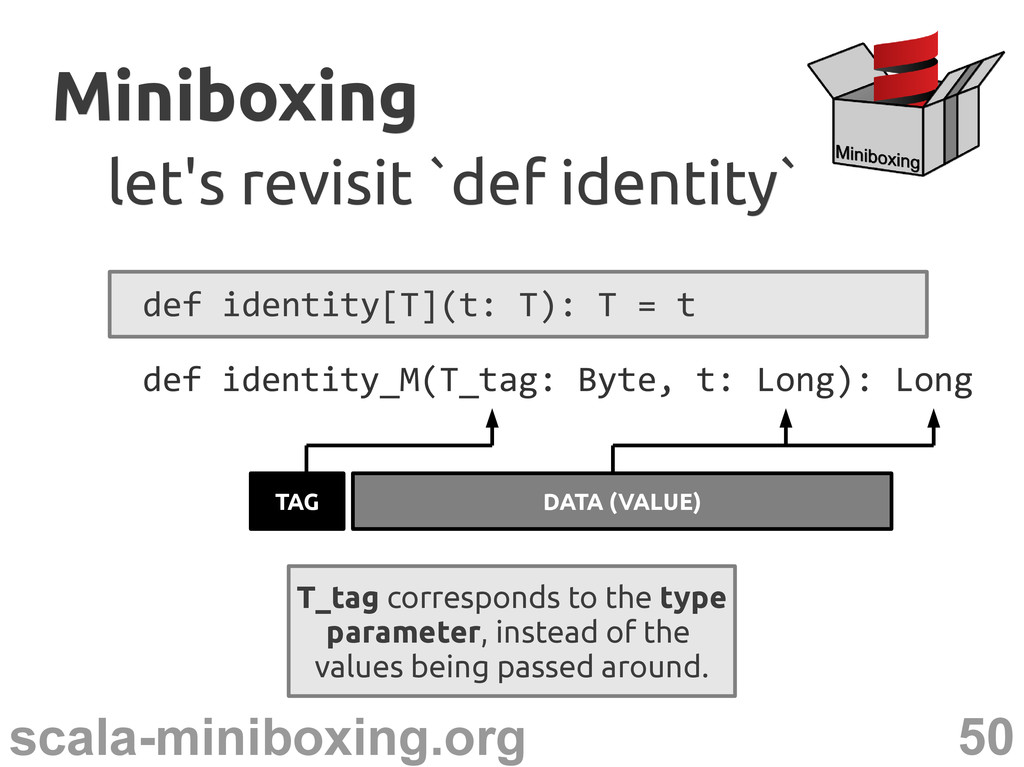
def identity[T](t: T): T = t a trivial example a trivial example but under erasure: def identity(t: Any): Any = t Any is the top of the Scala type system
generics execute similarly to dynamic languages – generic values lose their type information – primitives need boxing but under but under erasure erasure
generics execute similarly to dynamic languages – generic values lose their type information – primitives need boxing – performance is affected but under but under erasure erasure
generics execute similarly to dynamic languages – generic values lose their type information – primitives need boxing – performance is affected but under but under erasure erasure Dynamic language VMs use specialization to improve performance*
generics execute similarly to dynamic languages – generic values lose their type information – primitives need boxing – performance is affected but under but under erasure erasure Dynamic language VMs use specialization to improve performance* *but the HotSpot JVM doesn't
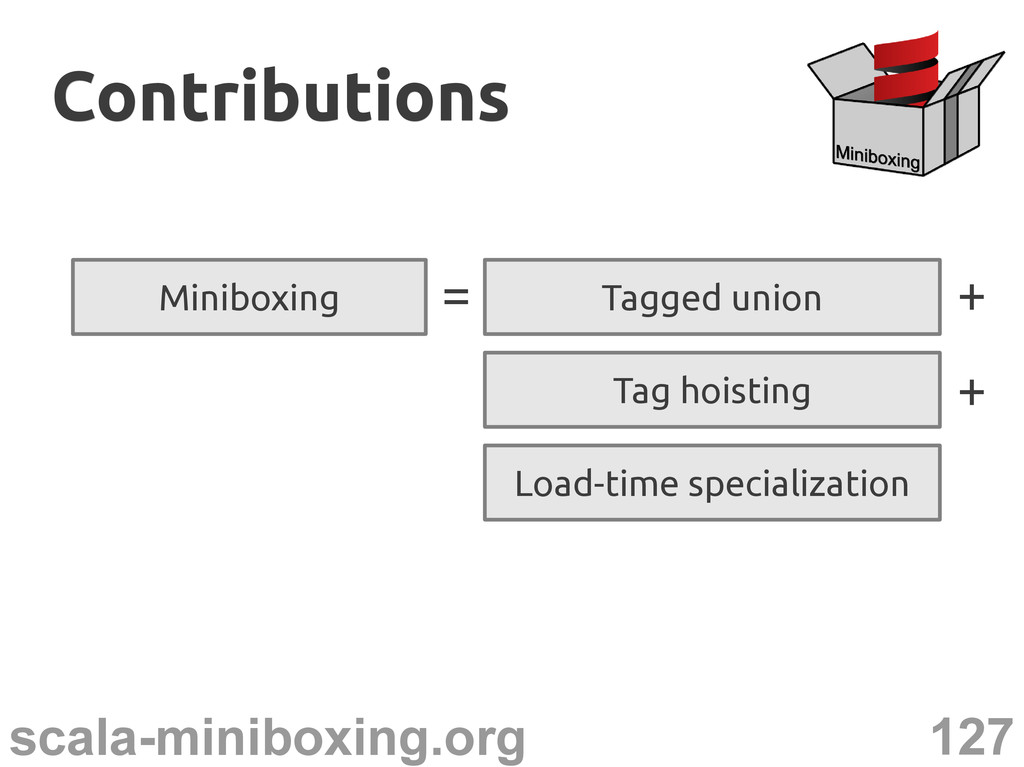
Compile-time (static) transformation – duplicates the original code – adapts it for each primitive type – rewrites programs to use the adapted code it's called specialization it's called specialization* * * Iulian Dragos – PhD thesis, EPFL, 2010
Compile-time (static) transformation – duplicates the original code – adapts it for each primitive type – rewrites programs to use the adapted code it's called specialization it's called specialization* * Adapted code doesn't need to box * Iulian Dragos – PhD thesis, EPFL, 2010
Compile-time (static) transformation – duplicates the original code – adapts it for each primitive type – rewrites programs to use the adapted code it's called specialization it's called specialization* * Adapted code doesn't need to box Performance is regained. * Iulian Dragos – PhD thesis, EPFL, 2010
`def identity` def identity[T](t: T): T = t def identity_V(t: Unit): Unit = t def identity_Z(t: Boolean): Boolean = t def identity_B(t: Byte): Byte = t def identity_C(t: Char): Char = t def identity_S(t: Short): Short = t def identity_I(t: Int): Int = t def identity_J(t: Long): Long = t def identity_F(t: Float): Float = t def identity_D(t: Double): Double = t
`def identity` def identity[T](t: T): T = t def identity_V(t: Unit): Unit = t def identity_Z(t: Boolean): Boolean = t def identity_B(t: Byte): Byte = t def identity_C(t: Char): Char = t def identity_S(t: Short): Short = t def identity_I(t: Int): Int = t def identity_J(t: Long): Long = t def identity_F(t: Float): Float = t def identity_D(t: Double): Double = t Generates 10 times the original code
t2: Boolean) def pack_VB(t1: Unit, t2: Byte) def pack_VC(t1: Unit, t2: Char) def pack_VS(t1: Unit, t2: Short) def pack_VI(t1: Unit, t2: Int) def pack_VJ(t1: Unit, t2: Long) def pack_VF(t1: Unit, t2: Float) def pack_VD(t1: Unit, t2: Double) Specialization Specialization … … it gets even worse it gets even worse def pack[T1, T2](t1: T1, t2: T2) = ... 10^n, where n is the number of type params
t2: Boolean) def pack_VB(t1: Unit, t2: Byte) def pack_VC(t1: Unit, t2: Char) def pack_VS(t1: Unit, t2: Short) def pack_VI(t1: Unit, t2: Int) def pack_VJ(t1: Unit, t2: Long) def pack_VF(t1: Unit, t2: Float) def pack_VD(t1: Unit, t2: Double) Specialization Specialization … … it gets even worse it gets even worse def pack[T1, T2](t1: T1, t2: T2) = ... 10^n, where n is the number of type params And this is common: Maps, Tuples, Functions
t2: Boolean) def pack_VB(t1: Unit, t2: Byte) def pack_VC(t1: Unit, t2: Char) def pack_VS(t1: Unit, t2: Short) def pack_VI(t1: Unit, t2: Int) def pack_VJ(t1: Unit, t2: Long) def pack_VF(t1: Unit, t2: Float) def pack_VD(t1: Unit, t2: Double) Specialization Specialization … … it gets even worse it gets even worse def pack[T1, T2](t1: T1, t2: T2) = ... 10^n, where n is the number of type params And this is common: Maps, Tuples, Functions
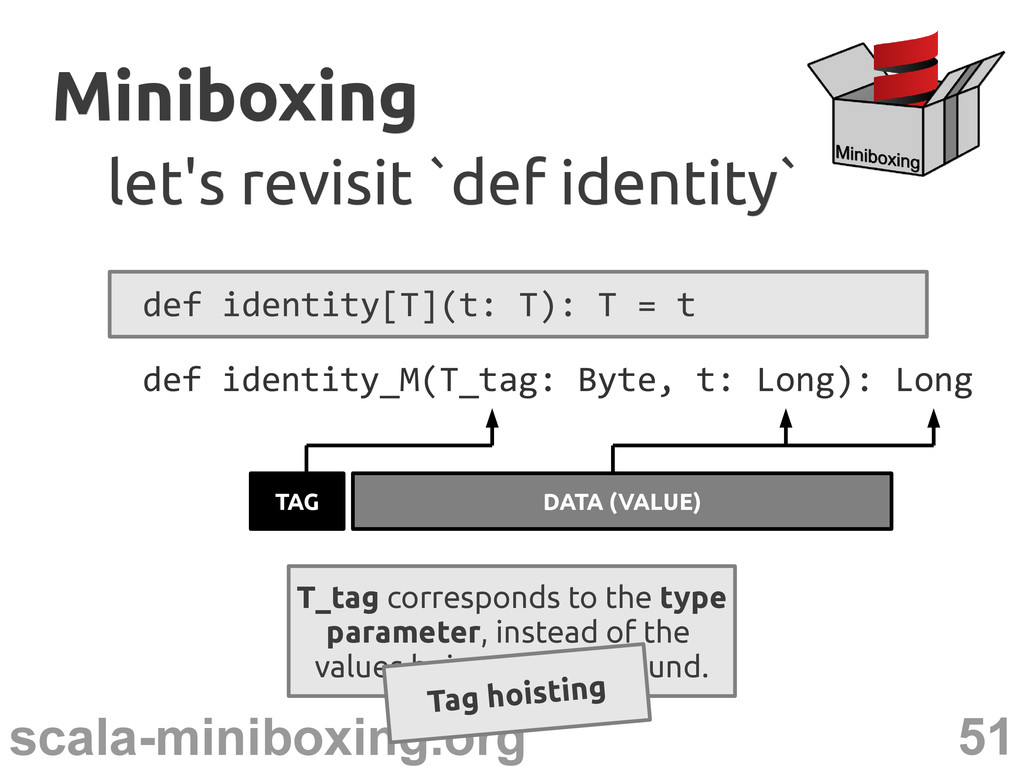
`def identity` def identity[T](t: T): T = t def identity_M(T_tag: Byte, t: Long): Long TAG DATA (VALUE) T_tag corresponds to the type parameter, instead of the values being passed around.
`def identity` def identity[T](t: T): T = t def identity_M(T_tag: Byte, t: Long): Long TAG DATA (VALUE) T_tag corresponds to the type parameter, instead of the values being passed around. Tag hoisting
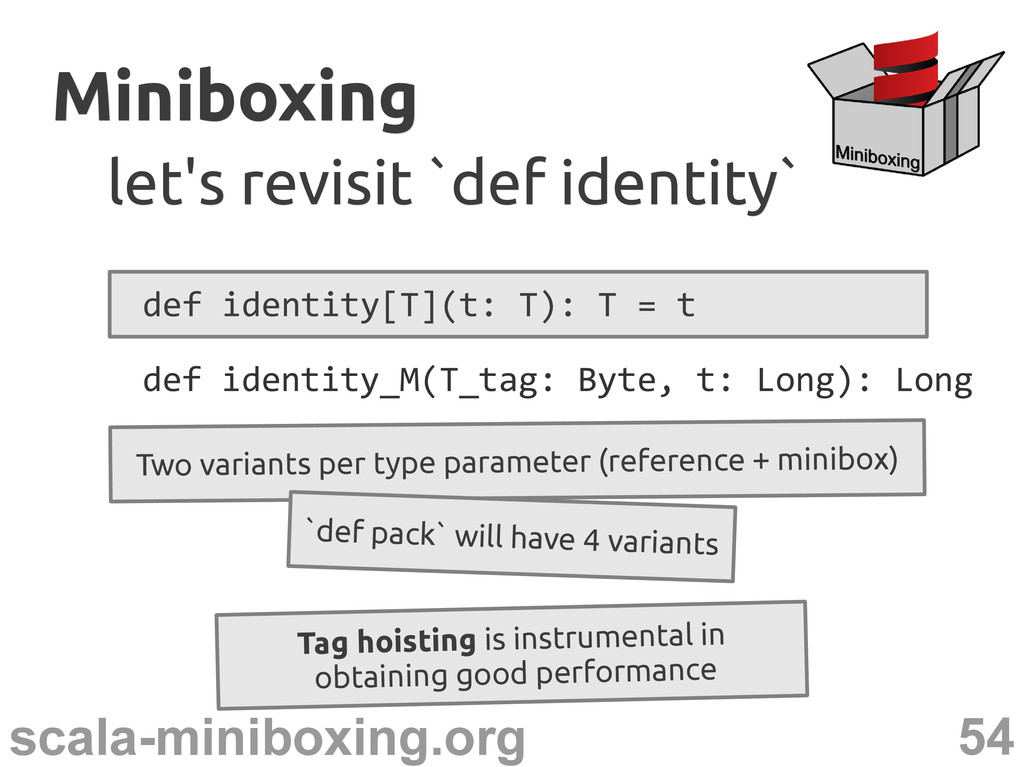
`def identity` def identity[T](t: T): T = t Two variants per type parameter (reference + minibox) `def pack` will have 4 variants def identity_M(T_tag: Byte, t: Long): Long
`def identity` def identity[T](t: T): T = t Two variants per type parameter (reference + minibox) `def pack` will have 4 variants Tag hoisting is instrumental in obtaining good performance def identity_M(T_tag: Byte, t: Long): Long
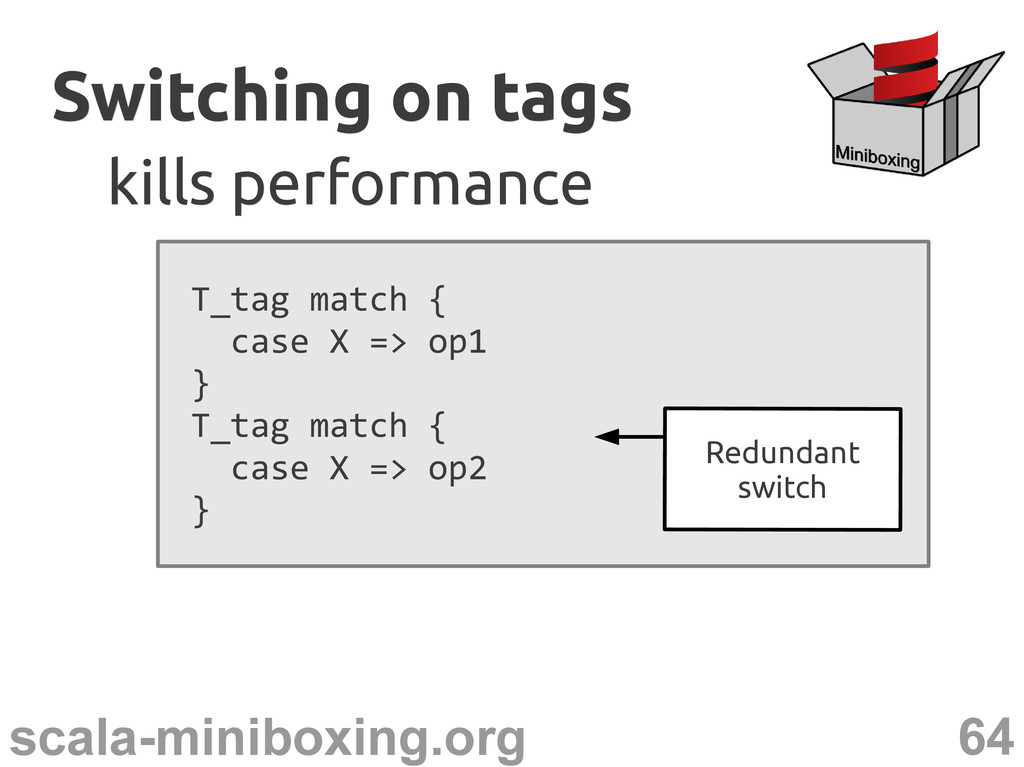
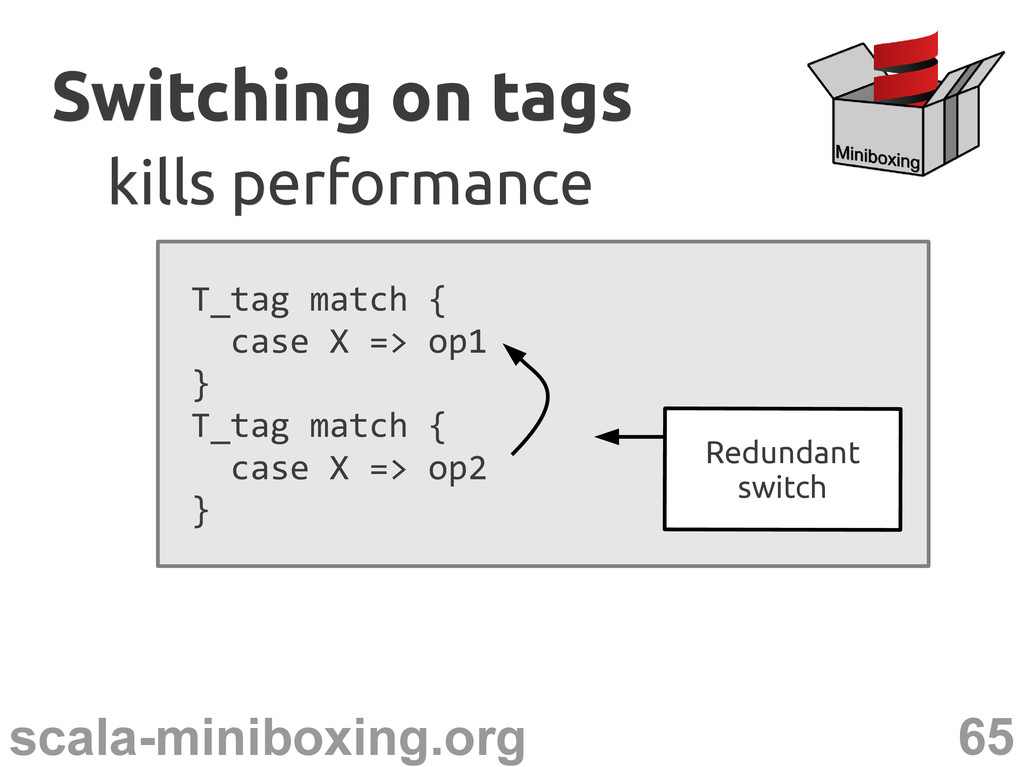
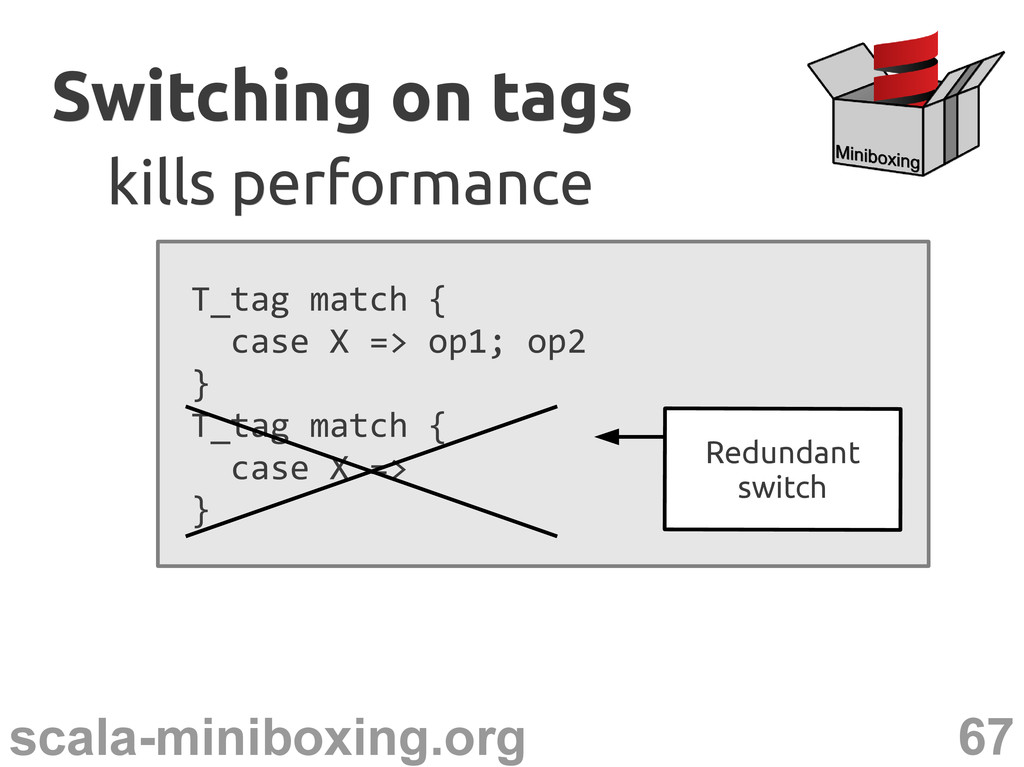
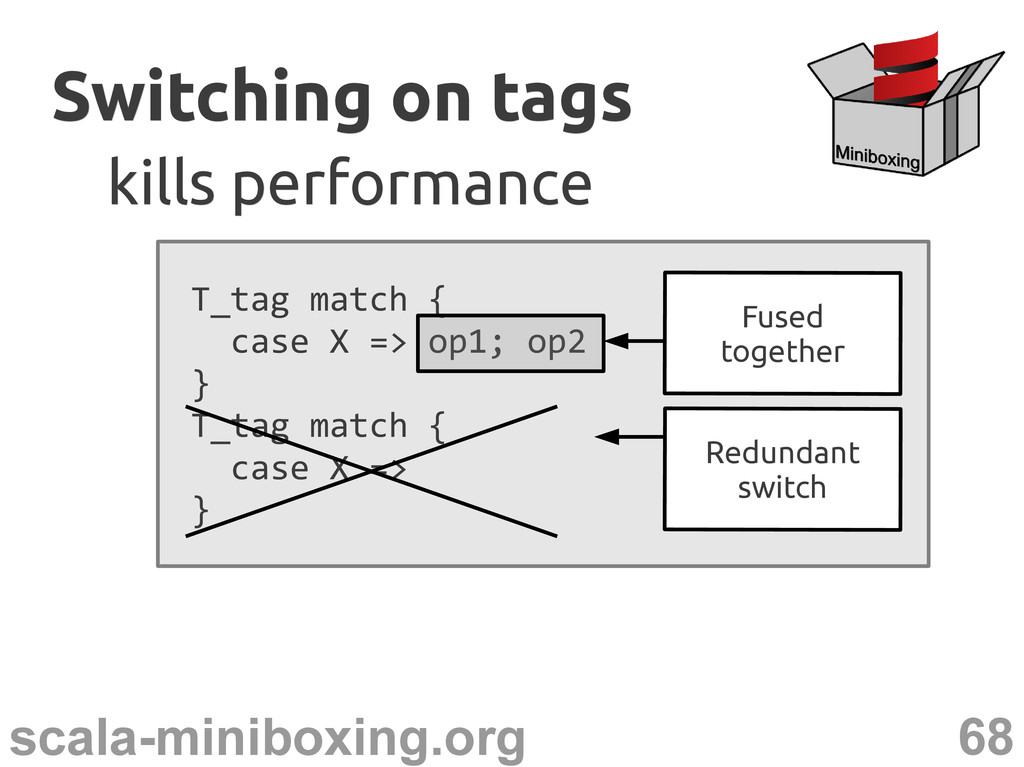
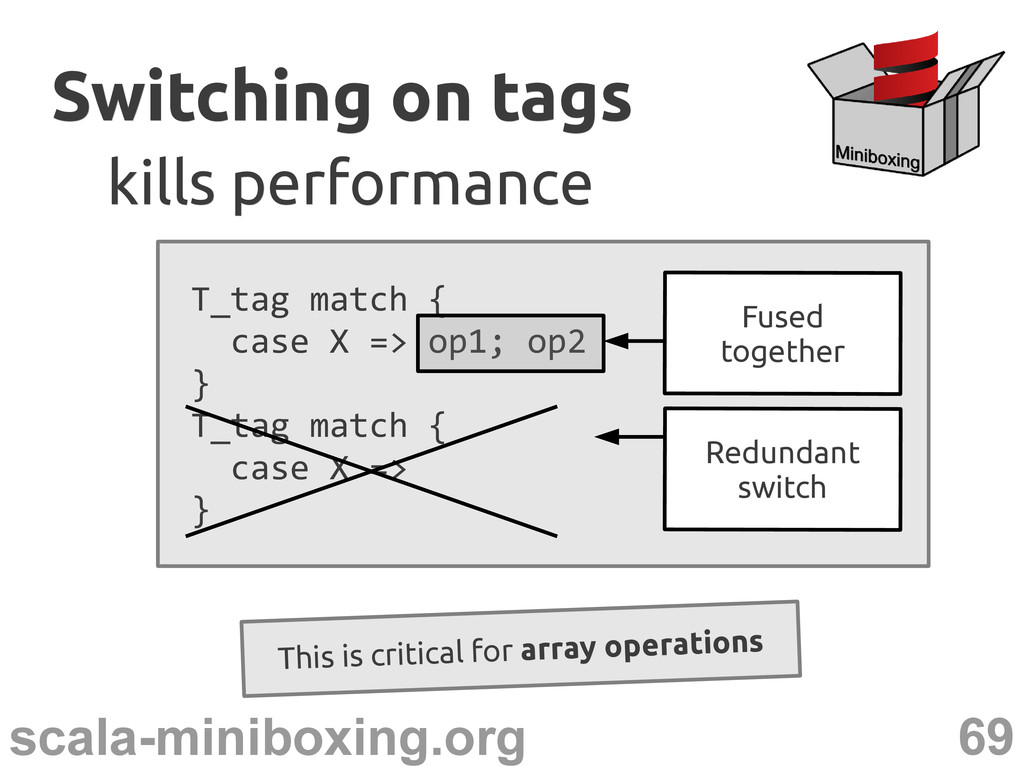
match { case UNIT => ... case BOOL => ... ... } Even more so for consecutive switches Switching on tags Switching on tags kills performance kills performance
} T_tag match { case X => } Switching on tags Switching on tags kills performance kills performance This is critical for array operations Redundant switch Fused together
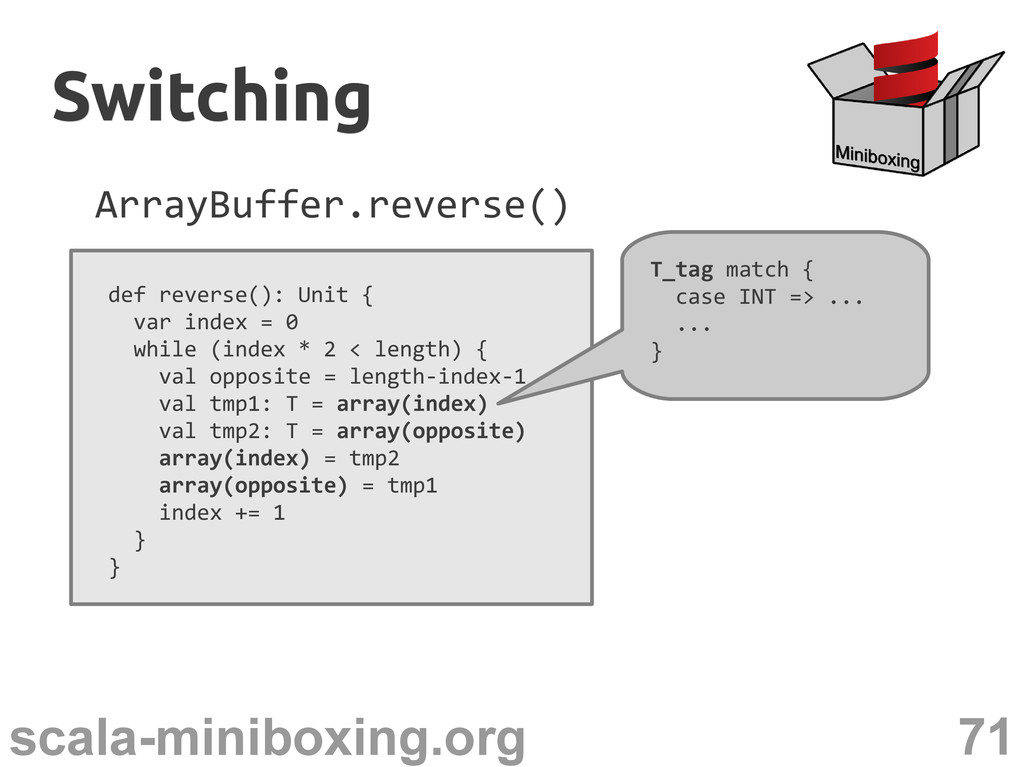
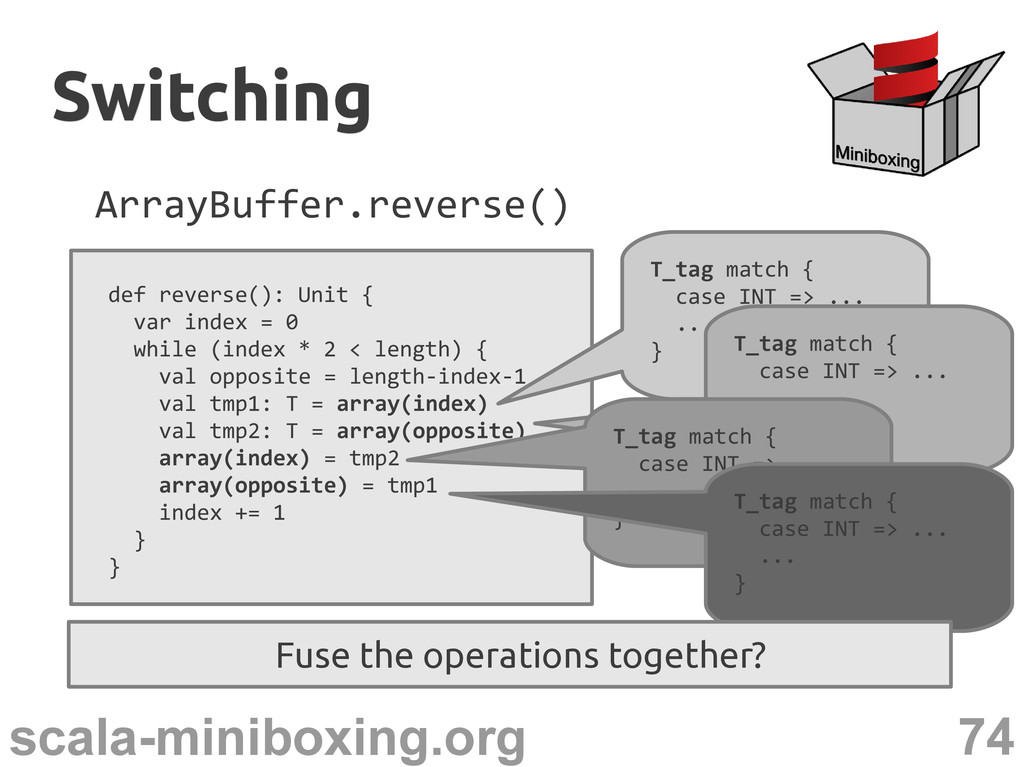
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } Switching Switching
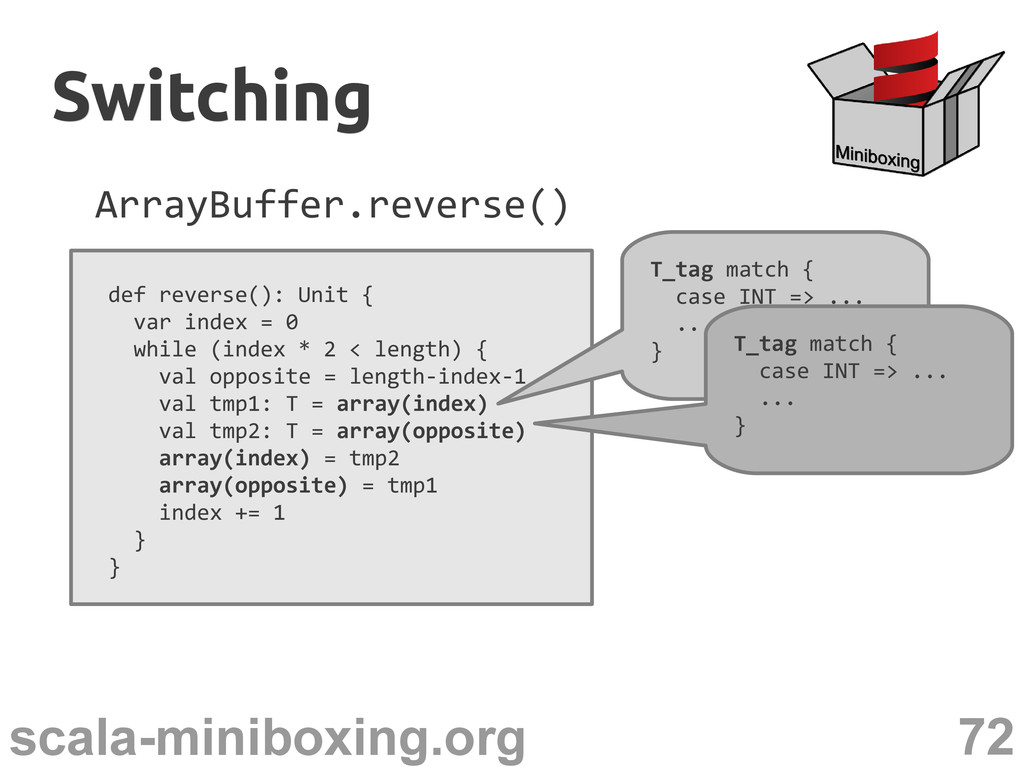
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } T_tag match { case INT => ... ... } Switching Switching
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } T_tag match { case INT => ... ... } T_tag match { case INT => ... ... } Switching Switching
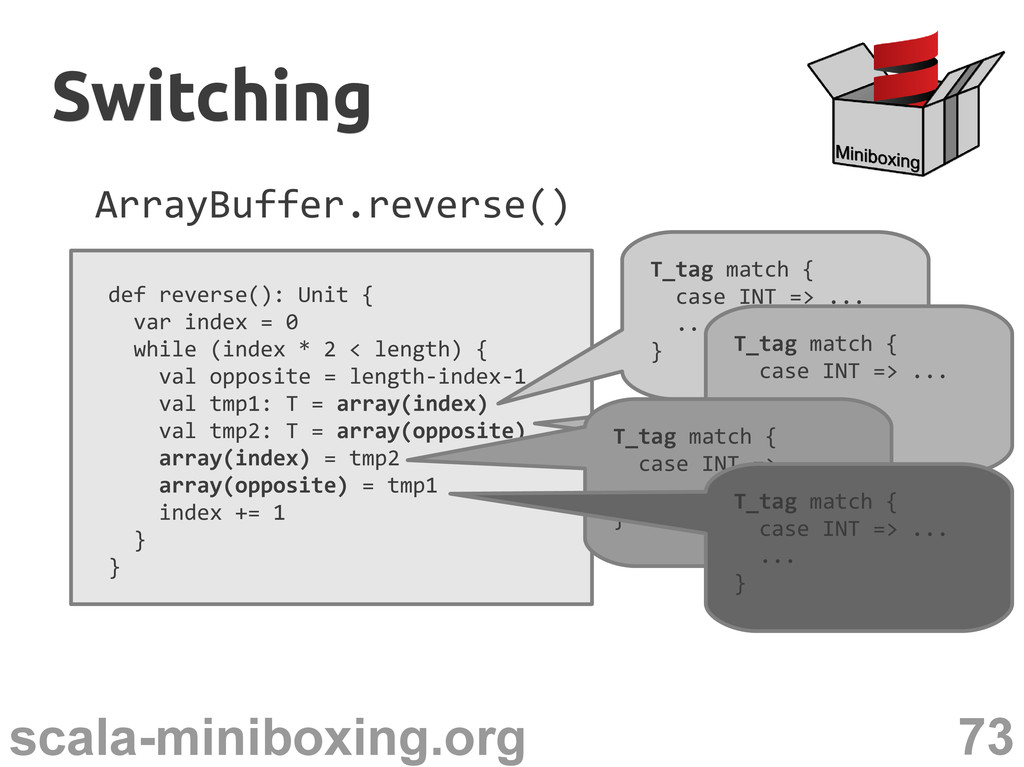
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } T_tag match { case INT => ... ... } T_tag match { case INT => ... ... } T_tag match { case INT => ... ... } T_tag match { case INT => ... ... } Switching Switching
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } T_tag match { case INT => ... ... } T_tag match { case INT => ... ... } T_tag match { case INT => ... ... } T_tag match { case INT => ... ... } Fuse the operations together? Switching Switching
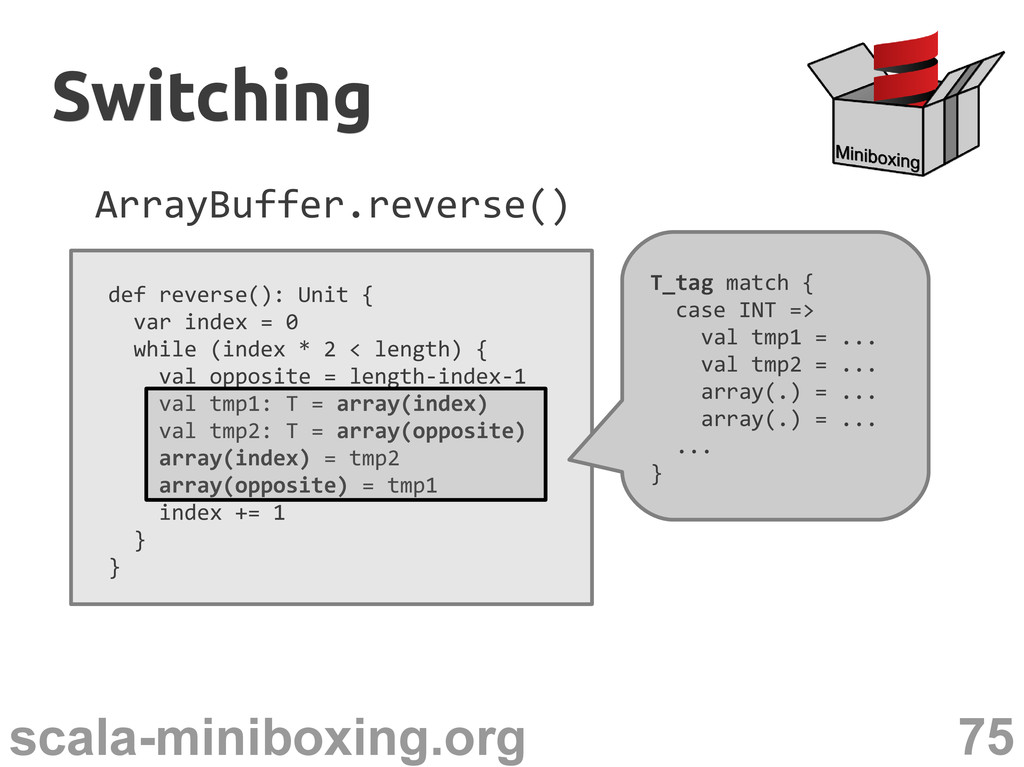
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } T_tag match { case INT => val tmp1 = ... val tmp2 = ... array(.) = ... array(.) = ... ... } Switching Switching
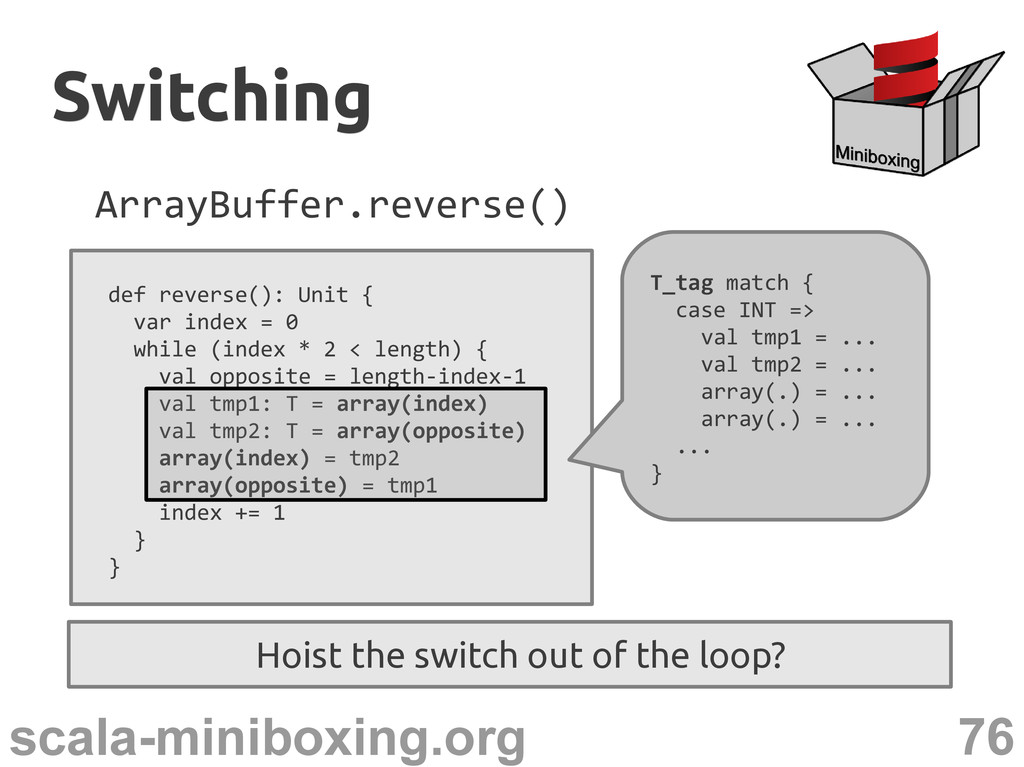
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } T_tag match { case INT => val tmp1 = ... val tmp2 = ... array(.) = ... array(.) = ... ... } Hoist the switch out of the loop? Switching Switching
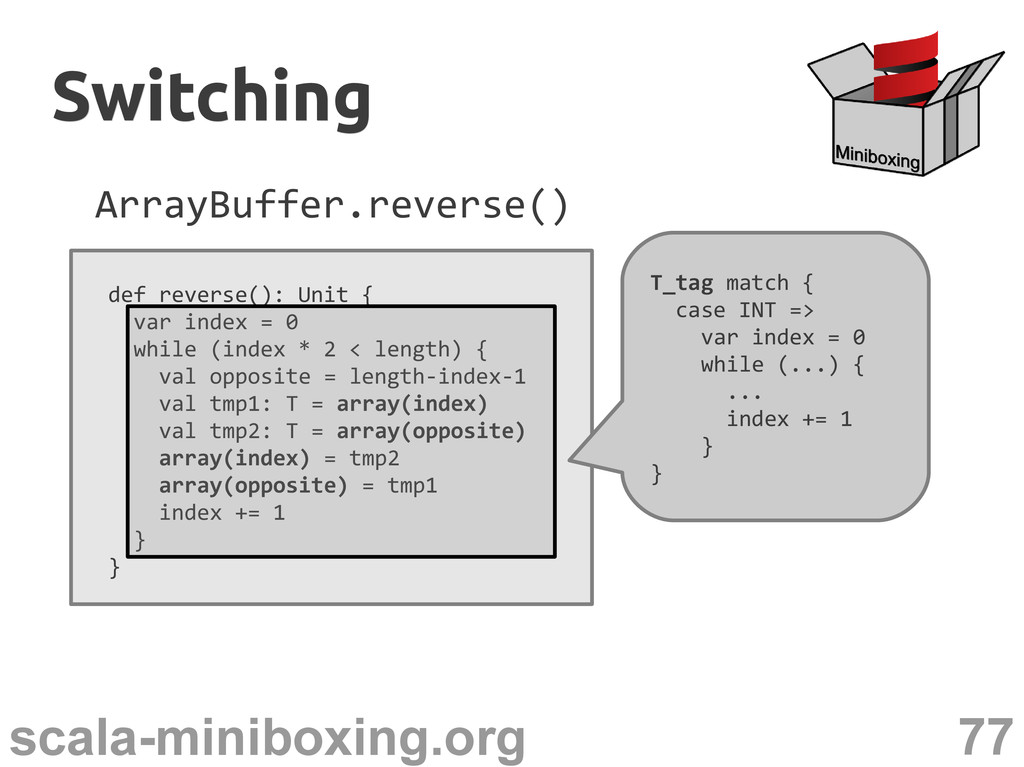
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } Switching Switching T_tag match { case INT => var index = 0 while (...) { ... index += 1 } }
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(opposite) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } Is that enough? Method may be called from a loop Switching Switching T_tag match { case INT => var index = 0 while (...) { ... index += 1 } }
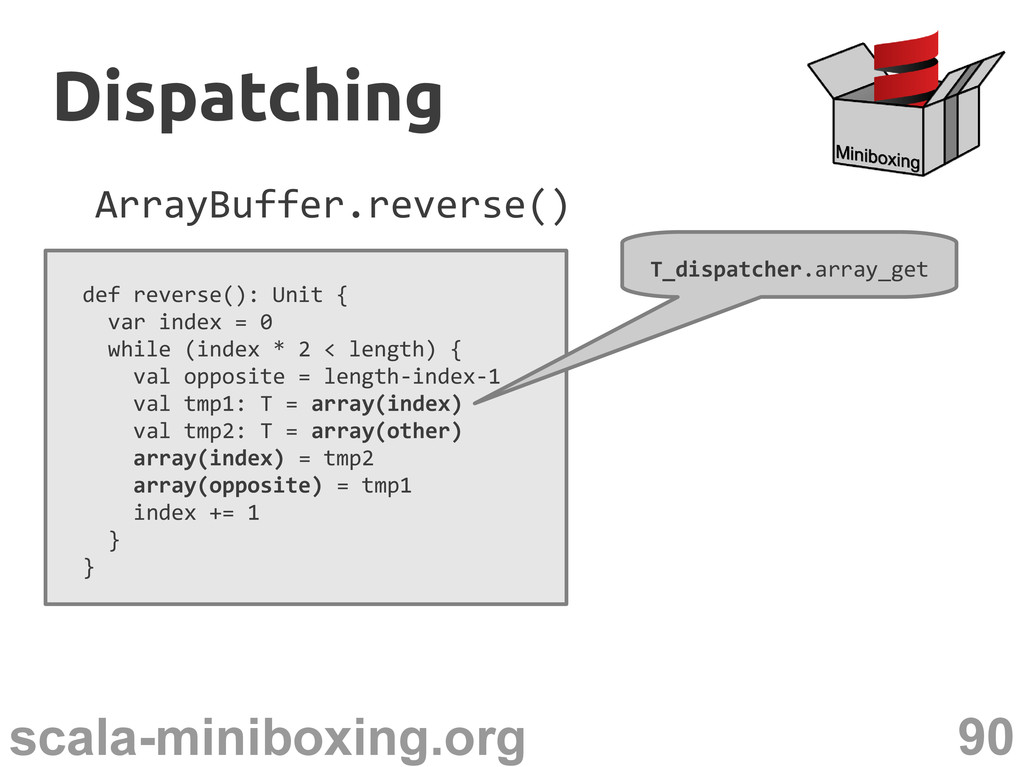
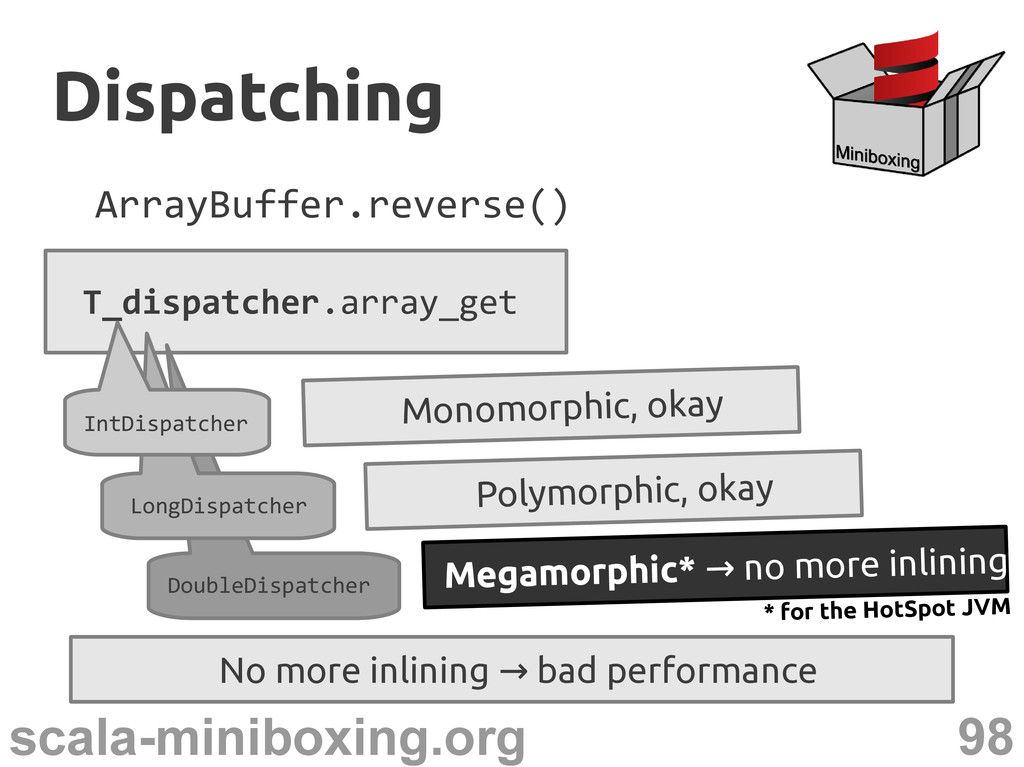
Dispatcher[T] { def array_get(...): Long def array_set(...): Unit } Dispatching Dispatching def identity_M(T_dispatcher: Dispatcher[T], t: Long): Long instead of tag
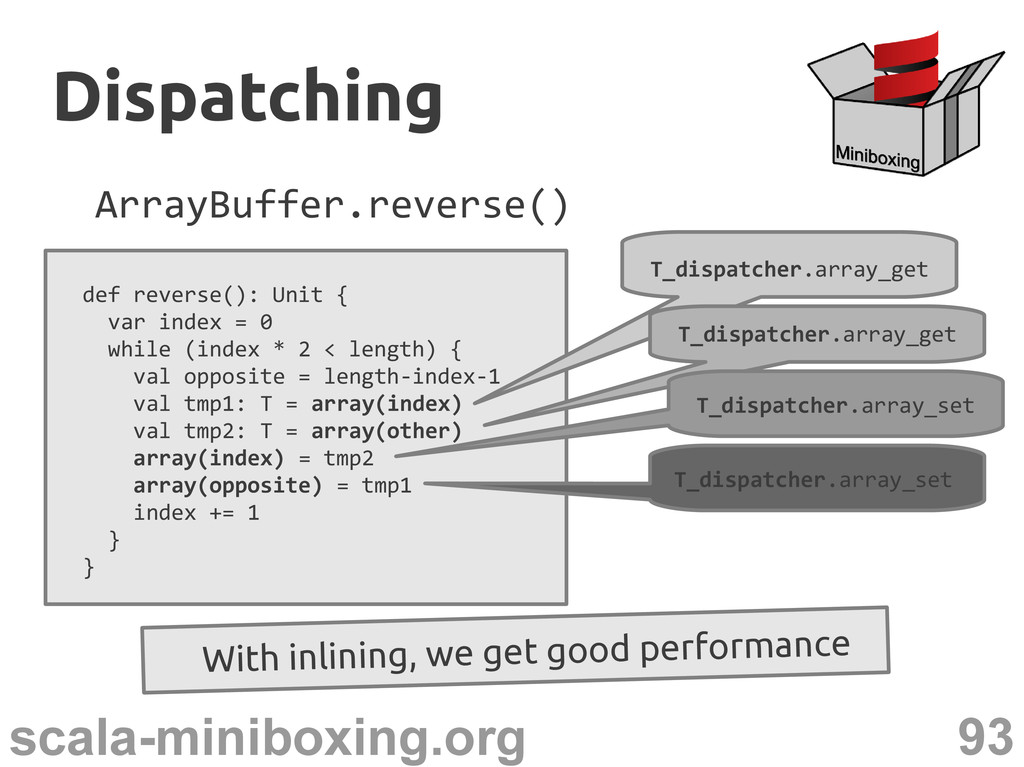
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(other) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } Dispatching Dispatching
0 while (index * 2 < length) { val opposite = length-index-1 val tmp1: T = array(index) val tmp2: T = array(other) array(index) = tmp2 array(opposite) = tmp1 index += 1 } } T_dispatcher.array_get T_dispatcher.array_get T_dispatcher.array_set T_dispatcher.array_set Dispatching Dispatching With inlining, we get good performance
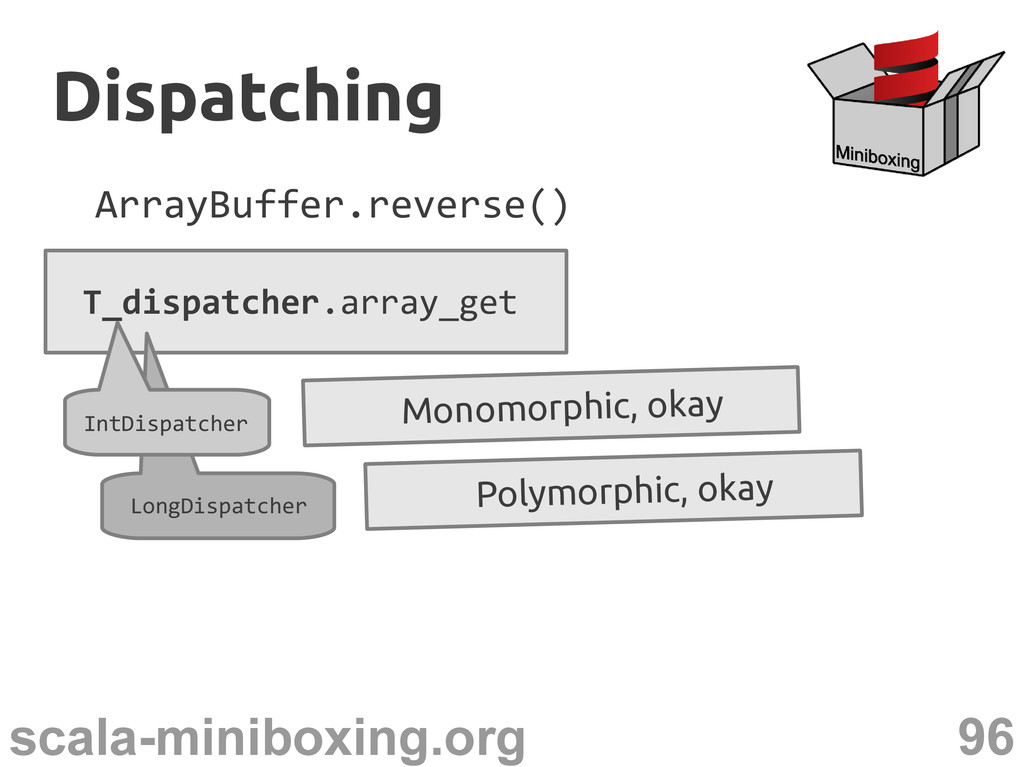
the HotSpot JVM ArrayBuffer.reverse() T_dispatcher.array_get Dispatching Dispatching LongDispatcher Polymorphic, okay IntDispatcher Monomorphic, okay No more inlining bad performance →
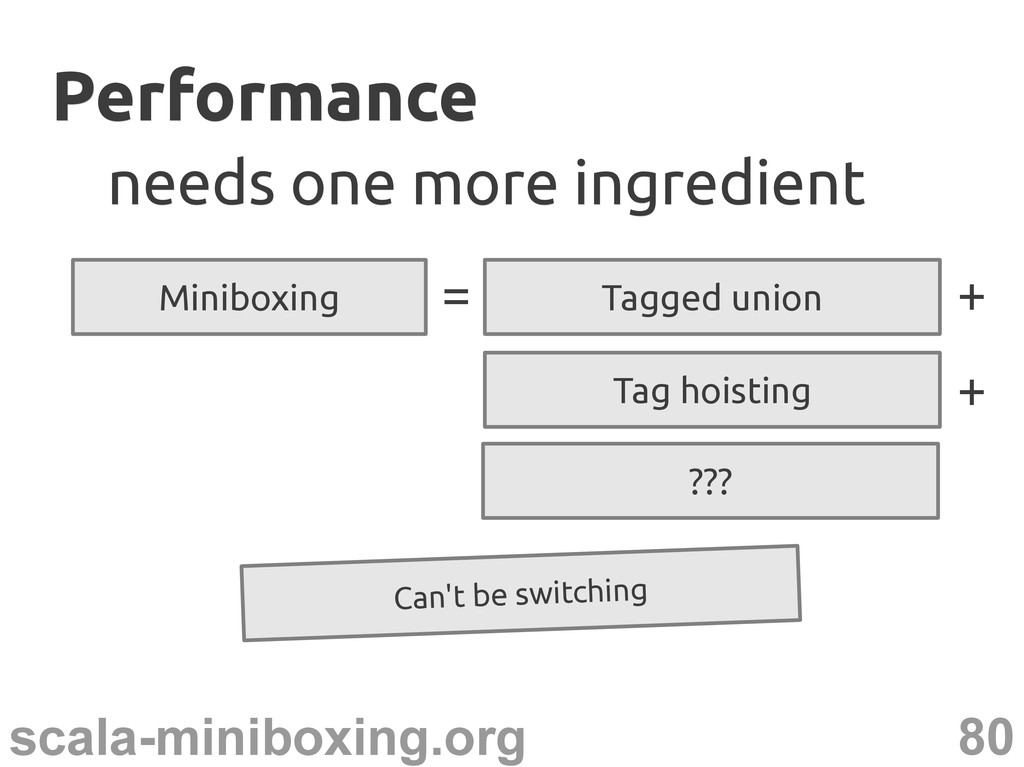
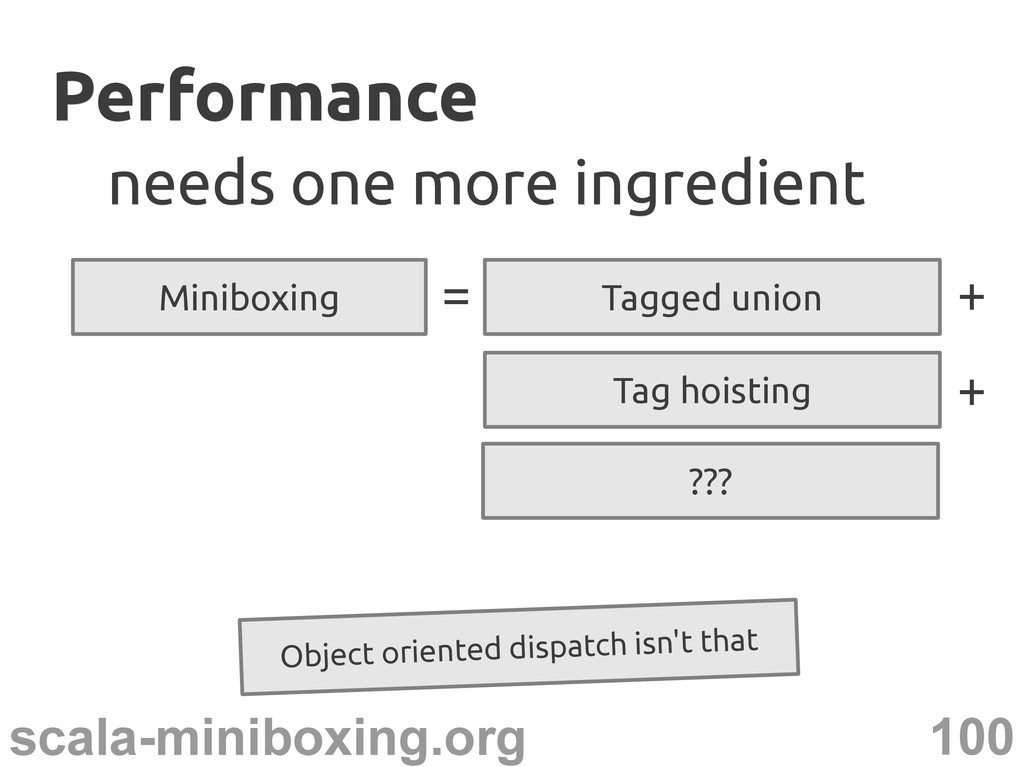
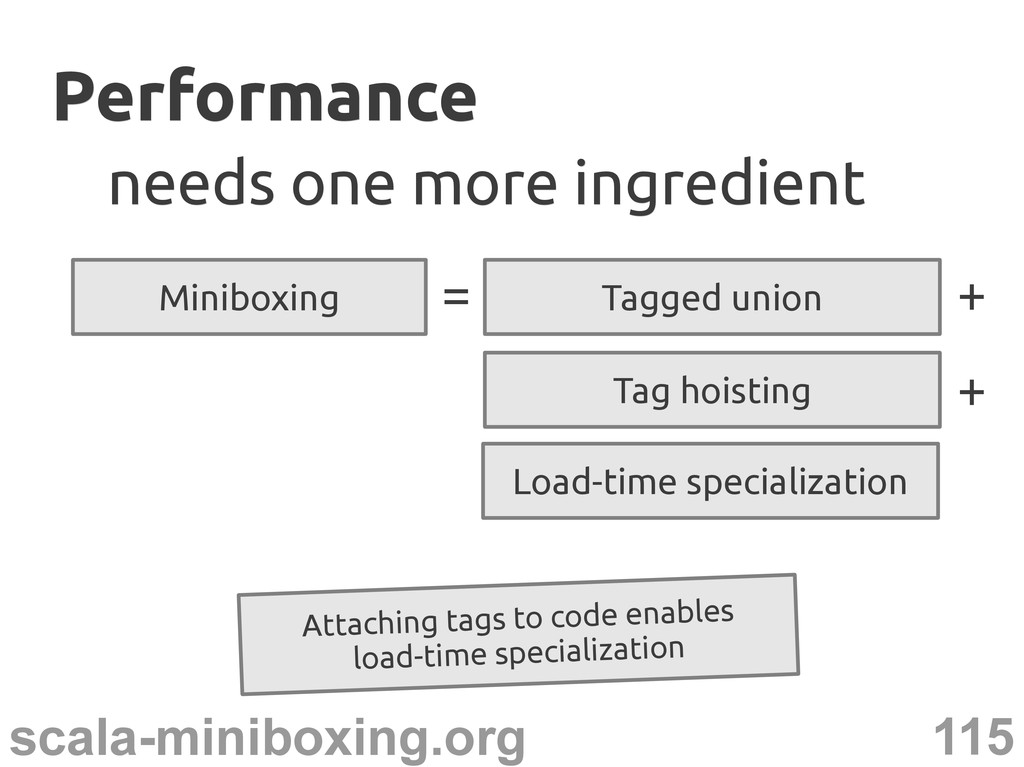
– T_tag is known – T_tag is a constant T_tag match { case INT => ... ... } Encode T_tag in the class name? The secret ingredient The secret ingredient Staticly? Code explosion!
perform constant folding T_tag match { case INT => ... case CHAR => ... case UNIT => ... ... } Load-time specialization Load-time specialization ... INT
perform constant folding – perform dead code elimination Is this the secret ingredient? Yes! Load-time specialization Load-time specialization ... Only the useful code No dispatching
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
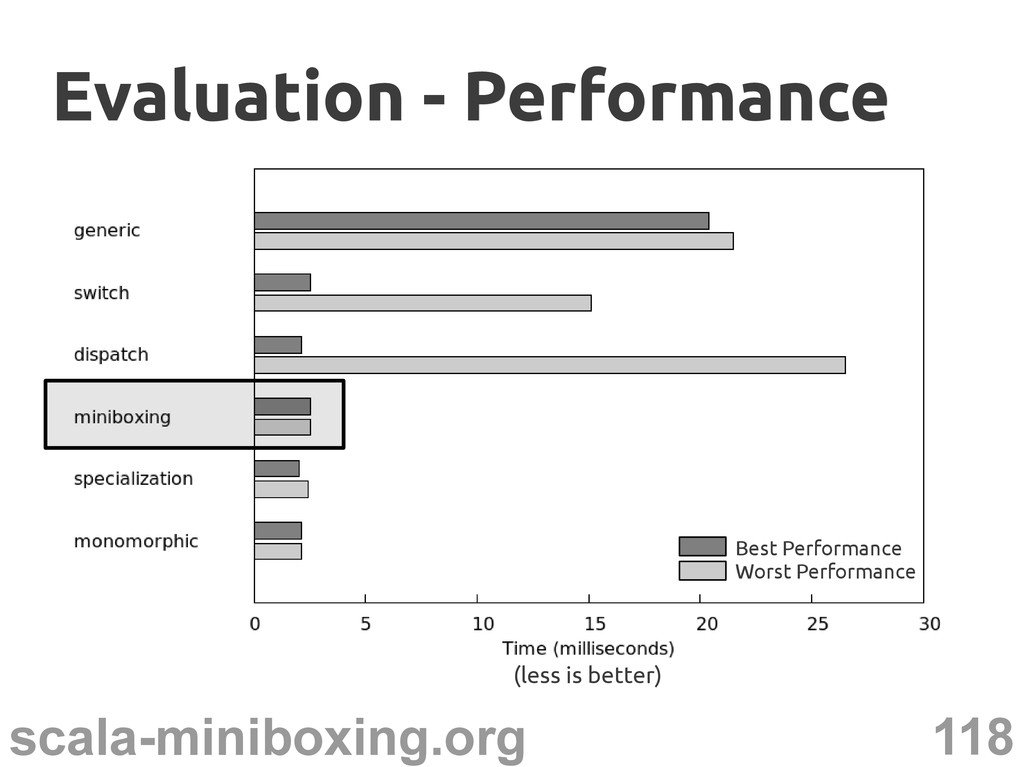{kind=link}
{kind=link}
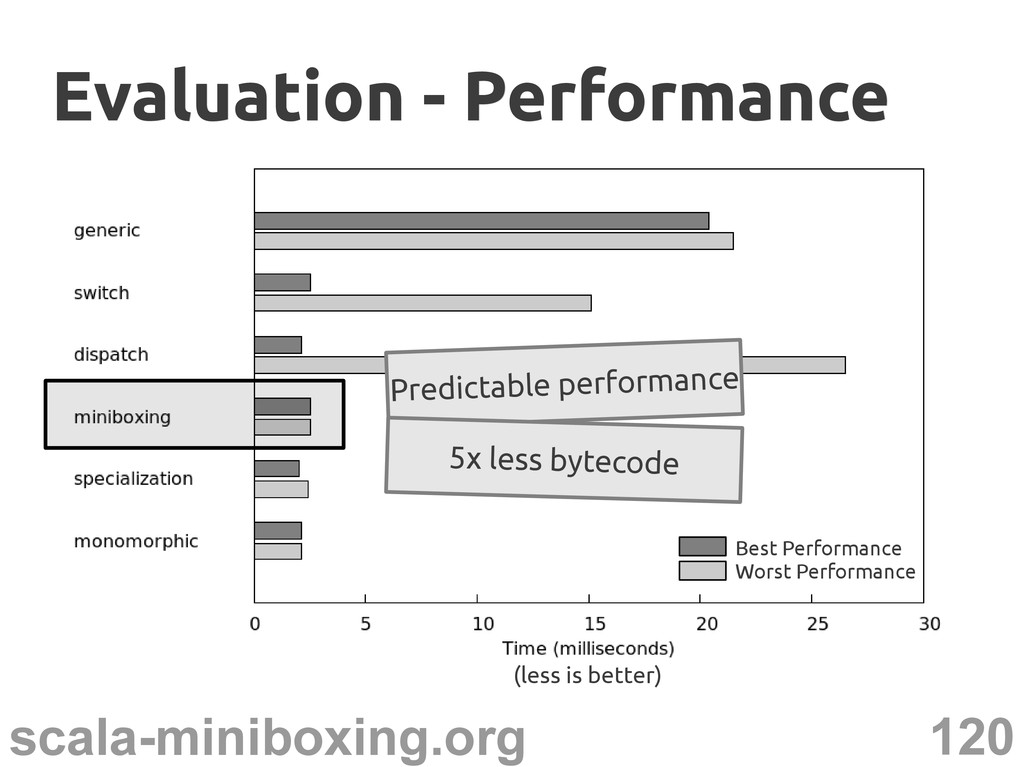{kind=link}
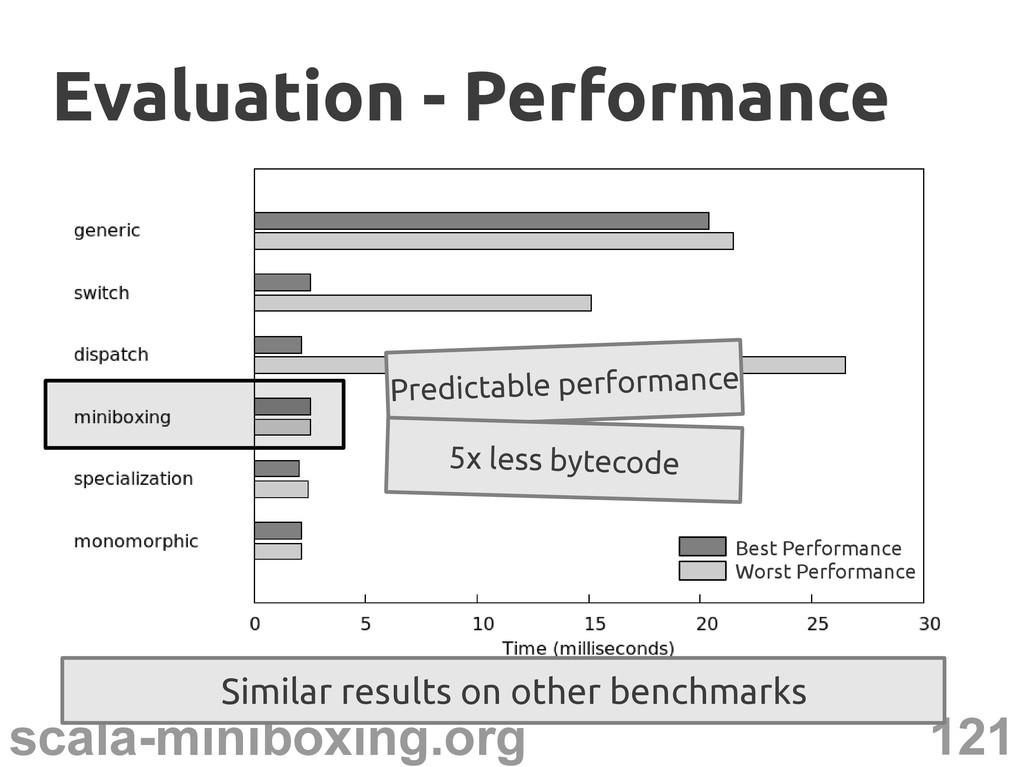{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}