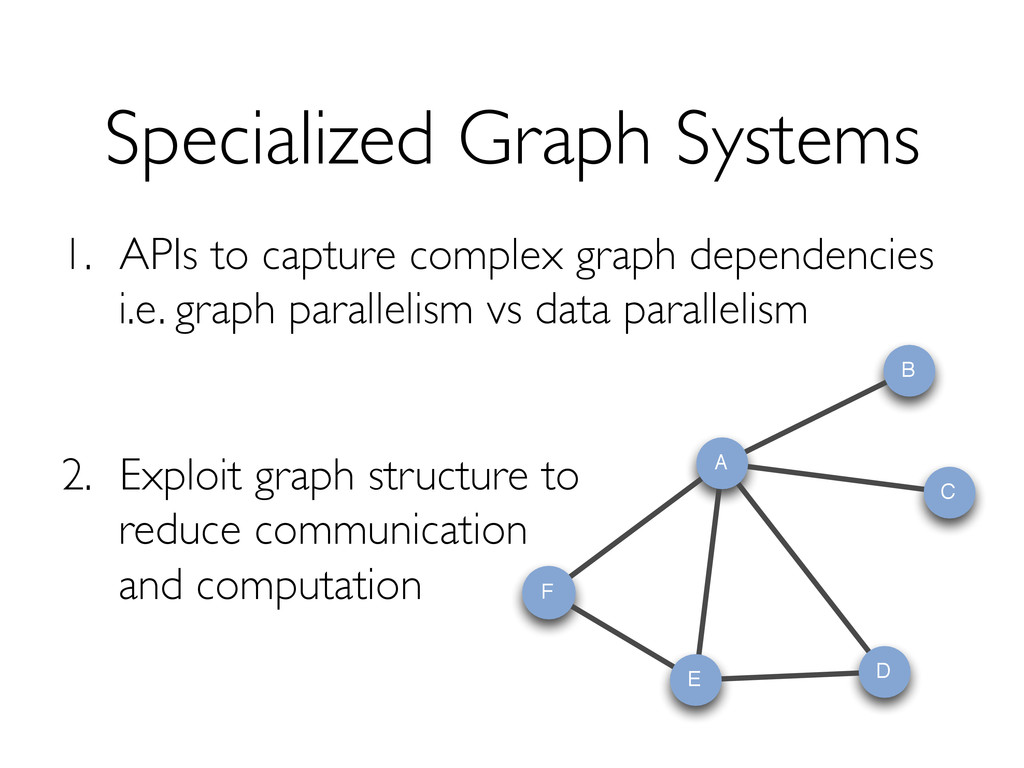
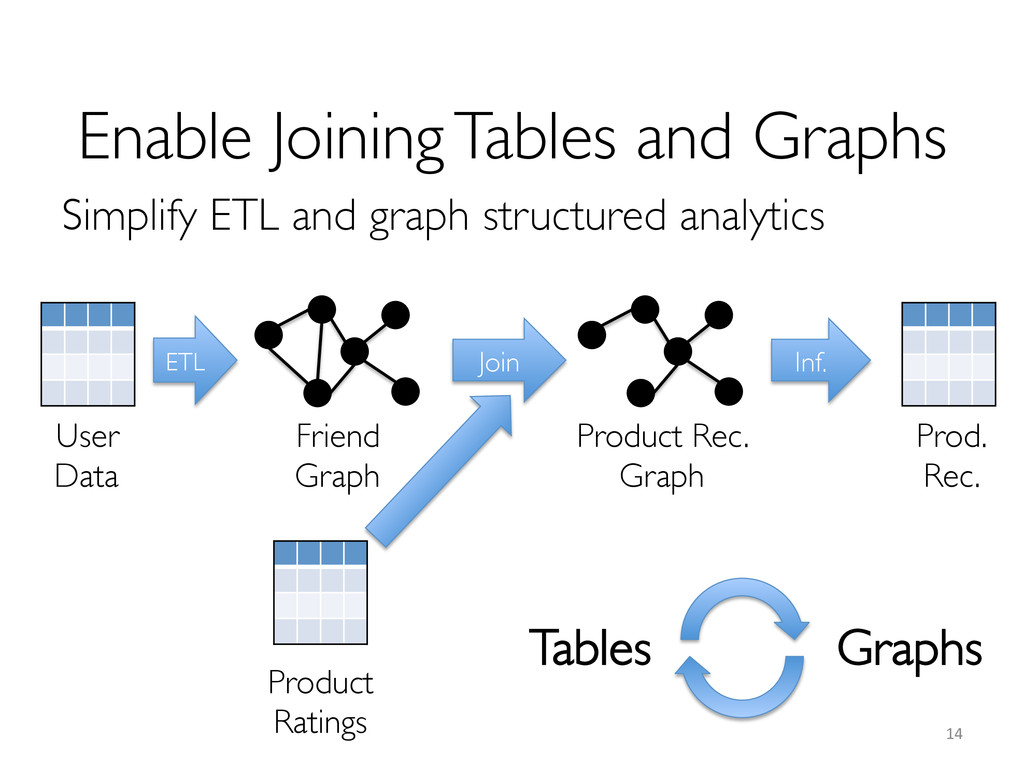
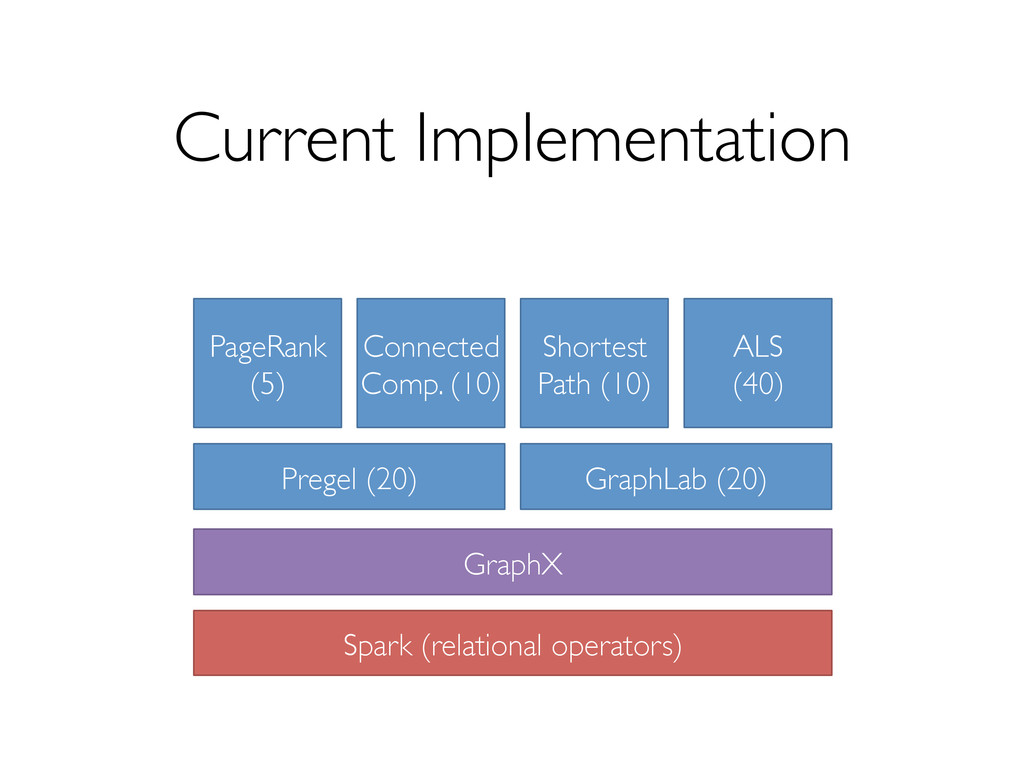
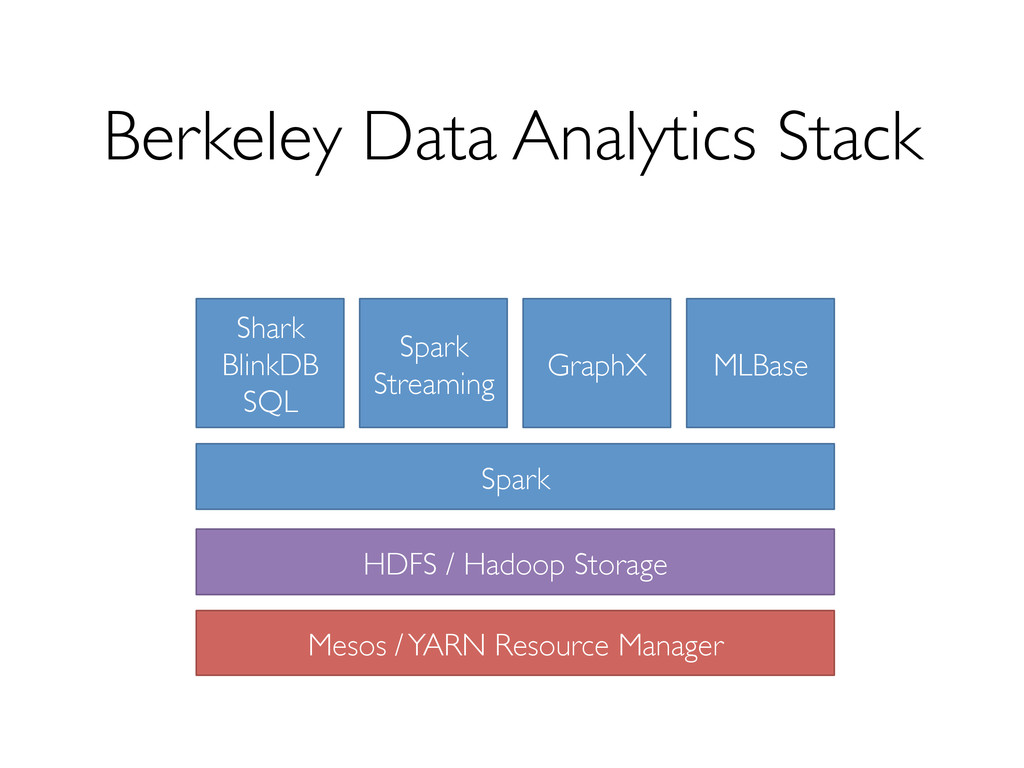
Leverage data-parallel engines for task scheduling, distribution and dispatch Reuse existing engines for ETL and consumption of graph computation output
data-parallel engines » Relational databases (with UDFs and UDAFs) » MapReduce-like frameworks, e.g. Hadoop, Spark Leveraging advanced properties and engine extensions to make these primitives fast » An optimizer for choosing execution strategies » Controlled data partitioning » New index-based access methods and operators
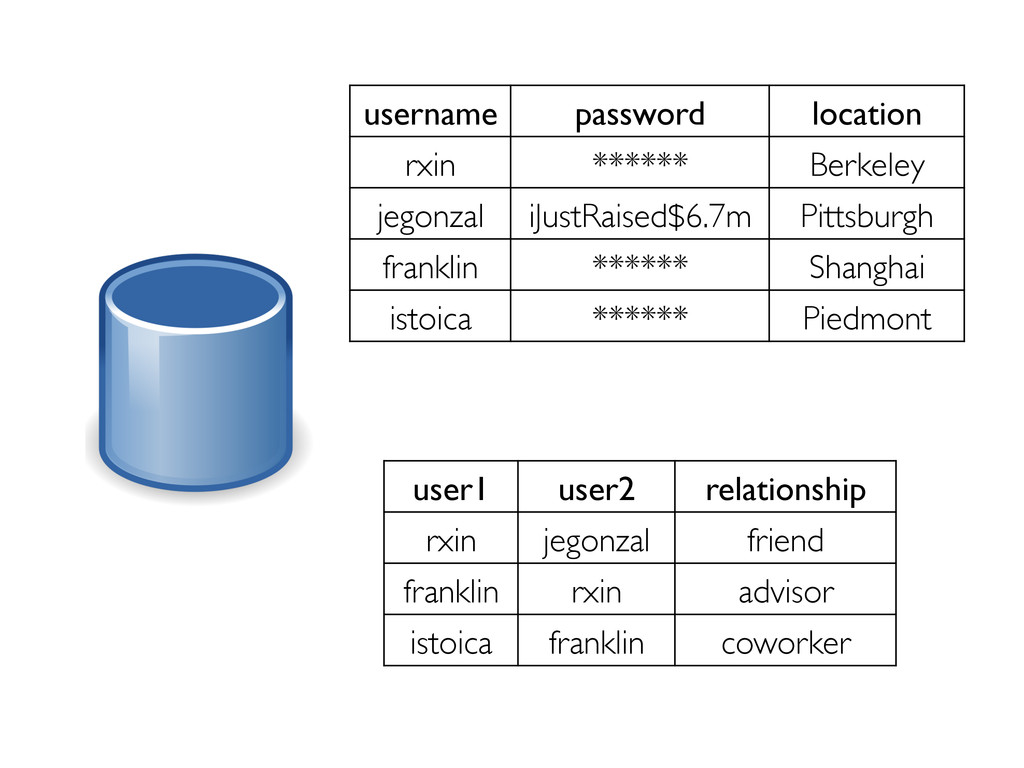
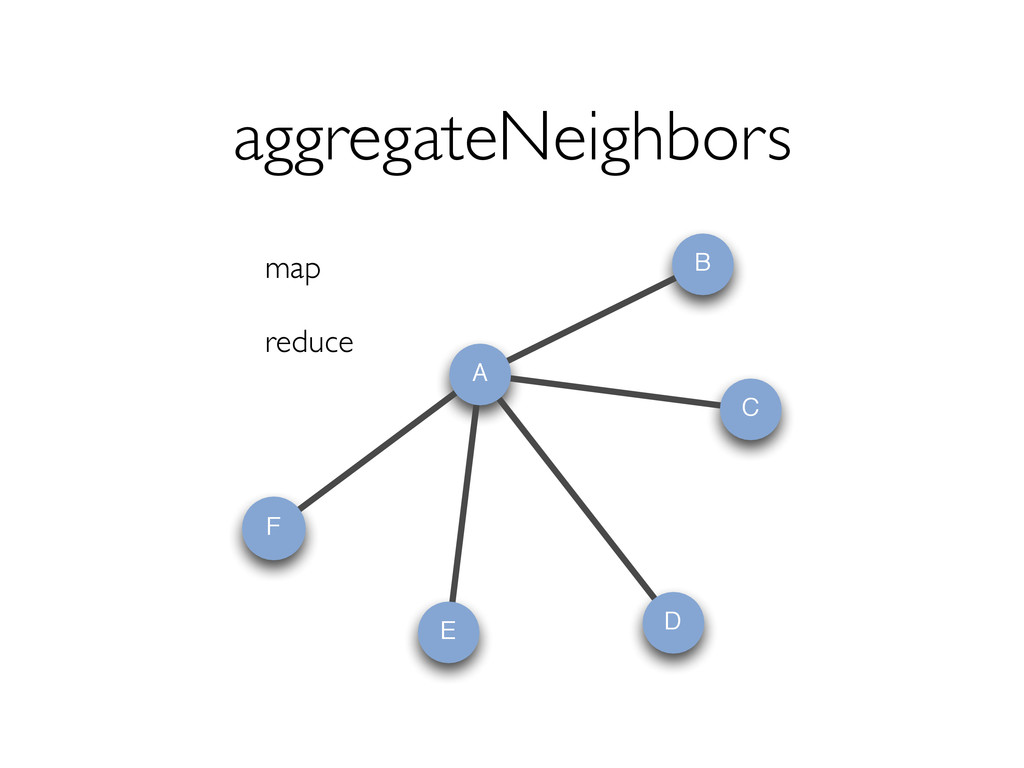
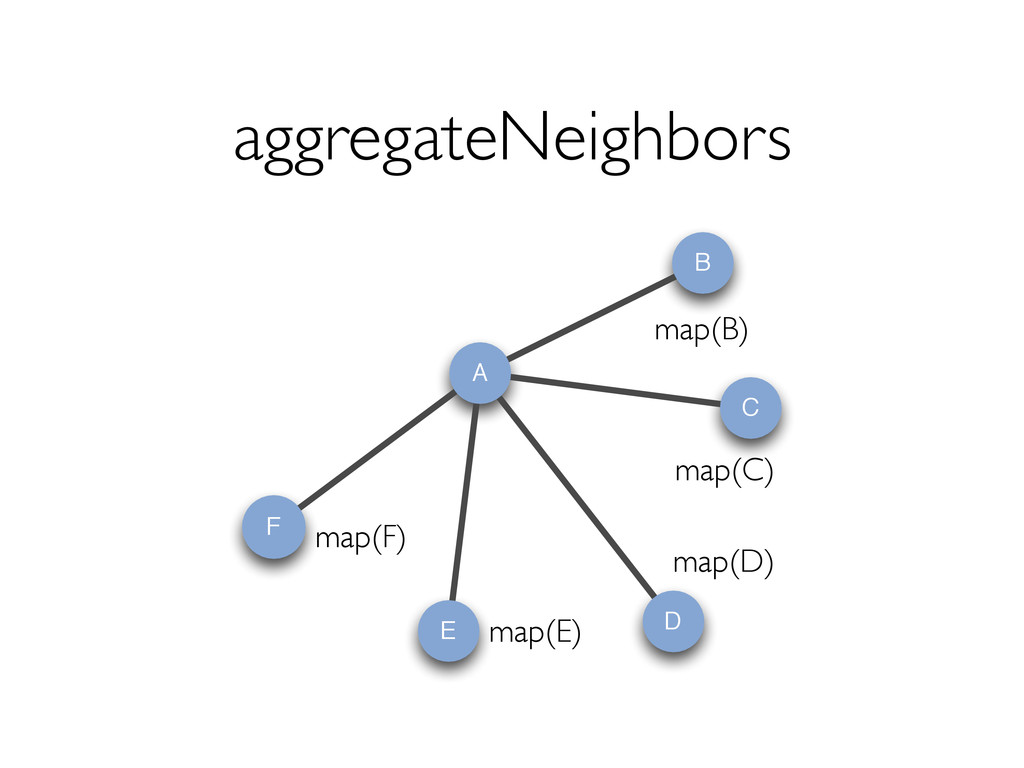
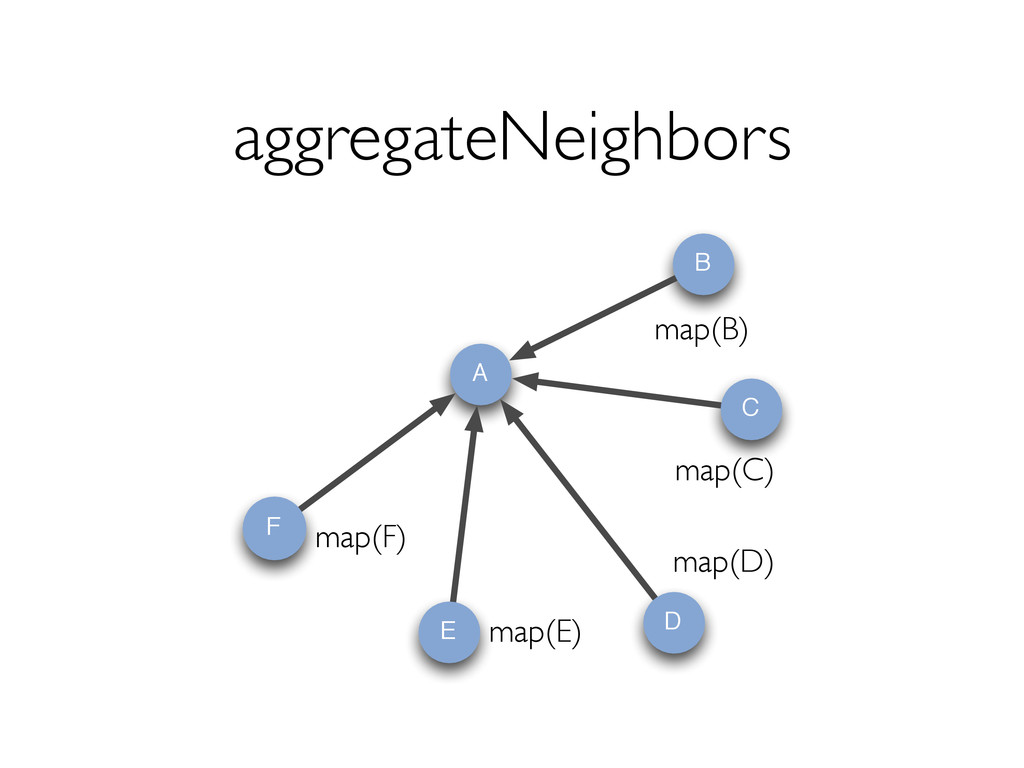
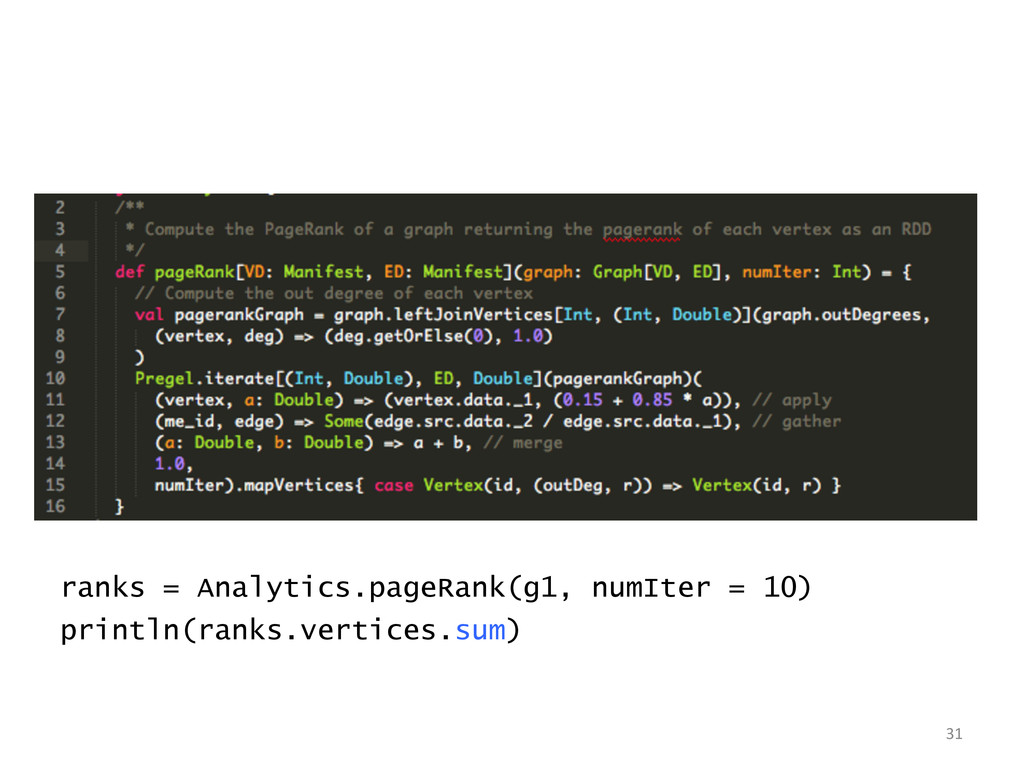
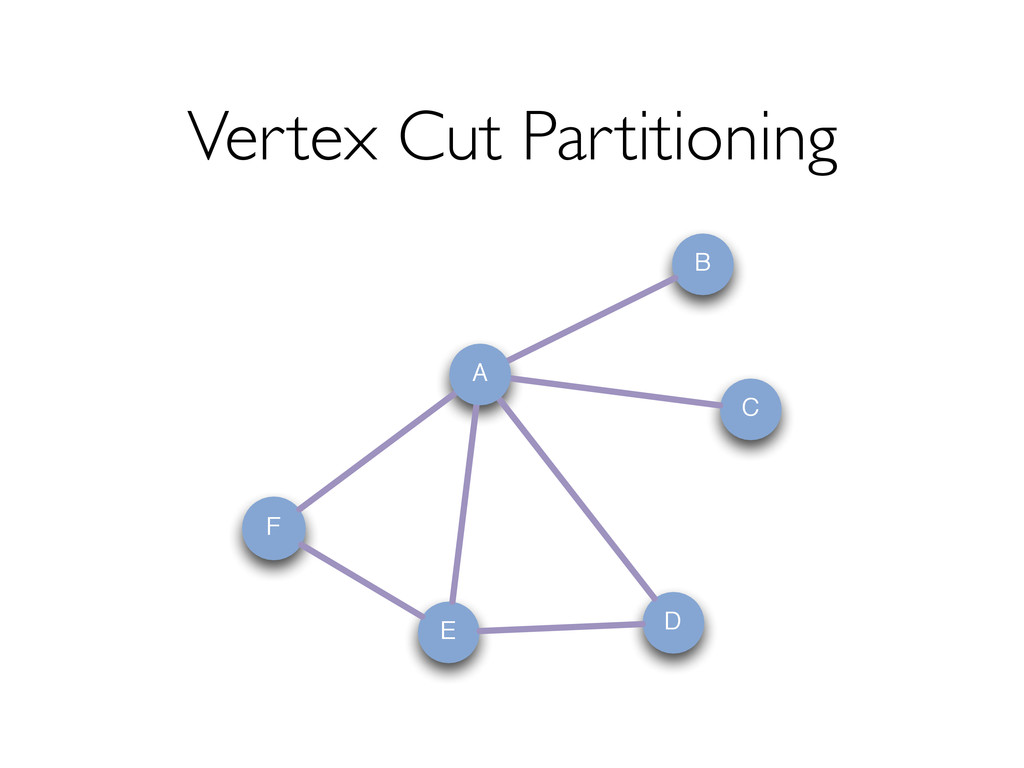
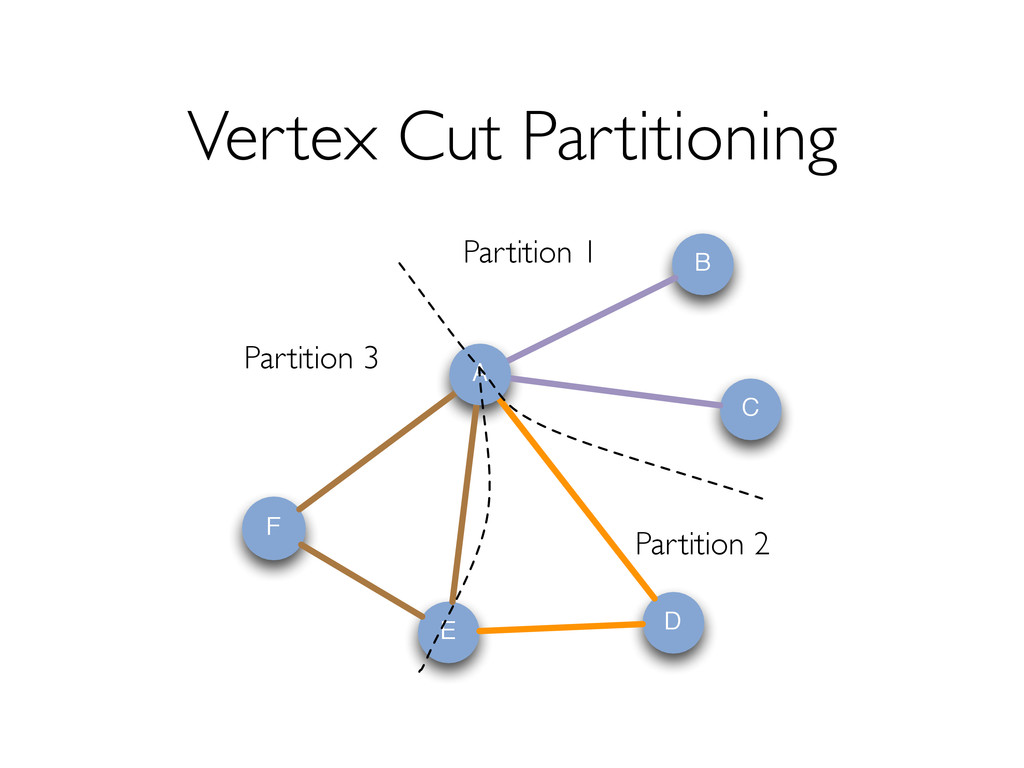
style vertex-cut partitioning » Minimize communication by avoiding edge data movement in JOINs In-memory hash index for vertices for fast joins Optimizer for choosing execution strategies » E.g. if mapUdf does not need edge data, we can rewrite the query to delay the join
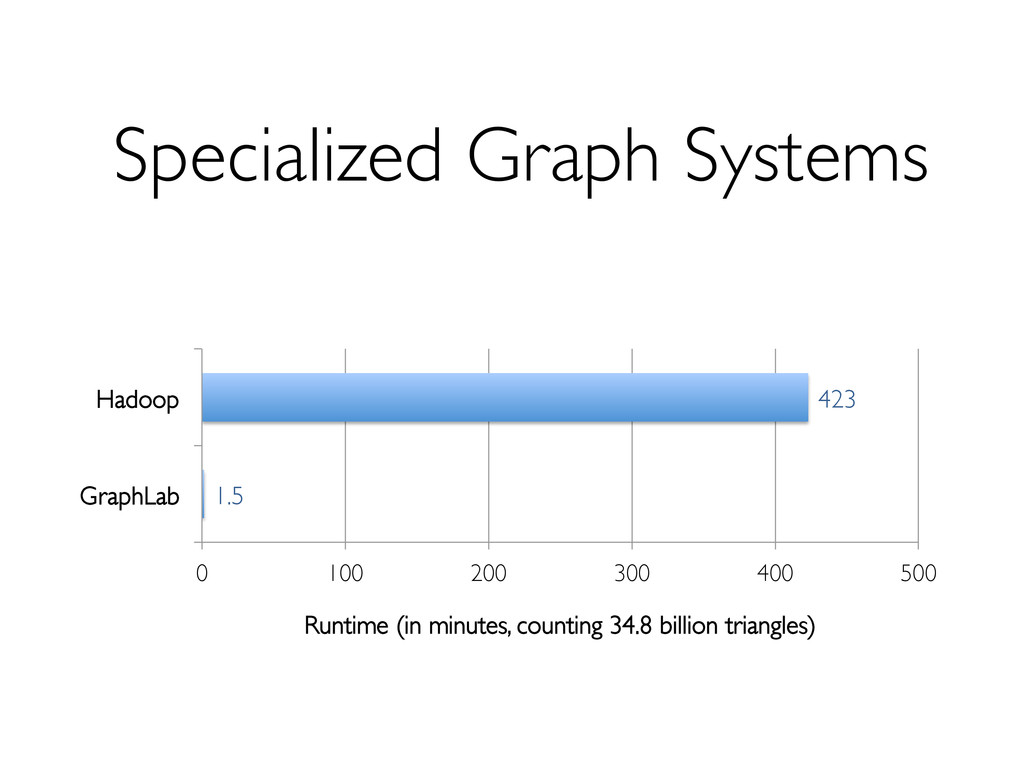
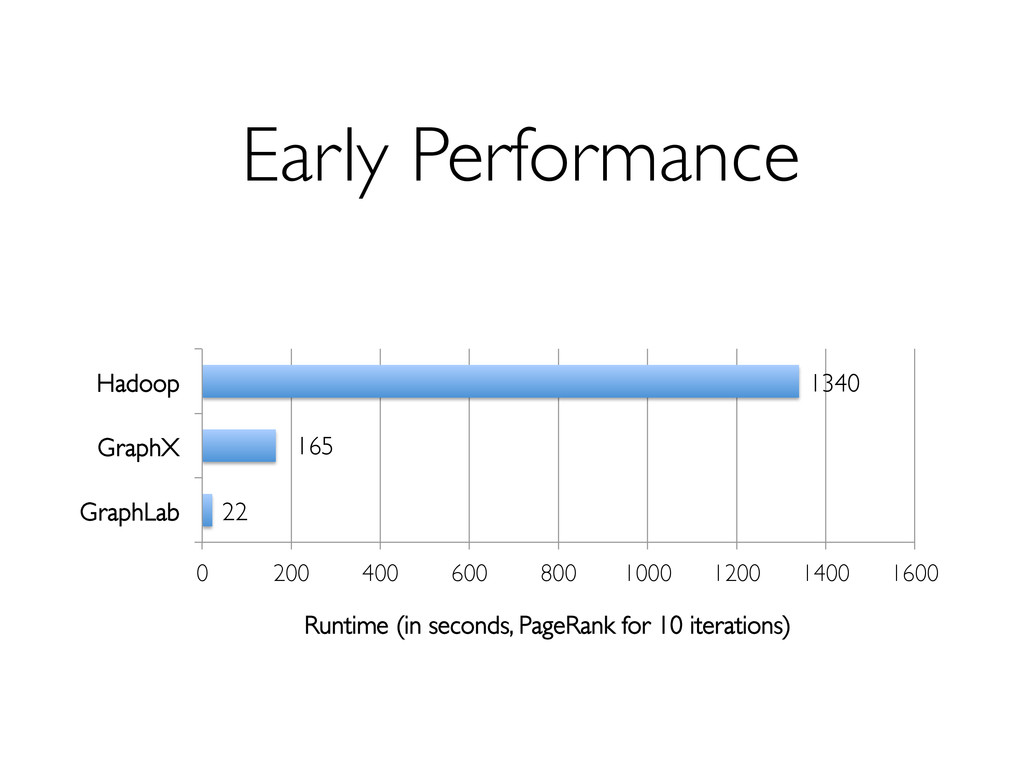
2. Currently slower than GraphLab, but » No need for specialized systems » Easier ETL, and easier consumption of output » Interactive graph data mining 3. Future work will bring performance closer to specialized engines.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}