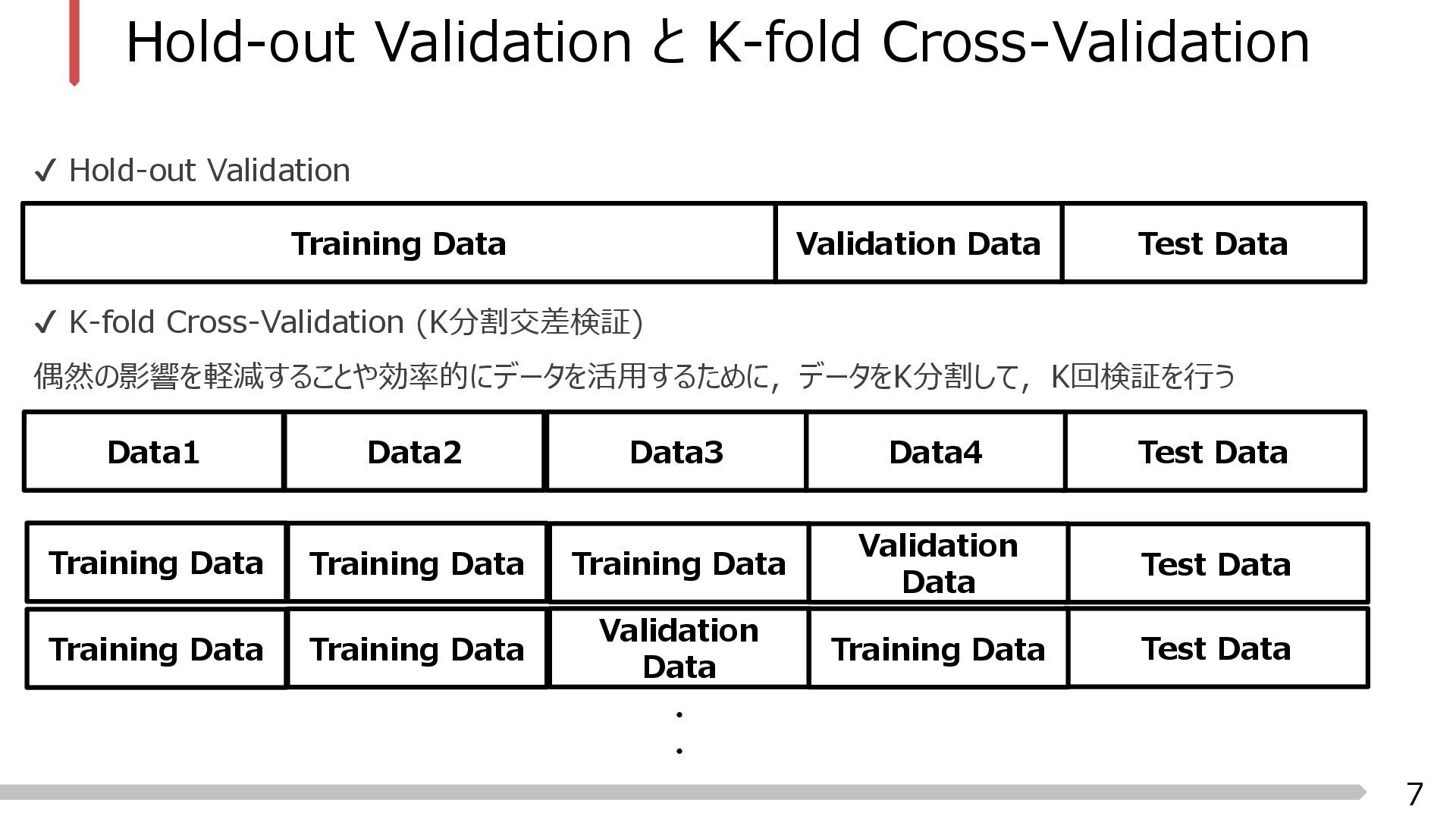
モデル選択,ハイパーパラメータの選択,モデルの過学習を抑制するなどの目的を達成するために,使用可 能なデータを訓練用データ (Training Data) と検証用データ (Validation Data) に分割して検証を行う Train Data Test Data Training Data Test Data Validation Data
K-fold Cross-Validation (K分割交差検証) 偶然の影響を軽減することや効率的にデータを活用するために,データをK分割して,K回検証を行う Training Data Test Data Validation Data Test Data Data4 Data3 Data2 Data1 Test Data Validation Data Training Data Training Data Training Data Test Data Training Data Validation Data Training Data Training Data ・ ・
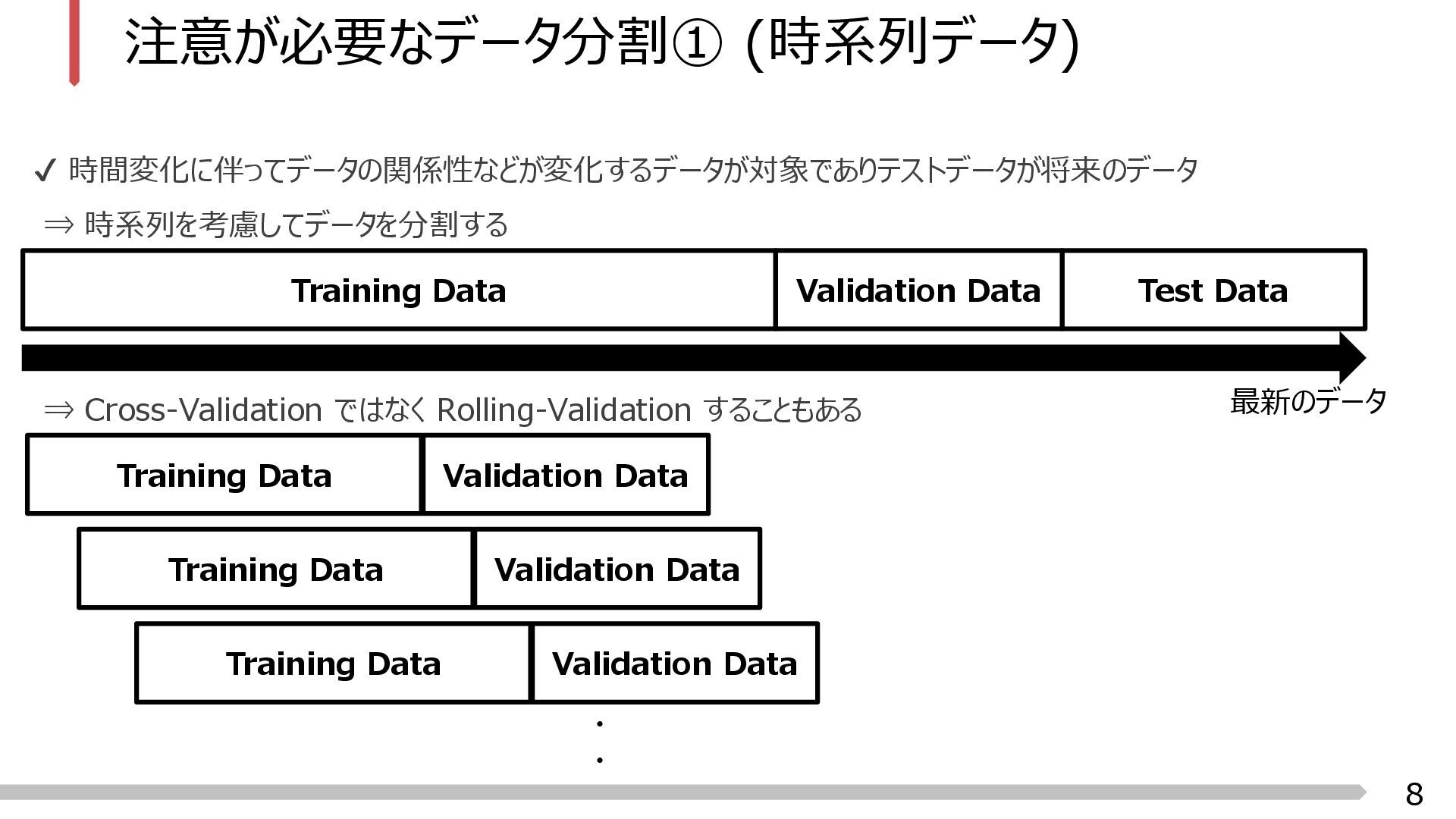
Rolling-Validation することもある Training Data Test Data Validation Data Training Data Validation Data Training Data Validation Data Training Data Validation Data ・ ・ 最新のデータ
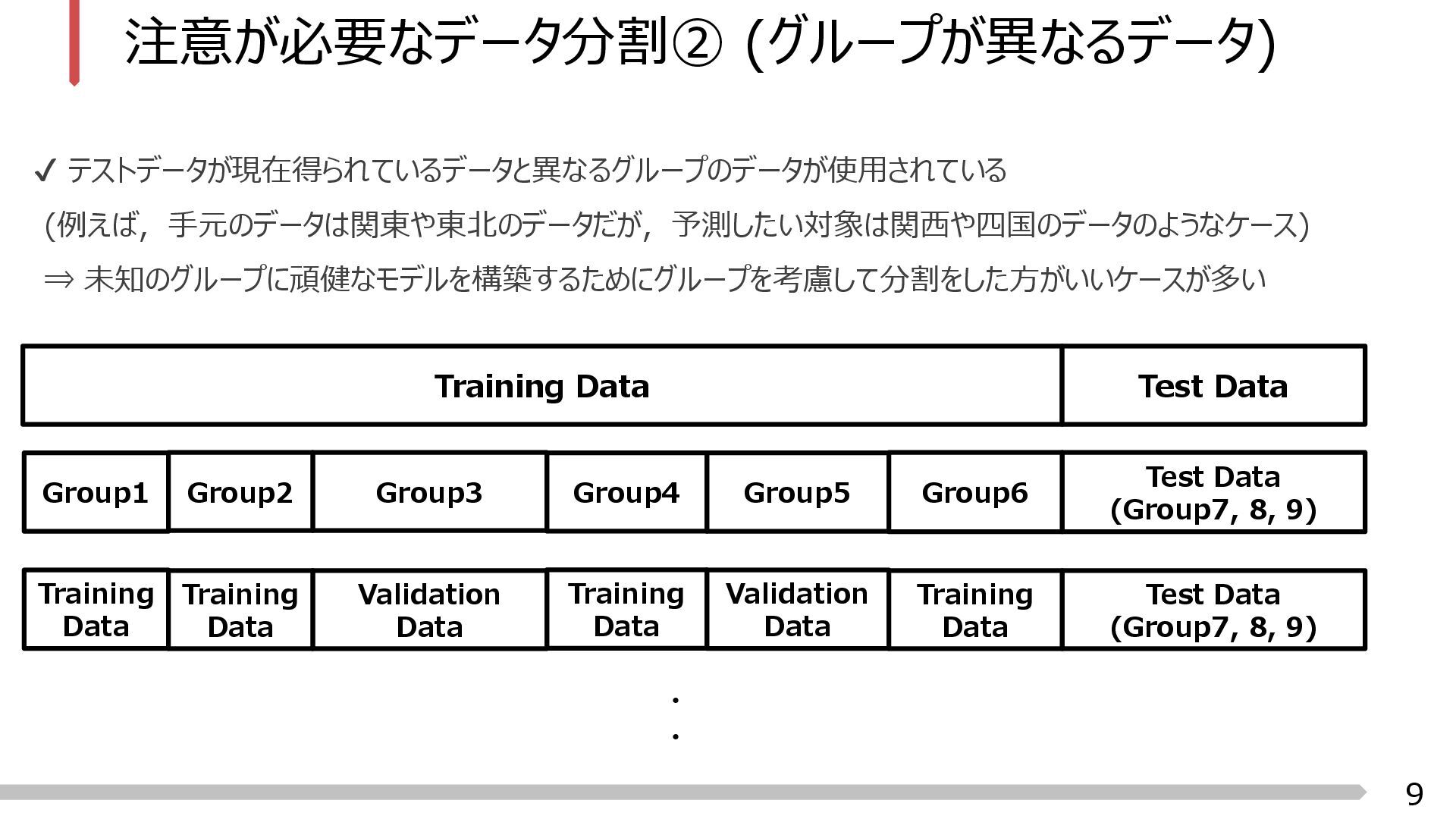
Test Data ・ ・ Test Data (Group7, 8, 9) Group5 Group4 Group3 Group1 Group2 Group6 Test Data (Group7, 8, 9) Validation Data Training Data Validation Data Training Data Training Data Training Data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
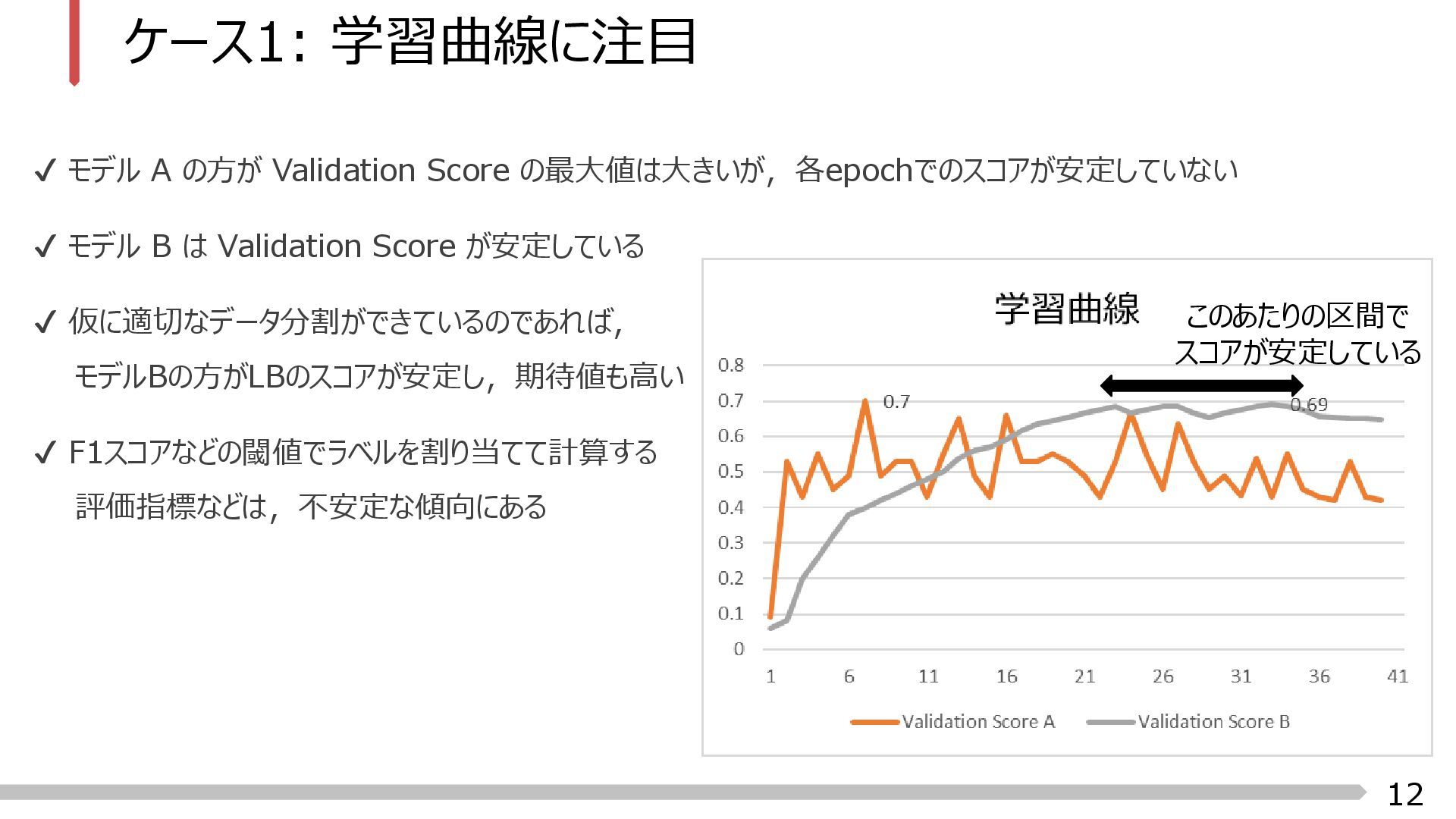
{kind=link}
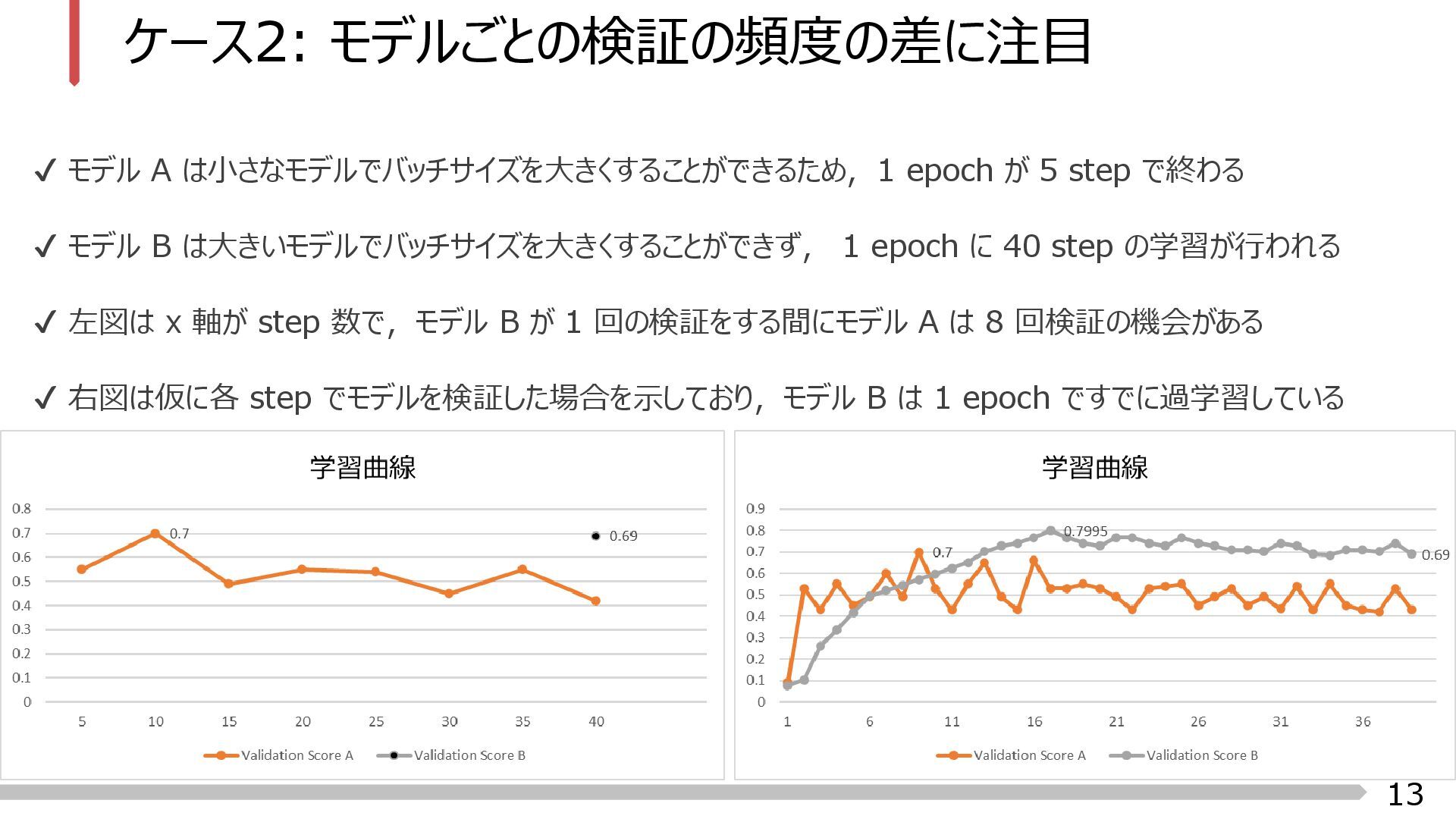
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}