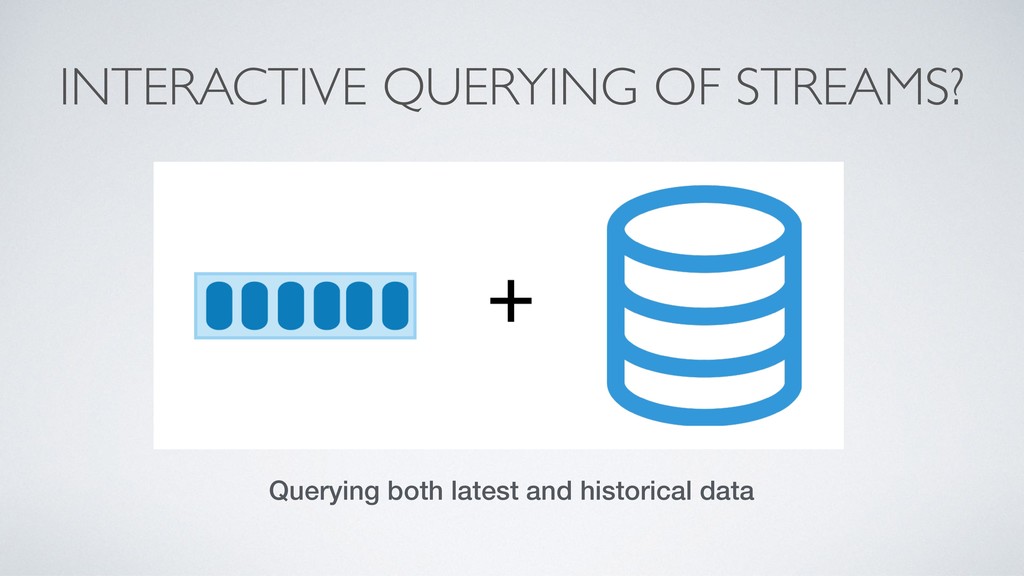
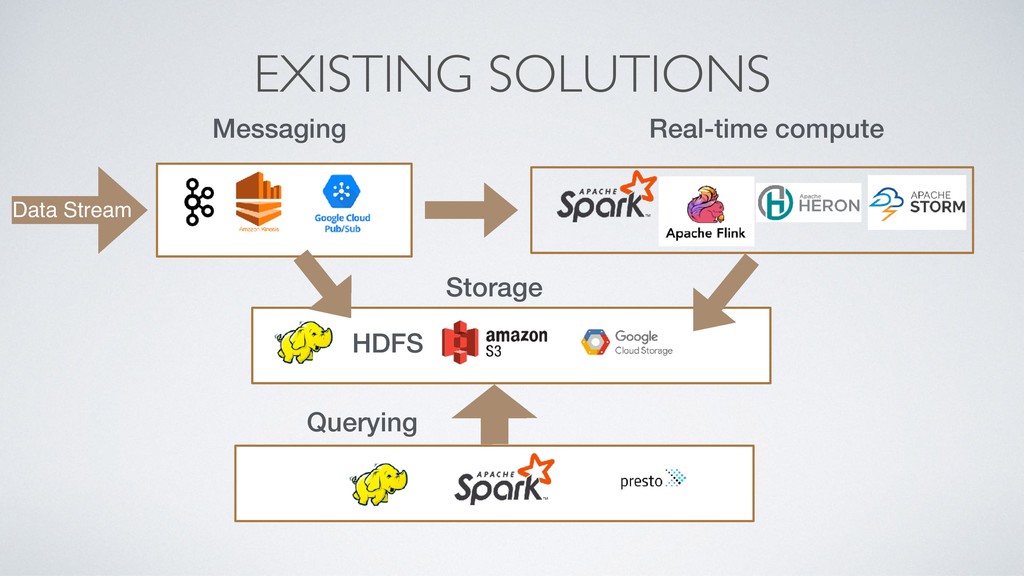
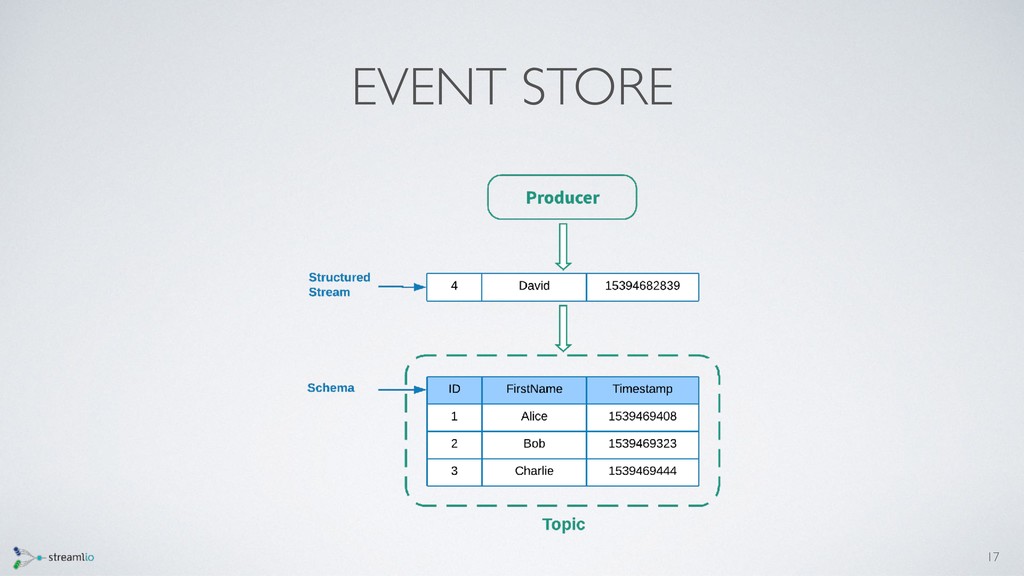
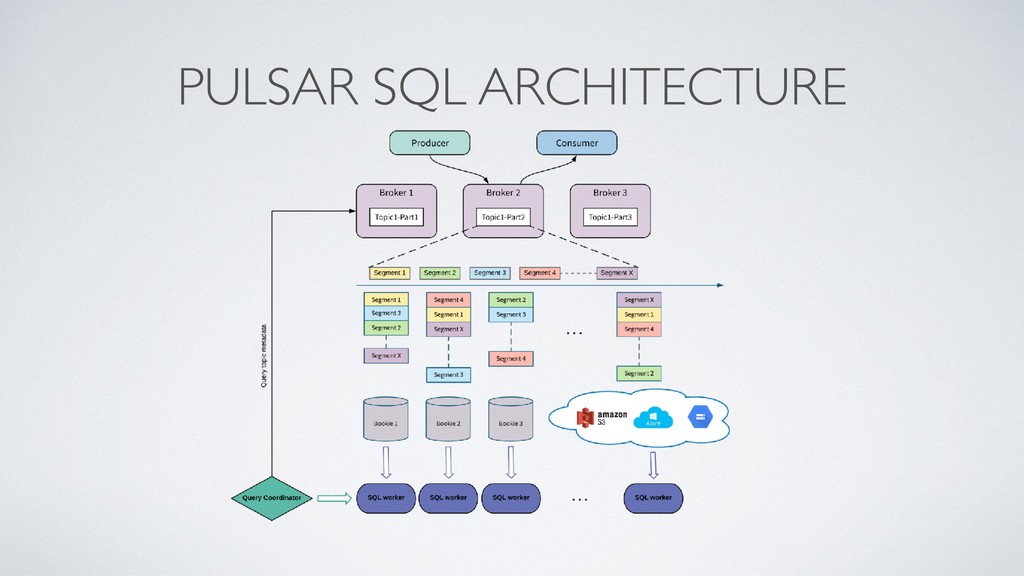
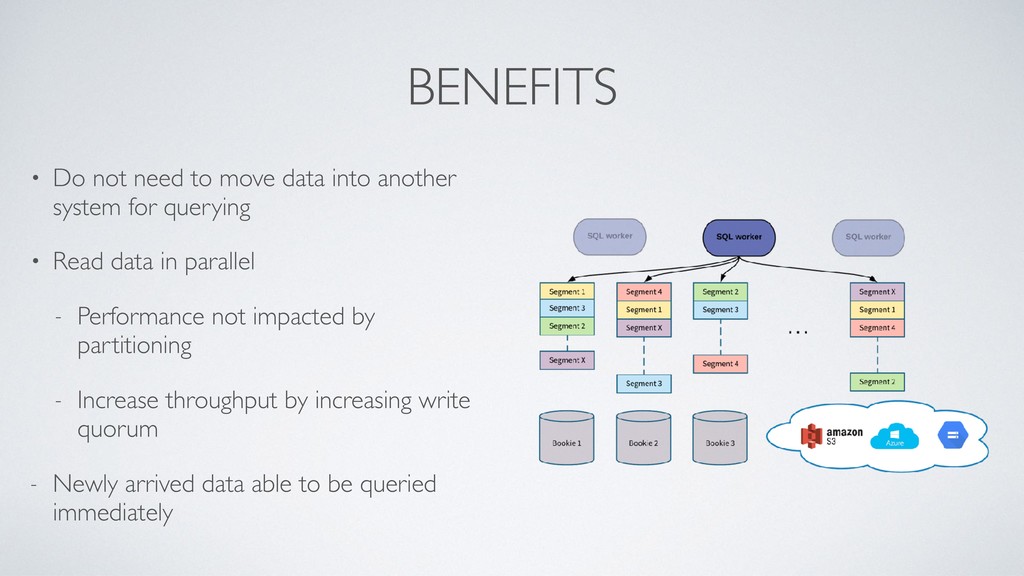
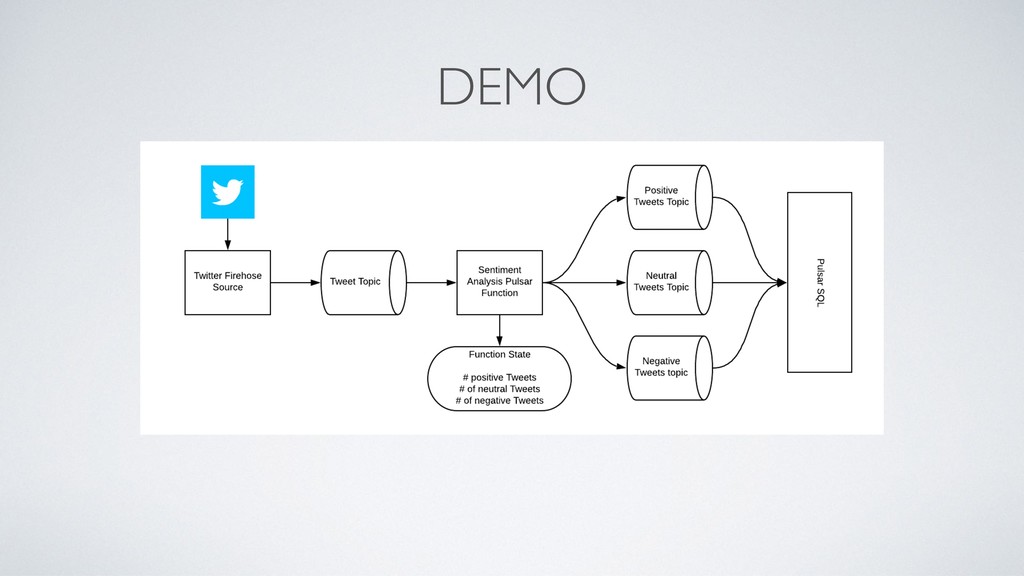
As applications become more reliant on real-time data, streaming/messaging platforms have become more and more popular and crucial to any data pipeline. Currently, many streaming/messaging platforms are only used to access the most recent events from streams of data, however, there is tremendous value that can be unlocked if the full history of streams can be queried in an interactive fashion. Pulsar SQL is a query layer built on top of Apache Pulsar (a next-gen messaging platform), that enables users to dynamically query all streams, old and new, stored inside of Pulsar. Thus, users can unlock insights from querying both new and historical streams of data in a single system. Pulsar SQL leverages Presto and Apache Pulsar’s unique architecture to execute queries in a highly scalable fashion regardless of the number of partitions of topics that make up the streams. In this talk, we will examine the use cases and advantages of being able to interactively query events within an streaming messaging platform and how Pulsar enables users to do that in the most user-friendly and efficient manner.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}