「ML/DSバックグラウンドだからこそ面白い。AIエージェントをプロダクトに実装する、泥臭い裏側と挑戦」での登壇資料です。
https://layerx.connpass.com/event/379705/
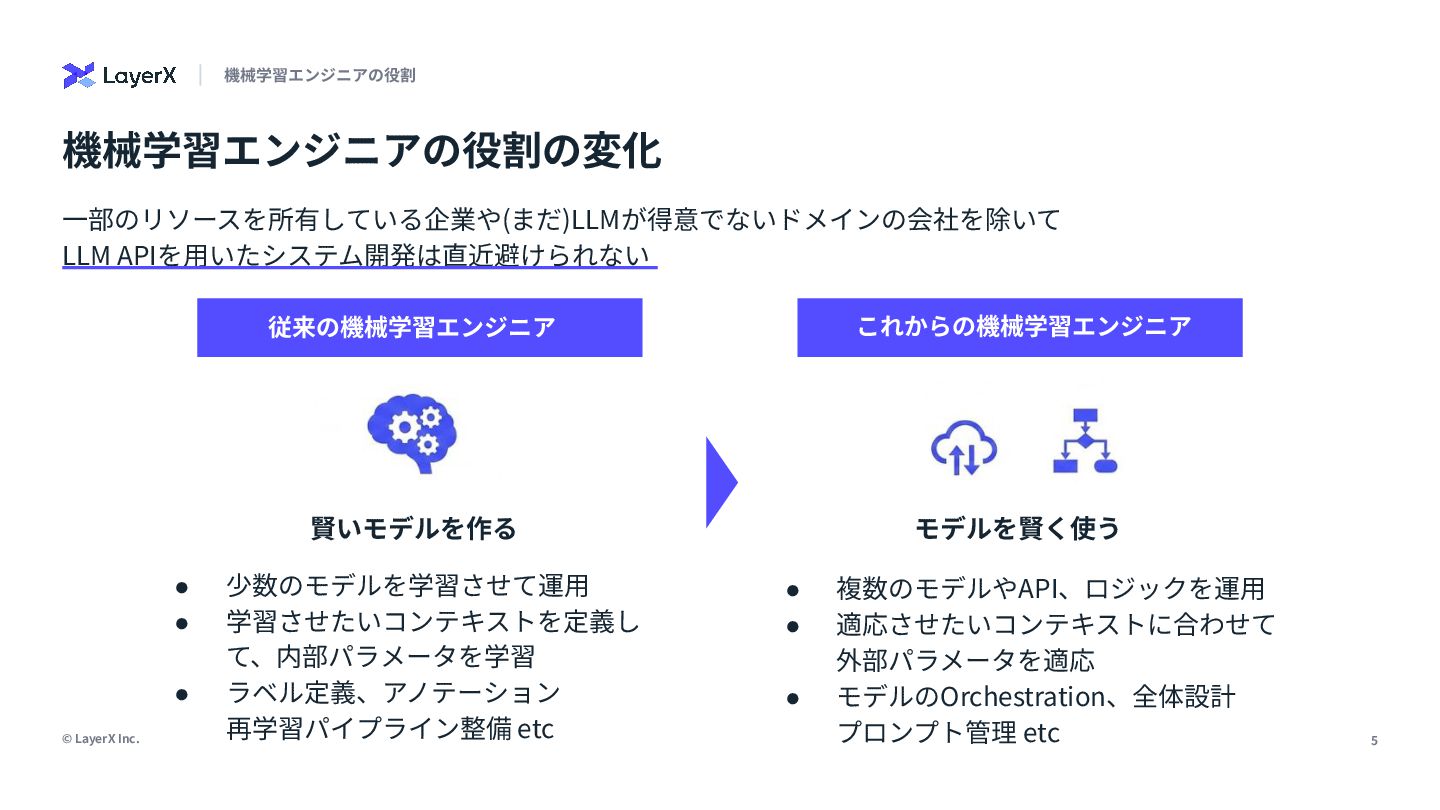
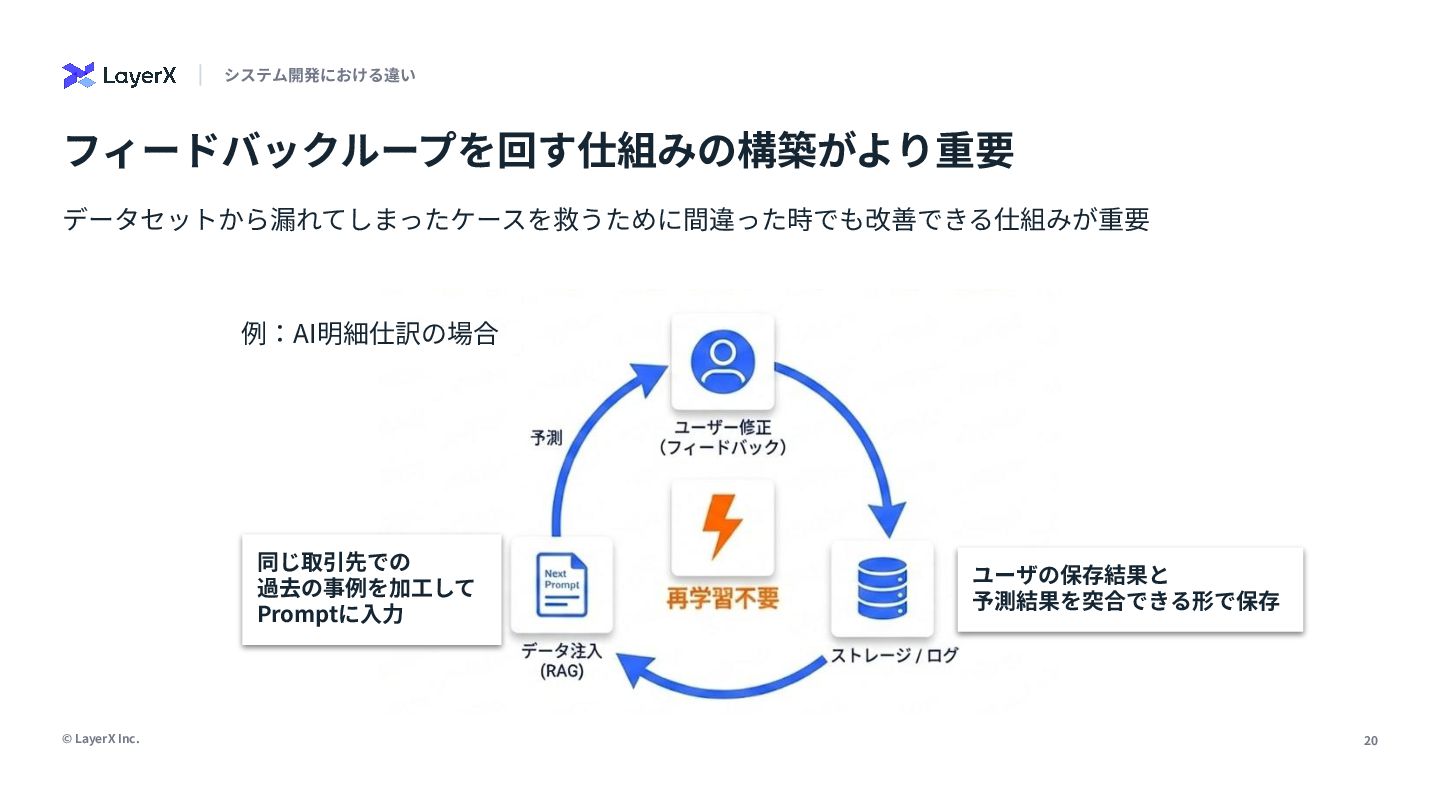
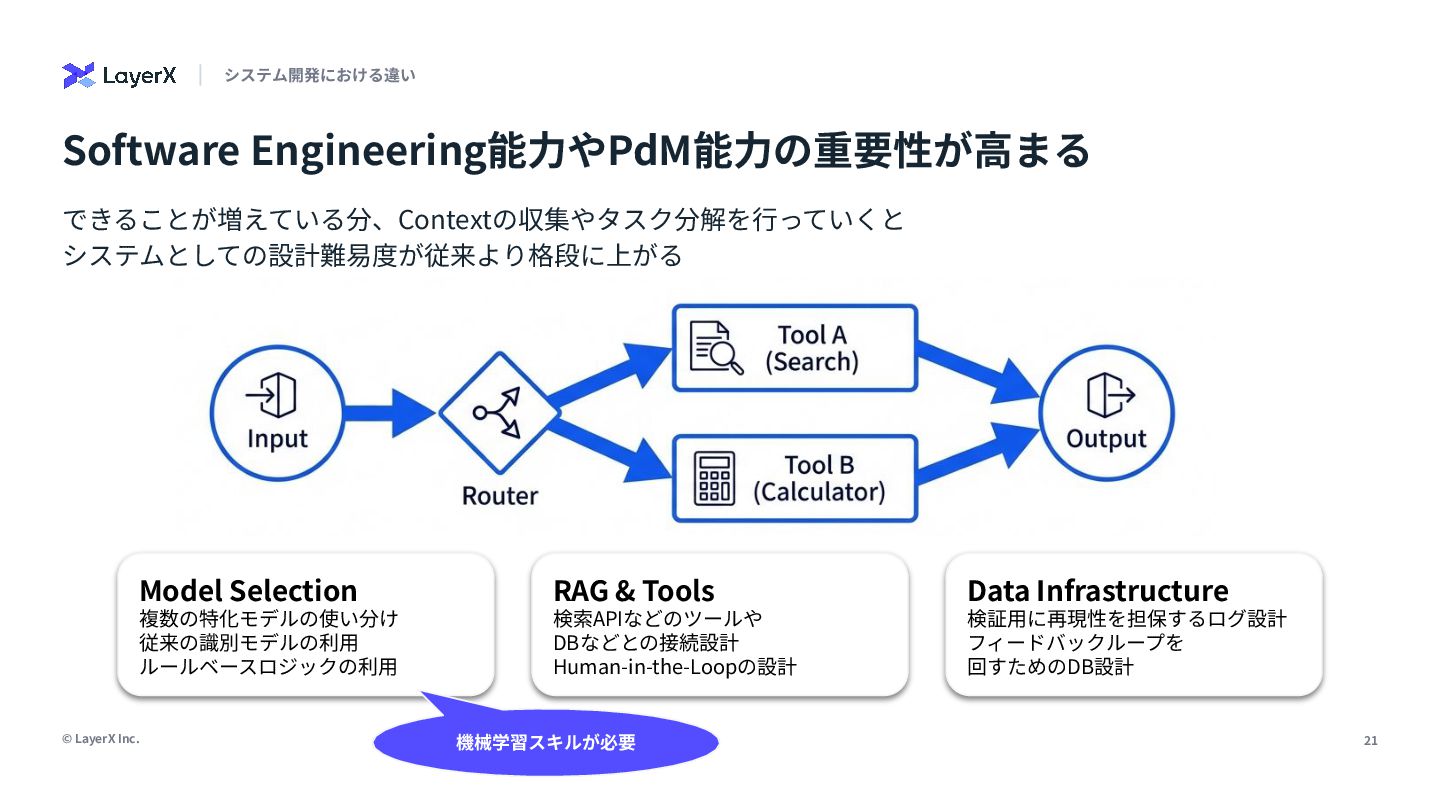
LLMの登場により、機械学習エンジニアの仕事は「賢いモデルを作る」ことから「モデルを賢く使う」ことに変化しつつあります。両者は一見全く違うスキルが必要になるように見えますが、実は従来の機械学習エンジニアとしての経験や勘所が活きる場面がたくさんあります。本発表では、発表者のAgent開発の実体験に基づき、従来の経験が武器になる領域と、逆に考え方やスキルの拡張が必要となる領域についてAI Agentの精度改善プロセスを元に話しました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
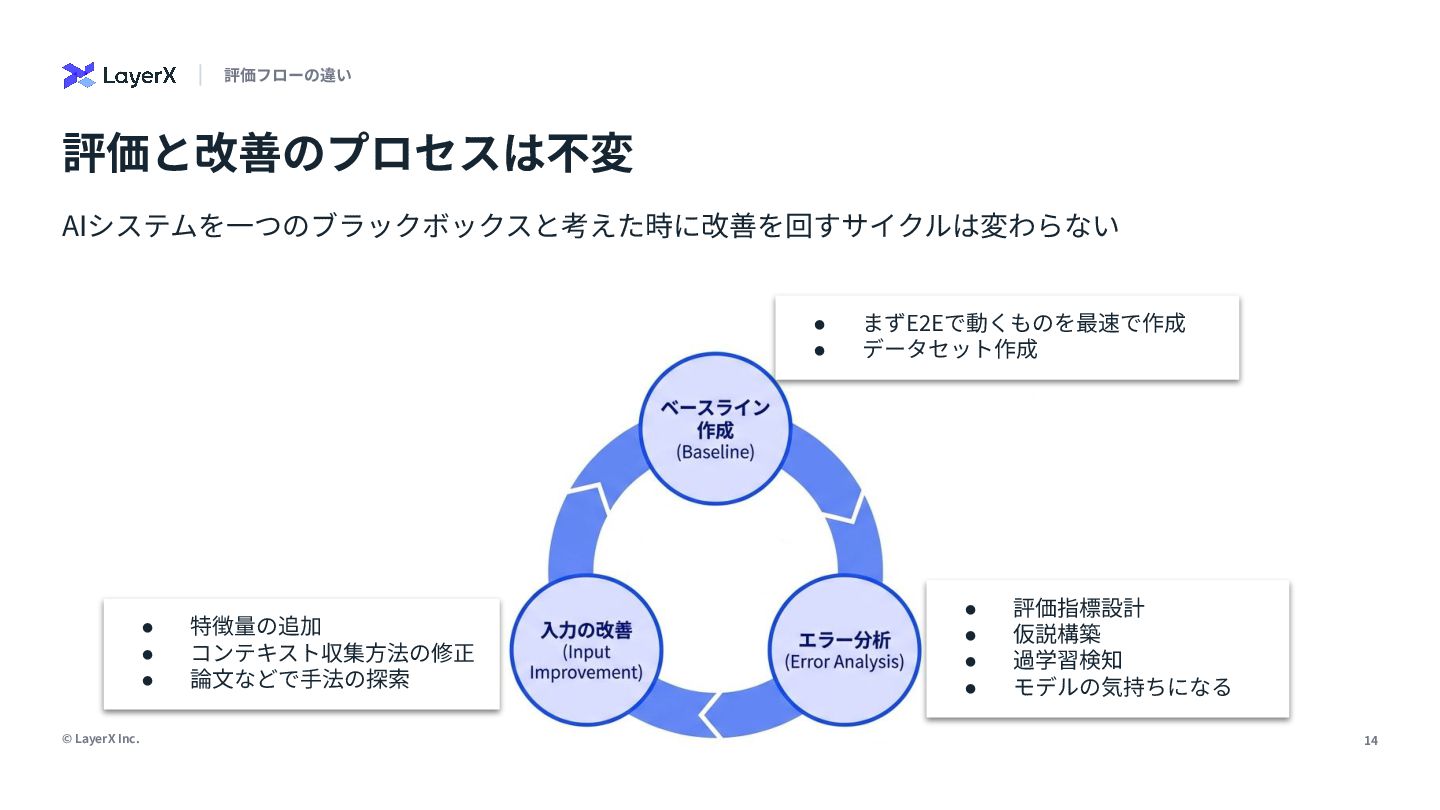{kind=link}
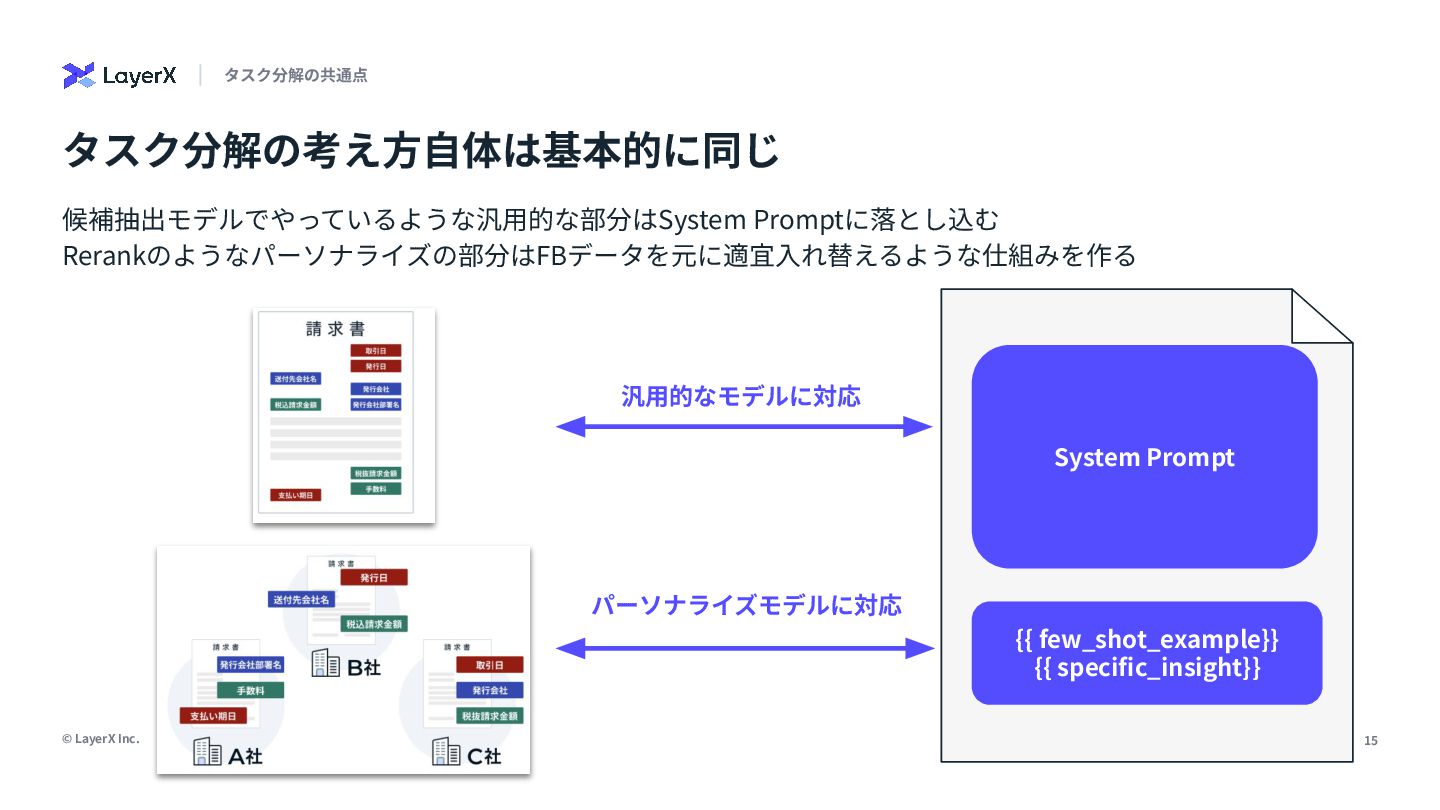{kind=link}
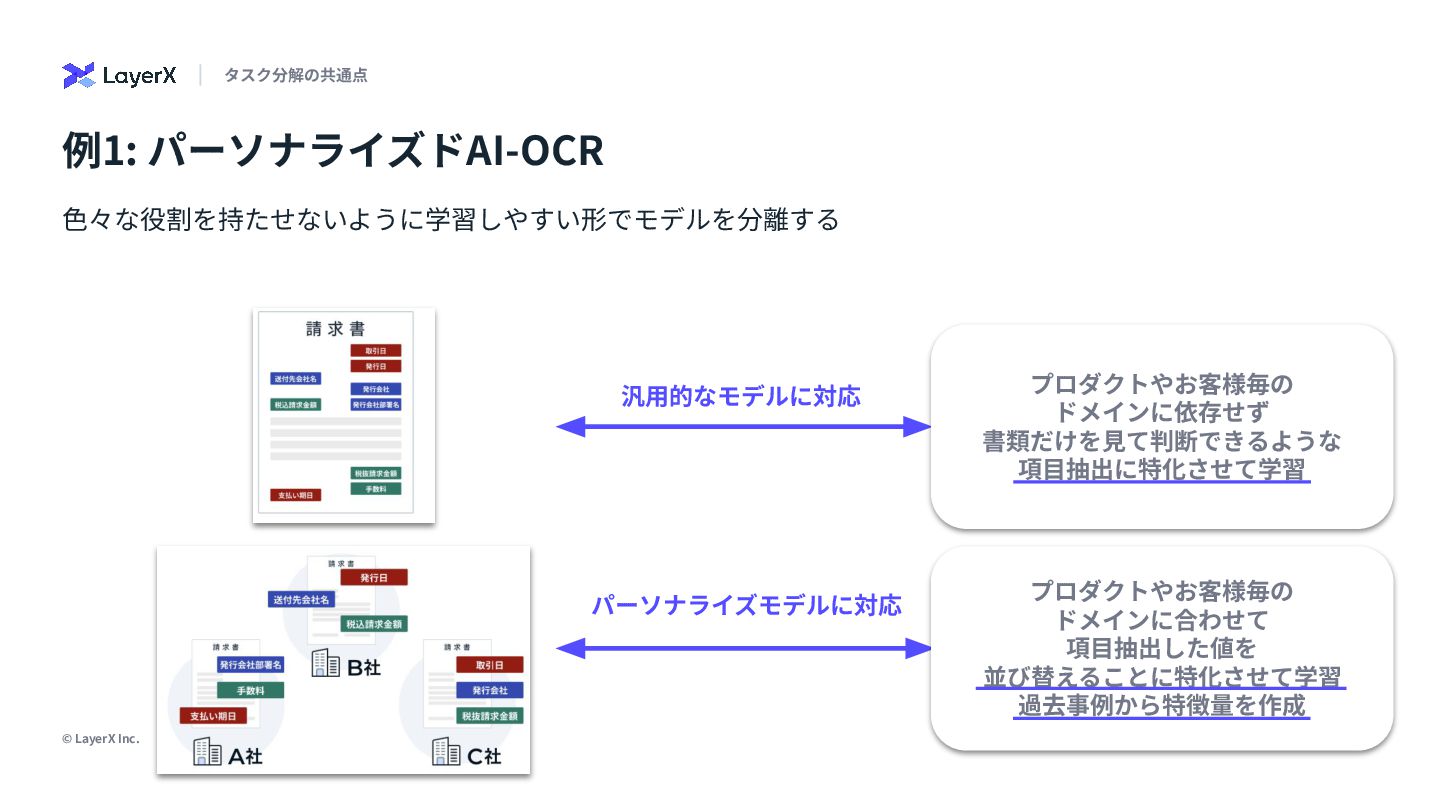{kind=link}
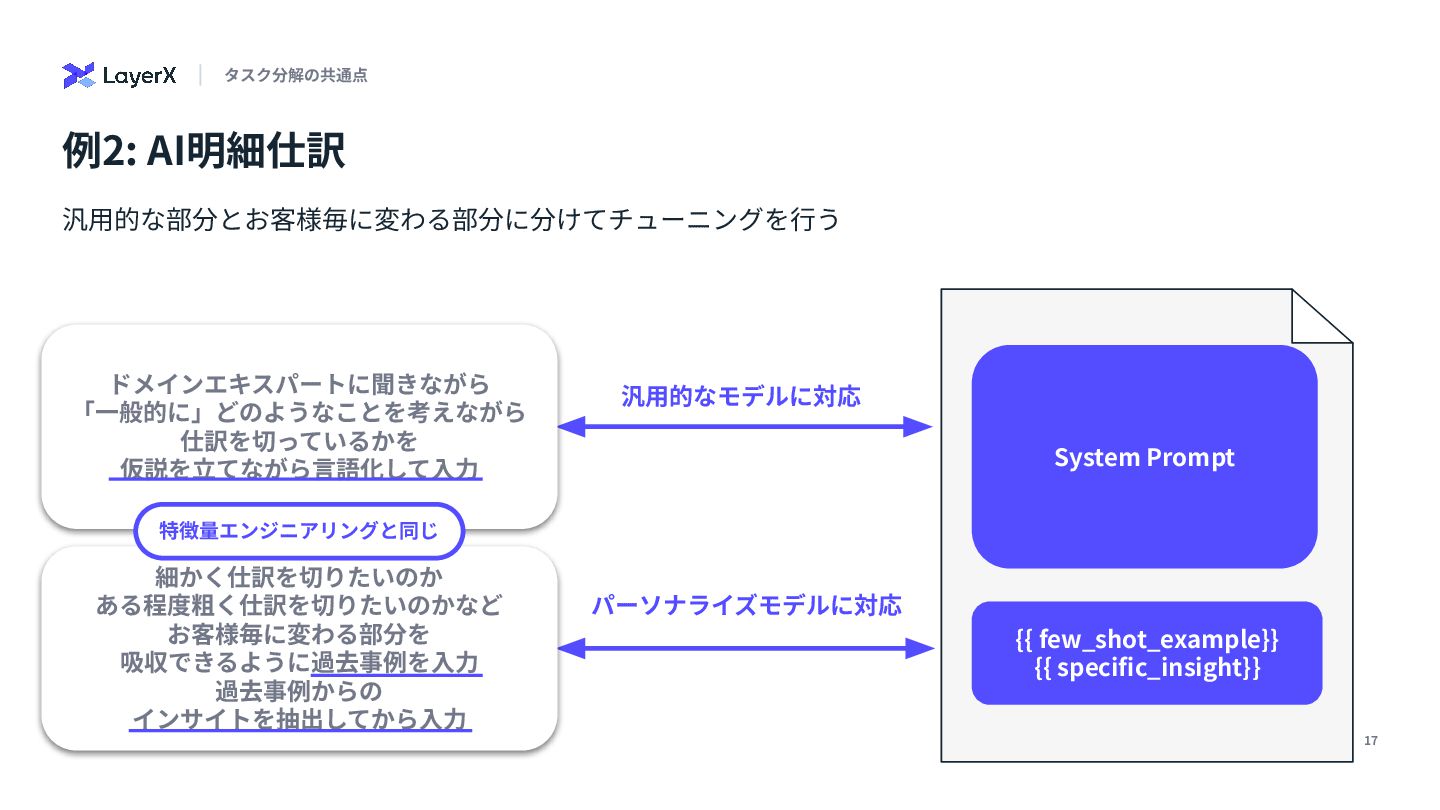{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}