COVID-19パンデミック時の共和党と民主党の過剰死亡率 (原文: Excess death rates for Republicans and Democrats during the COVID-19 pandemic) 3. AIで未来を予測する:指数関数的に成長する知識ネットワークにおける高品質なリンク予測 (原文: Predicting the Future of AI with AI: High-quality link prediction in an exponentially growing knowledge network) 4. ポアソンフロー生成モデル (原文: Poisson Flow Generative Models) 5. 人間の規則的な強化学習とプランニングによって、ノープレス外交ゲームをマスターする (原文: Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning) 6. 人間の規則的な探索と学習による人間とAIの協調 (原文: Human-AI Coordination via Human-Regularized Search and Learning) 7. Imagic: 拡散モデルによるテキストベースの実画像編集 (原文: Imagic: Text-Based Real Image Editing with Diffusion Models) 8. DiffDock:分子ドッキングのための拡散ステップ、ツイスト、そしてターン (原文: DiffDock: Diffusion Steps, Twists, and Turns for Molecular Docking) 9. PDEBENCH: 科学的機械学習のための広範なベンチマーク (原文: PDEBENCH: An Extensive Benchmark for Scientific Machine Learning) 10.フォールディング拡散による蛋白質構造生成 (原文: Protein structure generation via folding diffusion)
to play Hanab, a cooperative card game of logic and reasoning. https://github.com/Hanabi-Live/hanabi-live • Hanabiはテーブルの上にカードを順番に並べ、完璧な花火を作り上げる協力なゲーム(日本語の花火に由来) • 実験ではHANAB LIVEを使用 • HANAB LIVEはオンラインで協力的なカードゲームをプレイすることができるサイト • GitHub上でコードが公開されている
{kind=link}
{kind=link}
{kind=link}
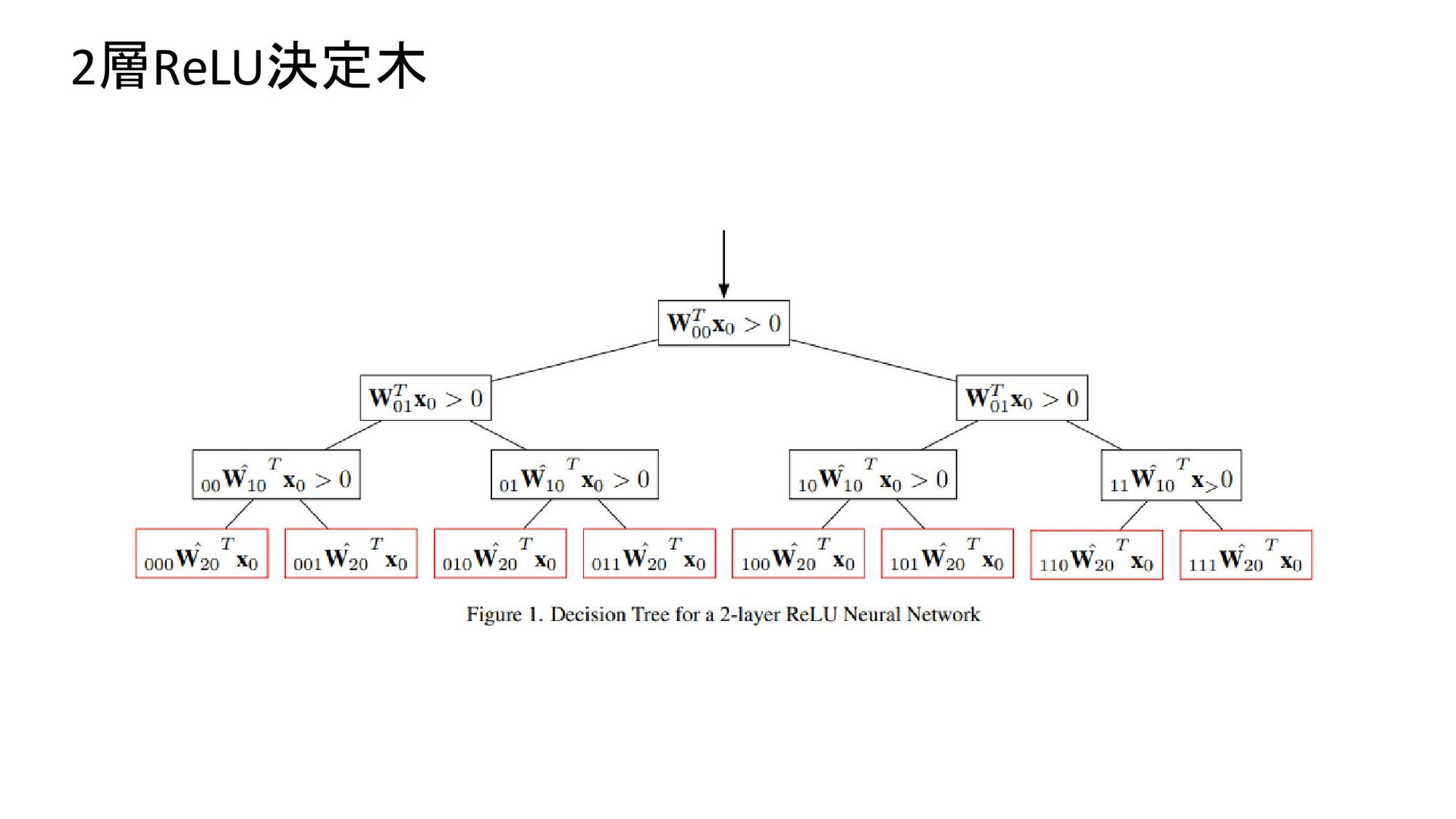{kind=link}
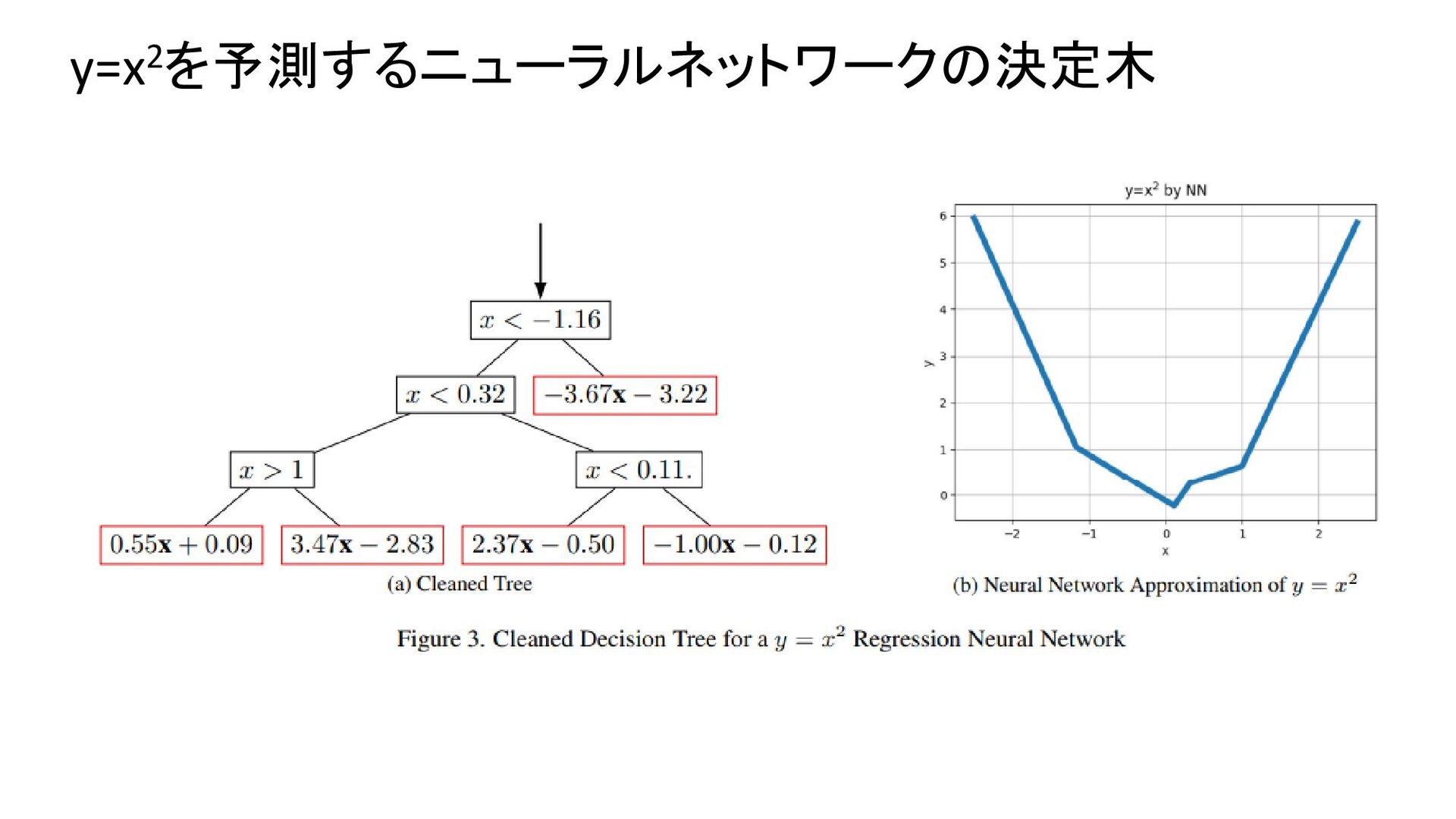{kind=link}
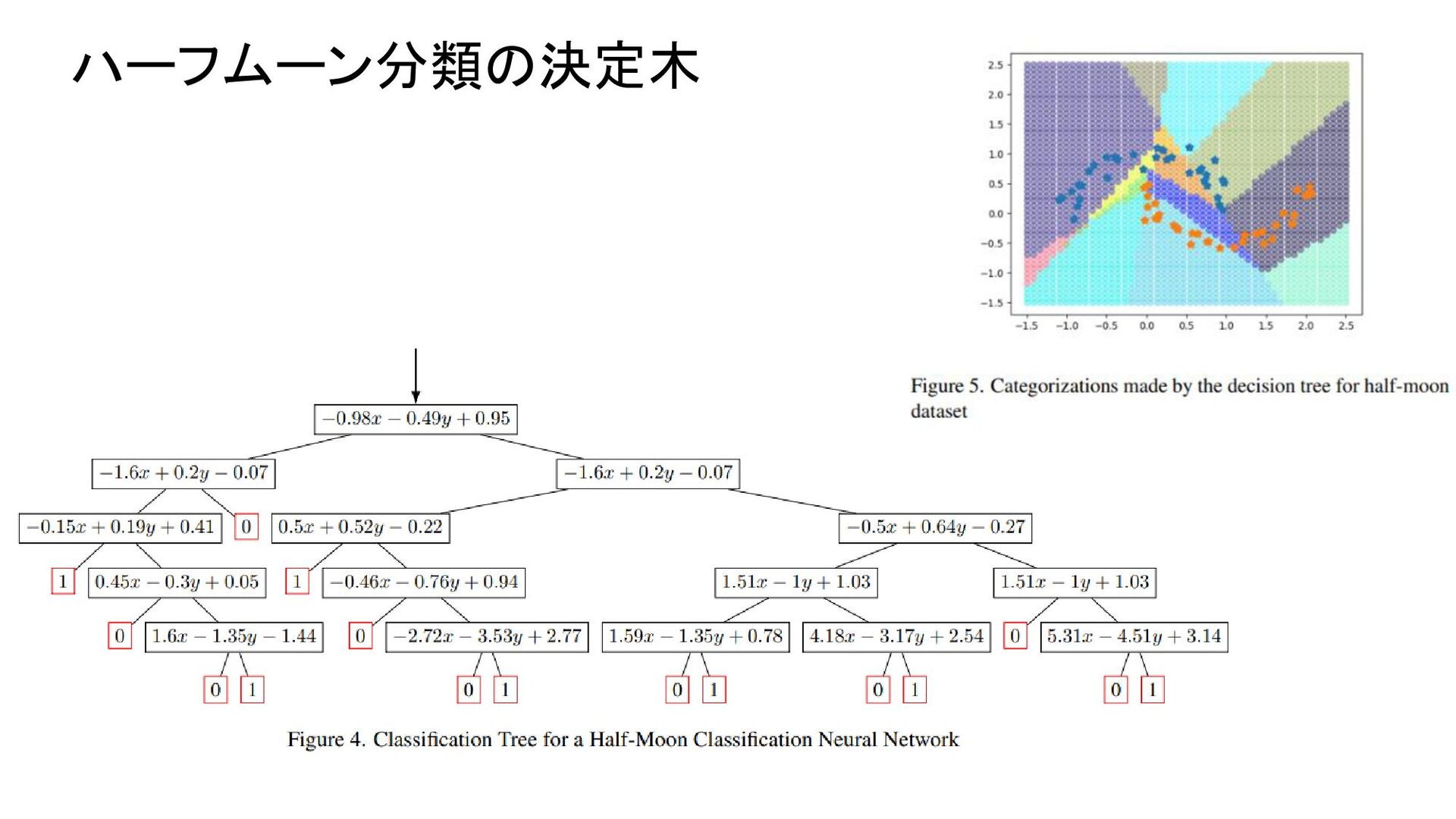{kind=link}
{kind=link}
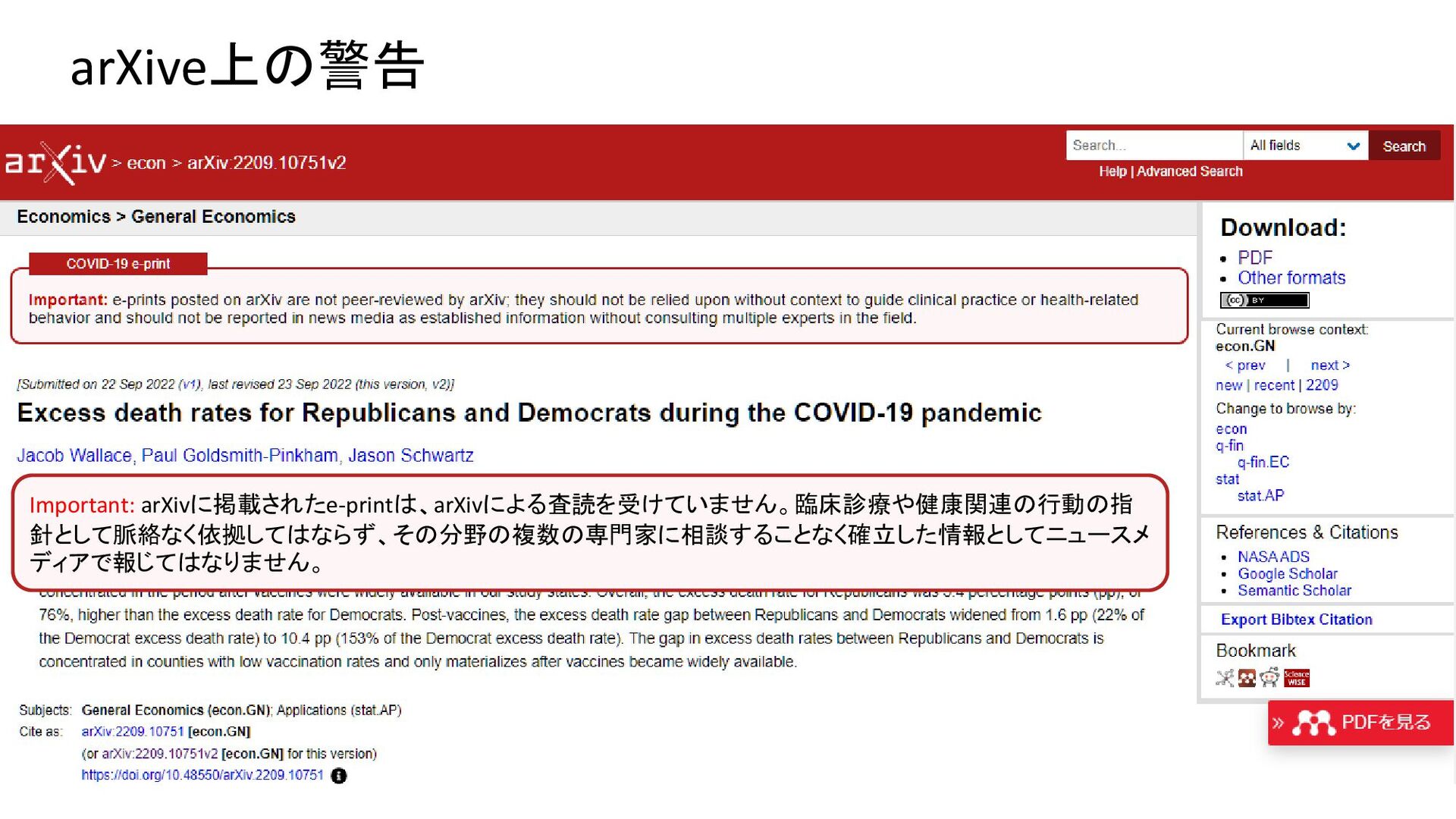{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}