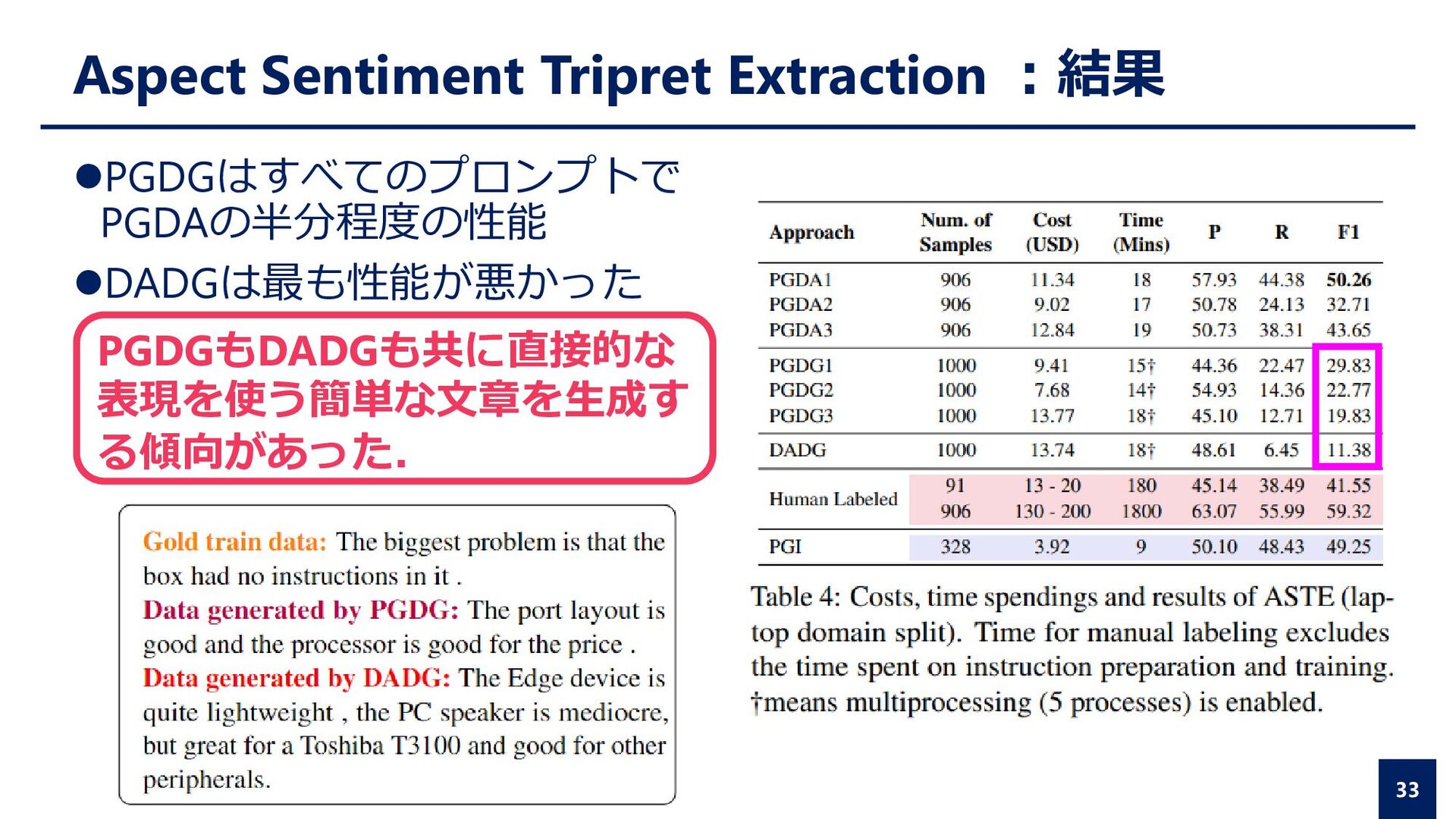
Generation (PGDG) ⚫GPT-3を使って訓練データの自動生成とラベリングを行う ⚫Dictionary-Assisted Training Data Generation (DADG) ⚫GPT-3とWikipediaを使って訓練データの自動生成とラベリングを行う それぞれタスクに合わせたプロンプトを作成 GPT-3にはOpen AI APIのtext-davinci-003を使用 3
Generation (PGDG) ⚫GPT-3を使って訓練データの自動生成とラベリングを行う ⚫Dictionary-Assisted Training Data Generation (DADG) ⚫GPT-3とWikipediaを使って訓練データの自動生成とラベリングを行う それぞれタスクに合わせたプロンプトを作成 GPT-3にはOpen AI APIのtext-davinci-003を使用 7
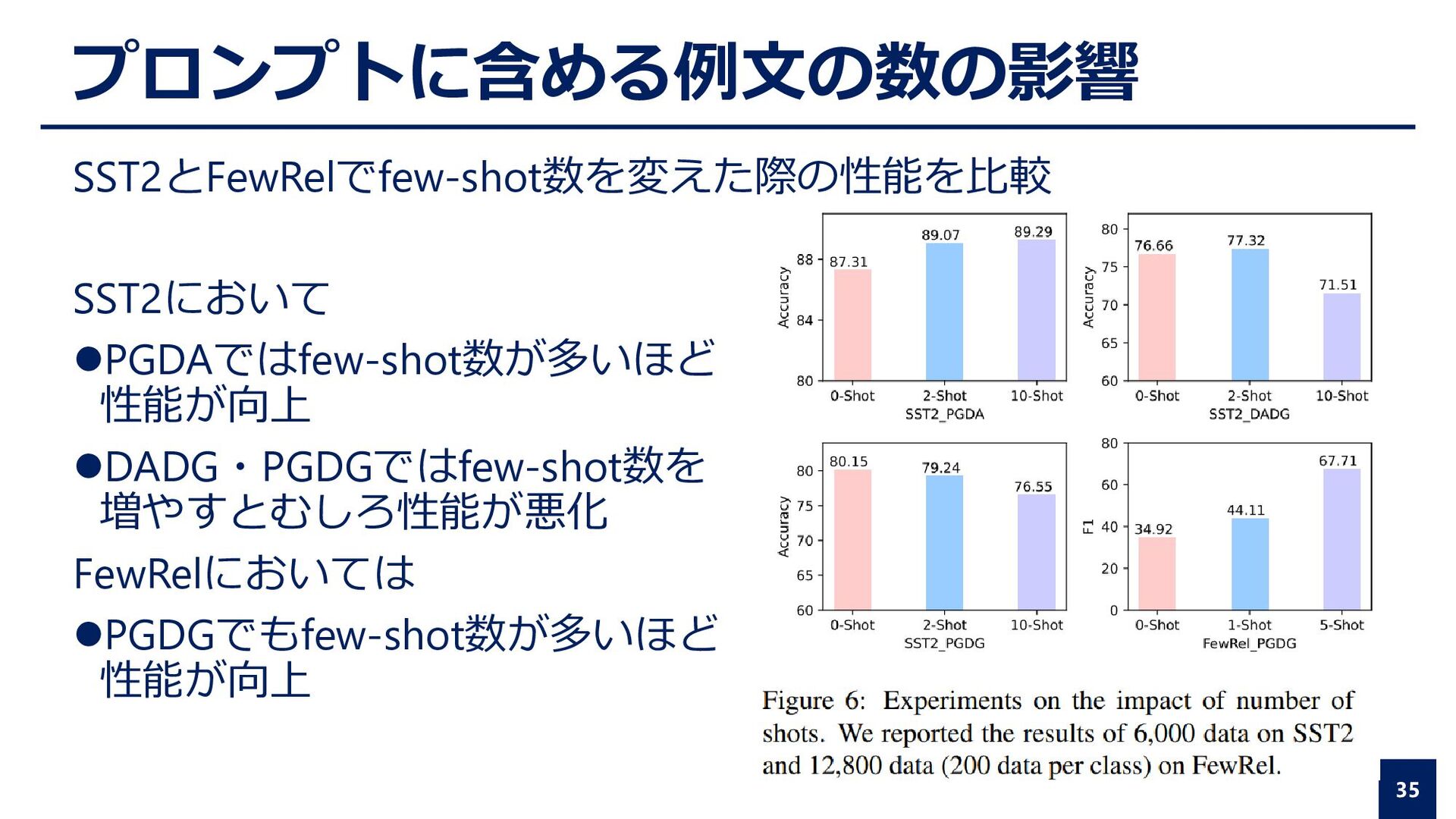
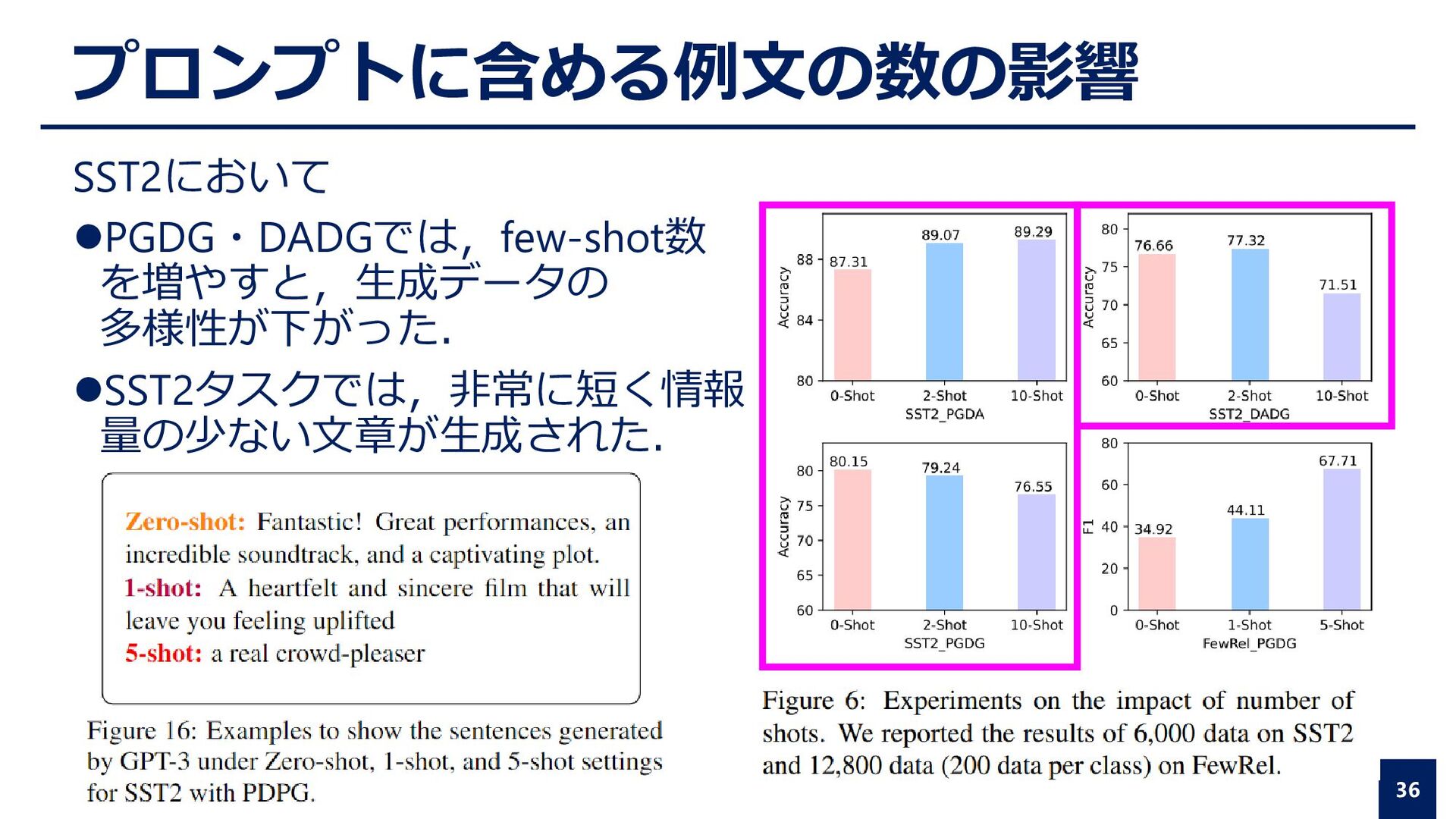
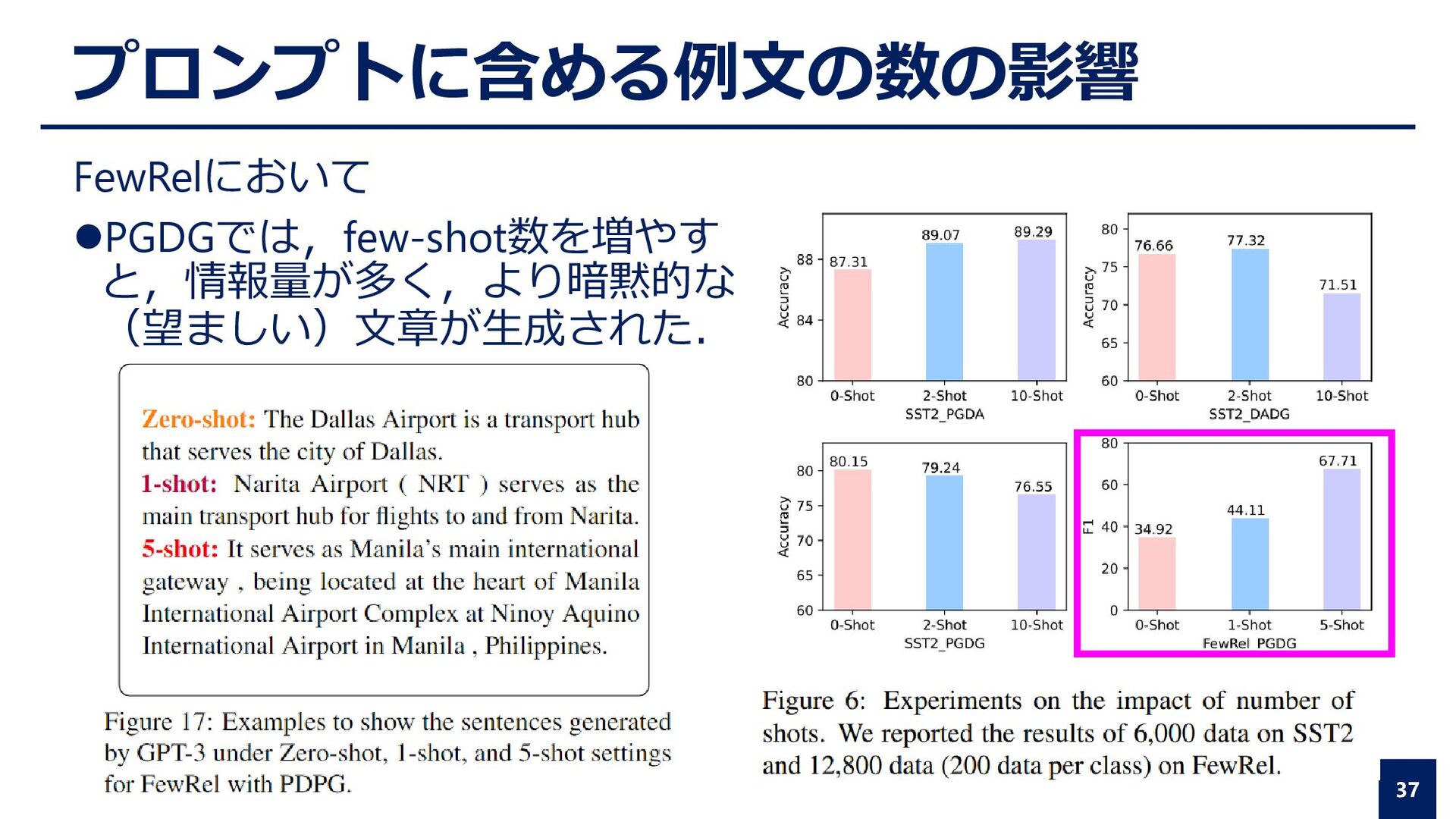
president of the Royal Society(Tail). Relation→(Head Entity) is member_of (Tail Entity) ⚫実験手順 ⚫各手法で作成された訓練データを元にBERT-baseを訓練 ⚫FewRelデータセットのテストデータを用いて評価 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![対象タスク (データセット) ⚫Sequence-level Task ⚫Sentiment Analysis (SST2[1]) ⚫Relation Extraction (FewRel[2])](https://files.speakerdeck.com/presentations/09cec0634d9344b7a27963e3cfb98c12/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
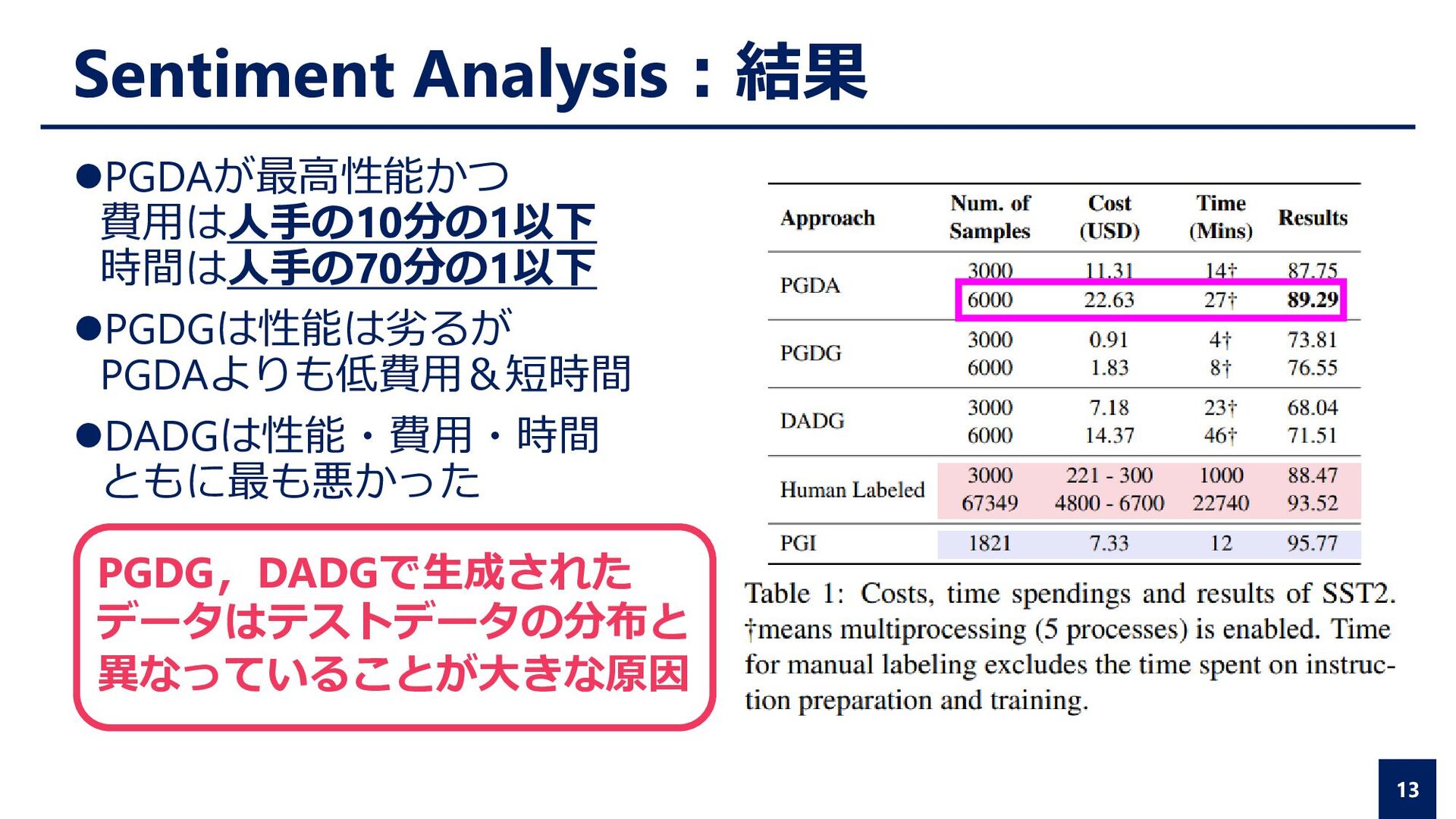{kind=link}
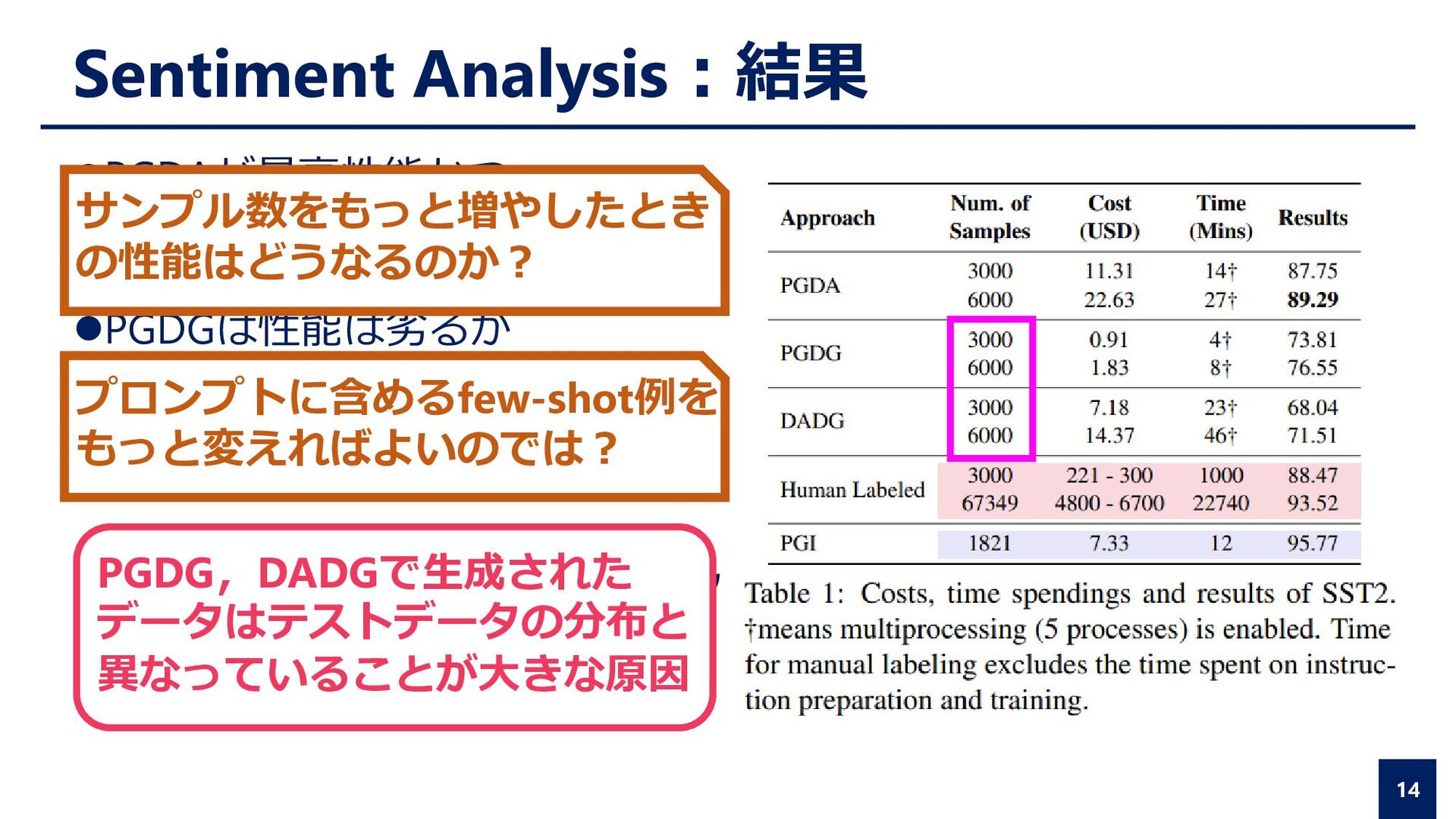{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
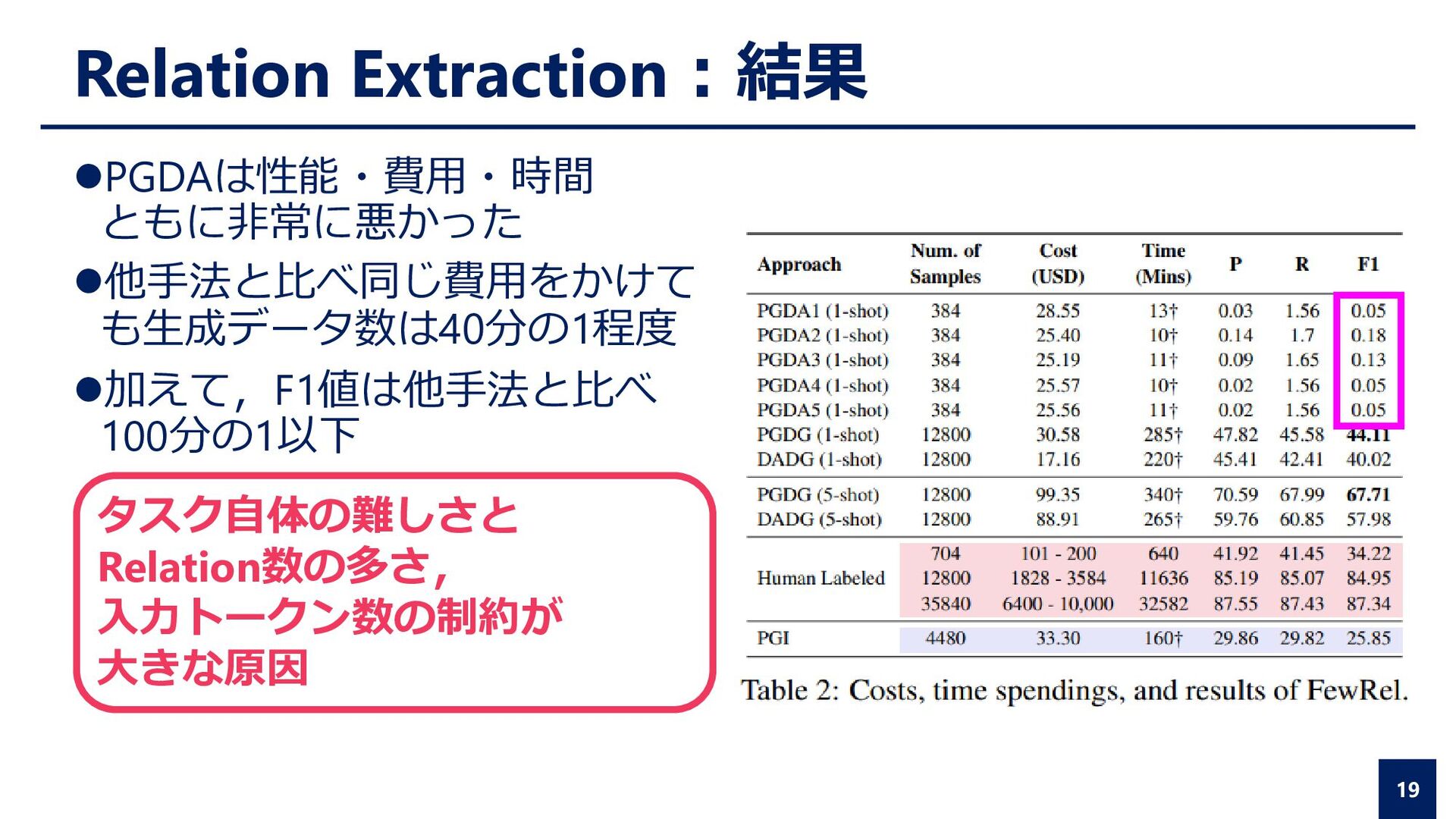{kind=link}
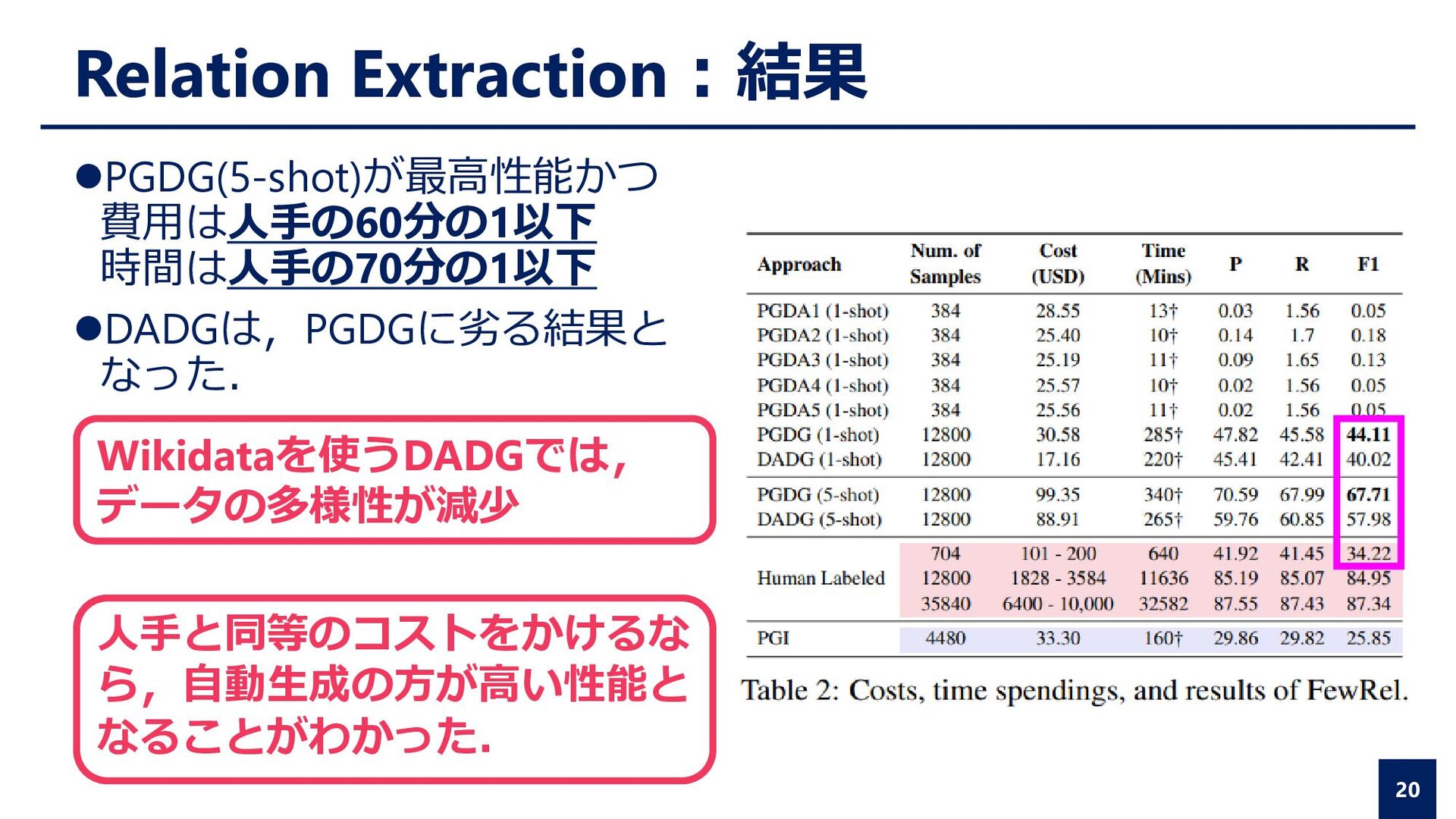{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}