The New Playbook for AEO Content in 2026: How to Get Your Brand Chosen as the Answer
As search evolves from “10 blue links” to AI-generated answers, the biggest opportunity for marketers isn’t just ranking—it’s becoming the source AI systems trust and cite. In this session, you’ll learn how to optimize your content for Relevance Engineering/Answer Engine Optimization (AEO) by aligning with how modern AI platforms discover, interpret, and reuse information.
Designed for content teams and marketers, this talk focuses on practical strategies to make your pages more “answer-ready.” We’ll explore how AI evaluates content at the passage level, why chunking and structure matter more than ever, and how marketers can create content that performs well across synthetic fan-out queries (the many follow-up questions AI generates behind the scenes). You’ll also learn how semantic relationships and “triples” help AI connect your brand to the topics that matter most.
Attendees will walk away with a clear framework for building content that is not only searchable—but usable in the next generation of AI-driven discovery.
Key Takeaways
How to structure and write content so AI engines can extract the best passages and choose your brand as the answer.
A marketer-friendly approach to passage relevance, chunking, and embedding-driven optimization without needing to be an engineer.
How to explore fan-out queries and build content ecosystems that anticipate the questions AI will ask next.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TARGETING [MACHINE LEARNING] AND [DATA PRIVACY] HERE’S AN ORIGINAL PARAGRAPH](https://files.speakerdeck.com/presentations/c161adc422954294b020b8d58bc27cc9/slide_46.jpg){kind=link}
![TARGETING [MACHINE LEARNING] AND [DATA PRIVACY] NOW I JUST SPLIT](https://files.speakerdeck.com/presentations/c161adc422954294b020b8d58bc27cc9/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
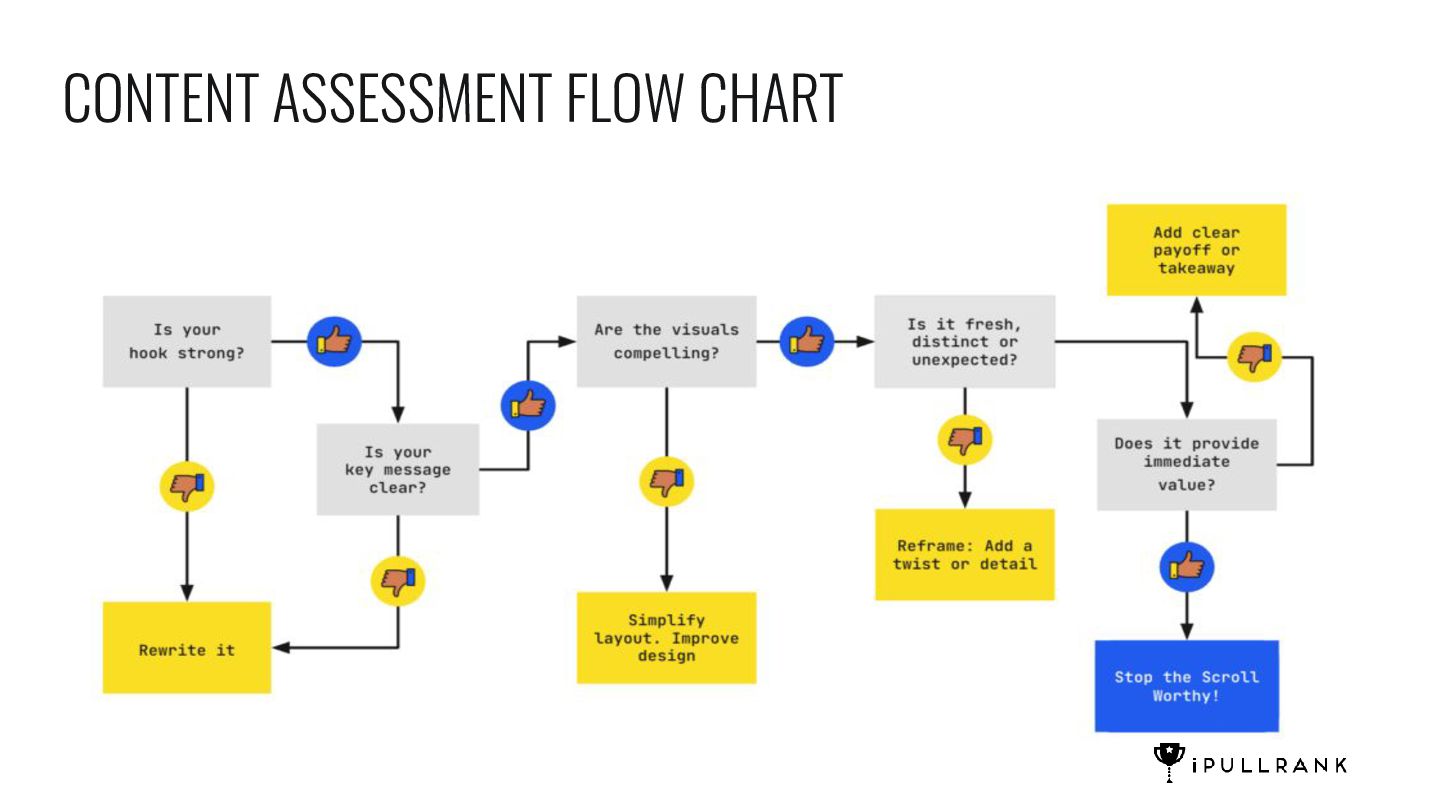{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}