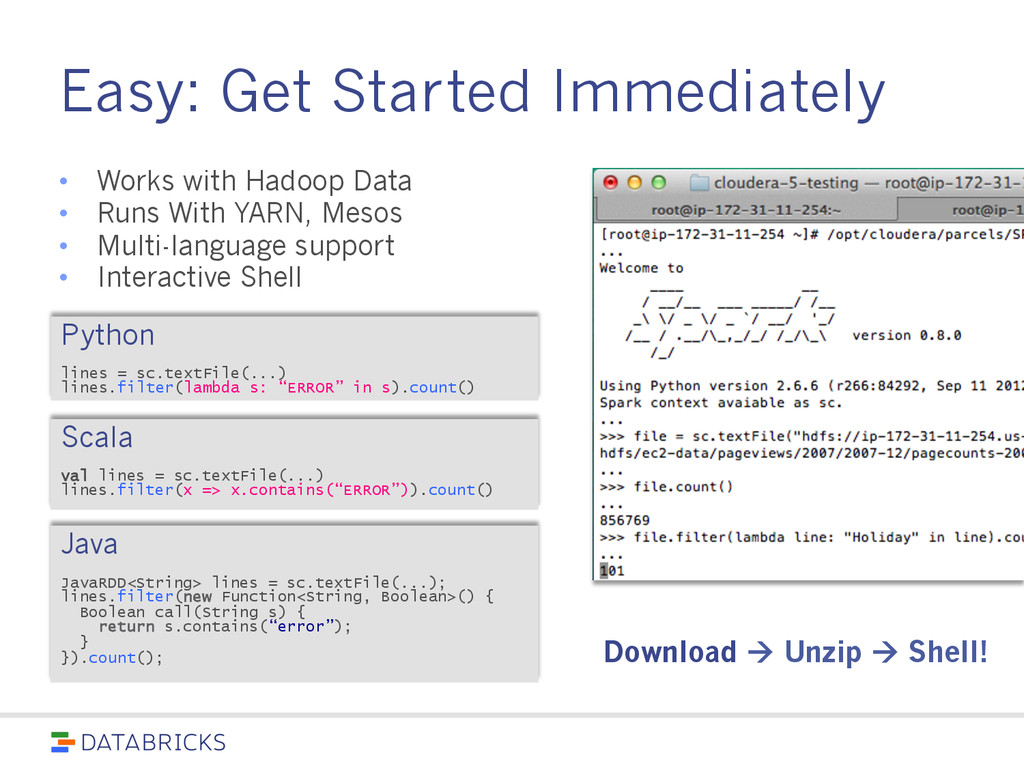
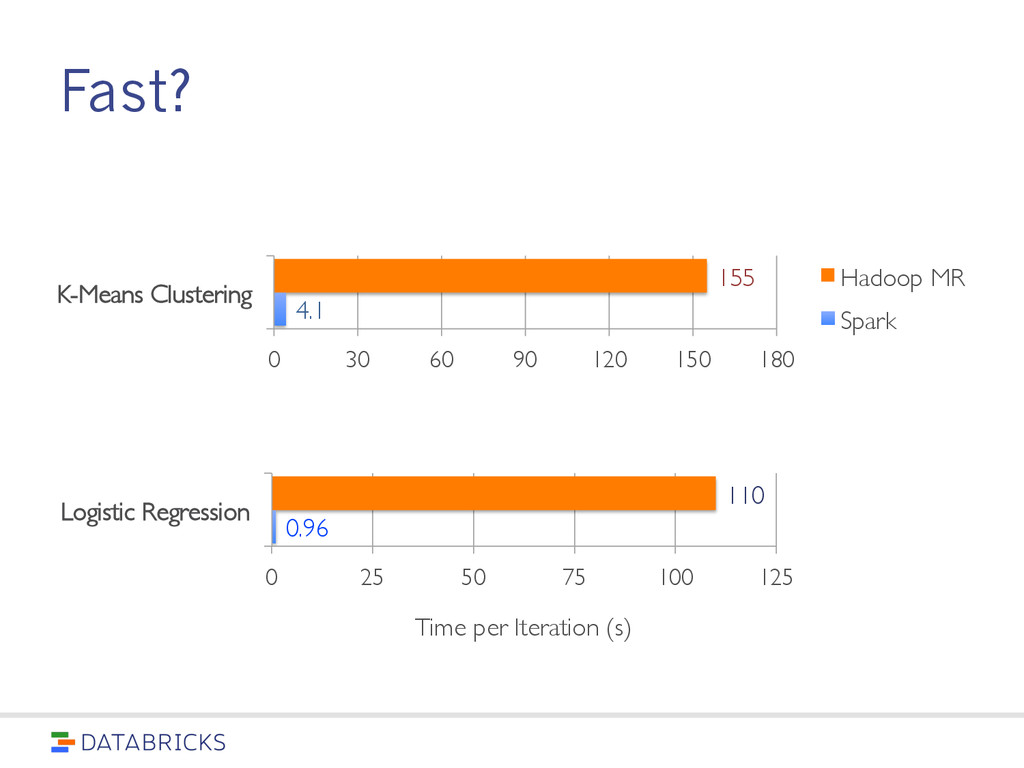
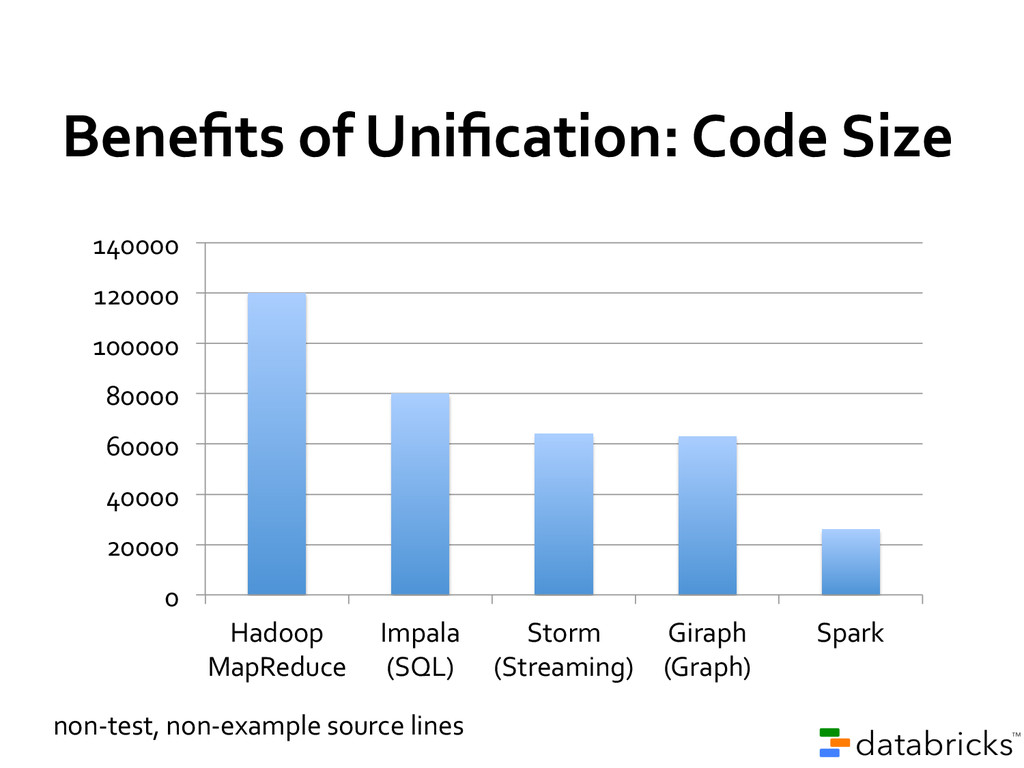
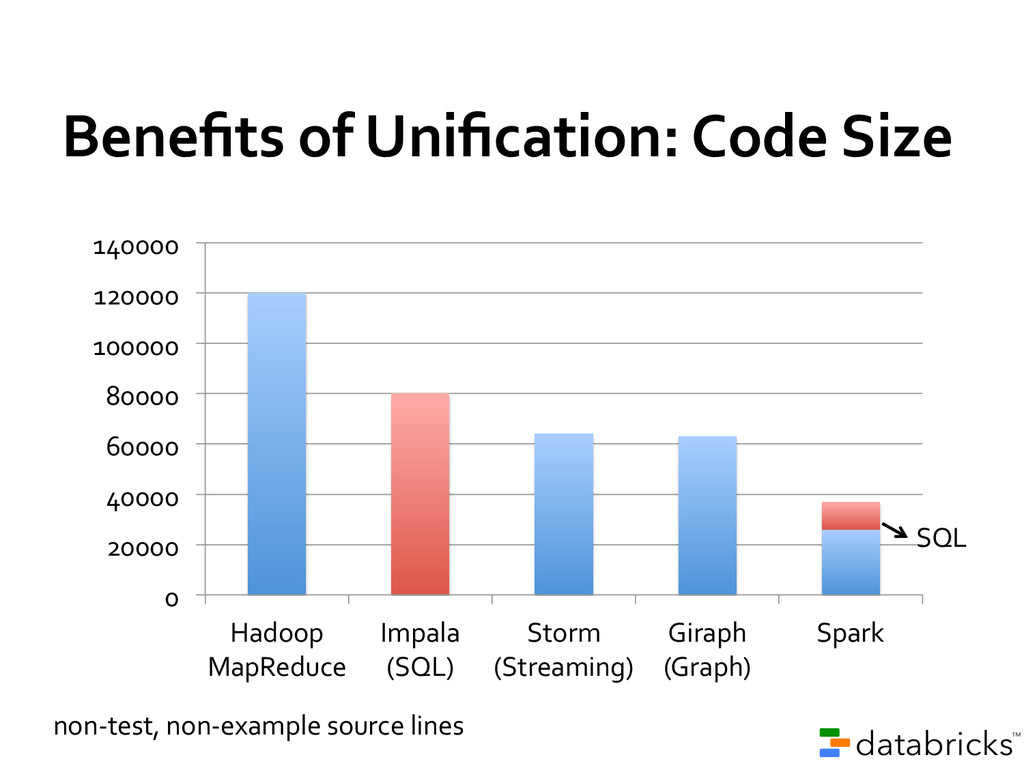
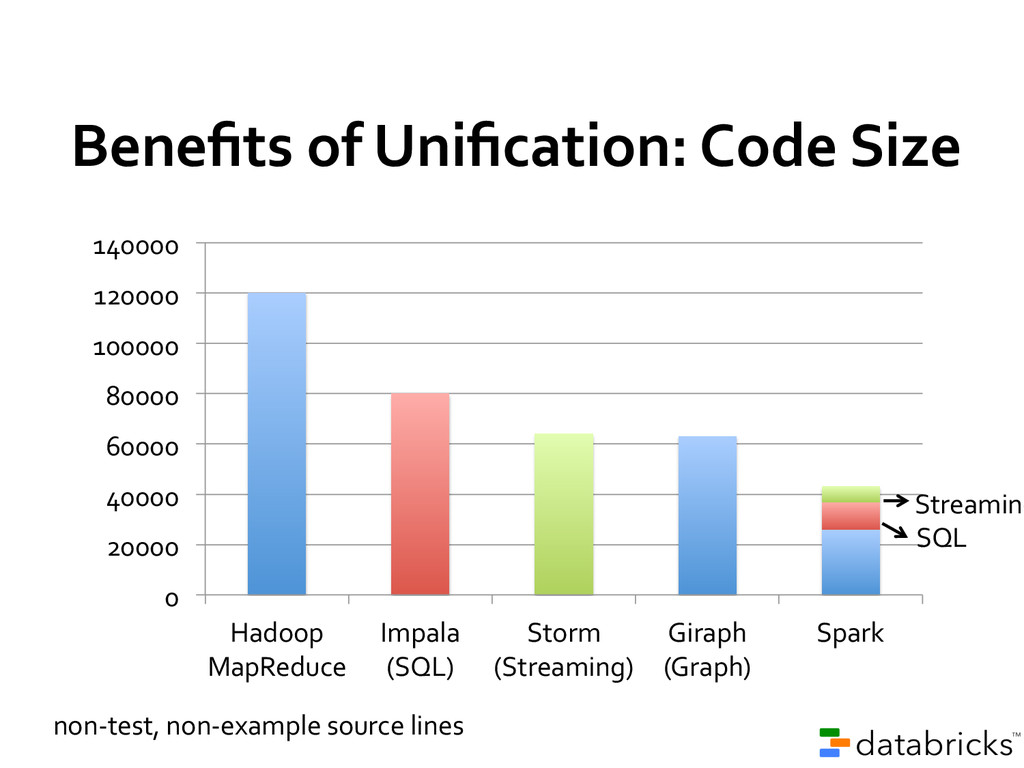
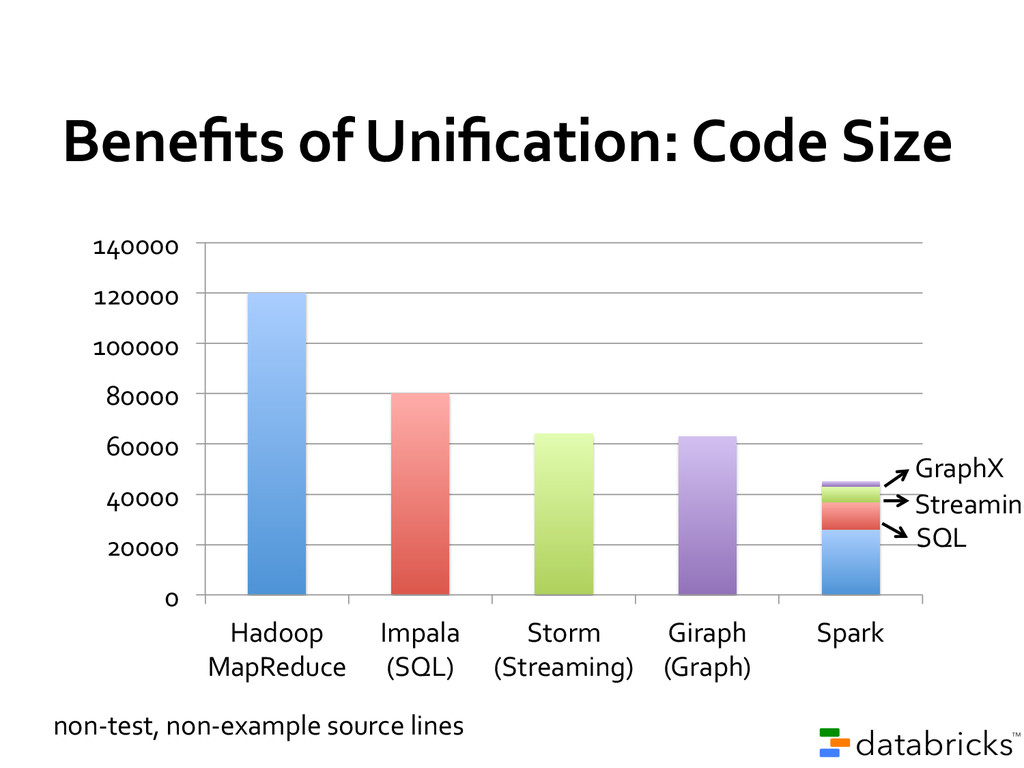
code than MapReduce Use Java, Python, or Scala (or interactive shell) 80+ high-level operators Single language across an entire workflow Simplify application development on top of Hadoop
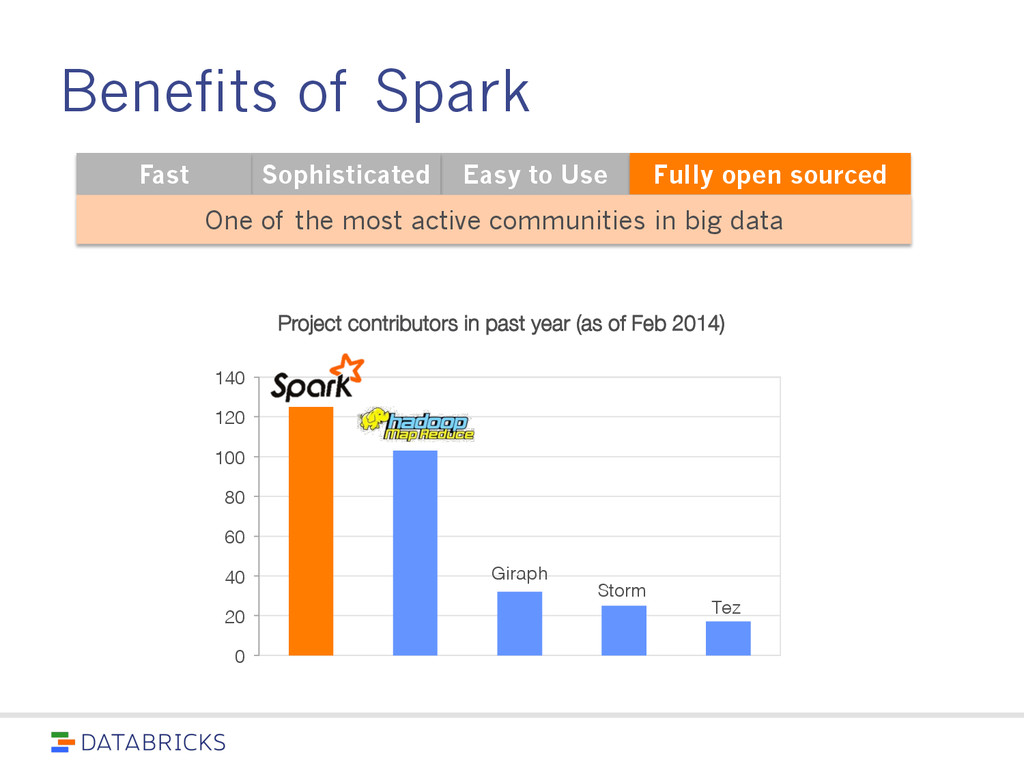
sourced One of the most active communities in big data Giraph! Storm! Tez! 0! 20! 40! 60! 80! 100! 120! 140! Project contributors in past year (as of Feb 2014)
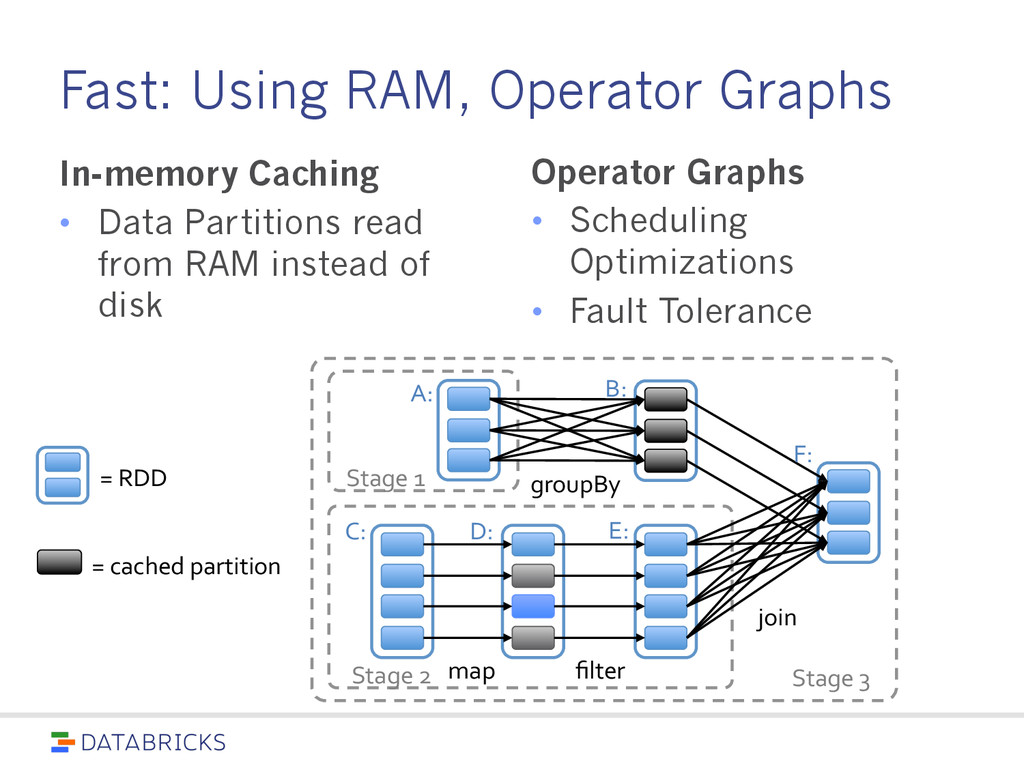
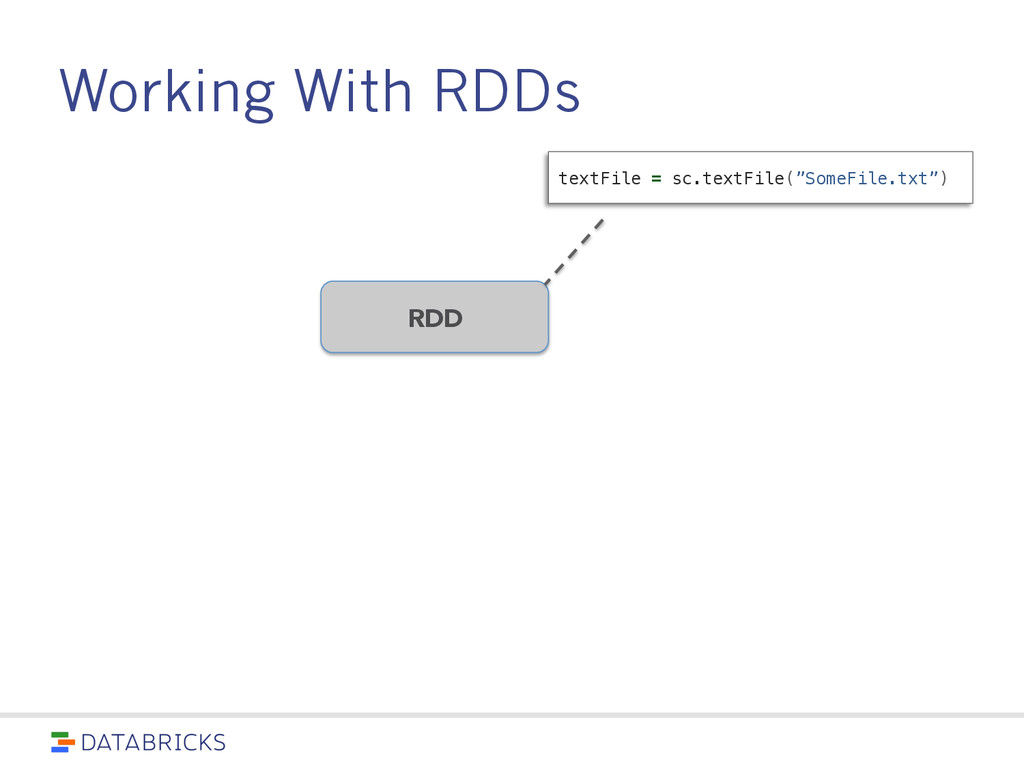
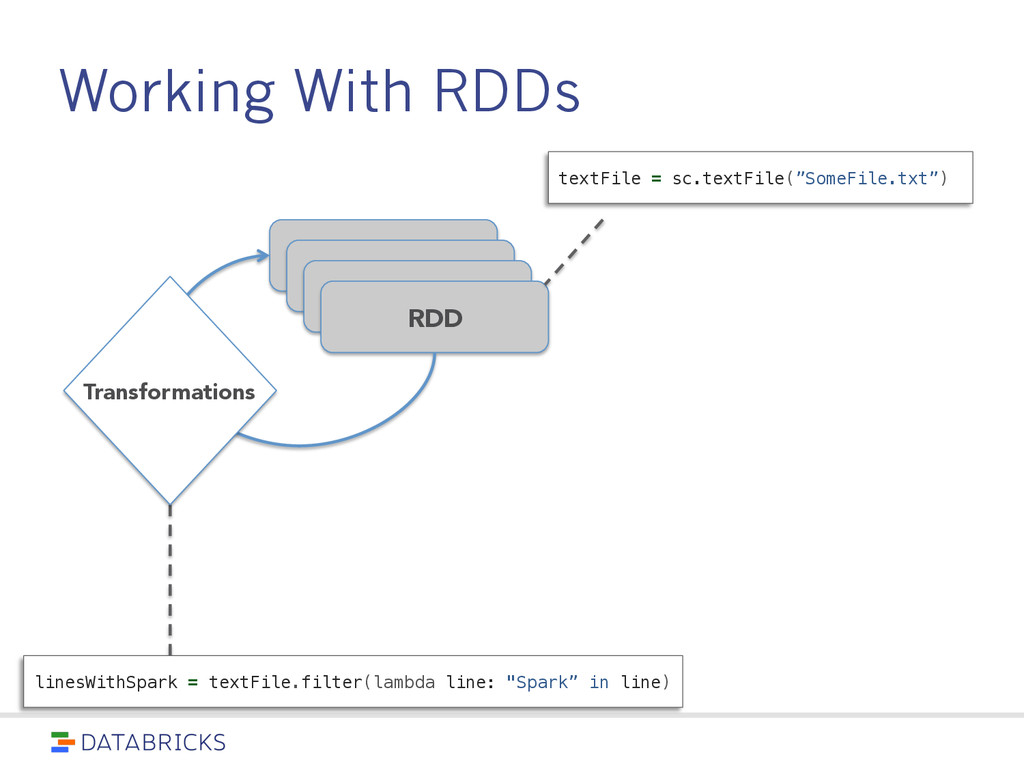
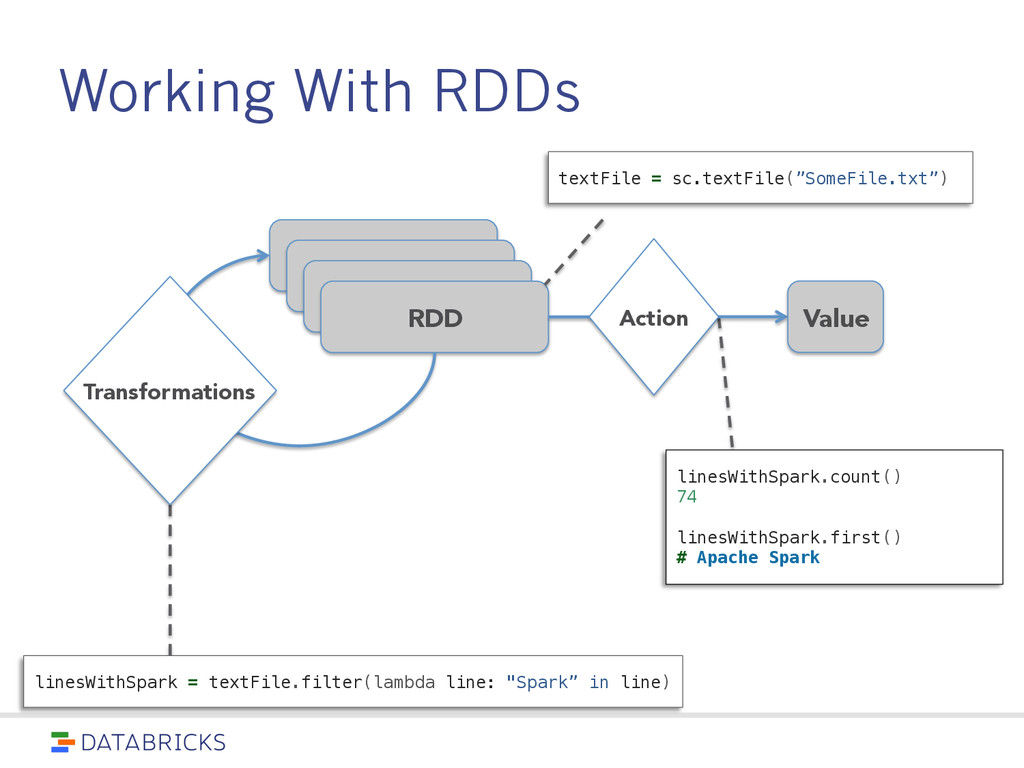
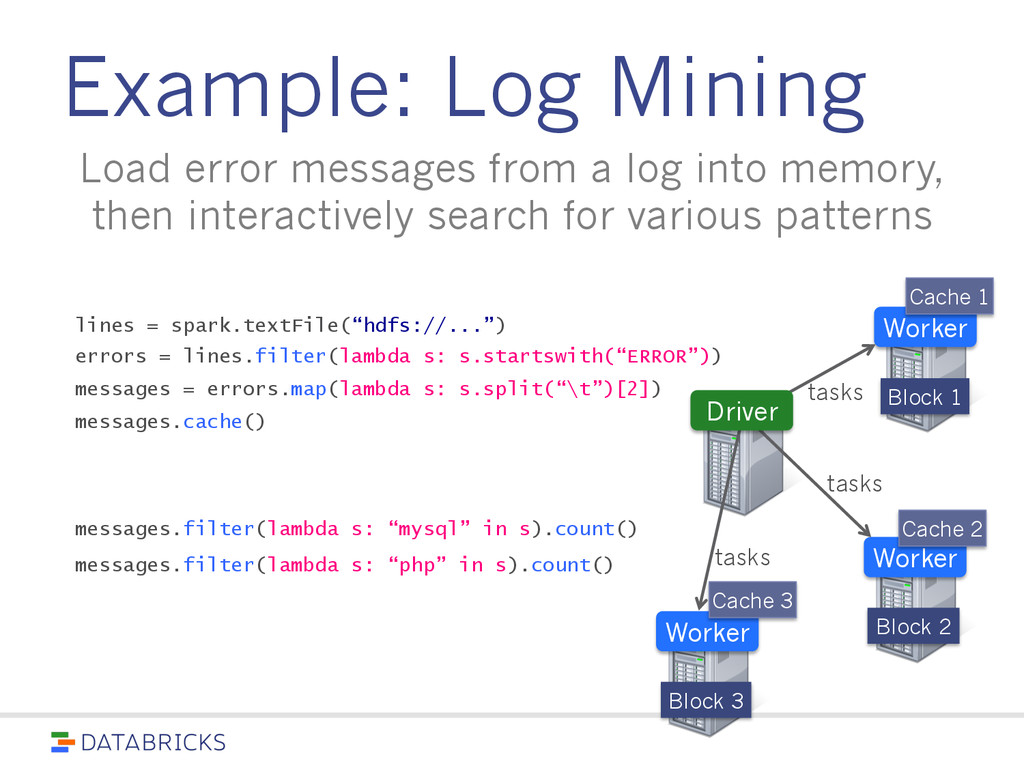
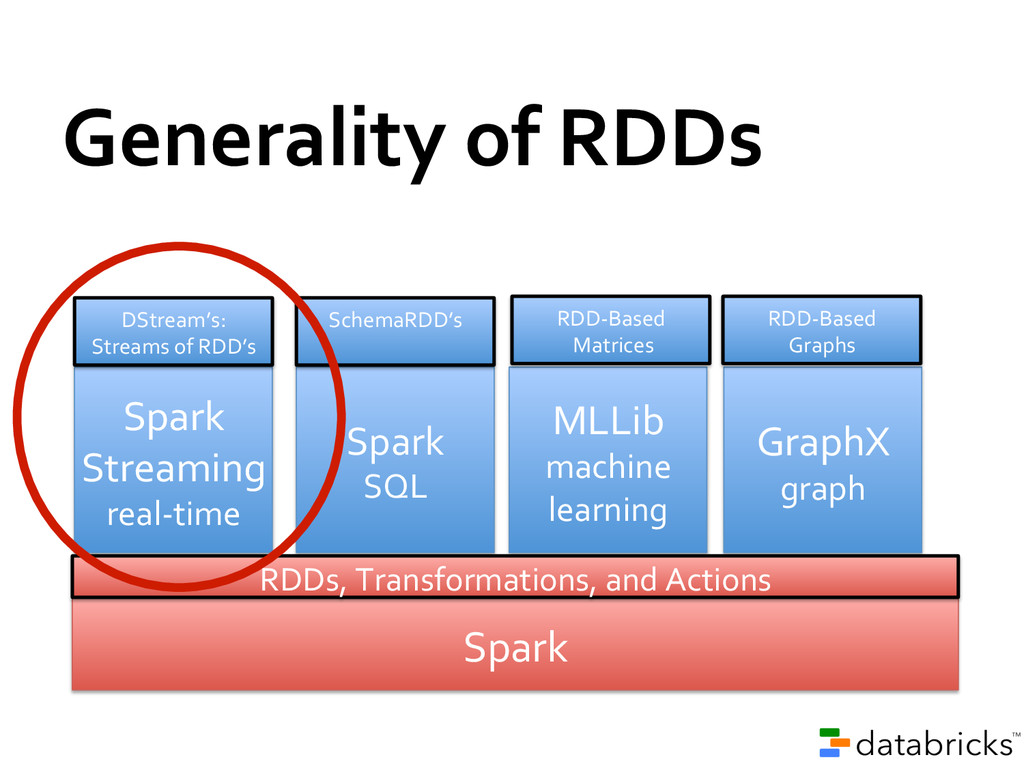
spread across a cluster, stored in RAM or on Disk • Built through parallel transformations • Automatically rebuilt on failure Operations • Transformations (e.g. map, filter, groupBy) • Actions (e.g. count, collect, save) Write programs in terms of distributed datasets and operations on them
“Former” PhD student at Berkeley Left Berkeley to help found Databricks Now managing open source work at Databricks Focus is on networking and operating systems
scientists Well documented, expressive API’s Powerful domain-‐specific libraries Easy integration with storage systems … and caching to avoid data movement Regular maintenance releases
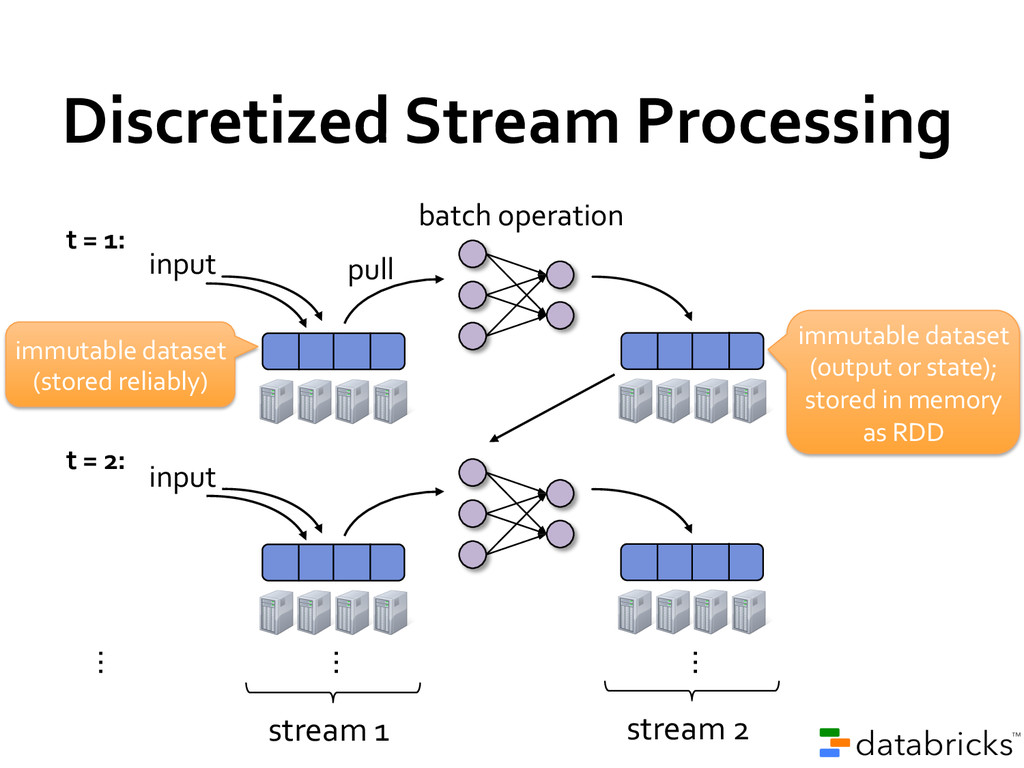
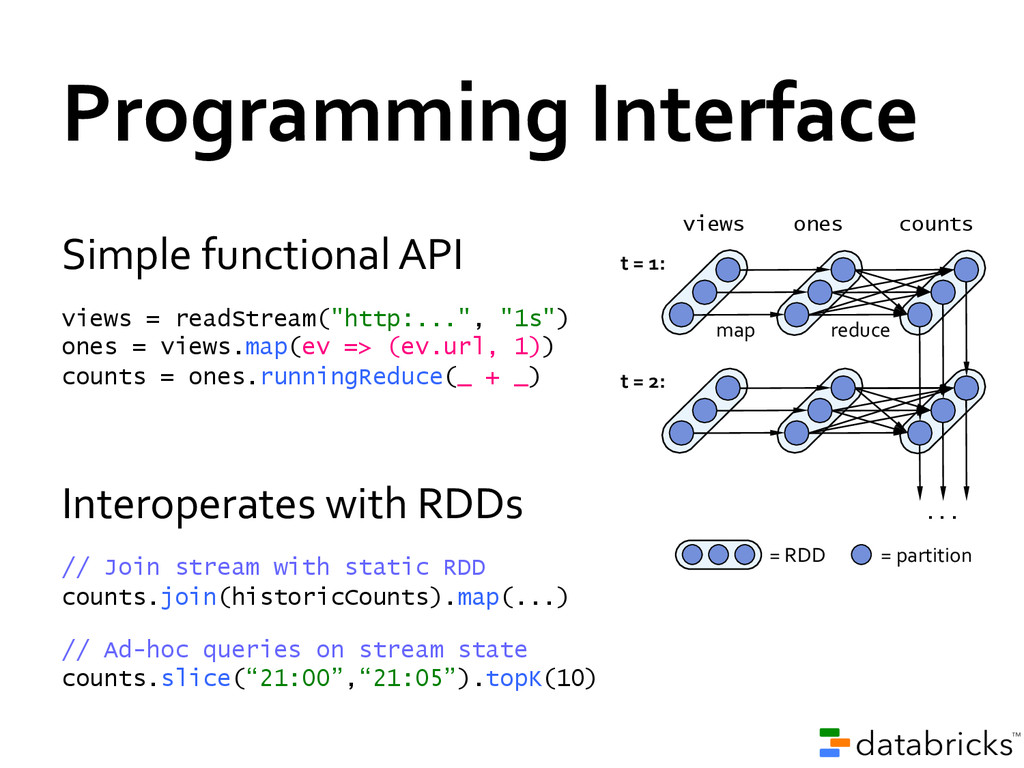
second-‐scale latencies » Site statistics, intrusion detection, online ML To build and scale these apps users want: » Integration: with offline analytical stack » Fault-‐tolerance: both for crashes and stragglers » Efficiency: low cost beyond base processing Spark Streaming: Motivation
schema using a case class. case class Person(name: String, age: Int) // Create an RDD of Person objects, register it as a table. val people = sc.textFile("examples/src/main/resources/people.txt") .map(_.split(",") .map(p => Person(p(0), p(1).trim.toInt)) people.registerAsTable("people")
directly on RDD’s val teenagers = sql("SELECT name FROM people WHERE age >= 13 AND age <= 19") // The results of SQL queries are SchemaRDDs and support // normal RDD operations. val nameList = teenagers.map(t => "Name: " + t(0)).collect() // Language integrated queries (ala LINQ) val teenagers = people.where('age >= 10).where('age <= 19).select('name)
people.saveAsParquetFile("people.parquet") // Load data stored in Hive val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc) import hiveContext._ // Queries can be expressed in HiveQL. hql("FROM src SELECT key, value")
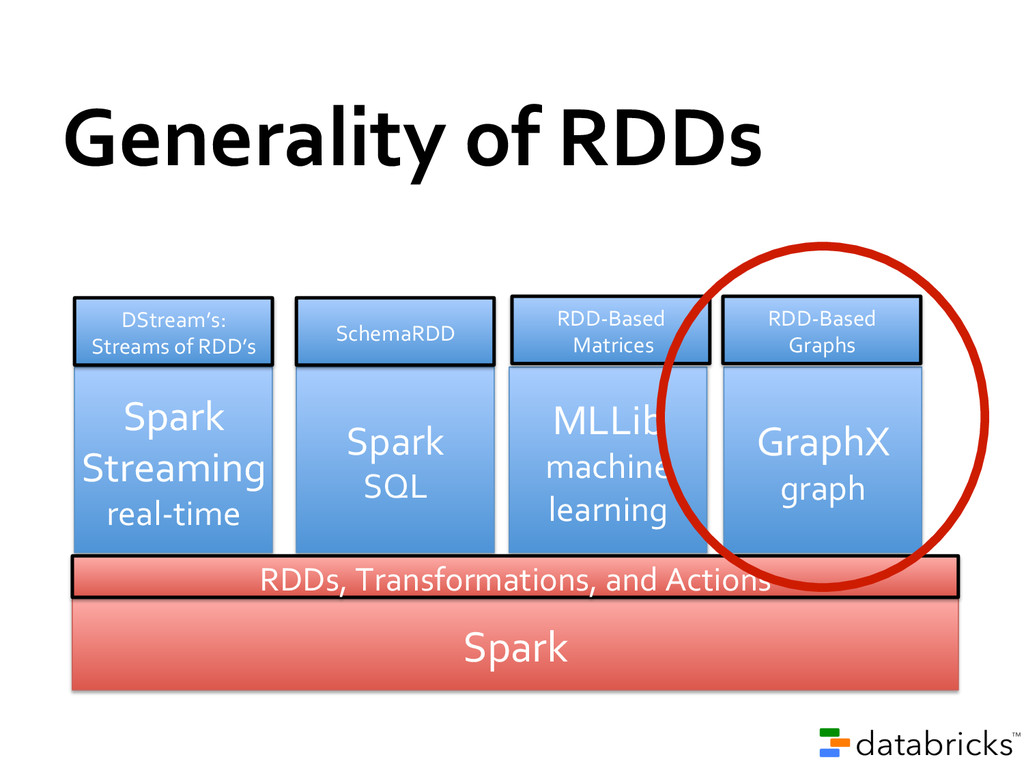
.textFile(“edges.txt”) .map(line => extractEdge(line)) val vertexRDD: RDD[Vertex] = sc .textFile(“vertices.txt”) .map(line => extractVertex(line)) val graph = new Graph(edgeRdd, vertexRdd) Val result = graph.pageRank()
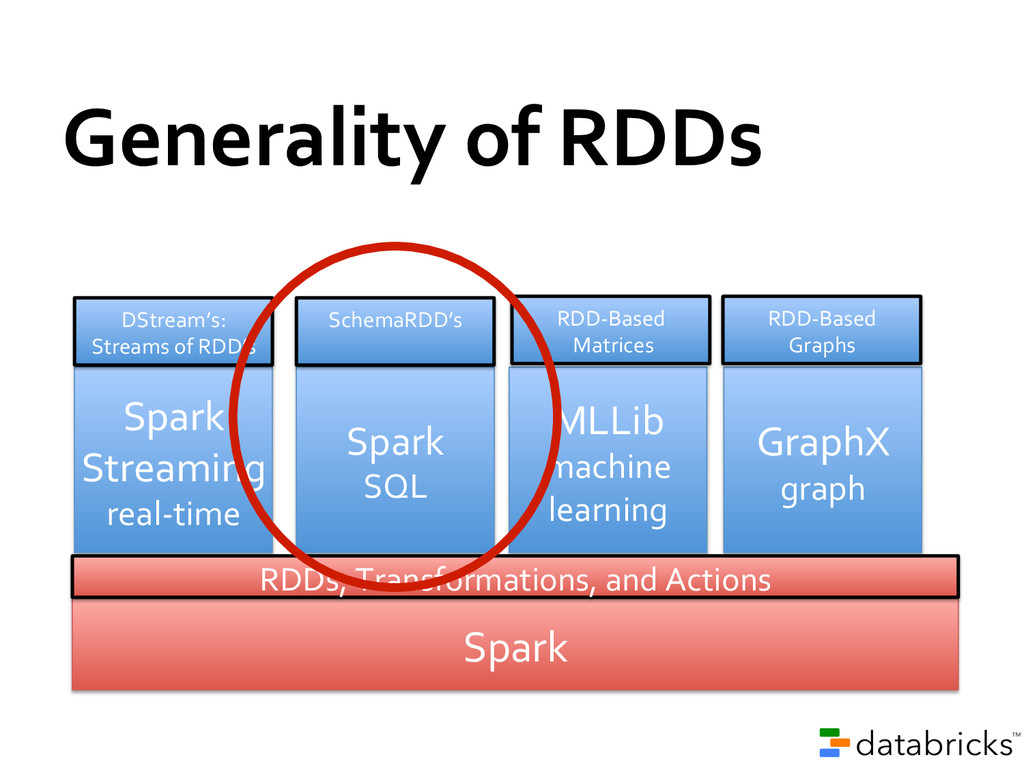
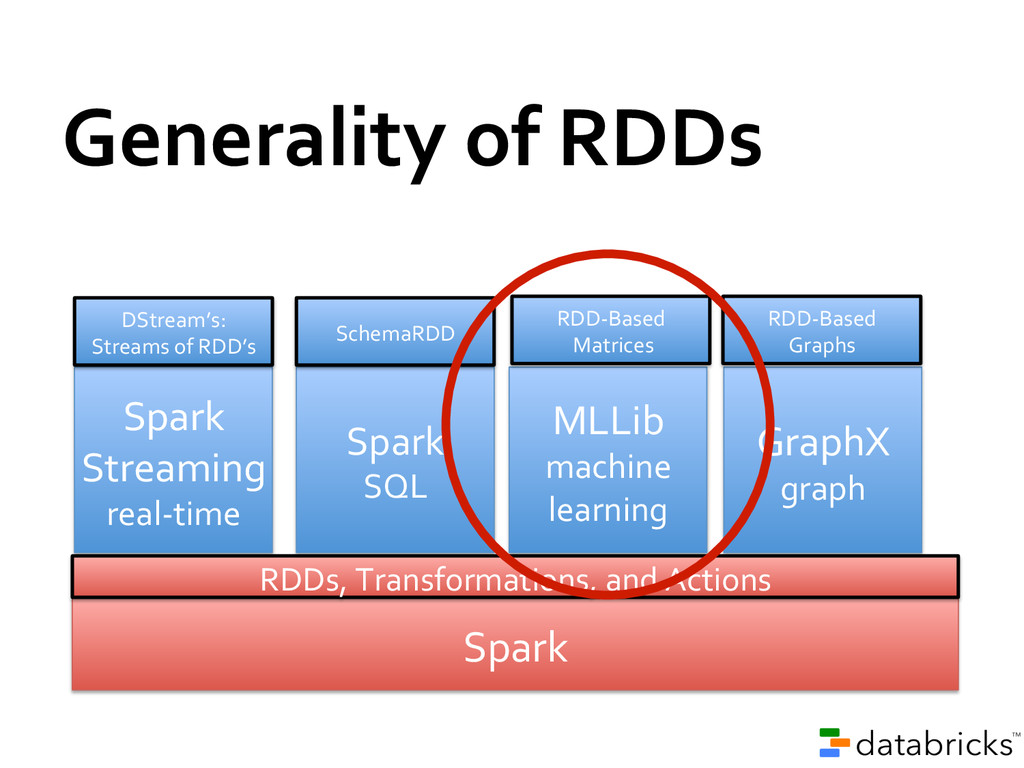
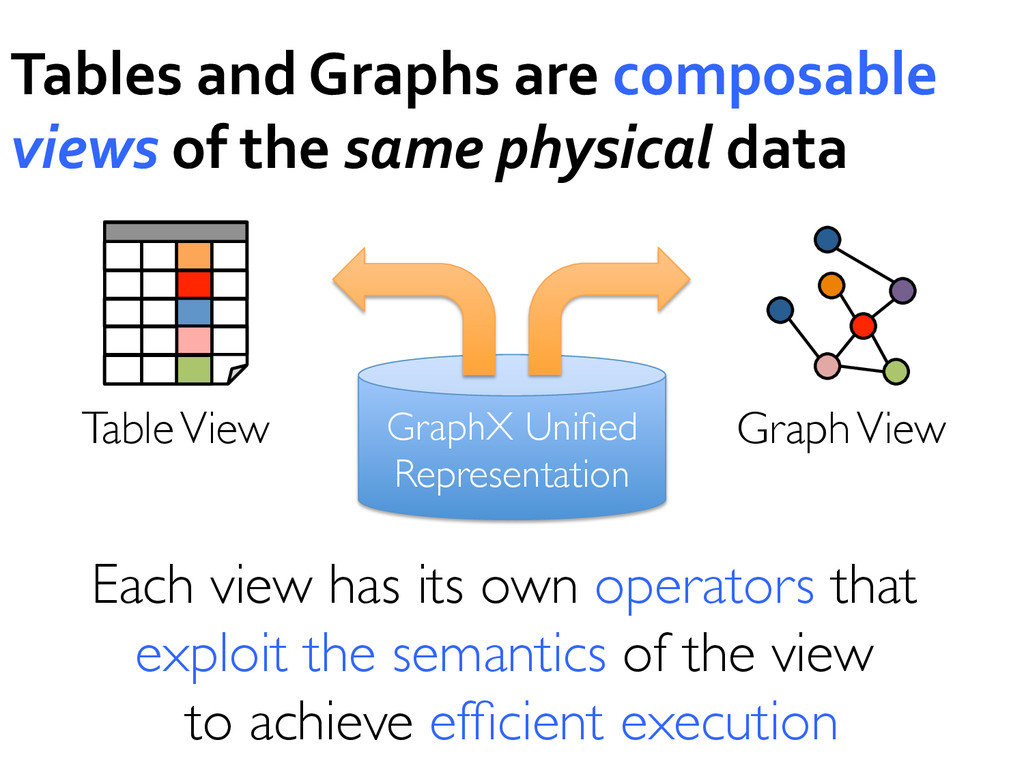
sharing is the bottleneck in many environments » RDD’s provide in-‐place sharing through memory Applications can compose models » Run a SQL query and then PageRank the results » ETL your data and then run graph/ML on it Benefit from investment in shared functioanlity » E.g. re-‐usable components (shell) and performance optimizations
(w/ Java and Python API’s) -‐ Support for Java 8 lambda syntax -‐ Sparse vector support and new algorithms in MLLib -‐ History server for Spark’s UI -‐ API stability -‐ Improved YARN support
hands-‐on exercises Easy to run in local mode, private clusters, EC2 Spark Summit on June 30th (spark-‐summit.org) Online training camp: ampcamp.berkeley.edu
» More complex analytics (e.g. machine learning) » More interactive ad-‐hoc queries » More real-‐time stream processing Spark is a platform that unifies these models, enabling sophisticated apps More info: spark-‐project.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GraphX Example val edgesRdd: RDD[Edge] = sc](https://files.speakerdeck.com/presentations/907dc5b0a30401312acf0e746327760f/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}