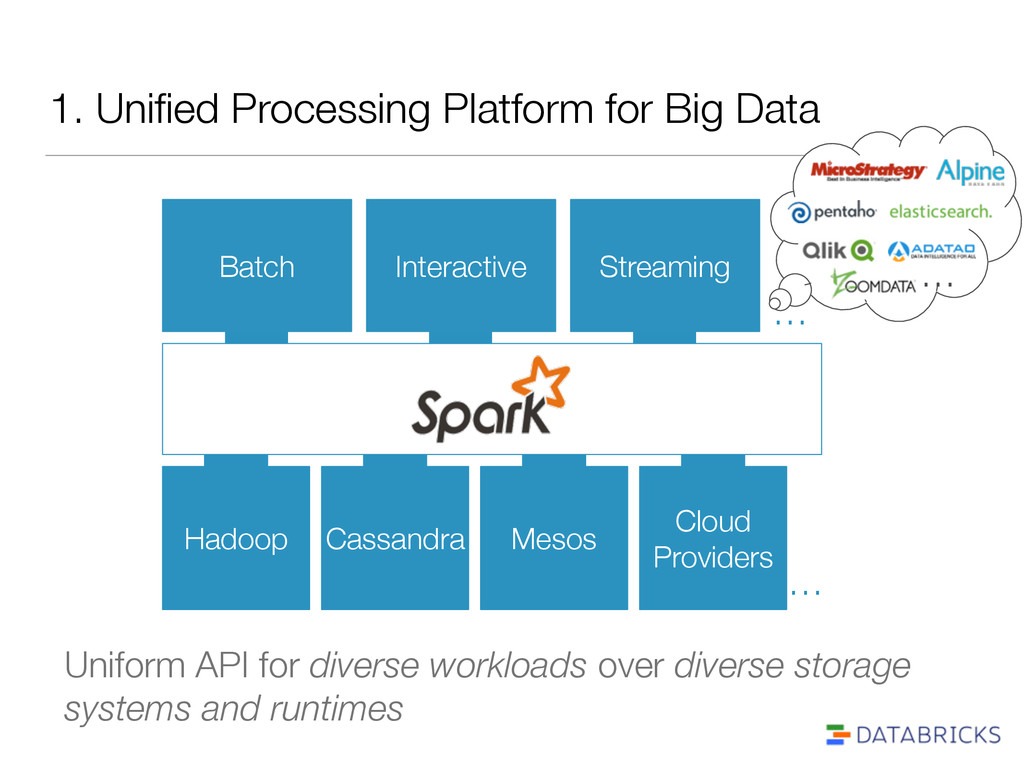
libraries of common algorithms ! Spark’s generality + support for multiple languages make it suitable to offer this Core SQL ML graph … Python Scala Java
algorithm, params, and model • multi-model training • multiclass support for classification tree • Java/Python APIs for decision trees • SVD via Lanczos • standardized text format for training data new • statistics: stratified sampling, linear/ rank correlation, hypothesis testing • non-negative matrix factorization (NMF) • preprocessing: tf-idf • evaluation: multiclass metrics • online model updates with streaming • and your contribution!
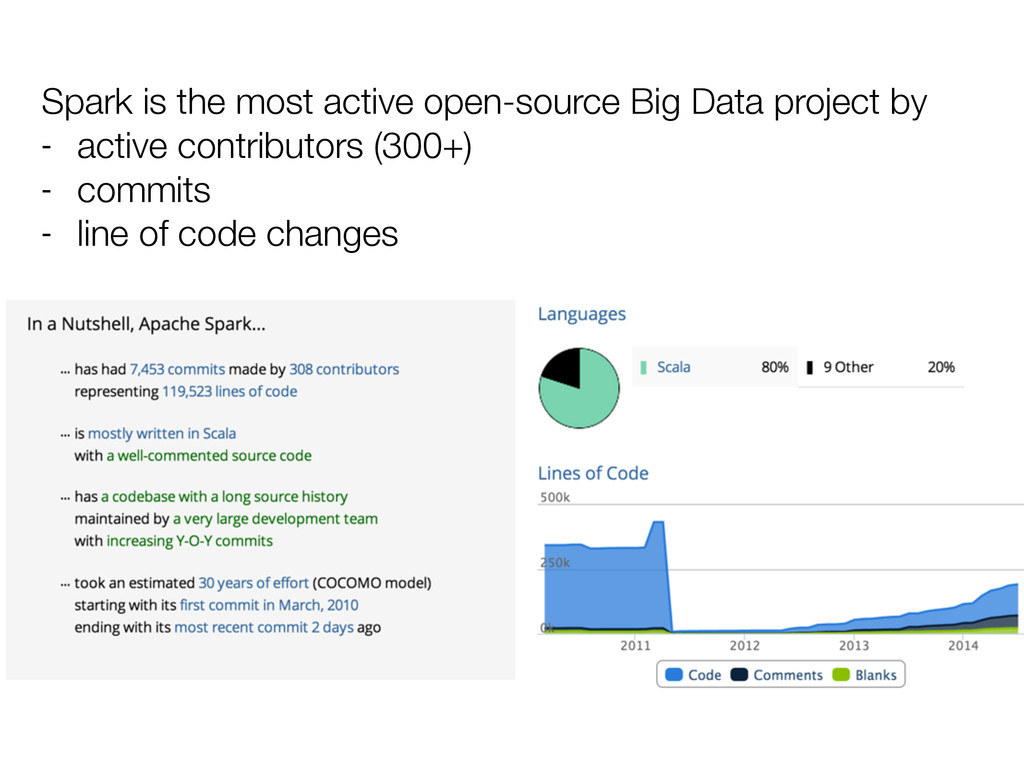
1000+ nodes Data size: processes data many times size of memory - petabyte sort on lots of machines - or handle tons of data on a few machines (sorting 5TB compressed/node; file system breaking before Spark did)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![And or course, we are hiring ! [email protected]](https://files.speakerdeck.com/presentations/cc11738006440132098a4ec2e24a2701/slide_21.jpg){kind=link}