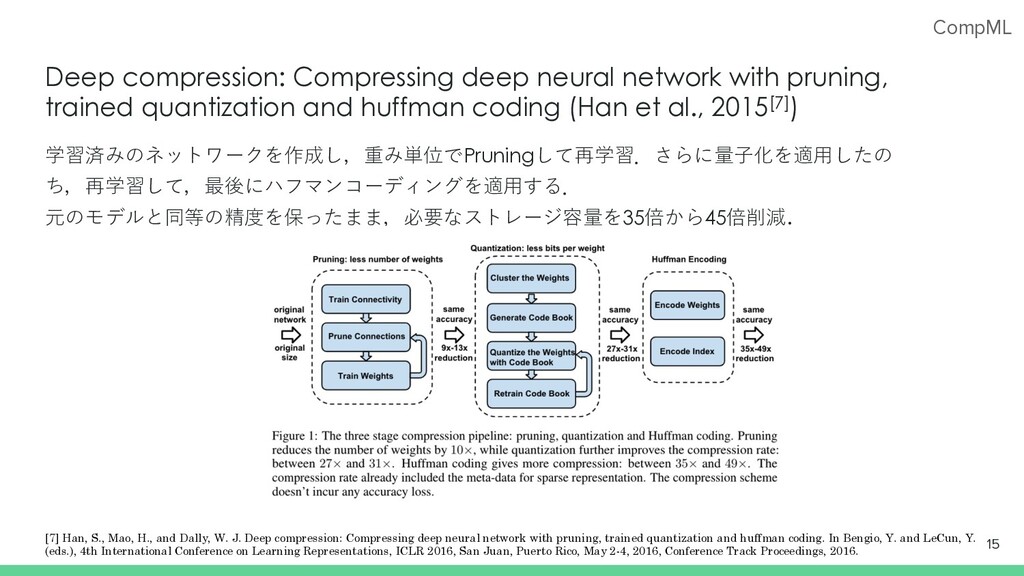
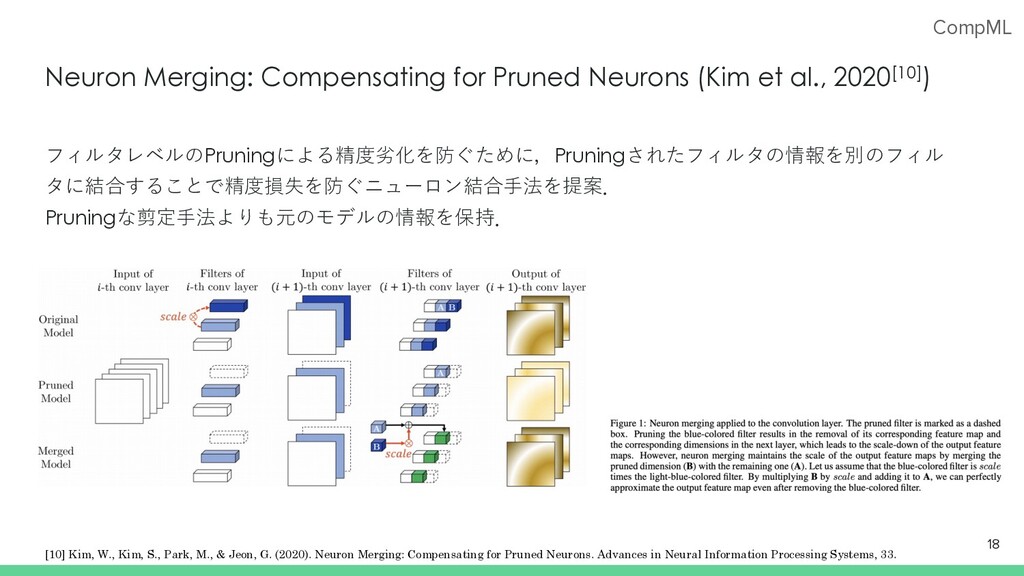
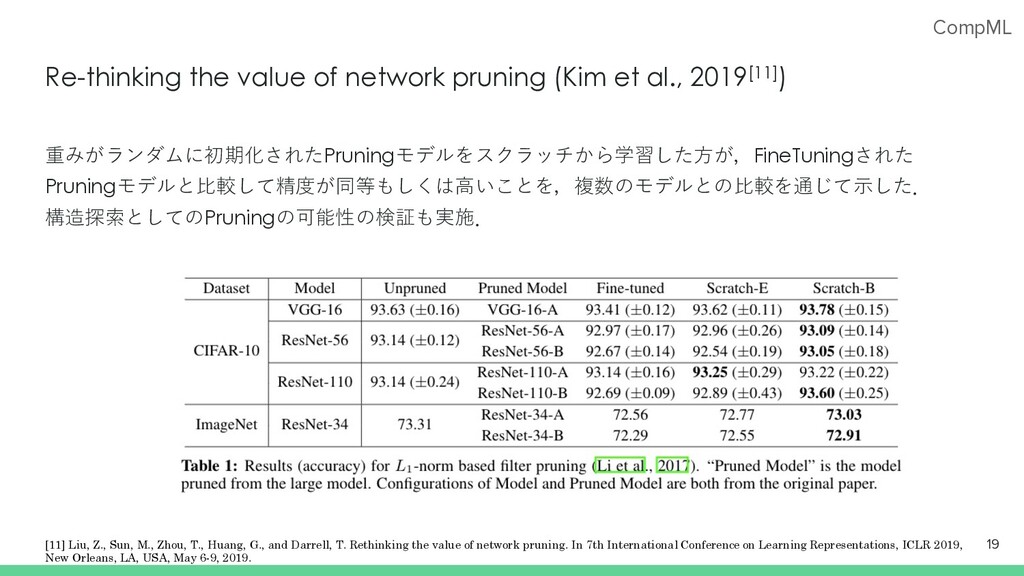
G., and Darrell, T. Rethinking the value of network pruning. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. [7] Han, S., Mao, H., and Dally, W. J. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. In Bengio, Y. and LeCun, Y. (eds.), 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016. [8] Li, H., Kadav, A., Durdanovic, I., Samet, H., and Graf, H. P. Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710, 2016. [9] He, Y., Zhang, X., and Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1389–1397, 2017. [10] Kim, W., Kim, S., Park, M., & Jeon, G. (2020). Neuron Merging: Compensating for Pruned Neurons. Advances in Neural Information Processing Systems, 33.
{kind=link}
{kind=link}
{kind=link}
![CompML Pruningとは Pruning(剪定,枝刈り)とは,ネットワークの重みの⼀部を0にすることで,パラメータ 数や計算量を削減する⼿法. 3 Han et al., 2015[1]](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_3.jpg){kind=link}
![CompML Pruningの研究の盛り上がり Pruningに関する論⽂数は年々増加. 4 Mirkes, E. M[3] Number of published](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_4.jpg){kind=link}
![CompML Pruningの⼿法 多くのNeural NetworkのPruning⼿法は,Han et al., 2015[1] の⼿法に由来している. 5 Han](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
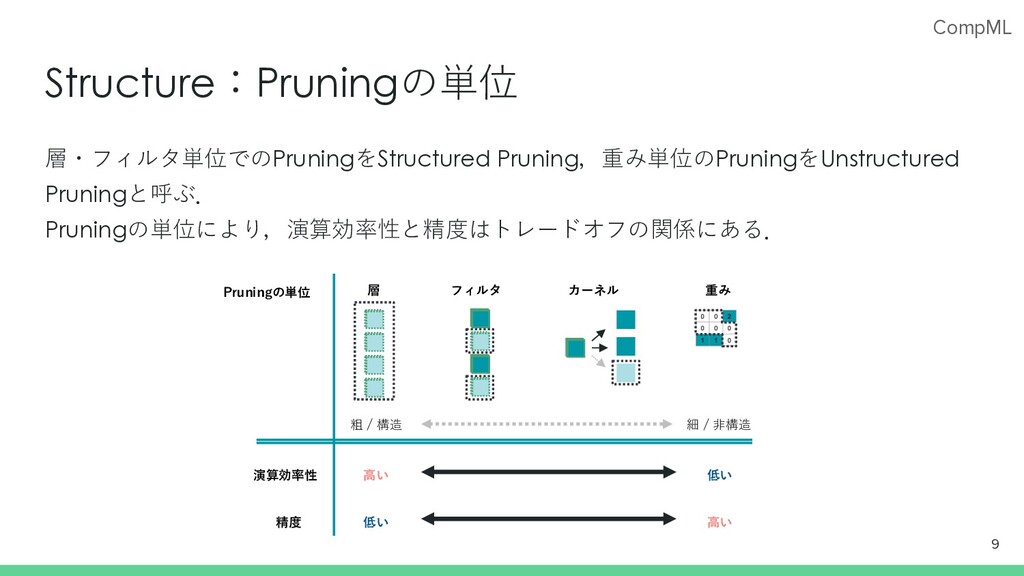
![CompML Pruningの⼿法の違いポイント 多くのPruning⼿法が提案されているが,主な違いのポイントは以下の4点.(Blalock et al,. 2020)[2] 8 • Structure :どの単位でPruningするか](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![CompML Fine-Tuning:再学習⽅法 Pruning前の学習済みの重みを使⽤して,ネットワークを再学習することが多い. 12 • ネットワークを学習前の値で再初期化(Frankle et al,. 2019[5]) •](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![CompML Pruning filters for efficient convnets (Li et al., 2016[8])](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CompML Pruningの評価 結局どの⼿法が良いのか? ⇨ 多くのPruning⼿法が提案されているが,評価⽅法がバラバラで横⽐較ができない. (Blalock et al,. 2020 [2]](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_25.jpg){kind=link}
{kind=link}
![CompML Pruningの効果 Blalock et al,. 2020[2]のメタ研究 27 • 精度が少しだけ下がる,下がらない⼿法も多くある. •](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![CompML 31 [1] Han, S., Pool, J., Tran, J., and](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_31.jpg){kind=link}
![CompML 32 [6] Liu, Z., Sun, M., Zhou, T., Huang,](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_32.jpg){kind=link}
![CompML 33 [11] Liu, Z., Sun, M., Zhou, T., Huang,](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_33.jpg){kind=link}
![CompML 34 [16] Gale, T., Elsen, E., and Hooker, S.](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_34.jpg){kind=link}
![CompML 35 [21] Wang, Z. (2020, September). SparseRT: Accelerating Unstructured](https://files.speakerdeck.com/presentations/ca9ba55615524ed0b98d4211a29b2c75/slide_35.jpg){kind=link}