Zero-Shot Hyperparameter Transfer) 2.知的な意思決定者の共通モデルの探求 (原文:The Quest for a Common Model of the Intelligent Decision Maker) 3.キューブリック スケーラブルなデータセット生成ツール 【pickup】 (原文:Kubric: A scalable dataset generator) 4.ディープネット: トランスフォーマーを1,000層まで拡張する (原文:DeepNet: Scaling Transformers to 1,000 Layers) 5.スパース全MLPによる効率的な言語モデリング (原文: Efficient Language Modeling with Sparse all-MLP ) 6.人工知能の数学 (原文: The Mathematics of Articial Intelligence ) 7.ブロック・リカレント・トランスフォーマー (原文: BLOCK-RECURRENT TRANSFORMERS ) 8. GAN (原文: Generative Adversarial Network ) 9.モデルスープ:複数の微調整されたモデルの重みを平均化することで、推論時間を増やすことなく精度を向上させることができる (原文: Model soups: averaging weights of multiple ne-tuned models improves accuracy without increasing inference time ) 10.表形式ディープラーニングにおける数値特徴のエンベッディングについて (原文: On Embeddings for Numerical Features in Tabular Deep Learning ) PaperWithCodeの10本を紹介 https://megalodon.jp/2022-0326-1516-40/https://paperswithcode.com:443/top-social?num_days=30
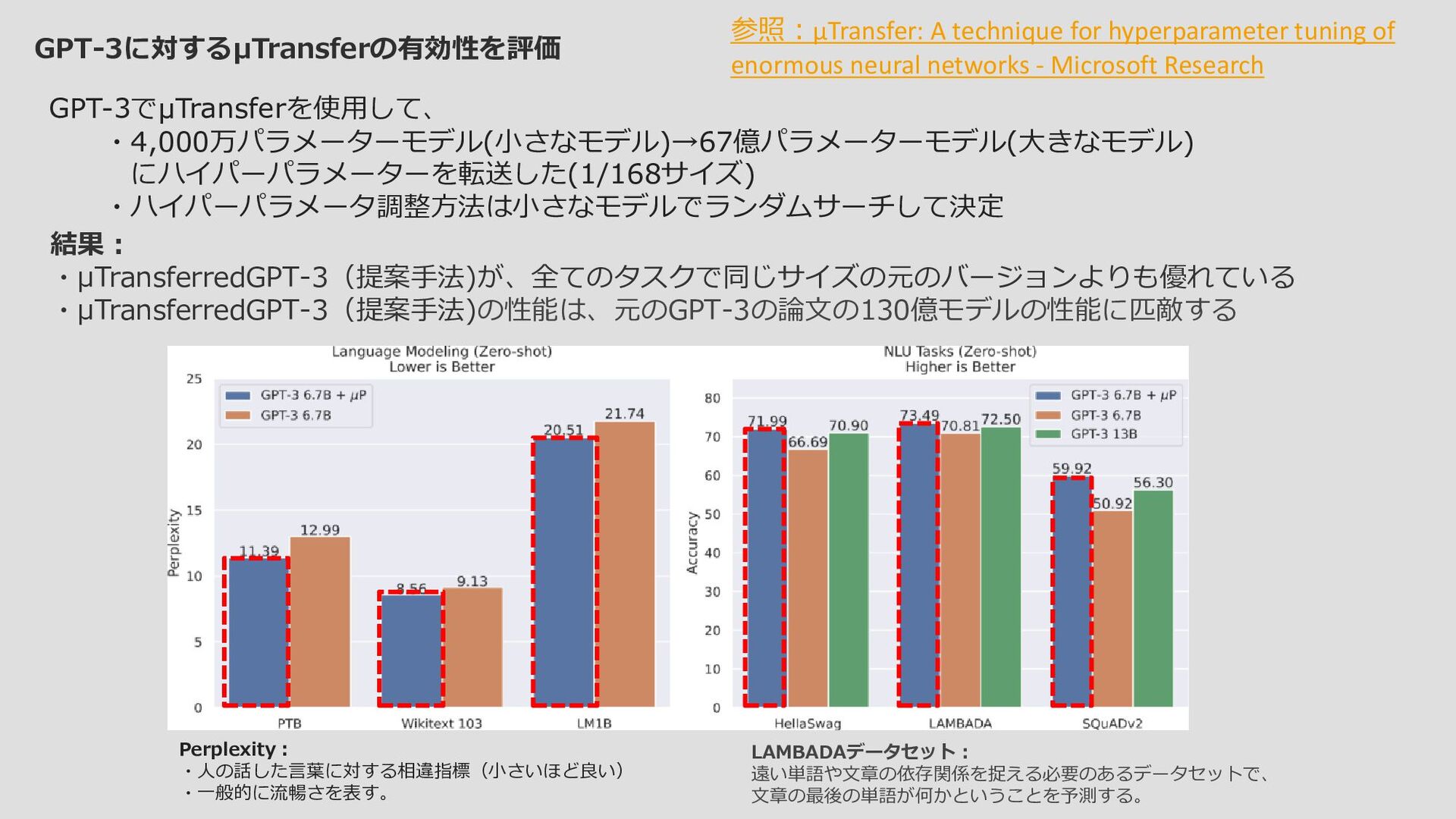
文章の最後の単語が何かということを予測する。 参照:µTransfer: A technique for hyperparameter tuning of enormous neural networks - Microsoft Research Perplexity: ・人の話した言葉に対する相違指標(小さいほど良い) ・一般的に流暢さを表す。
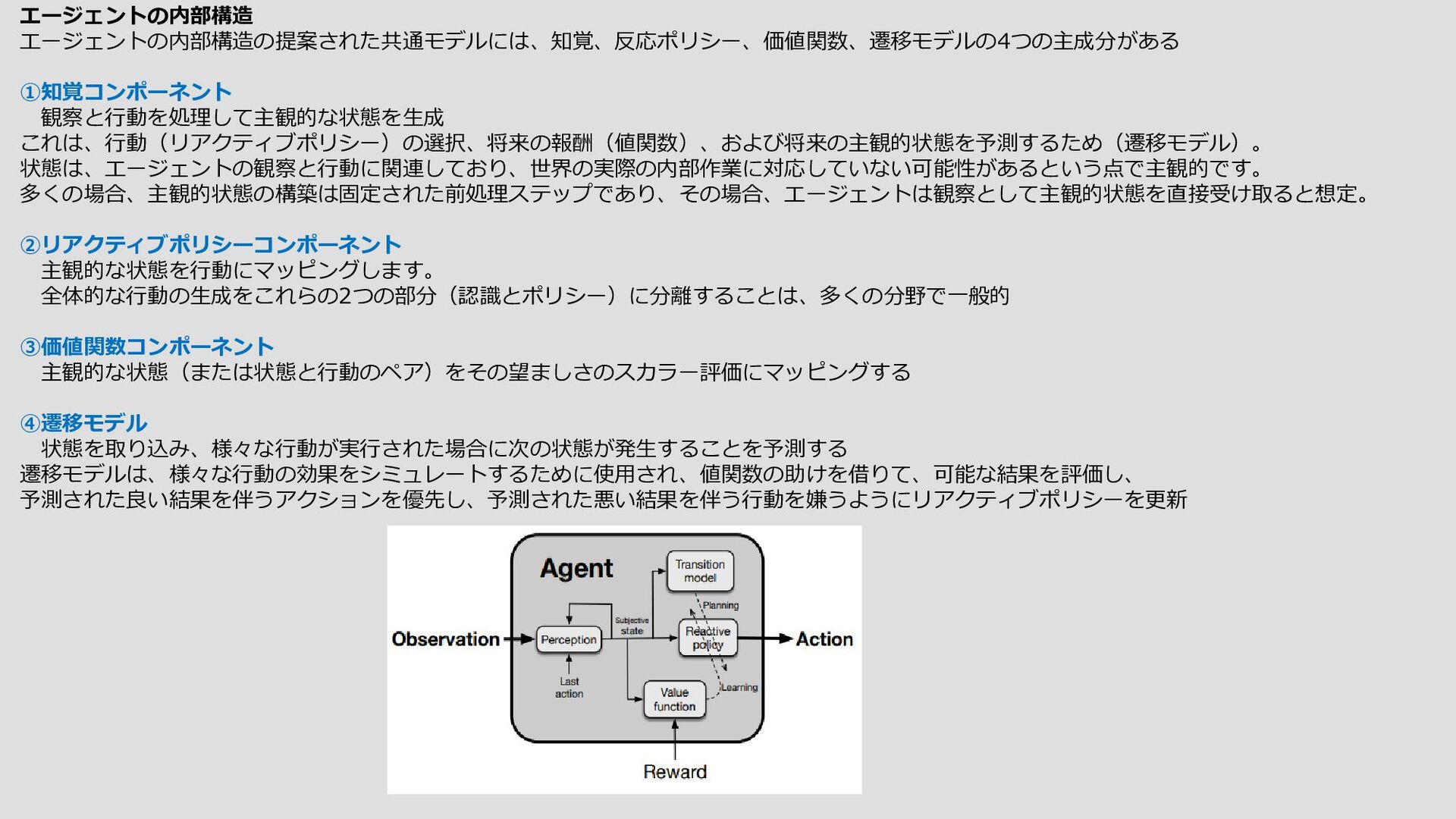
University of Alberta 2.知的な意思決定者の共通モデルの探求 (原文:The Quest for a Common Model of the Intelligent Decision Maker) https://arxiv.org/abs/2202.13252v1 Multi-disciplinary Conference on Reinforcement Learning and Decision Makingの前提は、複数の分野が時間を かけて目標指向の意思決定を行うことに関心を共有していることである。この論文のアイデアは、心理学、人工知能、 経済学、制御理論、神経科学にまたがって実質的で広く保持されている意思決定者の視点(私は「知的エージェント の共通モデル」と呼ぶ)を提案することによって、この前提をより鮮明に、より深くしようというものである。この 共通モデルには、いかなる生物、世界、あるいは応用領域にも固有のものは含まれていない。共通モデルには、意思 決定者とその世界との相互作用(入力と出力、および目標が必要)と、意思決定者の内部構成要素(知覚、意思決定、 内部評価、および世界モデルのための)が含まれる。これらの側面と構成要素を特定し、分野によって異なる名称が 与えられているが、本質的には同じ考えを指していることを指摘し、分野を超えて使用できる中立的な用語を考案す ることの難しさと利点について論じる。今こそ、知的エージェントの実質的な共通モデルに、複数の多様な分野が収 斂していることを認識し、それを基礎に据えるべき時である。
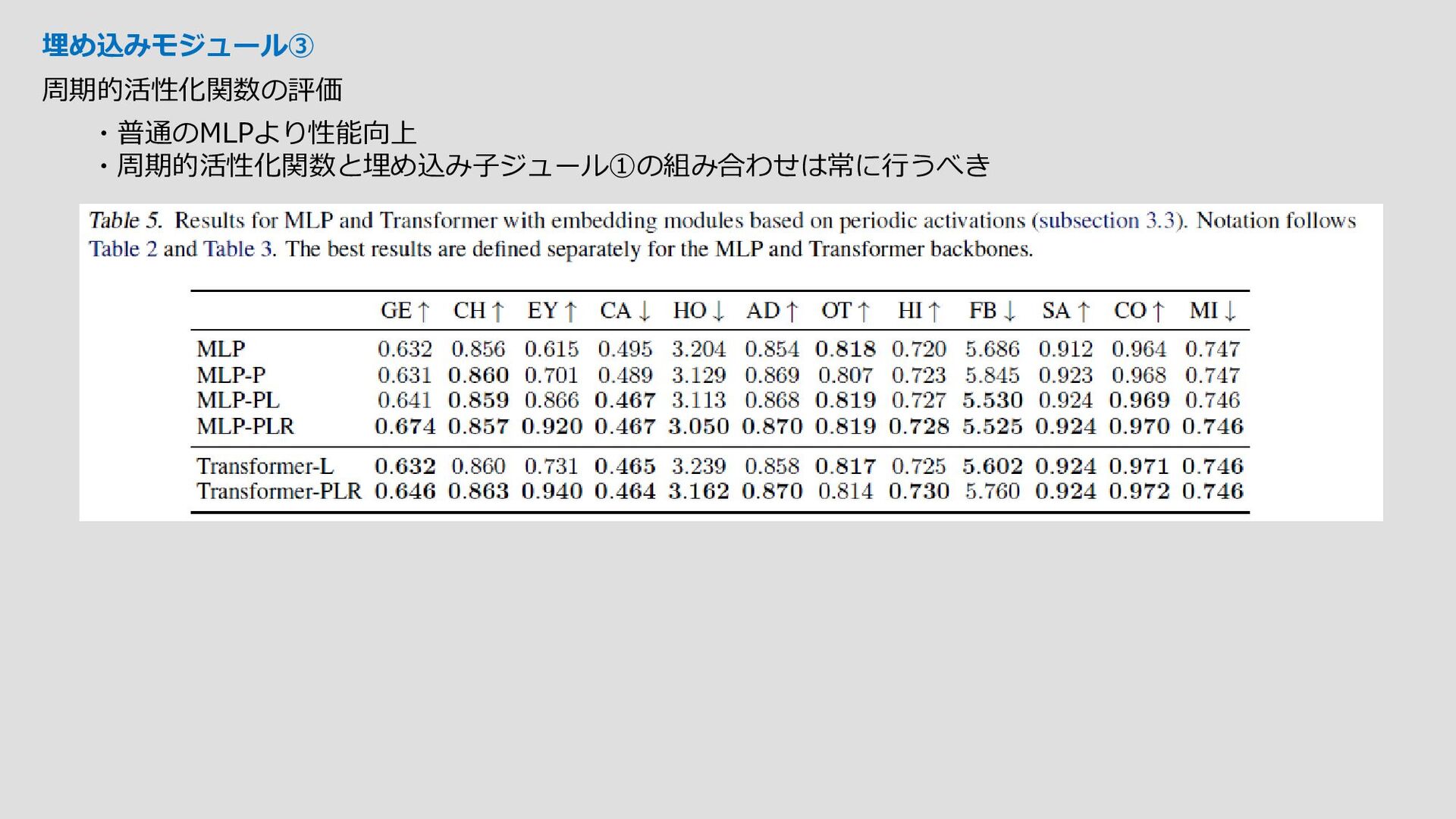
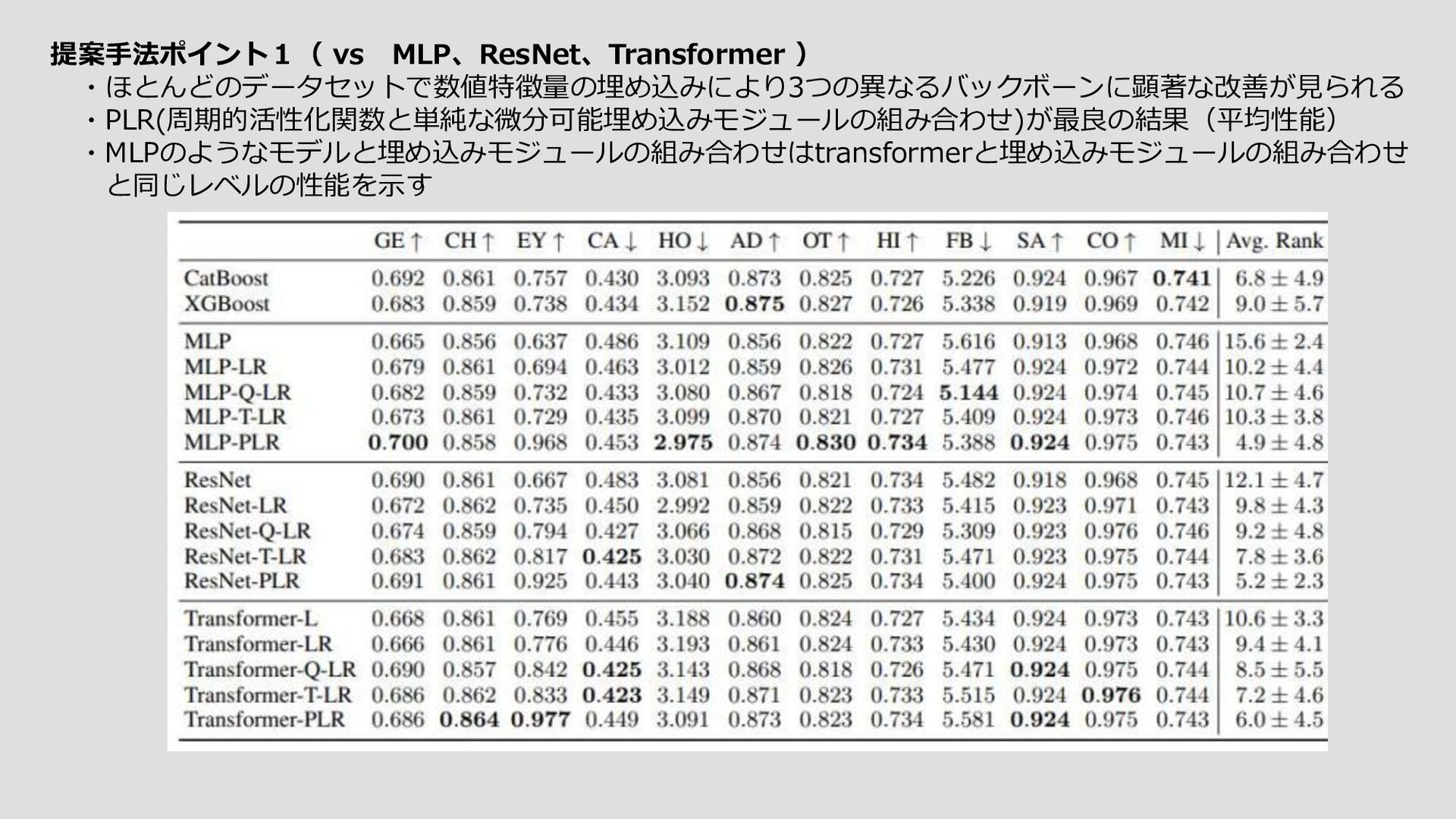
入力構造化データ例 One hot encording カテゴリカル データ 数値データ 特徴量の表現を変えることで Deeplearnigの性能が向上したという 論文にインスパイアされた ☆ポイント 埋め込みモジュールを提案するということが 本論文で力を入れている点である バックボーンのアーキテクチャの探索には力を入れず、 異なるアーキテクチャでも性能の同等レベルに向上できる Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains 推論結果 ①単純な微分可能層 →単純な線形層+活性化関数で構成される 数値データ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
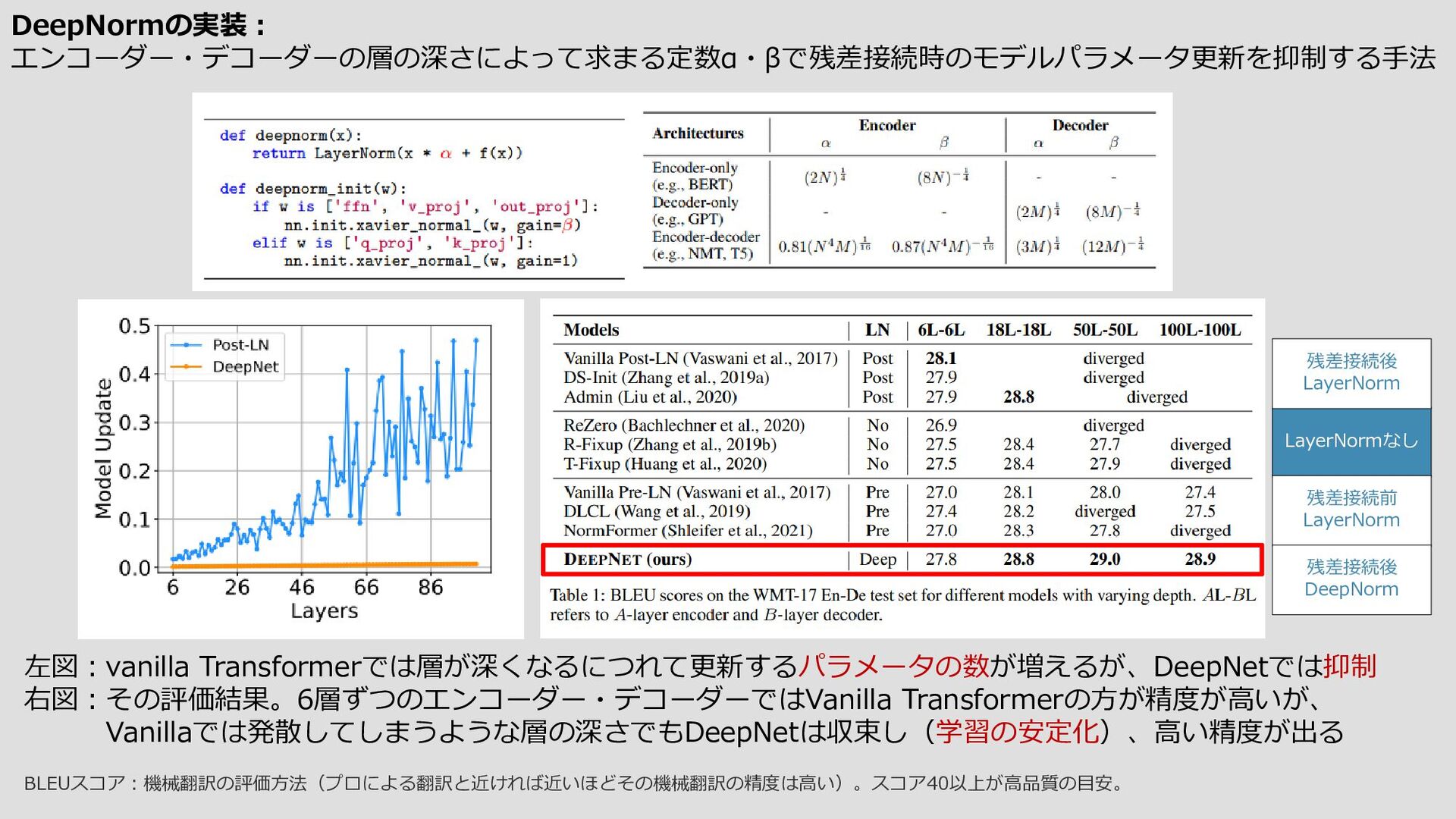{kind=link}
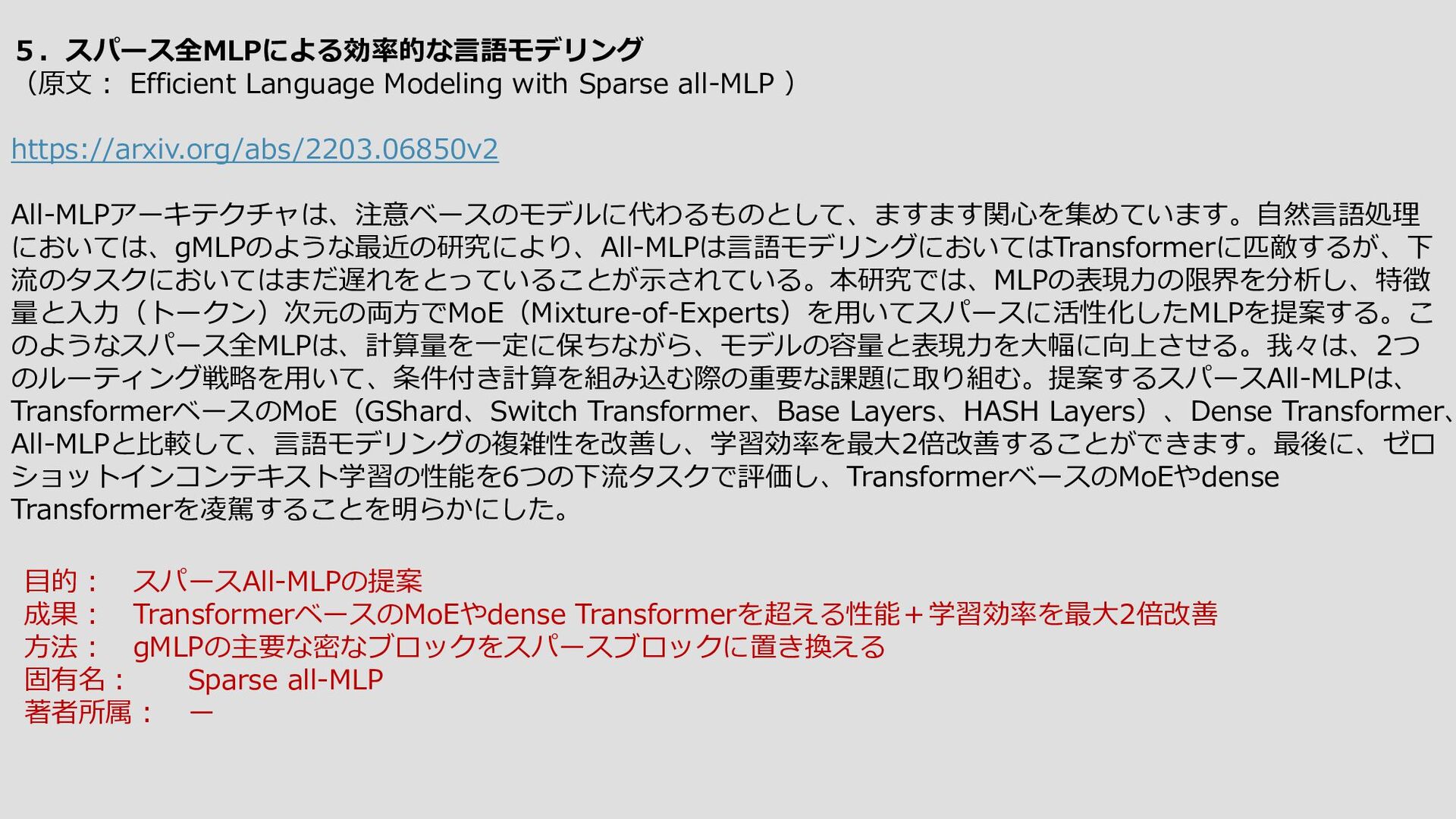{kind=link}
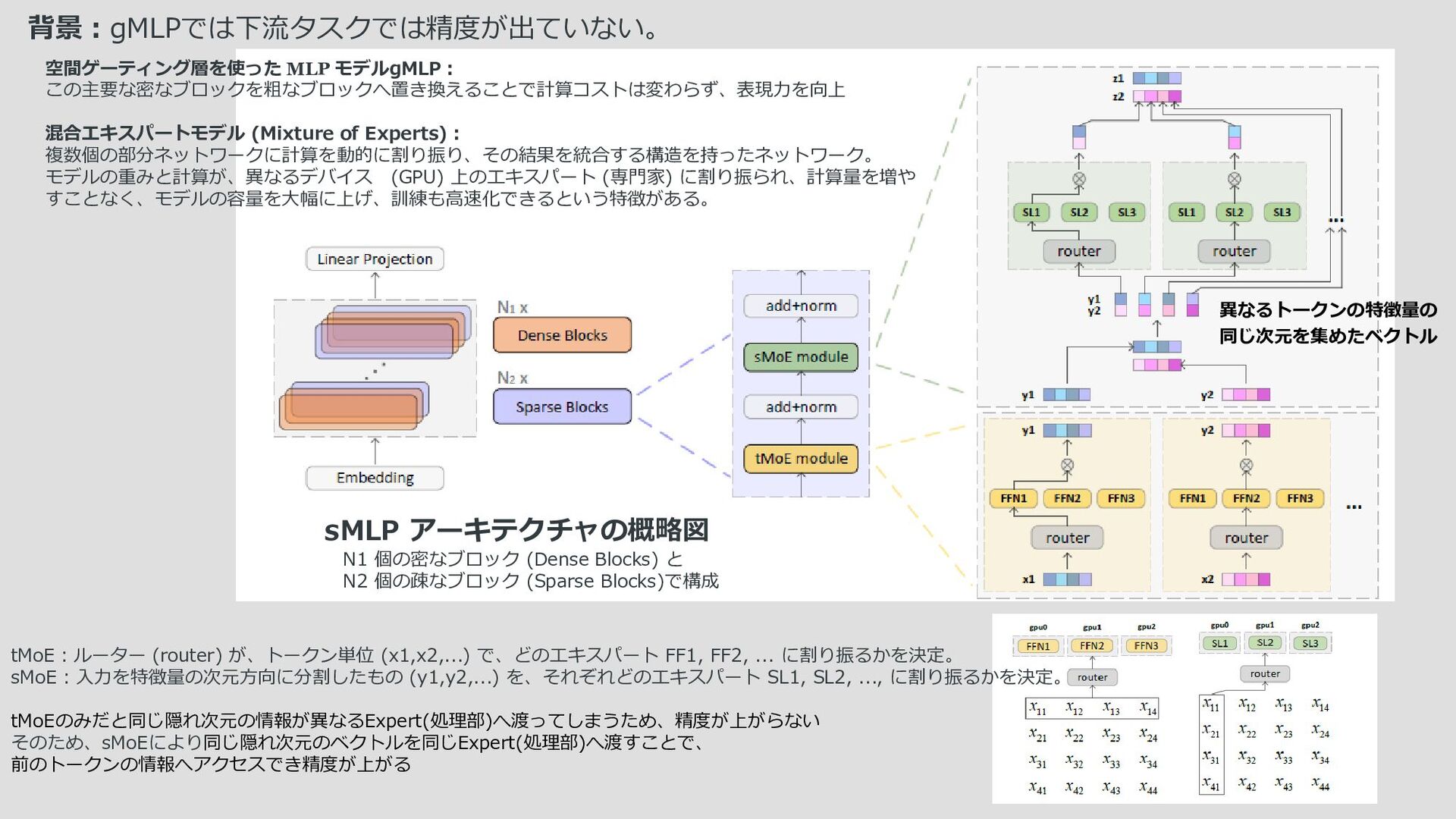{kind=link}
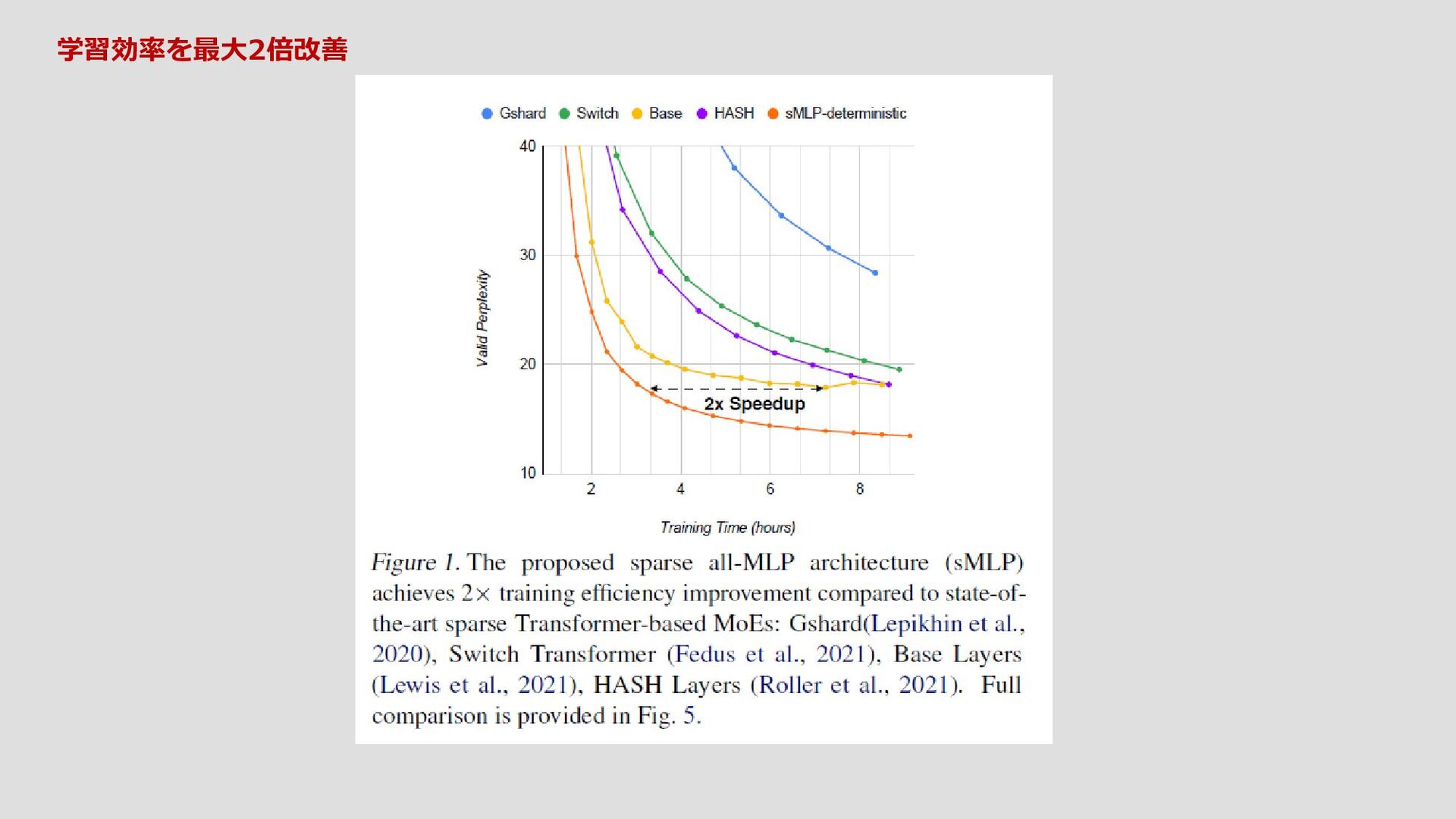{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
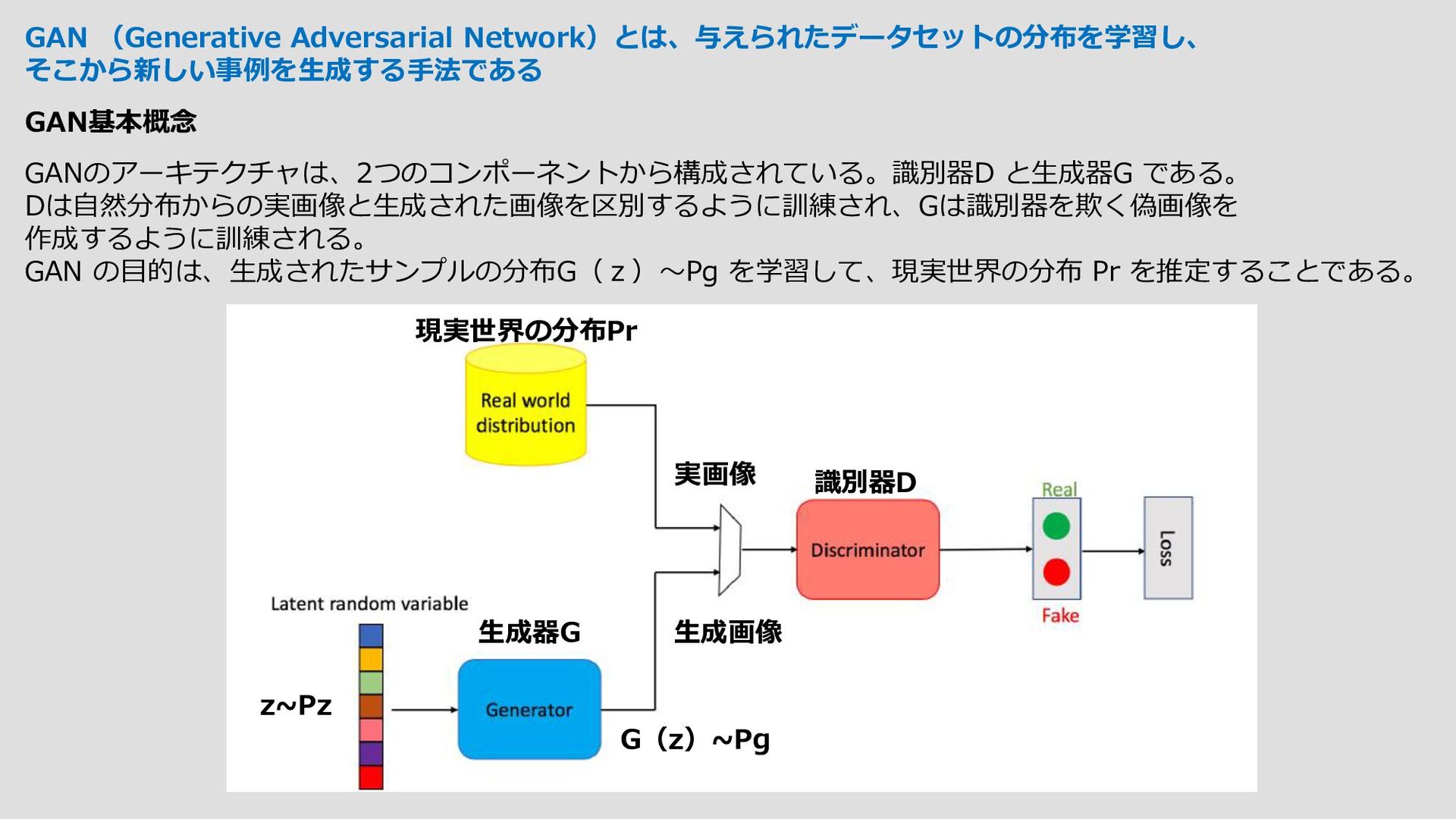{kind=link}
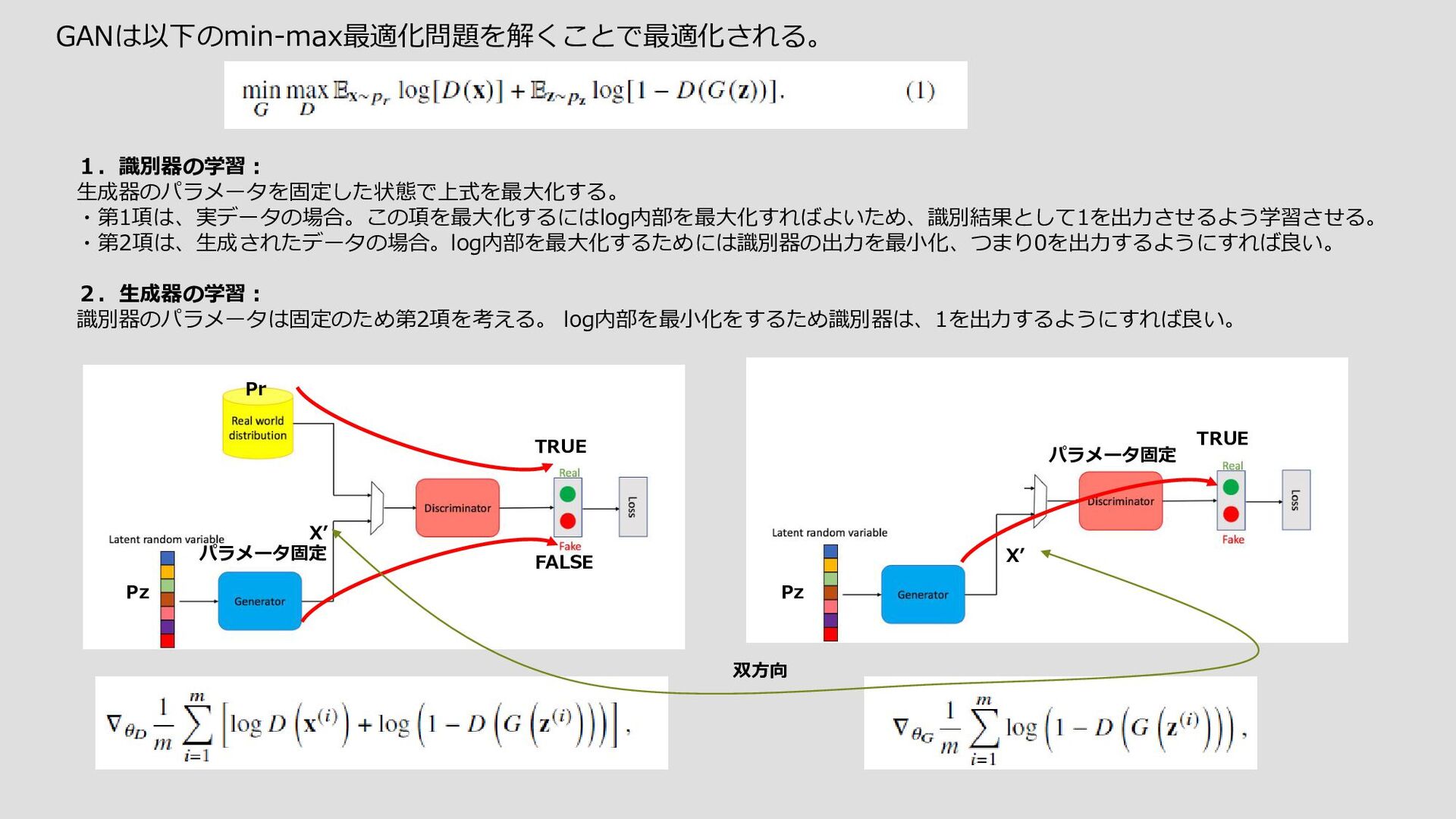{kind=link}
{kind=link}
{kind=link}
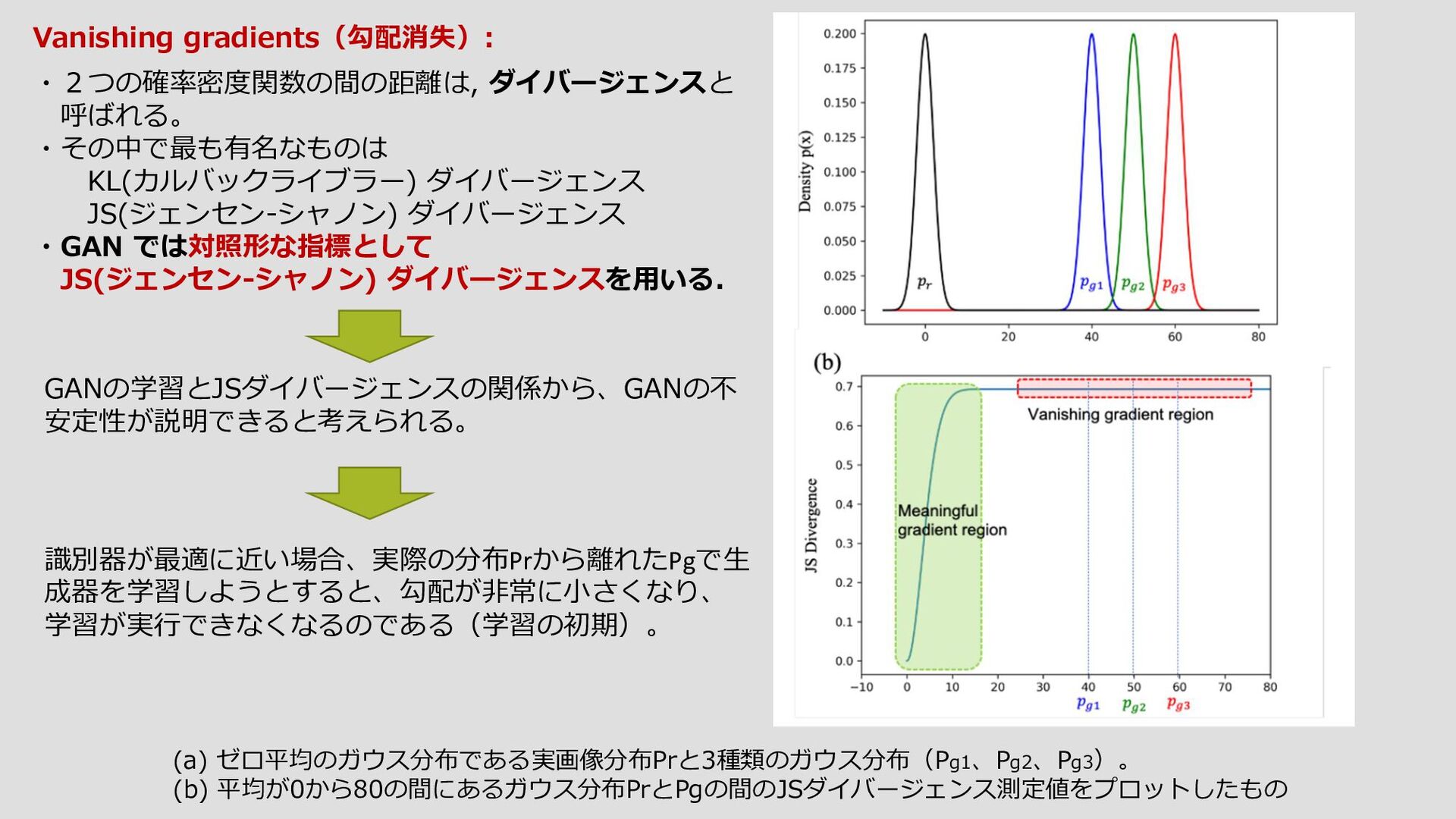{kind=link}
![Instability(不安定): 図5 GANにおける学習の不安定さ。 (a)式(1)の損失を用いたGAN学習におけるJS 距離の指標。この指標は生成された画像の品質 との相関が低く、JS距離がとる最高値であるlog2=0.69で飽和する。 (b) ジェネレータのコストを変えて学習させたところ、画質を大きく向上させることなく、 誤差が大きくなってしまった。プロットは[4]から引用。 補足:log(1-D(G(z)))の最小化ではなくlog(D(G(z)))の最大化](https://files.speakerdeck.com/presentations/01d4347375e941c3988bc022f48feab6/slide_45.jpg){kind=link}
{kind=link}
![WGAN [4]は、式(1)のコストをWasserstein(ワッサースタイン)距離とも呼ばれる EM(Earth Mover)距離に置き換え、元のGANの消失勾配問題など解決している。](https://files.speakerdeck.com/presentations/01d4347375e941c3988bc022f48feab6/slide_47.jpg){kind=link}
{kind=link}
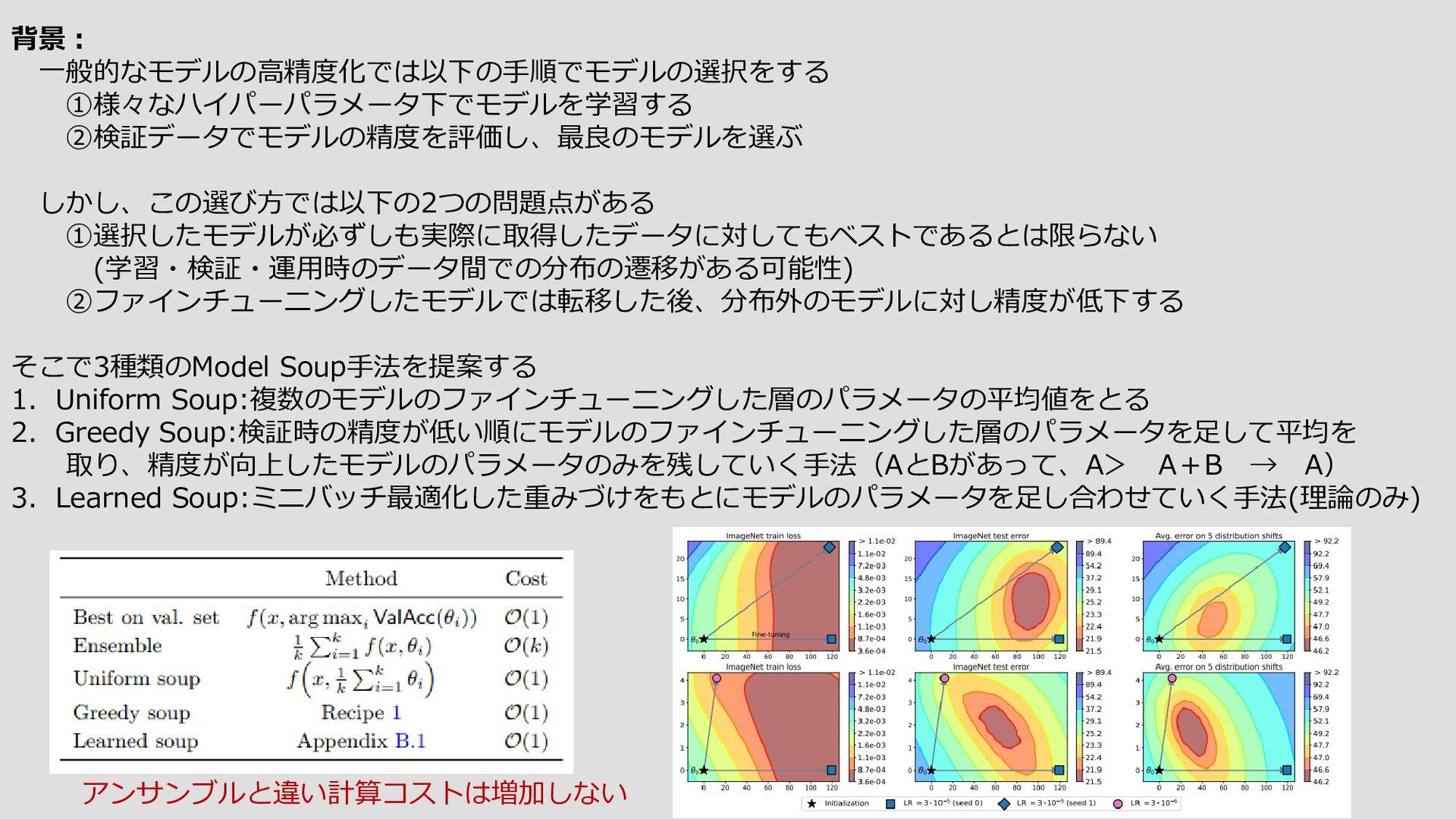{kind=link}
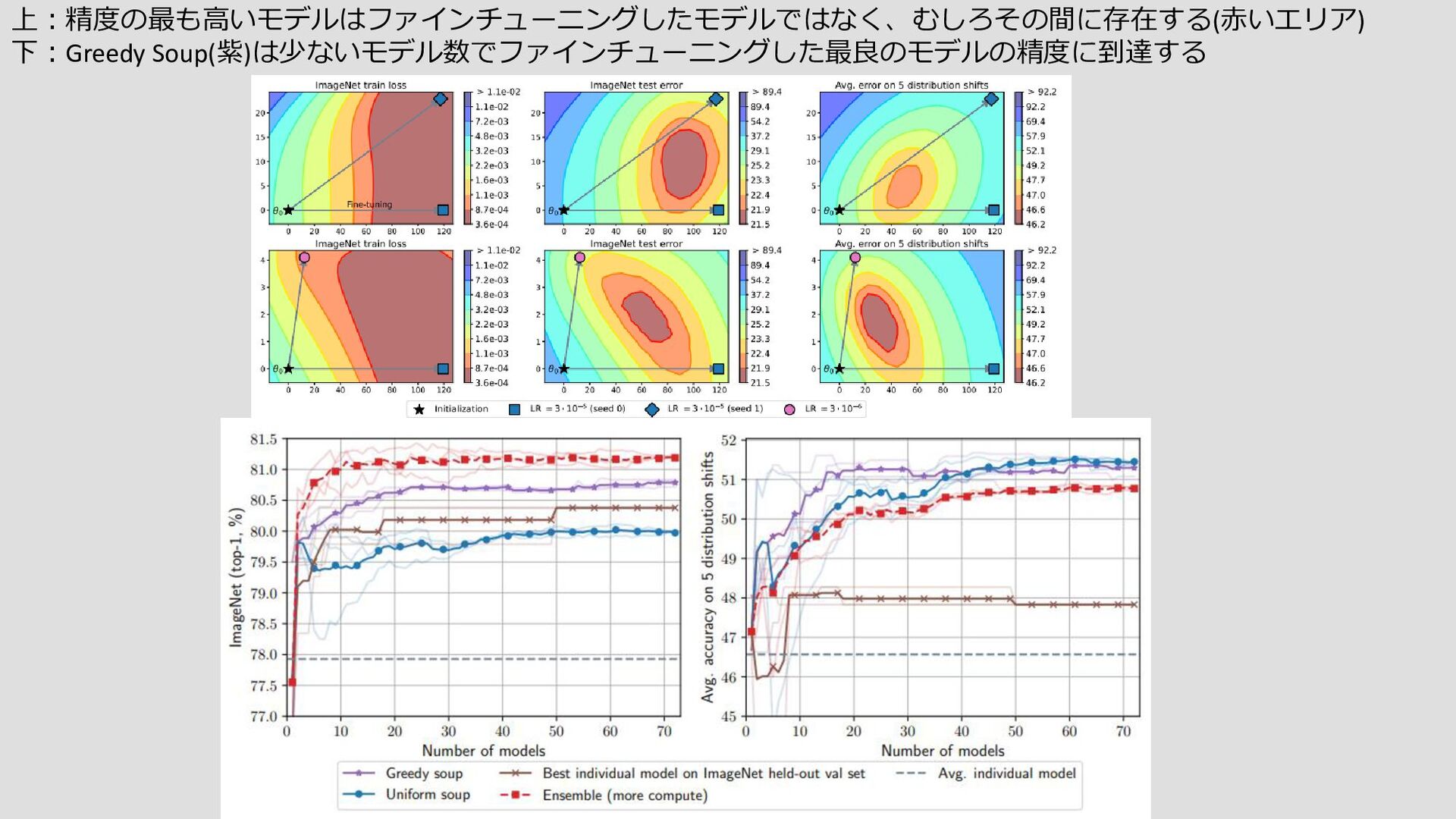{kind=link}
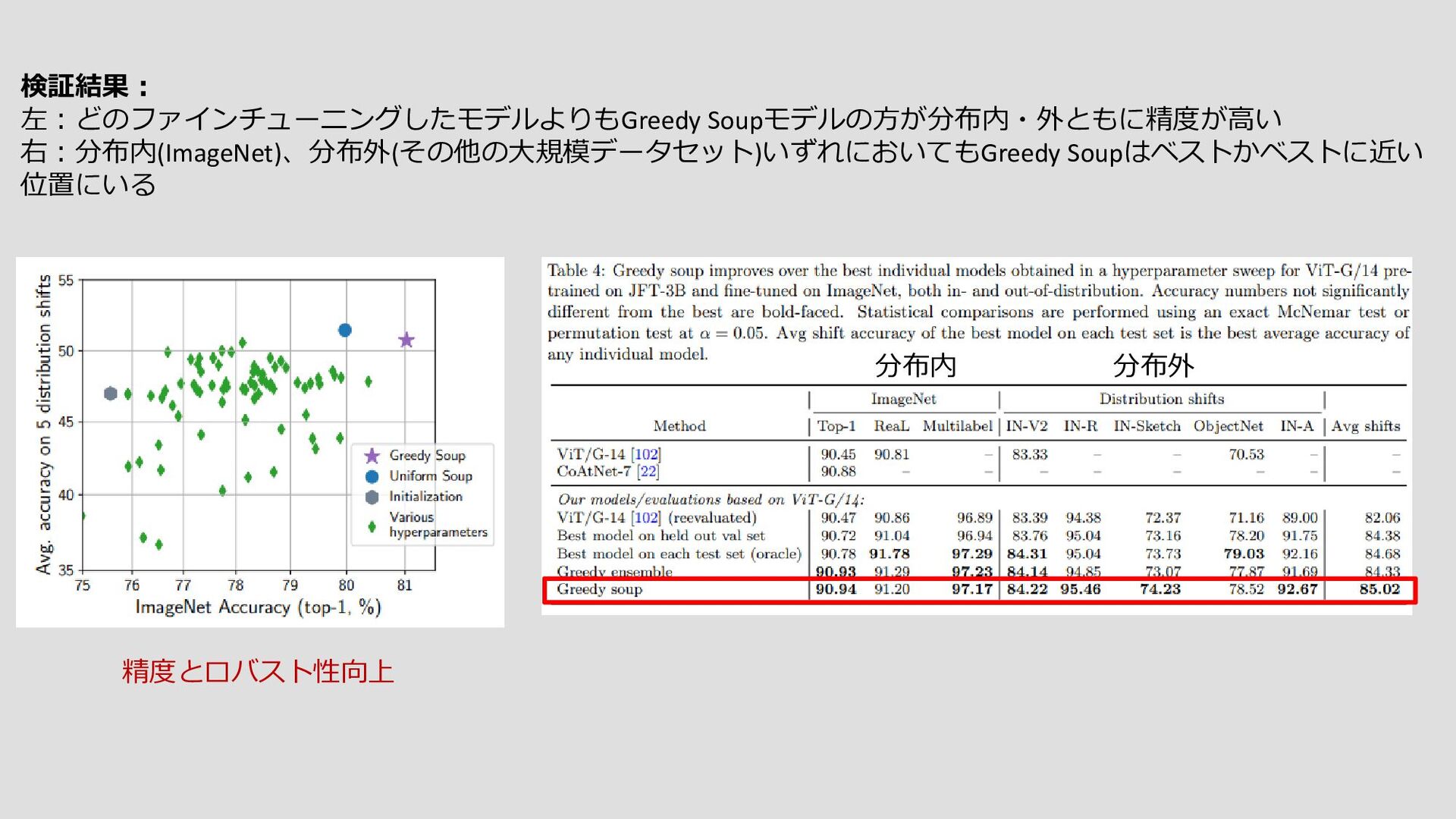{kind=link}
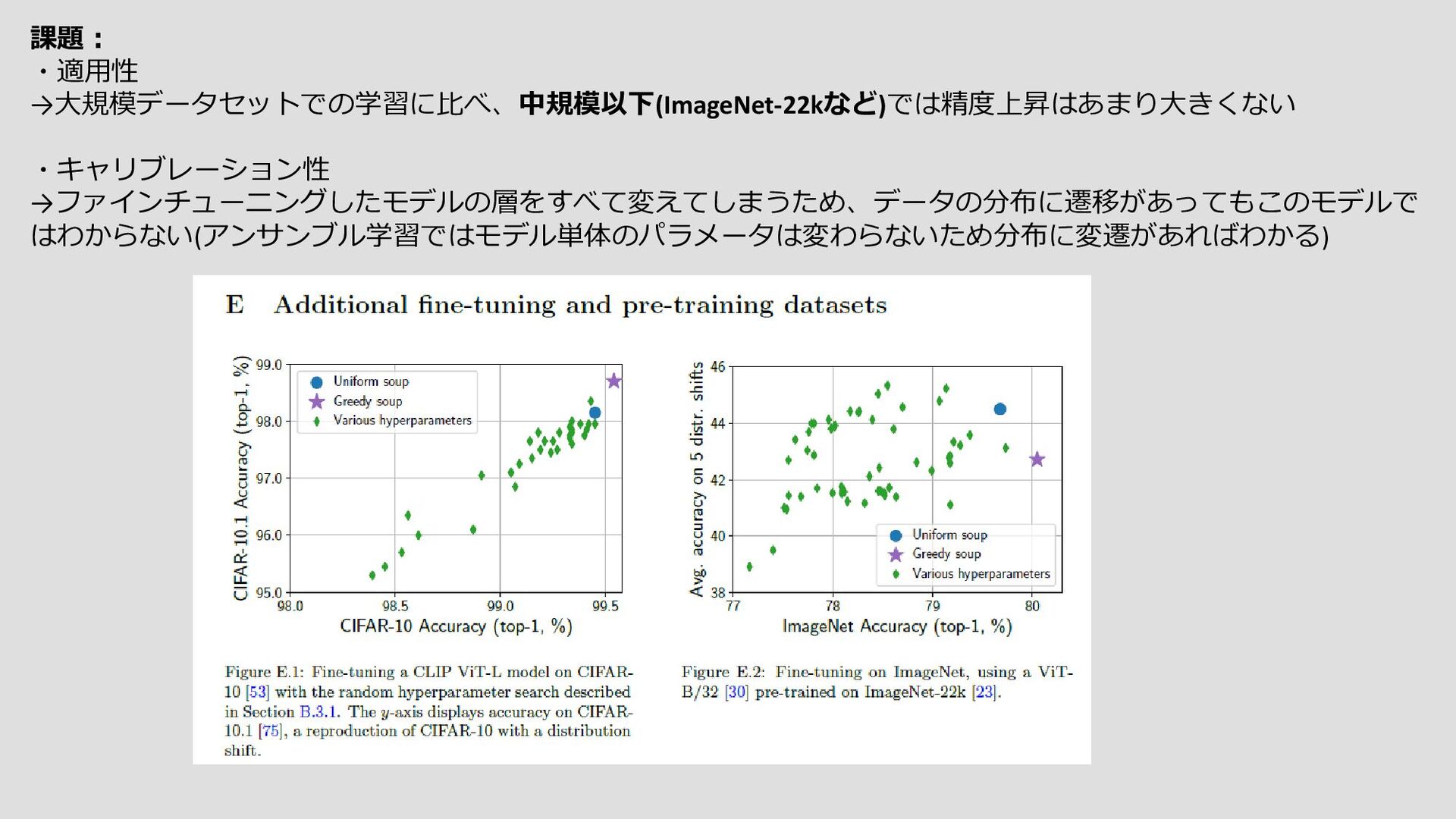{kind=link}
{kind=link}
{kind=link}
{kind=link}
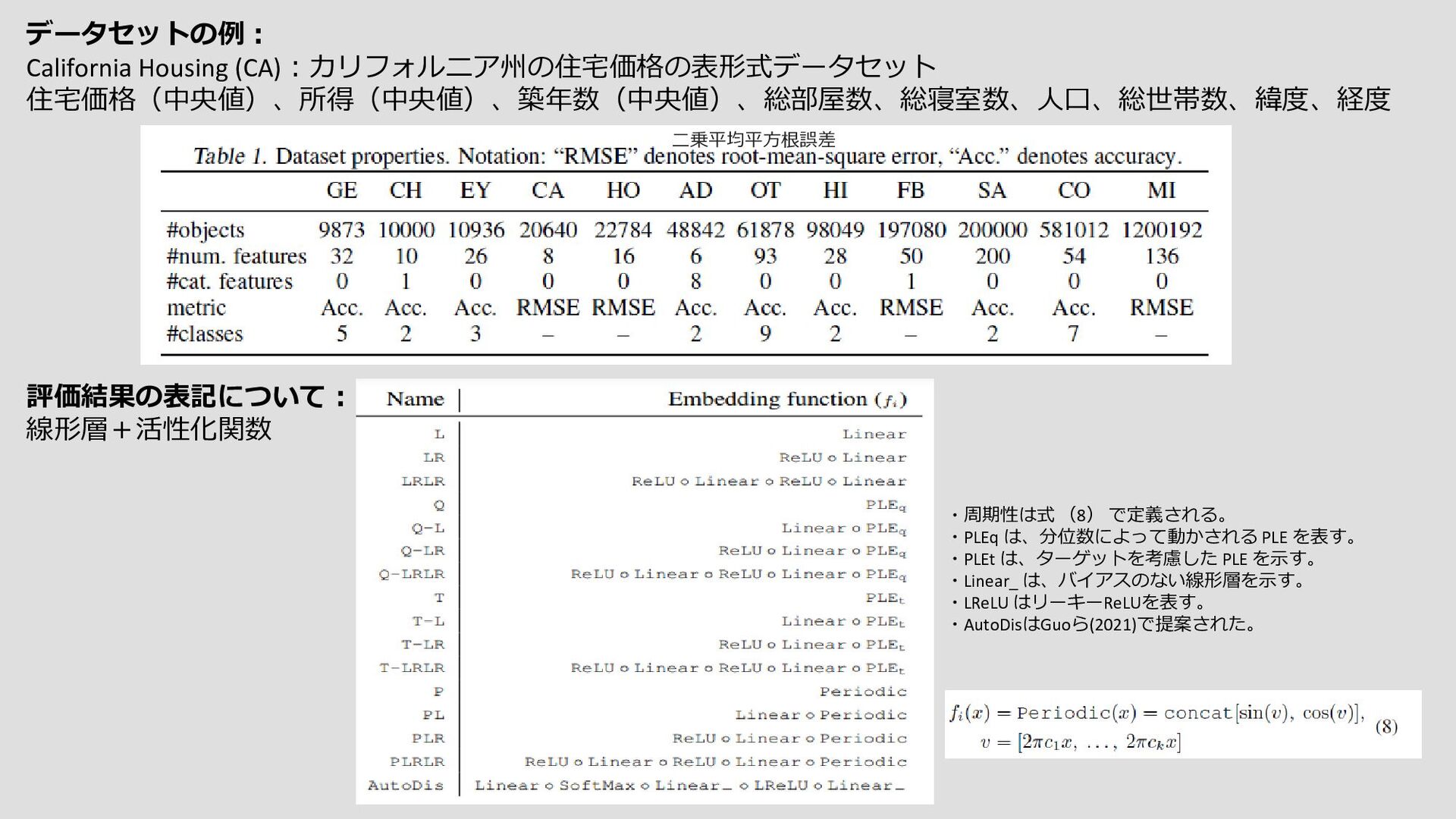{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}