of nodes in a fault- tolerant manner! 2. Good for analyzing semi-structured data and complex analytics! 3. Elasticity (cloud computing)! 4. Dynamic, multi-tenant resource sharing!
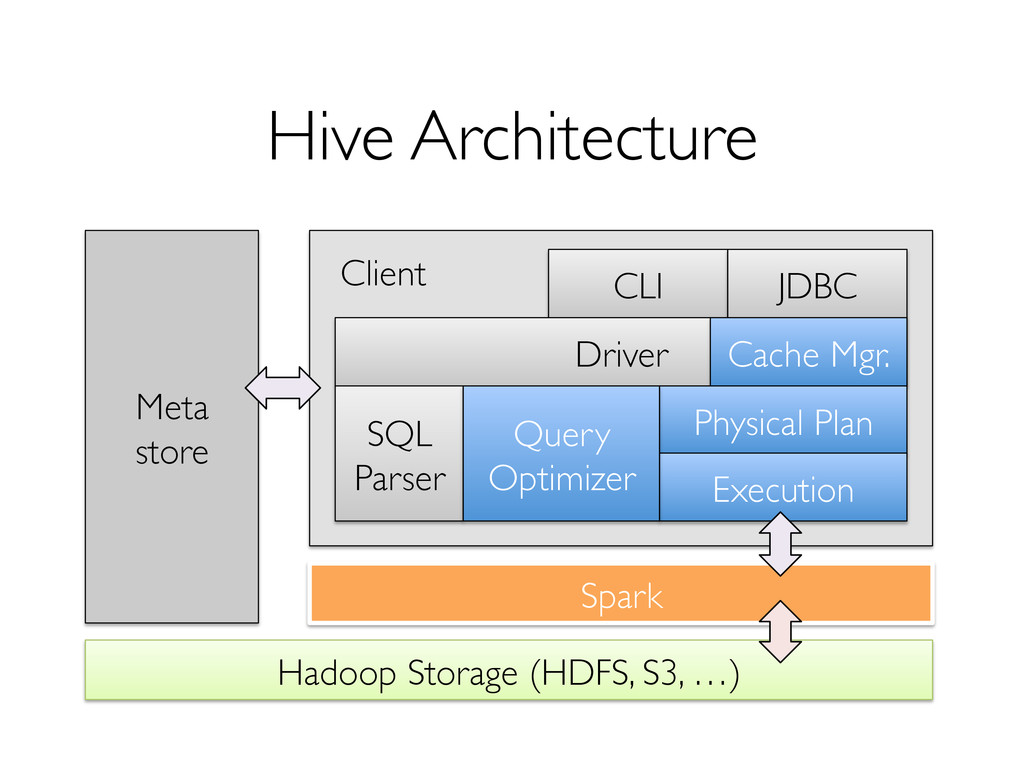
to support SQL efficiently! » Started from a powerful MR-like engine (Spark)! » Extended the engine in various ways! 2. The artifact: Shark, a fast engine on top of MR! » Performant SQL! » Complex analytics in the same engine! » Maintains MR benefits, e.g. fault-tolerance!
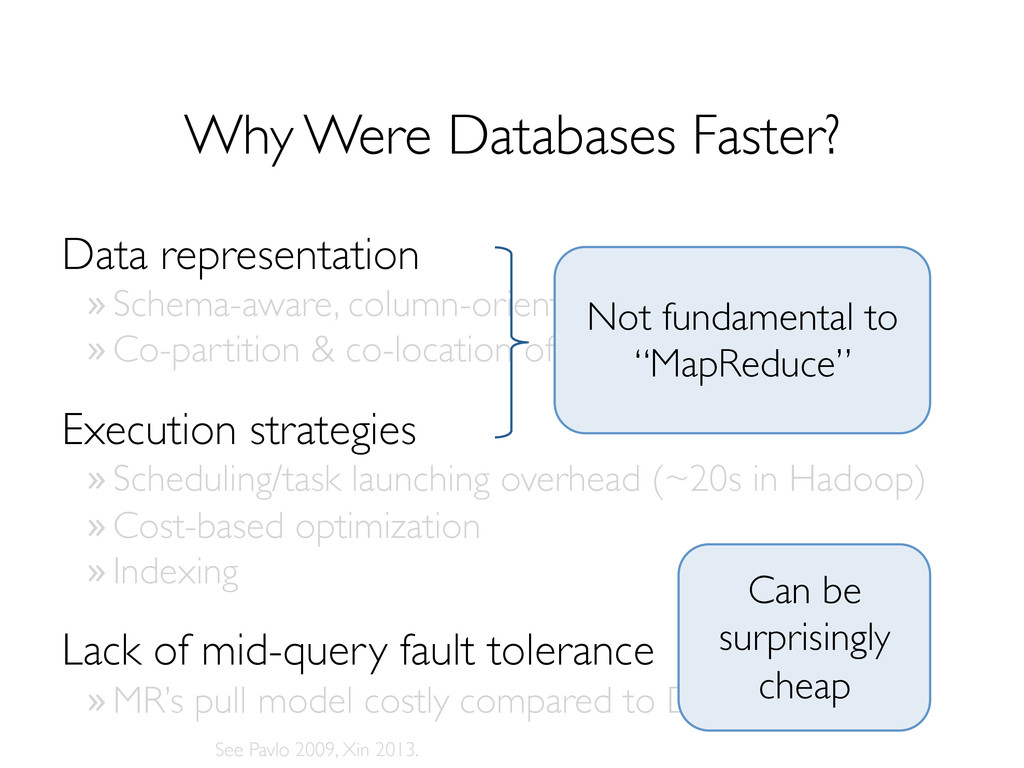
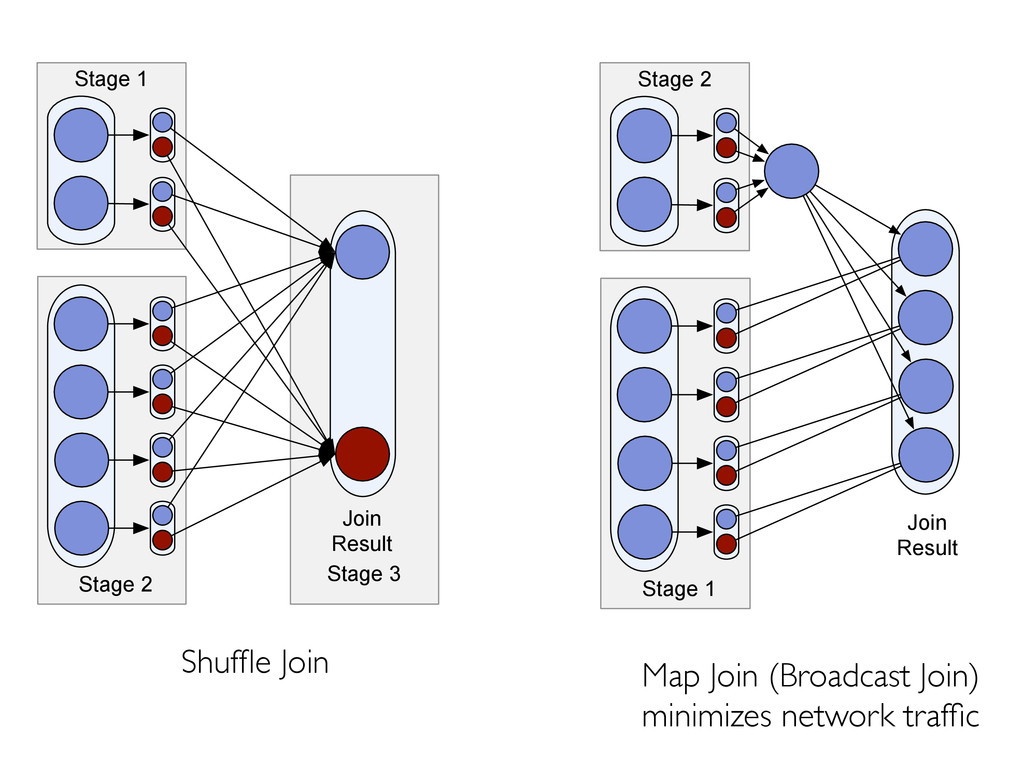
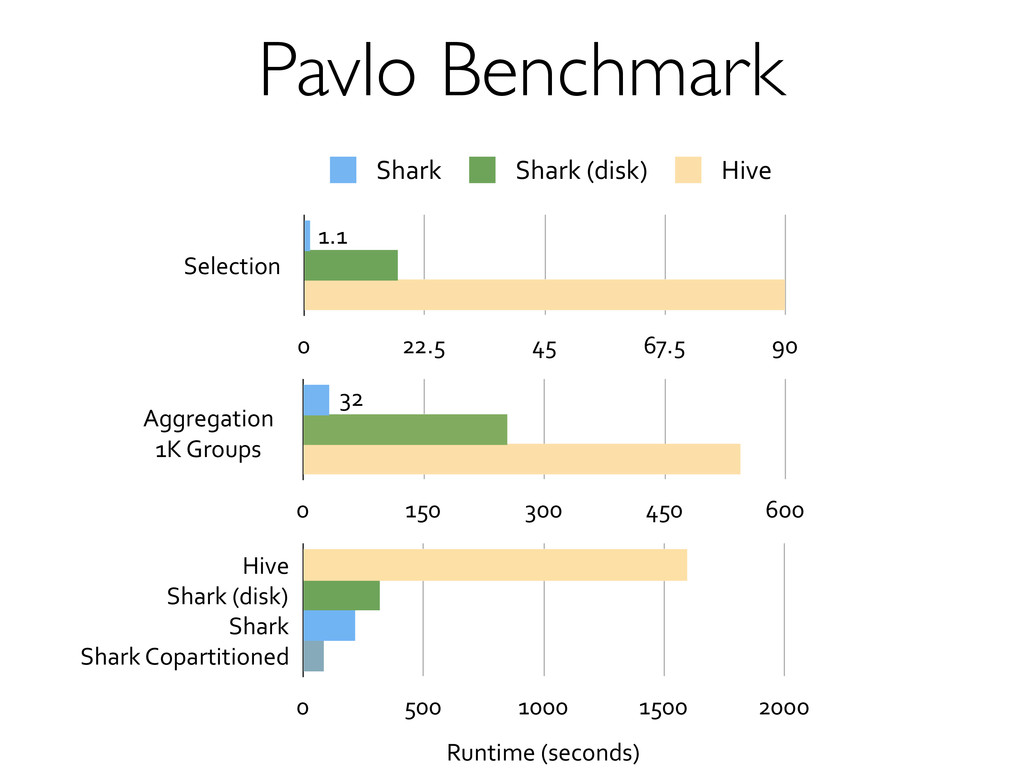
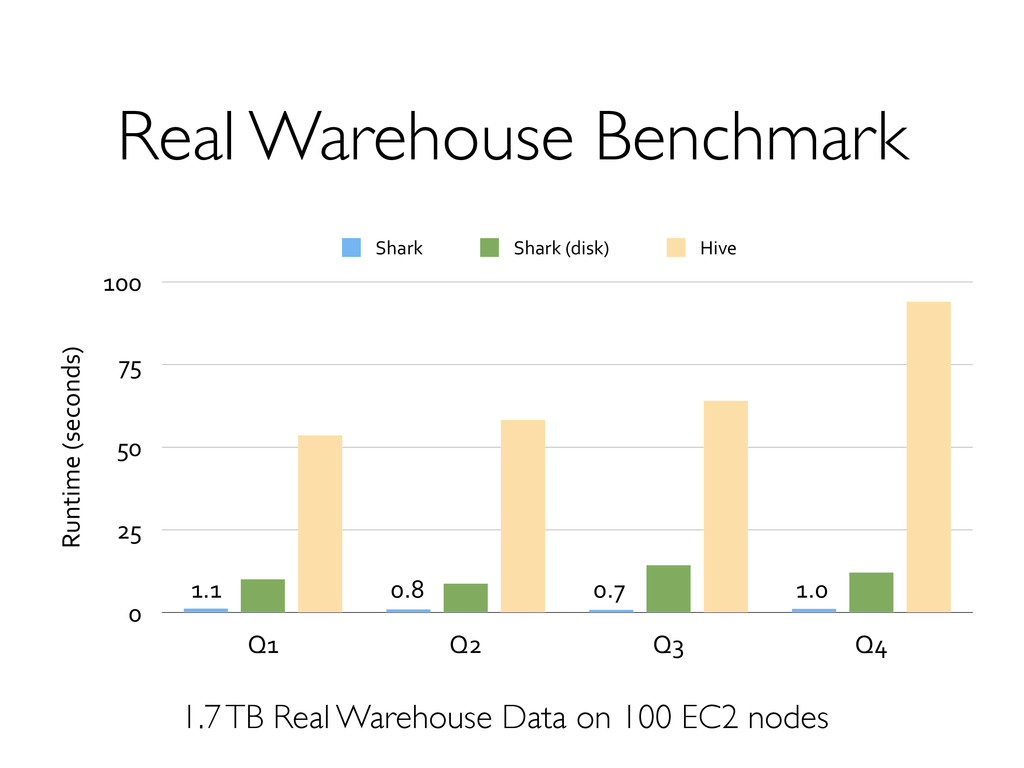
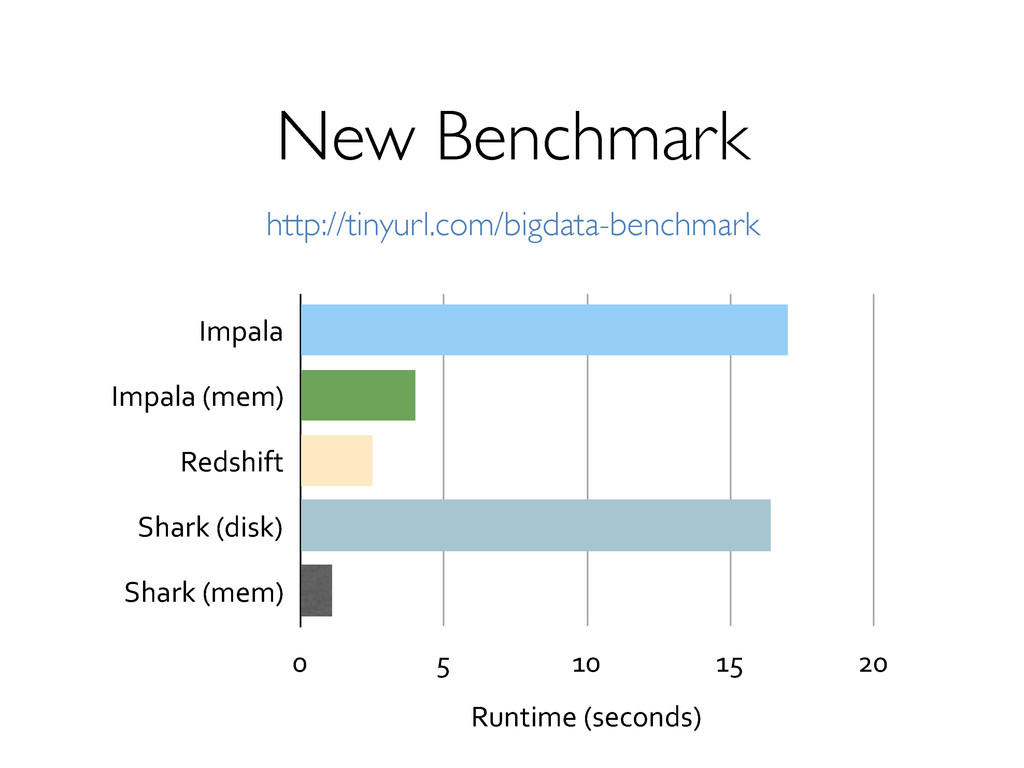
» Co-partition & co-location of data! Execution strategies! » Scheduling/task launching overhead (~20s in Hadoop)! » Cost-based optimization! » Indexing! Lack of mid-query fault tolerance! » MR’s pull model costly compared to DBMS “push”! See Pavlo 2009, Xin 2013.! Not fundamental to “MapReduce”! Can be surprisingly cheap!
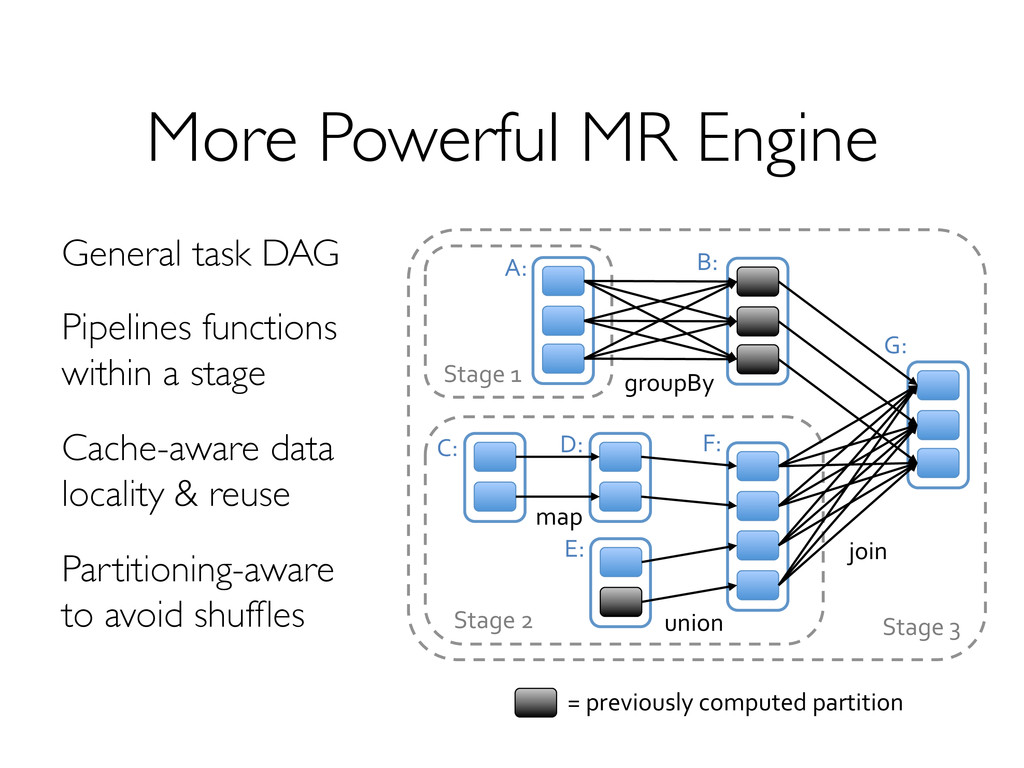
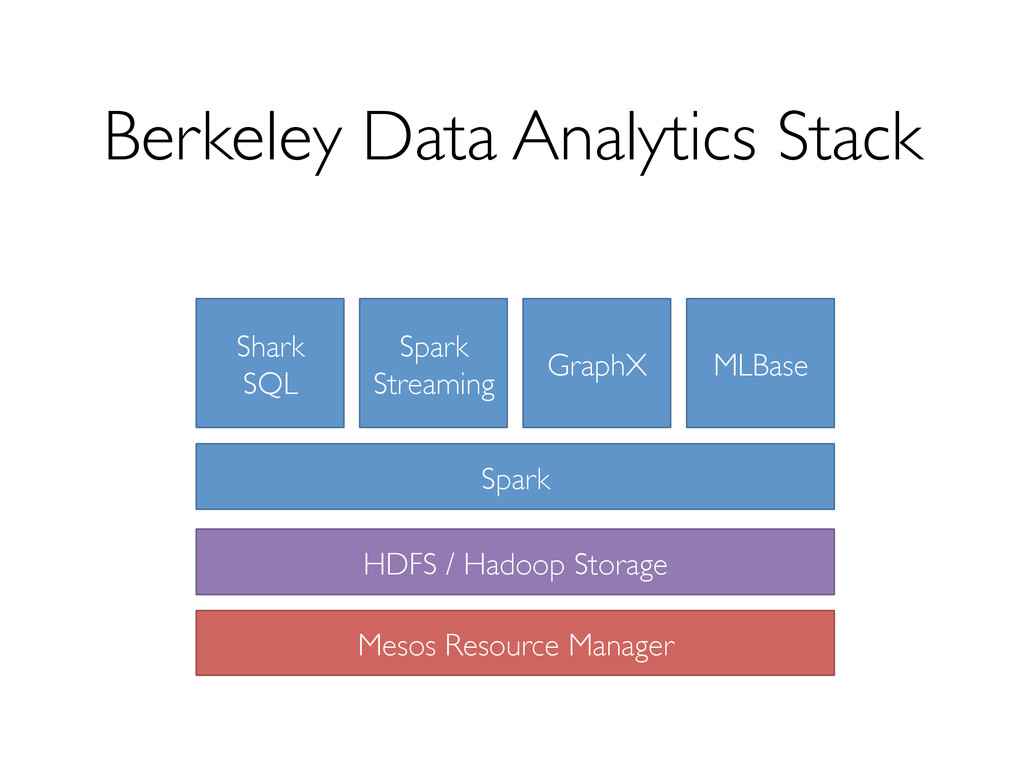
iterative computations! » General execution graphs! » Designed for low latency (~100ms jobs)! Compatible with Hadoop storage APIs! » Read/write to any Hadoop-supported systems, including HDFS, Hbase, SequenceFiles, etc! Growing open source platform! » 17 companies contributing code!
data and the prevalent use of UDFs necessitate dynamic approaches to query optimization.! ! PDE allows dynamic alternation of query plans based on statistics collected at run-time.!
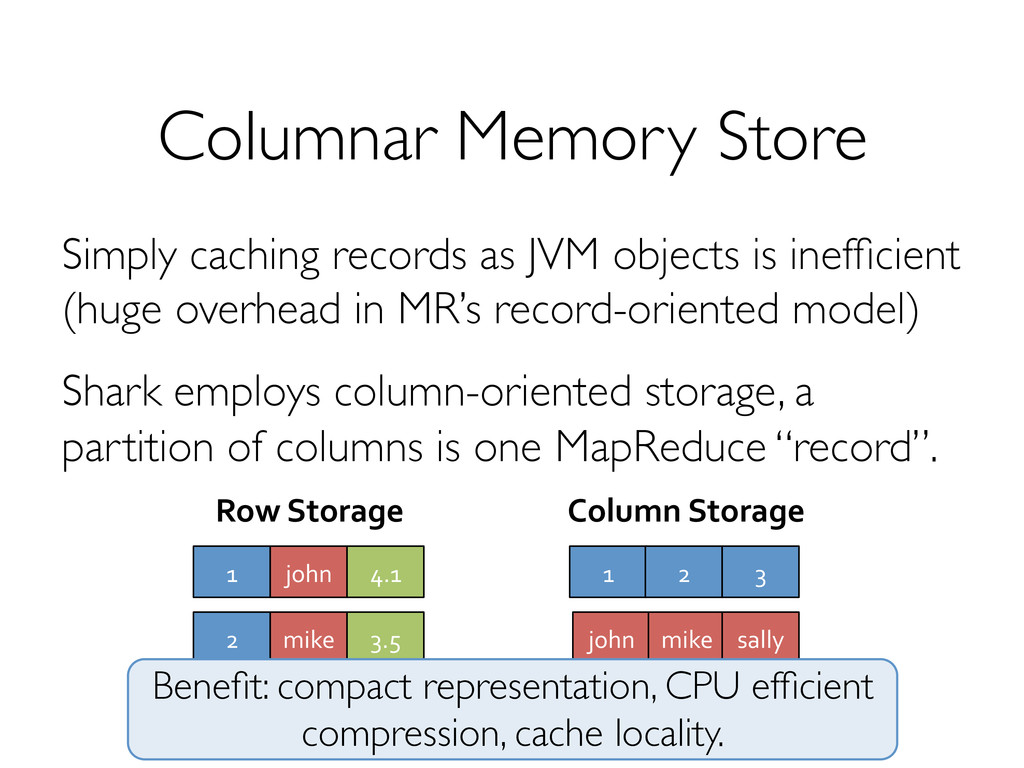
materializing map output.! » partition sizes, record counts (skew detection)! » “heavy hitters”! » approximate histograms! Can alter query plan based on such statistics! » map join vs shuffle join! » symmetric vs non-symmetric hash join! » skew handling!
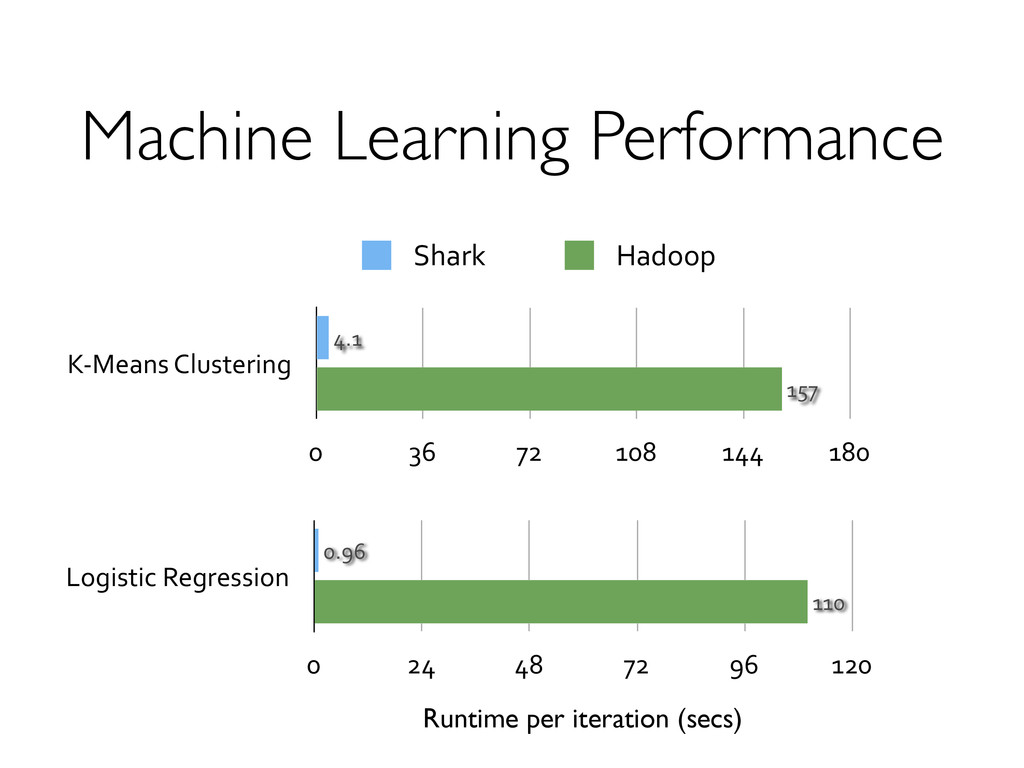
! Both share the same set of workers and caches! def logRegress(points: RDD[Point]): Vector { var w = Vector(D, _ => 2 * rand.nextDouble - 1) for (i <- 1 to ITERATIONS) { val gradient = points.map { p => val denom = 1 + exp(-p.y * (w dot p.x)) (1 / denom - 1) * p.y * p.x }.reduce(_ + _) w -= gradient } w } val users = sql2rdd("SELECT * FROM user u JOIN comment c ON c.uid=u.uid") val features = users.mapRows { row => new Vector(extractFeature1(row.getInt("age")), extractFeature2(row.getStr("country")), ...)} val trainedVector = logRegress(features.cache())
databases, Shark supports both SQL and complex analytics efficiently, while maintaining fault-tolerance.! Growing open source community! » Users observe similar speedups in real use cases! » http://shark.cs.berkeley.edu! » http://www.spark-project.org! !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}