L. Wu, et al., "MicroDiag: Fine-grained Performance Diagnosis for Microservice Systems," 2021 IEEE/ACM International Workshop on Cloud Intelligence, Madrid, Spain, 2021, pp. 31-36 [2] L. Pham, et al., “BARO: Robust Root Cause Analysis for Microservices via Multivariate Bayesian Online Change Point Detection,” Proc. ACM on Software Engineering, vol. 1, no. FSE, pp. 2214-2237, Jul. 2024, [3] H. Wang, et al., "Groot: An Event-graph-based Approach for Root Cause Analysis in Industrial Settings," 2021 36th IEEE/ACM International Conference on Automated Software Engineering, Melbourne, Australia, 2021, pp. 419-429 [4] C. Lee, et al., "Eadro: An End-to-End Troubleshooting Framework for Microservices on Multi-source Data," 2023 IEEE/ACM 45th International Conference on Software Engineering, Melbourne, Australia, 2023, pp. 1750-1762 [5] 小山 智之,串田 高幸,生野 壮一郎, "Kubernetesのリソースイベントと依存グラフとトレースによる障害の原因調査にかかる時間の短縮," 第33回マルチメディア通信と分散処理ワークショップ (DPSWS 2025) 講演論文集, 2025, pp. 268–275. • 複数データソースをRCAに使用 • Kubernetesリソース依存関係の分析が 不足 根本 原因 メトリクス ログ 根本 原因 根本 原因 4 • 以前の研究[5]ではイベントとトレース,マニフェストによる根本原因の分析を提案 • エラーの有無に関わらずトレースを抽出しており,混在する状況での精度に課題
{kind=link}
{kind=link}
{kind=link}
![関連研究 シングルモーダル型[1,2] マルチモーダル型[3,4] ログ トレース • 単一データソースをRCAに使用 • ミドルウェア状態の分析に情報不足 [1]](https://files.speakerdeck.com/presentations/e14a04a955644a2490ab77ef1888dcdc/slide_3.jpg){kind=link}
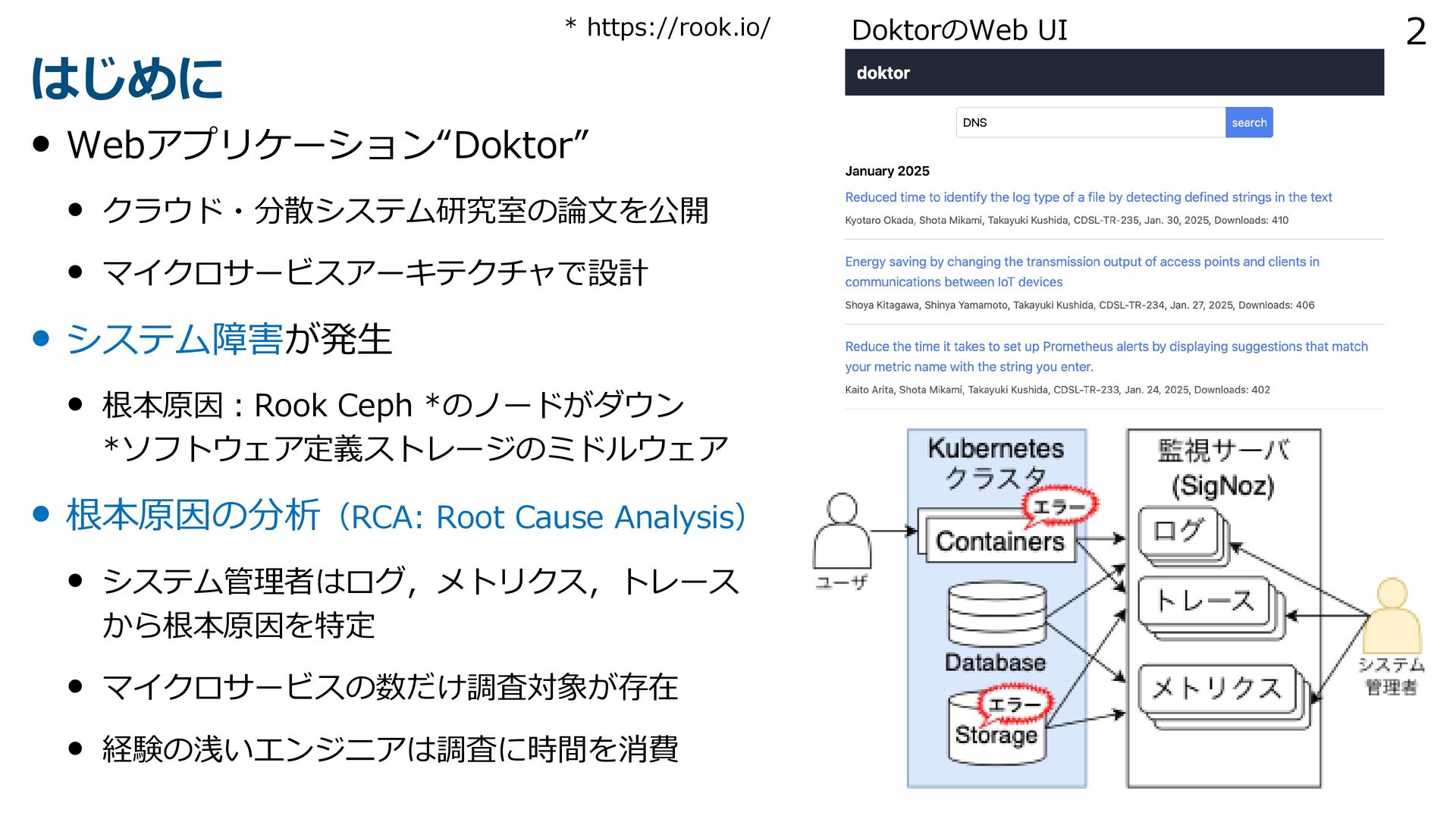
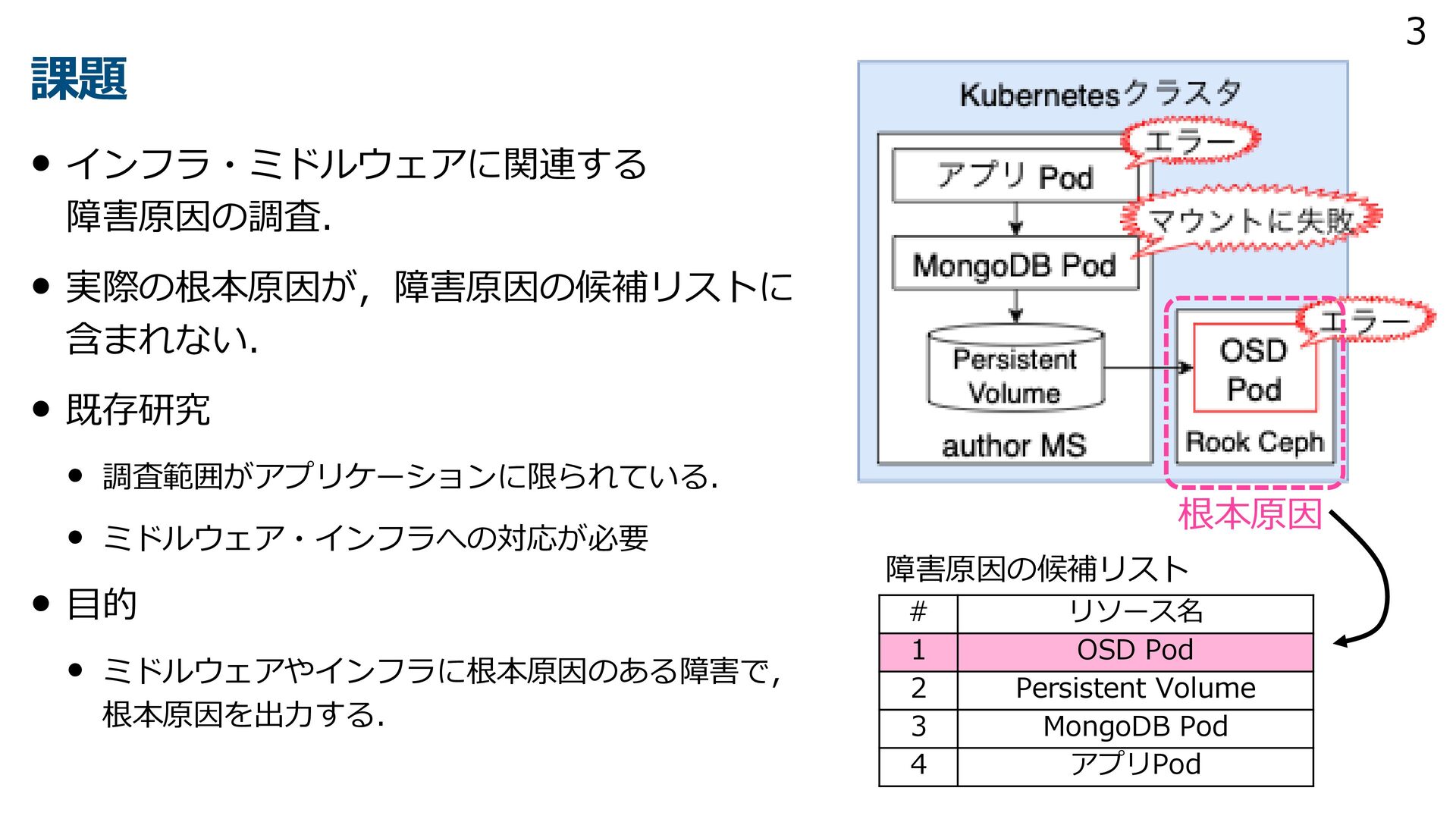
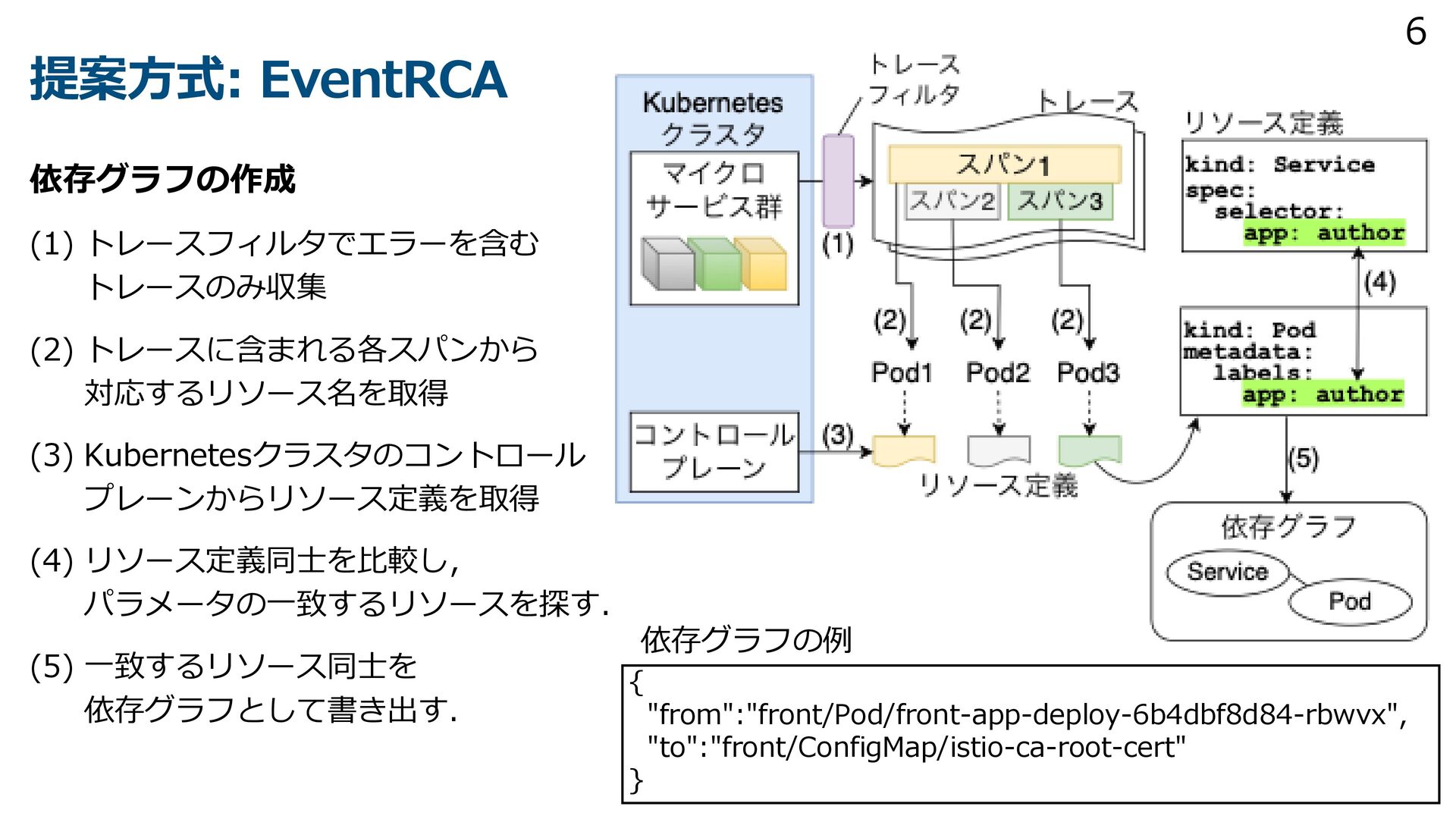
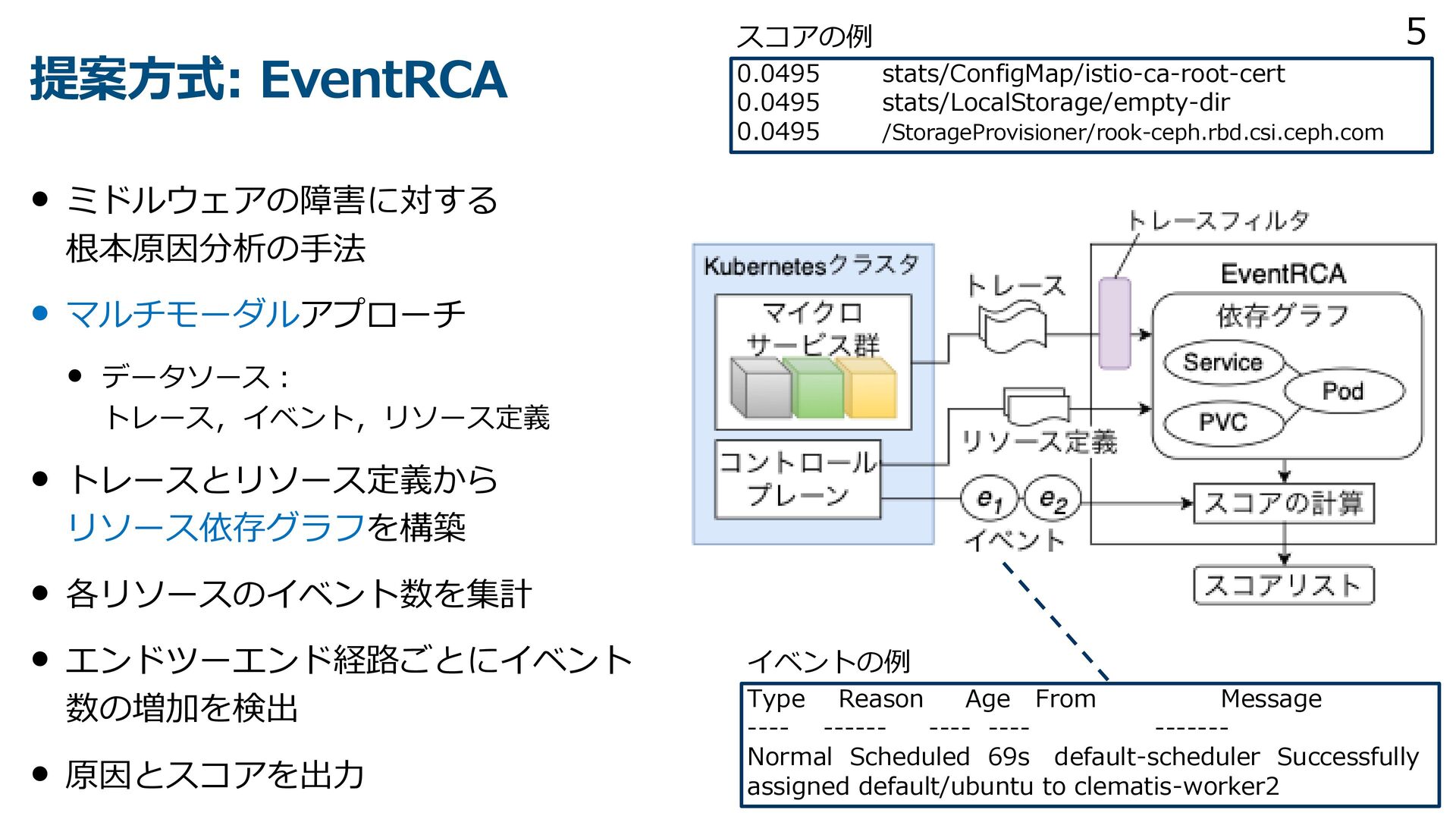{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}