Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SNLP2024:Planning Like Human: A Dual-process Fr...
Search
Yuki Zenimoto
August 20, 2024
Research
610
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SNLP2024:Planning Like Human: A Dual-process Framework for Dialogue Planning
Yuki Zenimoto
August 20, 2024
More Decks by Yuki Zenimoto
See All by Yuki Zenimoto
ACL読み会2025: Can Language Models Reason about Individualistic Human Values and Preferences?
yukizenimoto
0
160
SNLP2025:Can Language Models Reason about Individualistic Human Values and Preferences?
yukizenimoto
0
300
SNLP2023:Is GPT-3 a Good Data Annotator?
yukizenimoto
3
1.1k
発話者分類研究の現状とその応用
yukizenimoto
0
710
SNLP2022:What does the sea say to the shore? A BERT based DST style approach for speaker to dialogue attribution in novels
yukizenimoto
0
460
Other Decks in Research
See All in Research
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
170
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
690
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
130
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
300
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
1k
Fukui Shibiten 39 - AI Art
butchi
0
140
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
200
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.2k
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
620
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
Featured
See All Featured
Git: the NoSQL Database
bkeepers
PRO
432
67k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
How STYLIGHT went responsive
nonsquared
100
6.2k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Making Projects Easy
brettharned
120
6.7k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
The Invisible Side of Design
smashingmag
301
52k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Claude Code のすすめ
schroneko
67
230k
Transcript
読み手 銭本友樹/Zenimoto Yuki(名古屋大) @第16回最先端NLP勉強会 Planning Like Human: A Dual-process Framework
for Dialogue Planning https://aclanthology.org/2024.acl-long.262/ Tao He, Lizi Liao, Yixin Cao, Yuanxing Liu, Ming Liu, Zerui Chen, Bing Qin ACL2024 Long Paper ※特に注釈がない限り,スライド中の画像は論文からの引用になります
2 研究背景:Proactive Dialogue(能動的対話) ⚫ Proactive Dialogue:対話システムが特定の目的を持ち,その目的に向かっ て能動的に発話を行う対話のこと(Goal-Oriented Dialogueとも言う) ⚫ 具体例
◼ 患者(人間)とカウンセラー(対話システム)のカウンセリング ◼ 生徒(人間)と先生(対話システム)の語学学習 ◼ バーゲンサイトにおける売り手(人間)と買い手(対話システム)の値段交渉 ⚫ →対話システムが適切な対話戦略計画を構築することが重要 ◼ 対話戦略計画: 「今の状況では提案より共感の方が有効である」などの, 目的達成に有効な対話戦略の計画
3 先行研究 ⚫ 既存手法[Deng+’23, Fu+’23]の多くは未来の状況(システムの応答によってユー ザの応答がどのように変化するか)を考慮できていないため,長期的な対 話戦略を扱うことができない. ⚫ 未来の状況を扱うために,モンテカルロ木探索を応用した手法[Yu+’23]もあ るが,コスト面と応答速度の点で実用的でない.
⚫ →未来の状況を考慮しつつ,低コストで高速に対話戦略を決定する手法が 望まれる
4 Dual Process Theory(二重過程理論) ⚫ Dual Process Theory:人間の思考には「速く直感的な思考」と「遅く分析 的な思考」の2種類があり,これらを柔軟に使い分けているという理論 [Kahneman’03]
⚫ 具体例 ◼ 速く直感的な思考:既知の状況での対話(友達との雑談) ◼ 遅く分析的な思考:未知の状況での対話(初対面の人との対話) ⚫ →能動的対話タスクにおいて有益な理論
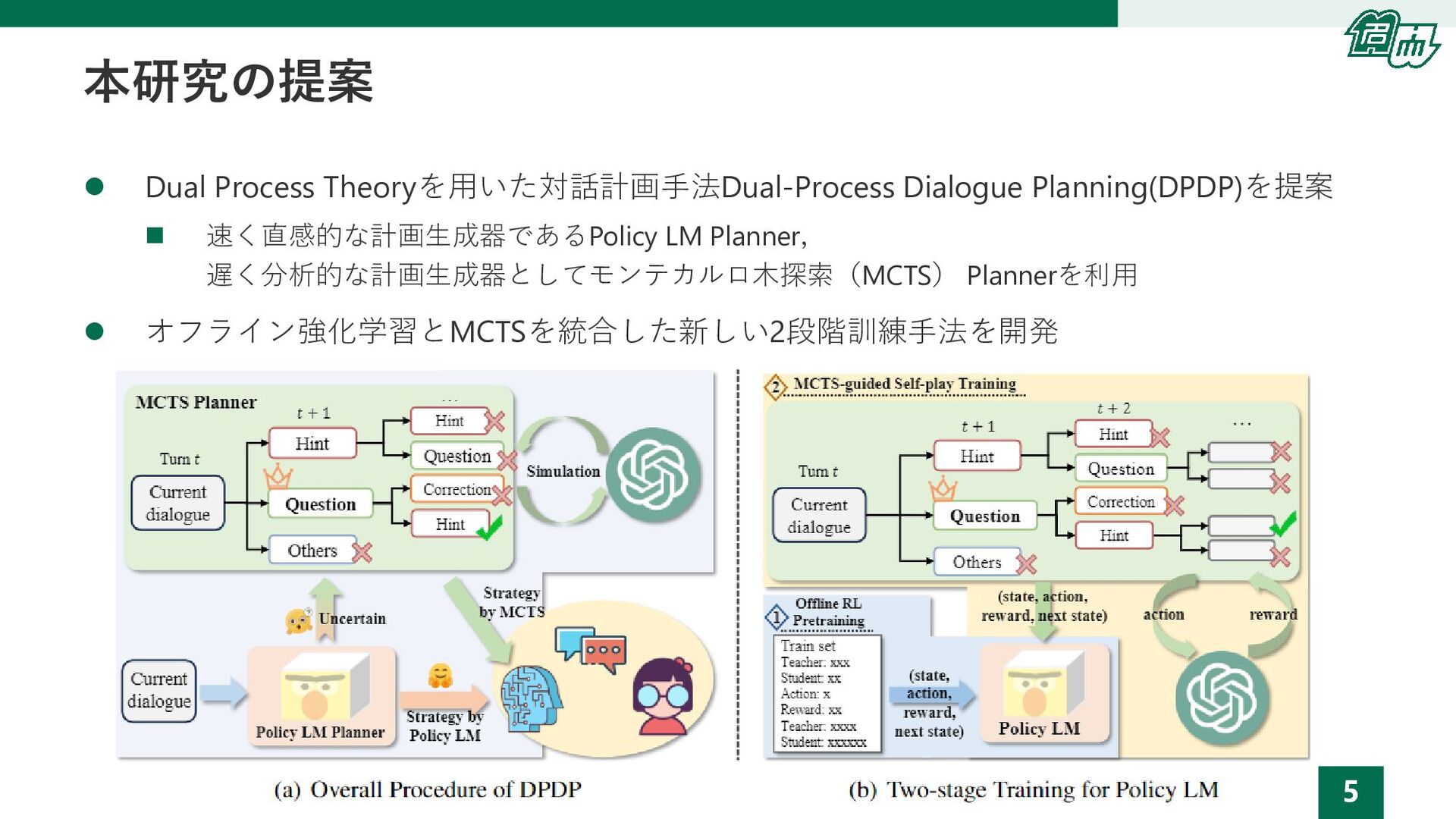
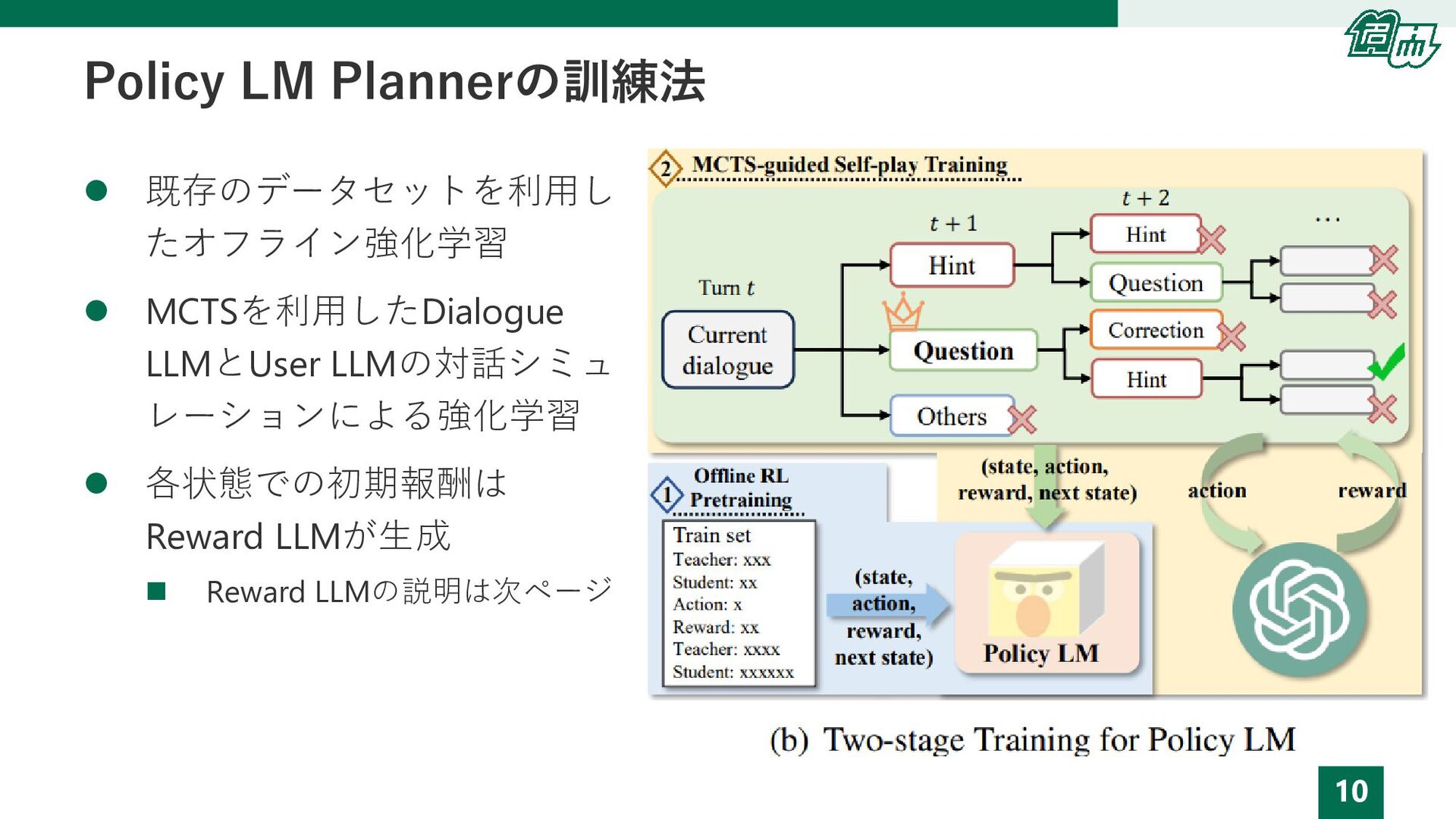
5 本研究の提案 ⚫ Dual Process Theoryを用いた対話計画手法Dual-Process Dialogue Planning(DPDP)を提案 ◼ 速く直感的な計画生成器であるPolicy
LM Planner, 遅く分析的な計画生成器としてモンテカルロ木探索(MCTS) Plannerを利用 ⚫ オフライン強化学習とMCTSを統合した新しい2段階訓練手法を開発
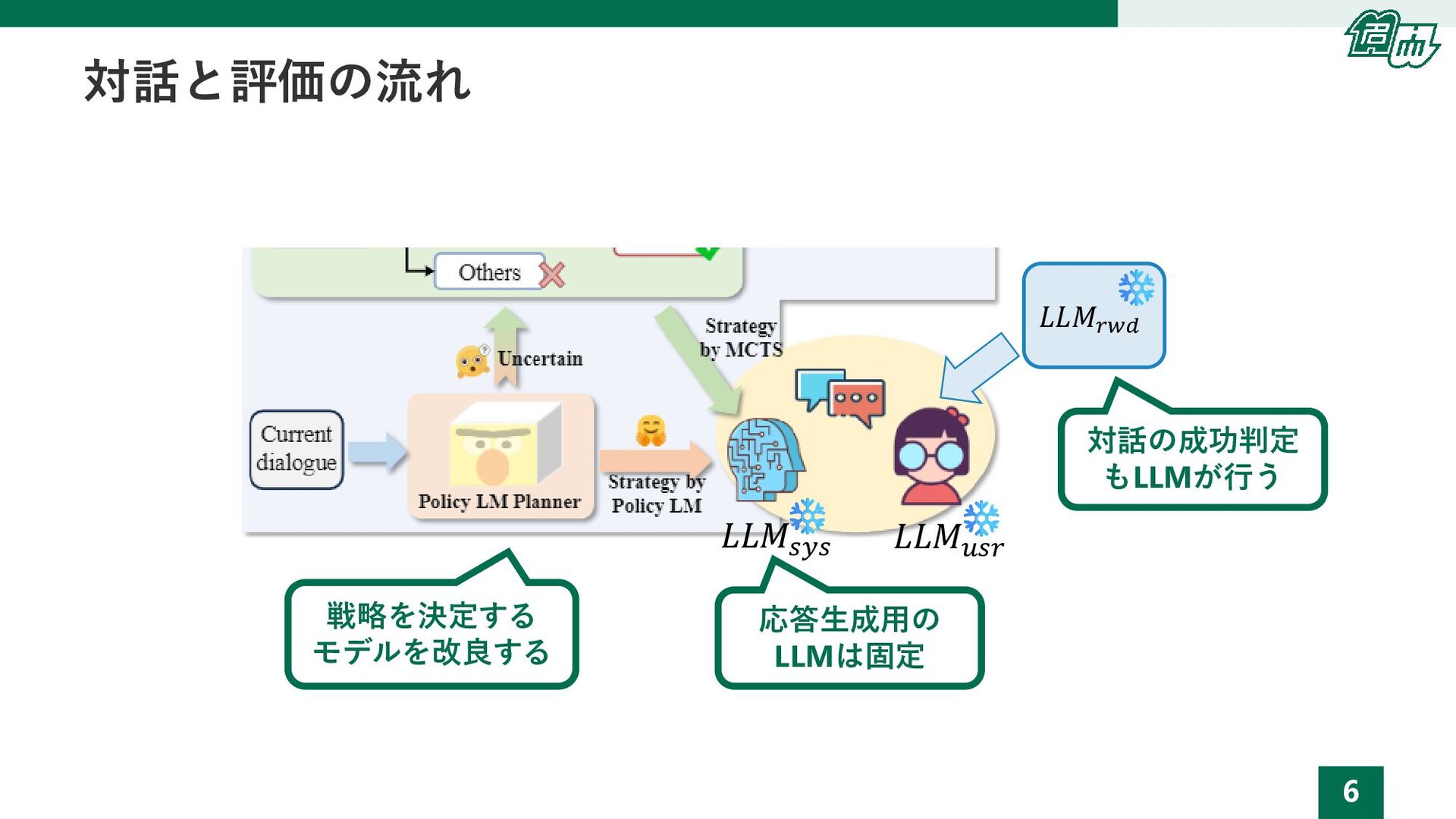
6 対話と評価の流れ 応答生成用の LLMは固定 𝐿𝐿𝑀𝑠𝑦𝑠 戦略を決定する モデルを改良する 𝐿𝐿𝑀𝑢𝑠𝑟 𝐿𝐿𝑀𝑟𝑤𝑑 対話の成功判定
もLLMが行う
7 タスクの定式化 ⚫ マルコフ決定過程としてマルチターン対話を定式化する ◼ 各ターンtでの対話履歴𝑠𝑡 = {… , 𝑢
𝑡−1 𝑠𝑦𝑠 , 𝑢𝑡−1 𝑢𝑠𝑟}に基づき,方策𝜋が戦略𝑎𝑡 ∈ 𝒜を取り, それに対して報酬𝑟(𝑠𝑡 , 𝑎𝑡 )が与えられる(𝒜は人手で作成した戦略集合) ⚫ この方策𝜋としてのPolicy PlannerとMCTS Planner
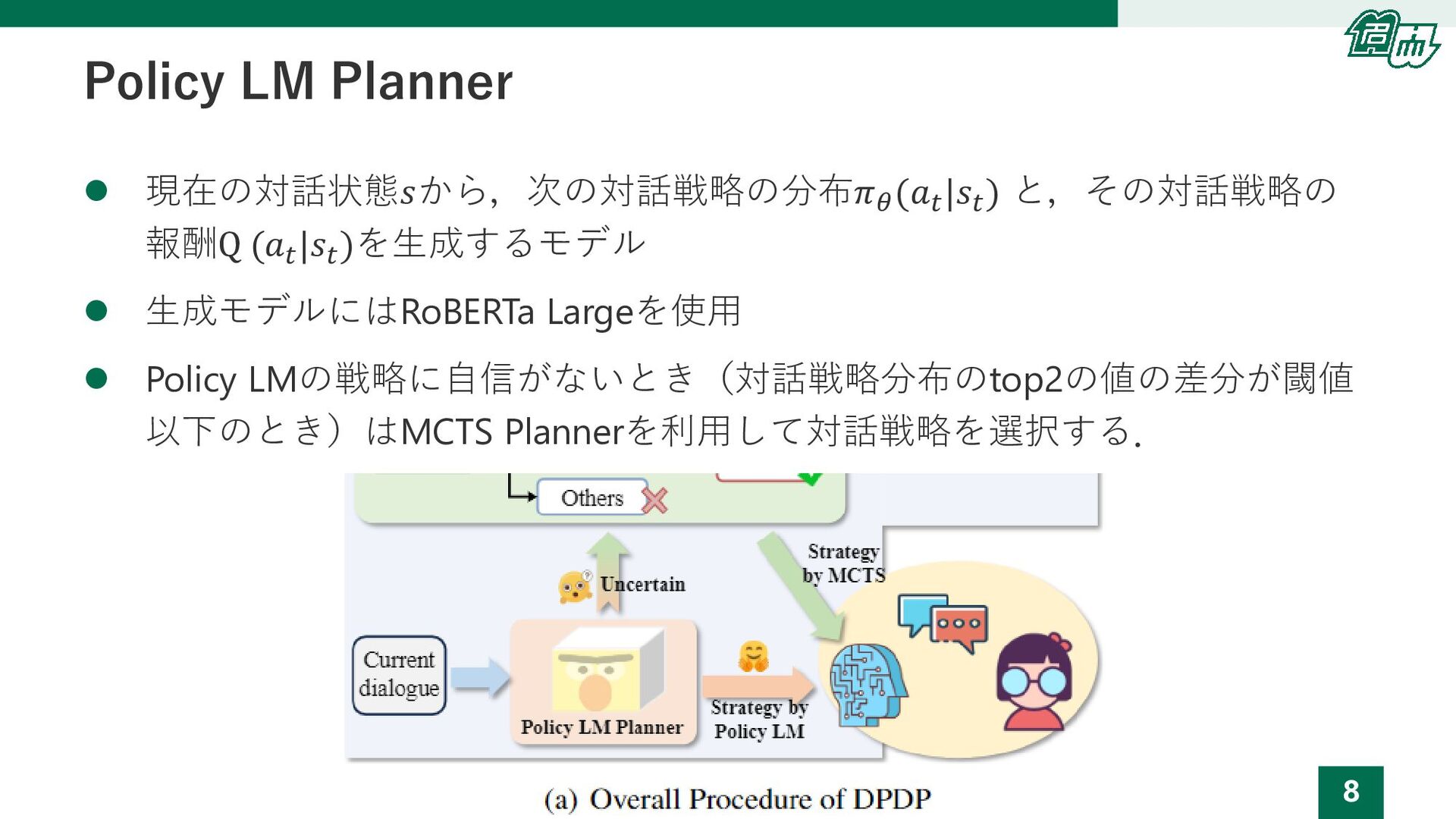
8 Policy LM Planner ⚫ 現在の対話状態𝑠から,次の対話戦略の分布𝜋𝜃 (𝑎𝑡 |𝑠𝑡 ) と,その対話戦略の
報酬Q (𝑎𝑡 |𝑠𝑡 )を生成するモデル ⚫ 生成モデルにはRoBERTa Largeを使用 ⚫ Policy LMの戦略に自信がないとき(対話戦略分布のtop2の値の差分が閾値 以下のとき)はMCTS Plannerを利用して対話戦略を選択する.
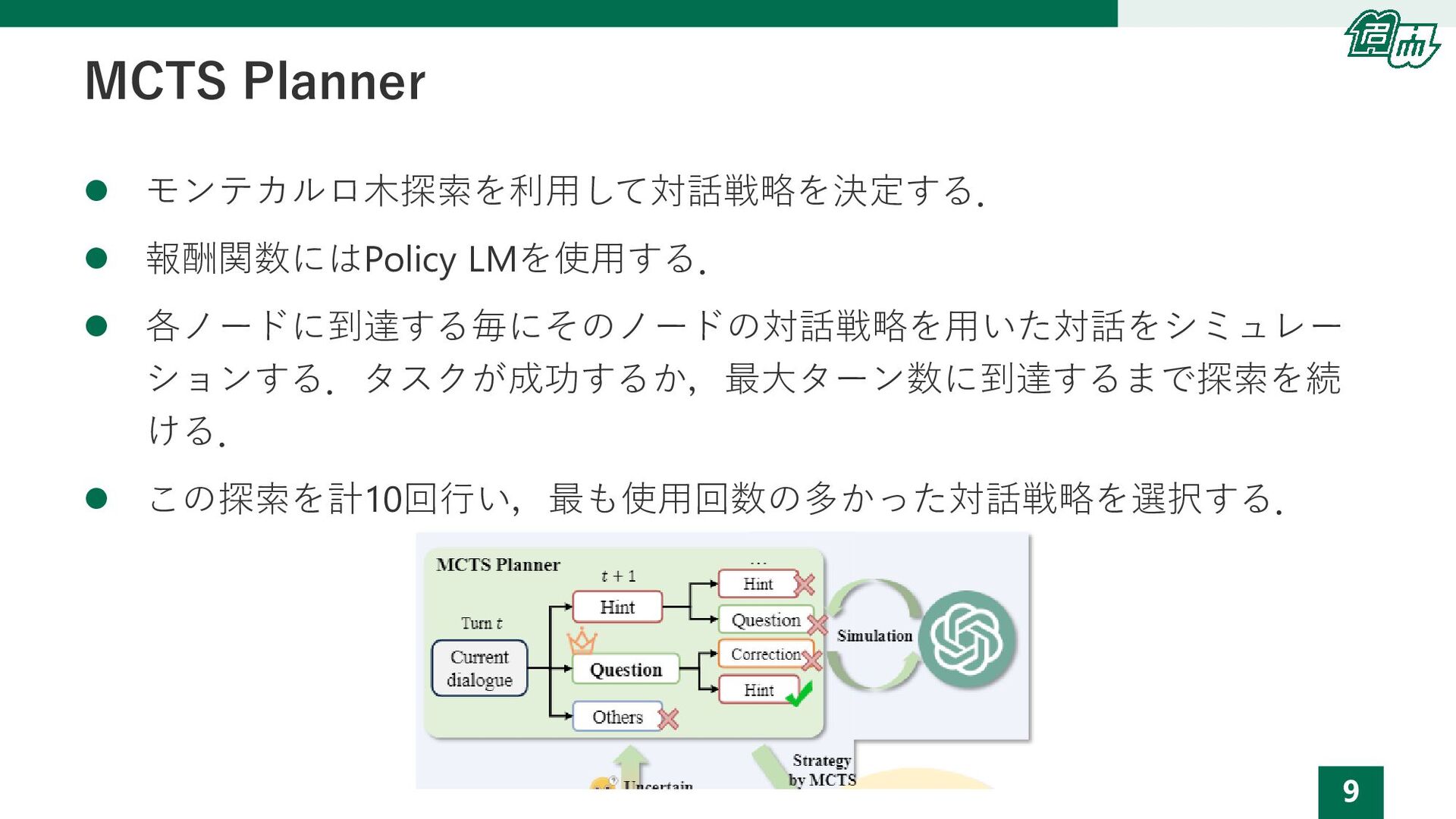
9 MCTS Planner ⚫ モンテカルロ木探索を利用して対話戦略を決定する. ⚫ 報酬関数にはPolicy LMを使用する. ⚫ 各ノードに到達する毎にそのノードの対話戦略を用いた対話をシミュレー
ションする.タスクが成功するか,最大ターン数に到達するまで探索を続 ける. ⚫ この探索を計10回行い,最も使用回数の多かった対話戦略を選択する.
10 Policy LM Plannerの訓練法 ⚫ 既存のデータセットを利用し たオフライン強化学習 ⚫ MCTSを利用したDialogue LLMとUser
LLMの対話シミュ レーションによる強化学習 ⚫ 各状態での初期報酬は Reward LLMが生成 ◼ Reward LLMの説明は次ページ
11 Reward LLM 𝐿𝐿𝑀𝑟𝑤𝑑 の報酬計算 ⚫ 𝐿𝐿𝑀𝑟𝑤𝑑 は現在の対話状態の成否を選択肢から判断する. ◼ ESConv(患者の問題が解決されたか)の例
◆ 1.患者の気分は悪化した(-1.0点), 2.患者の気分は変わらなかった(-0.5点) 3.患者の気分は良くなった(0.5点), 4.患者の問題は解決した(1.0点) ⚫ 𝐿𝐿𝑀𝑟𝑤𝑑 から複数回サンプルした結果の平均値𝑣𝑡 を計算 ⚫ 最大ターンTと閾値εに基づいて対話状態stateを決定 ⚫ stateに基づいて報酬rを決定
12 実験 ⚫ 3種類のデータセットを利用 ⚫ モデル ◼ Policy LM:RoBERTa Large
◼ 𝐿𝐿𝑀𝑠𝑦𝑠 /𝐿𝐿𝑀𝑢𝑠𝑟 /𝐿𝐿𝑀𝑟𝑤𝑑 :gpt-3.5-turbo-0613 ⚫ 評価方法 ◼ 評価尺度:Average Turn (AT), Success Rate (SR), 人手評価 ◼ 最大ターン数:8 データセット 概要 対話戦略の種類 ESConv [Liu’21] 患者とカウンセラーのカウンセリング 8種類(質問・共感等) CIMA [Stasaski’20] 生徒と先生の語学学習 5種類(ヒント・訂正等) CraisglistBargain [He’18] バーゲンサイトにおける売り手と買い手の値段交渉 11種類(質問・提案等)
13 実験結果ー自動評価(1/2) ⚫ Policy LMのみを利用するDPDP (System1)でも既存手法を大幅に上回 る性能を達成 ⚫ モンテカルロ木探索も利用する DPDP
(System 1&2)はほぼ100%の対 話成功率となった (平均約2ターンでタスクが達成される のは非現実的では…?)
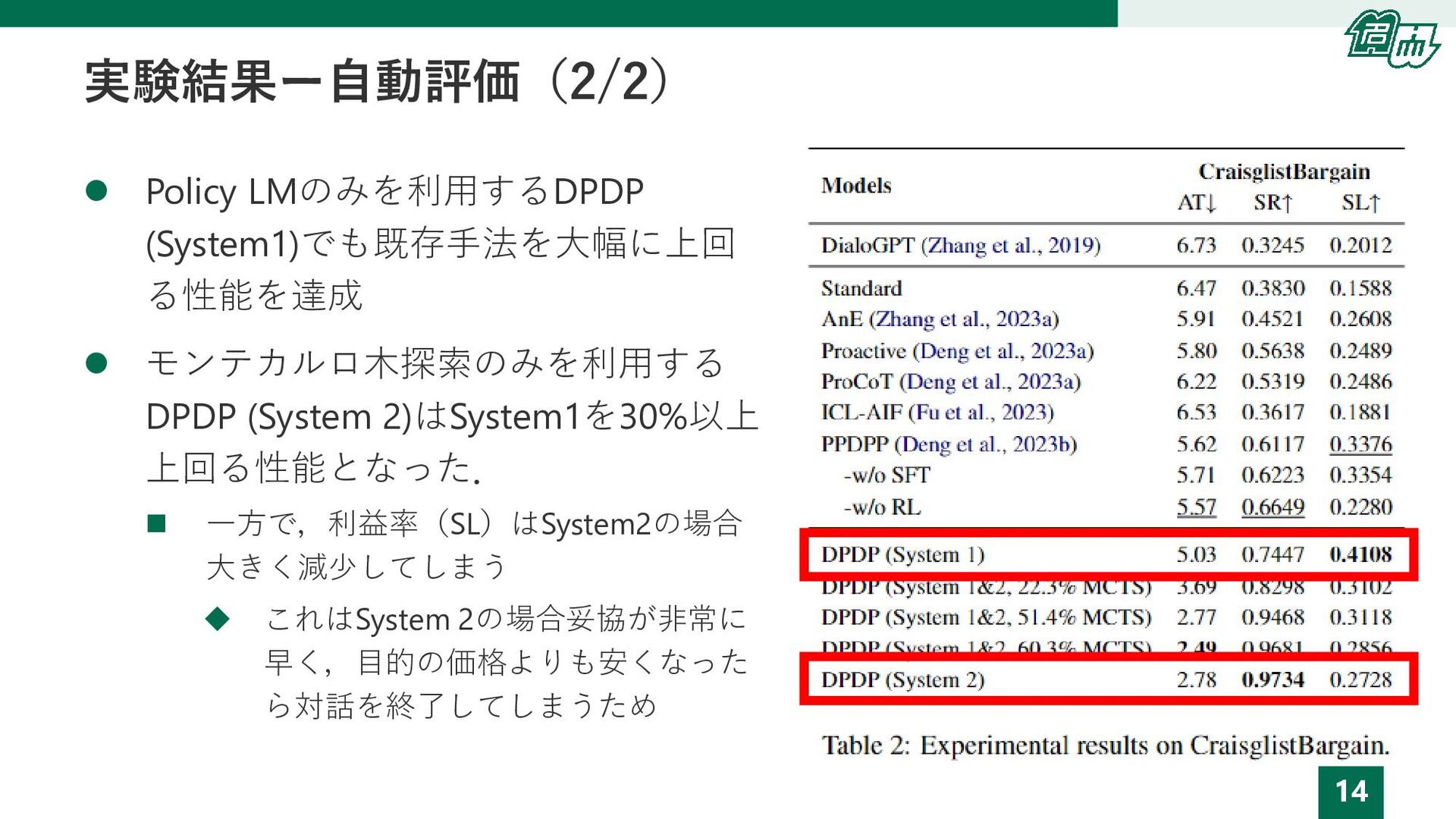
14 実験結果ー自動評価(2/2) ⚫ Policy LMのみを利用するDPDP (System1)でも既存手法を大幅に上回 る性能を達成 ⚫ モンテカルロ木探索のみを利用する DPDP
(System 2)はSystem1を30%以上 上回る性能となった. ◼ 一方で,利益率(SL)はSystem2の場合 大きく減少してしまう ◆ これはSystem 2の場合妥協が非常に 早く,目的の価格よりも安くなった ら対話を終了してしまうため
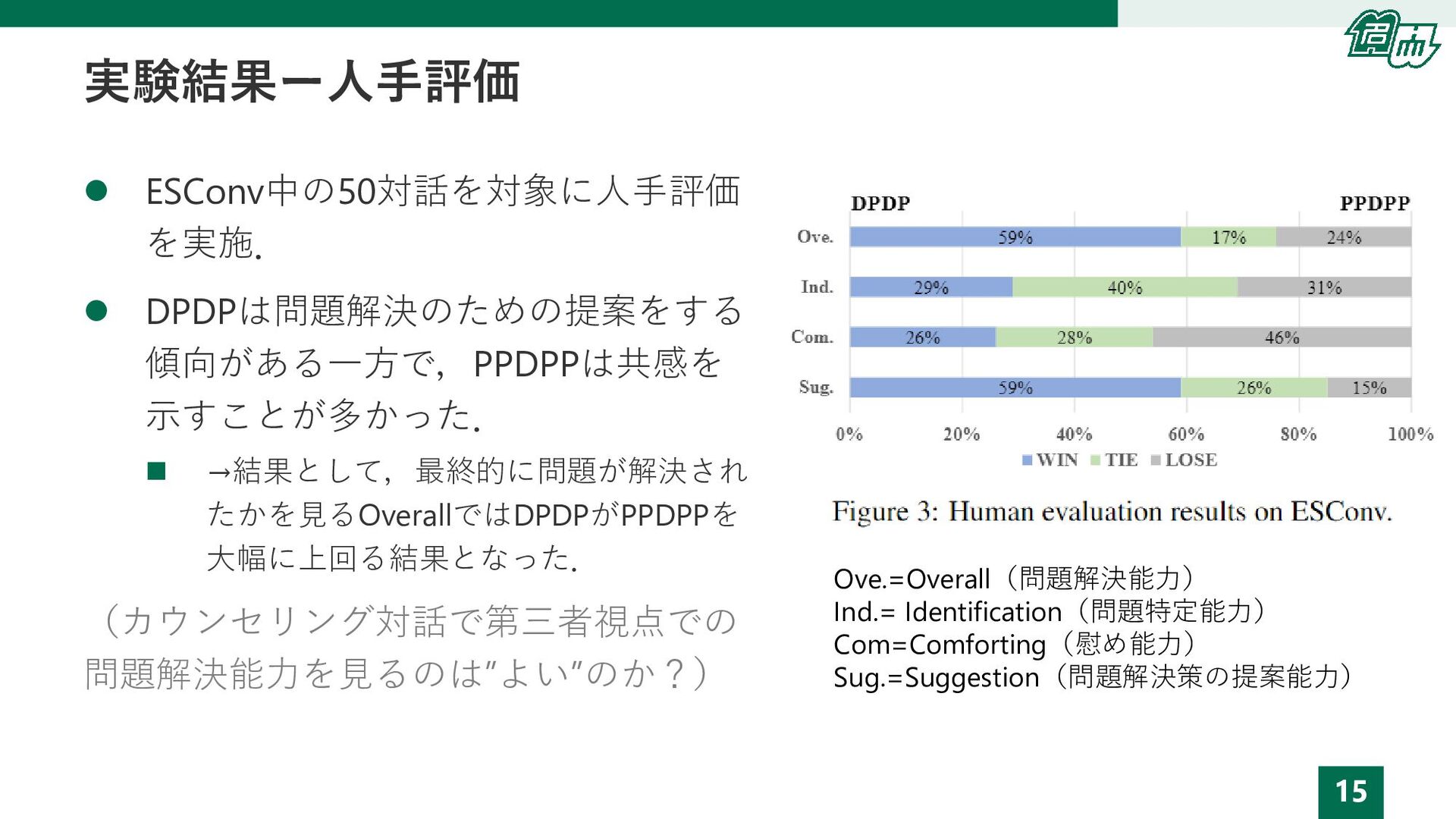
15 実験結果ー人手評価 ⚫ ESConv中の50対話を対象に人手評価 を実施. ⚫ DPDPは問題解決のための提案をする 傾向がある一方で,PPDPPは共感を 示すことが多かった. ◼
→結果として,最終的に問題が解決され たかを見るOverallではDPDPがPPDPPを 大幅に上回る結果となった. (カウンセリング対話で第三者視点での 問題解決能力を見るのは”よい”のか?) Ove.=Overall(問題解決能力) Ind.= Identification(問題特定能力) Com=Comforting(慰め能力) Sug.=Suggestion(問題解決策の提案能力)
16 個人的な感想 ⚫ シミュレーションのユーザーの応答と評価実験でのユーザーの応答が同じ モデルによって行われているのはずるいのでは? ◼ シチュエーション(患者の抱えている問題等)は異なるが,ほぼテストデータで訓練 しているのと同じなのではないか? ◼ 推論時においては,モンテカルロ木探索を使う場合は実質対話が成功するまでretryし
て,うまくいった戦略を使っているの同じ ◼ 一方で,推論時にモンテカルロ木探索を全く使わない手法でもかなり性能が改善して いるのはすごい ◆ 直感的に最適な戦略を取れるようになっている ⚫ 実際に人との対話実験を行って欲しかった…
17 まとめ ⚫ Dual Process Theoryを用いた対話計画手法Dual-Process Dialogue Planning(DPDP)を提案 ⚫ Policy
LMを訓練するため,オフライン強化学習とモンテカルロ木探索を組 み合わせた新しい2段階の訓練手法を開発 ⚫ 3種類の能動的対話タスクを対象とした評価実験により,提案手法が既存手 法を大幅に上回る性能を達成することを実証
{kind=link}
{kind=link}
![3 先行研究 ⚫ 既存手法[Deng+’23, Fu+’23]の多くは未来の状況(システムの応答によってユー ザの応答がどのように変化するか)を考慮できていないため,長期的な対 話戦略を扱うことができない. ⚫ 未来の状況を扱うために,モンテカルロ木探索を応用した手法[Yu+’23]もあ るが,コスト面と応答速度の点で実用的でない.](https://files.speakerdeck.com/presentations/b788649dd22d4390889476f06740a86d/slide_2.jpg){kind=link}
![4 Dual Process Theory(二重過程理論) ⚫ Dual Process Theory:人間の思考には「速く直感的な思考」と「遅く分析 的な思考」の2種類があり,これらを柔軟に使い分けているという理論 [Kahneman’03]](https://files.speakerdeck.com/presentations/b788649dd22d4390889476f06740a86d/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}