本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
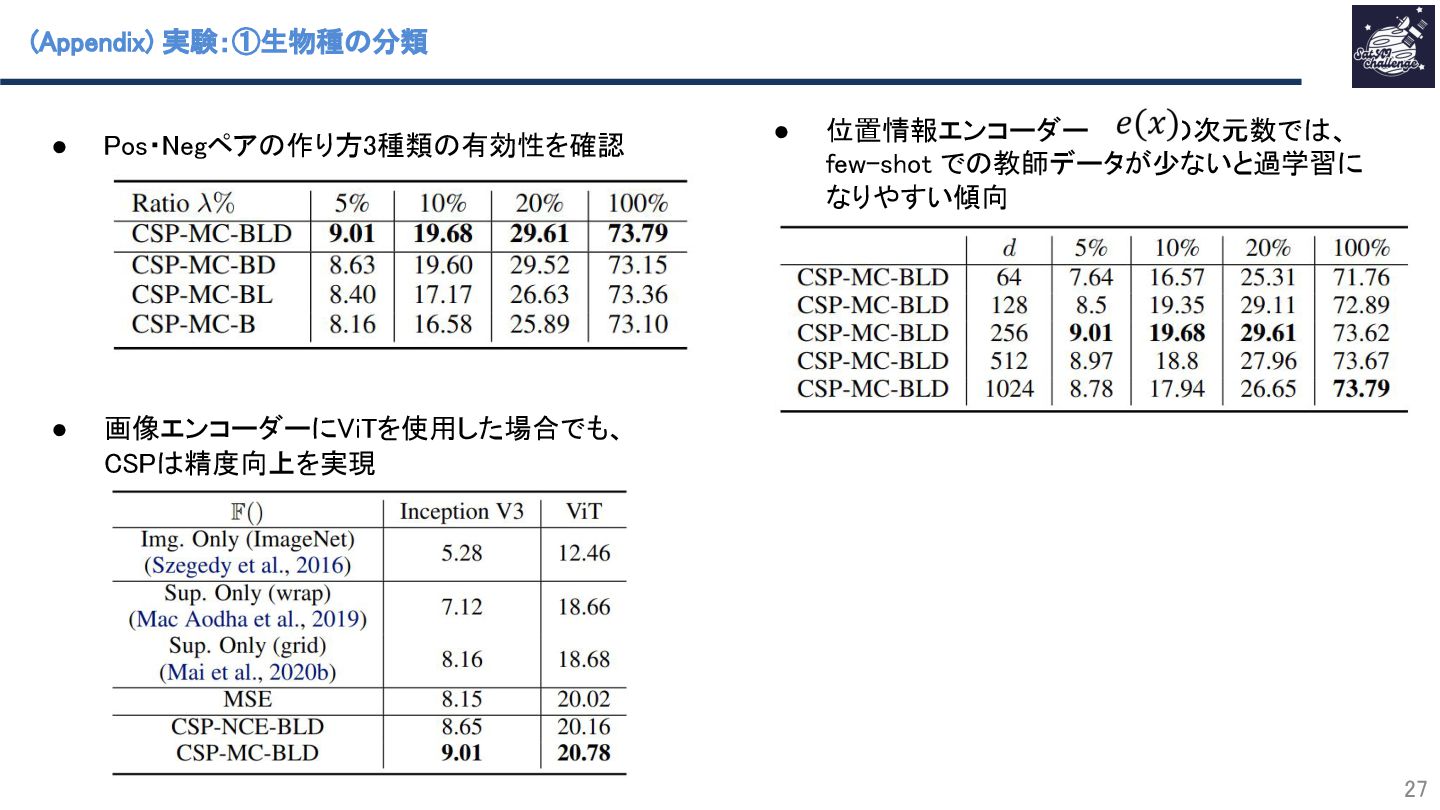
紹介する論文は「CSP: Self-Supervised Contrastive Spatial Pre-Training for Geospatial-Visual Representations」です。地球上の位置情報(緯度、経度)と、対応する画像の埋め込み特徴ペアを学習する自己教師あり事前学習を提案しています。これにより、テストデータ推論時に画像特徴と位置情報をマルチモーダルとして入力可能となり、推論の精度向上が期待できます。また、大量のラベルなしデータを学習することでラベル付きデータが少量の場合でも高精度な推論を可能にします。実験では、従来手法としてシングルモダリティ(画像のみ入力)やラベルなしデータを用いない場合と比較して最大34%の精度向上を実現しました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
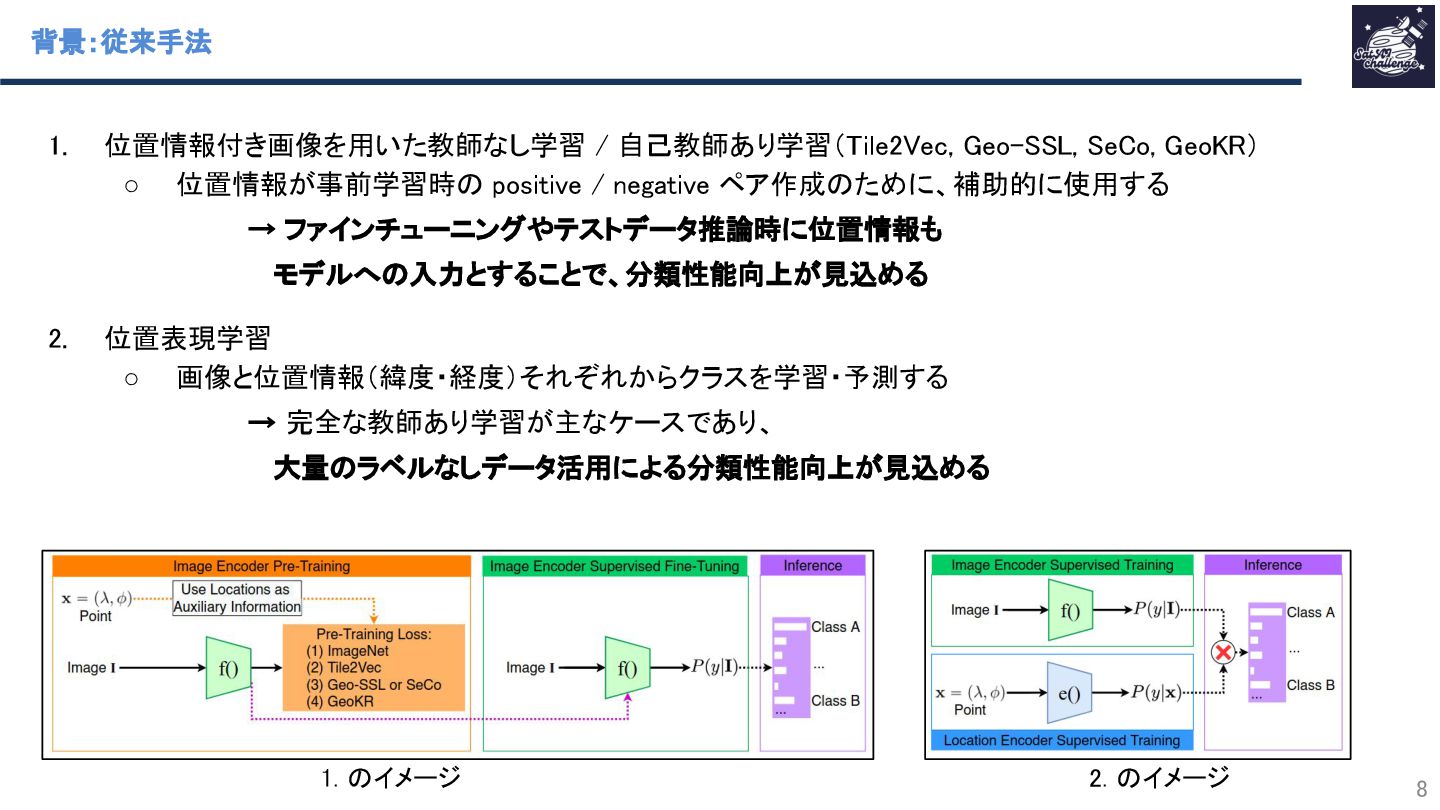{kind=link}
{kind=link}
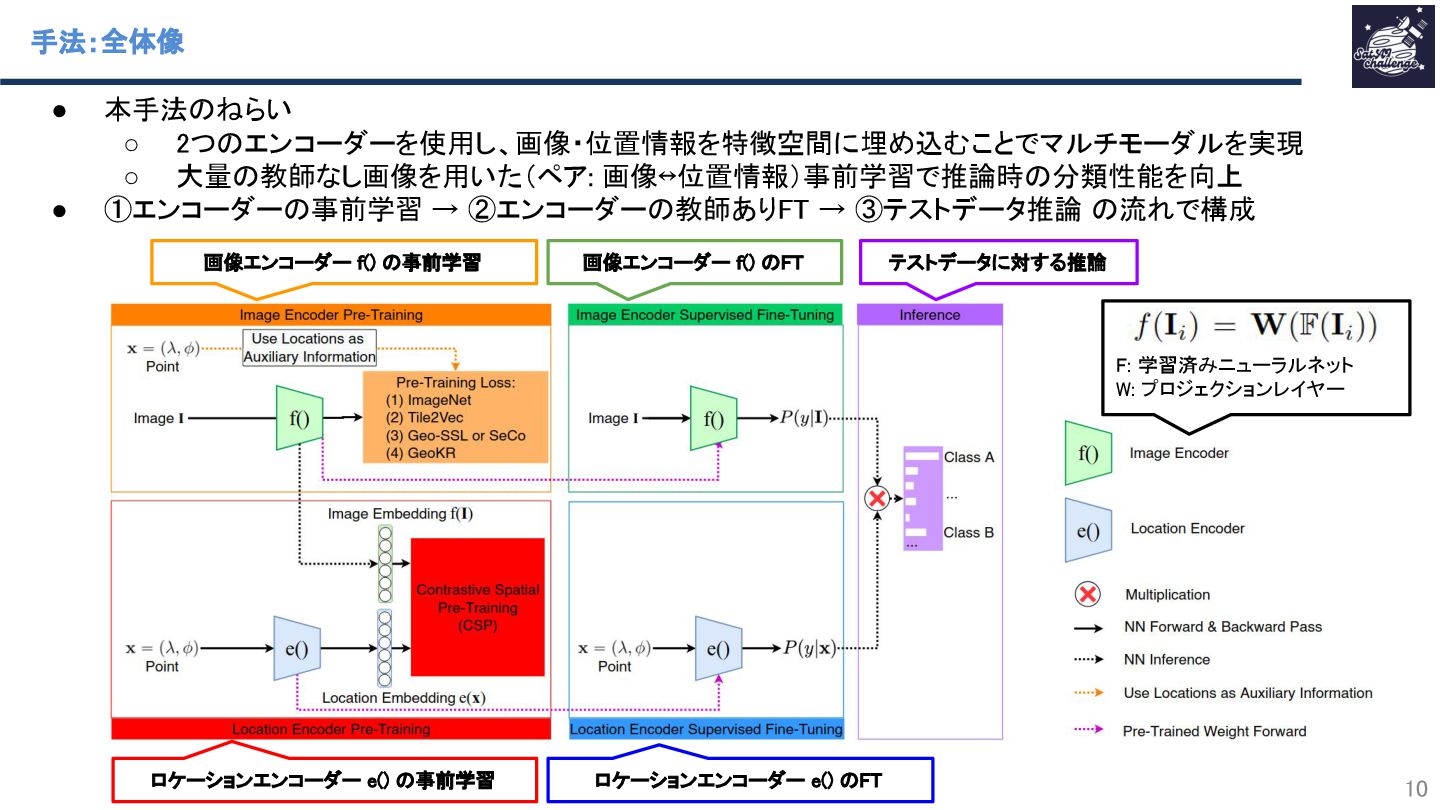{kind=link}
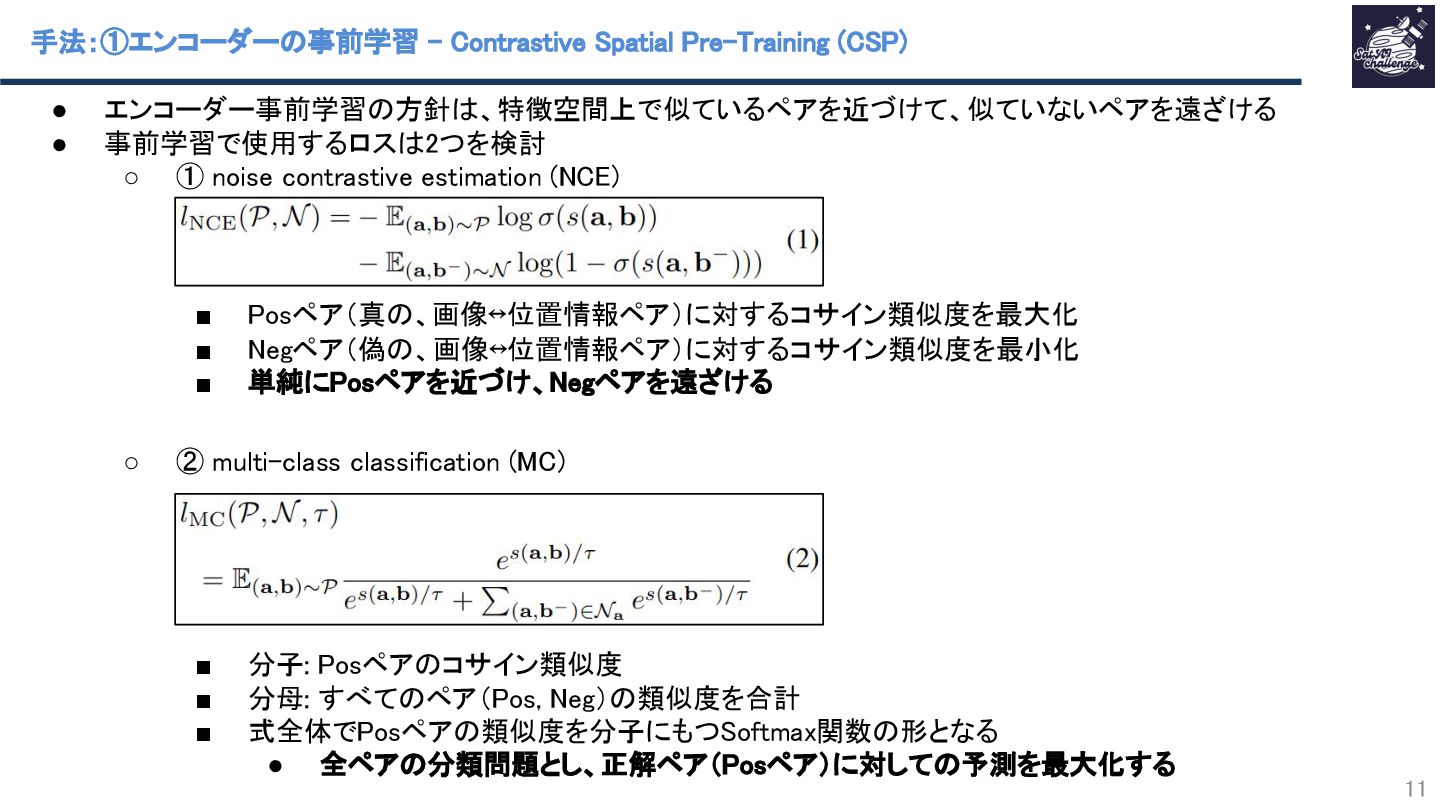{kind=link}
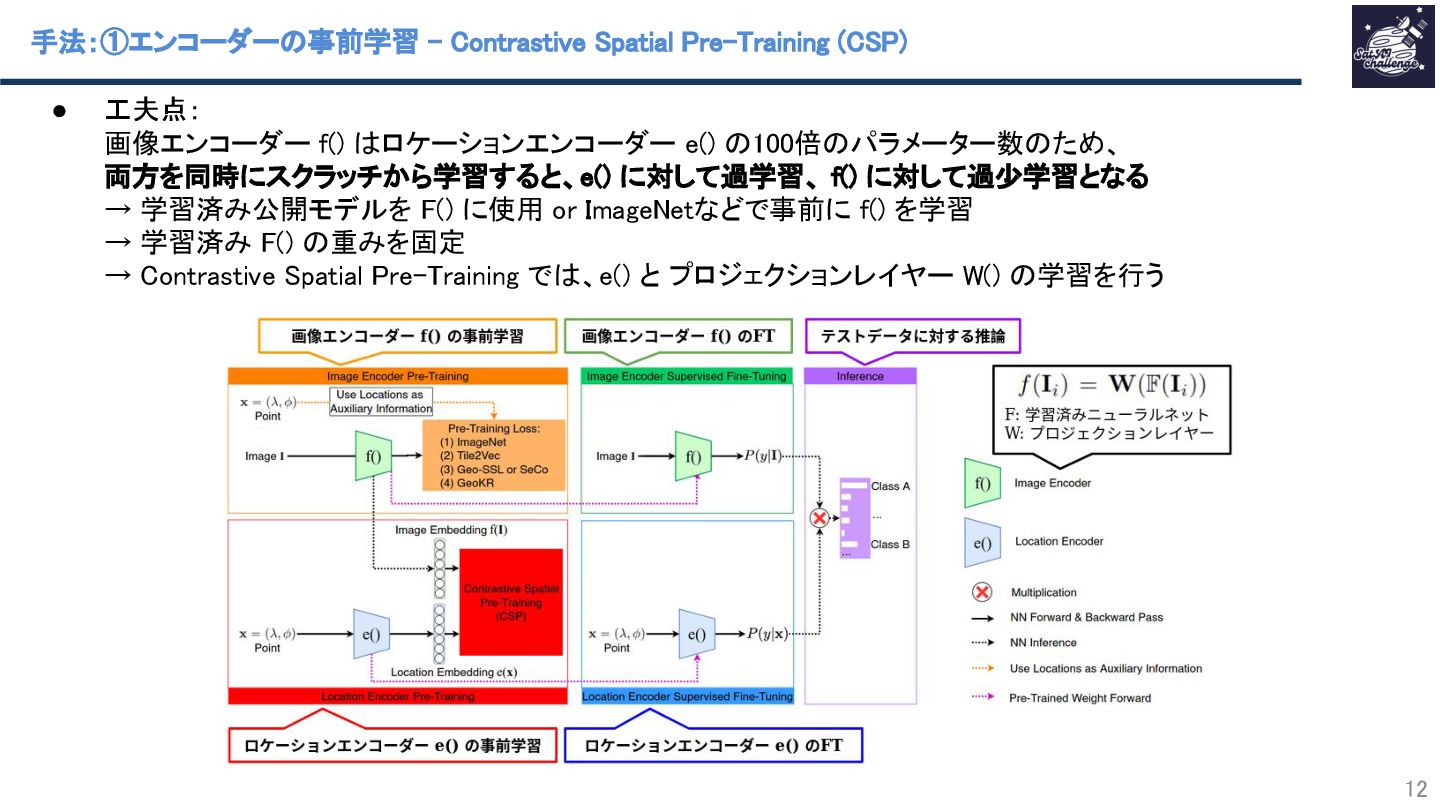{kind=link}
{kind=link}
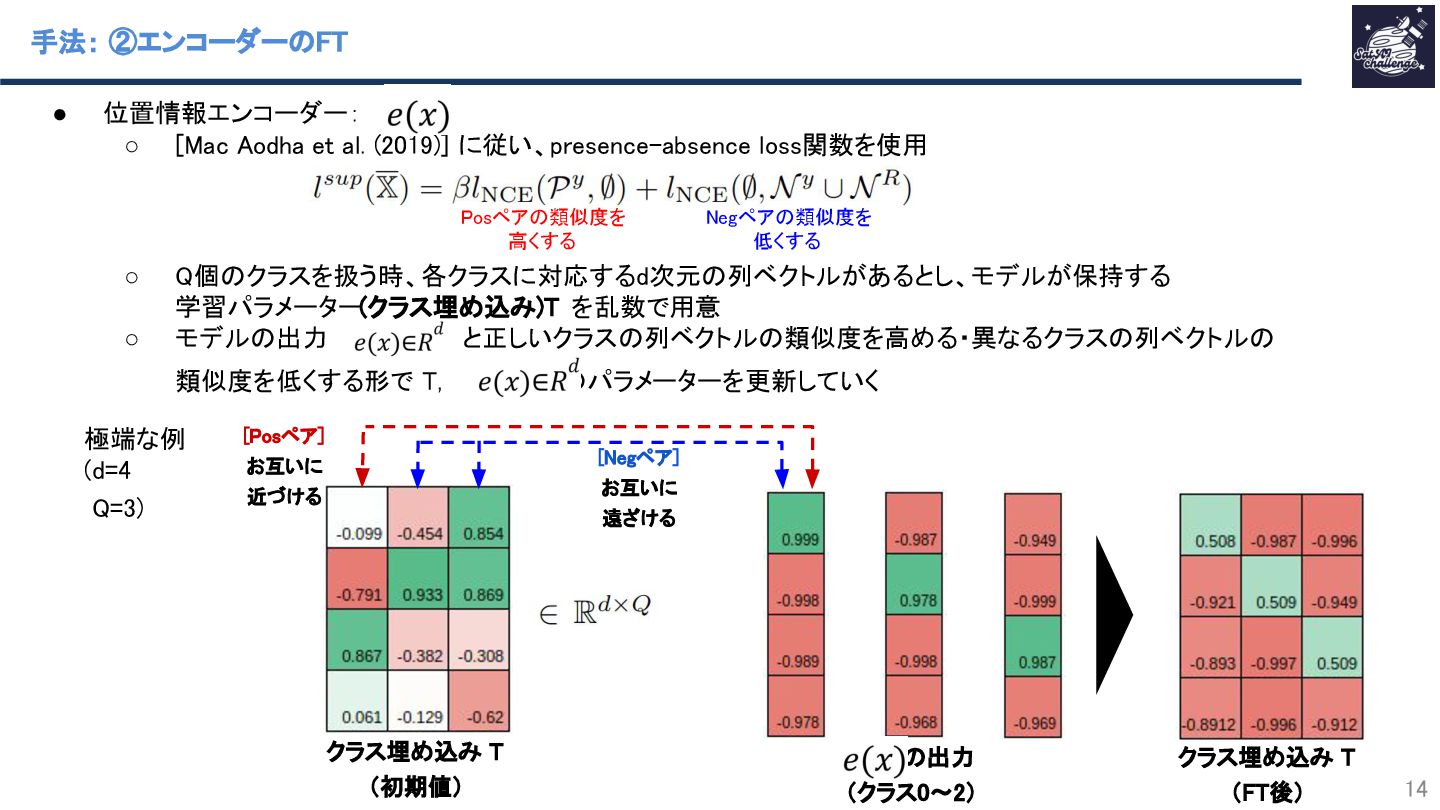{kind=link}
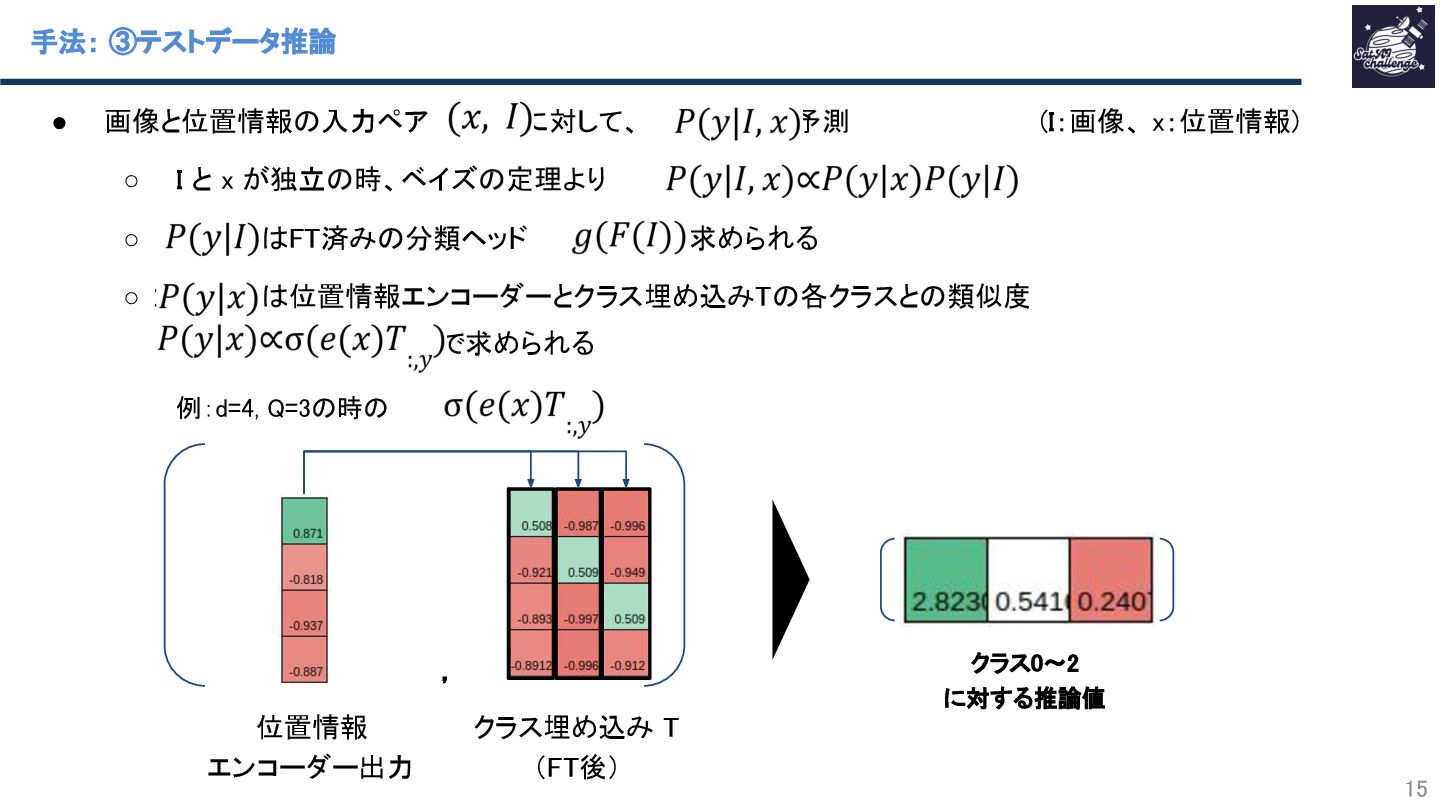{kind=link}
{kind=link}
{kind=link}
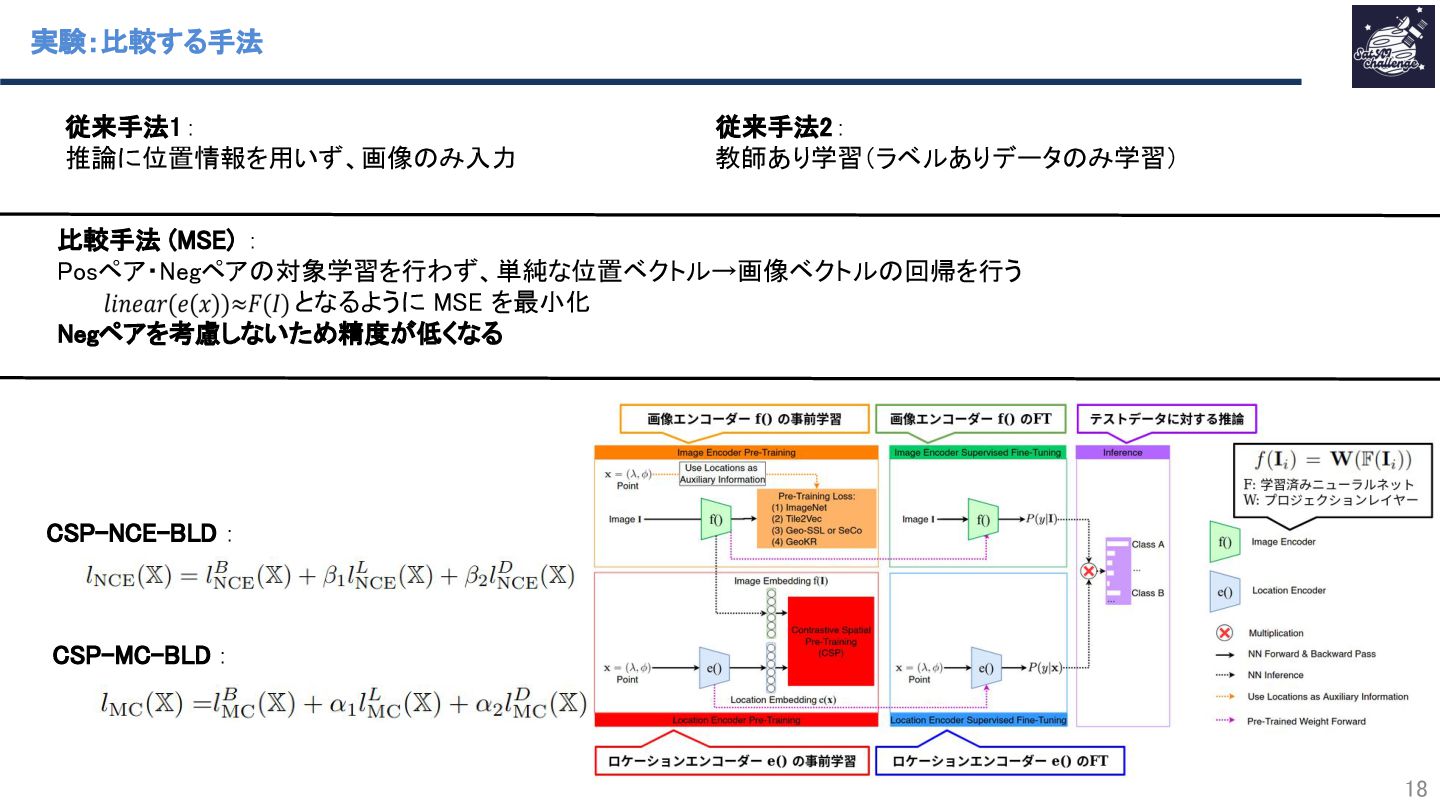{kind=link}
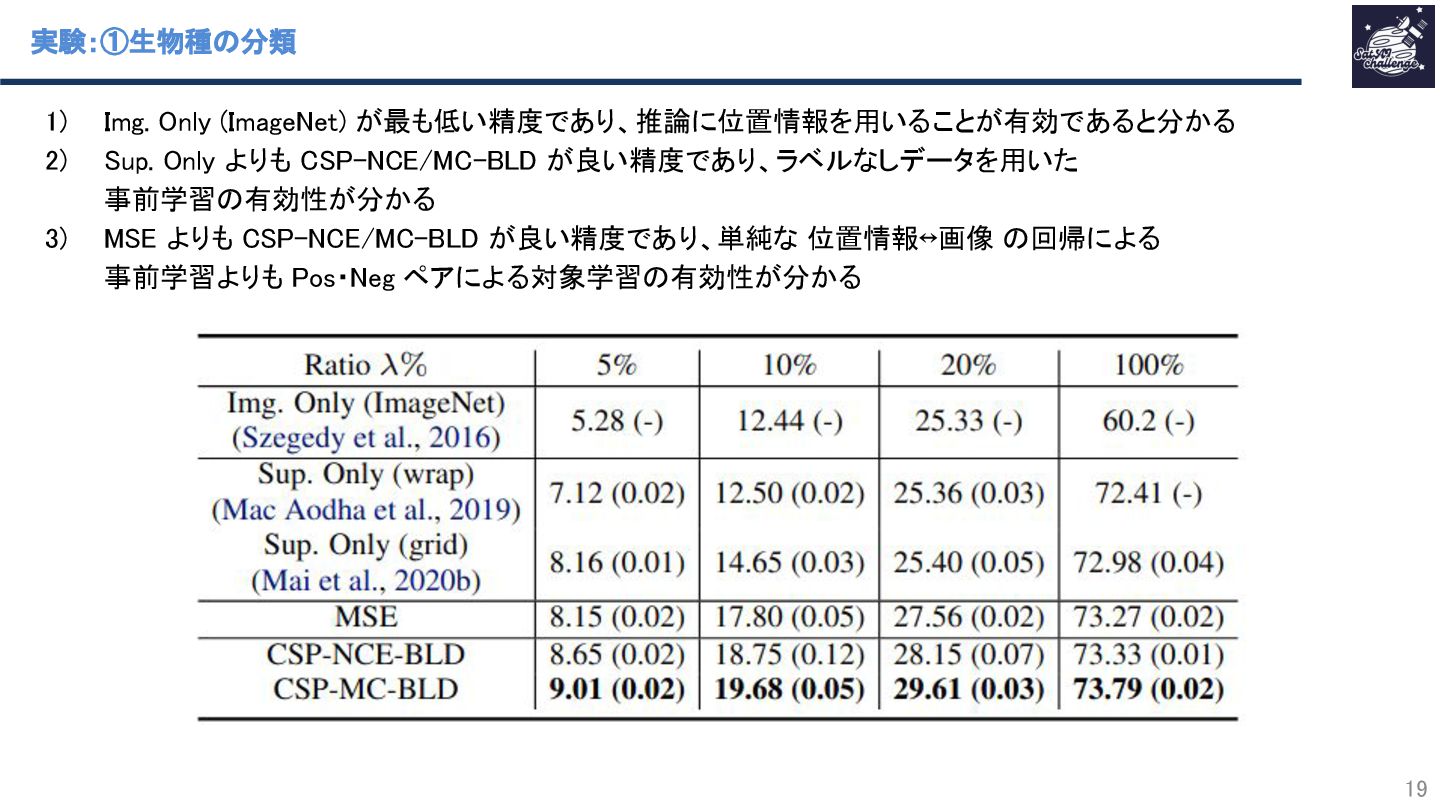{kind=link}
{kind=link}
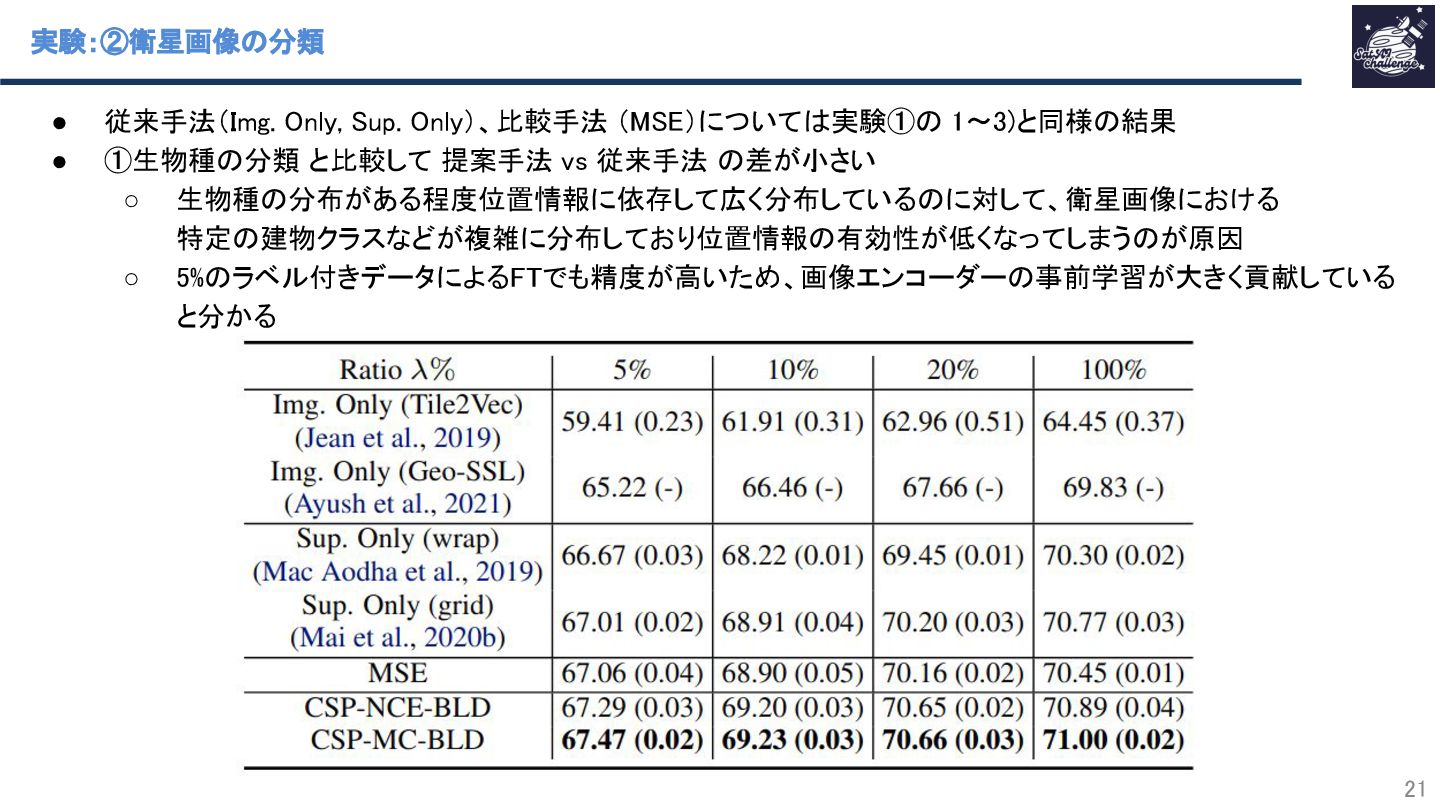{kind=link}
{kind=link}
{kind=link}
{kind=link}
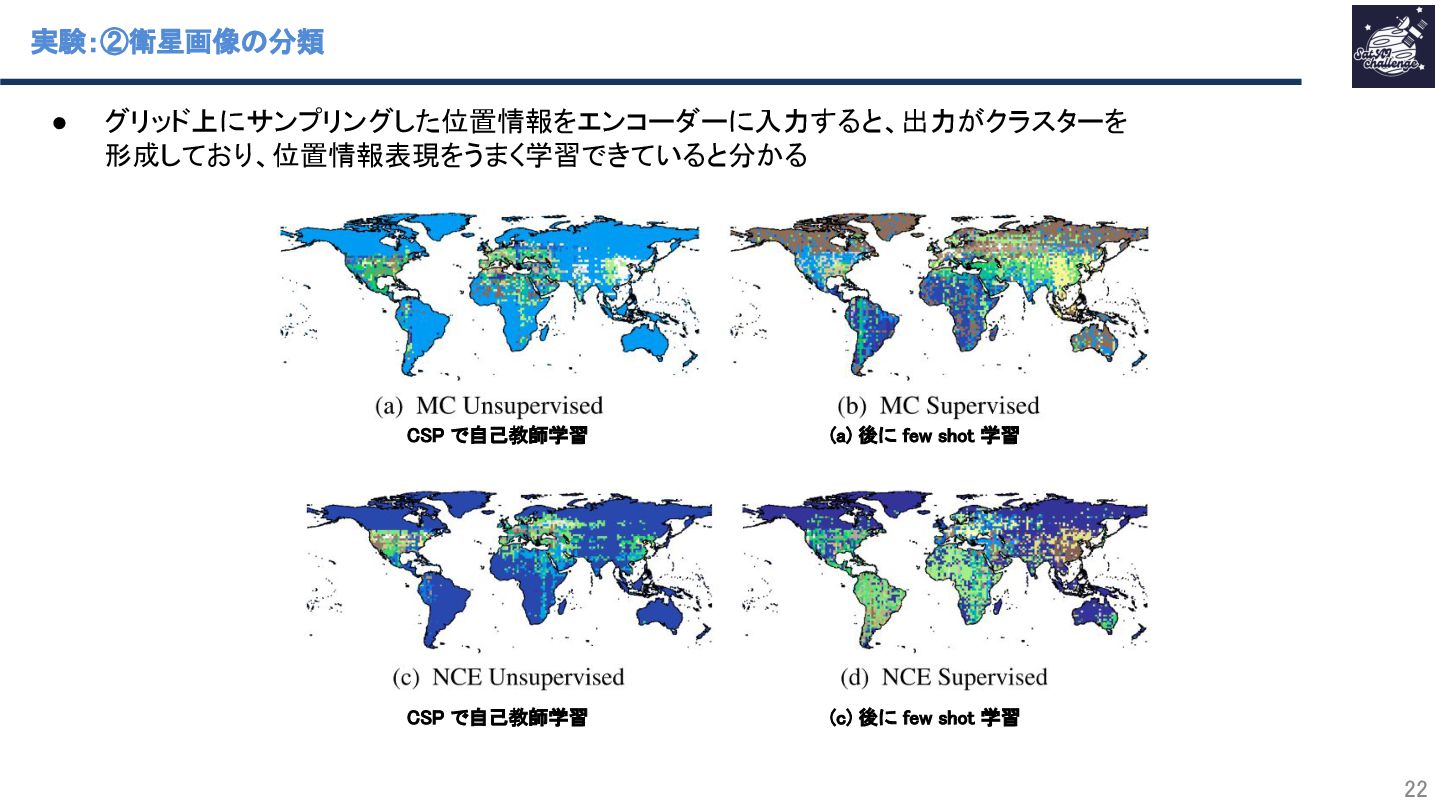
{kind=link}
{kind=link}
{kind=link}