and statistics: A tutorial. Commun. Inf. Theory, 1(4):417–528, December 2004. • Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. CoRR, abs/1909.08593, 2019. • Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. In 8th International Conference on Learning Representations, ICLR 2020. (PPLM: Plug-and-Play Language Model) • Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, and Richard Socher. CTRL: A conditional transformer language model for controllable generation. CoRR, abs/1909.05858, 2019. (CTRL: Conditional Transformer Language Model) 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
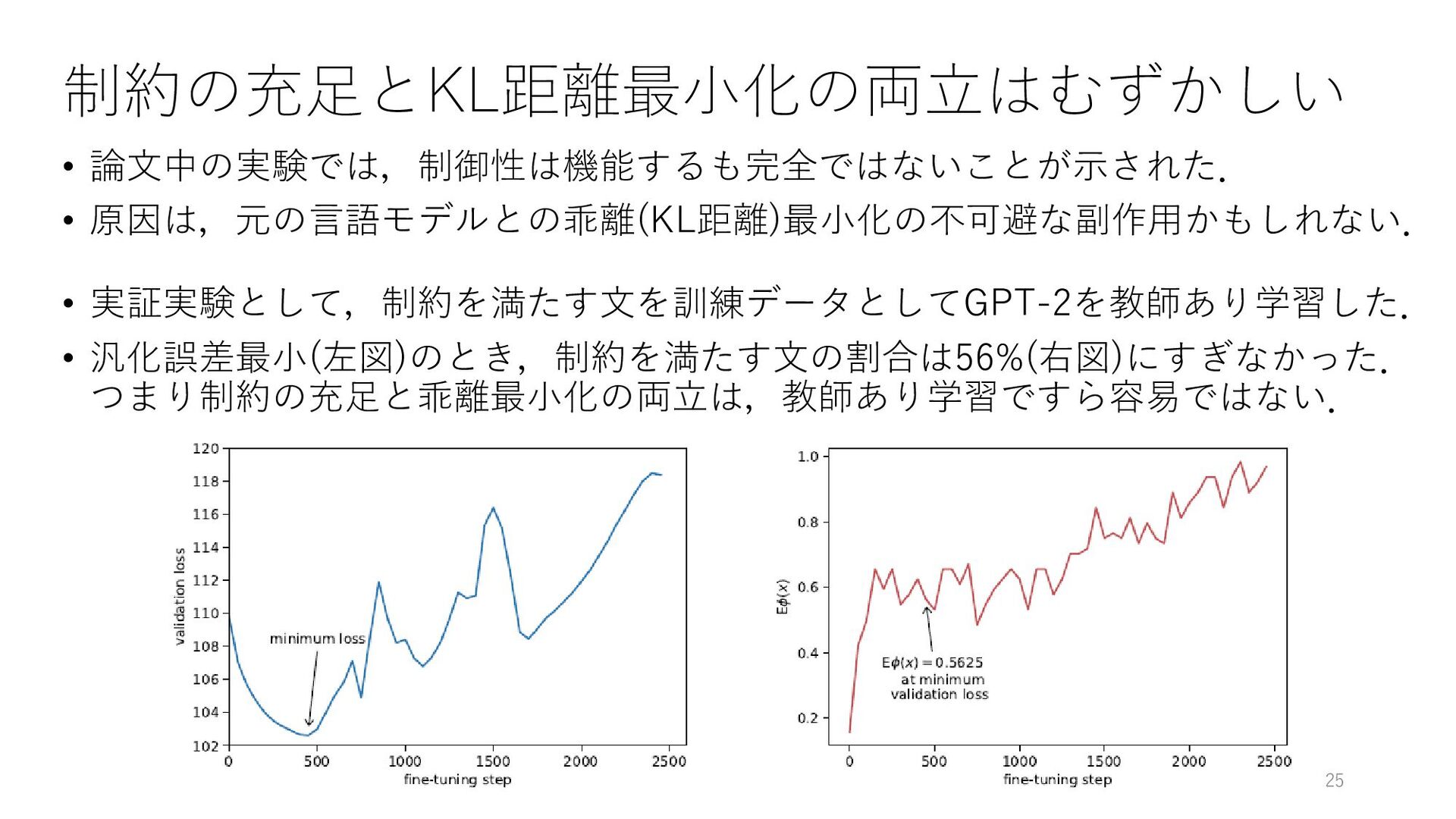
![簡易なバイアス解消にも応用できそう • 提案手法を応用して,略歴生成に特化した言語モデル(GPT2bio [Lebret+, 2016])が持つ 性別・職業バイアスの修正を試みる. • 修正前(Before:緑枠)と修正後(After:青枠)を比較すると,制約を満たす文の割合が 設定値(Desired:赤枠)に近づいている.バイアスの修正にも有効なことを示唆. 23](https://files.speakerdeck.com/presentations/d8b34b2749144d87883eef5c0c5b267a/slide_22.jpg){kind=link}
![強力な既存手法との比較 • 近年のテキスト制御手法;Plug & Play LM[Dathathri+, 2020] およびCTRL[Keskar+, 2019] と比較.](https://files.speakerdeck.com/presentations/d8b34b2749144d87883eef5c0c5b267a/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}