Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SNLP presentation 20190928
Search
Atsushi Sumita
September 28, 2019
Research
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SNLP presentation 20190928
Presentation by Atsushi Sumita (Univ. Tokyo, Miyao lab, M1)
Atsushi Sumita
September 28, 2019
More Decks by Atsushi Sumita
See All by Atsushi Sumita
LLMによるデータ構造化の精度管理
yummydum
1
300
Redshift Serverless vs Snowflake 徹底比較!
yummydum
1
2.7k
最強?のデータ組織アーキテクチャ
yummydum
2
660
データチームの境界を考える
yummydum
0
1.1k
データを開発するためのDataOps
yummydum
1
1.1k
Jupyter Notebook Ops
yummydum
1
240
Other Decks in Research
See All in Research
nlp2026 In-Context Learningに基づく経路案内のための地理的知識の活用方法に関する検討
takashiinui
0
110
SLAMはどこまで解決されたのか?
tomonom
0
870
全国町字単位空き家率推定データver1.0データ仕様
microbaseinc
0
140
Vector Map as Language: Toward Unified Remote Sensing Vector Mapping
satai
3
110
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
130
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
360
LA-Bench 2025:実験指示から 実行可能手順を生成するためのデータセット/LA-Bench 2025: A Dataset for Generating Executable Experimental Procedures from Experimental Instructions
stktu
0
100
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
330
HAKARI-Bench - 実運用視点での情報検索モデル評価ベンチマーク
hotchpotch
0
110
Featured
See All Featured
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Music & Morning Musume
bryan
47
7.3k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
910
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
sira's awesome portfolio website redesign presentation
elsirapls
0
310
Building Applications with DynamoDB
mza
96
7.1k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
Chasing Engaging Ingredients in Design
codingconduct
0
240
So, you think you're a good person
axbom
PRO
2
2.1k
Everyday Curiosity
cassininazir
0
260
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Transcript
SNLP発表資料 東大 宮尾研 M1 隅田 敦
自己紹介 東大宮尾研究室M1の隅田です. Probingに興味があります ◦ BERTのなかみってどうなってるんだろ~ ◦ 問いがふわふわなのでより具体的/特定的に定式化したい ◦ 興味が近い人は是非話しかけて下さい! YANSで奨励賞を頂きました!
◦ 表彰はされなかったので今宣伝… ◦ まだまだ未熟な研究なのでブラッシュアップしていきたいです!
読む人:東大宮尾研 M1 隅田 敦 (図表は論文や著者発表資料から抜粋)
概要 各次元に一つのsenseが対応する単語埋め込みを提案 senseとは? ◦ ここでは単語の集まりから想起される意味と定義 ◦ 数学的には,単語上の多項分布で表現 ◦ トピックモデルと似た発想 何が嬉しいのか?
◦ 各次元が解釈可能なものとなる ◦ 多義語をうまく表現することが出来る
抽出されたSenseの例
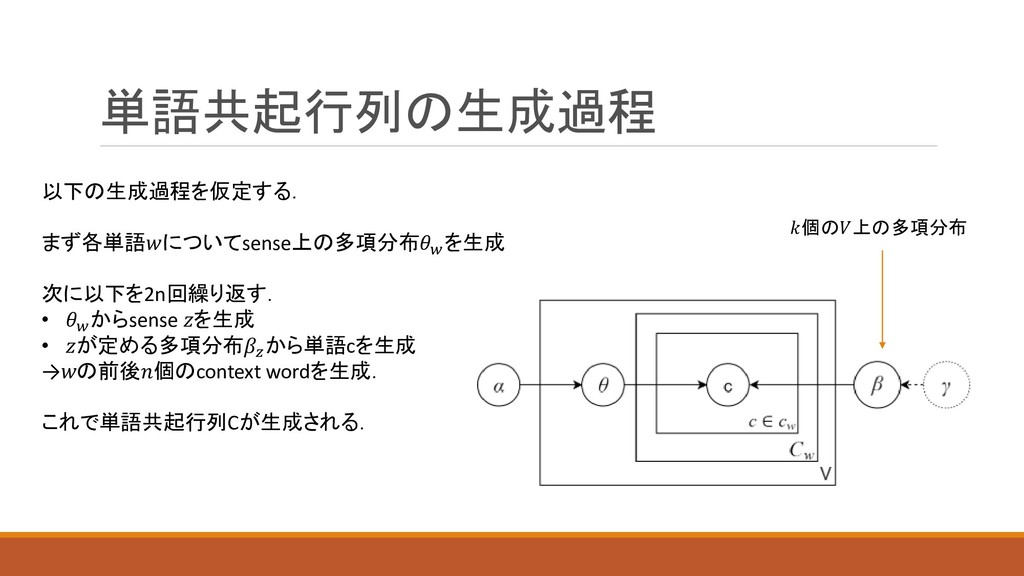
単語共起行列の生成過程 以下の生成過程を仮定する. まず各単語についてsense上の多項分布 を生成 次に以下を2n回繰り返す. • からsense を生成 • が定める多項分布
から単語cを生成 →の前後個のcontext wordを生成. これで単語共起行列Cが生成される. 個の上の多項分布
Word2senseの構成 変分推論でと を推定 ◦ 推定はマルチコアCPU1個で5時間 ◦ はやい ◦ の埋め込み の第次元目:
◦ 第一項:wがある単語のcontext wordの時に,zがwを生成している確率 ◦ 第二項:前述の生成モデルにおいてwのcontext wordを生成する際にzが選ばれる確率 他にもいくつか後処理を行う ◦ 似た単語の分布を持つsenseを階層クラスタリングでmerge ◦ スパースになるよう絶対値上位個の次元以外は0に置き換え,正規化
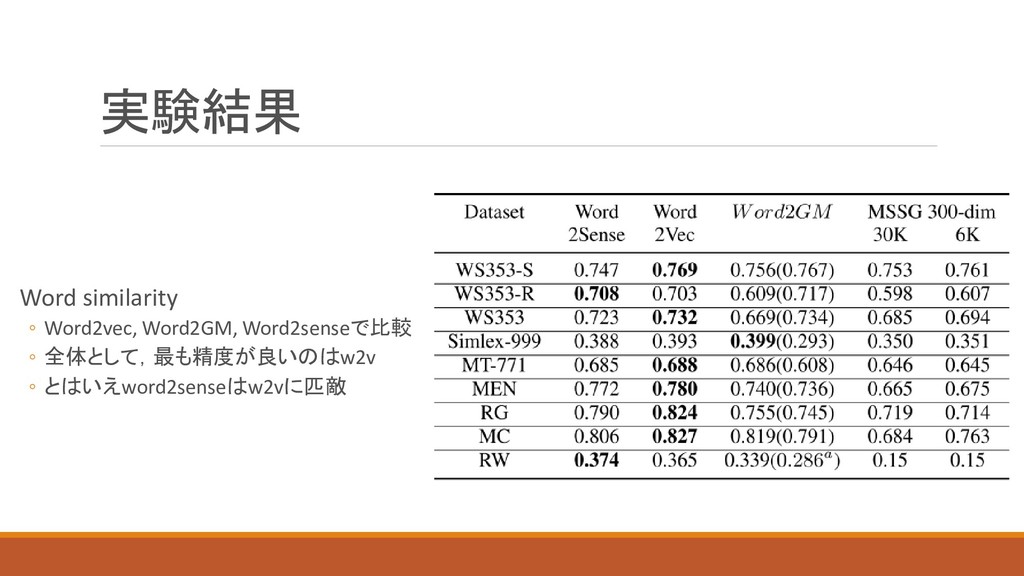
実験結果 Word similarity ◦ Word2vec, Word2GM, Word2senseで比較 ◦ 全体として,最も精度が良いのはw2v ◦
とはいえword2senseはw2vに匹敵
実験結果 Word entailment ◦ Word2GM, Word2senseで比較 ◦ Word2senseが良い性能を示した
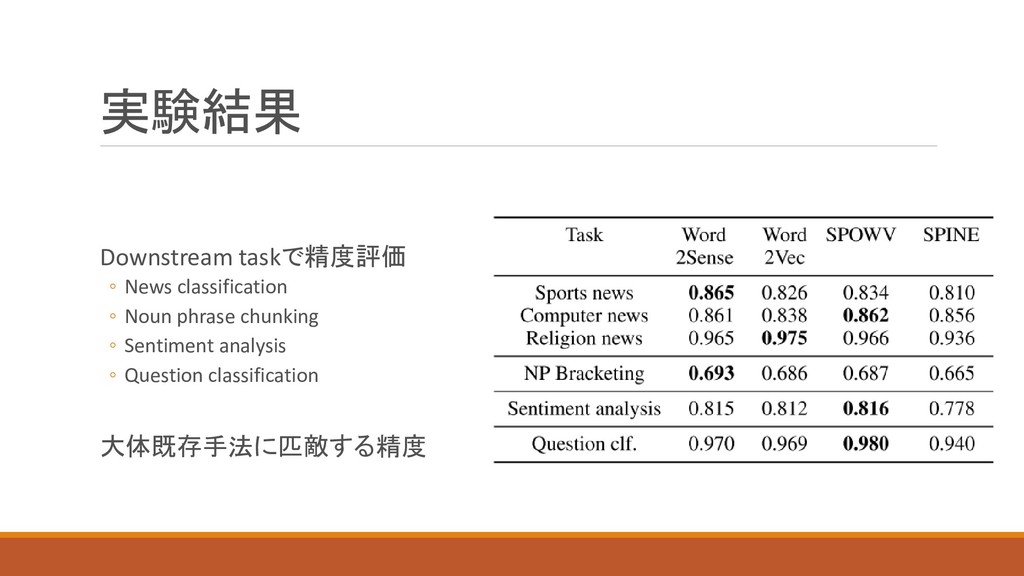
実験結果 Downstream taskで精度評価 ◦ News classification ◦ Noun phrase chunking
◦ Sentiment analysis ◦ Question classification 大体既存手法に匹敵する精度
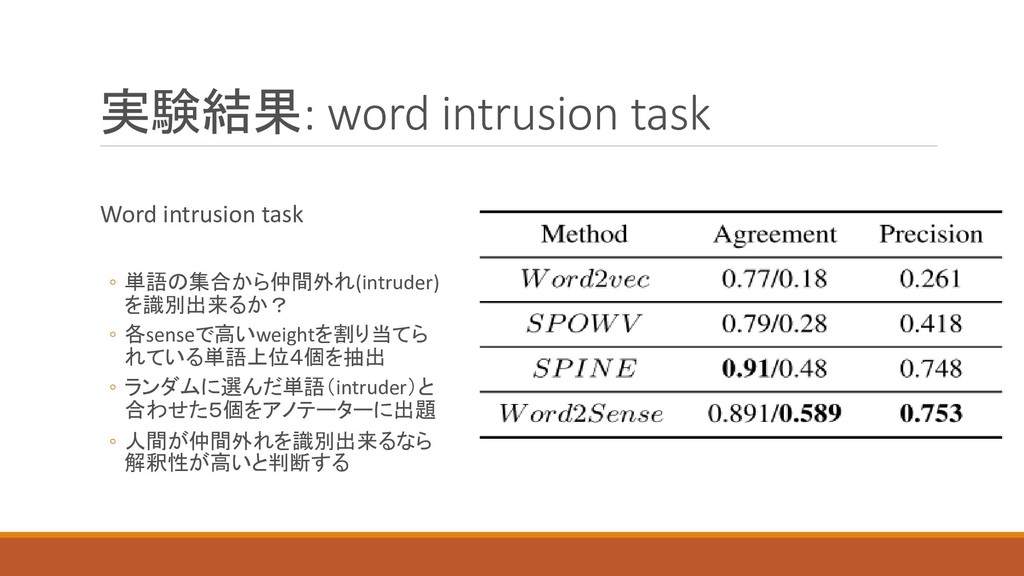
実験結果: word intrusion task Word intrusion task ◦ 単語の集合から仲間外れ(intruder) を識別出来るか?
◦ 各senseで高いweightを割り当てら れている単語上位4個を抽出 ◦ ランダムに選んだ単語(intruder)と 合わせた5個をアノテーターに出題 ◦ 人間が仲間外れを識別出来るなら 解釈性が高いと判断する
WordCtx2sense 多義語について,文脈からどの意味なのかを判定したい 文脈Tのsenseと単語埋め込みのsenseのintersectionを推定する 文脈Tの単語がより少数のsenseから生成されていると仮定 ◦ 更新後の埋め込みを , = 1,2, …
とする 元のembeddingをTに基づいて更新する ◦ の中で非零な成分が最大でも個となるようにmultiplicative weight updateを使用
WordCtx2sense 文脈Tの単語の生成過程を次のように仮定する ◦ を選び,ここから確率分布 = を得る ◦ から個の単語を生成し,を得る Log perplexity
を最大化するよう を学習し,元のembeddingを更新 ◦ 初期値は元のembeddingとし,KL距離を正則化項として追加
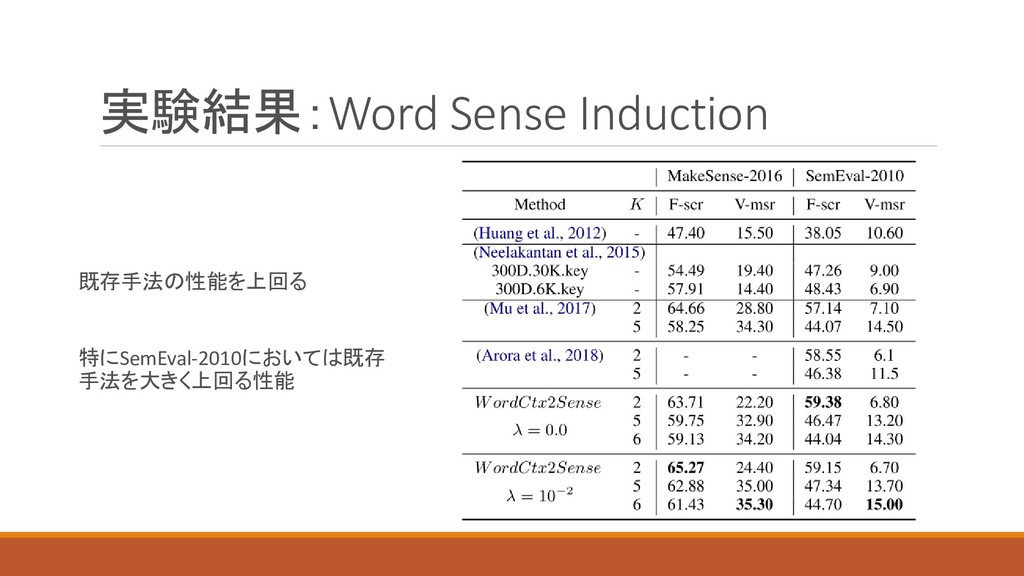
実験結果:Word Sense Induction 多義語が含まれた文書群を,意味ごとにクラスタリングするタスク 各文章毎にを学習し, ∗ = k をクラスターのラベルとする 評価指標は次の二つ
ある二つのinstanceが同じクラスターに属するか否かに関するF-score V-score : homogeneityとcoverageの調和平均 ◦ Homogeneity : 同じラベルを持つinstanceが同じクラスターに入っている割合 ◦ Coverage : 同じクラスターに入っているinstanceが同じラベルを持つ割合
実験結果:Word Sense Induction 既存手法の性能を上回る 特にSemEval-2010においては既存 手法を大きく上回る性能
実験結果:Contextual similarity 文脈付きの単語の組の類似度を推定するタスク アノテーターに1~10で類似度を答えてもらい,その平均をground truthとする この類似度との相関で評価を行う MSSG以外の全てのモデルより高性能
まとめ 各次元が解釈可能,スパース, 多義語を表現出来る単語埋め込みを提案 こうした性質がありながらも,様々なタスクで既存手法と同等あるいはそれ以上の性能を発揮 さらに文脈毎にどの意味で単語が用いられているのかを推定可能
読む人:東大 宮尾研 M1 隅田 敦 (図表は論文や著者発表資料から抜粋)
概要 Pretrain then fine tuningは様々なNLPタスクにおいて有効 ◦ 学習が安定/簡単 ◦ 汎化性能が高い しかし,これが何故なのかはまだよくわかっていない
Lossを可視化することで理由を探る ◦ ここではpretrain modelとしてBERTを分析対象にした
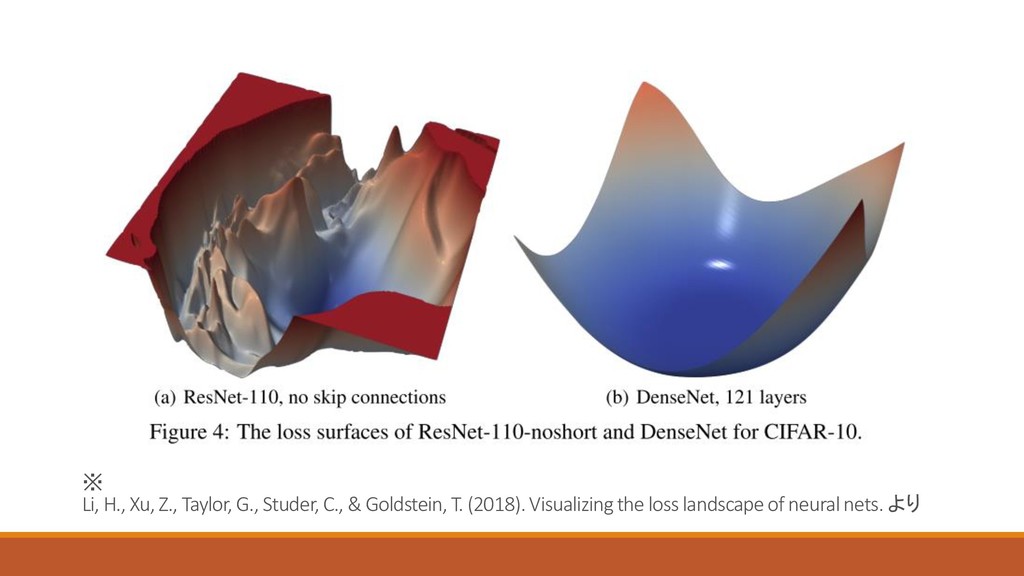
Lossの可視化:一次元の場合 Fine tuningで得た最終的なパラメタへの方向を1 = 1 − 0 とする 損失関数を初期点0 と訓練後パラメータへの方向1
に関して線形補完 ◦ i.e. 0 と1 の内分点で損失関数をプロットする
Lossの可視化 : 二次元の場合 二つのデータセットでfine tuningして得たパラメータへの方向1 と2 を軸として 可視化 それぞれの方向に対して1Dの場合と同じ線形補完を行う
※ Li, H., Xu, Z., Taylor, G., Studer, C., &
Goldstein, T. (2018). Visualizing the loss landscape of neural nets. より
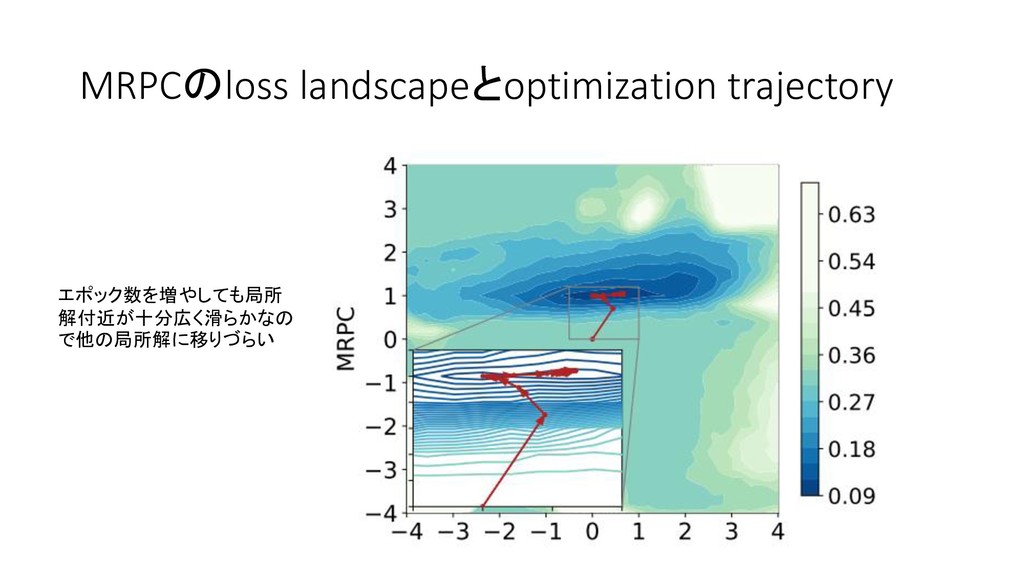
Lossの可視化 : Optimization trajectory 最適化の軌跡を可視化する 第エポック時のパラメータへの方向 を2Dに射影 ◦ 第エポックの座標が( ,
) 高次元空間の角度とノルムを二次元にそのまま持ってくる
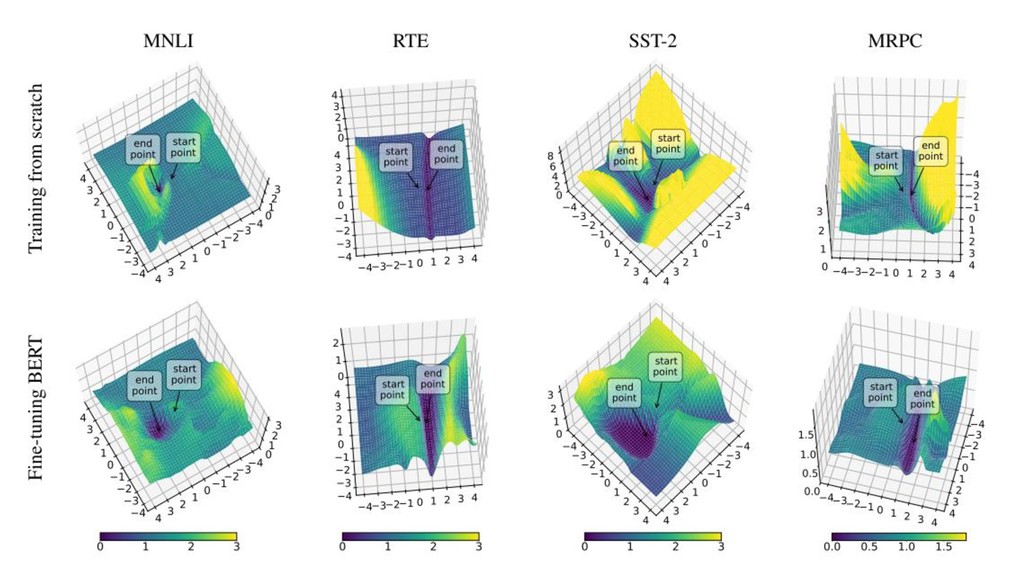
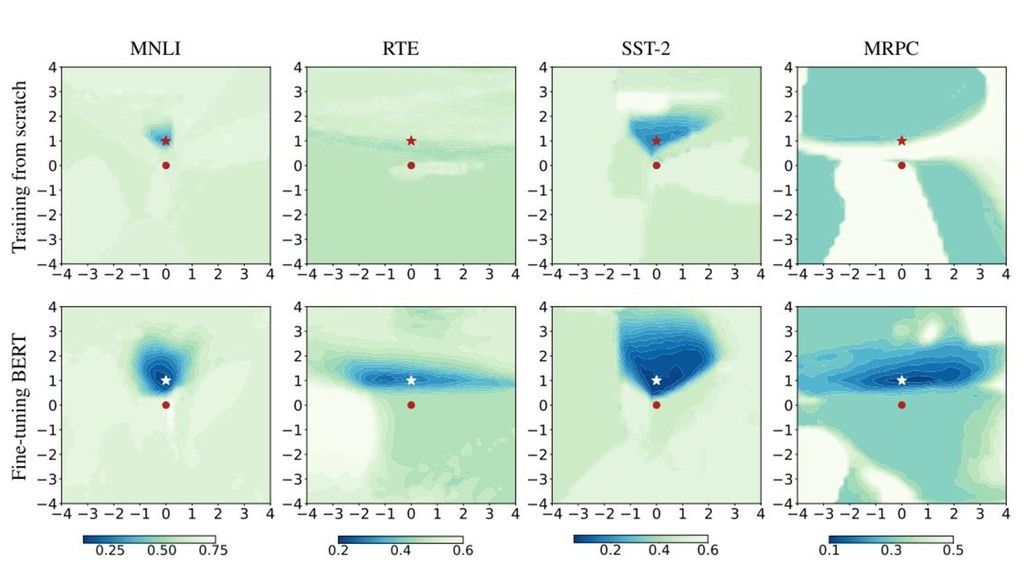
訓練済みBERTは良い初期点である 事前訓練済みのBERTからfine tuningする場合と,BERTのweightをランダムに初期化して学習を した場合とを比較 Fine tuningで得た局所解の周辺は滑らか Fine tuningのloss surfaceは最適化が容易な形をしている 得た局所解周辺は滑らかで広いので過学習しづらい
• エポック数を増やしてもdev dataにおけるlossが高まりづらい
None
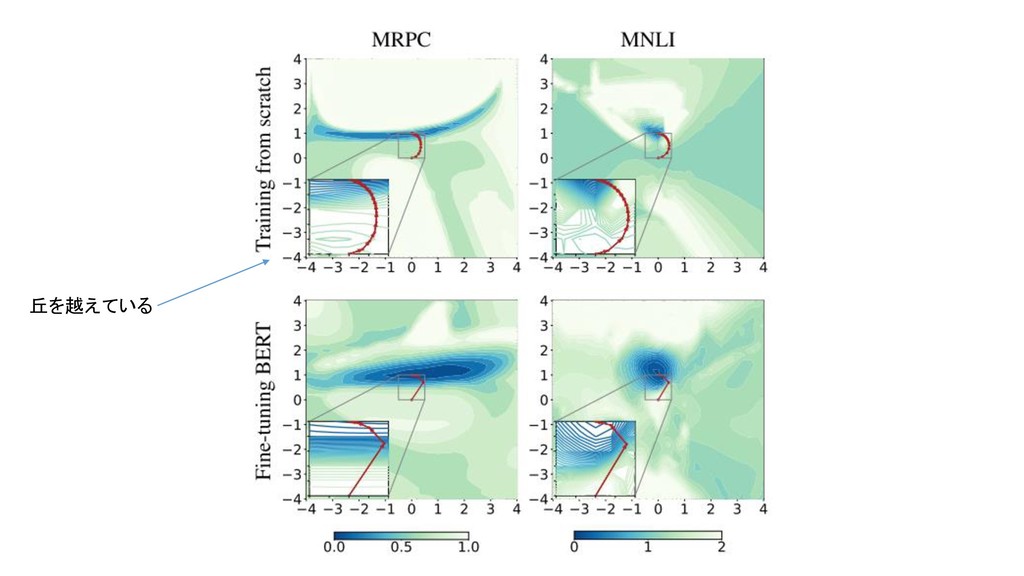
丘を越えている
MRPCのloss landscapeとoptimization trajectory エポック数を増やしても局所 解付近が十分広く滑らかなの で他の局所解に移りづらい
Fine tuningすると汎化しやすい 局所解付近が滑らかなほど汎化性能が高いという議論がある 汎化誤差のloss surfaceが訓練データのloss surfaceと整合的 ◦ 同じように滑らかな局所解に落ちていく
None
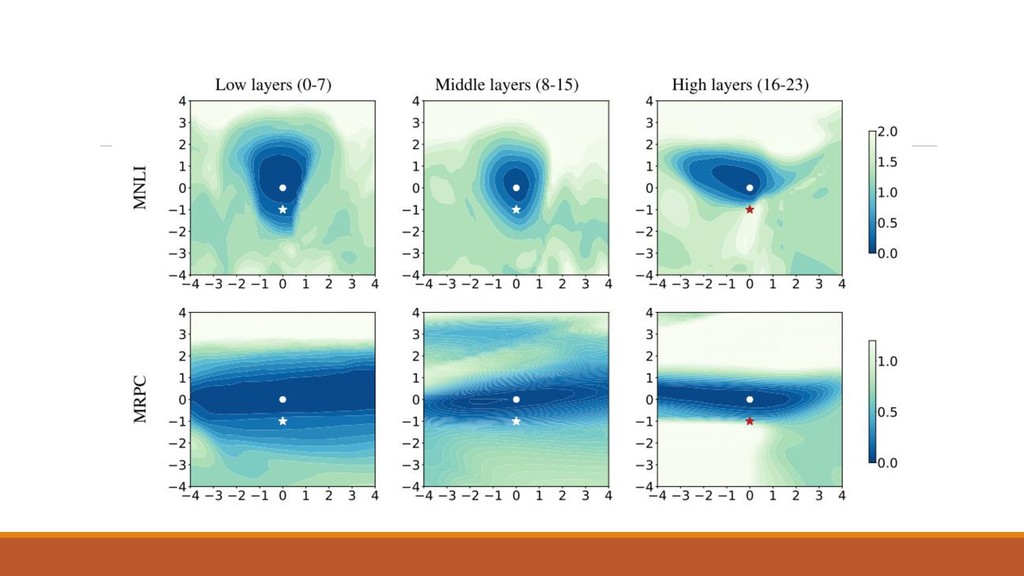
下層ほど一般的で転移可能性が高い 層ごとに違う情報を保持している説 ある層の訓練結果の方向を考える: 可視化してみると,下層のパラメタは動かしてもあまりロスが動かない 一方で上層のパラメタは動かすと精度に悪影響を及ぼす
None
まとめ BERTでfine tuningするのが何故有効なのかについて,可視化により調べた結果, ◦ より幅広い局所解が見つかるので, ◦ 学習が容易で汎化性能も良い ◦ 過学習しづらい ◦
訓練データのloss surfaceとテストデータのloss surfaceに整合性がある ◦ 下層ほど一般的で転移可能性の高い特徴量が含まれている といった事実が示唆された.
議論 可視化することで直感的な理解が可能になる 一方で結果の評価がやや主観的になってしまう ◦ “Loss surfaceが滑らか”とは? 曲率とかで定量的に測れると良いのかも? ◦ 汎化性能との関連も定量的に測ってみたいところ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}