Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Deep Learning 5章後半
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Takahiro Kawashima
May 29, 2018
Science
0
170
Deep Learning 5章後半
ゼミの輪講資料.Goodfellow本5.5節〜5.11節
Takahiro Kawashima
May 29, 2018
Tweet
Share
More Decks by Takahiro Kawashima
See All by Takahiro Kawashima
引力・斥力を制御可能なランダム部分集合の確率分布
wasyro
0
350
集合間Bregmanダイバージェンスと置換不変NNによるその学習
wasyro
0
250
論文紹介:Precise Expressions for Random Projections
wasyro
1
560
ガウス過程入門
wasyro
0
1k
論文紹介:Inter-domain Gaussian Processes
wasyro
0
190
論文紹介:Proximity Variational Inference (近接性変分推論)
wasyro
0
370
機械学習のための行列式点過程:概説
wasyro
0
2k
SOLVE-GP: ガウス過程の新しいスパース変分推論法
wasyro
1
1.5k
論文紹介:Stein Variational Gradient Descent
wasyro
0
1.9k
Other Decks in Science
See All in Science
機械学習 - K近傍法 & 機械学習のお作法
trycycle
PRO
0
1.4k
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.1k
NDCG is NOT All I Need
statditto
2
2.8k
データマイニング - コミュニティ発見
trycycle
PRO
0
210
データマイニング - グラフ埋め込み入門
trycycle
PRO
1
170
あなたに水耕栽培を愛していないとは言わせない
mutsumix
1
270
MCMCのR-hatは分散分析である
moricup
0
600
先端因果推論特別研究チームの研究構想と 人間とAIが協働する自律因果探索の展望
sshimizu2006
3
780
Navigating Weather and Climate Data
rabernat
0
120
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
PRO
0
1.1k
My Little Monster
juzishuu
0
580
良書紹介04_生命科学の実験デザイン
bunnchinn3
0
120
Featured
See All Featured
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
62
50k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Fireside Chat
paigeccino
41
3.8k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
150
Code Reviewing Like a Champion
maltzj
527
40k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.7k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.1k
Designing for Timeless Needs
cassininazir
0
140
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.6k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.1k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.3k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
1
120
Transcript
5 ষ: Machine Learning Basics ౡوେ May 29, 2018 ిؾ௨৴େֶ
ঙݚڀࣨ B4
࣍ 1. ࠷ਪఆ 2. ϕΠζ౷ܭ 3. ڭࢣ͋Γֶश 4. ڭࢣͳֶ͠श 5.
֬తޯ߱Լ๏ (SGD) 6. Deep Learning ͷಈػ 2
࠷ਪఆ
࠷ਪఆ ൘ॻͰΔ 3
ϕΠζ౷ܭ
ϕΠζ౷ܭ ൘ॻͰΔ 4
ڭࢣ͋Γֶश
ڭࢣ͋Γֶश ֬తڭࢣ͋Γֶश ෮श: ҰൠઢܗϞσϧ y = θT
x + ϵ ϵ ∼ N(ϵ|0, σ2) ⇒ p(y|x; θ) = N(y; θT x, σ2) (5.80) ਖ਼نͷఆٛҬ (−∞, ∞) ˠ {0, 1} ͷೋྨʹ͑ͳ͍ 5
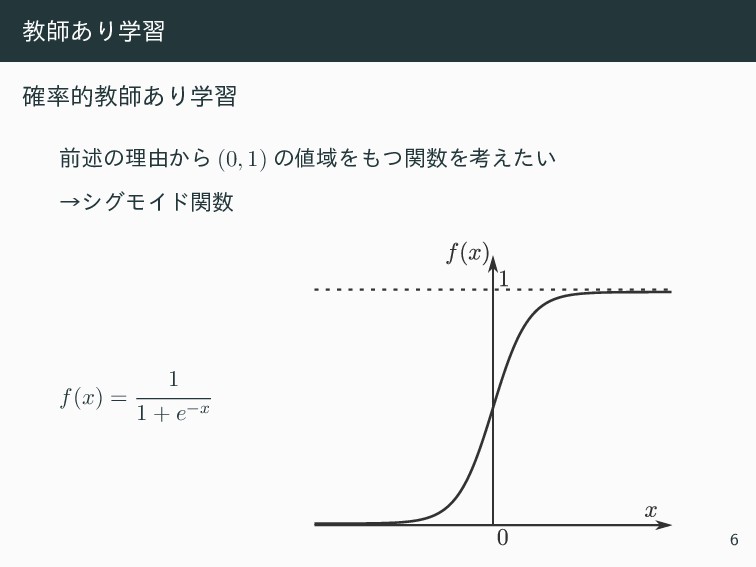
ڭࢣ͋Γֶश ֬తڭࢣ͋Γֶश લड़ͷཧ༝͔Β (0, 1) ͷҬΛͭؔΛߟ͍͑ͨ ˠγάϞΠυؔ f(x) = 1
1 + e−x 6
ڭࢣ͋Γֶश ֬తڭࢣ͋Γֶश ϩδεςΟ οΫճؼ p(y = 1|x; θ) = 1
1 + e−θT x = 1 1 + e−(θ0+θ1x1+θ2x2+··· ) ˠ {0, 1} ͷೋผʹ͑Δ 7
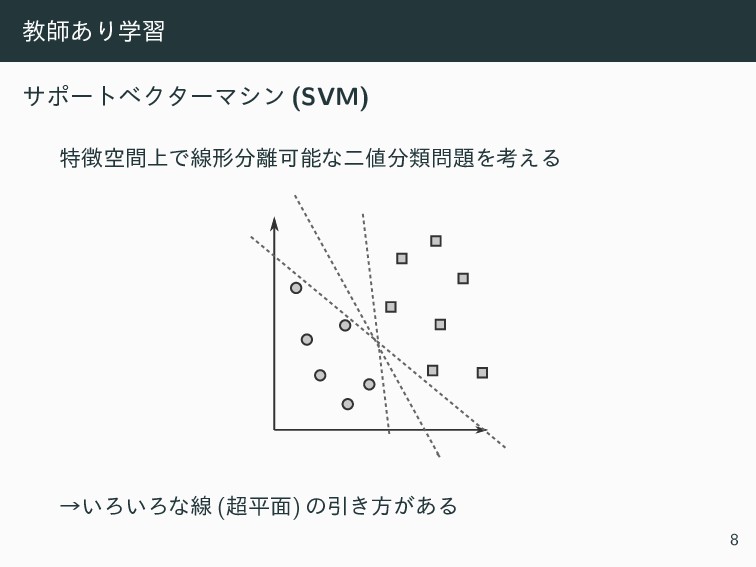
ڭࢣ͋Γֶश αϙʔτϕΫλʔϚγϯ (SVM) ಛ্ۭؒͰઢܗՄೳͳೋྨΛߟ͑Δ ˠ͍Ζ͍Ζͳઢ (ฏ໘) ͷҾ͖ํ͕͋Δ 8
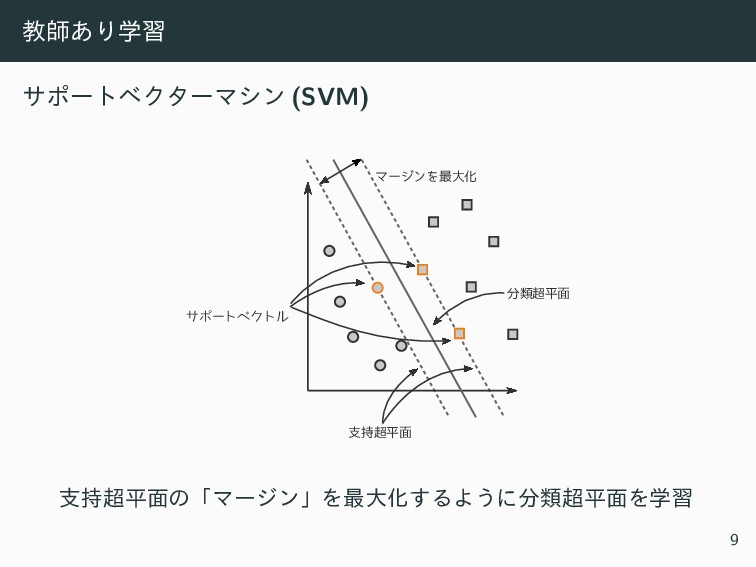
ڭࢣ͋Γֶश αϙʔτϕΫλʔϚγϯ (SVM) マージンを最大化 支持超平面 分類超平面 サポートベクトル ࢧ࣋ฏ໘ͷʮϚʔδϯʯΛ࠷େԽ͢ΔΑ͏ʹྨฏ໘Λֶश 9
ڭࢣ͋Γֶश αϙʔτϕΫλʔϚγϯ (SVM) ฏ໘ͷํఔࣜ ax + by + c =
0 ͳͷͰ͜ΕΛҰൠԽͯ͠ɼྨฏ໘ͷํఔࣜαϙʔτϕΫτ ϧͷू߹ x∗ Λ༻͍ͯ w0 + wT x∗ = 0 ͱॻ͚Δɽֶश͢Δͷ͜ͷ w Ͱ͋Δ 2 ͭͷࢧ࣋ฏ໘ɼྨฏ໘Λ ±k ͚ͩͣΒͯ͠ w0 + wT x∗ = k w0 + wT x∗ = −k ⇒ |w0 + wT x∗| = k Ͱ͋Δ 10
ڭࢣ͋Γֶश αϙʔτϕΫλʔϚγϯ (SVM) ฏ໘ͷࣜఆഒͯ͠ಉ͡ͷΛࣔ͢ͷͰɼֶश݁Ռ͕Ұҙ ʹఆ·Βͳ͍ ˠҰҙੑΛ࣋ͭΑ͏ʹ੍Λ՝͢ ੍: |w0 + wT
x∗| = 1 ॏΈϕΫτϧʹ͍ͭͯඪ४Խ͢Δͱ |w0 + wT x∗| ∥w∥ = 1 ∥w∥ ͜ΕΛ࠷େԽ͢ΔΑ͏ʹֶश͢Δ 11
ڭࢣ͋Γֶश αϙʔτϕΫλʔϚγϯ (SVM) ͜Ε·ͰઢܗՄೳͳͷ ˠઢܗෆՄೳͳΛߟ͍͑ͨ ղܾࡦ: ಛʹඇઢܗมΛࢪͯ͠ผͷಛۭؒʹࣹӨ 12
ڭࢣ͋Γֶश αϙʔτϕΫλʔϚγϯ (SVM) ྫ: ສ༗Ҿྗͷࣜ ಛ: ࣭ྔ m1, m2 ɼڑ
r f(m1, m2, r) = G m1m2 r2 ͜ΕΛ֤ಛʹؔͯ͠ઢܗʹ͍ͨ͠ ˠରΛͱΔ logf(m1, m2, r) = logG + logm1 + logm2 − logr2 ઢܗʹͳͬͨ 13
ڭࢣ͋Γֶश αϙʔτϕΫλʔϚγϯ (SVM) ҰൠʹͱͷಛΑΓߴ࣍ݩͷۭࣹؒӨ͢Δ ˠֶशσʔλ͕ଟ͍ͱܭࢉྔ͕େʹͳΔ ˠ ΧʔωϧτϦοΫͱ͍͏ຐज़Λ༻͍Δͱখ͍͞ܭࢉྔͰߴ࣍ݩ (ແݶ࣍ݩ) ͷࣹӨΛධՁͰ͖Δ 14
ڭࢣͳֶ͠श
ڭࢣͳֶ͠श ओੳ ͬͨͷͰύε 15
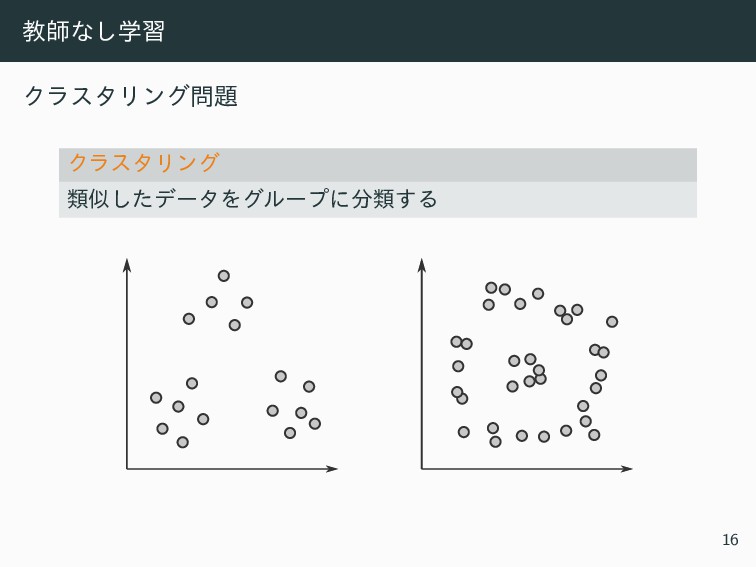
ڭࢣͳֶ͠श ΫϥελϦϯά ΫϥελϦϯά ྨࣅͨ͠σʔλΛάϧʔϓʹྨ͢Δ 16
ڭࢣͳֶ͠श k-means ๏ ΞϧΰϦζϜ 1. Ϋϥελத৺ͷॳظͱͯ͠ɼσʔλ͔Β k ݸͷηϯτϩ ΠυΛϥϯμϜʹબͿ (k
ط) 2. ֤αϯϓϧΛ࠷͍ۙηϯτϩΠυʹׂΓͯΔ 3. ֤ηϯτϩΠυΛࣗʹׂΓͯΒΕͨσʔλͷத৺ʹҠಈ ͢Δ 4. 2,3 Λ܁Γฦ͢ 17
ڭࢣͳֶ͠श k-means ๏ σϞΛΕ http://tech.nitoyon.com/ja/blog/2013/11/07/k-means/ 18
ڭࢣͳֶ͠श ิ: k-means++๏ k-means ๏ॳظґଘੑ͕ඇৗʹߴ͍ ˠ֤ηϯτϩΠυͷॳظΛόϥόϥʹࢃ͘͜ͱͰվળ (k-means++๏) σϞΛΕ https://wasyro.github.io/k-meansppVisualizer/ 19
֬తޯ߱Լ๏ (SGD)
֬తޯ߱Լ๏ (SGD) ίετؔ (ςετ) σʔλ͝ͱͷଛࣦؔͷʹղͰ͖Δ͜ ͱ͕ଟ͍ ઢܗճؼͰɼର L(x, y, θ)
Λ༻͍ͯ J(θ) = Ex,y∼ˆ pdata [L(x, y, θ)] = 1 m m ∑ i=1 L(x(i), y(i), θ) (5.96) L(x(i), y(i), θ) = −logp(y|x, θ) ͜ͷίετؔʹؔͯ͠ɼύϥϝʔλ θ ʹ͍ͭͯޯ๏Λద༻ 20
֬తޯ߱Լ๏ (SGD) ∇θJ(θ) = ∇θ [ 1 m m ∑
i=1 L(x(i), y(i), θ) ] = 1 m m ∑ i=1 ∇θL(x(i), y(i), θ) (5.97) ͜ͷܭࢉྔ O(m) Ͱɼσʔλ͕૿͑Δͱ͔ͳΓͭΒ͍ ˠ֬తޯ߱Լ๏ (SGD) 21
֬తޯ߱Լ๏ (SGD) SGD ޯΛظͰදݱͰ͖Δͱߟ͑ɼαϯϓϧͷখ͍͞αϒ ηοτ (ϛχόον) ͷޯ๏Ͱۙࣅతʹٻ·Δͱ͢Δ B = {x(1),
. . . , x(m′)} ͷϛχόονΛҰ༷ϥϯμϜʹֶशσʔλ ηοτ͔Βͬͯ͘Δ m′ ͍͍ͩͨ 100ʙ300 ͘Β͍Ͱɼm ͕ଟͯ͘ಉ༷ ޯͷਪఆྔ g g = 1 m′ ∇θ m′ ∑ i=1 L(x(i), y(i), θ) (5.98) ύϥϝʔλͷਪఆྔ θ ← θ − ϵg 22
Deep Learning ͷಈػ
Deep Learning ͷಈػ ࣍ݩͷढ͍ ಛྔͷ࣍ݩ͕૿͑ΔͱࢦతʹऔΓ͏ΔΈ߹Θ͕ͤ૿͑Δ ্ਤ֤ಛ͕ͦΕͧΕ 10 ݸͷΛऔΓ͏Δ߹ͷ֓೦ਤ 23
Deep Learning ͷಈػ ࣍ݩͷढ͍ ྫͱͯ͠ k ۙ๏ (k-Nearest Neighbour) ͱ͍͏ֶशΞϧΰϦζϜ
Λߟ͑Δ k ۙ๏ ςετσʔλͷೖྗʹରͯ͠ɼಛ্ۭؒͰͬͱ͍ۙ k ݸ ͷֶशσʔλΛ୳͠ɼͦΕΒͷֶशσʔλͷଐ͢ΔΫϥεͷଟ ܾͰςετσʔλʹׂΓৼΔΫϥεΛܾఆ͢Δ k = 3 ͷ߹ ೖྗ˔ͷϥϕϧ˙ 24
Deep Learning ͷಈػ ࣍ݩͷढ͍ ಛۭؒͰσʔλ͕εΧεΧͰ k ۙ๏Ͱ͏·͍͔͘ͳͦ͞͏ ˠಉ༷ʹଟ͘ͷݹయతػցֶशख๏ͰଠଧͪͰ͖ͳ͘ͳΔ 25
References I [1] ਢࢁರࢤ, ϕΠζਪʹΑΔػցֶशೖ. ߨஊࣾ, 2017. [2] খాਸ, αϙʔτϕΫλʔϚγϯ.
ΦʔϜࣾ, 2007. [3] Sebastian Raschka ஶ, גࣜձࣾΫΠʔϓ༁, ୡਓσʔλαΠ ΤϯςΟετʹΑΔཧͱ࣮ફ Python ػցֶशϓϩάϥϛ ϯά, ΠϯϓϨε, 2016.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References I [1] ਢࢁರࢤ, ϕΠζਪʹΑΔػցֶशೖ. ߨஊࣾ, 2017. [2] খాਸ, αϙʔτϕΫλʔϚγϯ.](https://files.speakerdeck.com/presentations/7c0b46c431bd4639b5a90fecf39d340a/slide_31.jpg){kind=link}