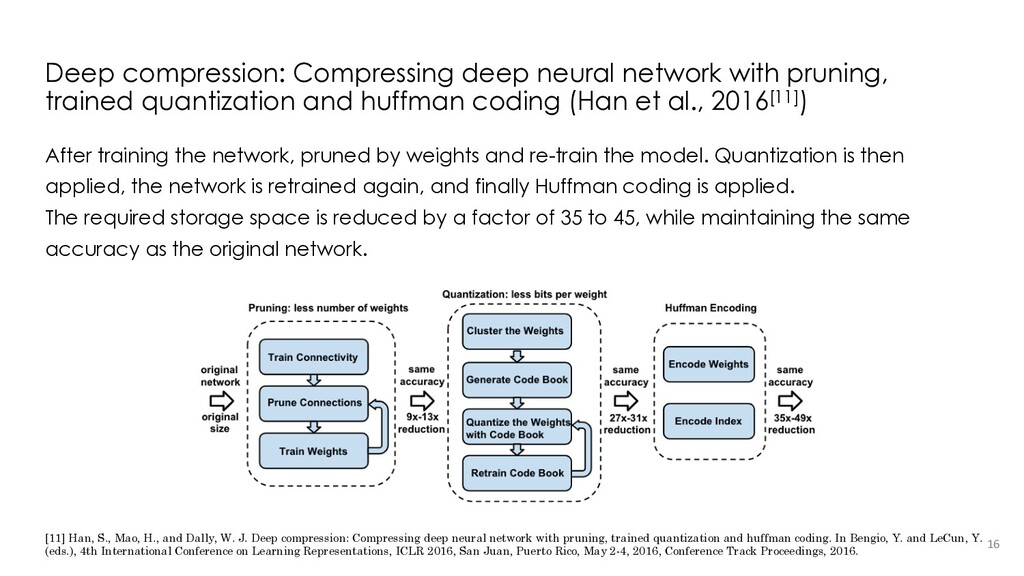
Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. In Bengio, Y. and LeCun, Y. (eds.), 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016. [12] Gray, S., Radford, A., & Kingma, D. P. (2017). Gpu kernels for block-sparse weights. arXiv preprint arXiv:1711.09224, 3. [13] Elsen, E., Dukhan, M., Gale, T., & Simonyan, K. (2020). Fast sparse convnets. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 14629-14638). [14] Gray, S., Radford, A., & Kingma, D. P. (2017). Gpu kernels for block-sparse weights. arXiv preprint arXiv:1711.09224, 3. [15] Wang, Z. (2020, September). SparseRT: Accelerating Unstructured Sparsity on GPUs for Deep Learning Inference. In Proceedings of the ACM International Conference on Parallel Architectures and Compilation Techniques (pp. 31-42).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fine-Tuning Which weight to use when Fine-Tuning. 12 [6] Liu,](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
![Unstructured Pruning Irregular pruning method in weight units. 15 [7]](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pruning filters for efficient convnets (Li et al., 2016[16]) Per-filter](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_19.jpg){kind=link}
![Neuron Merging: Compensating for Pruned Neurons (Kim et al., 2020[17])](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_20.jpg){kind=link}
{kind=link}
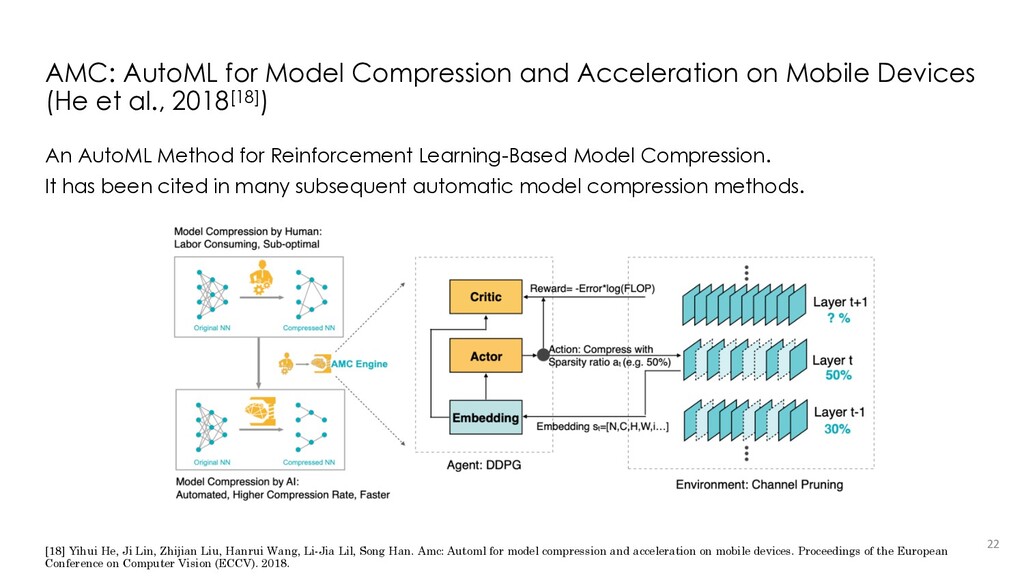{kind=link}
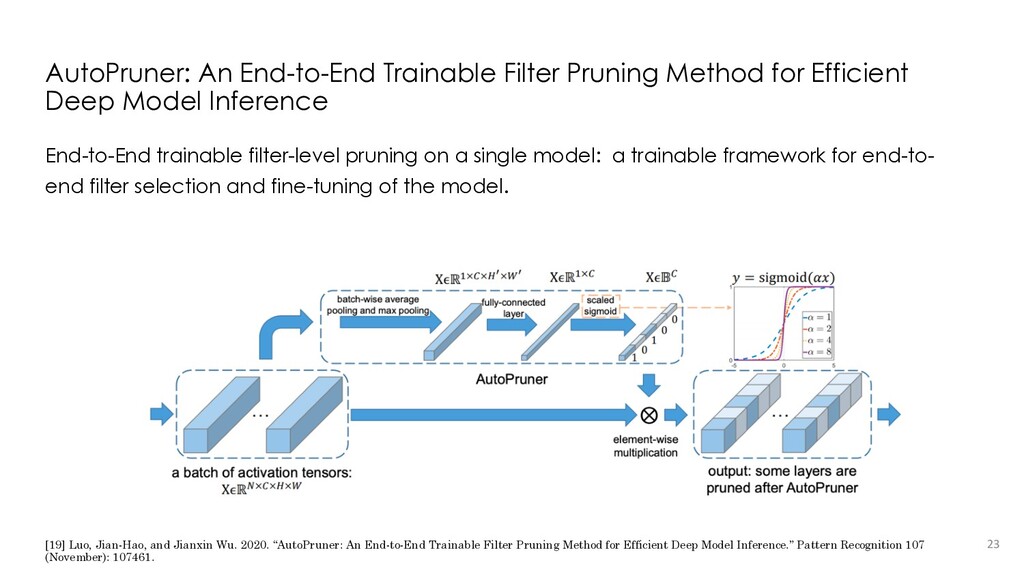{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Re-thinking the value of network pruning (Kim et al., 2019[6])](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![36 [1] Han, S., Pool, J., Tran, J., and Dally,](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_36.jpg){kind=link}
![37 [6] Liu, Z., Sun, M., Zhou, T., Huang, G.,](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_37.jpg){kind=link}
![38 [11] Han, S., Mao, H., and Dally, W. J.](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_38.jpg){kind=link}
![39 [16] Li, H., Kadav, A., Durdanovic, I., Samet, H.,](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_39.jpg){kind=link}
![40 [21] Li, Bingbing, et al. "Efficient Transformer-based Large Scale](https://files.speakerdeck.com/presentations/61ff36cf26e34ad99c570c9267ee0400/slide_40.jpg){kind=link}