Performance Debugging * Assumes you can write word count, knows what transformation/action is “Mechanical sympathy” by Jackie Stewart: a driver does not need to know how to build an engine but they need to know the fundamentals of how one works to get the best out of it
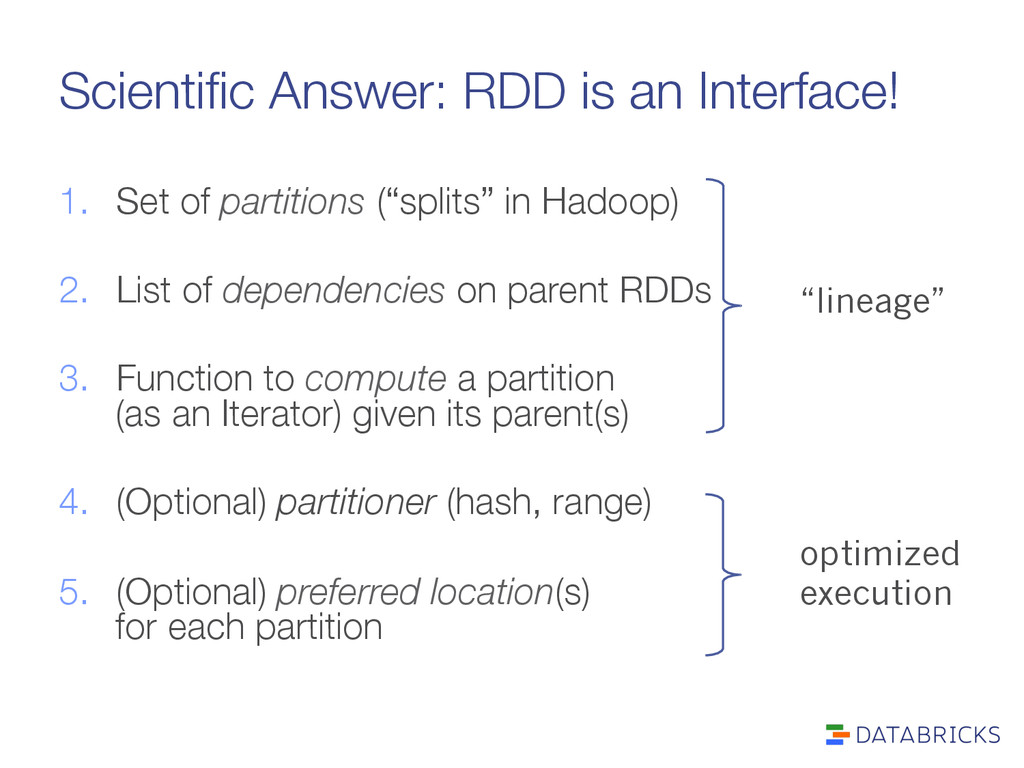
(“splits” in Hadoop) 2. List of dependencies on parent RDDs 3. Function to compute a partition" (as an Iterator) given its parent(s) 4. (Optional) partitioner (hash, range) 5. (Optional) preferred location(s)" for each partition “lineage” optimized execution
“shuffle” on each parent compute(partition) = read and join shuffled data preferredLocations(part) = none" partitioner = HashPartitioner(numTasks) Spark will now know this data is hashed!
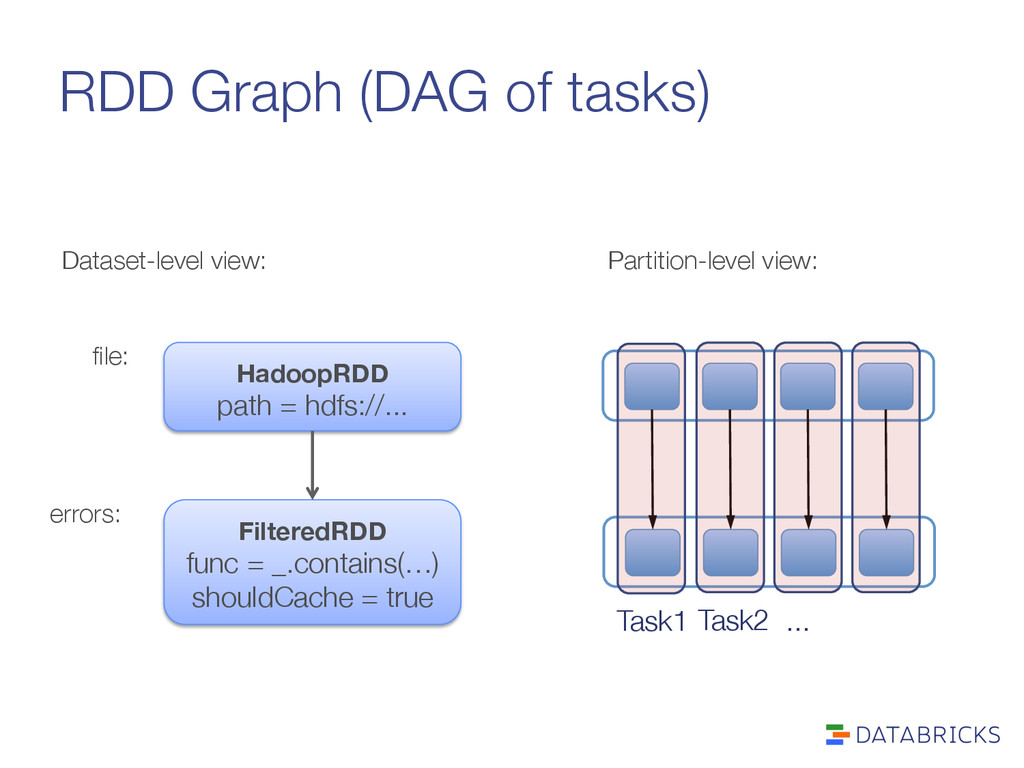
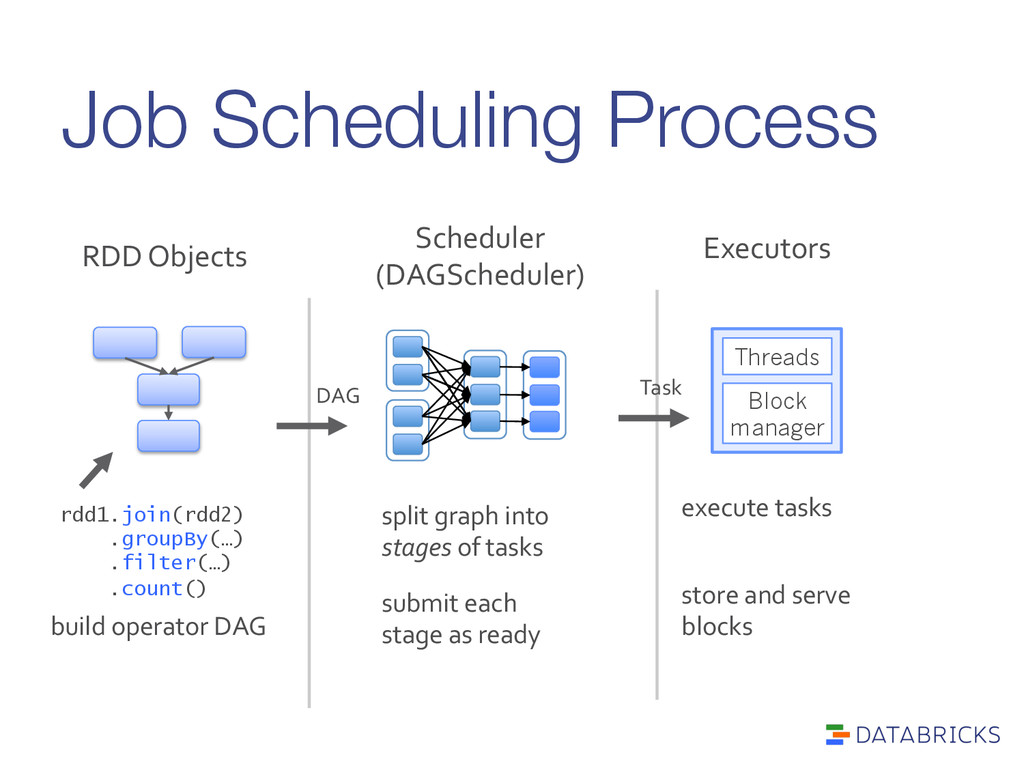
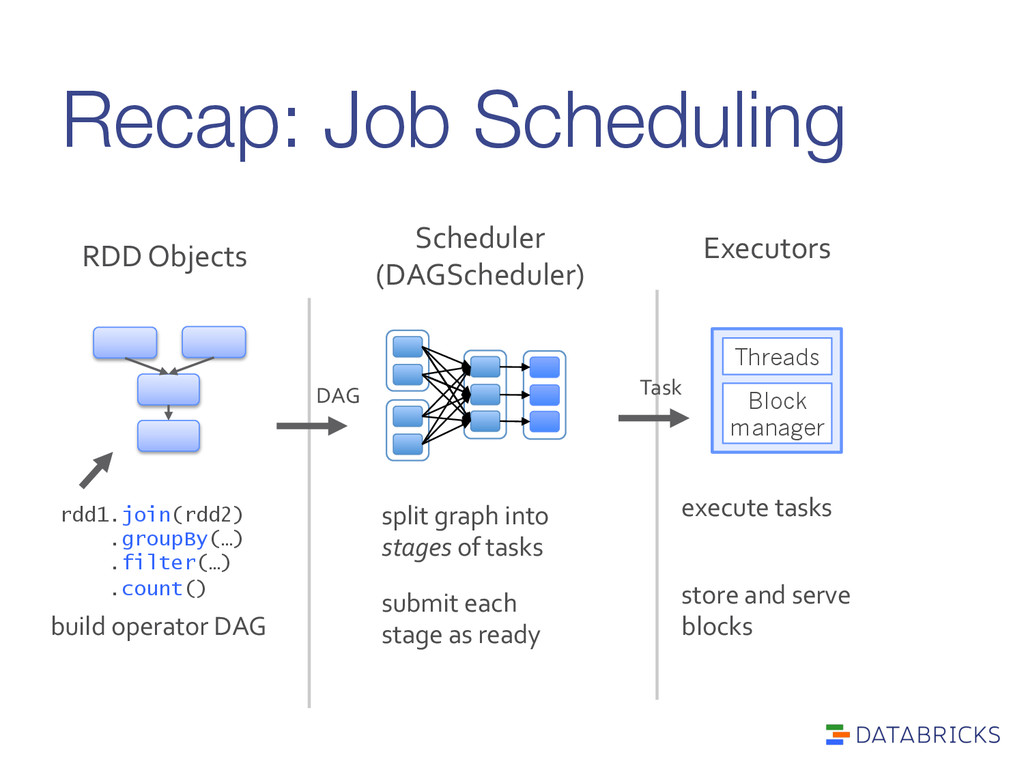
build operator DAG Scheduler (DAGScheduler) split graph into stages of tasks submit each stage as ready DAG Executors execute tasks store and serve blocks Block manager Threads Task
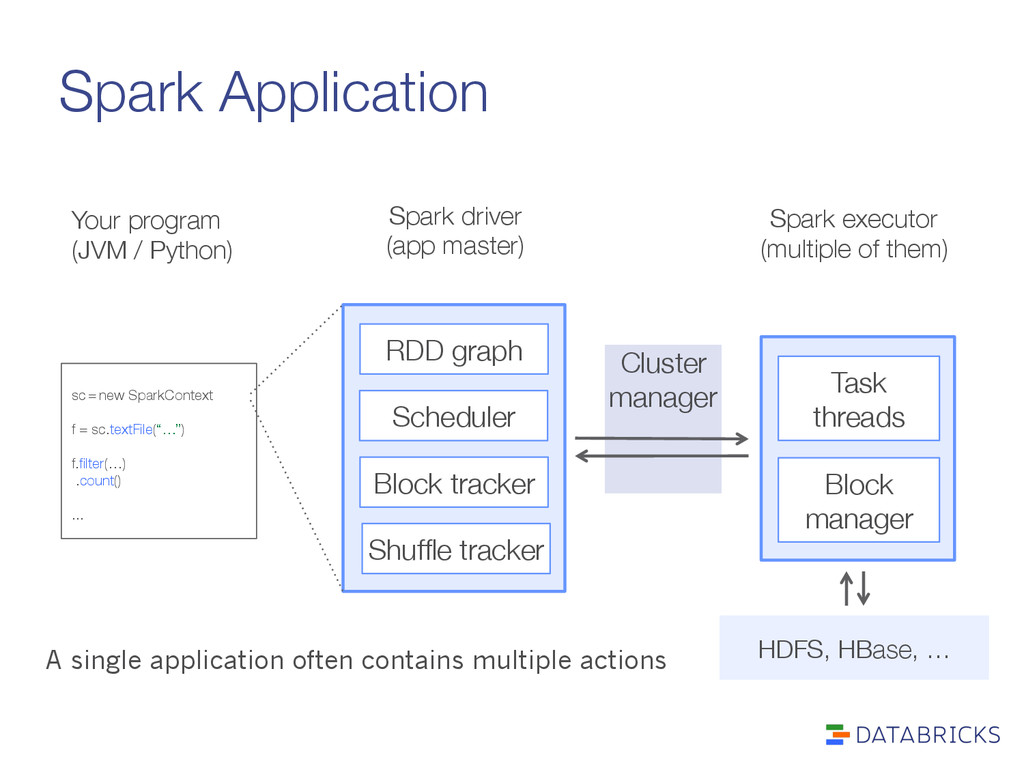
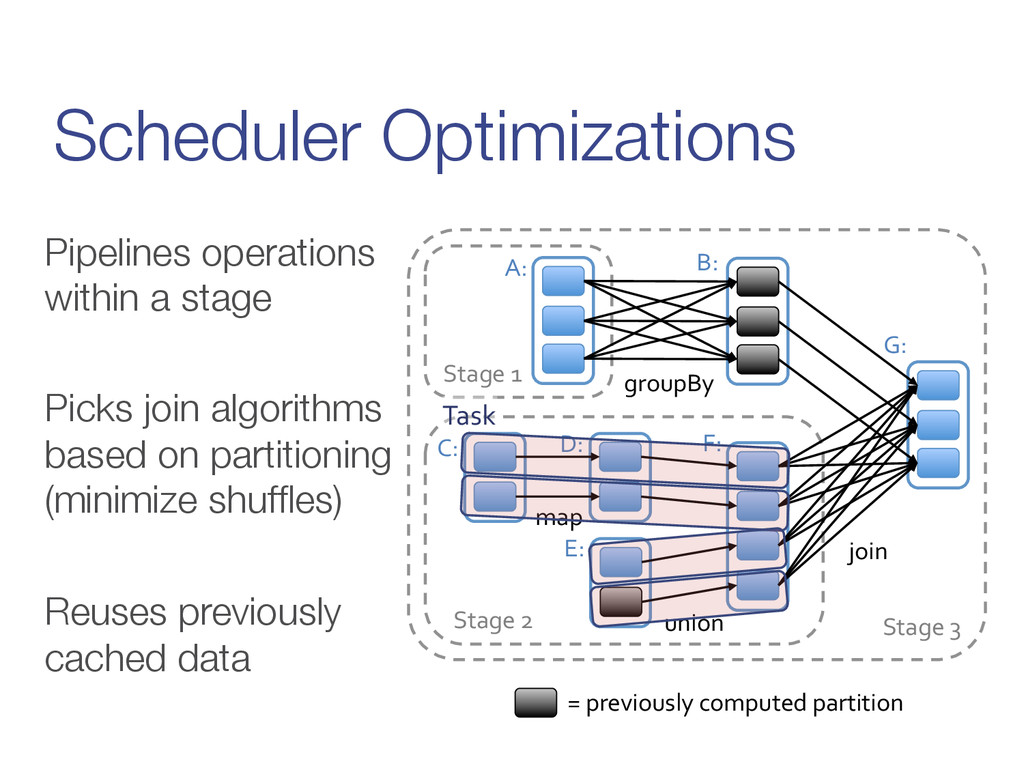
from actions on those partitions Roles: > Build stages of tasks > Submit them to lower level scheduler (e.g. YARN, Mesos, Standalone) as ready > Lower level scheduler will schedule data based on locality > Resubmit failed stages if outputs are lost
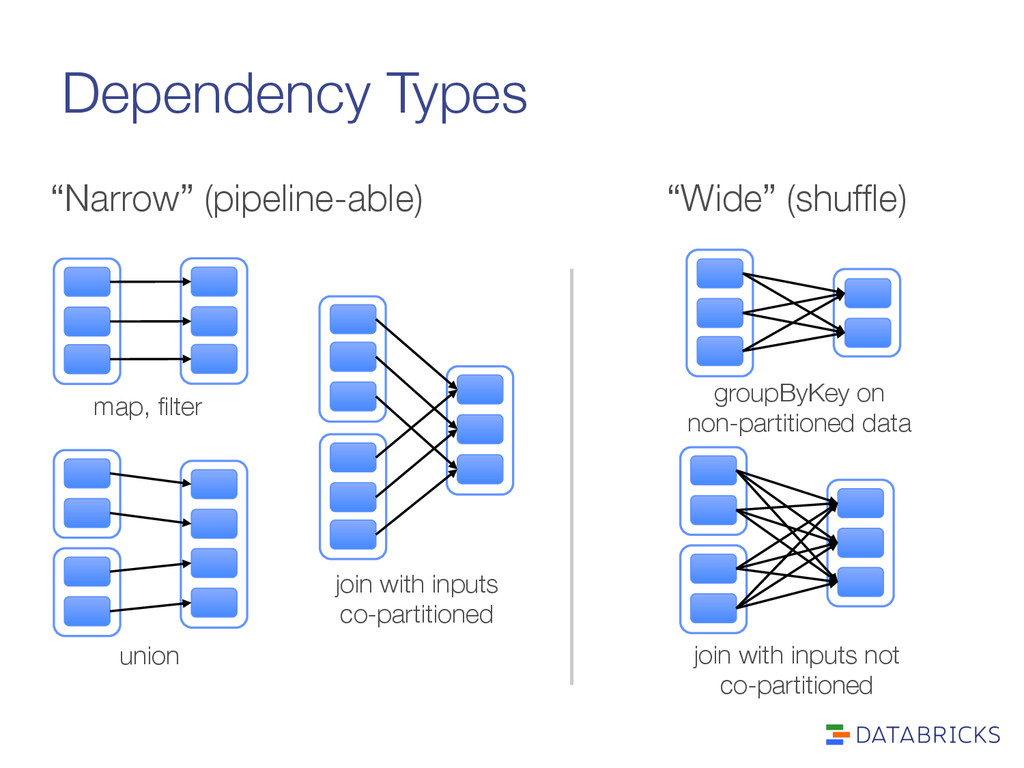
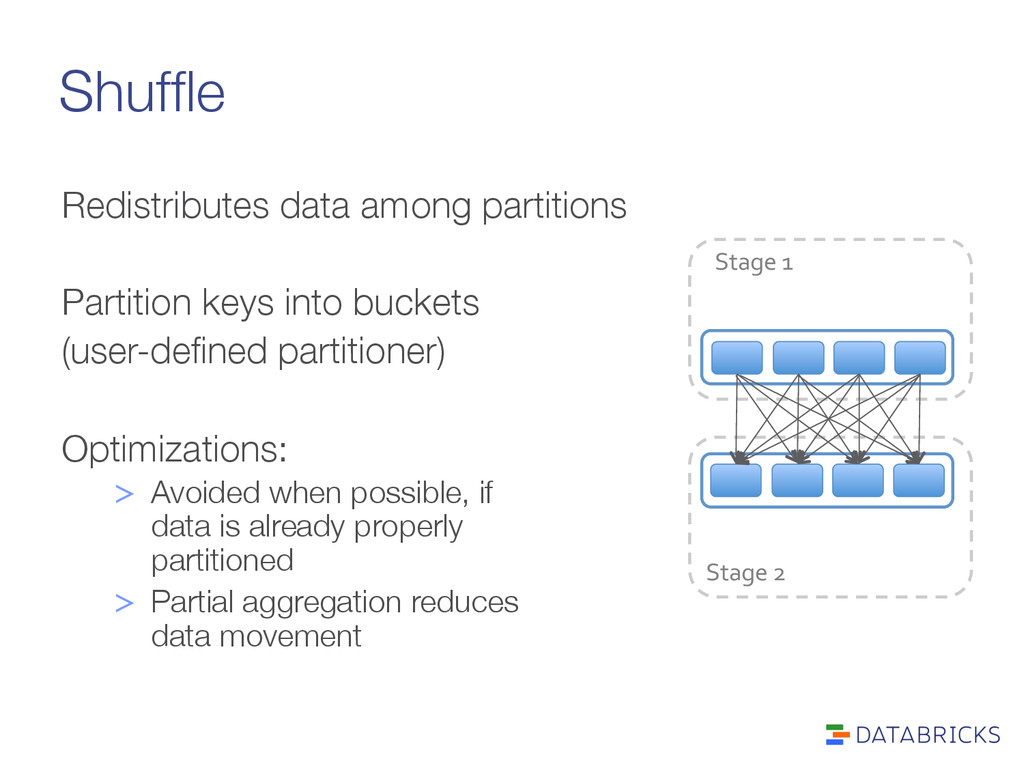
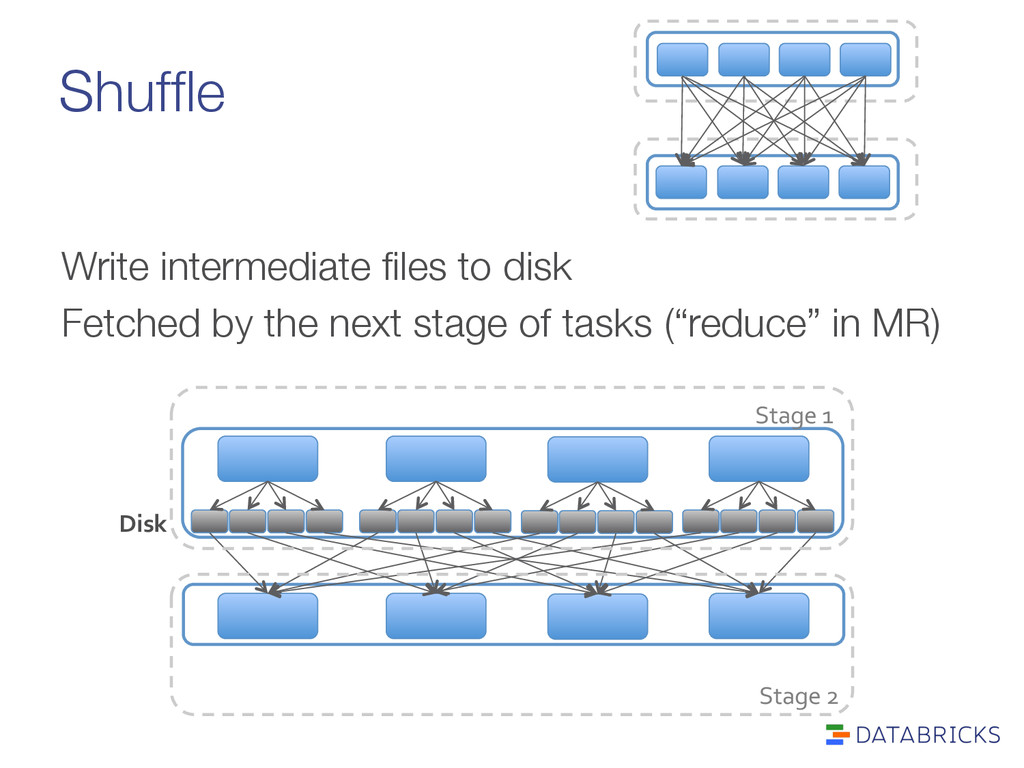
partitions Partition keys into buckets (user-defined partitioner) Optimizations: > Avoided when possible, if" data is already properly" partitioned > Partial aggregation reduces" data movement
build operator DAG Scheduler (DAGScheduler) split graph into stages of tasks submit each stage as ready DAG Executors execute tasks store and serve blocks Block manager Threads Task
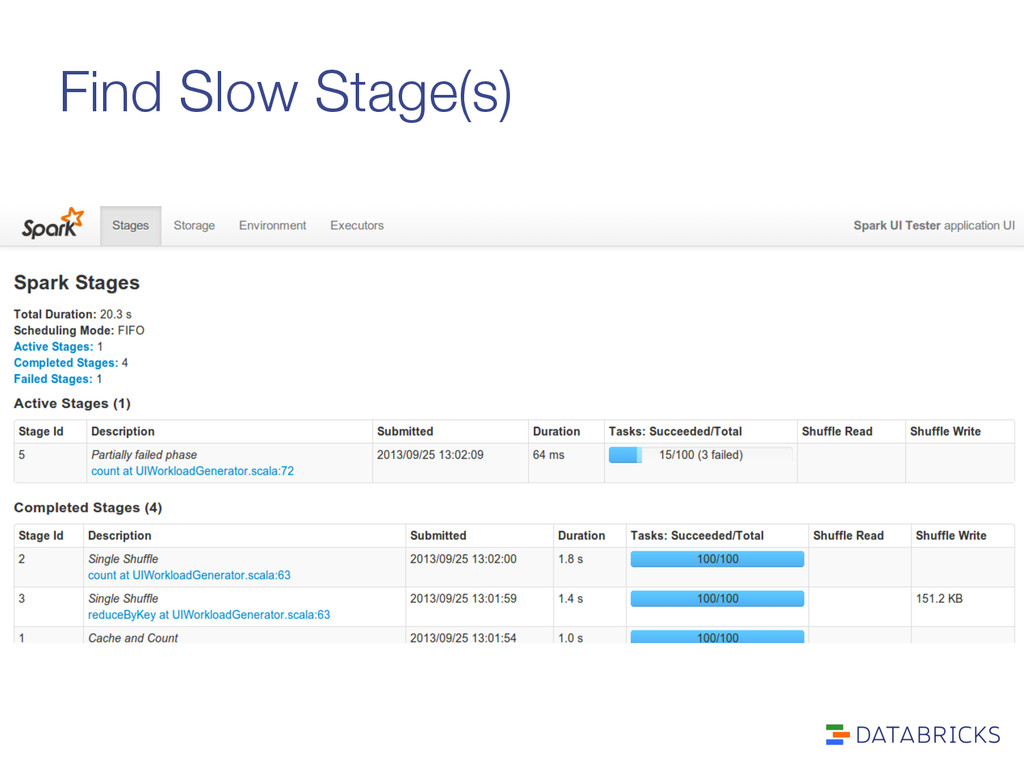
or data distribution) Local performance: program slow because whatever I’m running is just slow on a single node Two useful tools: > Application web UI (default port 4040) > Executor logs (spark/work)
this problem. Speculation: Spark identifies slow tasks (by looking at runtime distribution), and re-launches those tasks on other nodes. spark.speculation true
{ i => 1 to i } .map { i => Thread.sleep(1000) } .count() Speculation is not going to help because the problem is inherent in the algorithm/data. Pick a different algorithm or restructure the data.
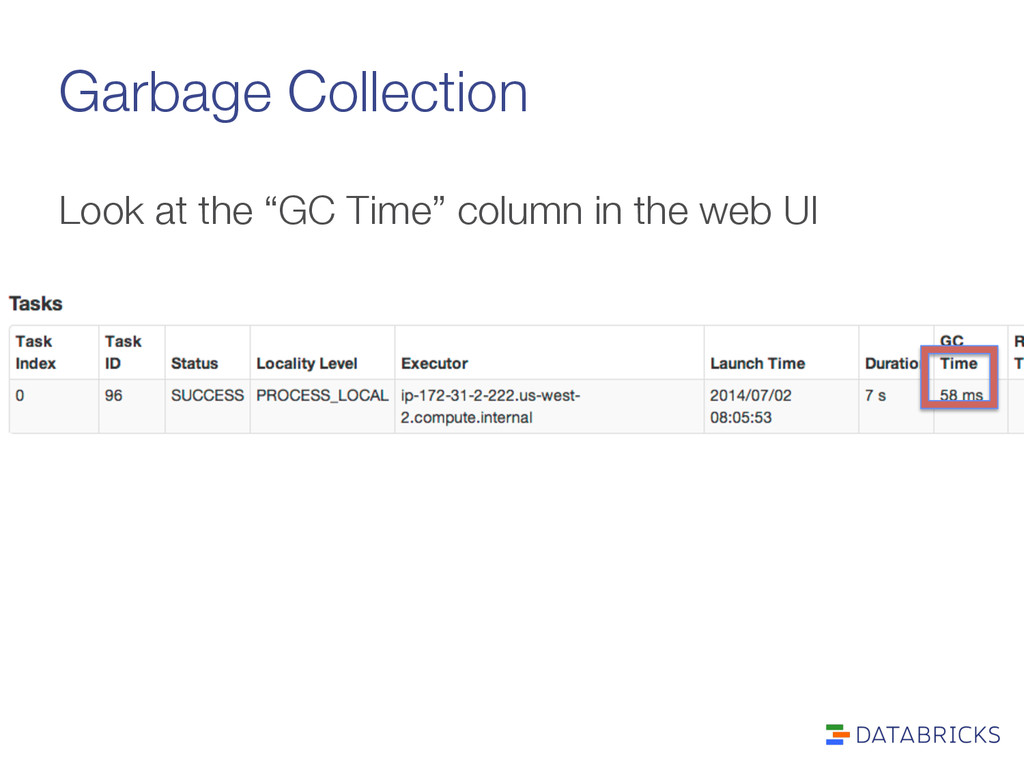
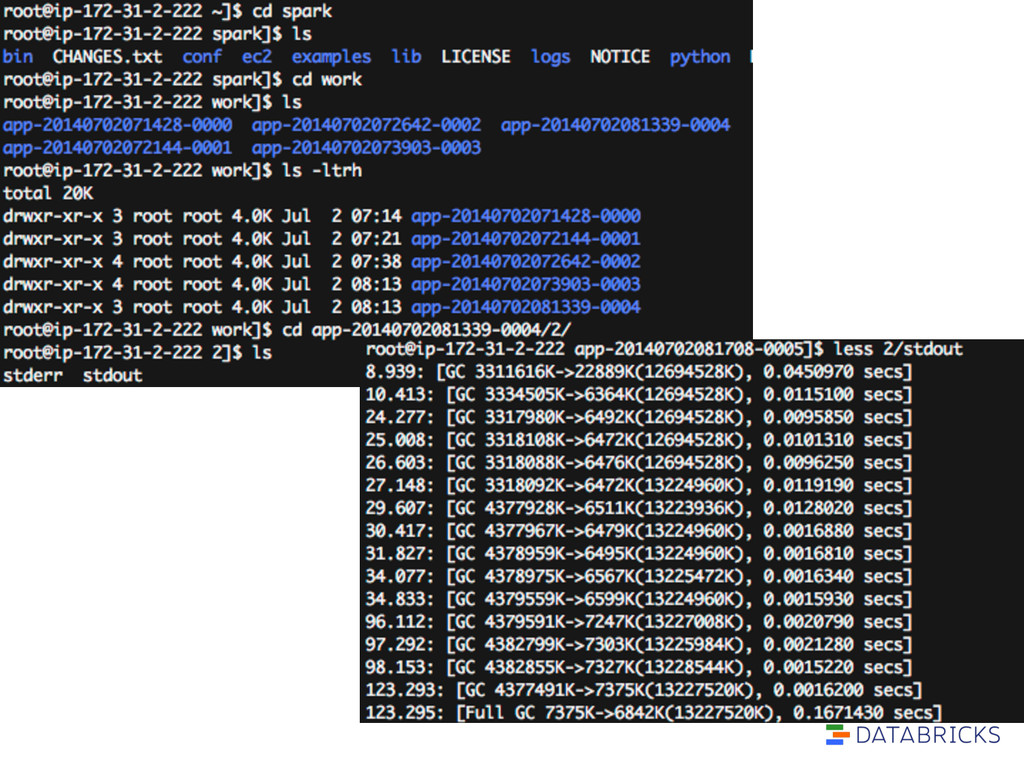
GC is the problem: 1. Set spark.executor.extraJavaOptions to include: “-XX:-PrintGCDetails -XX:+PrintGCTimeStamps” 2. Look at spark/work/app…/[n]/stdout on executors 3. Short GC times are OK. Long ones are bad.
= i } sc.parallelize(1 to 100 * 1000 * 1000, 1).map { i => new DummyObject(i) // new object every record obj.toInt } sc.parallelize(1 to 100 * 1000 * 1000, 1).mapPartitions { iter => val obj = new DummyObject(0) // reuse the same object iter.map { i => obj.i = i obj.toInt } }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![jmap: heap analysis jmap -histo [pid] Gets a histogram of](https://files.speakerdeck.com/presentations/5b5c74e00644013258d2029fef629589/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}