Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介:∞-former: Infinite Memory Transformer
Search
yuri
September 20, 2022
Research
430
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介:∞-former: Infinite Memory Transformer
第14回最先端NLP勉強会(2022年9月26日、27日)@お茶大 発表用資料
yuri
September 20, 2022
More Decks by yuri
See All by yuri
データ指向モデリング「テキストマイニングの基礎」
yuri00
0
31
論文紹介:What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task Learning
yuri00
0
650
論文紹介:Learning Dependency-Based Compositional Semantics
yuri00
0
170
論文紹介:What Context Features Can Transformer Language Models Use?
yuri00
0
460
Other Decks in Research
See All in Research
AIで最適化を解けるか?
mickey_kubo
0
120
Claude Code × autoresearch 実践
mathbullet
0
160
PGDM: Physically Guided Diffusion Model for L Downscaling
satai
2
280
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
290
量子コンピュータの紹介
oqtopus
0
330
Cross-Media Information Spaces and Architectures
signer
PRO
0
300
「AIとWhyを深堀る」をAIと深堀る
iflection
0
490
Any-Optical-Model: A Universal Foundation Model for Optical Remote Sensing
satai
3
830
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
130
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1k
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
130
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
280
Featured
See All Featured
Agile that works and the tools we love
rasmusluckow
331
21k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.3k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
320
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Tell your own story through comics
letsgokoyo
1
950
Ruling the World: When Life Gets Gamed
codingconduct
0
250
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Music & Morning Musume
bryan
47
7.2k
Mind Mapping
helmedeiros
PRO
1
250
The SEO Collaboration Effect
kristinabergwall1
1
490
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
350
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Transcript
∞-former: Infinite Memory Transformer Pedro Henrique Martins, Zita Marinho, André
F. T. Martins ACL 2022 お茶大 村山友理
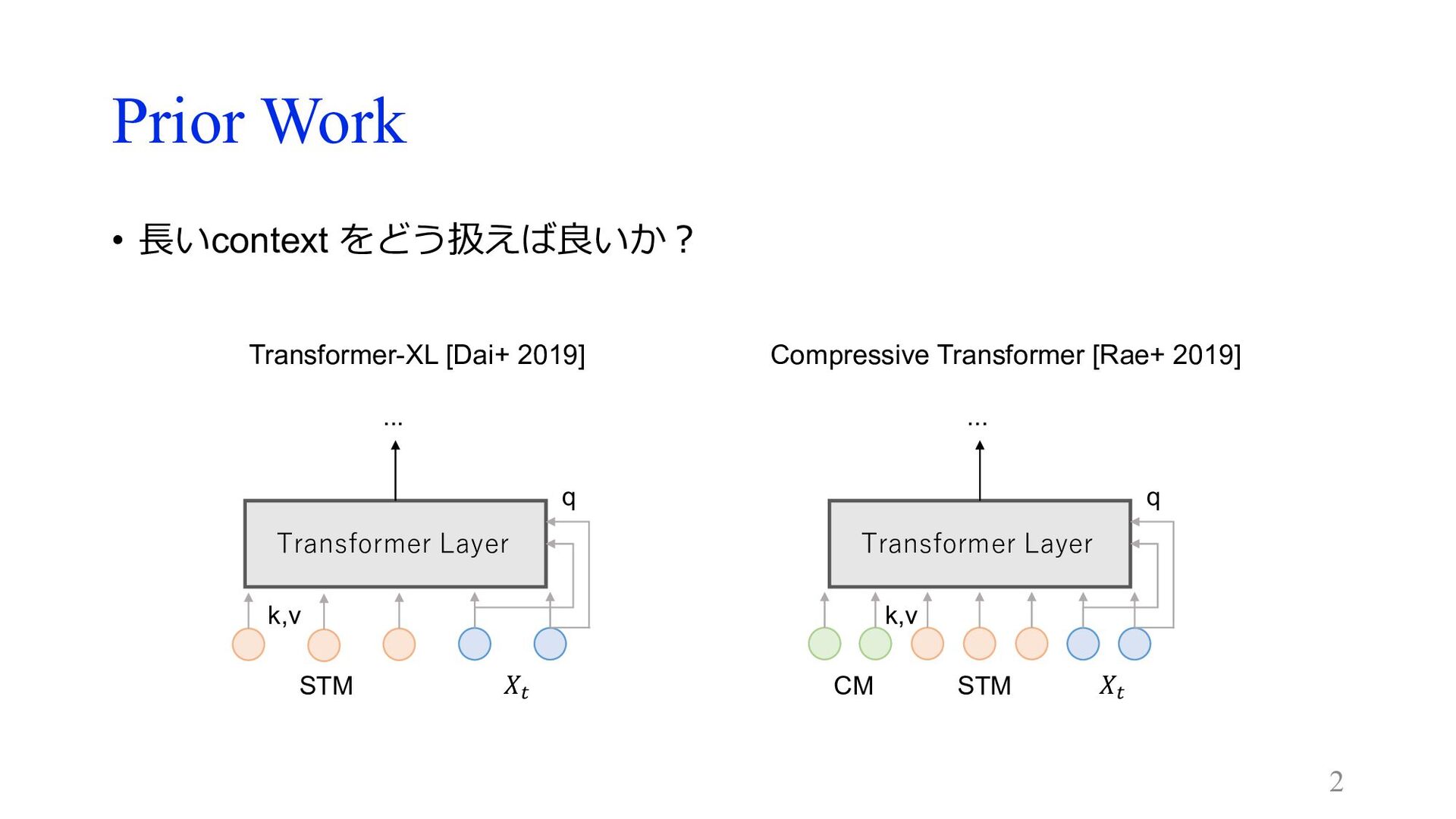
Prior Work • ⻑いcontext をどう扱えば良いか︖ 2 Transformer Layer 𝑋! STM
q k,v ... Transformer Layer 𝑋! STM CM q k,v ... Compressive Transformer [Rae+ 2019] Transformer-XL [Dai+ 2019]
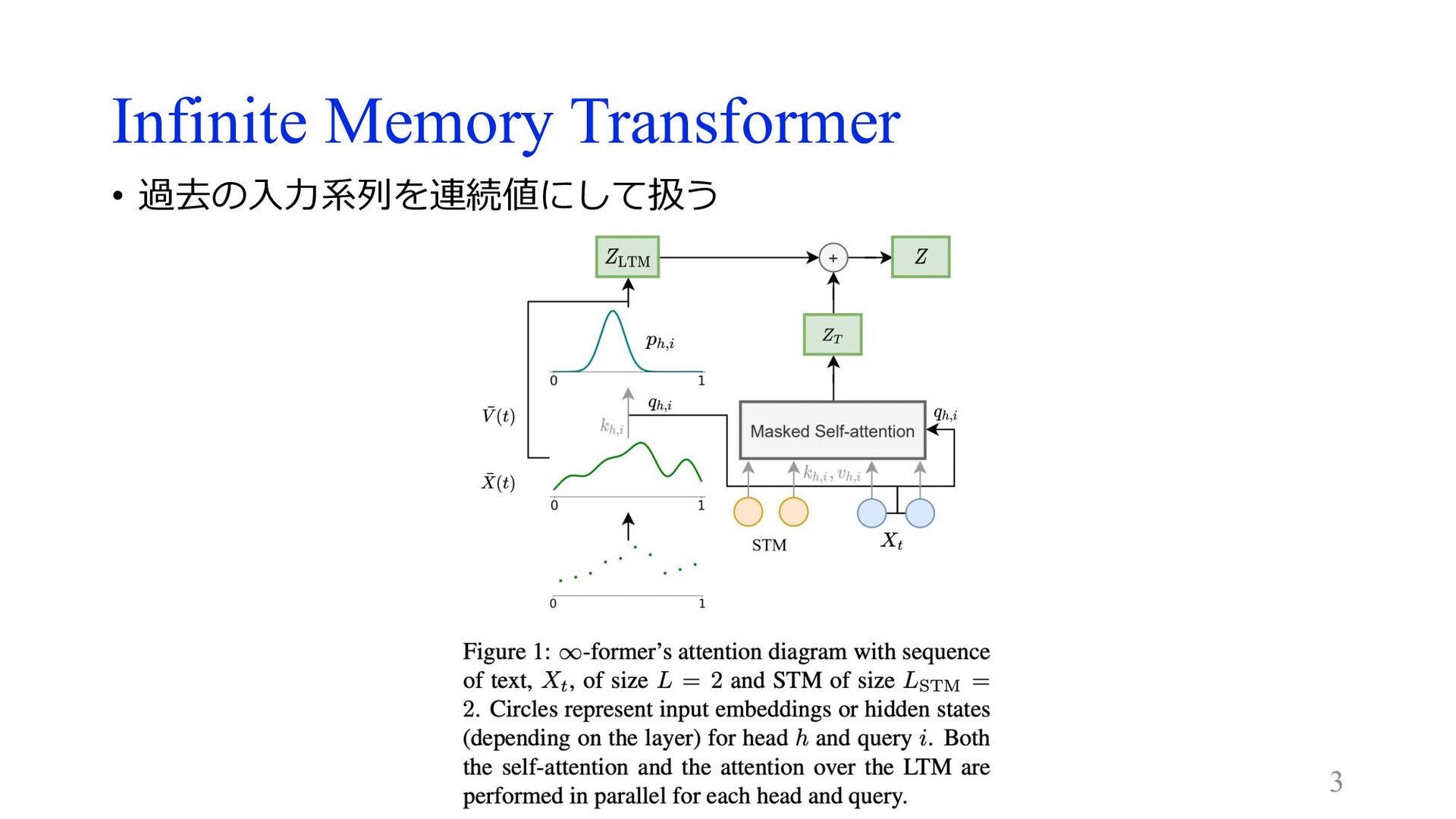
Infinite Memory Transformer • 過去の⼊⼒系列を連続値にして扱う 3
Long-term Memory • ⼊⼒Xに畳み込み(stride=1, width=3)をし、スムージングを⾏う Lはinput size, eはembedding size •
Xを連続値 ! 𝑋(𝑡)に変換 𝑡 ∈ 0, 1 : 𝑡! = 𝑖/𝐿 𝜓 𝑡 ∈ ℝ"はN個のRBF (radial basis function) のベクトル B ∈ ℝ"×$は多変量リッジ回帰によって得られる係数⾏列 4
Long-term Memory 𝑄 = 𝑋𝑊" ∈ ℝ#×% 𝐾 = 𝐵𝑊&
∈ ℝ'×% 𝑉 = 𝐵𝑊( ∈ ℝ'×% • attention mechanism としてガウス分布を⽤いる 5
Long-term Memory • 𝑧),+ は𝑍#,-,) ∈ ℝ#×.の⾏を成す • Transformerのcontext vector
𝑍, と⾜し合わせて最終的なcontext vector 𝑍を得る 6 ← attention × value
Unbounded Memory 7 • ! 𝑋(𝑡)を圧縮 • ! 𝑋(𝑡)から𝑀個のベクトルを等間隔にサンプリング
Sticky Memories • 重要な部分のメモリを積極的に保存したほうが良いのでは︖ • 前ステップのattentionからヒストグラムを作成し、D個の等間隔なbinに分割 {𝑑/, … , 𝑑0}
• 各binについてattention probability 𝑝(𝑑1 )を計算 • 𝑝に従ってM個をサンプリング 8
Complexity • Key matrix 𝐾 は基底関数の数𝑁 だけに依存し、contextの⻑さとは無関係 • Complexityもcontextの⻑さとは独⽴ •
short-term memory も使う場合︓ • LTMのみの場合︓ • どちらもvanilla transformer より⼩さい 9
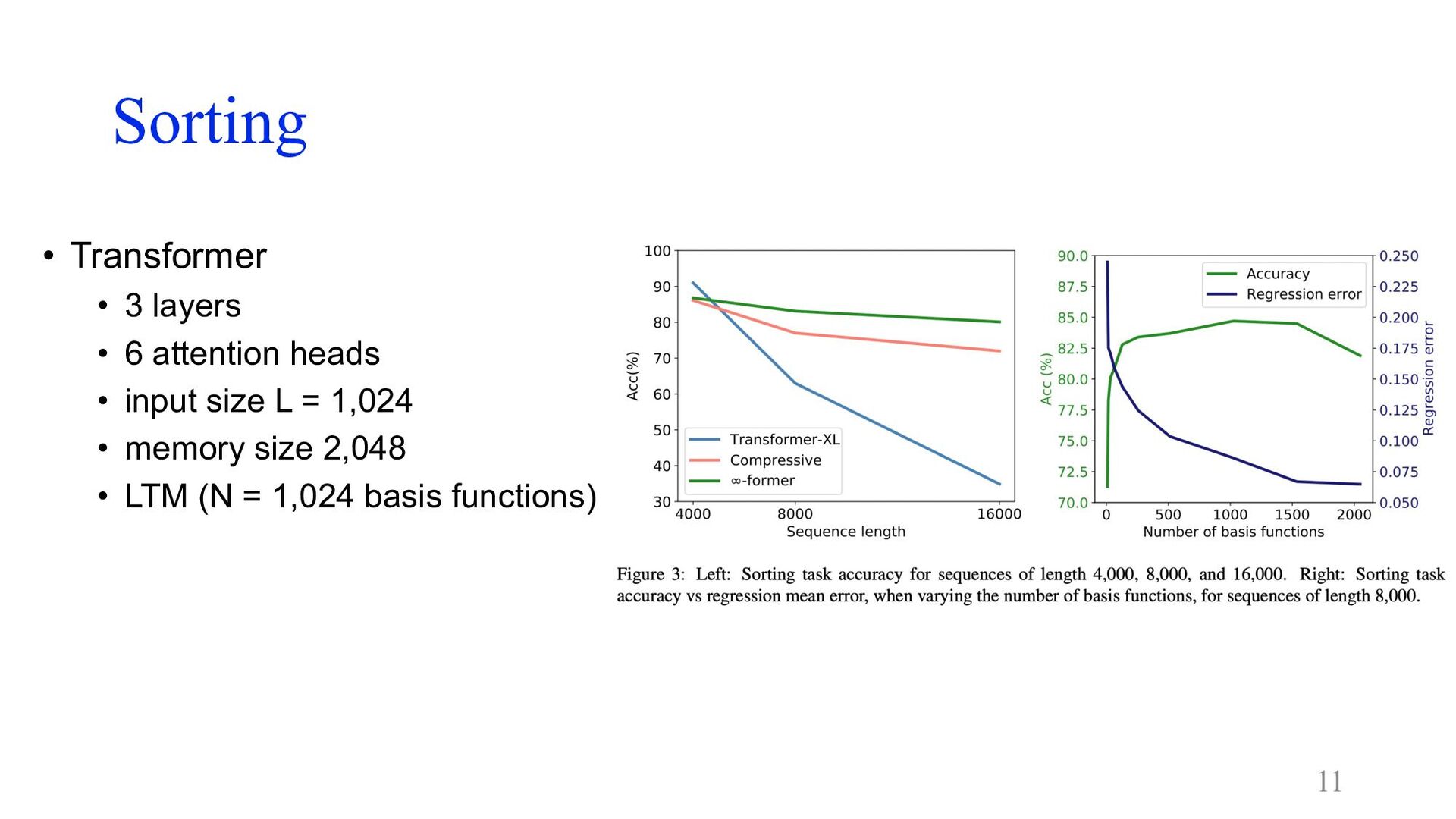
Sorting • 系列のトークンを頻度順に並べる • モデルが直近のトークンだけでなく⻑期記憶も⾒ているか調べるために、 トークンの確率分布を変化させていく • 系列が⻑くなるほど𝛼 ∈ [0,1]は0から1に徐々に増加
• vocabulary size 20 • 4,000, 8,000, 16,000トークンで実験 10
Sorting • Transformer • 3 layers • 6 attention heads
• input size L = 1,024 • memory size 2,048 • LTM (N = 1,024 basis functions) 11
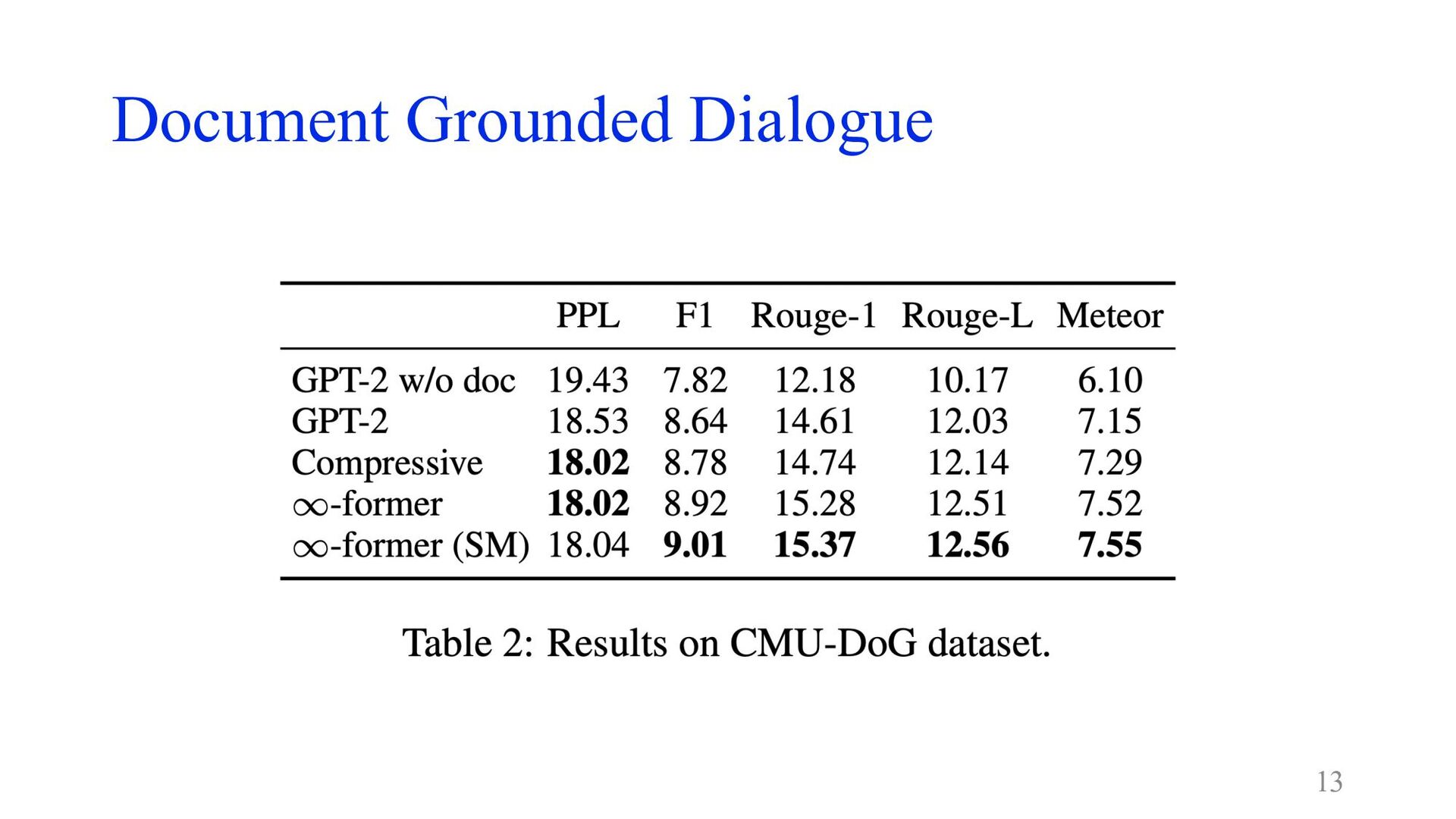
Document Grounded Dialogue • CMU Document Grounded Conversation dataset (CMU-DoG)
[Zhou+ 2018] • より難しくするために、会話が始まる前にしかdocumentにアクセスできなくする • GPT-2 small + continuous LTM (N = 512 basis functions) 12
Document Grounded Dialogue 13
Document Grounded Dialogue 14
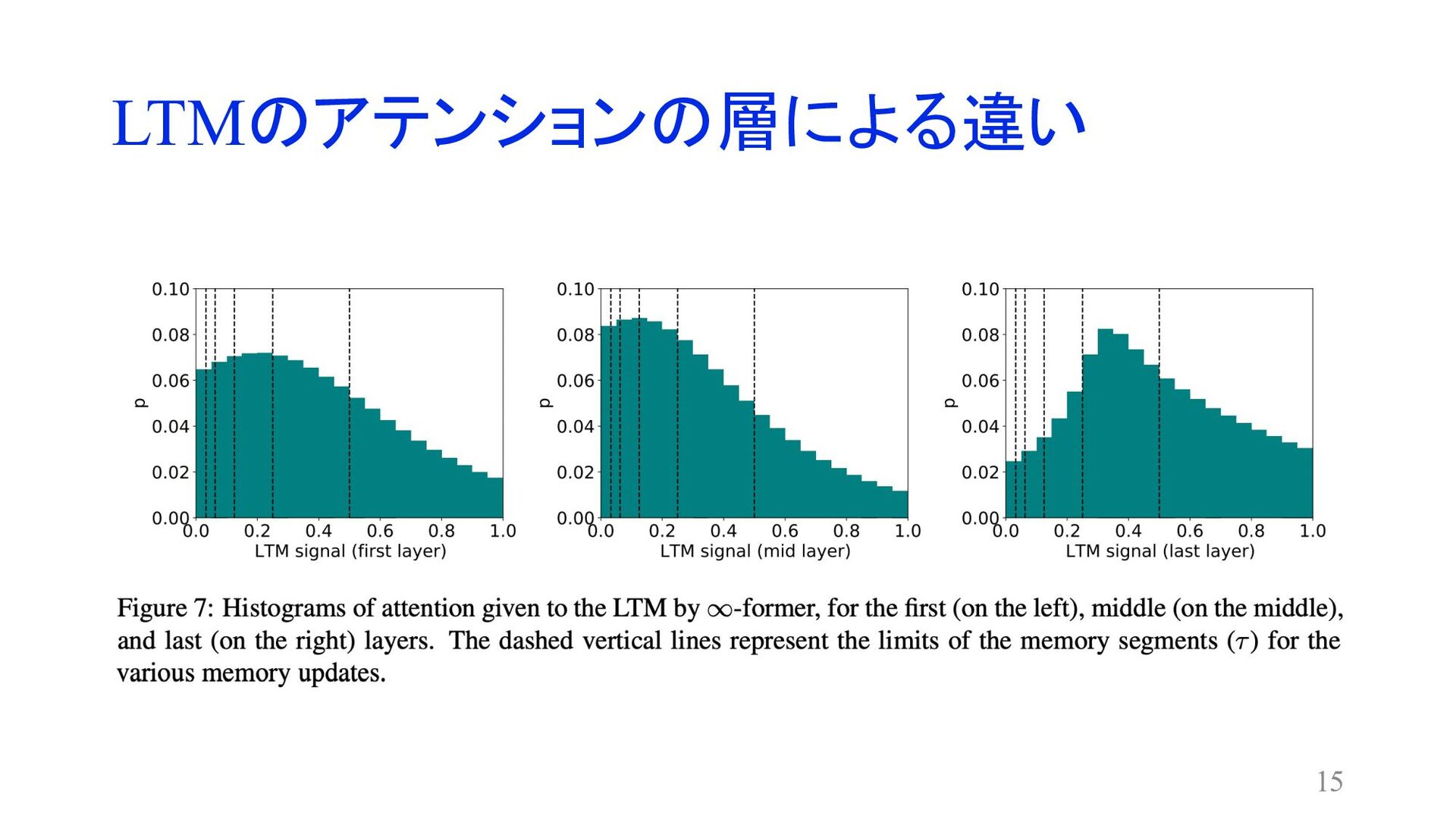
LTMのアテンションの層による違い 15
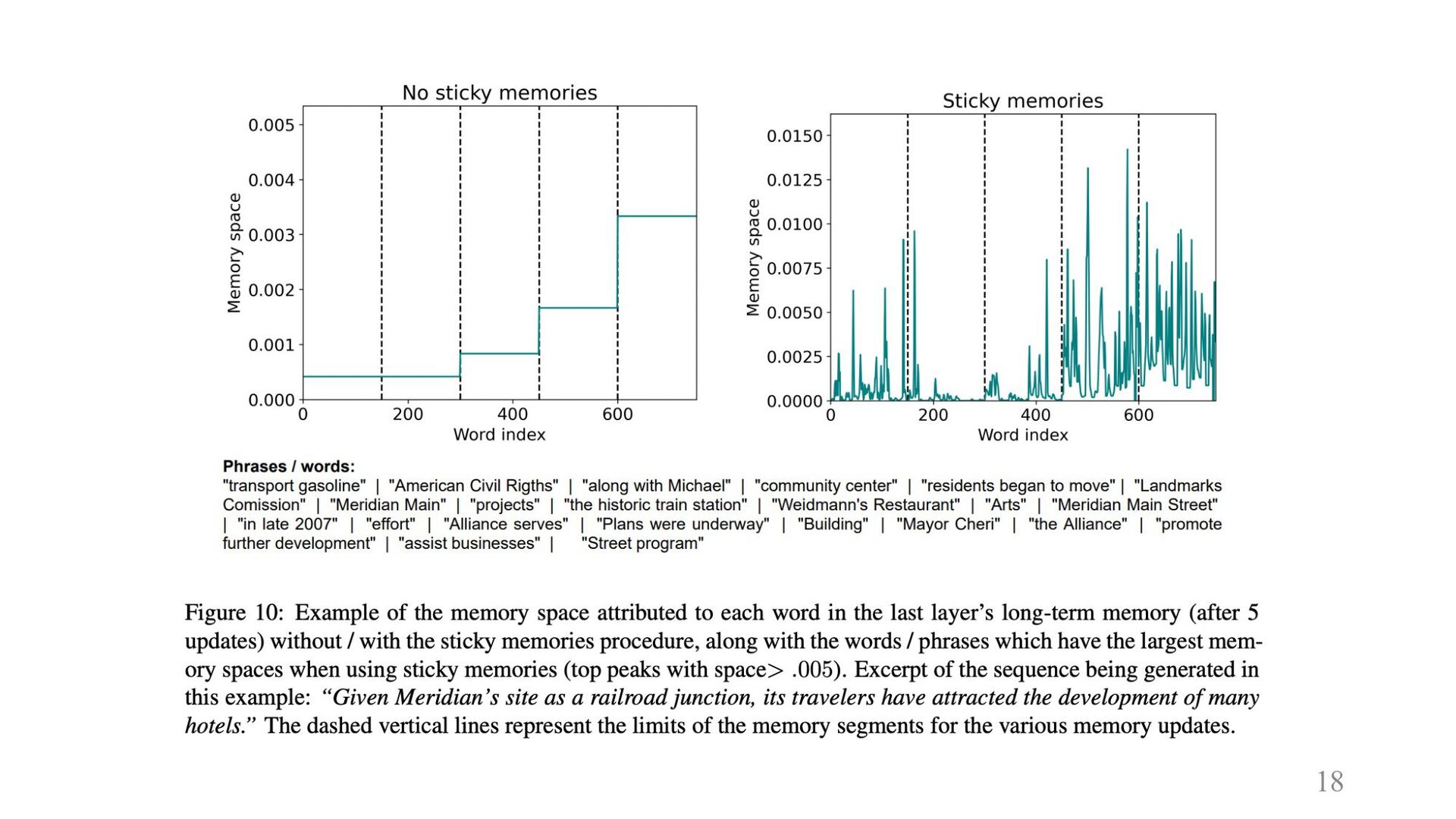
16
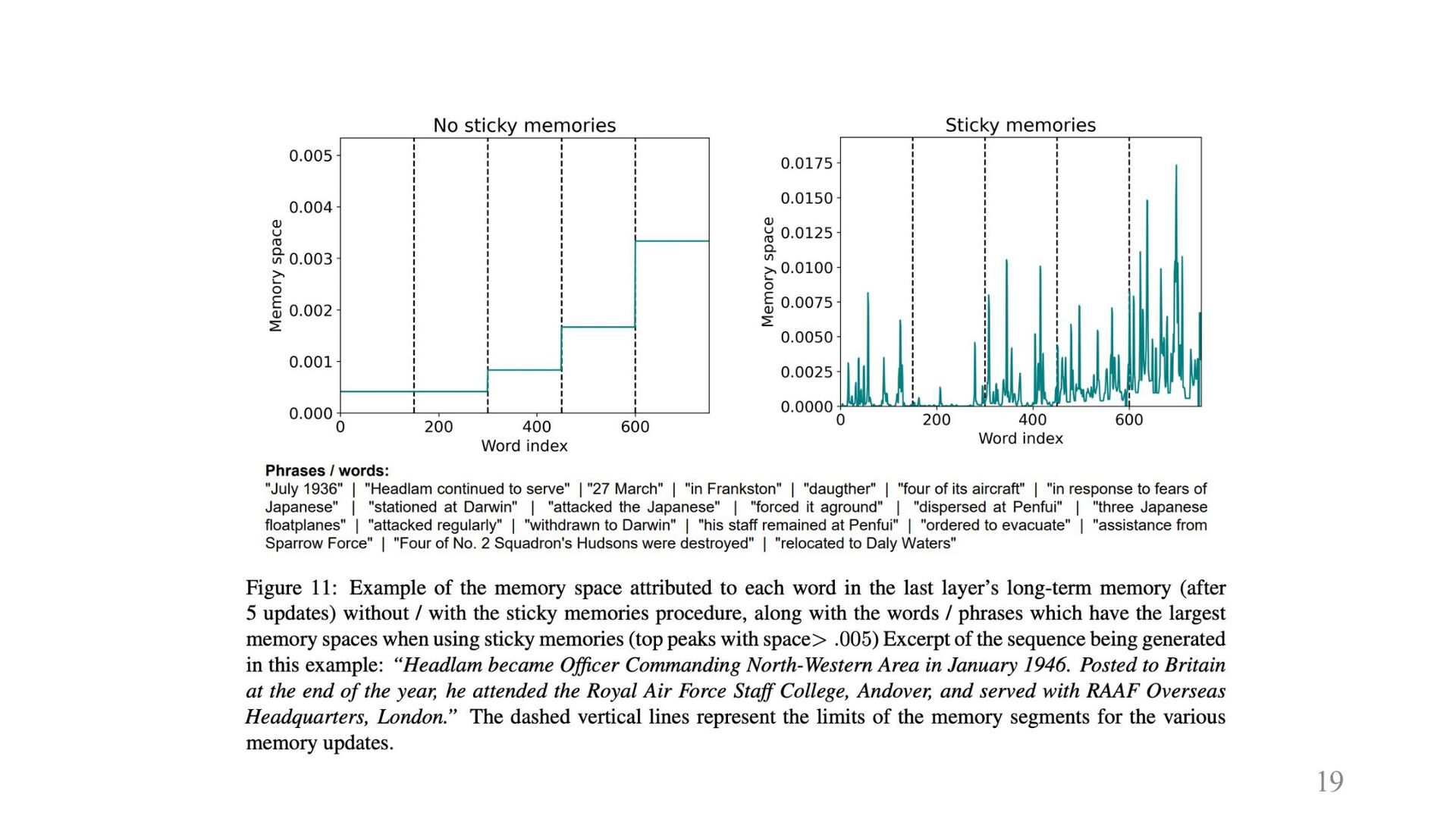
17
18
19
まとめ • Infinite Memory Transformer を提案 • Unbounded context •
計算量はcontextの⻑さと独⽴ • Sorting, Language modeling, Document grounded dialogue で実験 • ⻑期記憶の有⽤性を⽰した 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sorting • 系列のトークンを頻度順に並べる • モデルが直近のトークンだけでなく⻑期記憶も⾒ているか調べるために、 トークンの確率分布を変化させていく • 系列が⻑くなるほど𝛼 ∈ [0,1]は0から1に徐々に増加](https://files.speakerdeck.com/presentations/f290c7a292524520a803a7e1eb035490/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}