Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データチームの境界を考える
Search
Atsushi Sumita
June 16, 2022
Technology
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データチームの境界を考える
ナウキャストのストリームアラインドチームと, チームAPIとしてのdbt導入の取り組みについて紹介しています.
Atsushi Sumita
June 16, 2022
More Decks by Atsushi Sumita
See All by Atsushi Sumita
LLMによるデータ構造化の精度管理
yummydum
1
300
Redshift Serverless vs Snowflake 徹底比較!
yummydum
1
2.7k
最強?のデータ組織アーキテクチャ
yummydum
2
660
データを開発するためのDataOps
yummydum
1
1.1k
Jupyter Notebook Ops
yummydum
1
240
SNLP presentation 20190928
yummydum
0
390
Other Decks in Technology
See All in Technology
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
6
1.5k
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
190
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
4
6k
Jitera Company Deck
jitera
0
570
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
960
人とエージェントが高め合う協業設計
kintotechdev
0
940
VPCセキュリティ対応の最新事情
nagisa53
1
330
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
880
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
660
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
450
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
720
文字起こし基盤の信頼性
abnoumaru
0
140
Featured
See All Featured
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
Navigating Weather and Climate Data
rabernat
0
400
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
380
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
280
Building Applications with DynamoDB
mza
96
7.1k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
630
The SEO identity crisis: Don't let AI make you average
varn
0
520
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
980
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Transcript
© 2015 - 2022 Nowcast Inc. データチームの境界を考える 株式会社ナウキャスト 隅田 敦
1
© 2013 - 2022 Finatext Ltd. 2 目次 これまでのナウキャストのチーム構造 -
データエンジニアが主役となる組織 - チームトポロジー: Stream Aligned Team / Platform Team / チームAPI - Stream Aligned Data Engineering Teamによる効率的な開発 - 課題: チームAPIが整備されていないことによる非効率性 チーム境界とプラットフォームチーム - チームAPIとしてのdbt - Data hub platformに向けた取り組み - Platformチームは中央集権型のデータエンジニアチームではない
© 2013 - 2022 Finatext Ltd. 3 これまでのナウキャストのチーム構造
© 2013 - 2022 Finatext Ltd. 4 データエンジニアが主役となる組織 データの保有側・利用側の双方に価値を提供するAlternative Dataの
Two-Sided Platformを展開
© 2013 - 2022 Finatext Ltd. 5 チームトポロジー: Stream Aligned
Team / Platform Team / チームAPI • Stream Aligned Team ◦ 価値のデリバリーをend to endで担う ◦ 要求探索から本番運用まで他チームへの引き継ぎ無しで行える • Platform Team ◦ Stream Aligned Teamを支援する内部プロダクトの開発を担う ◦ インフラなど下位の機能を横断的に抽象化したツールを提供 • チームAPI ◦ チームとやり取りするための方法を記述した仕様 ◦ コードであれば, ランタイムのエンドポイント, ライブラリ, UI ◦ データの場合はどうか? これを考えるのが本発表の目的
© 2013 - 2022 Finatext Ltd. 6 The Bezos Mandate
(2002) 私とAWSの15年 あるいはThe Bezos Mandateの話 - NRIネットコムBlog
© 2013 - 2022 Finatext Ltd. 7 Stream Aligned Data
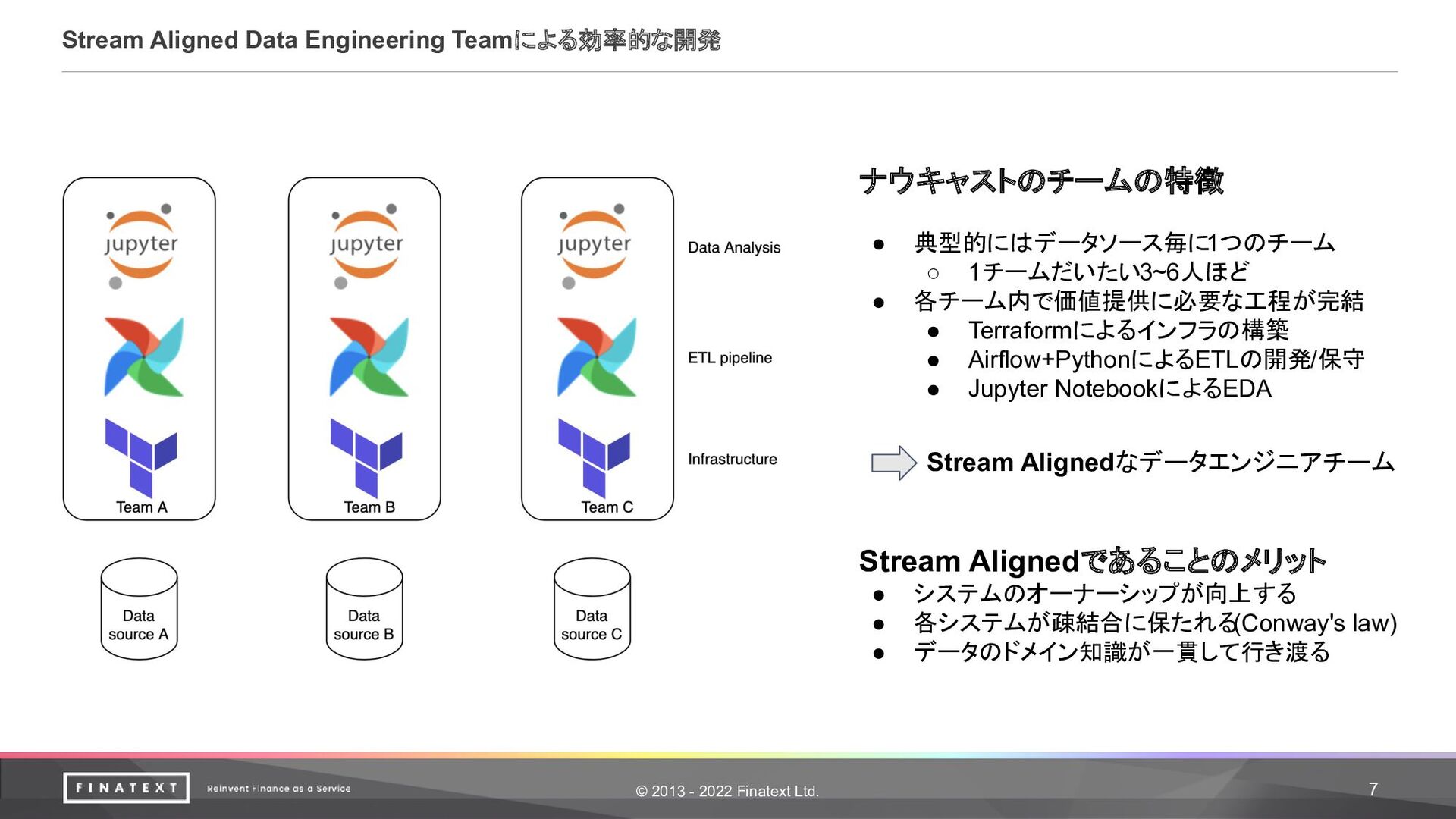
Engineering Teamによる効率的な開発 ナウキャストのチームの特徴 • 典型的にはデータソース毎に1つのチーム ◦ 1チームだいたい3~6人ほど • 各チーム内で価値提供に必要な工程が完結 • Terraformによるインフラの構築 • Airflow+PythonによるETLの開発/保守 • Jupyter NotebookによるEDA Stream Alignedなデータエンジニアチーム Stream Alignedであることのメリット • システムのオーナーシップが向上する • 各システムが疎結合に保たれる (Conway's law) • データのドメイン知識が一貫して行き渡る
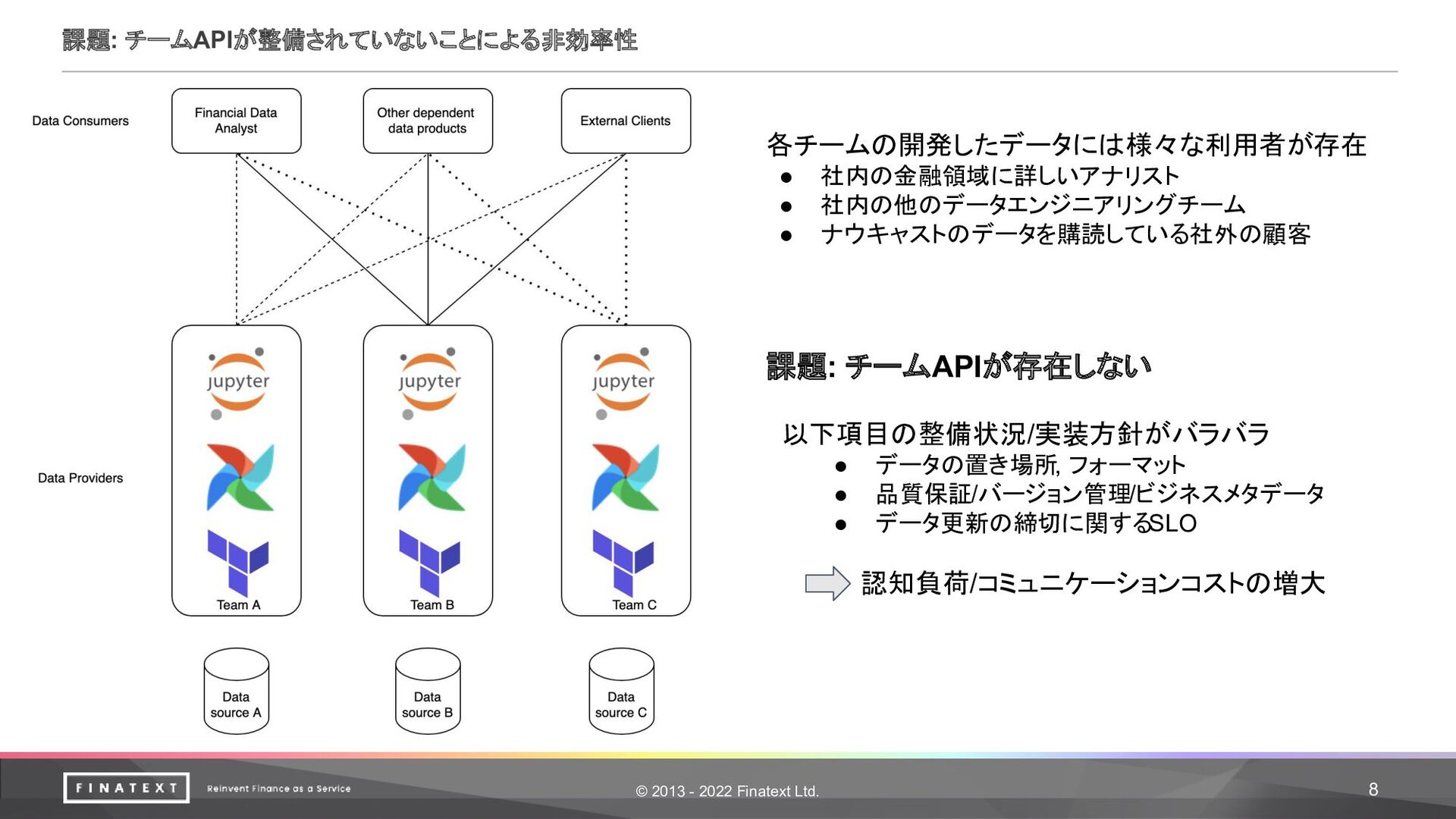
© 2013 - 2022 Finatext Ltd. 8 課題: チームAPIが整備されていないことによる非効率性 各チームの開発したデータには様々な利用者が存在
• 社内の金融領域に詳しいアナリスト • 社内の他のデータエンジニアリングチーム • ナウキャストのデータを購読している社外の顧客 課題: チームAPIが存在しない 以下項目の整備状況/実装方針がバラバラ • データの置き場所, フォーマット • 品質保証/バージョン管理/ビジネスメタデータ • データ更新の締切に関するSLO 認知負荷/コミュニケーションコストの増大
© 2013 - 2022 Finatext Ltd. 9 チーム境界とプラットフォームチーム
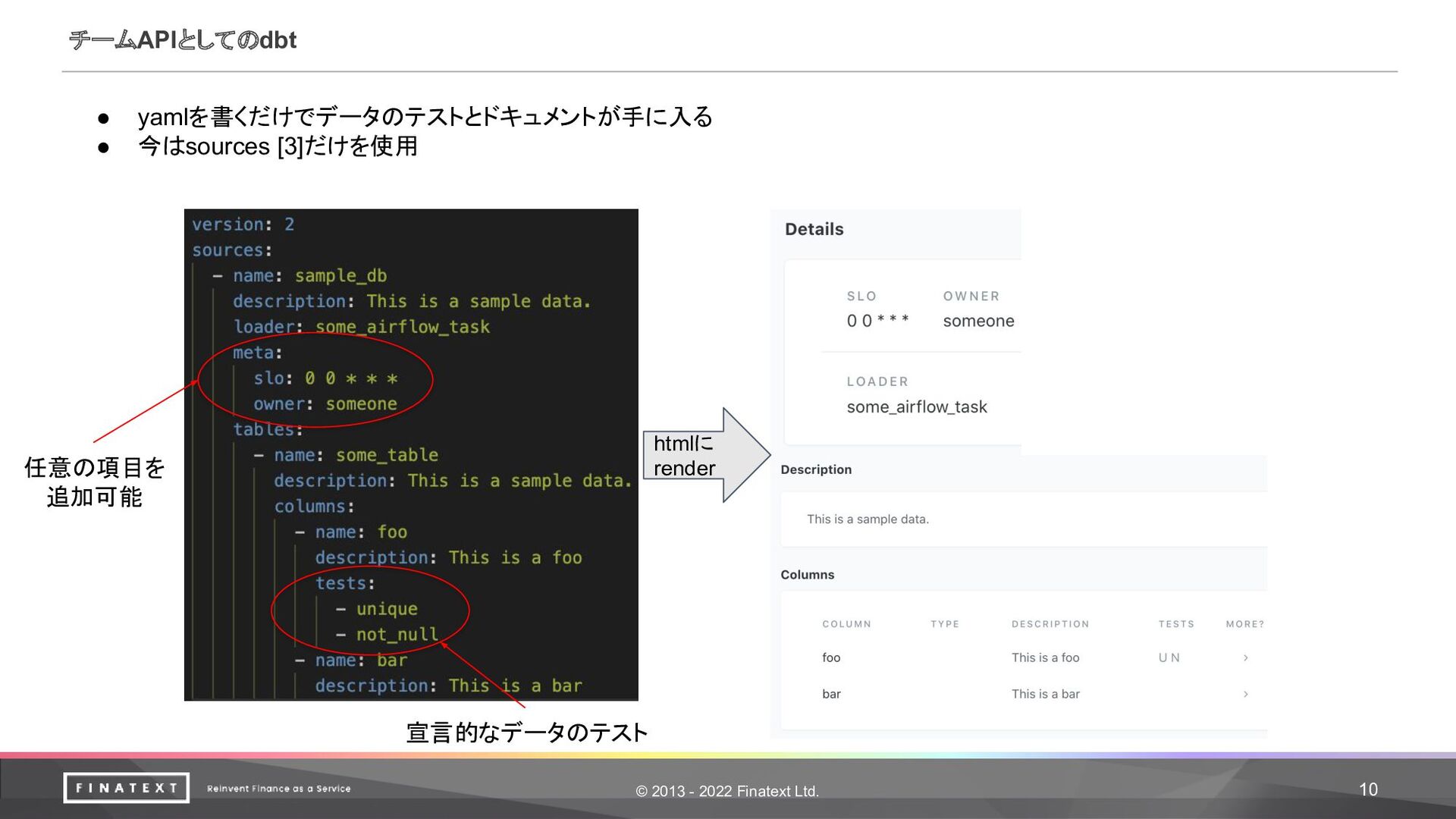
© 2013 - 2022 Finatext Ltd. 10 チームAPIとしてのdbt • yamlを書くだけでデータのテストとドキュメントが手に入る
• 今はsources [3]だけを使用 htmlに render 宣言的なデータのテスト 任意の項目を 追加可能
© 2013 - 2022 Finatext Ltd. 11 Data hub platformに向けた取り組み
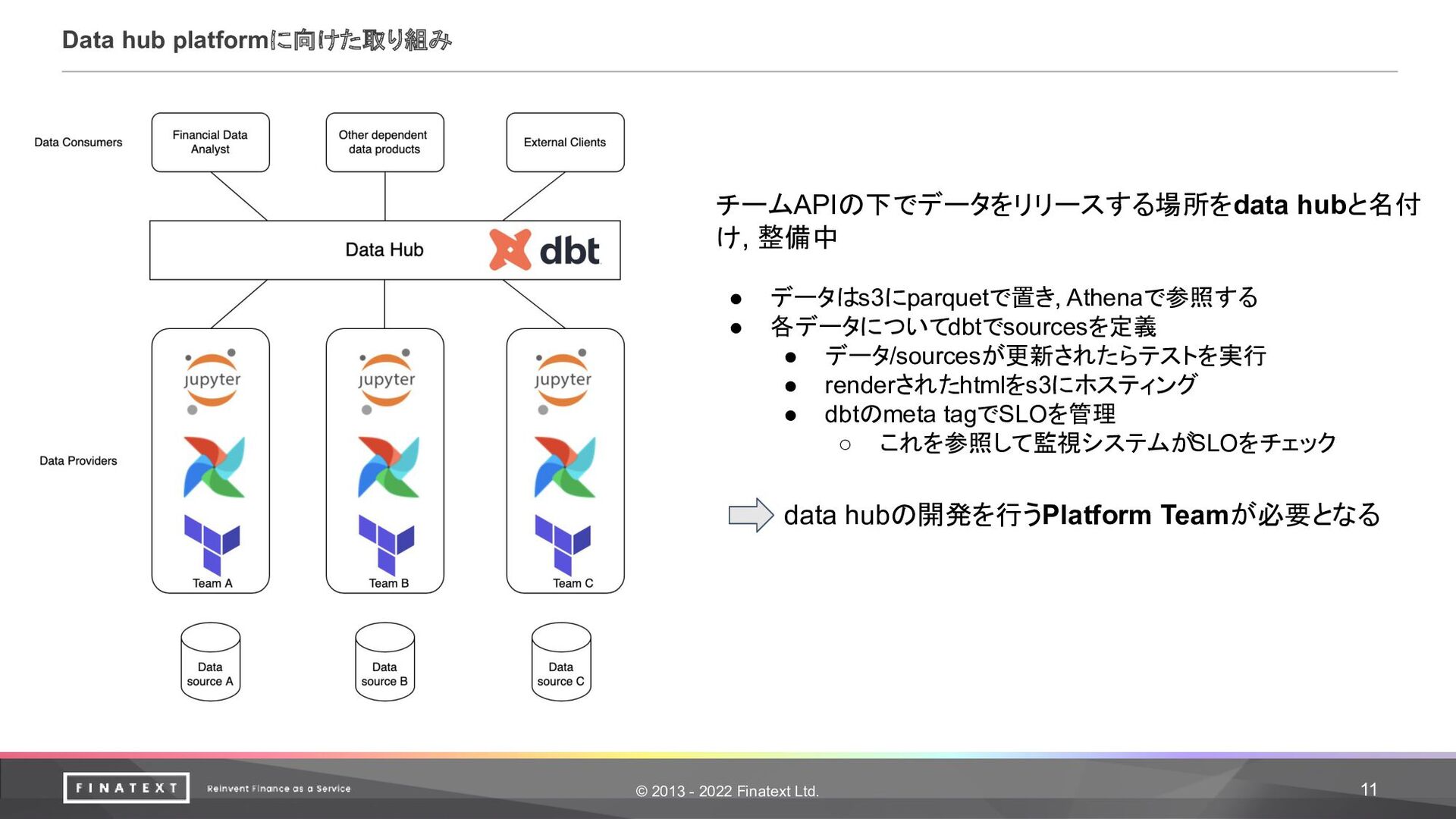
チームAPIの下でデータをリリースする場所をdata hubと名付 け, 整備中 • データはs3にparquetで置き, Athenaで参照する • 各データについてdbtでsourcesを定義 • データ/sourcesが更新されたらテストを実行 • renderされたhtmlをs3にホスティング • dbtのmeta tagでSLOを管理 ◦ これを参照して監視システムがSLOをチェック data hubの開発を行うPlatform Teamが必要となる
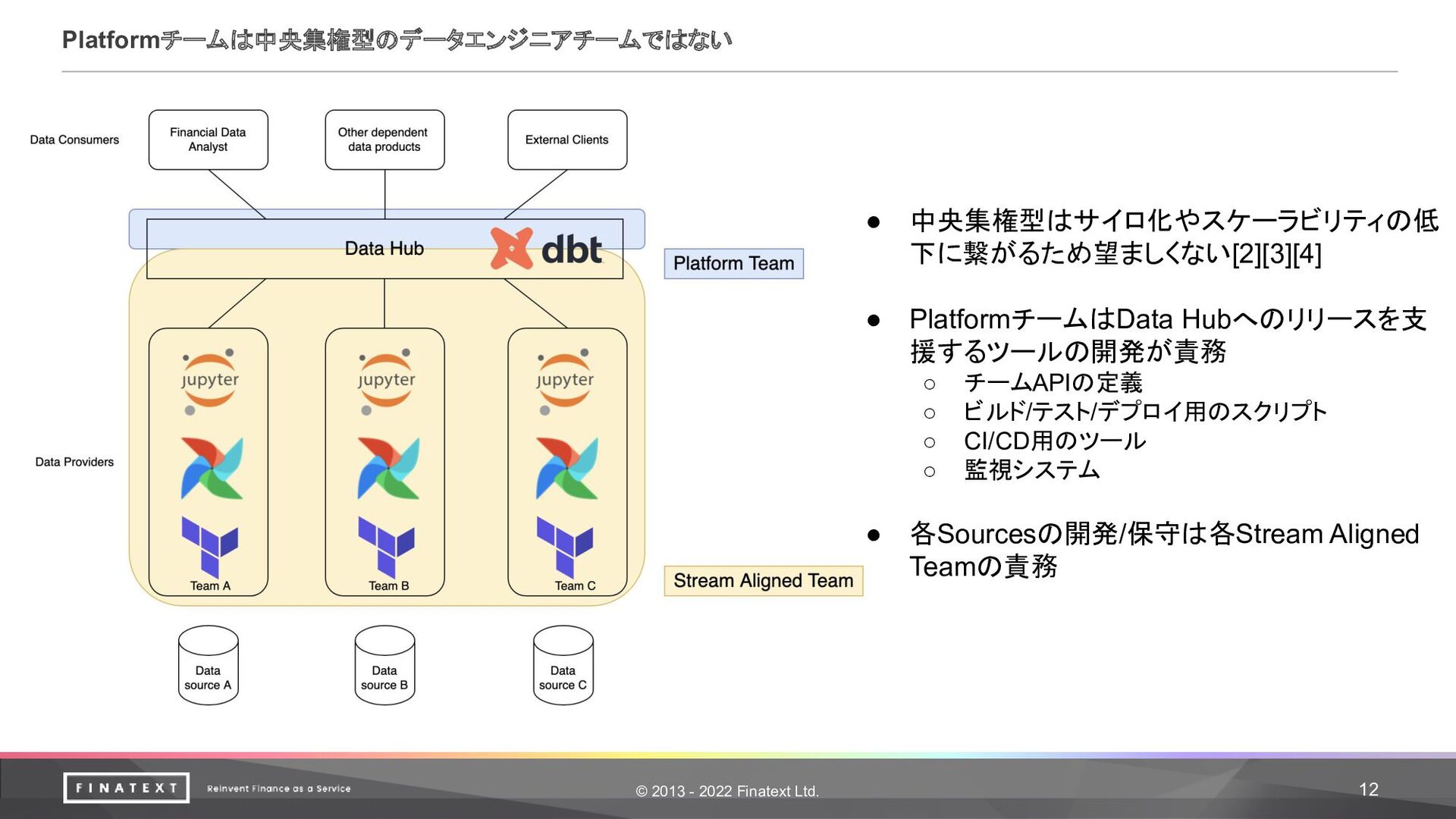
© 2013 - 2022 Finatext Ltd. 12 Platformチームは中央集権型のデータエンジニアチームではない • 中央集権型はサイロ化やスケーラビリティの低
下に繋がるため望ましくない[2][3][4] • PlatformチームはData Hubへのリリースを支 援するツールの開発が責務 ◦ チームAPIの定義 ◦ ビルド/テスト/デプロイ用のスクリプト ◦ CI/CD用のツール ◦ 監視システム • 各Sourcesの開発/保守は各Stream Aligned Teamの責務
© 2013 - 2022 Finatext Ltd. 13 Reference [1] Team
Topologies [2] 私とAWSの15年 あるいはThe Bezos Mandateの話 - NRIネットコムBlog [3] Sources | dbt Docs [4] How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh [5] Data Mesh Principles and Logical Architecture [6] Data Management at Scale
© 2013 - 2022 Finatext Ltd. 14 End
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© 2013 - 2022 Finatext Ltd. 13 Reference [1] Team](https://files.speakerdeck.com/presentations/cbd2be134fcf4bb5b11f1792fbbe9405/slide_12.jpg){kind=link}
{kind=link}