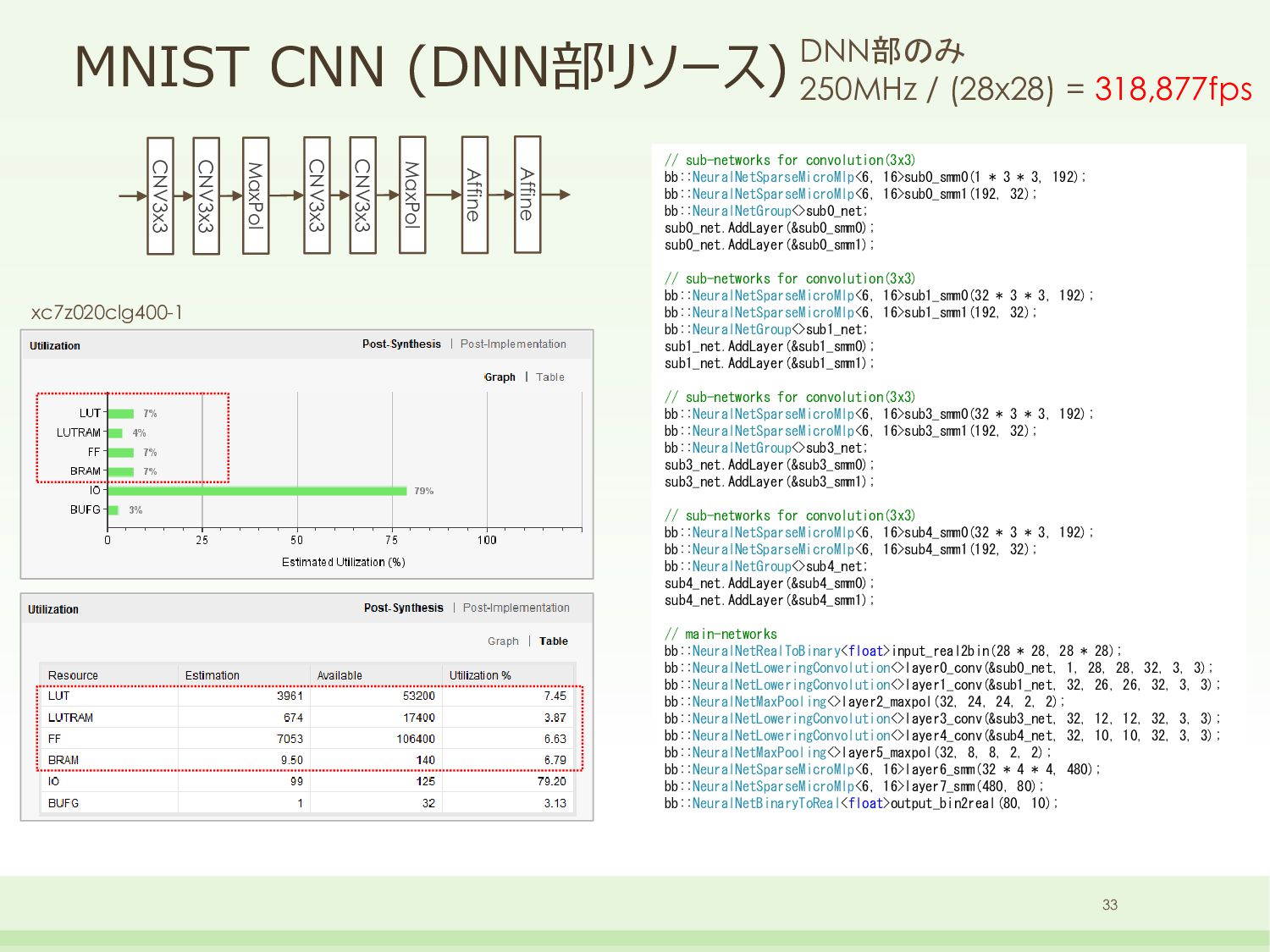
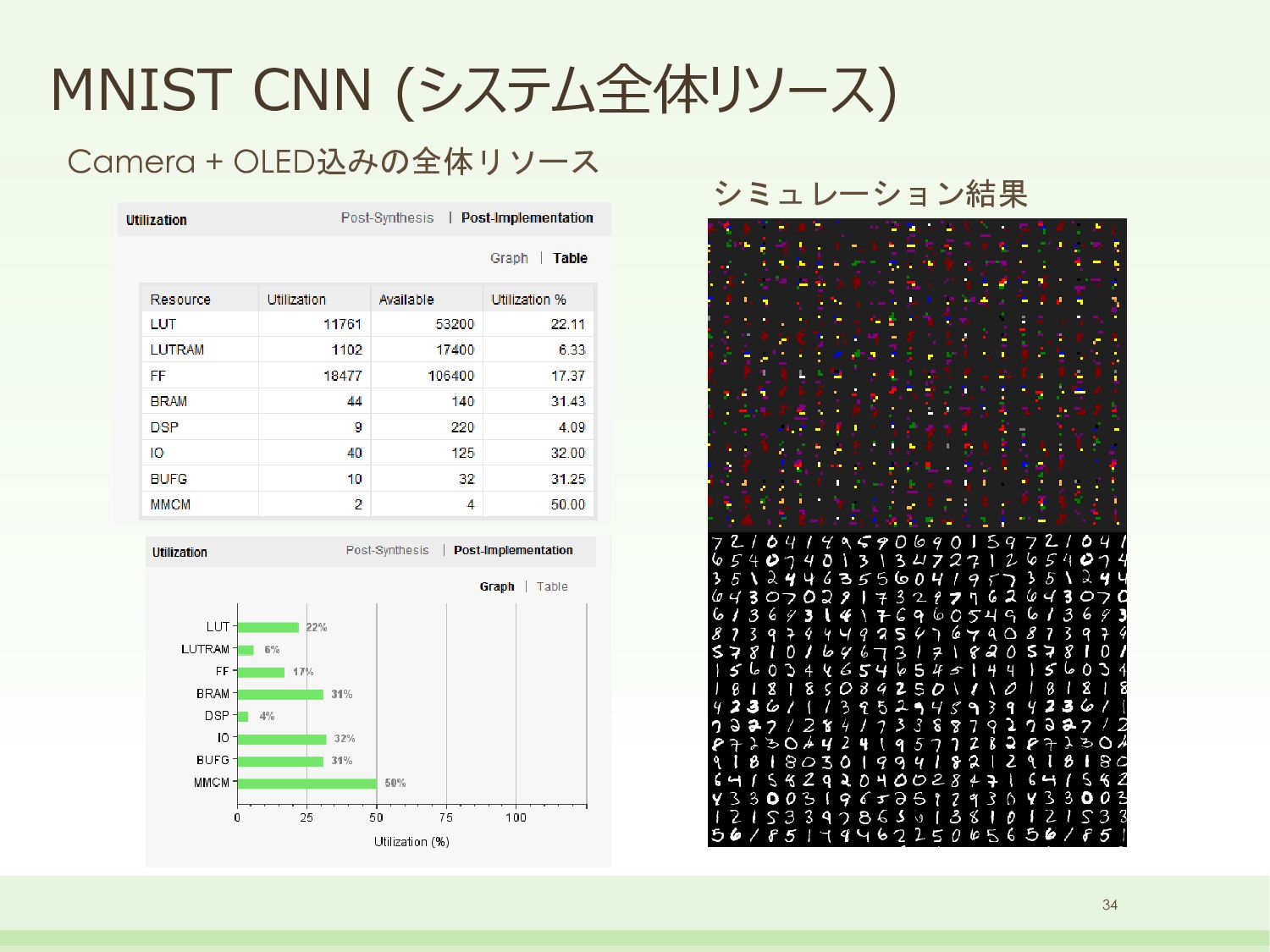
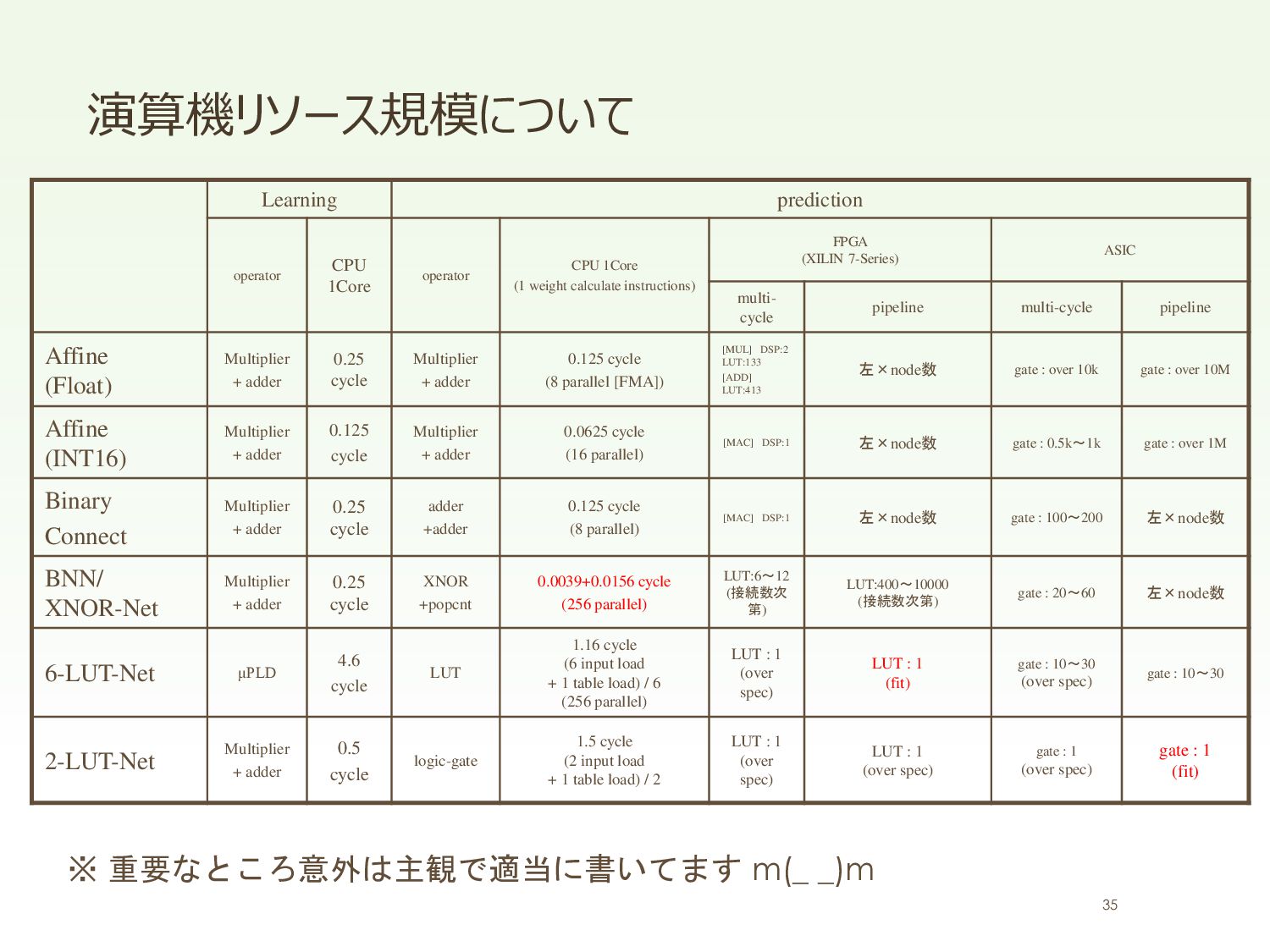
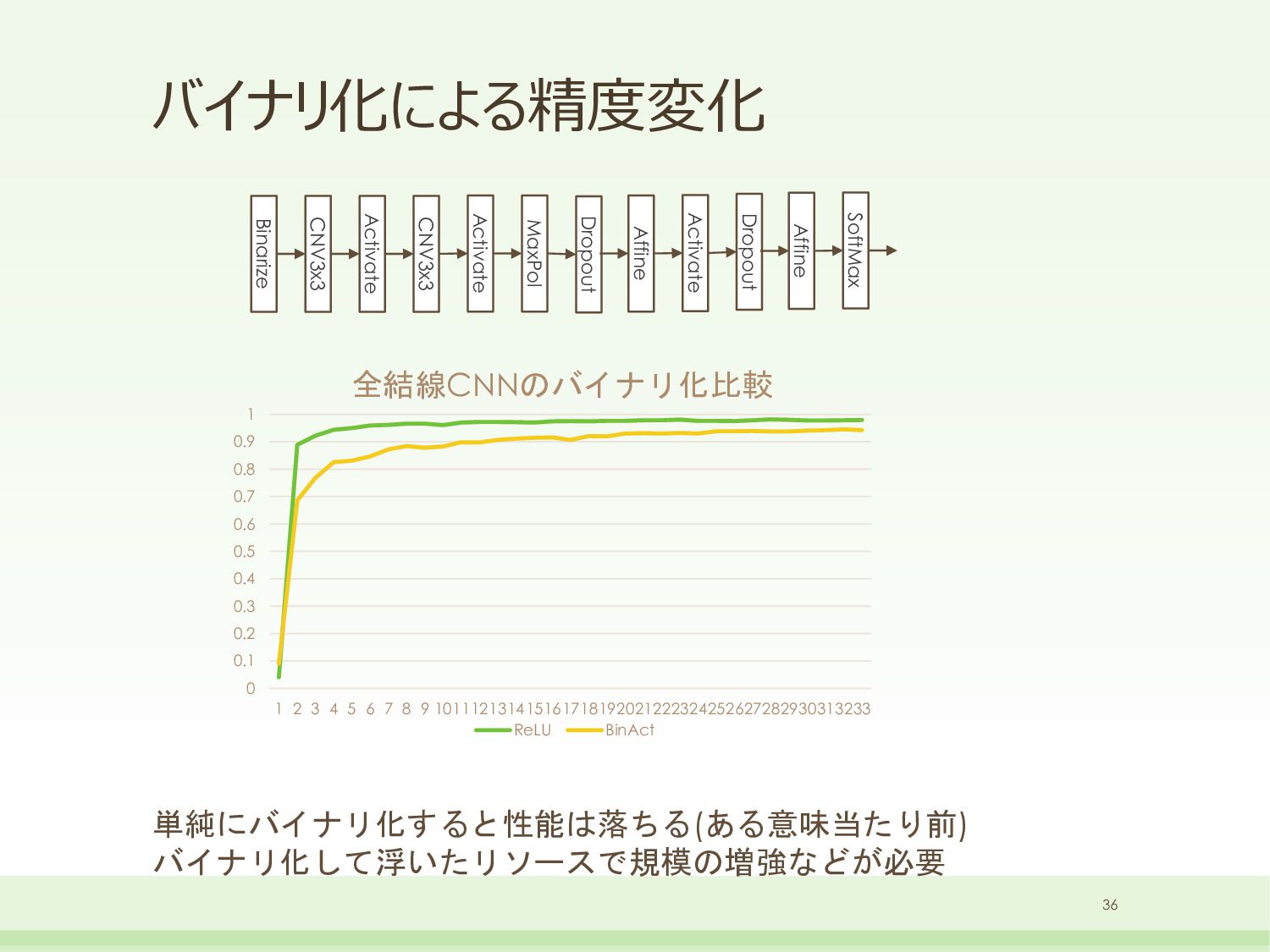
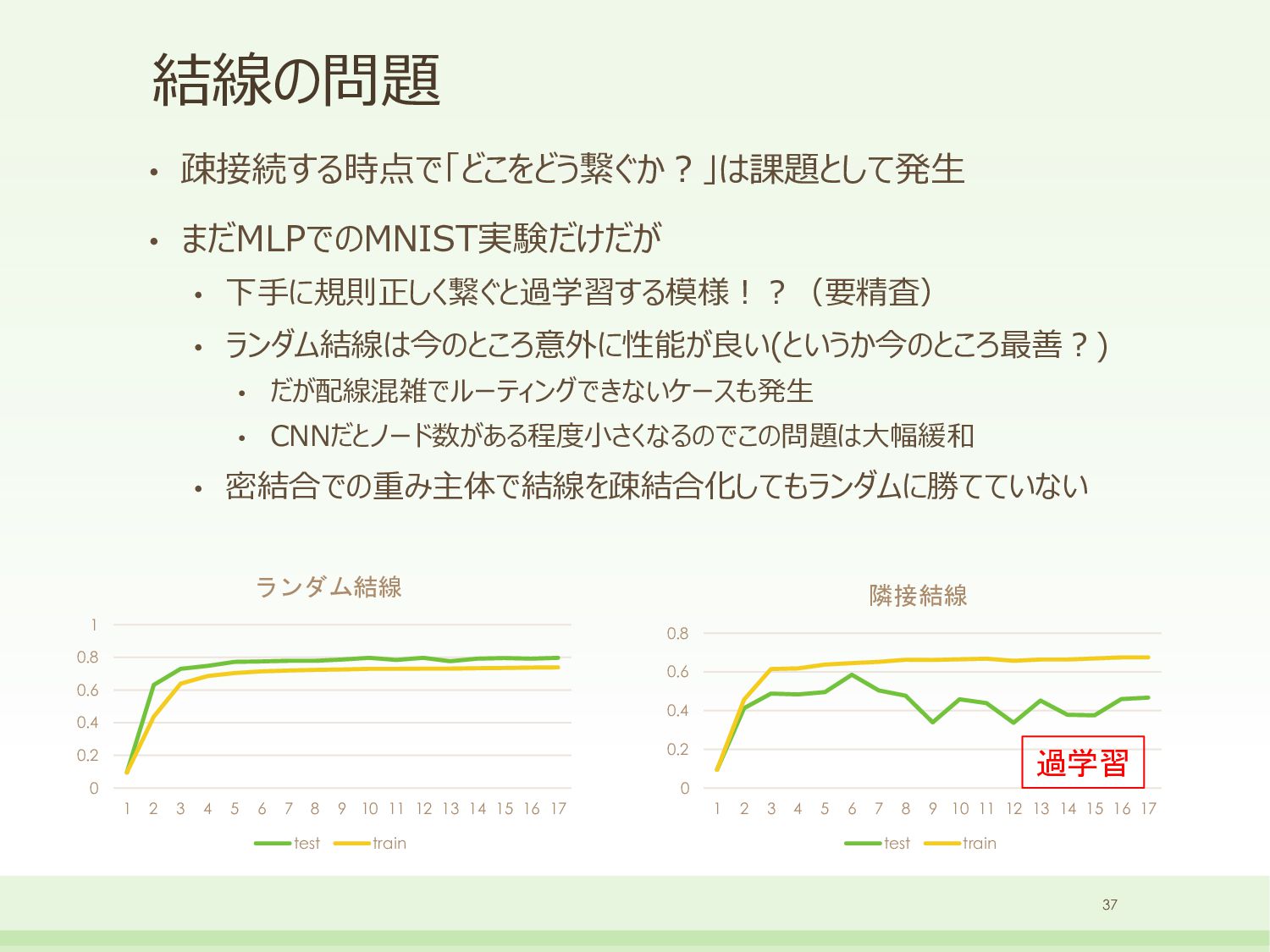
Affine // sub-networks for convolution(3x3) bb::NeuralNetSparseMicroMlp<6, 16>sub0_smm0(1 * 3 * 3, 192); bb::NeuralNetSparseMicroMlp<6, 16>sub0_smm1(192, 32); bb::NeuralNetGroup<>sub0_net; sub0_net.AddLayer(&sub0_smm0); sub0_net.AddLayer(&sub0_smm1); // sub-networks for convolution(3x3) bb::NeuralNetSparseMicroMlp<6, 16>sub1_smm0(32 * 3 * 3, 192); bb::NeuralNetSparseMicroMlp<6, 16>sub1_smm1(192, 32); bb::NeuralNetGroup<>sub1_net; sub1_net.AddLayer(&sub1_smm0); sub1_net.AddLayer(&sub1_smm1); // sub-networks for convolution(3x3) bb::NeuralNetSparseMicroMlp<6, 16>sub3_smm0(32 * 3 * 3, 192); bb::NeuralNetSparseMicroMlp<6, 16>sub3_smm1(192, 32); bb::NeuralNetGroup<>sub3_net; sub3_net.AddLayer(&sub3_smm0); sub3_net.AddLayer(&sub3_smm1); // sub-networks for convolution(3x3) bb::NeuralNetSparseMicroMlp<6, 16>sub4_smm0(32 * 3 * 3, 192); bb::NeuralNetSparseMicroMlp<6, 16>sub4_smm1(192, 32); bb::NeuralNetGroup<>sub4_net; sub4_net.AddLayer(&sub4_smm0); sub4_net.AddLayer(&sub4_smm1); // main-networks bb::NeuralNetRealToBinary<float>input_real2bin(28 * 28, 28 * 28); bb::NeuralNetLoweringConvolution<>layer0_conv(&sub0_net, 1, 28, 28, 32, 3, 3); bb::NeuralNetLoweringConvolution<>layer1_conv(&sub1_net, 32, 26, 26, 32, 3, 3); bb::NeuralNetMaxPooling<>layer2_maxpol(32, 24, 24, 2, 2); bb::NeuralNetLoweringConvolution<>layer3_conv(&sub3_net, 32, 12, 12, 32, 3, 3); bb::NeuralNetLoweringConvolution<>layer4_conv(&sub4_net, 32, 10, 10, 32, 3, 3); bb::NeuralNetMaxPooling<>layer5_maxpol(32, 8, 8, 2, 2); bb::NeuralNetSparseMicroMlp<6, 16>layer6_smm(32 * 4 * 4, 480); bb::NeuralNetSparseMicroMlp<6, 16>layer7_smm(480, 80); bb::NeuralNetBinaryToReal<float>output_bin2real(80, 10); xc7z020clg400-1 33 DNN部のみ 250MHz / (28x28) = 318,877fps
{kind=link}
{kind=link}
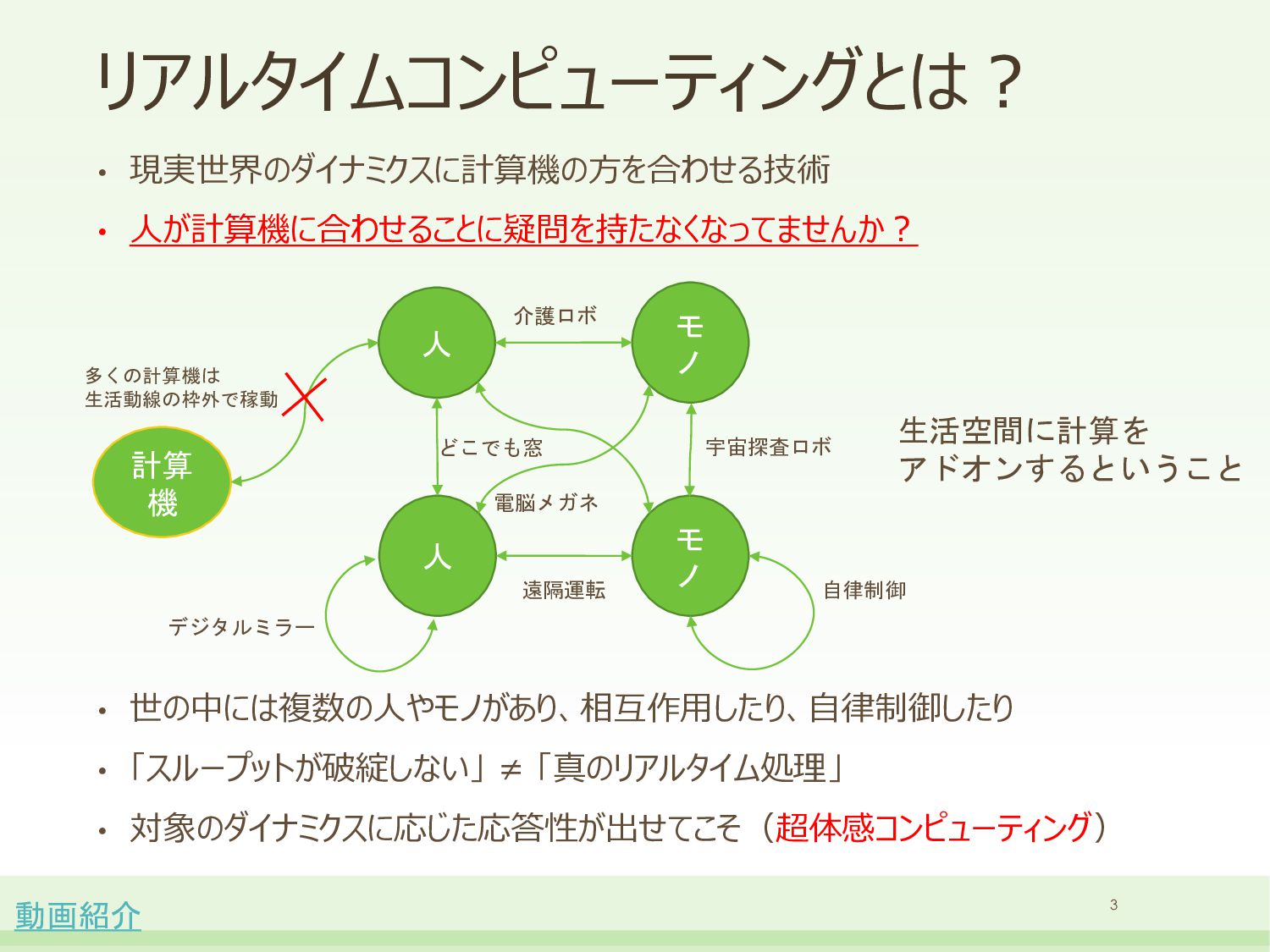{kind=link}
{kind=link}
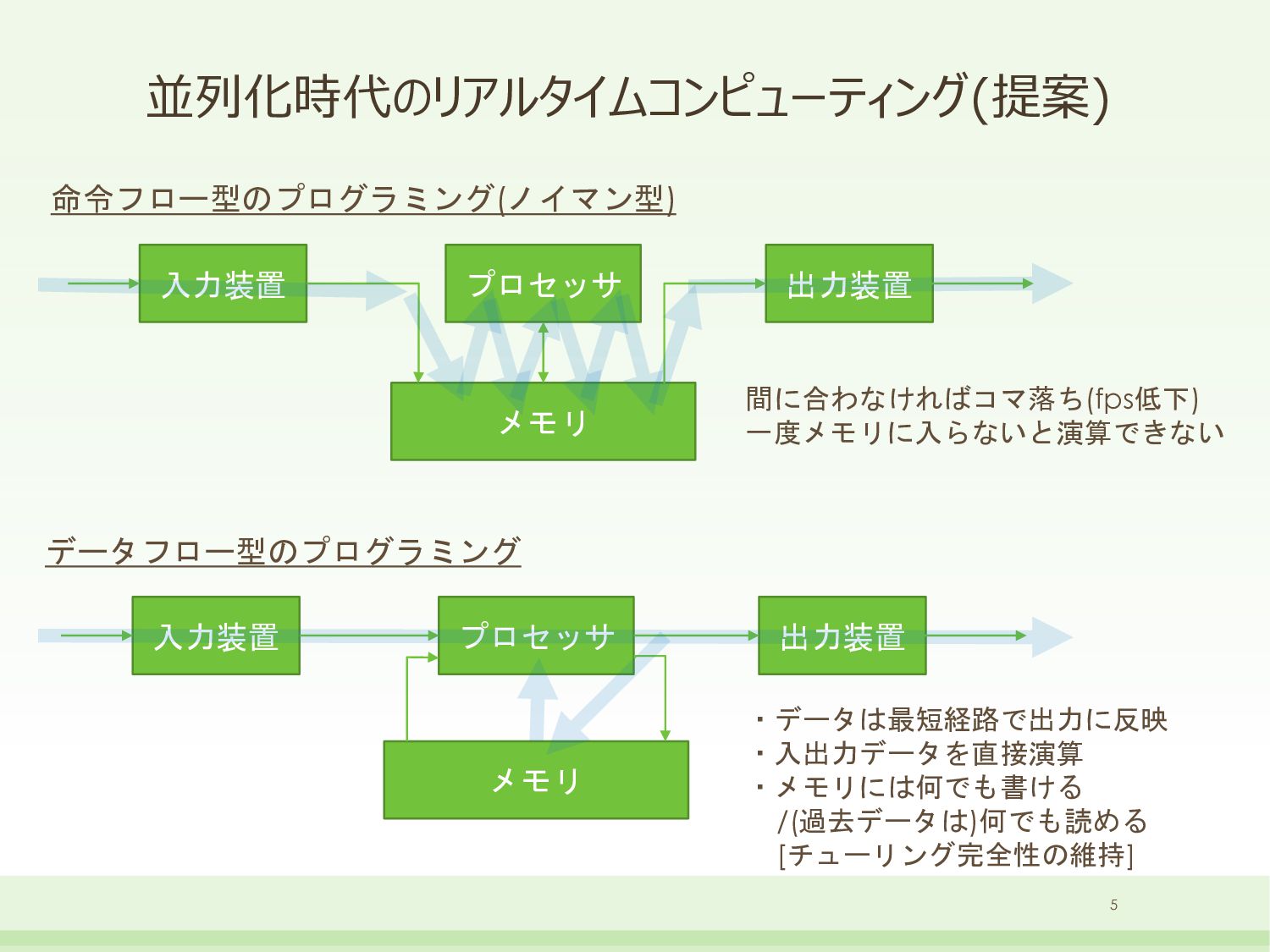{kind=link}
{kind=link}
{kind=link}
{kind=link}
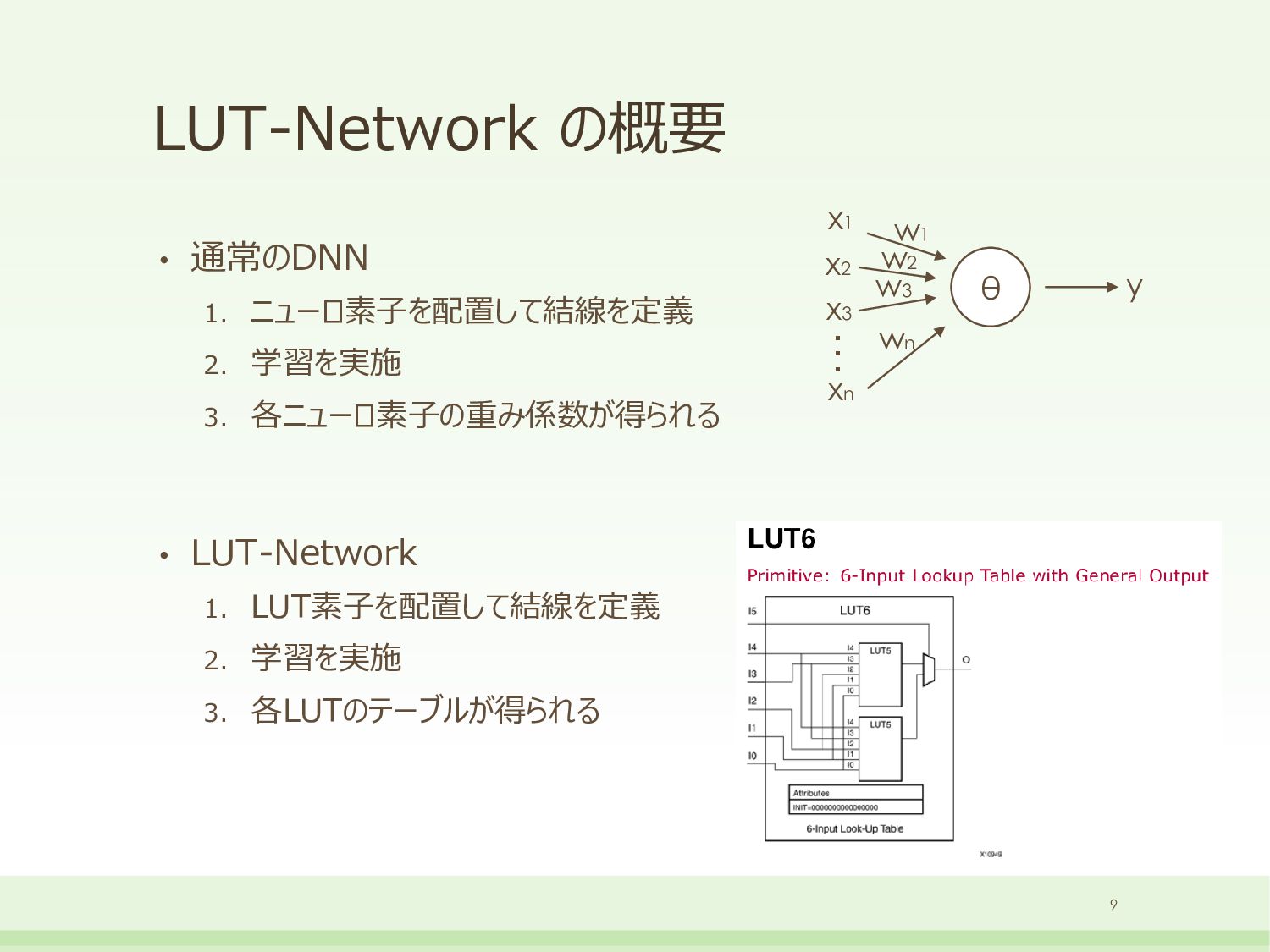{kind=link}
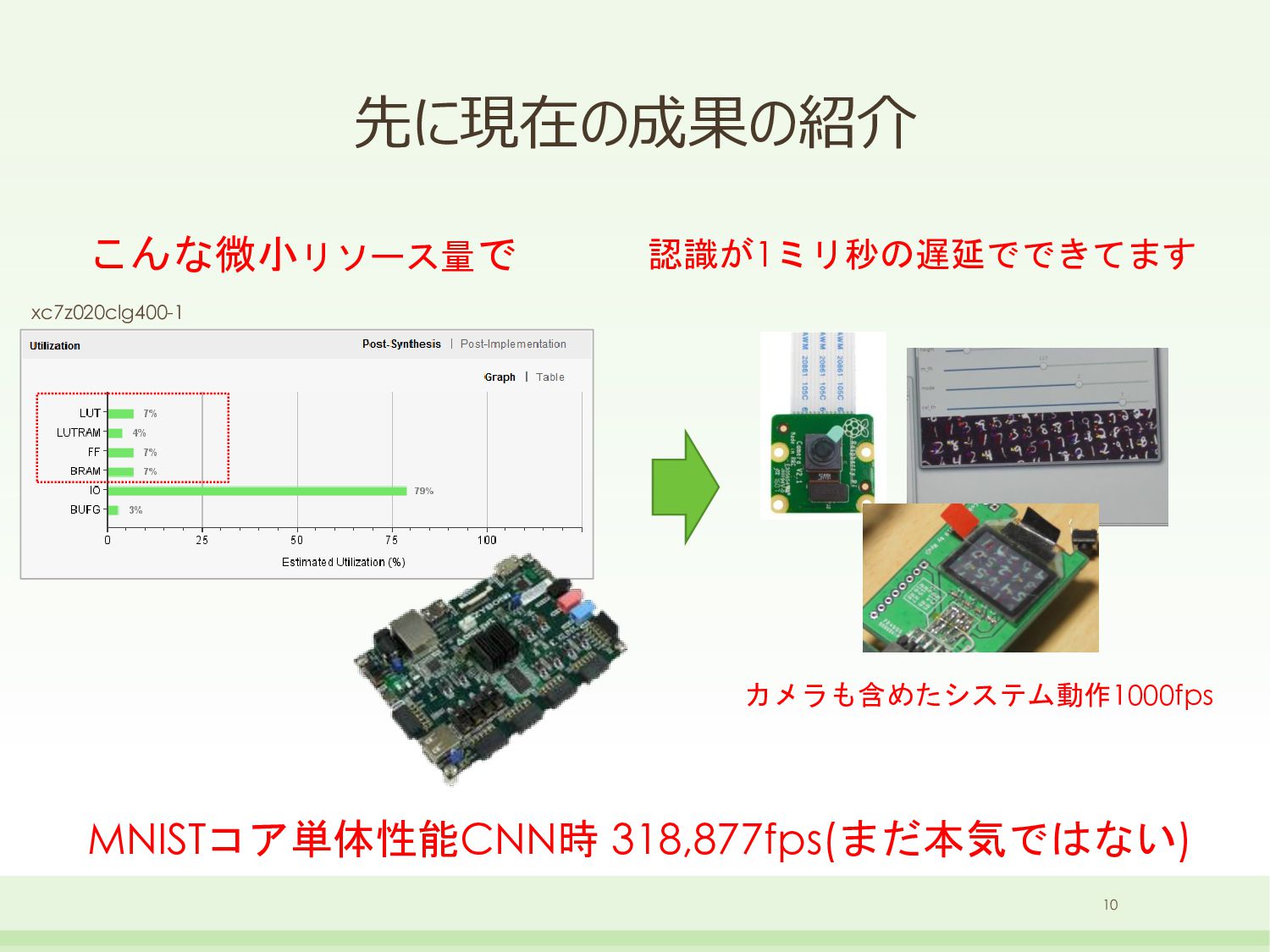{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[直接学習] 学習方法 入力値 発生回数 0出力時の損失 1出力時の損失 0 37932 47813.7 48233.9](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_14.jpg){kind=link}
![[直接学習] MNISTの学習実験 0.6 0.65 0.7 0.75 0.8 0.85 1 2](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_15.jpg){kind=link}
![[直接学習] 模倣学習の可能性について(仮説) • まだなんの実験できていないので仮説ですが • 巨大なネットについて • 現状のままでは巨大なネットは学習困難(課題) • ただし従来のバイナリネットワークの手法で学習された巨大なネットの学習](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_16.jpg){kind=link}
![[直接学習] 模倣学習によるLUT化のアイデア(未検証) Affine Binarize im2col BatchNorm col2im BinAct ReLU Binarize](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_17.jpg){kind=link}
![[直接学習] FPGAのLUTの動的変更について • 重みの変更を動的にやるにはLUTの テーブル変更が必要 • パーシャルリコンフィギュレー ショでもよいが、Xilinx の SRLC32E](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_18.jpg){kind=link}
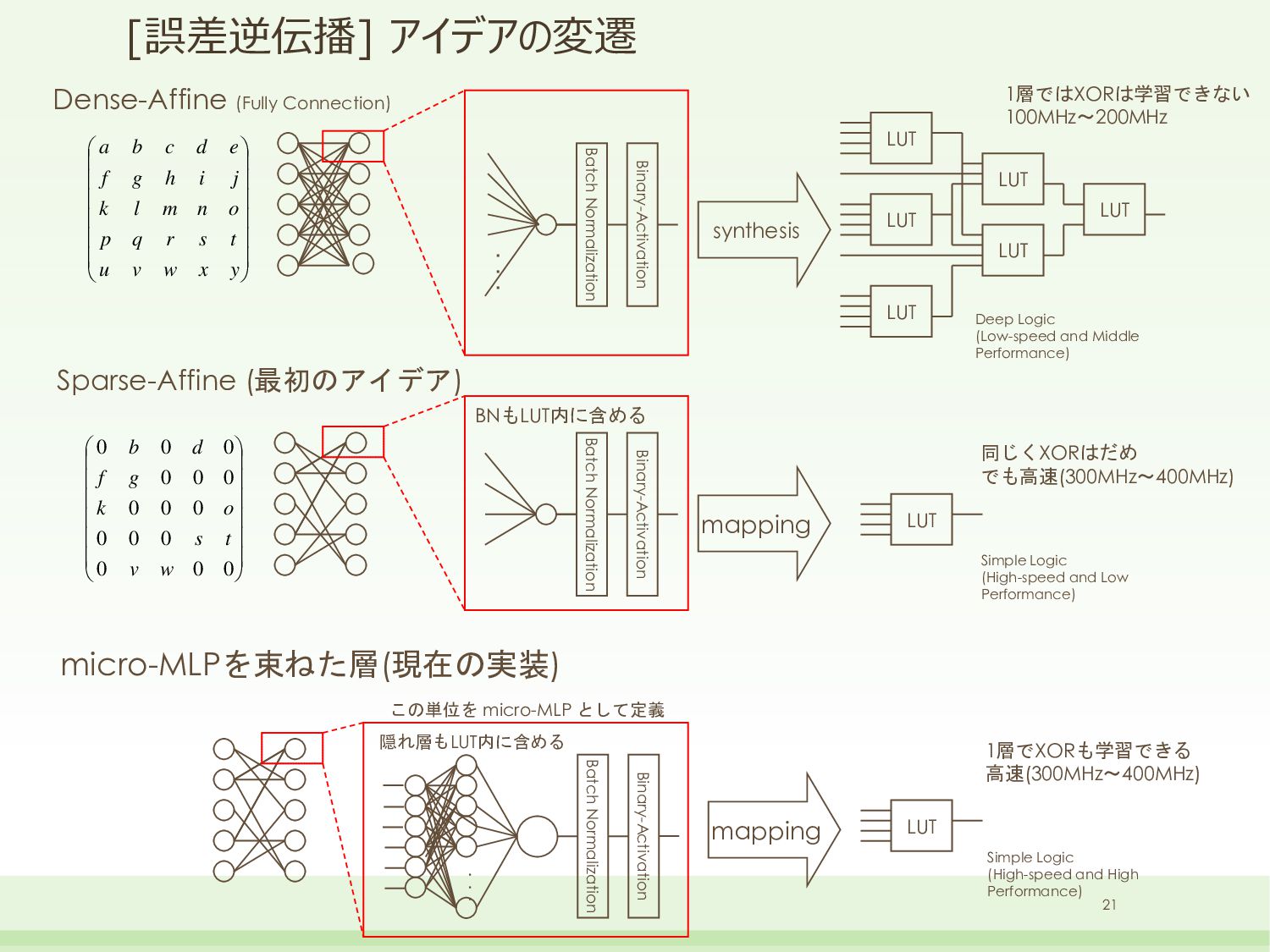
![[誤差逆伝播] 誤差逆伝播法による手法 • LUTと同じ入出力条件のニューラルネットワークの定義 • 6入力1出力のバイナリ結合のNetwork • 従来のバイナリネットを疎結合にしただけ? → No!](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_19.jpg){kind=link}
{kind=link}
![[誤差逆伝播] バイナリ活性層 (binary activation layer) • forward • Sign() •](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_21.jpg){kind=link}
![[誤差逆伝播] Batch Normalization (計算式は変えずに実装だけ工夫) = N i i x](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_22.jpg){kind=link}
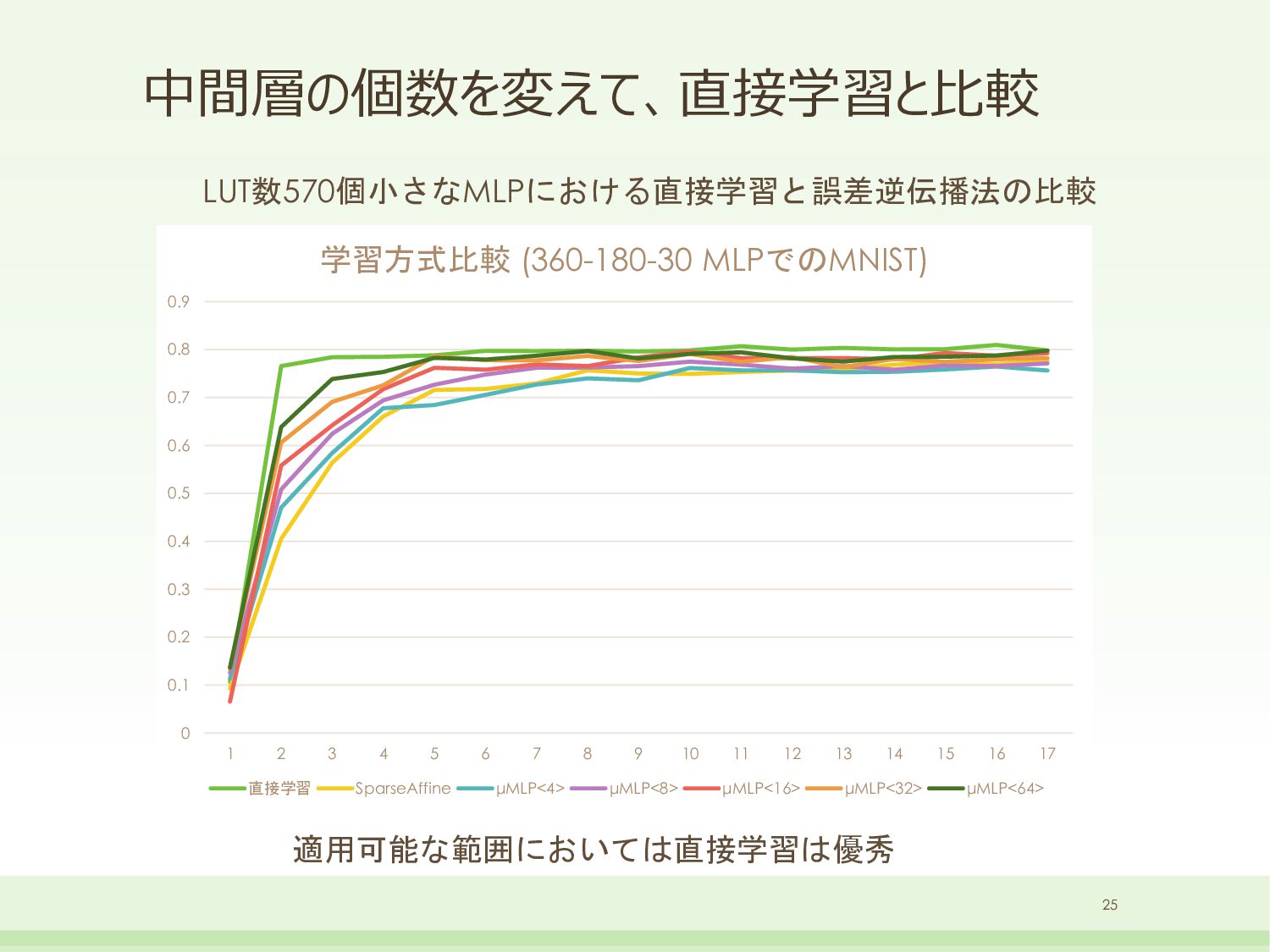
![[誤差逆伝播] パーセプトロン部分 6次のXORパターンを学習実験 中間層はいくら増やしても Predictionのリソースは増えない 数が多いほど学習性能は高い (Learning時の計算量は増える) 数が少ないとそもそも学習できな いケースが多発(局所解) 20個以上あれば大丈夫?](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_23.jpg){kind=link}
{kind=link}
![[誤差逆伝播] micro-MLP の学習 Affine Layer (16~64 perceptron) Activation Layer Sigmoid](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
![実例紹介1 [MNIST MLP] (1000fps 動作) DNN (LUT-Net) MIPI-CSI RX Raspberry](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
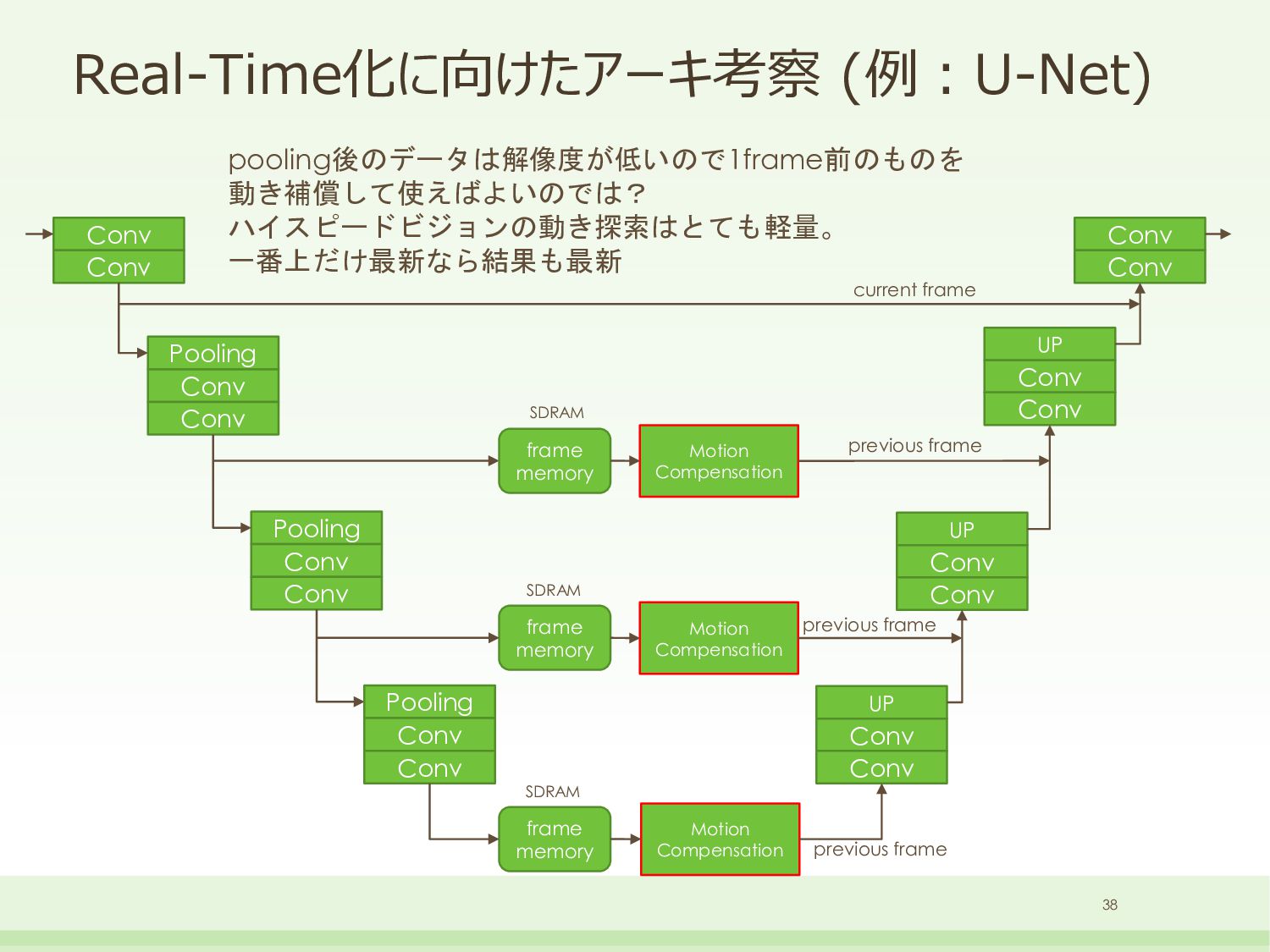{kind=link}
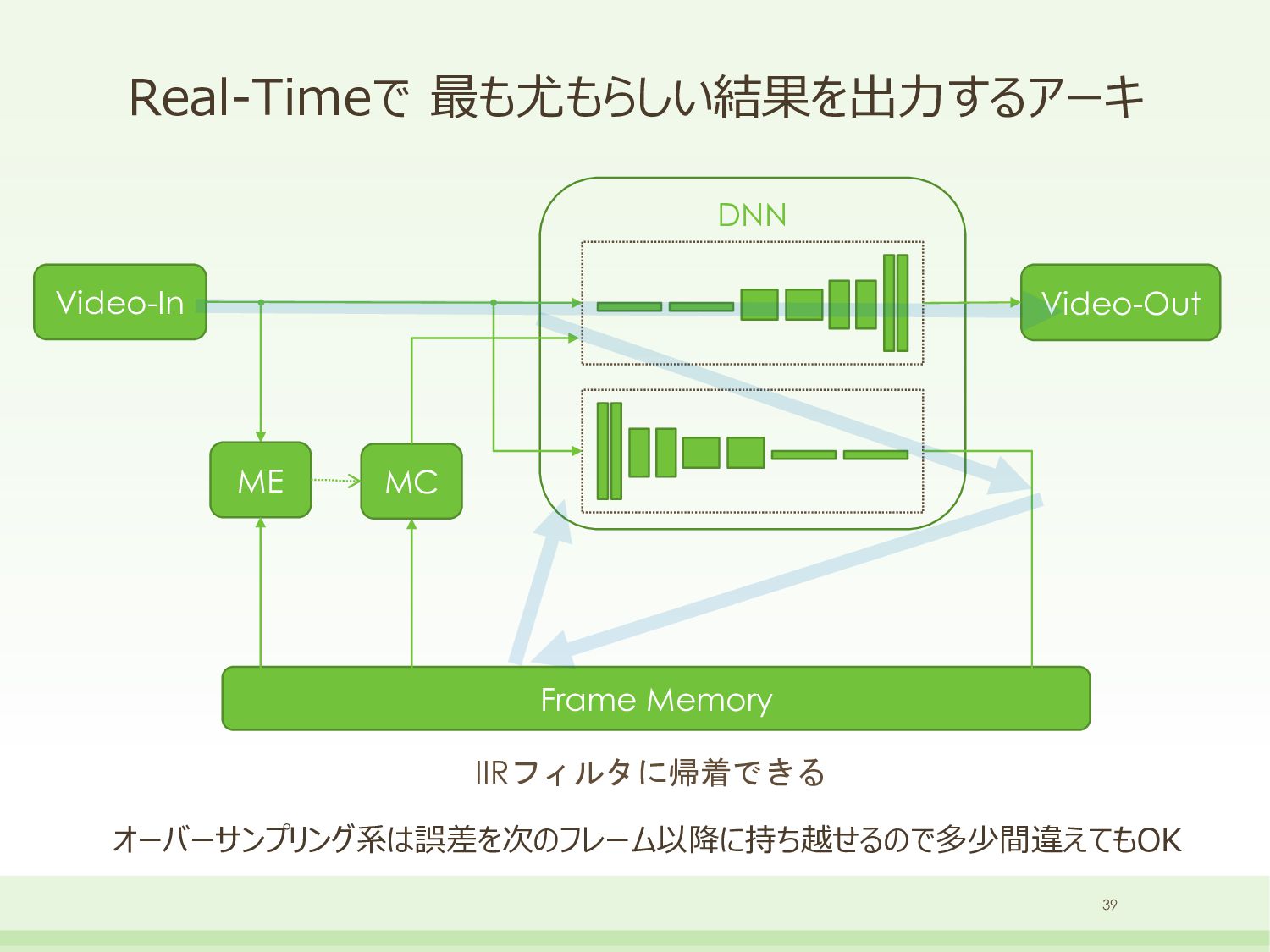{kind=link}
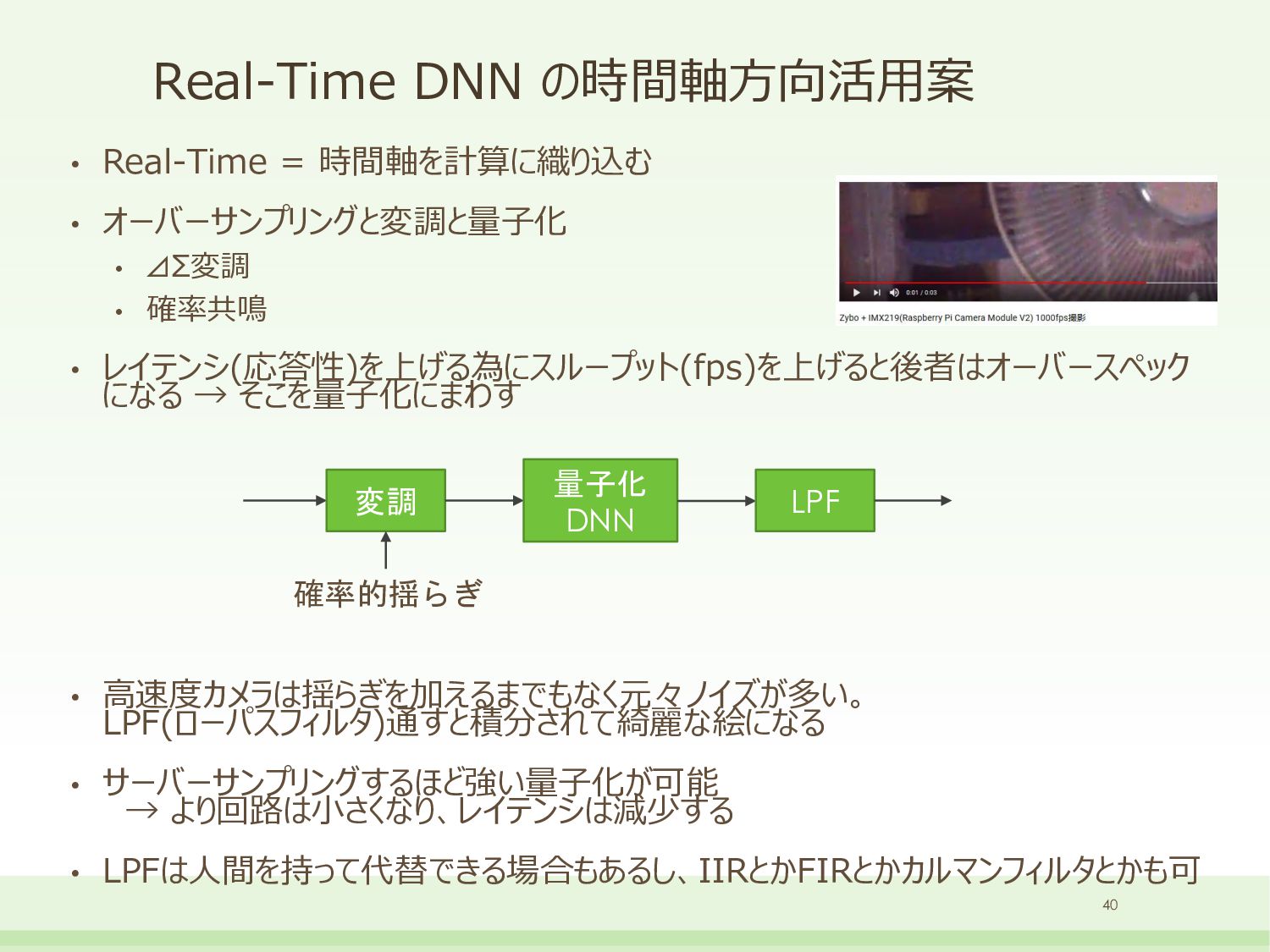{kind=link}
{kind=link}
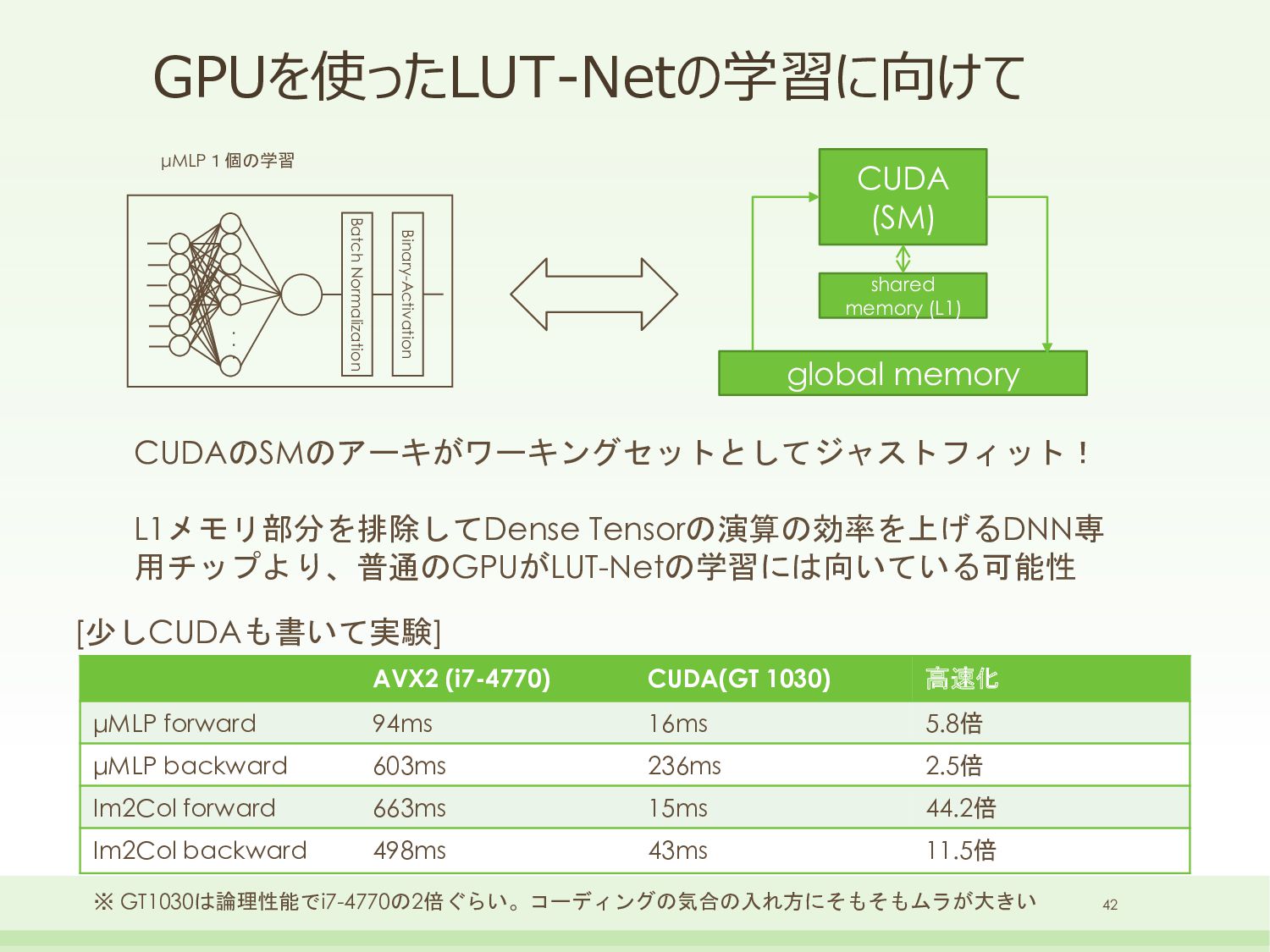{kind=link}
{kind=link}
{kind=link}
{kind=link}
![発表者アクセス先 • 渕上 竜司 (Ryuji Fuchikami) • e-mail : [email protected]](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_45.jpg){kind=link}
{kind=link}
![LUTモデルの数学的な考察 48 input[n-1:0] output 入力をn個とすると、テーブル自体がn次元のデータ 下記はXORの2次元テーブルを図示したもの ・テーブル値を頂点の値として補完できるし、多値も取れる ・入力はテーブルの位置を指すインデックス ・誤差逆伝播に対しては -](https://files.speakerdeck.com/presentations/063899e4bab24af192f5ba73ea76ee75/slide_47.jpg){kind=link}
{kind=link}
{kind=link}