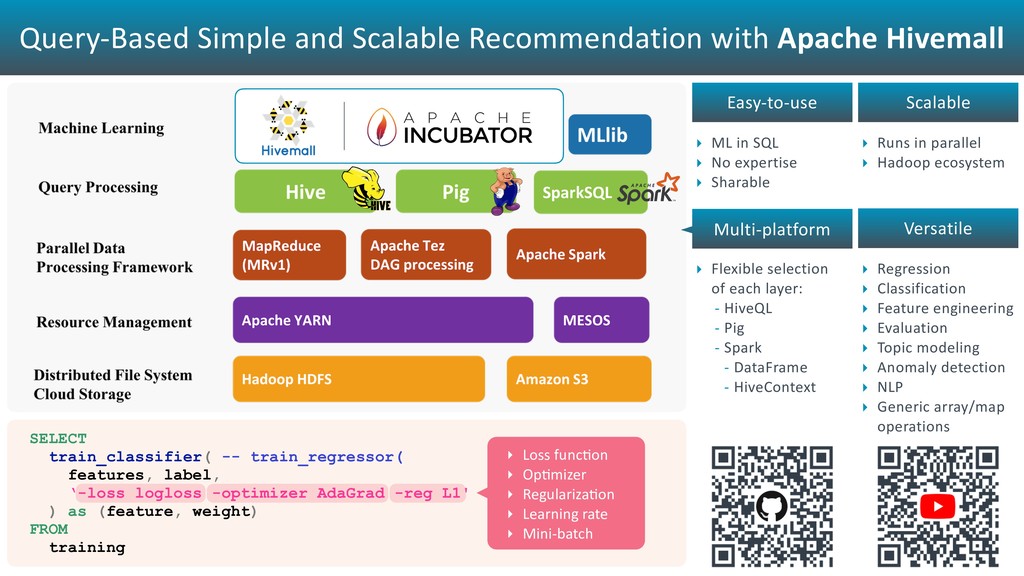
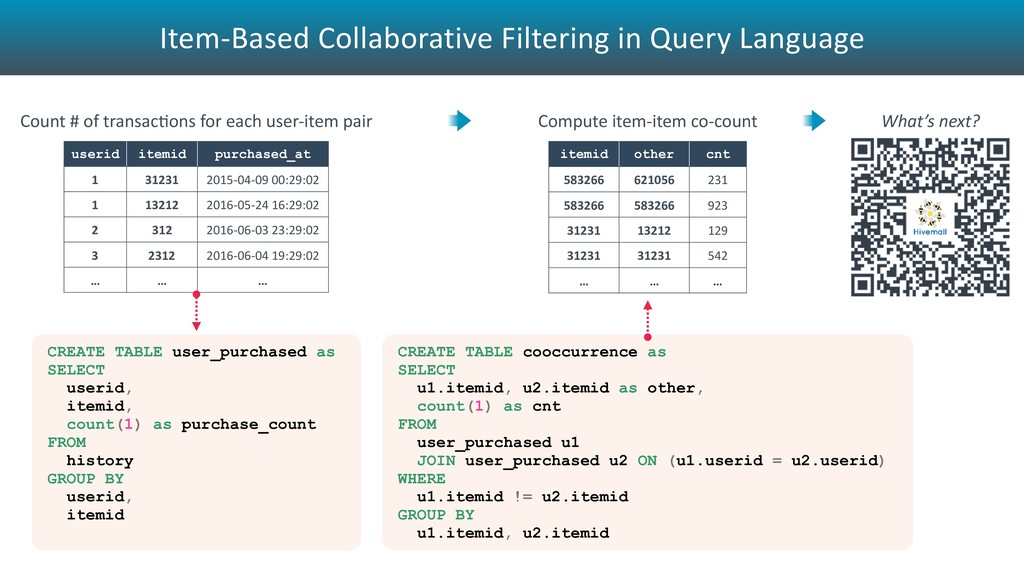
idx, array_avg(u_rank) as Pu, array_avg(i_rank) as Qi, avg(u_bias) as Bu, avg(i_bias) as Bi FROM ( SELECT train_mf_sgd( user_id, item_id, rating, '-factor ${factor} -mu ${mu} -iter ${iters}' ) as (idx, u_rank, i_rank, u_bias, i_bias) FROM training ) t GROUP BY idx SELECT mf_predict(t2.Pu, p2.Qi, t2.Bu, p2.Bi, ${mu}) as predicted FROM ( SELECT t1.user_id, t1.item_id, m1.Pu, m1.Bu FROM target t1 LEFT OUTER JOIN sgd_model m1 ON (t1.user_id = m1.idx) ) t2 LEFT OUTER JOIN sgd_model m2 ON (t2.item_id = m2.idx)
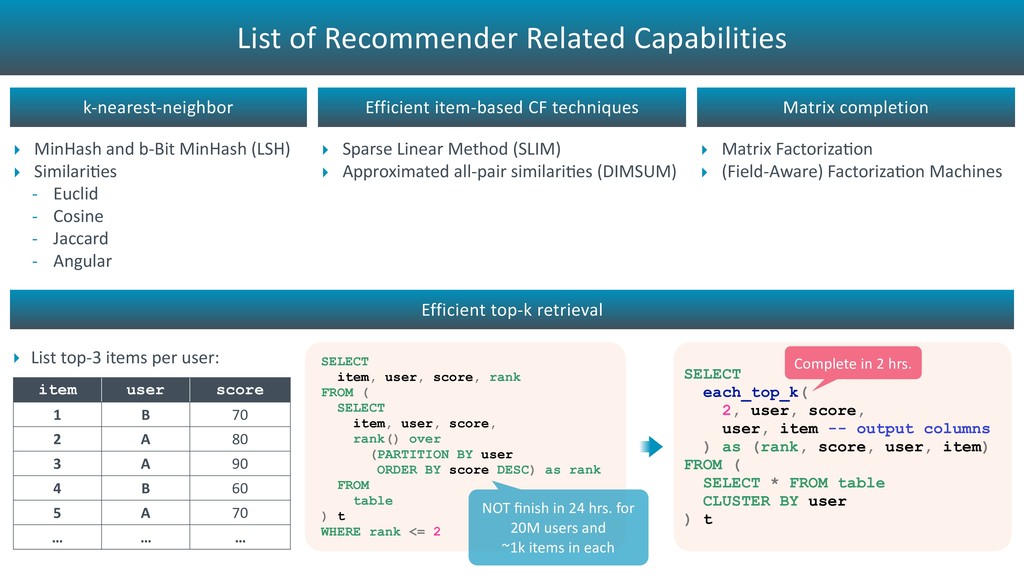
user: item user score 1 B 70 2 A 80 3 A 90 4 B 60 5 A 70 … … … SELECT each_top_k( 2, user, score, user, item -- output columns ) as (rank, score, user, item) FROM ( SELECT * FROM table CLUSTER BY user ) t Complete in 2 hrs. k-nearest-neighbor ‣ MinHash and b-Bit MinHash (LSH) ‣ Similari?es - Euclid - Cosine - Jaccard - Angular Efficient top-k retrieval Efficient item-based CF techniques ‣ Sparse Linear Method (SLIM) ‣ Approximated all-pair similari?es (DIMSUM) Matrix completion ‣ Matrix Factoriza?on ‣ (Field-Aware) Factoriza?on Machines SELECT item, user, score, rank FROM ( SELECT item, user, score, rank() over (PARTITION BY user ORDER BY score DESC) as rank FROM table ) t WHERE rank <= 2 NOT finish in 24 hrs. for 20M users and ~1k items in each
{kind=link}
{kind=link}
{kind=link}
{kind=link}