Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文読み会 SNLP2024 Instruction-tuned Language Model...
Search
S
August 19, 2024
Research
620
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文読み会 SNLP2024 Instruction-tuned Language Models are Better Knowledge Learners. In: ACL 2024
S
August 19, 2024
More Decks by S
See All by S
論文読み会 SNLP2025 Learning Dynamics of LLM Finetuning. In: ICLR 2025
s_mizuki_nlp
0
470
埋め込み表現の意味適応による知識ベース語義曖昧性解消
s_mizuki_nlp
2
600
論文読み会 SNLP2018 Sequence to Action: End to End Semantic Graph Generation for Semantic Parsing
s_mizuki_nlp
0
130
論文読み会 SNLP2019 Ordered neurons: Integrating tree structures into recurrent neural networks
s_mizuki_nlp
0
140
論文読み会 SNLP2020 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
s_mizuki_nlp
0
200
論文読み会 SNLP2021 A Distributional Approach to Controlled Text Generation
s_mizuki_nlp
0
160
Other Decks in Research
See All in Research
Data Visualization Tools in the Age of AI
flekschas
0
170
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
160
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
500
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
530
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
340
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
290
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
200
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
330
量子コンピュータの紹介
oqtopus
0
360
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
520
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
200
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
Featured
See All Featured
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Embracing the Ebb and Flow
colly
88
5.1k
The Curse of the Amulet
leimatthew05
2
13k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
890
Transcript
Instruction-tuned Language Models are Better Knowledge Learners. In: ACL 2024
Zhengbao Jiang, Zhiqing Sun, Weijia Shi, Pedro Rodriguez, Chunting Zhou, Graham Neubig, Xi Lin, Wen-tau Yih, Srini Iyer 第16回 最先端NLP勉強会 Hottolink/ Titech Okazaki Lab/AIST: Sakae Mizuki 2024-08-25 ※ スライド中の図表・数式は,断りのないかぎり本論文からの引用です
概要 2
背景と目的 • 最新の情報に答えられるようにしたい • うまく継続事前学習させるにはどうしたらよいか 3 知識カットオフ:2022年9月 2023年のテキストを追加で学習 Q. マーベルズの監督は?
A. ニア・ダコスタ +2023年の情報 Q. マーベルズの監督は? A. ルッソ兄弟
仮説 • LLMは事前学習テキストから知識をエンコードする • 質問応答(QA)による指示チューニングは知識の引き出し方を教える • [Sanh+, ICLR22][Wei+, ICLR22] など
• ならば,QAで事前学習すると「引き出し方」を意識したエンコードを するようになって,継続事前学習の性能が改善するのでは? 4 Q. マーベルズの監督は? A. ニア・ダコスタ Q. マーベルズの脚本は? A. ミーガン・マクドネル QAで事前学習 Better Knowledge Learner +知識獲得能力
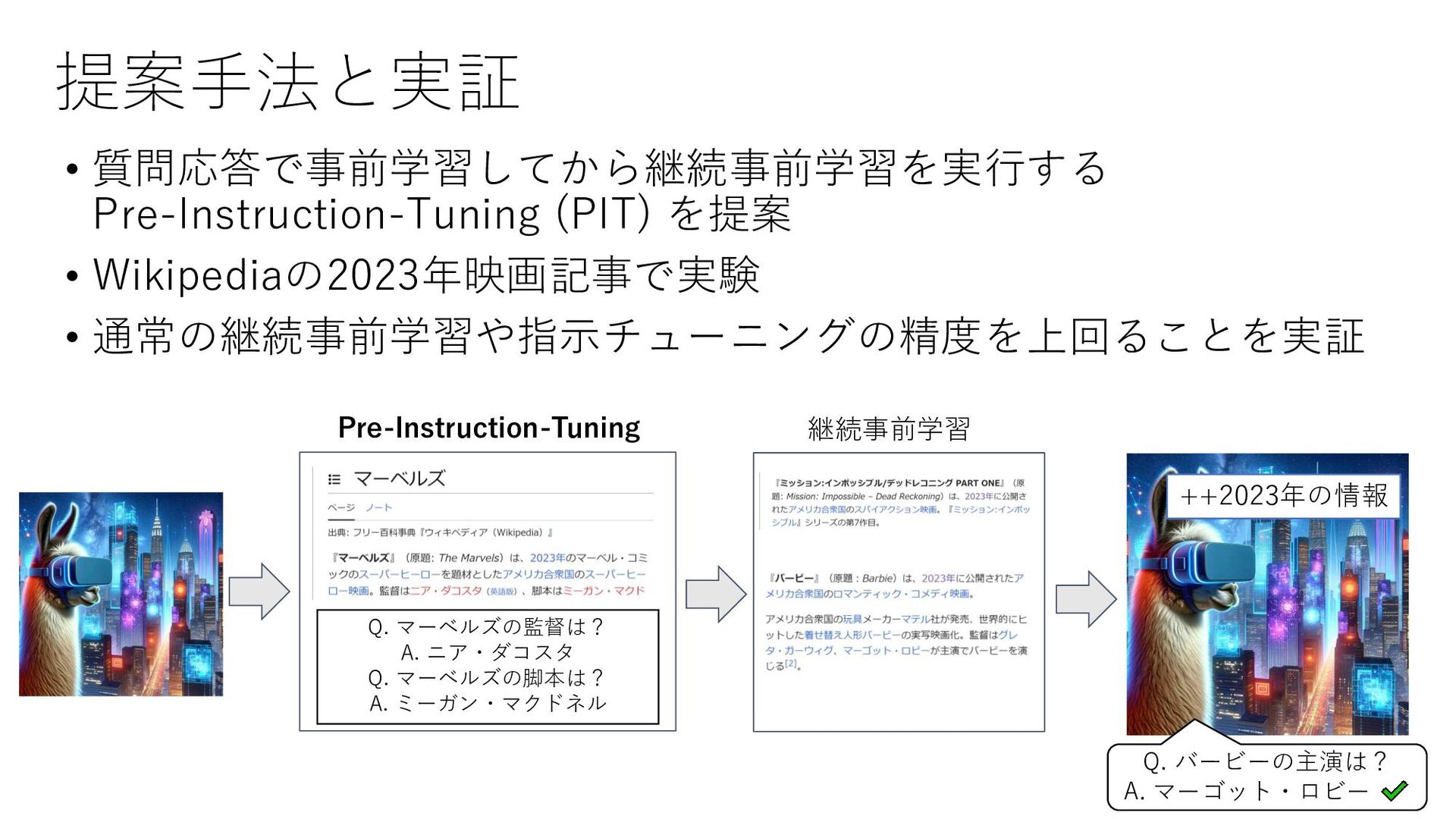
提案手法と実証 • 質問応答で事前学習してから継続事前学習を実行する Pre-Instruction-Tuning (PIT) を提案 • Wikipediaの2023年映画記事で実験 • 通常の継続事前学習や指示チューニングの精度を上回ることを実証
5 Q. マーベルズの監督は? A. ニア・ダコスタ Q. マーベルズの脚本は? A. ミーガン・マクドネル Pre-Instruction-Tuning 継続事前学習 Q. バービーの主演は? A. マーゴット・ロビー ++2023年の情報
実験設定 6
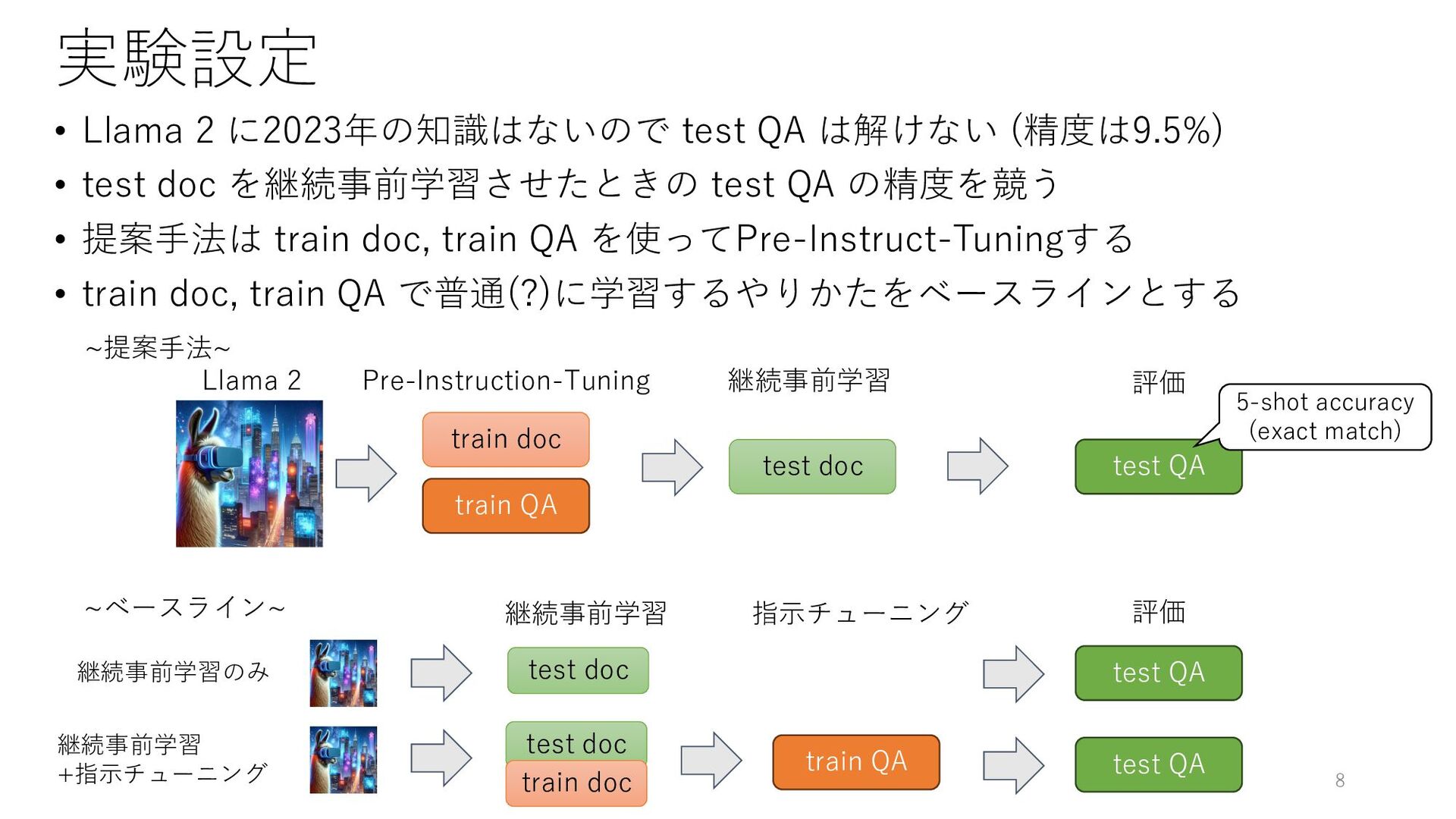
実験設定 • 2022年9月までの知識を持つ Llama 2 7B に 2023年の映画の情報を学習させる設定 • 2023年のWikipedia映画記事=docを収集して
LLMに記事の質問応答=QAを作らせる • {train doc, train QA, test doc, test QA}に分割 7 doc QA train QA train doc test QA test doc 1,720件 11,603問 1,743問 256件
実験設定 • Llama 2 に2023年の知識はないので test QA は解けない (精度は9.5%) •
test doc を継続事前学習させたときの test QA の精度を競う • 提案手法は train doc, train QA を使ってPre-Instruct-Tuningする • train doc, train QA で普通(?)に学習するやりかたをベースラインとする train QA train doc test QA test doc Pre-Instruction-Tuning 継続事前学習 評価 5-shot accuracy (exact match) Llama 2 ~提案手法~ ~ベースライン~ test doc 継続事前学習 test QA 評価 継続事前学習のみ 継続事前学習 +指示チューニング test doc train doc 指示チューニング test QA train QA 8
実験と分析 9
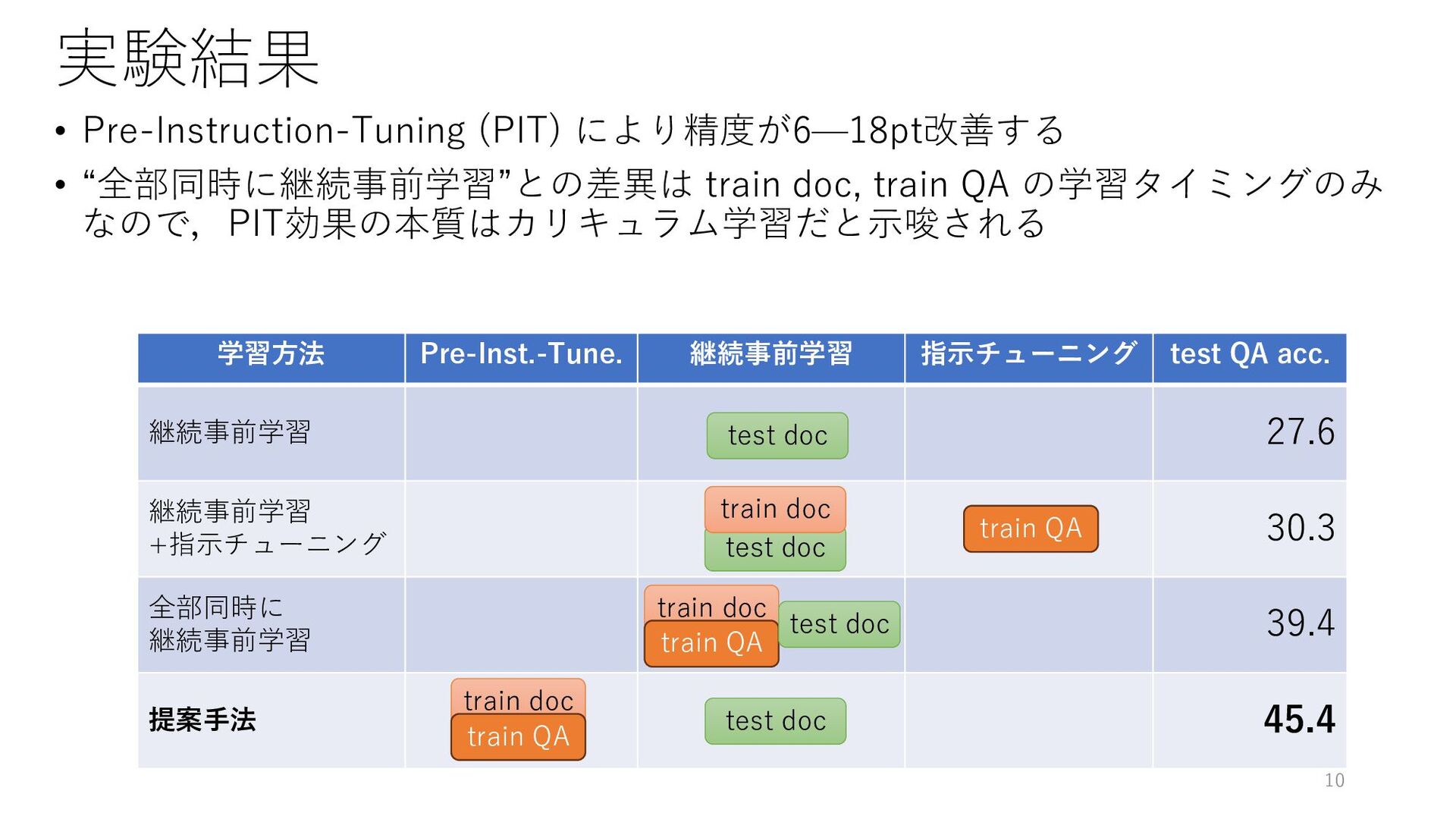
実験結果 • Pre-Instruction-Tuning (PIT) により精度が6—18pt改善する • “全部同時に継続事前学習”との差異は train doc, train
QA の学習タイミングのみ なので,PIT効果の本質はカリキュラム学習だと示唆される 学習方法 Pre-Inst.-Tune. 継続事前学習 指示チューニング test QA acc. 継続事前学習 27.6 継続事前学習 +指示チューニング 30.3 全部同時に 継続事前学習 39.4 提案手法 45.4 test doc train QA test doc train doc train doc train QA test doc train doc train QA test doc 10
分析結果 • Pre-Inst.-Tune. はdocとQAを交互に配置して学習する • 論文の記述が不明瞭で断言できないが,たぶんそう • QAのみ学習したり,docとQAをそれぞれまとめて学習するとPITの効果は消失す るので,open-book QAのようなスタイルがカギなのだと示唆される
学習方法 Pre-Inst.-Tune. 継続事前学習 test QA acc. QAのみでPIT 28.6 QAのあとでdoc 32.5 提案手法 45.4 test doc test doc test doc train QA train QA train doc train doc train QA 11
分析結果 • 本実験はtrain, testとも映画記事というドメイン内設定である • 映画以外(芸術・経済・政治等)から train doc, train QA
を取ってくる設定でも PITは依然として有効だが,ドメイン内設定よりも精度が8pt低下する • したがって,汎化能力は怪しい気がする 学習方法 Pre-Inst.-Tune. 継続事前学習 指示チューニング test QA acc. 継続事前学習 +指示チューニング 23.6 提案手法 36.9 提案手法 45.4 映画以外のtrain QA test doc 映画以外のtrain doc train doc train QA test doc 映画以外のtrain doc 映画以外のtrain QA test doc 12
まとめと考察 13
まとめ • 質問応答でPre-Instruction-Tuning (PIT) したLLMは”Better knowledge learner”になって,継続事前学習の知識獲得が改善する • open-book QAのように文書と質問応答を交互に並べるのがカギ
• ドメイン間設定では効果が低下するもよう • 質問応答での有効性のみ確認.推論や読解での有効性は不明 14
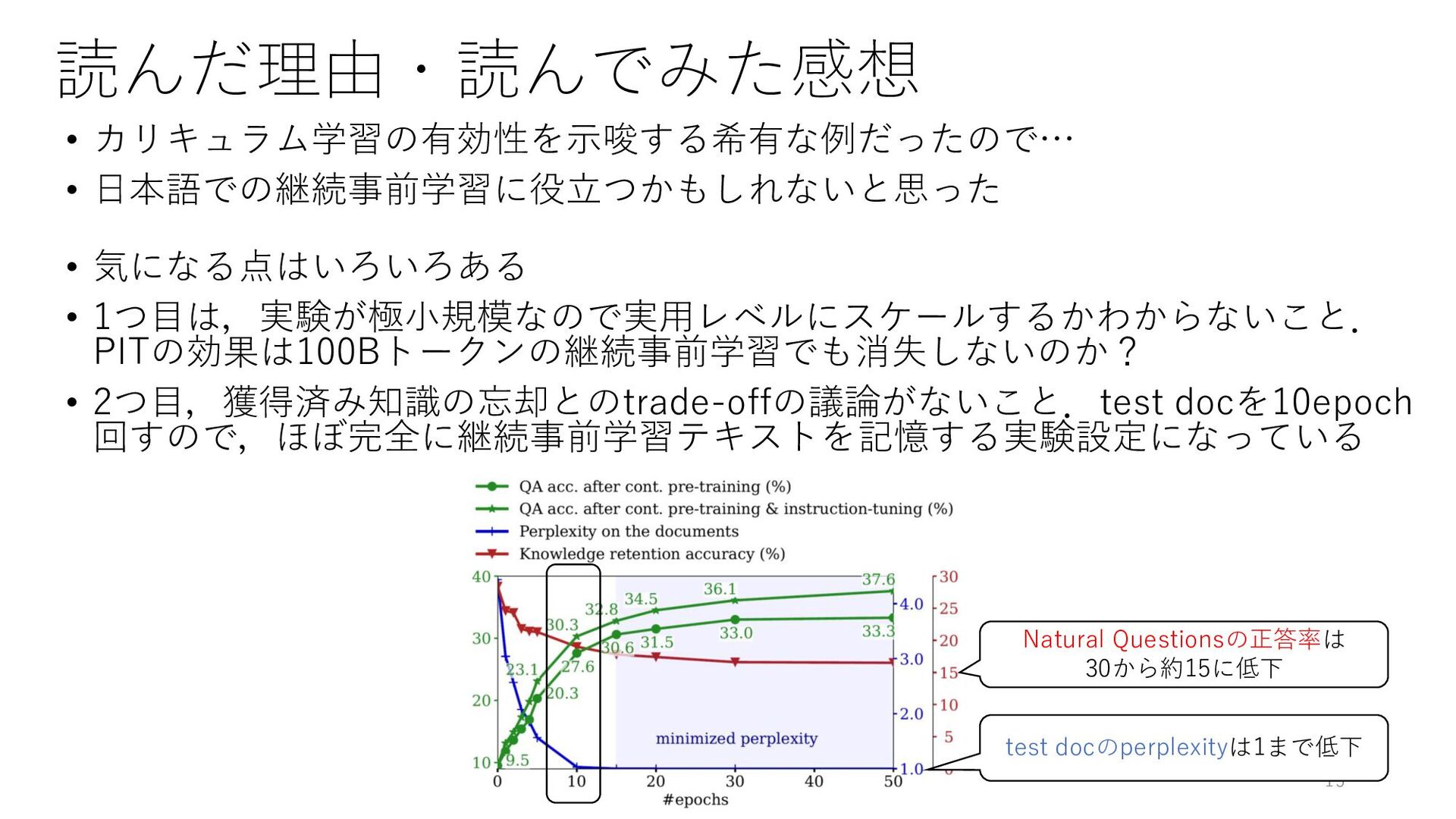
読んだ理由・読んでみた感想 • カリキュラム学習の有効性を示唆する希有な例だったので… • 日本語での継続事前学習に役立つかもしれないと思った • 気になる点はいろいろある • 1つ目は,実験が極小規模なので実用レベルにスケールするかわからないこと. PITの効果は100Bトークンの継続事前学習でも消失しないのか?
• 2つ目,獲得済み知識の忘却とのtrade-offの議論がないこと.test docを10epoch 回すので,ほぼ完全に継続事前学習テキストを記憶する実験設定になっている 15 test docのperplexityは1まで低下 Natural Questionsの正答率は 30から約15に低下
{kind=link}
{kind=link}
{kind=link}
![仮説 • LLMは事前学習テキストから知識をエンコードする • 質問応答(QA)による指示チューニングは知識の引き出し方を教える • [Sanh+, ICLR22][Wei+, ICLR22] など](https://files.speakerdeck.com/presentations/a2f9bc75bb094dd9a4211227af35d437/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}