for Multi-Subject Generation 4 Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or テキストから画像を生成する時に,複数の異なる対象(multi-subject)を生成しようとすると, 対象同士が混ざったり(subject leakage)、数や特徴が間違ったりしやすい この論文で着目する問題 “A polar bear, a grizzly bear, a panda bear, and a koala bear” →「ホッキョクグマ、ハイイログマ、ジャイアントパンダ、そしてコアラ」 “Two teddy bears and four red toy cars on a white carpet” →「白いカーペットの上に、2体のテディベアと4台の赤いおもちゃの車」 Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. 2025. Be Decisive: Noise-Induced Layouts for Multi-Subject Generation. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 92, 1–12. https://doi.org/10.1145/3721238.3730631
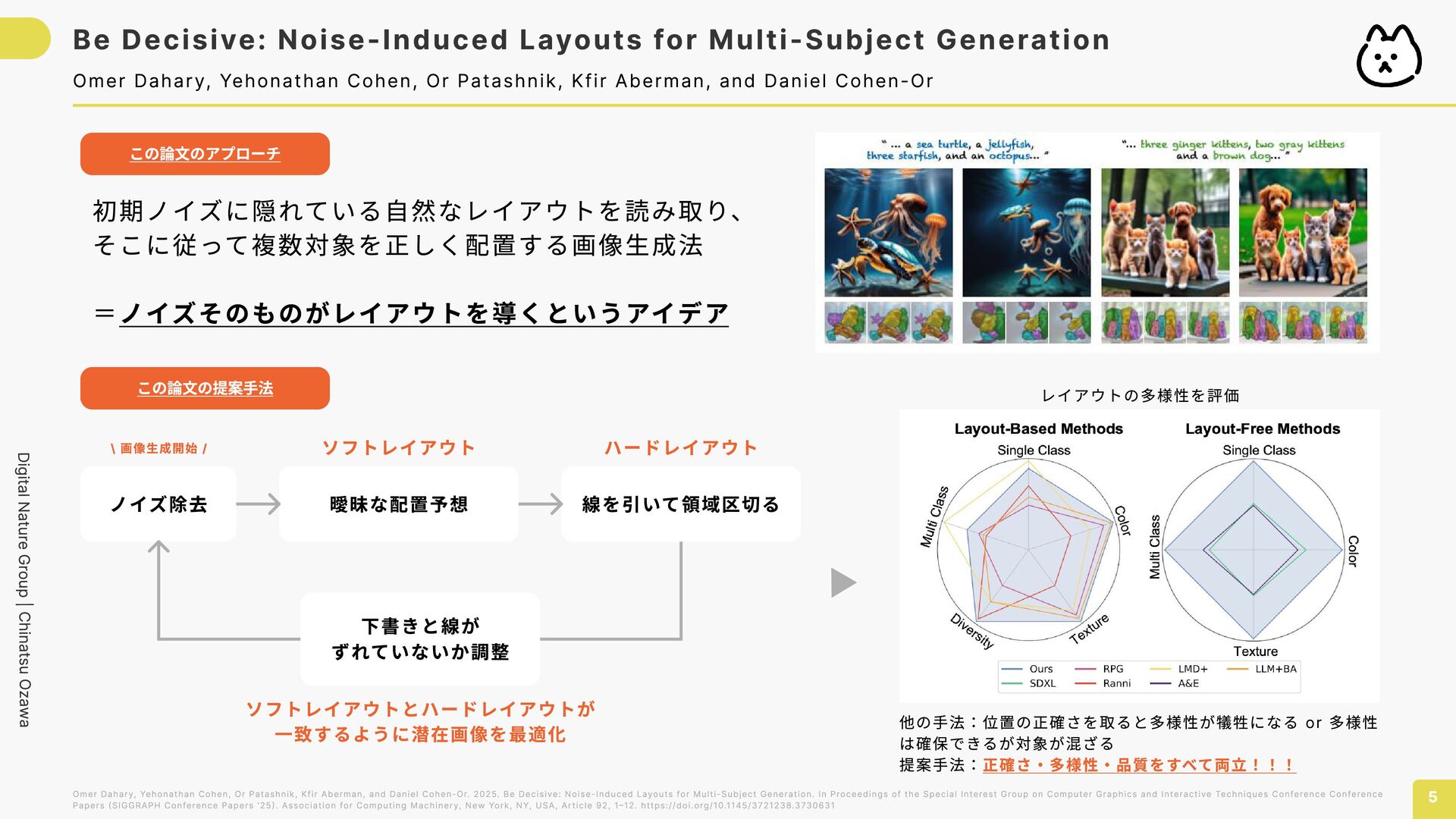
for Multi-Subject Generation 5 Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or 初期ノイズに隠れている自然なレイアウトを読み取り、 そこに従って複数対象を正しく配置する画像生成法 =ノイズそのものがレイアウトを導くというアイデア この論文のアプローチ この論文の提案手法 ノイズ除去 曖昧な配置予想 線を引いて領域区切る \ 画像生成開始 / 下書きと線が ずれていないか調整 ソフトレイアウトとハードレイアウトが 一致するように潜在画像を最適化 ソフトレイアウト ハードレイアウト 他の手法:位置の正確さを取ると多様性が犠牲になる or 多様性 は確保できるが対象が混ざる 提案手法:正確さ・多様性・品質をすべて両立!!! レイアウトの多様性を評価 Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. 2025. Be Decisive: Noise-Induced Layouts for Multi-Subject Generation. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 92, 1–12. https://doi.org/10.1145/3721238.3730631
using few step diffusion 6 Amirhossein Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri few-step diffusion を使った画像編集において、構造やテクスチャの整合性が崩れやすい この論文で着目する問題 Amirhossein Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri. 2025. Cora: Correspondence-aware image editing using few step diffusion. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 93, 1–11. https://doi.org/10.1145/3721238.3730650
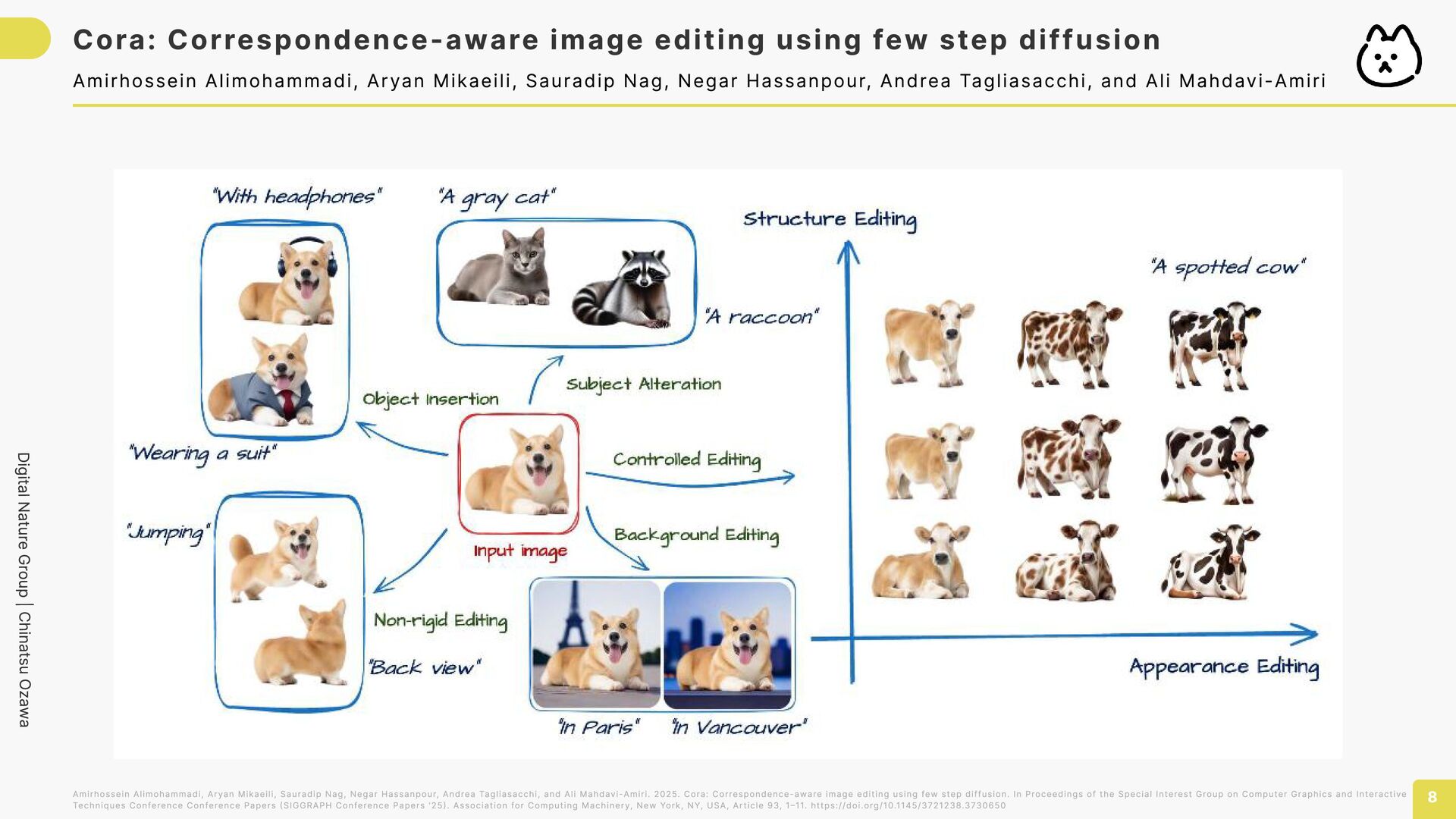
using few step diffusion 7 Amirhossein Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri Amirhossein Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri. 2025. Cora: Correspondence-aware image editing using few step diffusion. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 93, 1–11. https://doi.org/10.1145/3721238.3730650 この論文の提案手法 ターゲットと元画像の似ている部分 同士をAIの特徴で地図のように結ぶ 地図に合わせて, ノイズのかけ方を並べ替える 元画像の見た目と新しく描く 見た目をなめらかにブレンド 絵の「骨格(どこを重視する か)」が似るように並べ替える 元写真の形を残す←→指示どお り形を変える」を調整 「見た目の転写量(どれだけ元の 質感を持ってくるか)」を調整 SLEAP correspondence map ハンガリアン法 βつまみ αつまみ 「必要なら生成, 合う所だけ転写する」 から破綻が少なくなる!
using few step diffusion 8 Amirhossein Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri Amirhossein Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri. 2025. Cora: Correspondence-aware image editing using few step diffusion. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 93, 1–11. https://doi.org/10.1145/3721238.3730650
using few step diffusion 9 Amirhossein Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri Amirhossein Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri. 2025. Cora: Correspondence-aware image editing using few step diffusion. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 93, 1–11. https://doi.org/10.1145/3721238.3730650
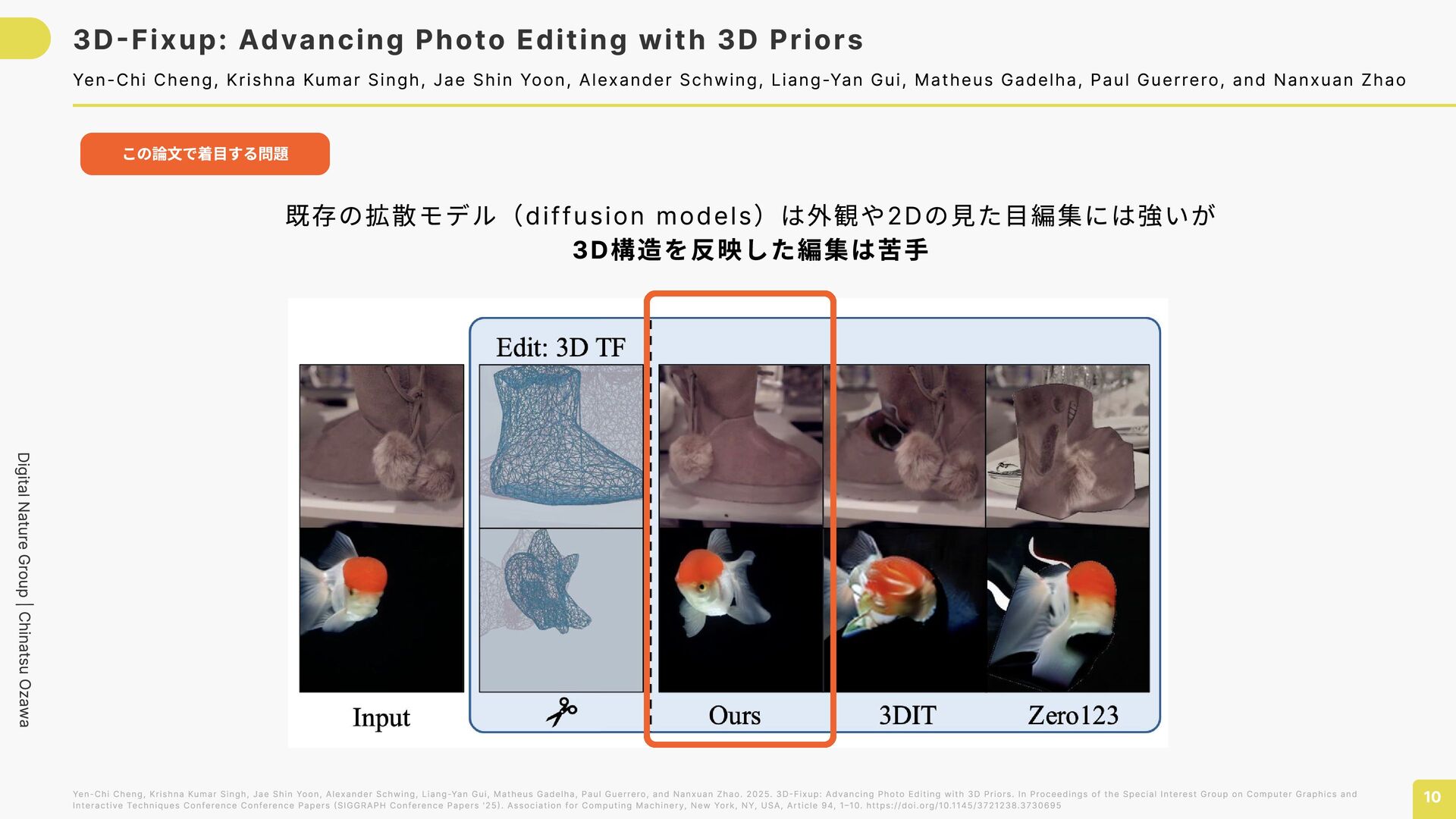
with 3D Priors 10 Yen-Chi Cheng, Krishna Kumar Singh, Jae Shin Yoon, Alexander Schwing, Liang-Yan Gui, Matheus Gadelha, Paul Guerrero, and Nanxuan Zhao この論文で着目する問題 Yen-Chi Cheng, Krishna Kumar Singh, Jae Shin Yoon, Alexander Schwing, Liang-Yan Gui, Matheus Gadelha, Paul Guerrero, and Nanxuan Zhao. 2025. 3D-Fixup: Advancing Photo Editing with 3D Priors. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 94, 1–10. https://doi.org/10.1145/3721238.3730695 既存の拡散モデル(diffusion models)は外観や2Dの見た目編集には強いが 3D構造を反映した編集は苦手
with 3D Priors 11 Yen-Chi Cheng, Krishna Kumar Singh, Jae Shin Yoon, Alexander Schwing, Liang-Yan Gui, Matheus Gadelha, Paul Guerrero, and Nanxuan Zhao Yen-Chi Cheng, Krishna Kumar Singh, Jae Shin Yoon, Alexander Schwing, Liang-Yan Gui, Matheus Gadelha, Paul Guerrero, and Nanxuan Zhao. 2025. 3D-Fixup: Advancing Photo Editing with 3D Priors. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 94, 1–10. https://doi.org/10.1145/3721238.3730695 この論文の提案手法 動画から学習データ をつくる 「入力(正面写真)」と 「出力(ちょっと回した写真)」 のペアにする Image-to-3D モデルを使い 写真から「立体の形」を推定 ステップ1と2で作ったペア データを使って画像生成AIに 学習させる 動画とImage-to-3Dを利用して訓練した、拡散モデルベースの高速・高品質な3D写真編集フレームワーク
using Pre-Trained Diffusion Models 12 Aleksandar Cvejic, Abdelrahman Eldesokey, and Peter Wonka Aleksandar Cvejic, Abdelrahman Eldesokey, and Peter Wonka. 2025. PartEdit: Fine-Grained Image Editing using Pre-Trained Diffusion Models. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 95, 1–11. https://doi.org/10.1145/3721238.3730747 この論文で着目する問題 従来のテキストによる画像編集(例:「髪を金髪にして」など)は可能だけど 細かいパーツ単位の編集(顔の髪だけ・車のボンネットだけなど) が苦手
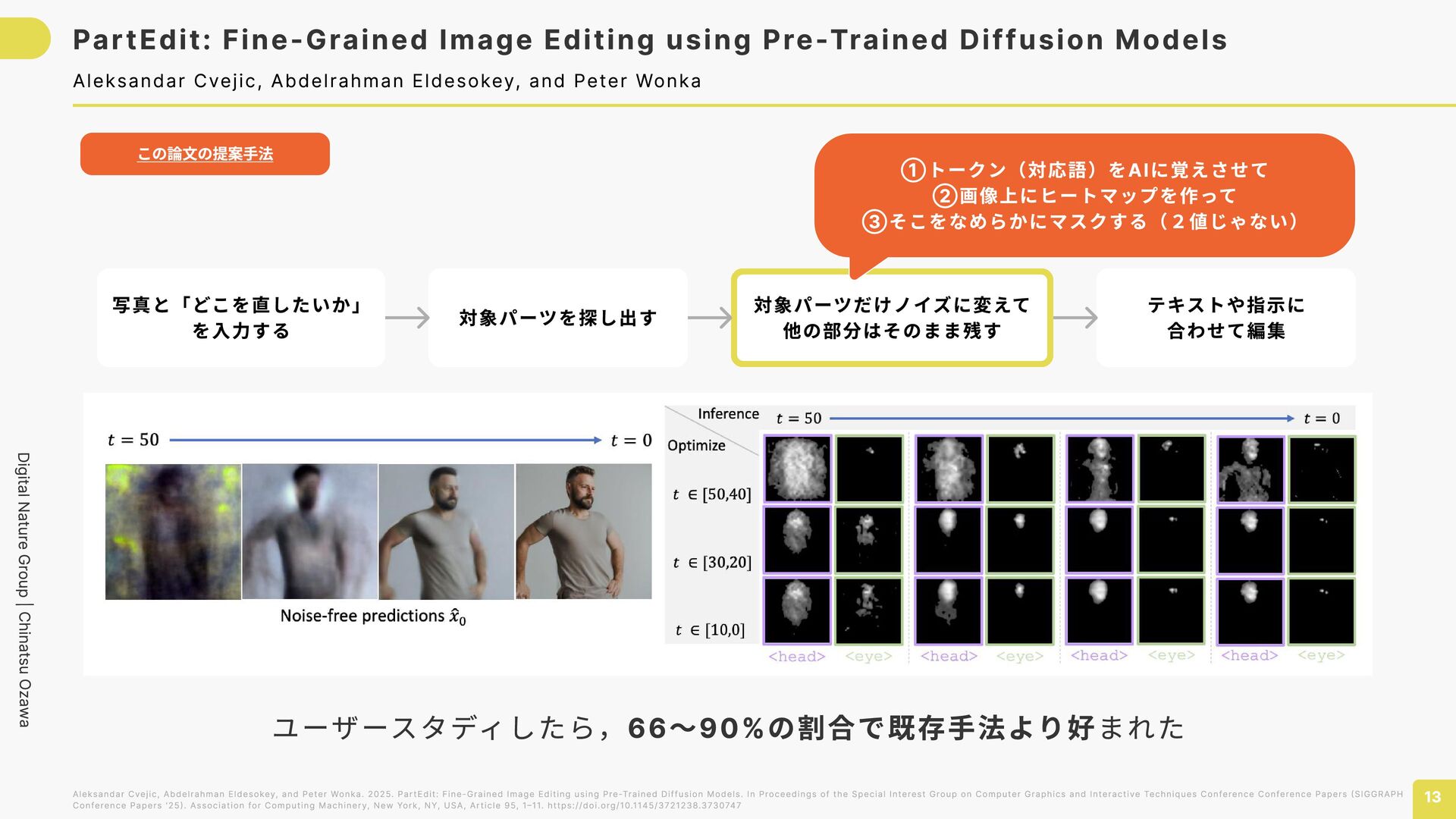
using Pre-Trained Diffusion Models 13 Aleksandar Cvejic, Abdelrahman Eldesokey, and Peter Wonka Aleksandar Cvejic, Abdelrahman Eldesokey, and Peter Wonka. 2025. PartEdit: Fine-Grained Image Editing using Pre-Trained Diffusion Models. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 95, 1–11. https://doi.org/10.1145/3721238.3730747 この論文の提案手法 写真と「どこを直したいか」 を入力する 対象パーツを探し出す 対象パーツだけノイズに変えて 他の部分はそのまま残す テキストや指示に 合わせて編集 ①トークン(対応語)をAIに覚えさせて ②画像上にヒートマップを作って ③そこをなめらかにマスクする(2値じゃない) ユーザースタディしたら,66〜90%の割合で既存手法より好まれた
using Pre-Trained Diffusion Models 14 Aleksandar Cvejic, Abdelrahman Eldesokey, and Peter Wonka Aleksandar Cvejic, Abdelrahman Eldesokey, and Peter Wonka. 2025. PartEdit: Fine-Grained Image Editing using Pre-Trained Diffusion Models. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 95, 1–11. https://doi.org/10.1145/3721238.3730747
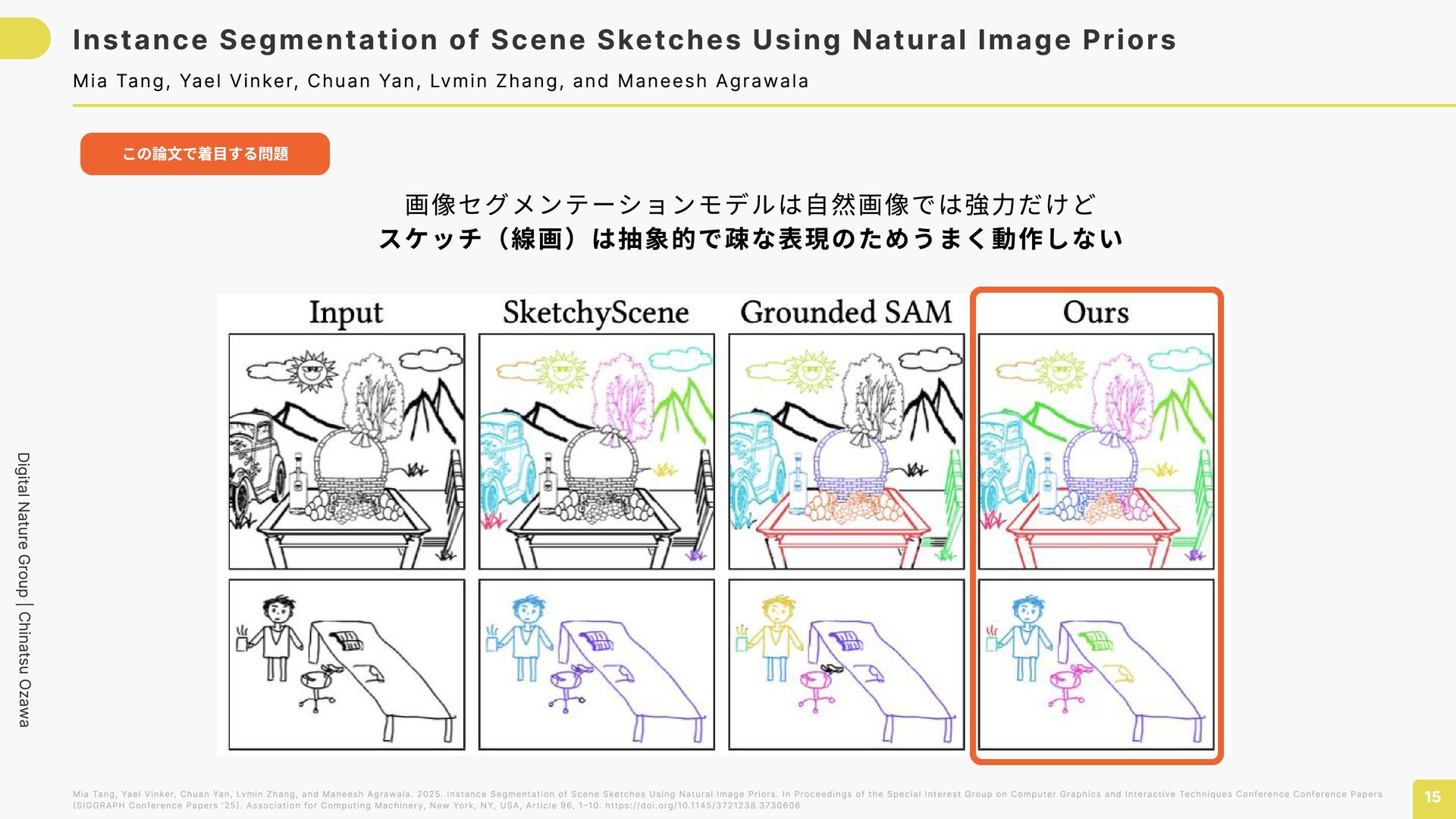
Sketches Using Natural Image Priors 15 Mia Tang, Yael Vinker, Chuan Yan, Lvmin Zhang, and Maneesh Agrawala Mia Tang, Yael Vinker, Chuan Yan, Lvmin Zhang, and Maneesh Agrawala. 2025. Instance Segmentation of Scene Sketches Using Natural Image Priors. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 96, 1–10. https://doi.org/10.1145/3721238.3730606 この論文で着目する問題 画像セグメンテーションモデルは自然画像では強力だけど スケッチ(線画)は抽象的で疎な表現のためうまく動作しない
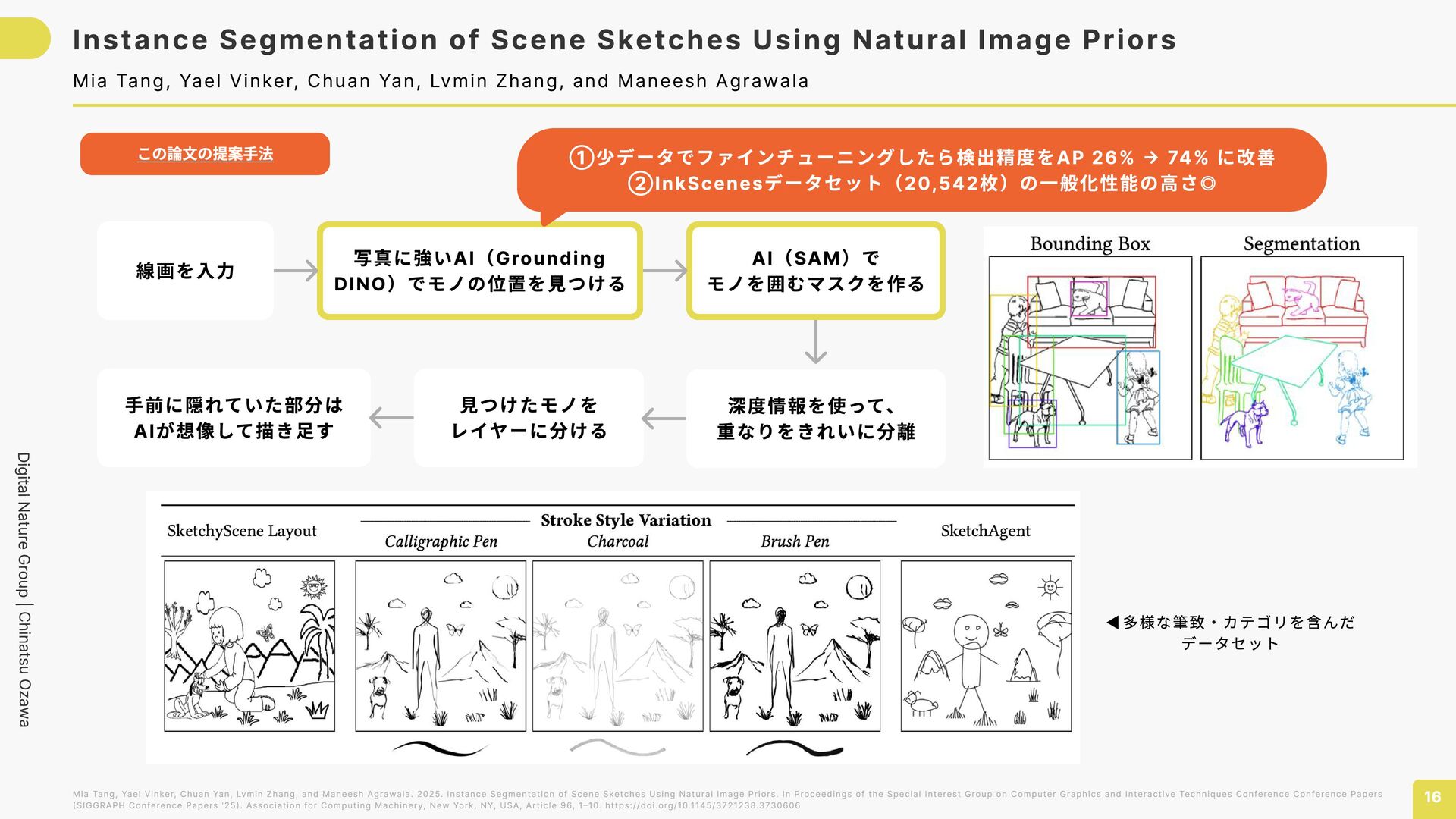
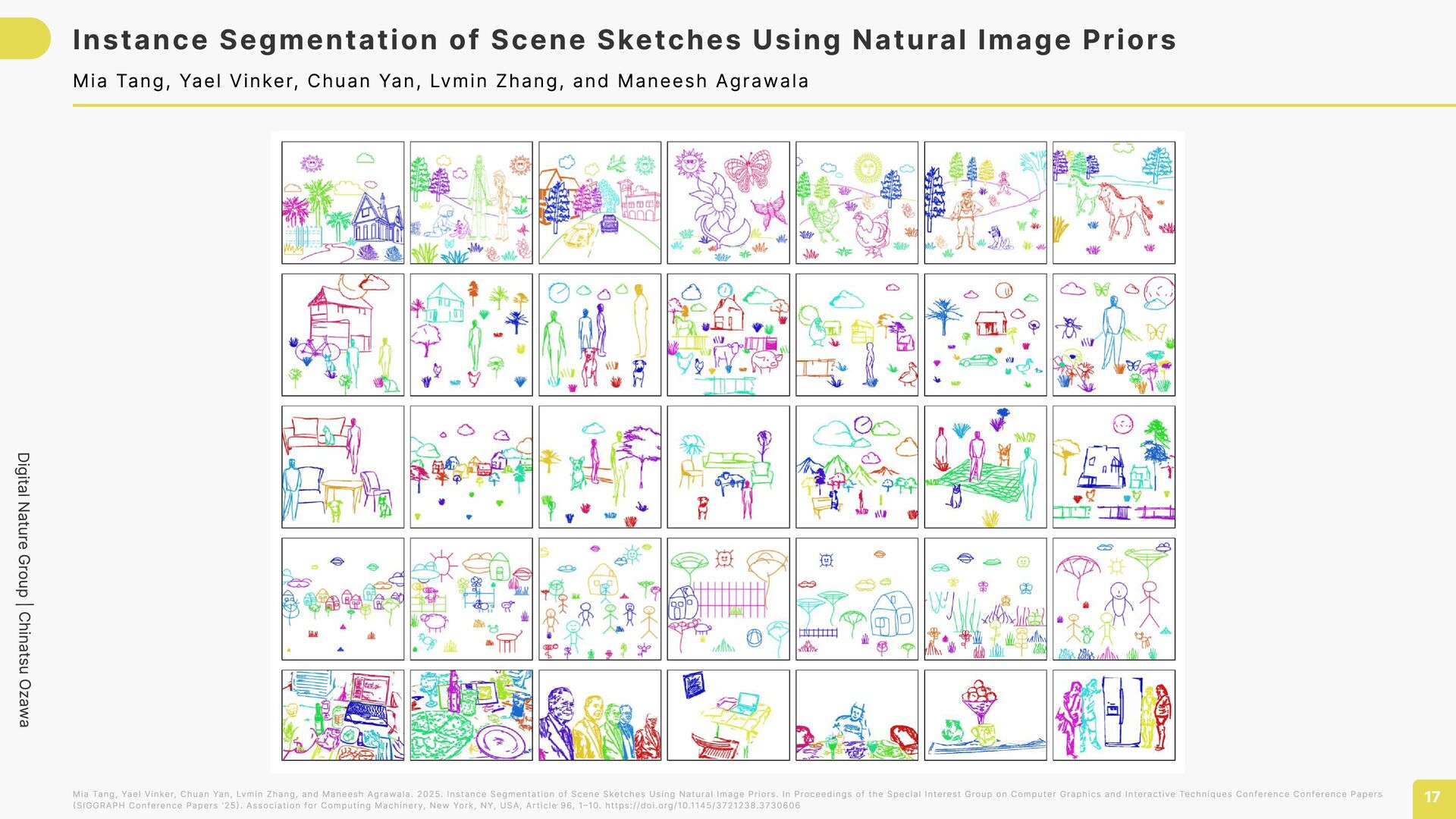
Sketches Using Natural Image Priors 16 Mia Tang, Yael Vinker, Chuan Yan, Lvmin Zhang, and Maneesh Agrawala Mia Tang, Yael Vinker, Chuan Yan, Lvmin Zhang, and Maneesh Agrawala. 2025. Instance Segmentation of Scene Sketches Using Natural Image Priors. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 96, 1–10. https://doi.org/10.1145/3721238.3730606 この論文の提案手法 線画を入力 写真に強いAI(Grounding DINO)でモノの位置を見つける AI(SAM)で モノを囲むマスクを作る 深度情報を使って、 重なりをきれいに分離 見つけたモノを レイヤーに分ける 手前に隠れていた部分は AIが想像して描き足す ①少データでファインチューニングしたら検出精度をAP 26% → 74% に改善 ②InkScenesデータセット(20,542枚)の一般化性能の高さ◎ ◀︎多様な筆致・カテゴリを含んだ データセット
Sketches Using Natural Image Priors 17 Mia Tang, Yael Vinker, Chuan Yan, Lvmin Zhang, and Maneesh Agrawala Mia Tang, Yael Vinker, Chuan Yan, Lvmin Zhang, and Maneesh Agrawala. 2025. Instance Segmentation of Scene Sketches Using Natural Image Priors. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 96, 1–10. https://doi.org/10.1145/3721238.3730606
Enhances MLLMs' Image Retouching Skills 22 Niladri Shekhar Dutt, Duygu Ceylan, and Niloy J. Mitra 推し 論文 Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. 2025. Be Decisive: Noise-Induced Layouts for Multi-Subject Generation. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 92, 1–12. https://doi.org/10.1145/3721238.3730631 この論文で着目する問題 従来のAI画像編集は元の被写体の自然さや同一性を壊してしまい、かつ編集理由が説明できない 生成系: 元の人らしさが消えやすいし、一部だけ やり直すのが難しい プロシージャル系:元を壊しにくくて、途中の手 順を飛ばしたり直したりしやすい 生成+プロシージャル:言葉では分かるけど実物 を触ってないから、微妙な効きが分からず操作が 的外れになりがち 提案手法:スライダー1目盛りの違いまで体で分 かってるから、筋の良い手順を出せる
Enhances MLLMs' Image Retouching Skills 23 Niladri Shekhar Dutt, Duygu Ceylan, and Niloy J. Mitra 推し 論文 Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. 2025. Be Decisive: Noise-Induced Layouts for Multi-Subject Generation. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 92, 1–12. https://doi.org/10.1145/3721238.3730631 この論文の提案手法 レタッチのパラメータと数値の 対応関係をAIが学習 画像を見て問題を発見する 「ここ暗いかも…」 AIで作った一連の編集レシピを 画像に適用する
Enhances MLLMs' Image Retouching Skills 24 Niladri Shekhar Dutt, Duygu Ceylan, and Niloy J. Mitra 推し 論文 Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. 2025. Be Decisive: Noise-Induced Layouts for Multi-Subject Generation. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 92, 1–12. https://doi.org/10.1145/3721238.3730631 この論文の提案手法 レタッチのパラメータと数値の 対応関係をAIが学習 画像を見て問題を発見する 「ここ暗いかも…」 AIで作った一連の編集レシピを 画像に適用する ここの有無で 画像のクオリティが 格段に違う!
Enhances MLLMs' Image Retouching Skills 25 Niladri Shekhar Dutt, Duygu Ceylan, and Niloy J. Mitra 推し 論文 Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. 2025. Be Decisive: Noise-Induced Layouts for Multi-Subject Generation. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers '25). Association for Computing Machinery, New York, NY, USA, Article 92, 1–12. https://doi.org/10.1145/3721238.3730631 この論文の提案手法 MonetGPT が一番高く評価された→ 特に「写真の質」と「被写体のアイデンティティ保持」が良い
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Digital Nature Group | Chinatsu Ozawa [TOG] IntrinsicEdit: Precise generative](https://files.speakerdeck.com/presentations/d39c47fe6a3c4fcea116e1bd19ec4283/slide_17.jpg){kind=link}
![Digital Nature Group | Chinatsu Ozawa [TOG] IntrinsicEdit: Precise generative](https://files.speakerdeck.com/presentations/d39c47fe6a3c4fcea116e1bd19ec4283/slide_18.jpg){kind=link}
![Digital Nature Group | Chinatsu Ozawa [TOG] IntrinsicEdit: Precise generative](https://files.speakerdeck.com/presentations/d39c47fe6a3c4fcea116e1bd19ec4283/slide_19.jpg){kind=link}
![Digital Nature Group | Chinatsu Ozawa [TOG] IntrinsicEdit: Precise generative](https://files.speakerdeck.com/presentations/d39c47fe6a3c4fcea116e1bd19ec4283/slide_20.jpg){kind=link}
![Digital Nature Group | Chinatsu Ozawa [TOG] MonetGPT: Solving Puzzles](https://files.speakerdeck.com/presentations/d39c47fe6a3c4fcea116e1bd19ec4283/slide_21.jpg){kind=link}
![Digital Nature Group | Chinatsu Ozawa [TOG] MonetGPT: Solving Puzzles](https://files.speakerdeck.com/presentations/d39c47fe6a3c4fcea116e1bd19ec4283/slide_22.jpg){kind=link}
![Digital Nature Group | Chinatsu Ozawa [TOG] MonetGPT: Solving Puzzles](https://files.speakerdeck.com/presentations/d39c47fe6a3c4fcea116e1bd19ec4283/slide_23.jpg){kind=link}
![Digital Nature Group | Chinatsu Ozawa [TOG] MonetGPT: Solving Puzzles](https://files.speakerdeck.com/presentations/d39c47fe6a3c4fcea116e1bd19ec4283/slide_24.jpg){kind=link}