DeNA, Mobility TechnologiesのAI勉強会で発表した資料です
・顔認識分野周りってどんな感じなの
・特に、最近のArcFaceまわりの手法どうなってきてるの
紹介論文:
AdaptiveFace (CVPR’19)
AdaCos (CVPR’19)
(MV-ArcFace (AAAI’20))
CurricularFace (CVPR’20)
GroupFace (CVPR’20)
Sub-center ArcFace (ECCV’20)
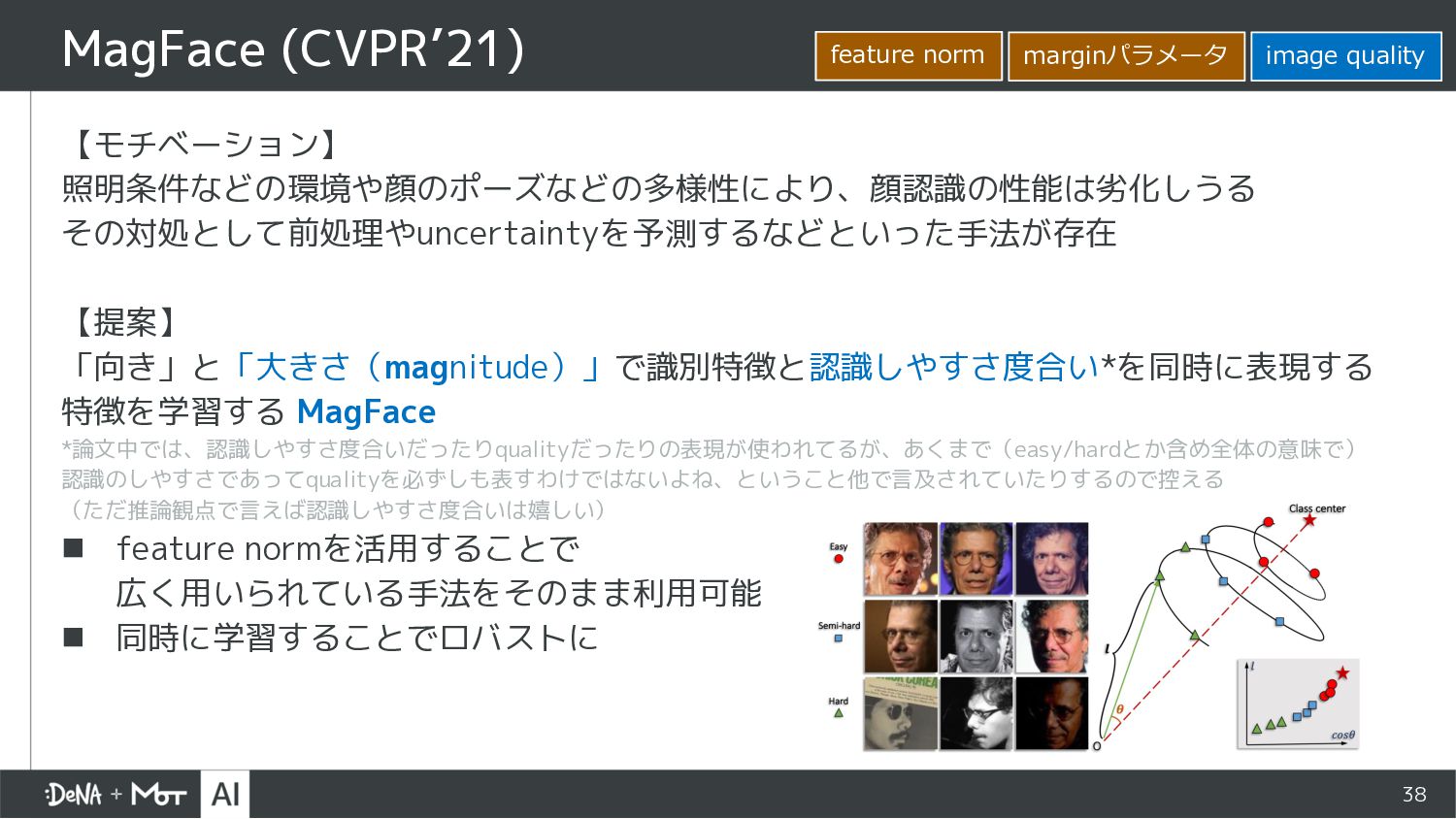
MagFace (CVPR’21)
ElasticFace (CVPRW’22)
AdaFace (CVPR’22)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![顔認識手法のざっくりとした流れ *Deep Face Recognition: A Survey [M. Wang+, 2018] 2020年8月にv9へ更新されている](https://files.speakerdeck.com/presentations/f811d33eff78492c9dcdfecd9e440c91/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}