ICLR 2020 Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning 第12回 最先端NLP勉強会 Titech Okazaki Lab/Hottolink: Sakae Mizuki 2020/09/26 ※ スライド中の図表・数式は,断りのないかぎり本論文からの引用です
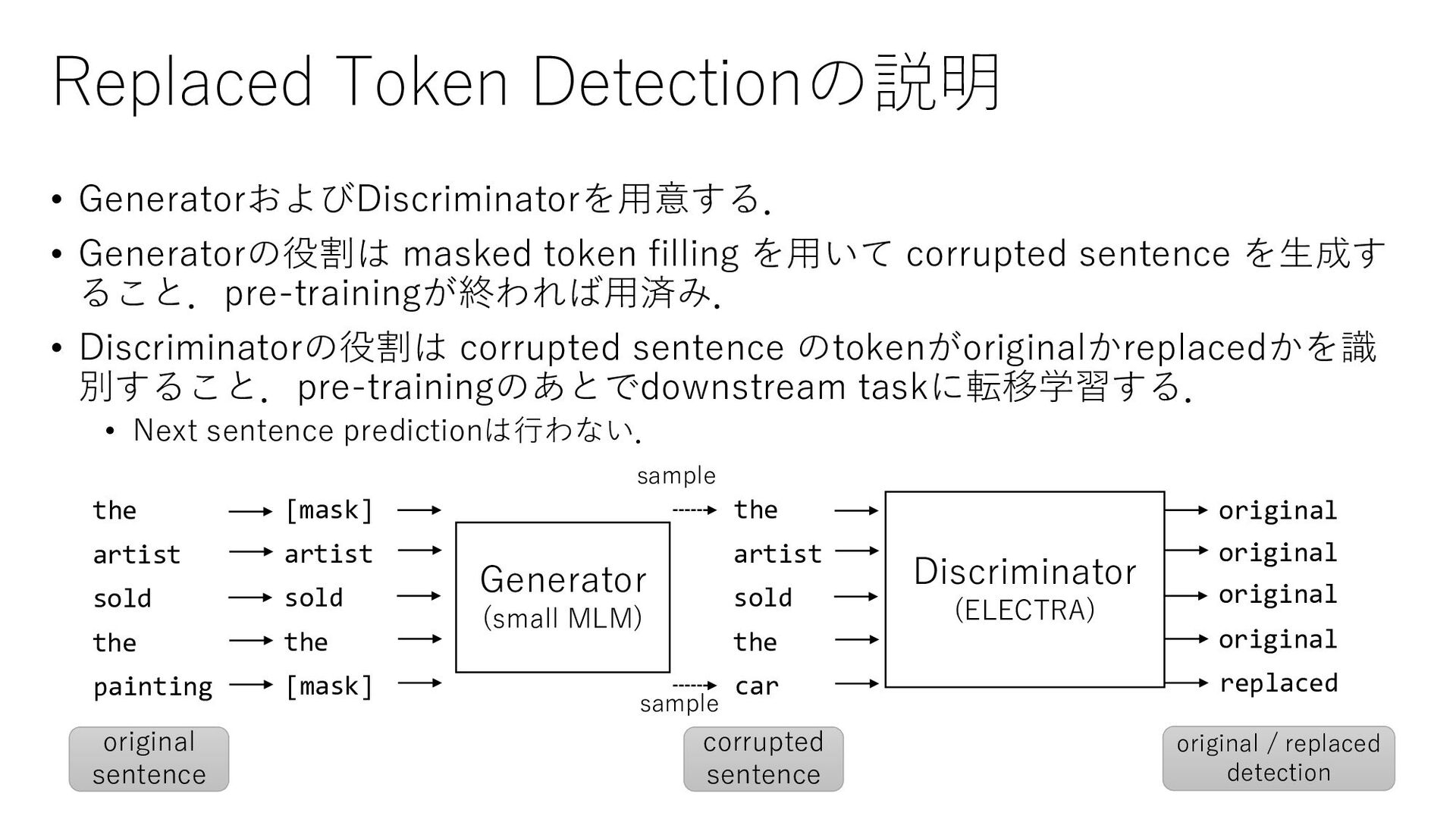
を用いて corrupted sentence を生成す ること.pre-trainingが終われば用済み. • Discriminatorの役割は corrupted sentence のtokenがoriginalかreplacedかを識 別すること.pre-trainingのあとでdownstream taskに転移学習する. • Next sentence predictionは行わない. 6 Generator (small MLM) Discriminator (ELECTRA) the artist sold the car original original original original replaced [mask] artist sold the [mask] the artist sold the painting original sentence corrupted sentence original / replaced detection sample sample
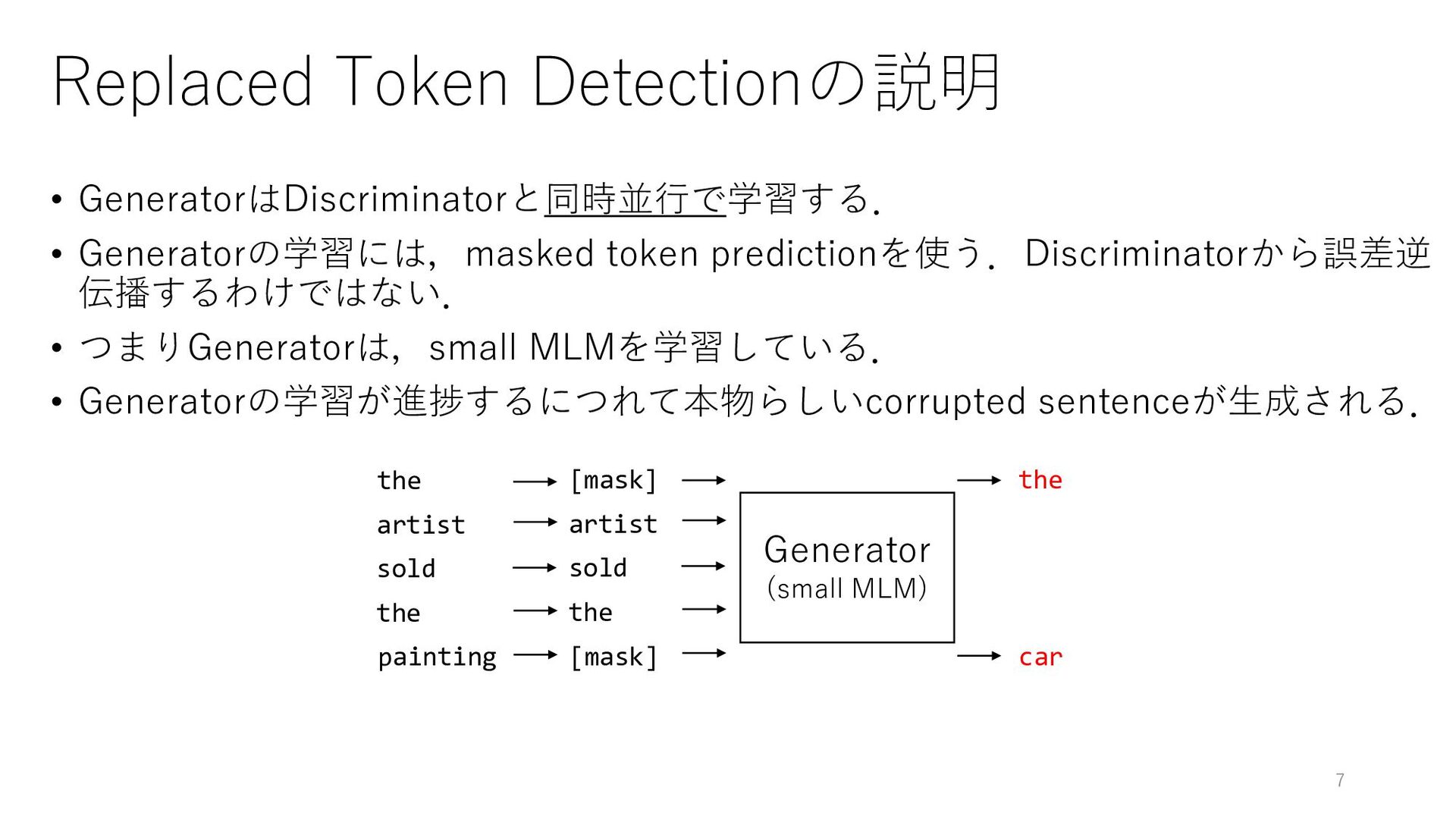
• つまりGeneratorは,small MLMを学習している. • Generatorの学習が進捗するにつれて本物らしいcorrupted sentenceが生成される. Generator (small MLM) the car [mask] artist sold the [mask] the artist sold the painting 7
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
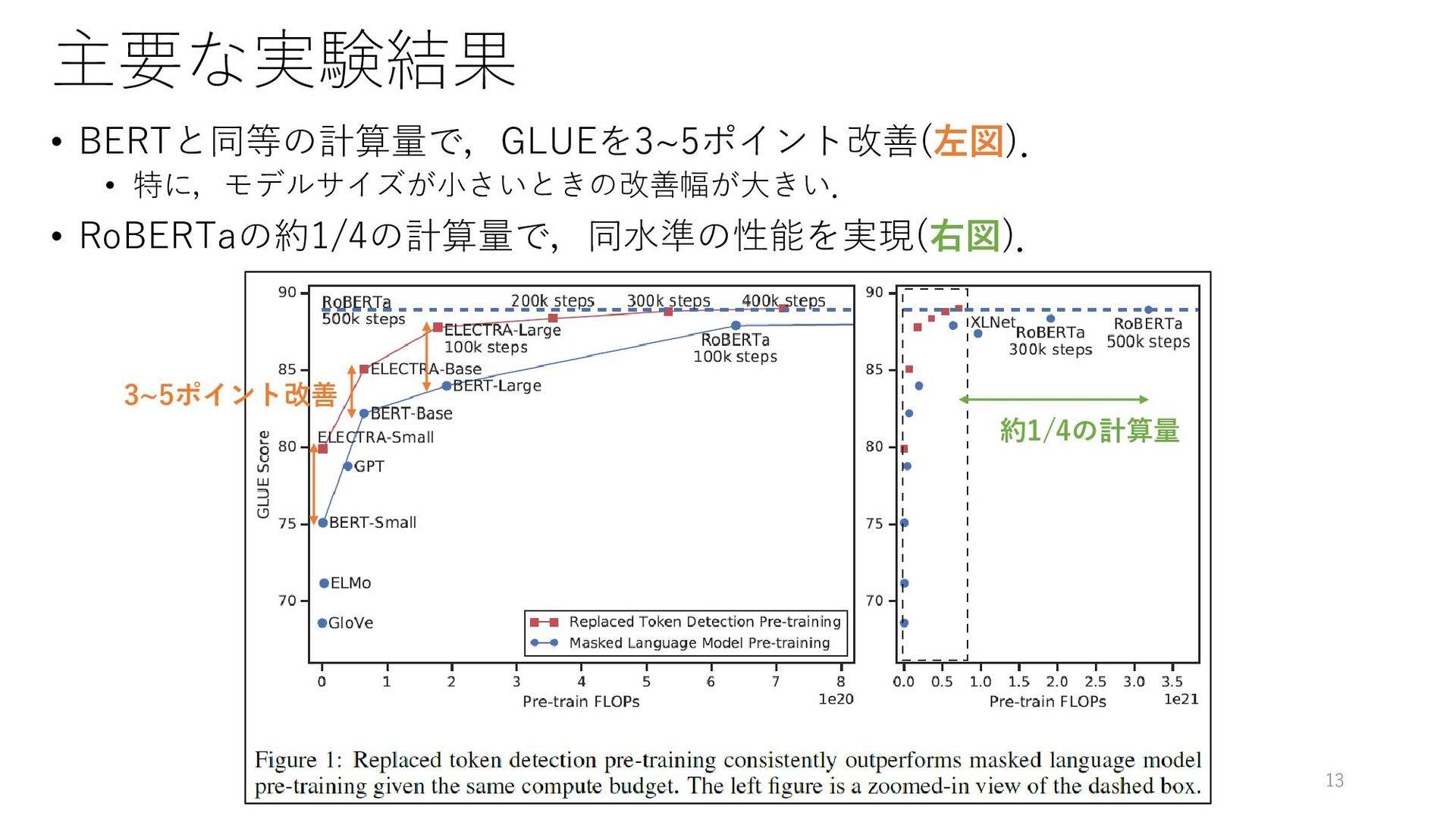{kind=link}
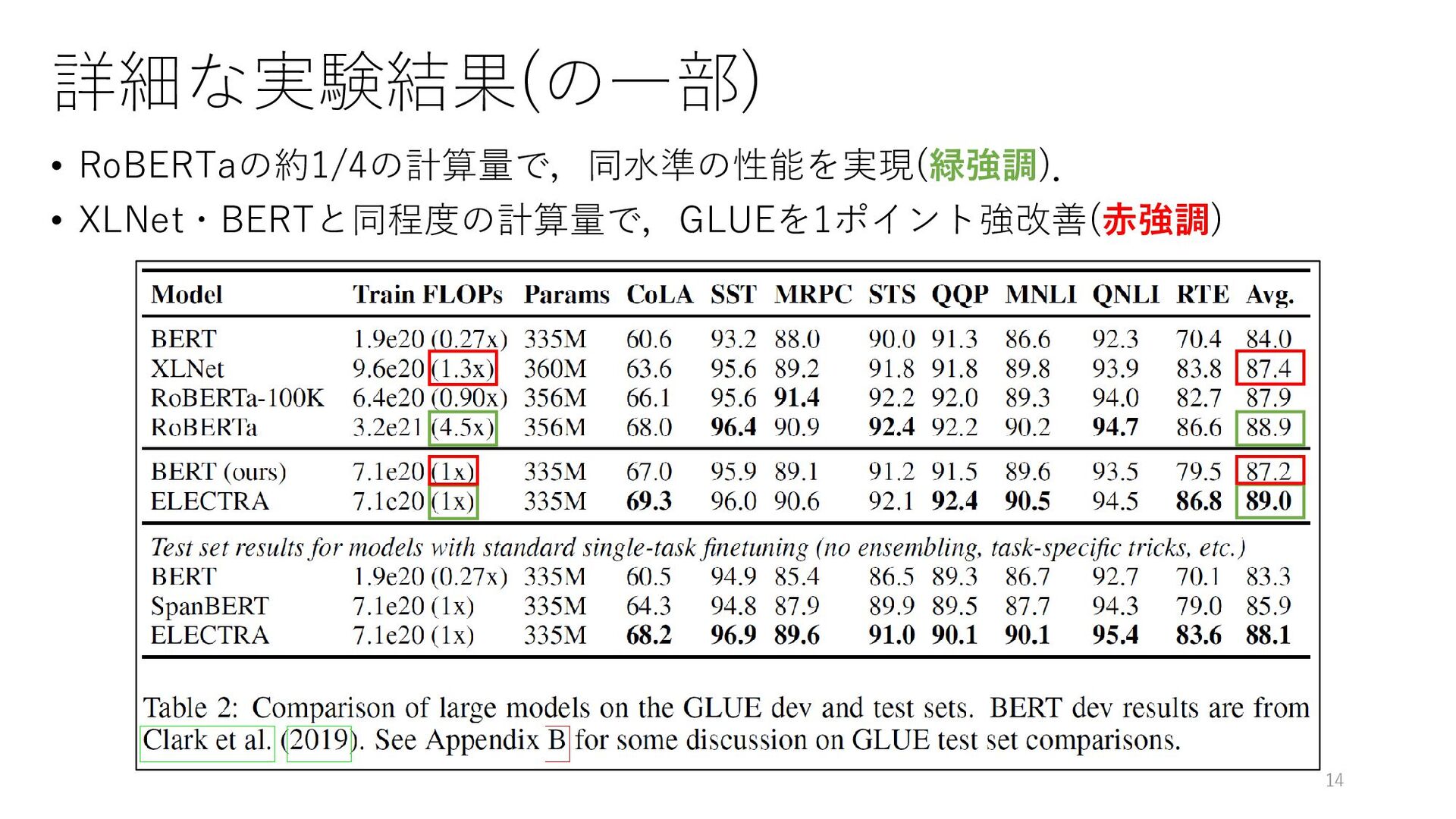{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
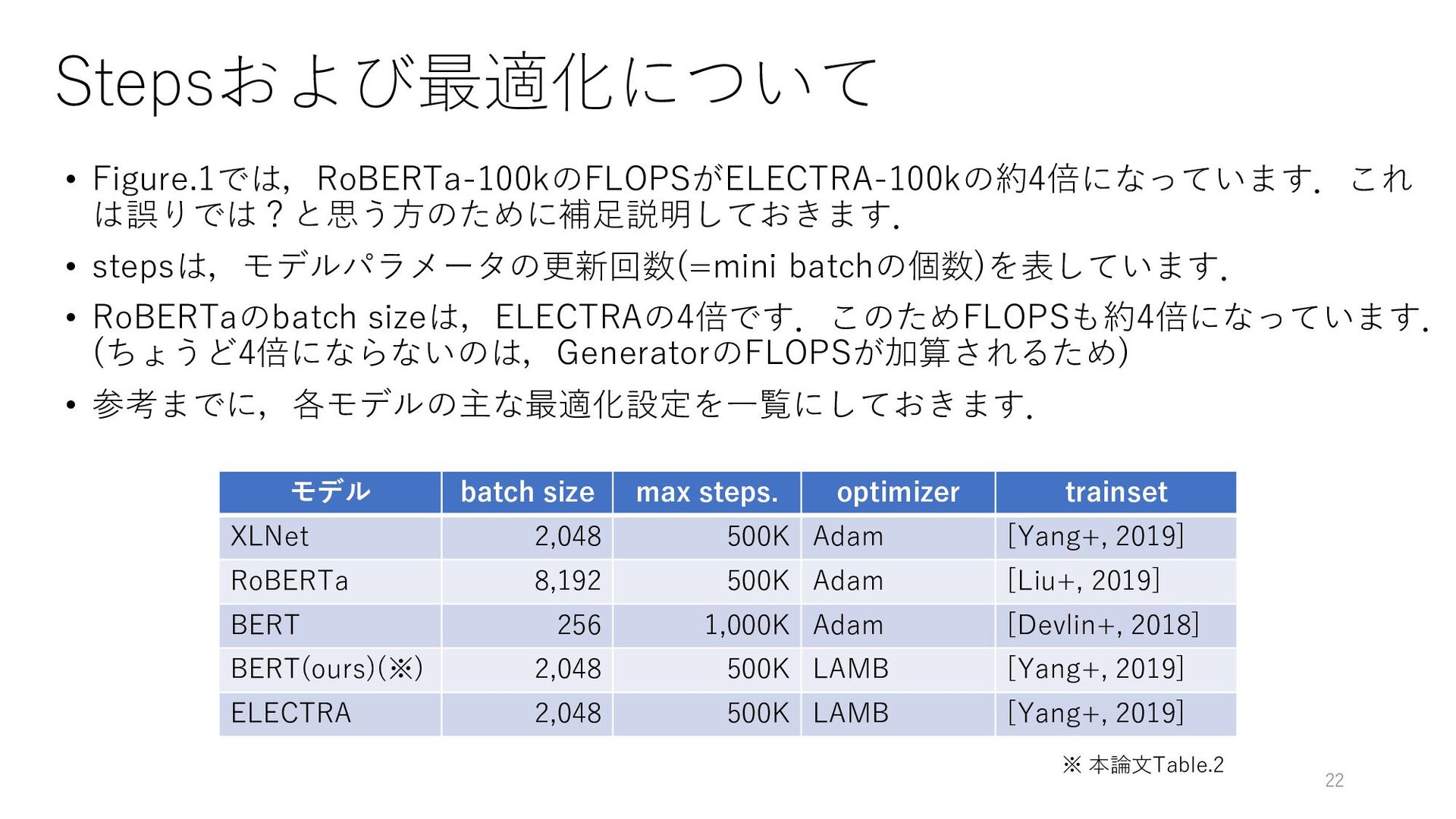{kind=link}
{kind=link}