Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
他チームへ越境したら、生データ提供ソリューションのクエリ費用95%削減へ繋がった話 / Cro...
Search
yamamoto-yuta
May 27, 2025
Technology
890
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
他チームへ越境したら、生データ提供ソリューションのクエリ費用95%削減へ繋がった話 / Cross-Team Impact: 95% Off Raw Data Query Costs
DataOps Night #7 登壇資料
https://finatext.connpass.com/event/350823/
yamamoto-yuta
May 27, 2025
More Decks by yamamoto-yuta
See All by yamamoto-yuta
プロダクトデザイナーに学ぶ、『見る気が起きる』ダッシュボードの作り方 / Creating Engaging Dashboards: Lessons from Product Designers
yamamotoyuta
3
890
「必要とされるデータ基盤」であり続けるためにやってきたこと / What We've Done to Make a Needed Data Analytics Platforms Grow
yamamotoyuta
0
610
プロダクト観点で考えるデータ基盤の育成戦略 / Growth Strategy of Data Analytics Platforms from a Product Perspective
yamamotoyuta
1
2.3k
ヤプリのデータカタログ整備 1年間の歩み / Progress of Building a Data Catalog at Yappli
yamamotoyuta
4
4.3k
私のdbt布教用資料 〜TROCCOUG Ver.〜 / My Guide to Evangelizing dbt - TROCCOUG Ver.
yamamotoyuta
1
3.2k
データカタログの最初の一歩 〜データ組織向けに dbt docs を整備している話〜 / Maintaining dbt docs for data organizations
yamamotoyuta
2
3.7k
次の10年を戦える分析用データ基盤構築の第一歩 - dbtによる基盤刷新とクエリ費用90%削減への取り組み -
yamamotoyuta
1
2.1k
技術書LT #11 実践 Docker - ソフトウェアエンジニアの「Docker よくわからない」を終わりにする本
yamamotoyuta
0
1.8k
Other Decks in Technology
See All in Technology
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
320
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
260
cccccc
moznion
0
1.9k
Making sense of Google’s agentic dev tools
glaforge
1
140
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
200
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
600
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
2.8k
DatabricksにおけるMCPソリューション
taka_aki
1
210
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
160
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
130
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
1
120
Featured
See All Featured
Large-scale JavaScript Application Architecture
addyosmani
515
110k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Google's AI Overviews - The New Search
badams
0
1.1k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
4 Signs Your Business is Dying
shpigford
187
22k
So, you think you're a good person
axbom
PRO
2
2.1k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
260
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Transcript
他チームへ越境したら、 ⽣データ提供ソリューションの クエリ費⽤95%削減へ繋がった話 DataOps Night #7 株式会社ヤプリ ⼭本 雄太
SPEAKER 開発統括本部 プロダクト開発本部 データサイエンス室(以下、DS室) ⼭本 雄太 • 2023年に新卒⼊社 • dbt導⼊に際して、開発体制やリリースフローなどの 構築を担当
• pUG(旧TROCCOUG)の運営にも携わらせていただ いています
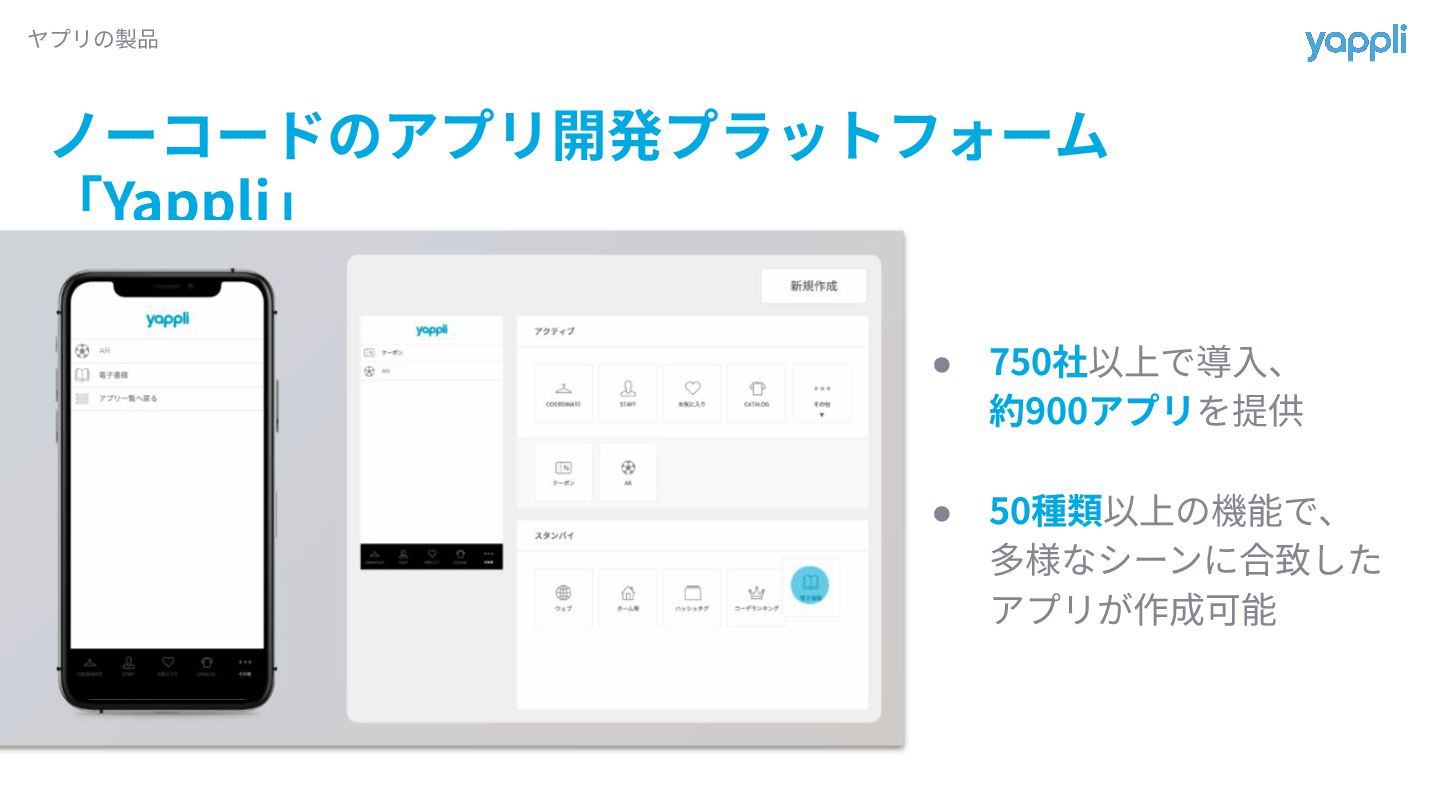
ノーコードのアプリ開発プラットフォーム 「Yappli」 ヤプリの製品 • 750社以上で導⼊、 約900アプリを提供 • 50種類以上の機能で、 多様なシーンに合致した アプリが作成可能
Yappli導⼊顧客向けにアナリティクスサービスを提供 ヤプリの製品 CMS ダッシュボード Yappli 管理画⾯のトップに 表⽰されるダッシュボード Yappli Data Hub
アプリ内の⾏動データや属性データを ユーザ単位で分析を可能にする データ連携サービス Yappli Analytics アプリログを網羅した分析や、 機能別に特化した分析が可能な ダッシュボード 無償 有償
Yappli導⼊顧客向けにアナリティクスサービスを提供 ヤプリの製品 CMS ダッシュボード Yappli 管理画⾯のトップに 表⽰されるダッシュボード Yappli Data Hub
アプリ内の⾏動データや属性データを ユーザ単位で分析を可能にする データ連携サービス Yappli Analytics アプリログを網羅した分析や、 機能別に特化した分析が可能な ダッシュボード 無償 有償 ここの話をします
「Yappli Data Hub」サービスとは? ヤプリの製品 • アプリ内の⾏動データや属性データをユーザ単位で分析可能にするデータ連携 サービス • 集約(GROUP BYする)前の⽣データを提供
◦ 顧客は⽣データをそのまま分析したり、⾃社のCRM‧CDPへ取り込んだりして活⽤
今⽇お話しすること Yappli Data Hubの開発チームへ越境 ▼ Yappli Data Hubのクエリ費⽤の 95%削減へ繋がった!(まだ絶賛進⾏中) 繋がった経緯、取り組んだことについてお話しします!
INDEX ⽬次 1. 越境‧クエリ費⽤削減の経緯 2. コストインパクトの試算 3. 実⾏ジョブの時系列整理 4. 顧客影響との折り合い
5. 得られた学び‧恩恵
越境‧クエリ費⽤削減の経緯
2023年から分析⽤データ基盤の 移⾏を開始 (詳細はテックブログに⾊々記事書いてます: https://tech.yappli.io/archive/category/dbt )
Yappli導⼊顧客向けにアナリティクスサービスを提供 1. 越境‧クエリ費⽤削減の経緯 CMS ダッシュボード Yappli 管理画⾯のトップに 表⽰されるダッシュボード Yappli Data
Hub アプリ内の⾏動データや属性データを ユーザ単位で分析を可能にする データ連携サービス Yappli Analytics アプリログを網羅した分析や、 機能別に特化した分析が可能な ダッシュボード 無償 有償 あとはココだけ!
当時のYappli Data Hubの開発体制 • エンジニアのみで開発‧保守 = DS室としてはブラックボックスな状態 • エンジニアも引き継ぎで後からジョイン‧他業務の⽚⼿間 → 専任エンジニアがいない状態 → データ基盤として全体像を把握している⼈がいなかった 当時、Yappli
Data Hubの開発チームで週次定例を⾏っていた → そこへ私が突撃 1. 越境‧クエリ費⽤削減の経緯 Yappli Data Hubの開発チームに参加
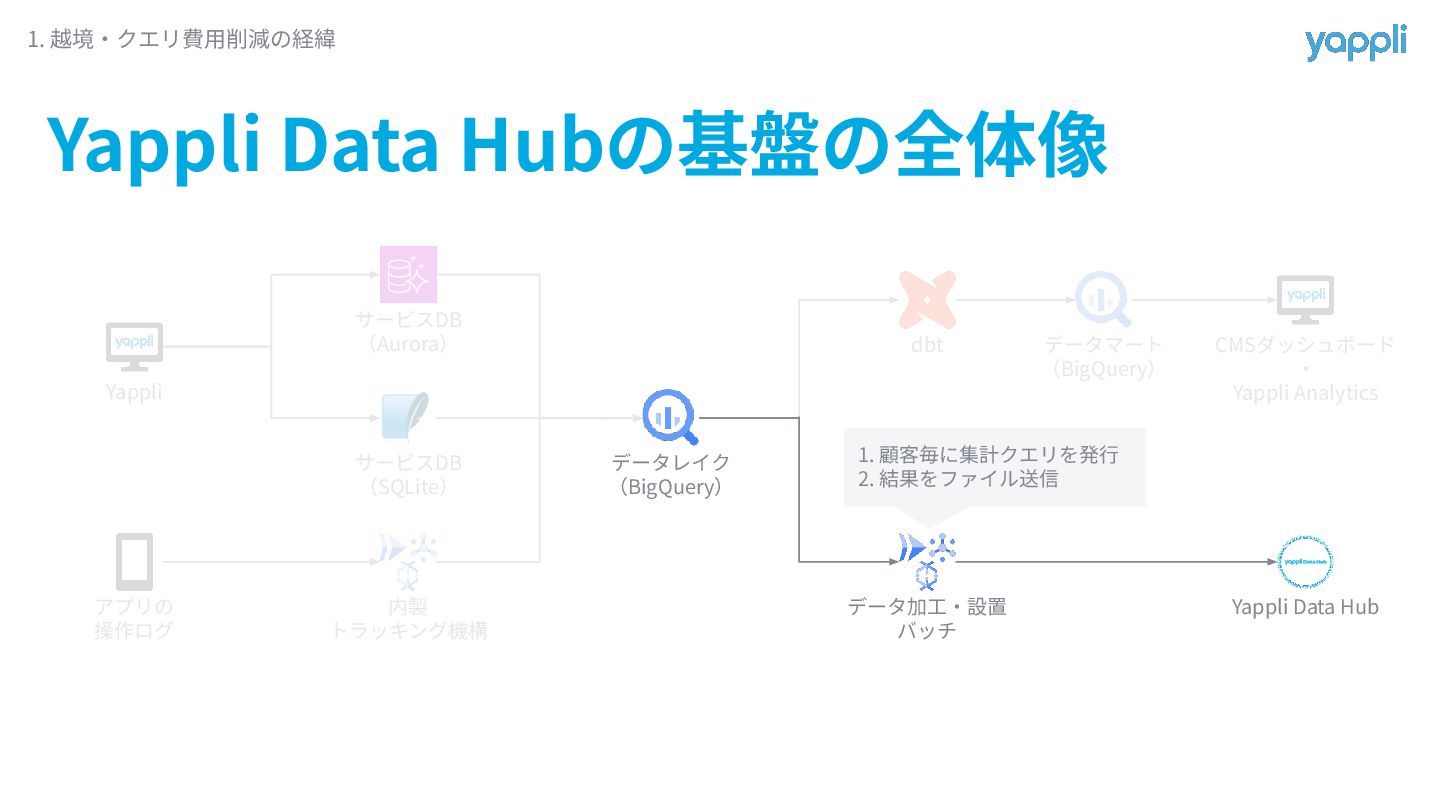
参加して取り組んだこと Yappli Data Hubについてのキャッチアップ • データ基盤としての全体像の整理 • ドキュメント更新 • DS室で巻き取るべき業務の特定 → 実際に巻き取り
◦ サービスDB→DWH(BigQuery)への同期対象テーブルの追加 1. 越境‧クエリ費⽤削減の経緯
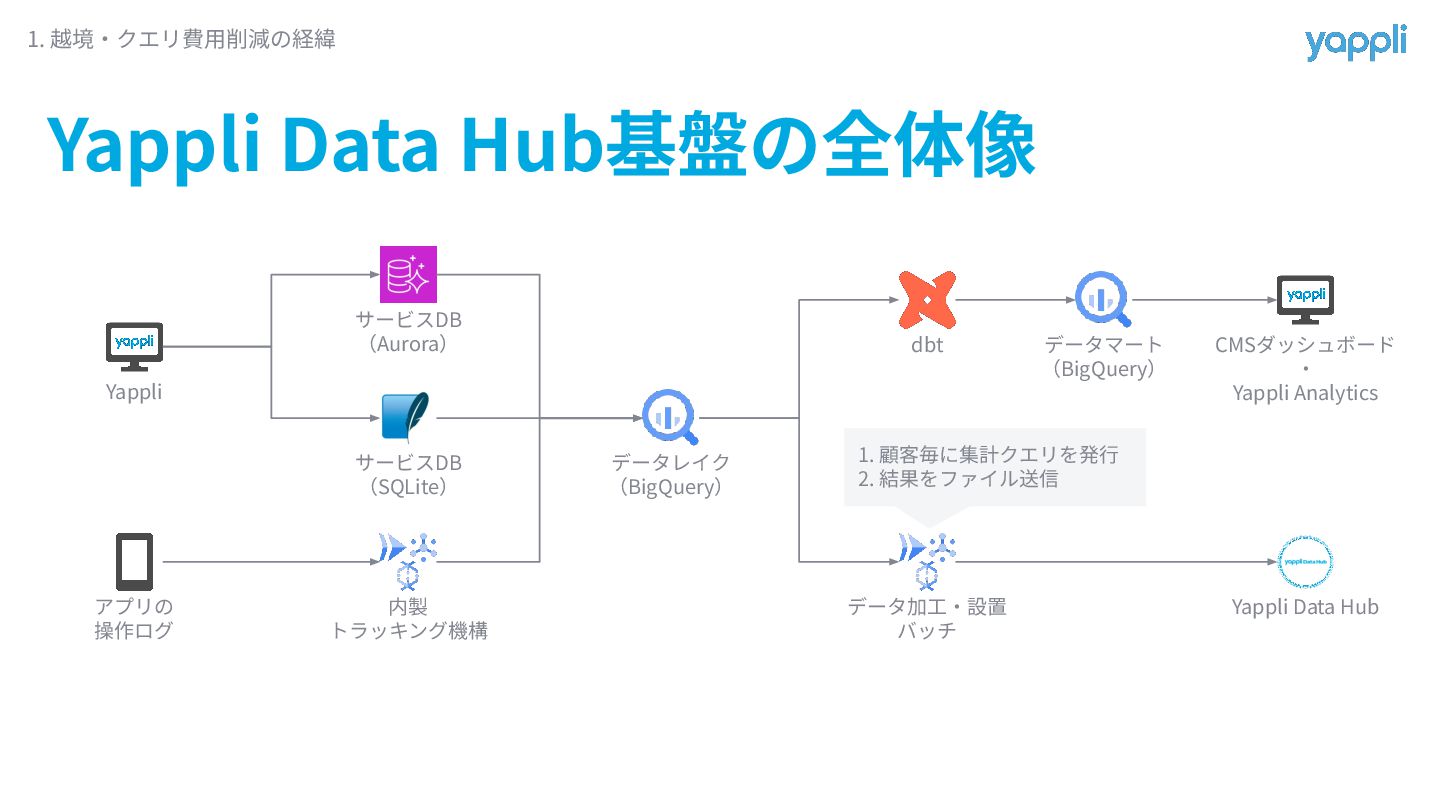
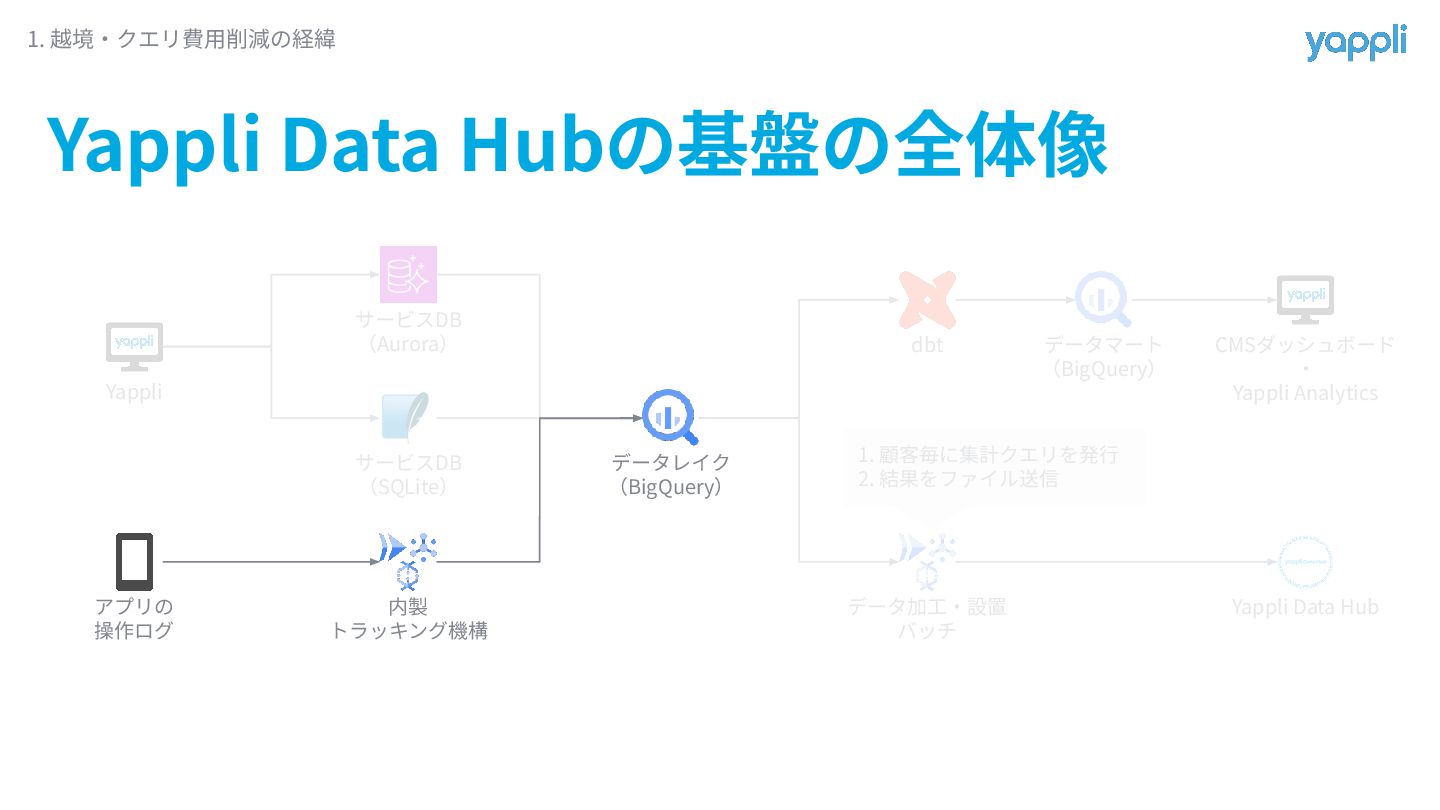
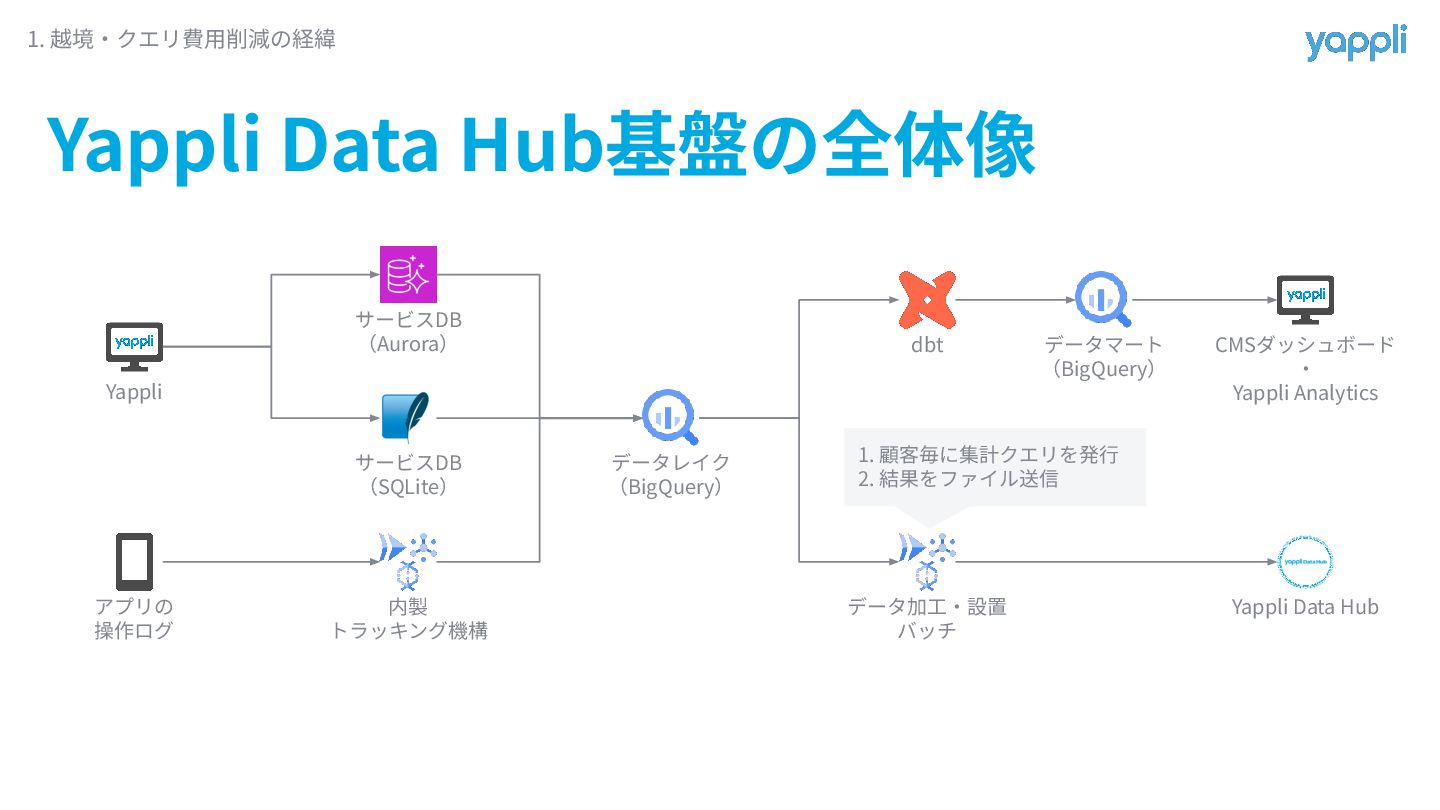
Yappli Data Hub基盤の全体像 1. 越境‧クエリ費⽤削減の経緯 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信 CMSダッシュボード ‧ Yappli Analytics
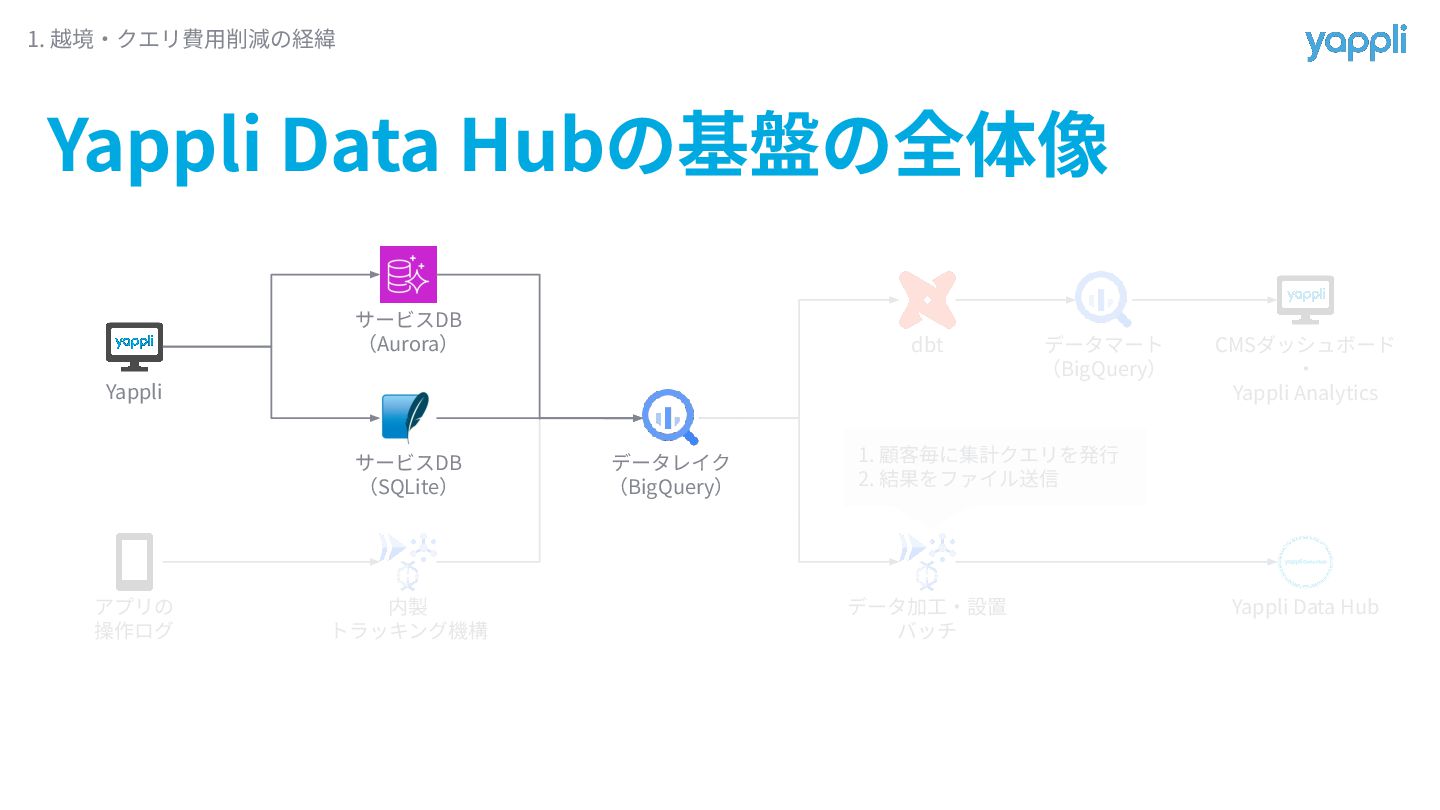
Yappli Data Hubの基盤の全体像 1. 越境‧クエリ費⽤削減の経緯 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信 CMSダッシュボード ‧ Yappli Analytics
Yappli Data Hubの基盤の全体像 1. 越境‧クエリ費⽤削減の経緯 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信 CMSダッシュボード ‧ Yappli Analytics
Yappli Data Hubの基盤の全体像 1. 越境‧クエリ費⽤削減の経緯 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ CMSダッシュボード ‧ Yappli Analytics Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信
Yappli Data Hubの基盤の全体像 1. 越境‧クエリ費⽤削減の経緯 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信 CMSダッシュボード ‧ Yappli Analytics
Yappli Data Hub基盤の全体像 1. 越境‧クエリ費⽤削減の経緯 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信 CMSダッシュボード ‧ Yappli Analytics
会社的にコスト削減の波が到来 • Yappli Data Hubのクエリ費⽤がかなり⾼額になってしまっていた → なんとか削減できないか? 1. 越境‧クエリ費⽤削減の経緯
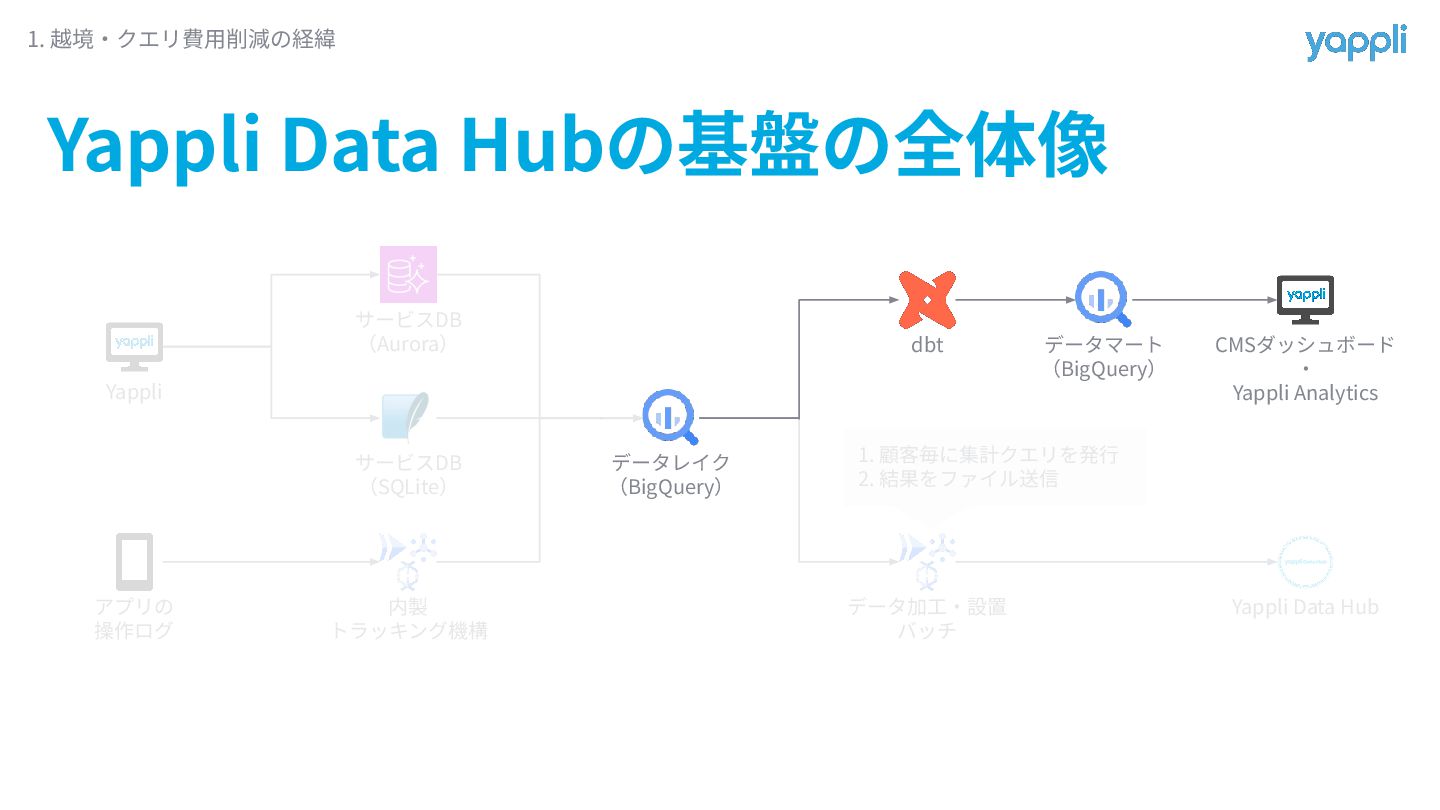
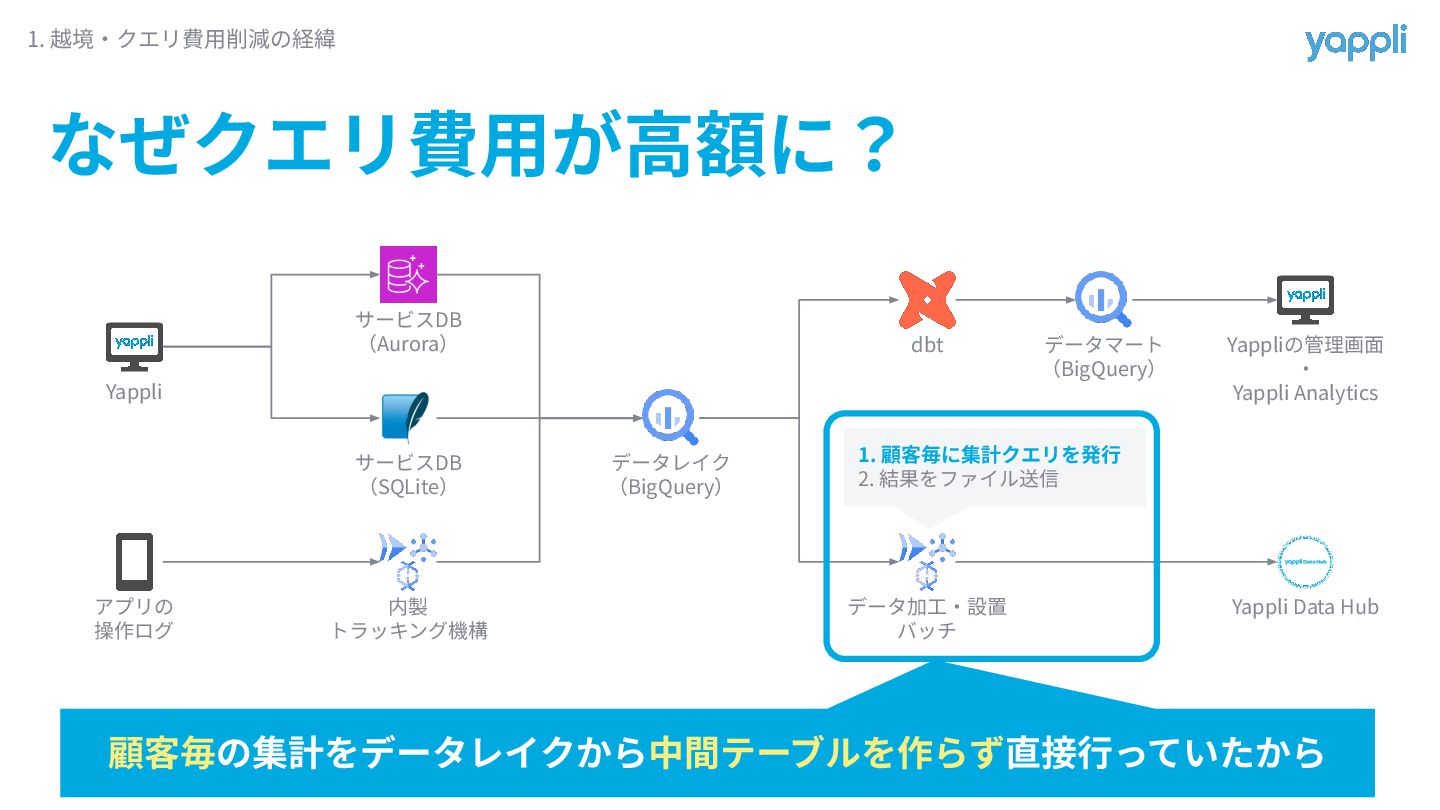
なぜクエリ費⽤が⾼額に? 1. 越境‧クエリ費⽤削減の経緯 Yappli アプリの 操作ログ サービスDB (Aurora) サービスDB (SQLite)
内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappliの管理画⾯ ‧ Yappli Analytics Yappli Data Hub 顧客毎の集計をデータレイクから中間テーブルを作らず直接⾏っていたから 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信
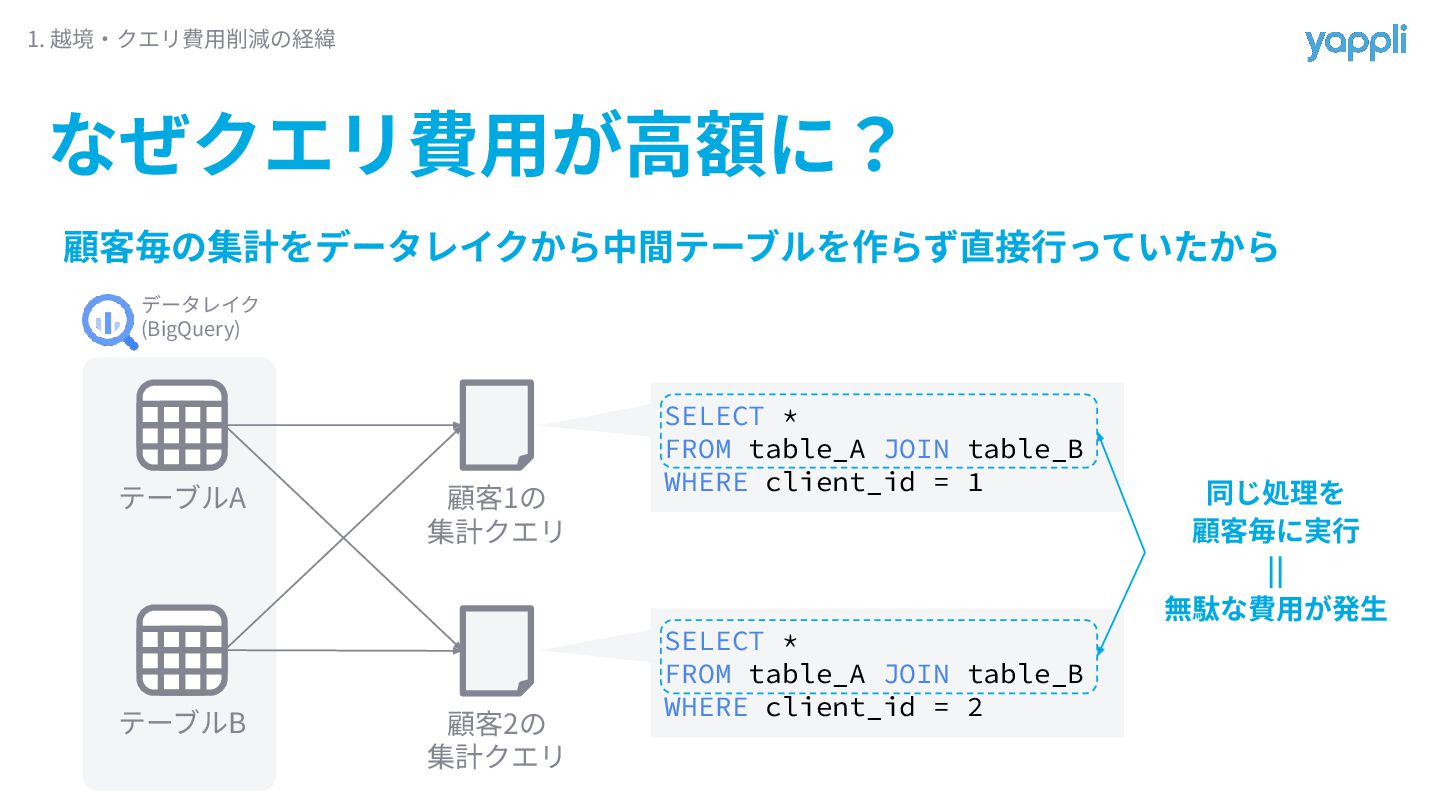
顧客毎の集計をデータレイクから中間テーブルを作らず直接⾏っていたから なぜクエリ費⽤が⾼額に? 1. 越境‧クエリ費⽤削減の経緯 テーブルA テーブルB 顧客1の 集計クエリ 顧客2の 集計クエリ
SELECT * FROM table_A JOIN table_B WHERE client_id = 1 SELECT * FROM table_A JOIN table_B WHERE client_id = 2 データレイク (BigQuery) 同じ処理を 顧客毎に実⾏ || 無駄な費⽤が発⽣
解決策は事前に中間テーブルを⽤意(事前集計化)するようにすること ▼ DS室的には、 Yappli Data Hubへdbtを導⼊するチャンス! ▼ dbtによる事前集計化を提案 1. 越境‧クエリ費⽤削減の経緯
コストインパクトの試算
どのくらいコスト削減できるのか? • 削減額が分かれば「どのくらいの温度感でやるべきか?」が分かる • 今かかっている費⽤、事前集計化した場合の費⽤を試算して⽐較 ◦ 両者の⽉額費⽤で⽐較 • 試算はBigQueryのINFORMATION_SCHEMA.JOBSビューを利⽤ ◦
total_bytes_billedカラムの値にBigQueryのクエリ費⽤と為替を掛けて計算 2. コストインパクトの試算
試算で分かったコストインパクト 2. コストインパクトの試算 Yappli Data Hubのクエリ費⽤を… Google Cloud全体の費⽤を… 約 20%
削減 約 95% 削減 チーム全体で「温度感⾼くやるべき」という共通認識ができた!
実⾏ジョブの時系列整理
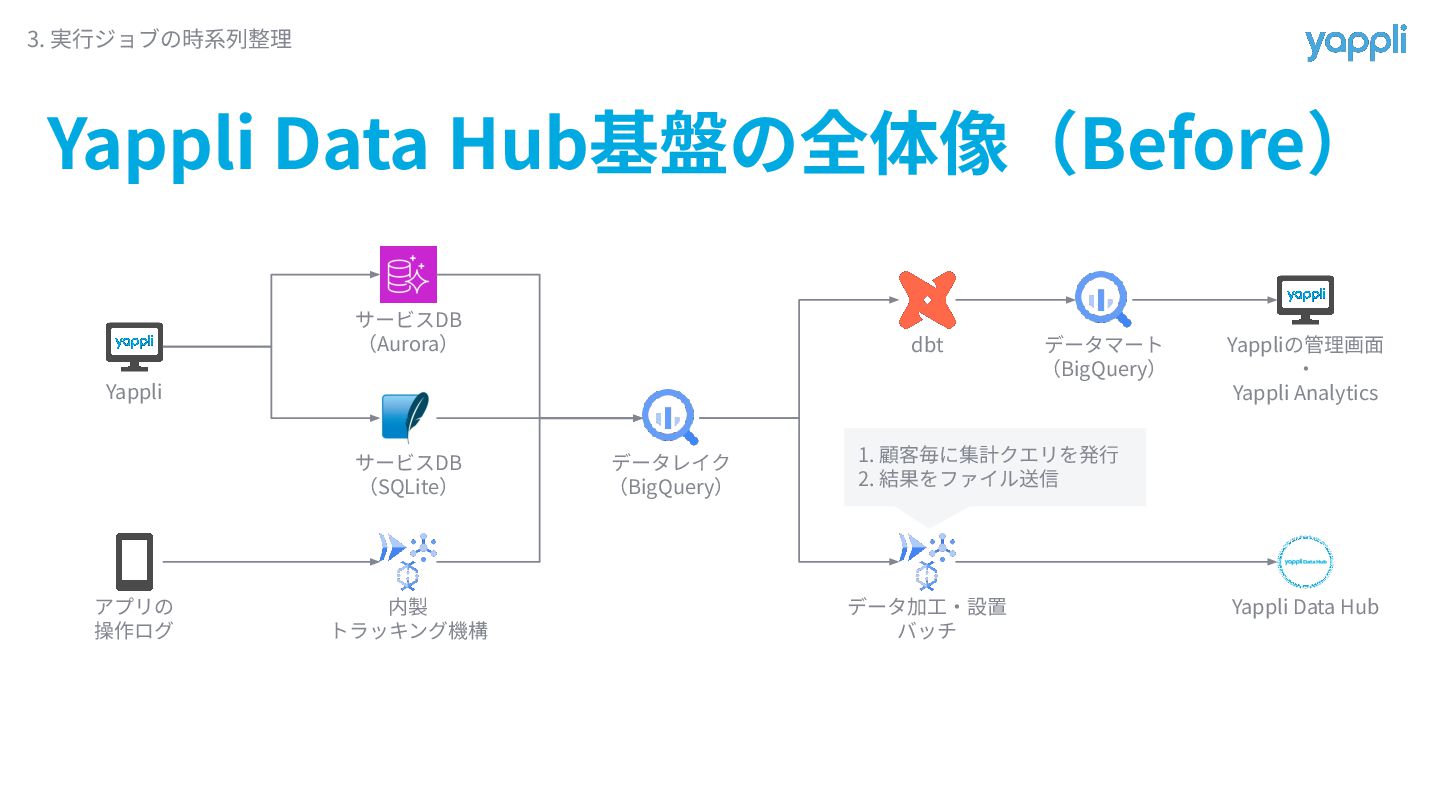
Yappli Data Hub基盤の全体像(Before) 3. 実⾏ジョブの時系列整理 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappliの管理画⾯ ‧ Yappli Analytics Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信
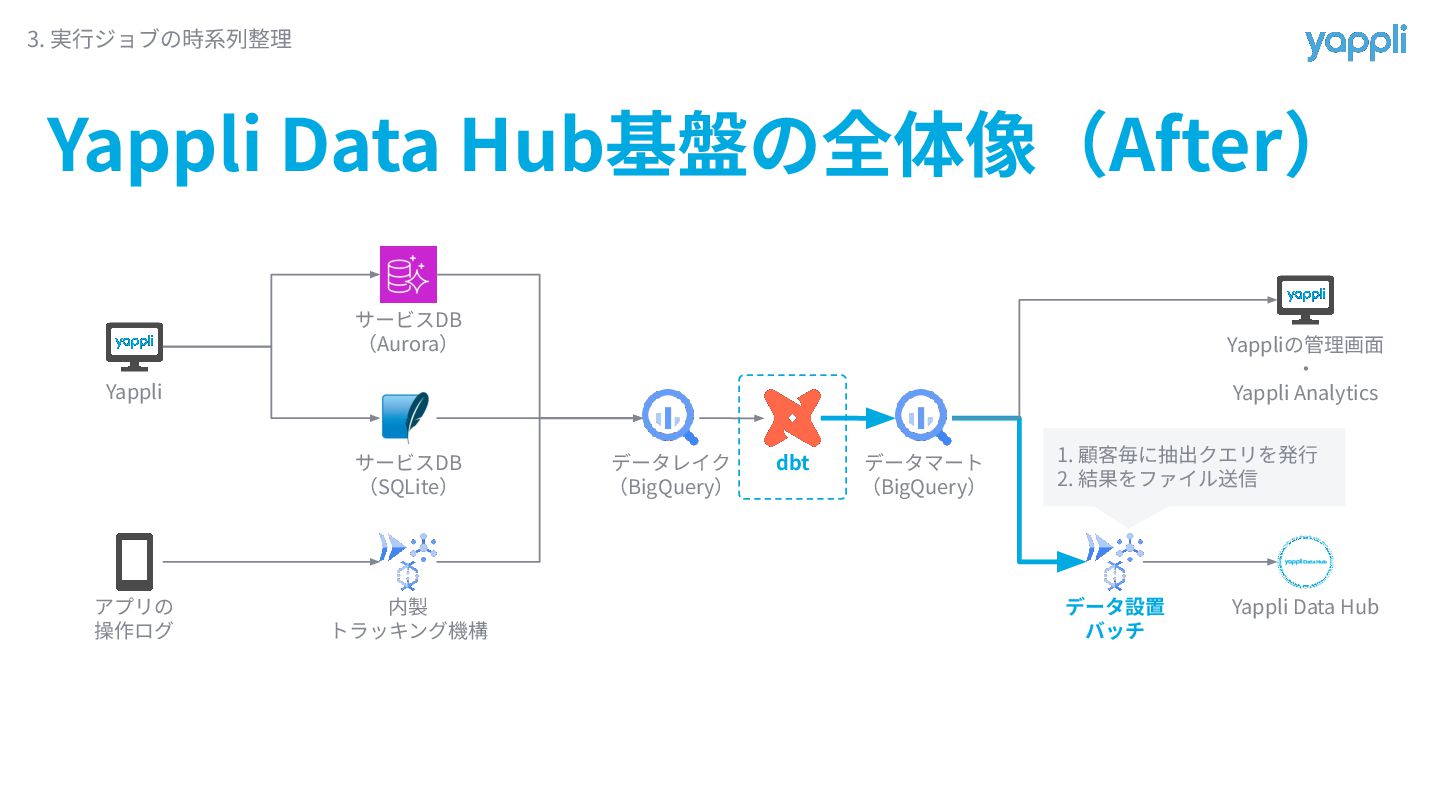
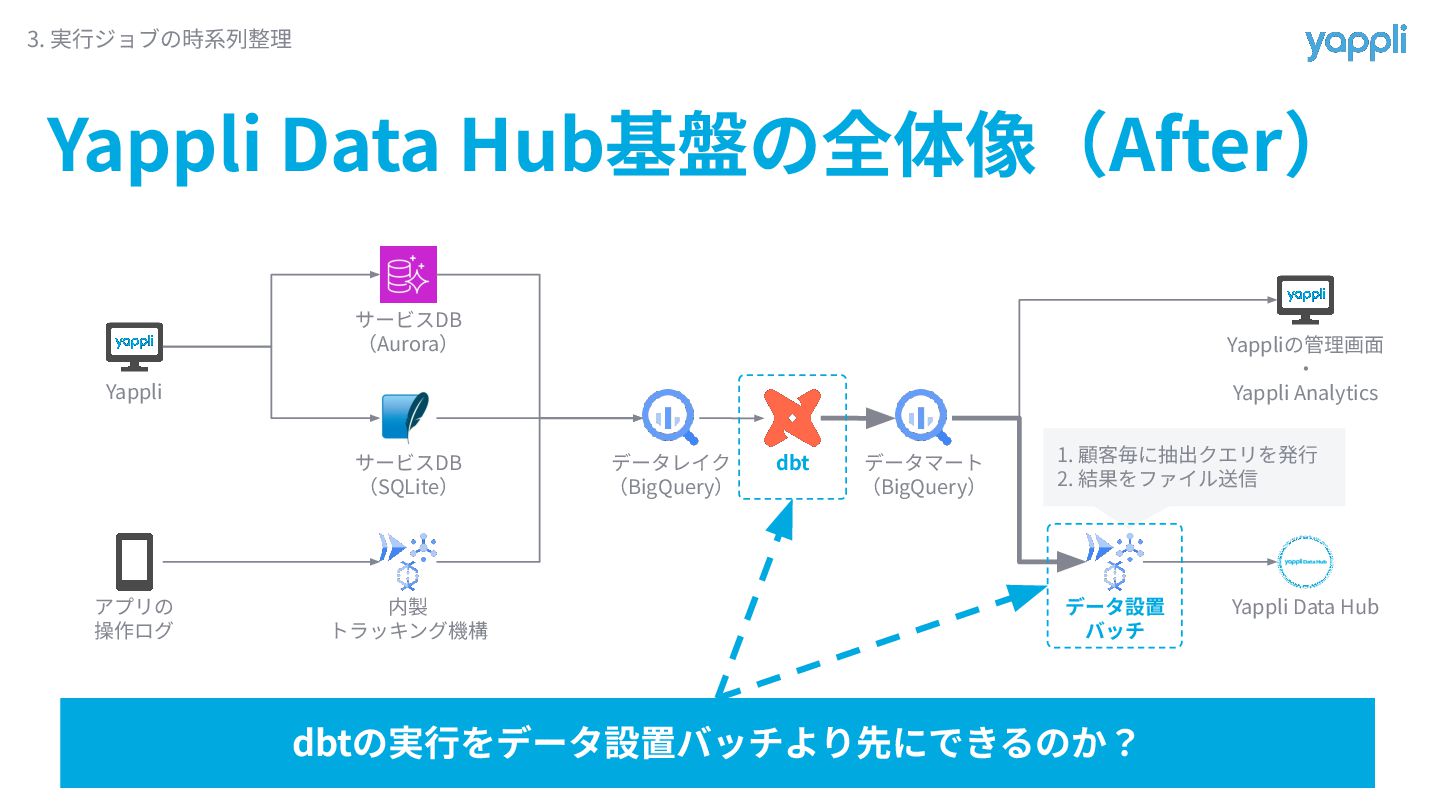
Yappli Data Hub基盤の全体像(After) 3. 実⾏ジョブの時系列整理 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ設置 バッチ Yappliの管理画⾯ ‧ Yappli Analytics Yappli Data Hub 1. 顧客毎に抽出クエリを発⾏ 2. 結果をファイル送信
Yappli Data Hub基盤の全体像(After) 3. 実⾏ジョブの時系列整理 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ設置 バッチ Yappliの管理画⾯ ‧ Yappli Analytics Yappli Data Hub 1. 顧客毎に抽出クエリを発⾏ 2. 結果をファイル送信 dbtの実⾏をデータ設置バッチより先にできるのか?
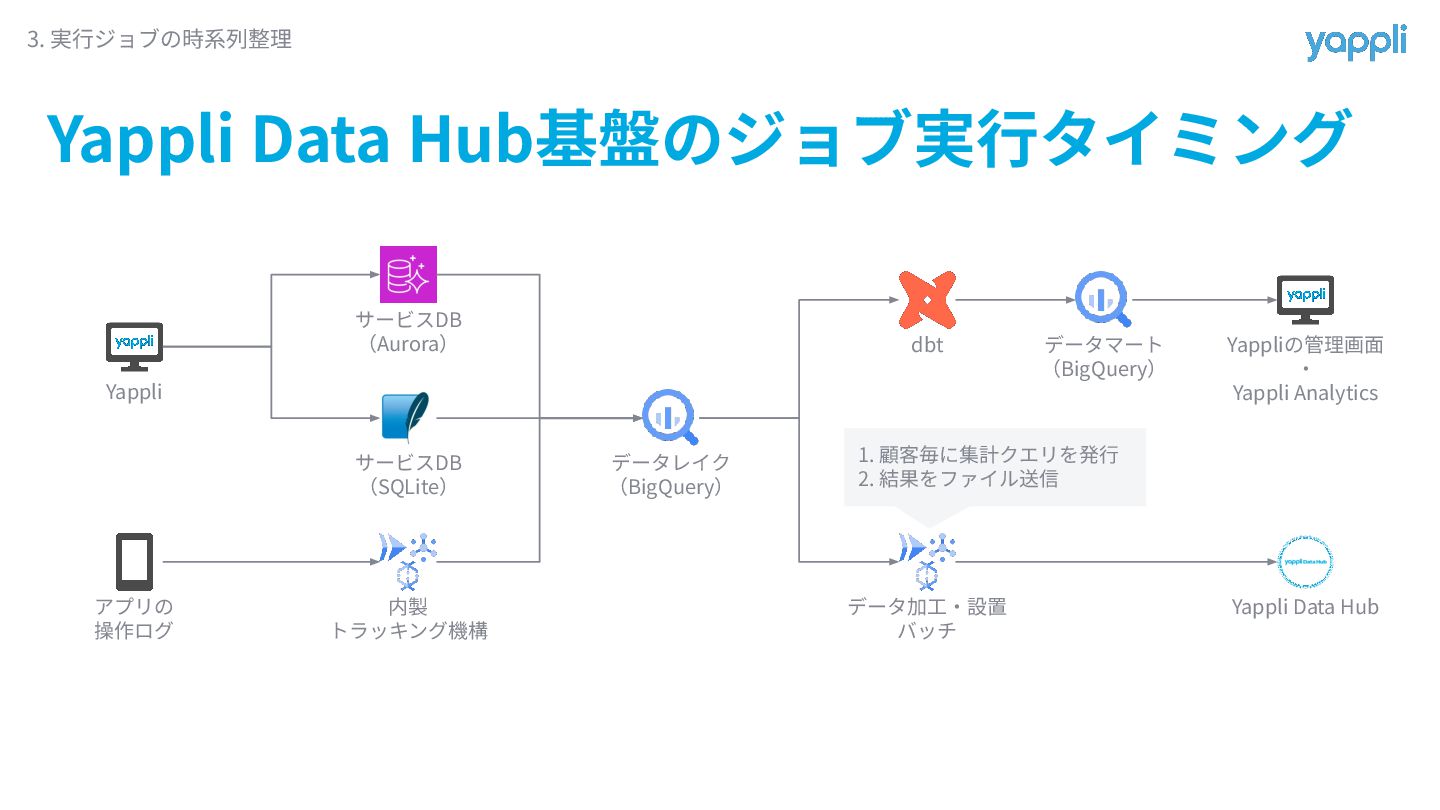
Yappli Data Hub基盤のジョブ実⾏タイミング 3. 実⾏ジョブの時系列整理 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappliの管理画⾯ ‧ Yappli Analytics Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信
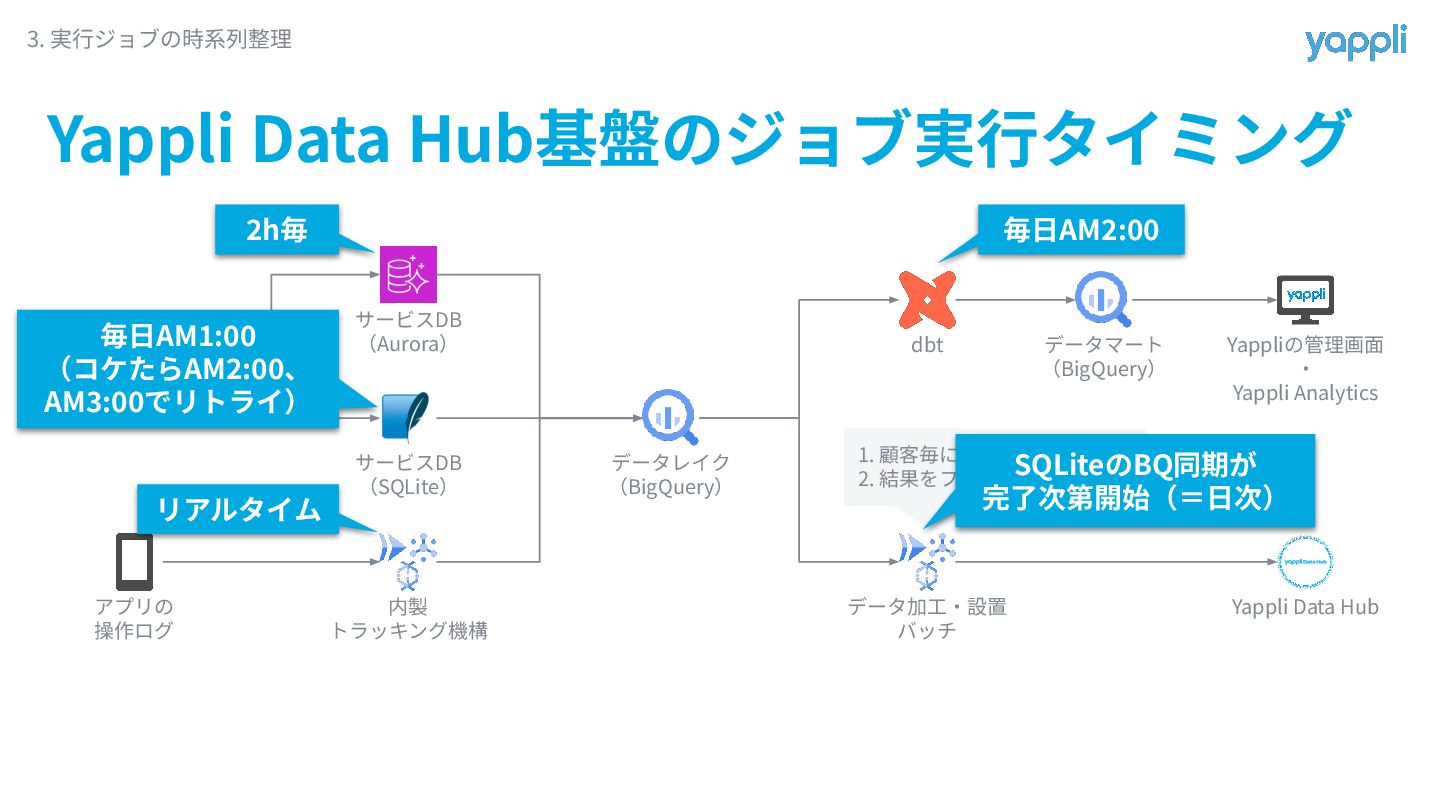
Yappli Data Hub基盤のジョブ実⾏タイミング 3. 実⾏ジョブの時系列整理 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappliの管理画⾯ ‧ Yappli Analytics Yappli Data Hub 1. 顧客毎に集計クエリを発⾏ 2. 結果をファイル送信 2h毎 毎⽇AM2:00 リアルタイム SQLiteのBQ同期が 完了次第開始(=⽇次) 毎⽇AM1:00 (コケたらAM2:00、 AM :00でリトライ)
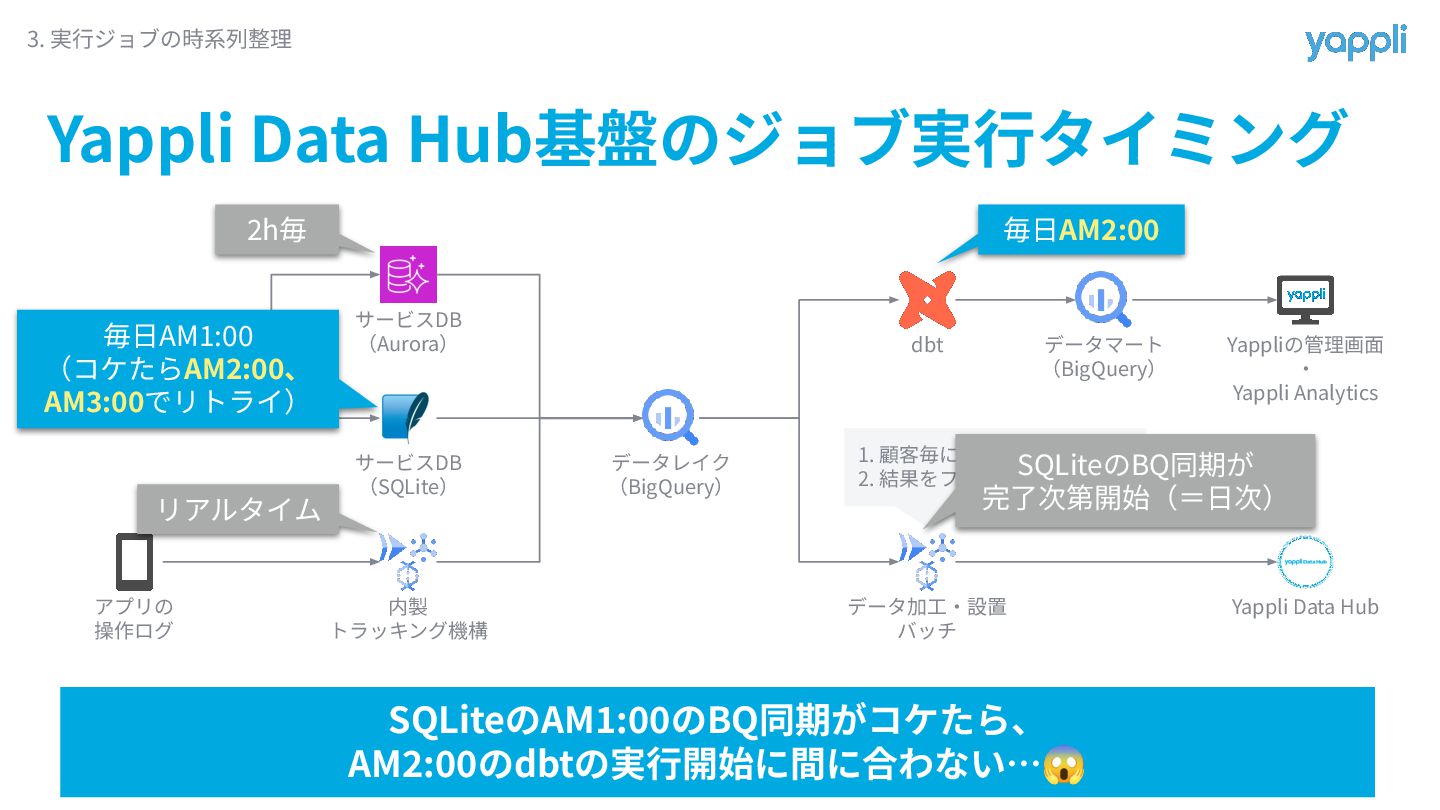
Yappli Data Hub基盤のジョブ実⾏タイミング 3. 実⾏ジョブの時系列整理 Yappli アプリの 操作ログ サービスDB (Aurora)
サービスDB (SQLite) 内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ加⼯‧設置 バッチ Yappliの管理画⾯ ‧ Yappli Analytics Yappli Data Hub 毎⽇AM2:00 SQLiteのAM1:00のBQ同期がコケたら、 AM2:00のdbtの実⾏開始に間に合わない…😱 h毎 リアルタイム 1. 顧客毎に抽出クエリを発⾏ 2. 結果をファイル送信 SQLiteのBQ同期が 完了次第開始(=⽇次) 毎⽇AM : (コケたらAM2:00、 AM :00でリトライ)
代替案を検討してみるが… • dbtもSQLiteのBQ同期が完了次第開始にする ◦ CMSダッシュボードの提供時刻に間に合わない ◦ SQLiteテーブルの中にはデータソリューションで使っていないテーブルもある → 無関係なテーブルのBQ同期失敗で後続が全ストップ(=インシデント)は怖い • dbtを使わずYappli
Data Hub側で独⾃に事前集計 ◦ 似たような集計処理をdbtとYappli Data Hubで⼆重管理することになってしまう ◦ 保守性が良いとは⾔い難い → どれも決め⼿に⽋ける…🤔 3. 実⾏ジョブの時系列整理 なんとか予定通りdbtでいけるようにできないか?
Yappli Data Hubの集計クエリを精査 分かったこと: • 集計で使っているSQLite由来のテーブルは1つのみ • SQLiteのBQ同期が間に合わなかったとしても、確定で全顧客のクエリ結果がおかしく なるわけではない ◦
さらに特定条件下の顧客のみが影響範囲 • 翌⽇の実⾏でちゃんと間に合えばリカバリーできる → 間に合わないリスクを許容できないか? • チーム内のSREに調査依頼 → 直近1年でそもそもBQ同期がコケたこと⾃体なし → 許容できると判断 3. 実⾏ジョブの時系列整理 予定通り、dbtで事前集計化する⽅針に決定!
顧客影響との折り合い
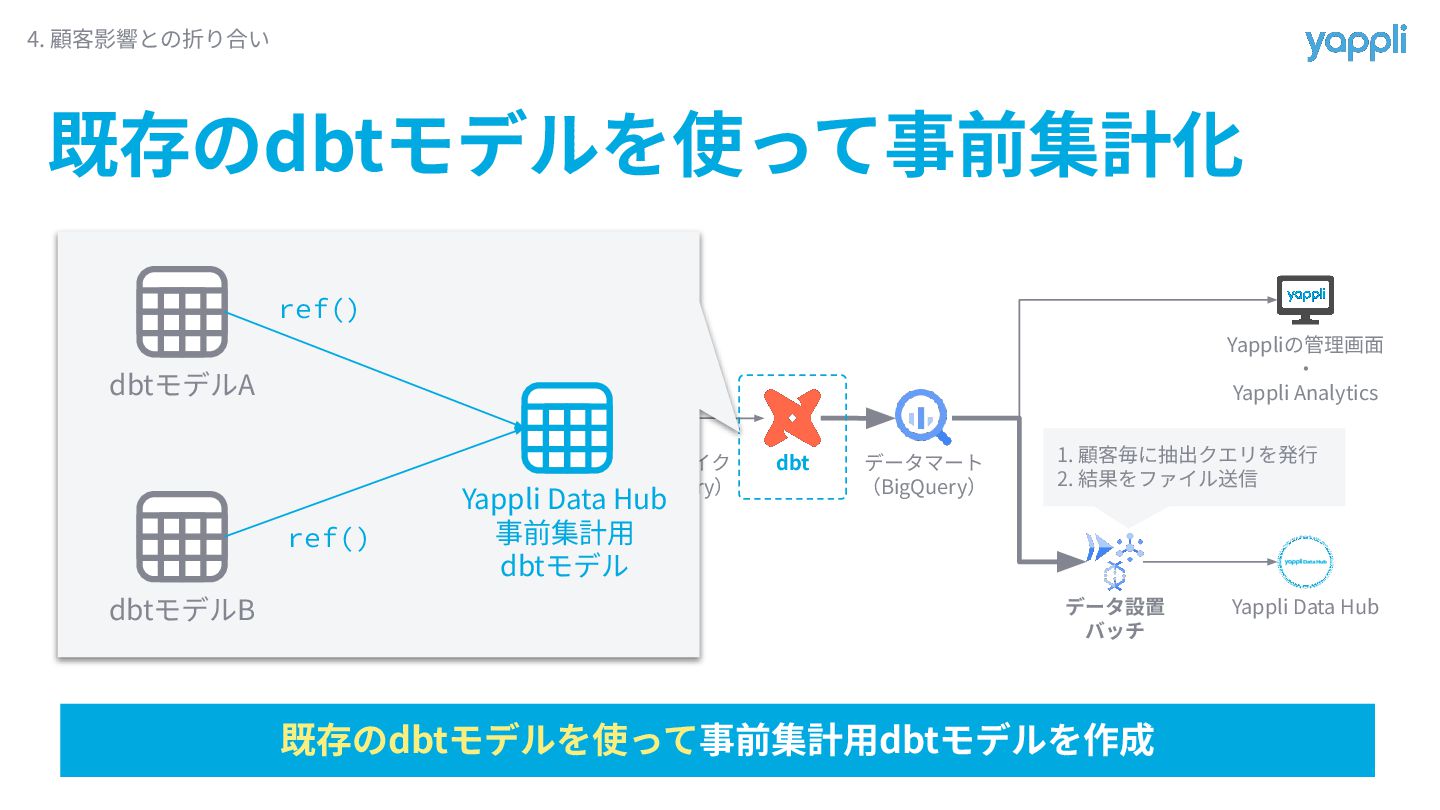
既存のdbtモデルを使って事前集計化 4. 顧客影響との折り合い Yappli アプリの 操作ログ サービスDB (Aurora) サービスDB (SQLite)
内製 トラッキング機構 データレイク (BigQuery) dbt データマート (BigQuery) データ設置 バッチ Yappliの管理画⾯ ‧ Yappli Analytics Yappli Data Hub 1. 顧客毎に抽出クエリを発⾏ 2. 結果をファイル送信 dbtモデルA dbtモデルB Yappli Data Hub 事前集計⽤ dbtモデル ref() ref() 既存のdbtモデルを使って事前集計⽤dbtモデルを作成
クエリ結果が変わってしまう • Yappli Data Hubの集計クエリには積年の技術的負債が存在 • これまでのdbt導⼊で、既存のdbtモデルには様々な改善が施されている → 既存のdbtモデルを使ってYappli Data Hubの集計を⾏うと、
クエリ結果が変わってしまう (例: 今まで5番⽬のカラムに⼊ってた値が2番⽬のカラムに⼊るようになる) → 詳細が気になる⽅は懇親会で!(そもそもクエリ作成⾃体が⼤変だった…) ‧ そもそもクエリが⻑い上に難読すぎる問題 ‧ クエリがまともに差分チェックできない問題 ‧ 真の⽣データ提供先顧客のマスタ、どれ…?問題 ‧ etc. 4. 顧客影響との折り合い
そのまま本番反映は顧客影響が⼤きすぎる • ⽣データを提供サービスなので、クエリ結果が変わる場合は要顧客調整 ◦ 提供した⽣データは顧客のCRM‧CDPへ取り込まれている → クエリ結果変更でCRM‧CDPの取り込み結果が変わると顧客の業務に⽀障が…😱 しかし… • 要調整な顧客の数が多い •
各顧客で社内調整も必要(=時間が必要) ◦ ⾃社のCRM‧CDPへの修正が必要なため → ‧ 顧客調整に⻑い時間が必要 ‧ 本番反映後にインシデントを起こしてしまった場合の対応も⼤変 4. 顧客影響との折り合い 何とか顧客影響を⼩さく本番反映ができないか?
2フェーズに分割して進めよう 1. 今の集計クエリをそのままdbtモデル化 a. 既存のdbtモデルは使わず、Sourceテーブルを直接参照 b. クエリ⾃体はそのままなので、集計結果は変わらない → 顧客調整なしで進められる → 事前集計化によるクエリ費⽤削減をまずは達成 2.
既存のdbtモデルを使うよう改善 a. クエリ結果変更に伴う顧客調整も含めてじっくり対応 → 今の集計クエリの技術的負債を解消 4. 顧客影響との折り合い
2フェーズに分割して進めよう 1. 今の集計クエリをそのままdbtモデル化 a. 既存のdbtモデルは使わず、Sourceテーブルを直接参照 b. クエリ⾃体はそのままなので、集計結果は変わらない → 顧客調整なしで進められる → 事前集計化によるクエリ費⽤削減をまずは達成 2.
既存のdbtモデルを使うよう改善 a. クエリ結果変更に伴う顧客調整も含めてじっくり対応 → 今の集計クエリの技術的負債を解消 4. 顧客影響との折り合い イマココ
得られた学び‧恩恵
得られた学び(⾏動⾯) • ⽇頃の越境しての関係構築‧信⽤貯⾦は⼤事 ◦ 元々のドキュメント整備や業務巻き取りで、データ基盤の全体像把握と⼀定の関係構築がで きている状態だった → 今回のdbtで事前集計化する提案もしやすかった&受け⼊れられやすかった • 地道な基盤の全体像把握は⼤事 ◦
ちゃんとしないといけないところ、妥協が許容されるところが⾒極められる ▪ 今回の「SQLiteのBQ同期がコケるとdbt間に合わない問題」は全体像把握をちゃんと ⾏ったことで、気づけた&妥協が許容されることを⽰せた 5. 得られた学び‧恩恵
得られた学び(技術⾯) • クエリ結果の変更が許容されにくい場⾯では… クエリを⼀旦そのままdbtモデル化すると良い ◦ 次の2フェーズに分けて取り組む: ▪ ① クエリをそのままdbtモデル化(Source直接参照) ▪
② dbt内で再モデリング(既存dbtモデルを参照するよう繋ぎかえ) ◦ メリット: ▪ 集計ロジックがdbtへ集約されている状況を早く作れる • まだ再モデリングまで済んでいなくても、集計ロジック変更をdbt内で完結できる → 対応しやすい 5. 得られた学び‧恩恵
Yappli Data Hub基盤の全体像把握による恩恵 Yappli Data Hubについて、チーム外の⼈へ説明しやすくなった • Yappli CRM開発チームとCRM基盤との⽴ち位置について議論 ◦
CRM基盤で管理すべきデータ、Yappli Data Hub基盤で管理すべきデータの棲み分け • Yappli Data Hub基盤との連携を検討している他の開発チームへのインプット ◦ 意図しない連携⽅法でプロダクト側もYappli Data Hub基盤側も⾟い状況になってしまうのを 防⽌ → 双⽅にとってベストな連携⽅法を模索しやすくできた 5. 得られた学び‧恩恵 Yappli Data Hubだけでなく、その周辺に対しても⼤きなプラスに!
今後の展望 Yappli Data Hubの集計クエリの技術的負債解消 1. 今の集計クエリをそのままdbtモデル化 a. 既存のdbtモデルは使わず、Sourceテーブルを直接参照 b. クエリ⾃体はそのままなので、集計結果は変わらない
→ 顧客調整なしで進められる → 事前集計化によるクエリ費⽤削減をまずは達成 2. 既存のdbtモデルを使うよう改善 a. クエリ結果変更に伴う顧客調整も含めてじっくり対応 → 今の集計クエリの技術的負債を解消 5. 得られた学び‧恩恵 次ココ
FOLLOW ME!! Yappli Tech Blog Yappli Developers カジュアル⾯談 @yappli_dev https://tech.yappli.io/
https://open.talentio.com/r/1/c/yappli/pages/59642
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}