Go for high information 2D visualizations. Select data subsets to visualize. http://www.inf.ed.ac.uk/teaching/courses/dme/slides2014/visualization-print4up.pdf
you by. Dig deeper. Use your visualizations to inform potential models. Use your potential model to direct your visualizations. Expect problems in your data. http://www.inf.ed.ac.uk/teaching/courses/dme/slides2014/visualization-print4up.pdf
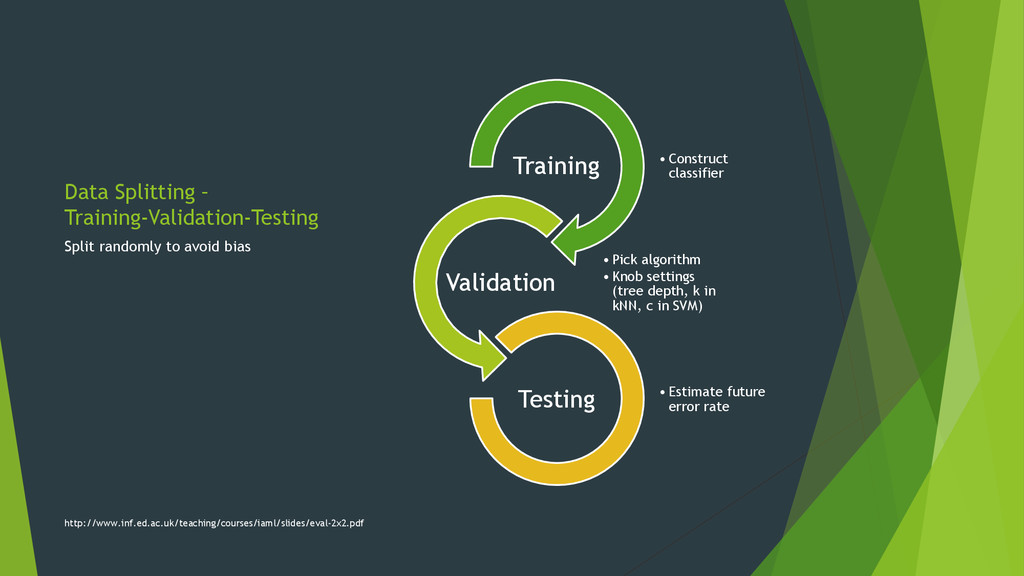
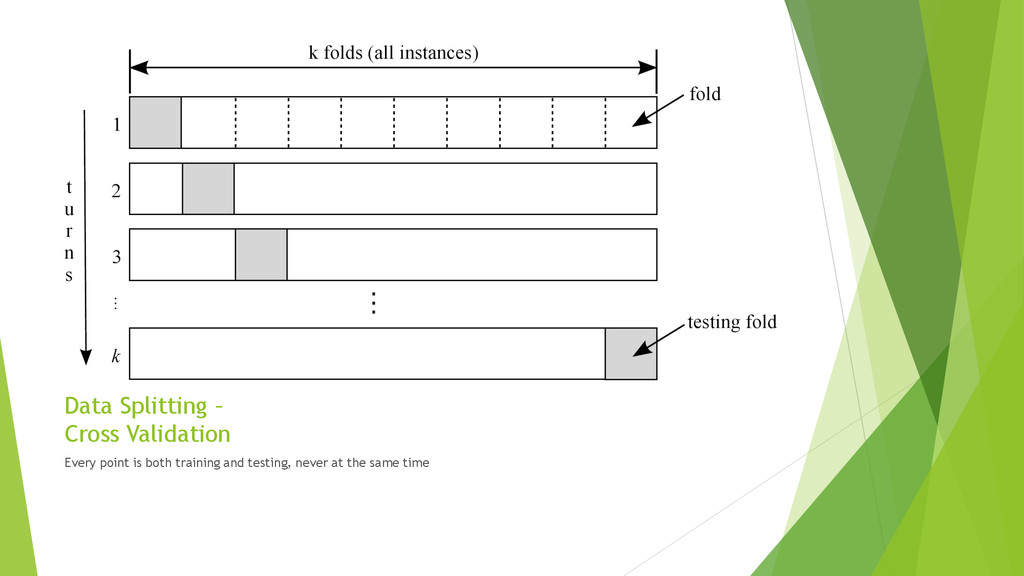
algorithm • Knob settings (tree depth, k in kNN, c in SVM) Validation • Estimate future error rate Testing Split randomly to avoid bias http://www.inf.ed.ac.uk/teaching/courses/iaml/slides/eval-2x2.pdf
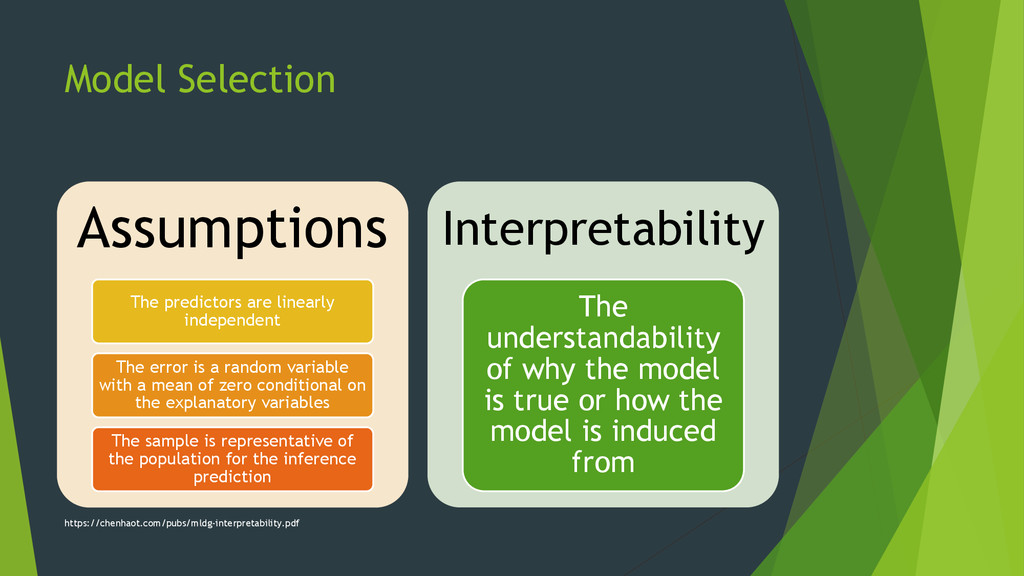
is a random variable with a mean of zero conditional on the explanatory variables The sample is representative of the population for the inference prediction Interpretability The understandability of why the model is true or how the model is induced from https://chenhaot.com/pubs/mldg-interpretability.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
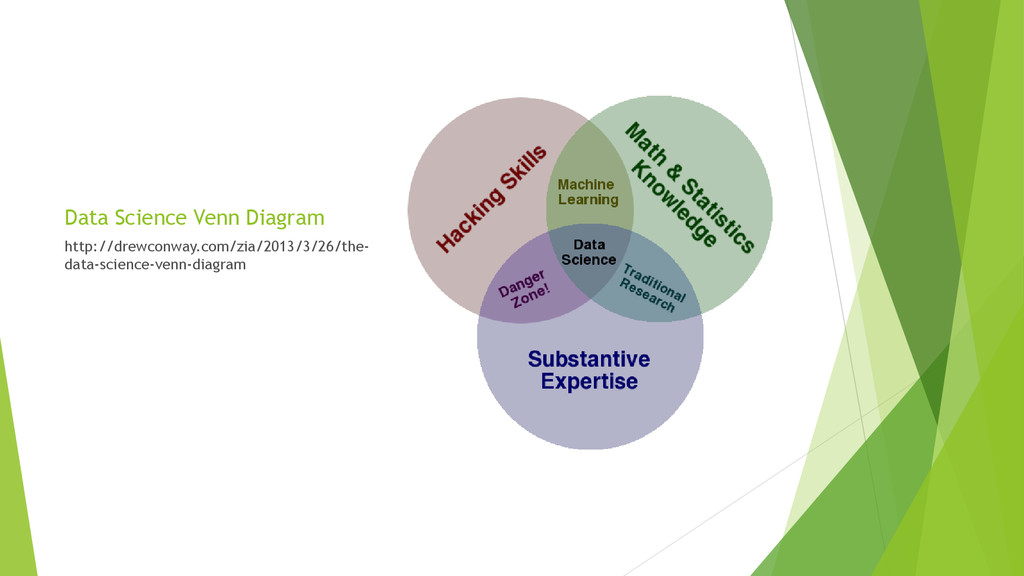{kind=link}
{kind=link}
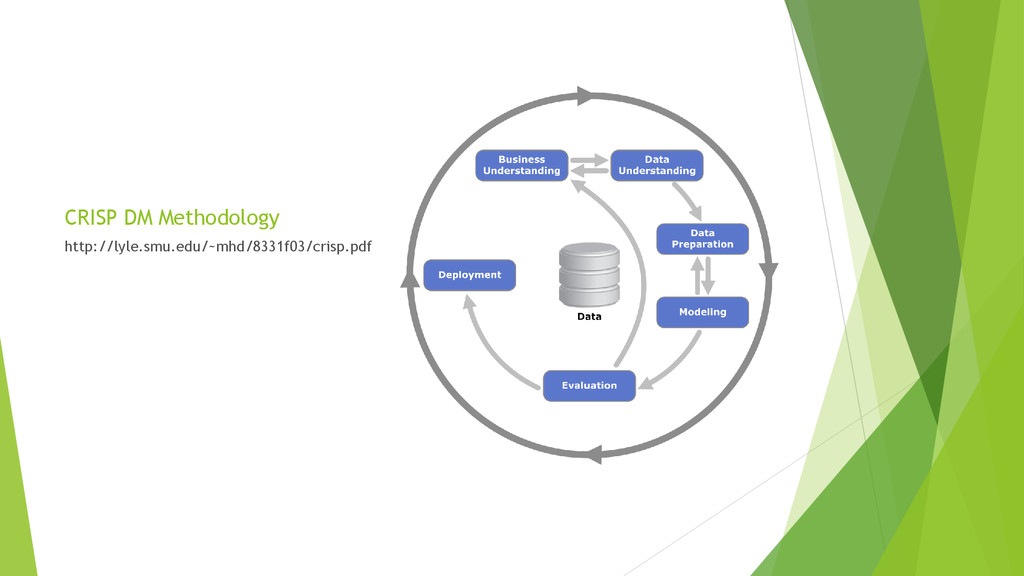{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
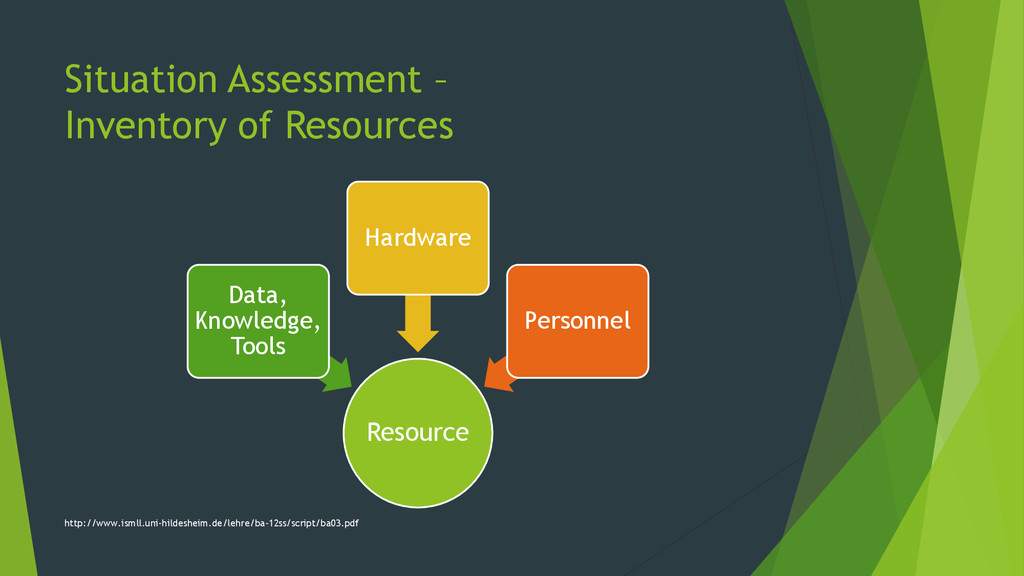{kind=link}
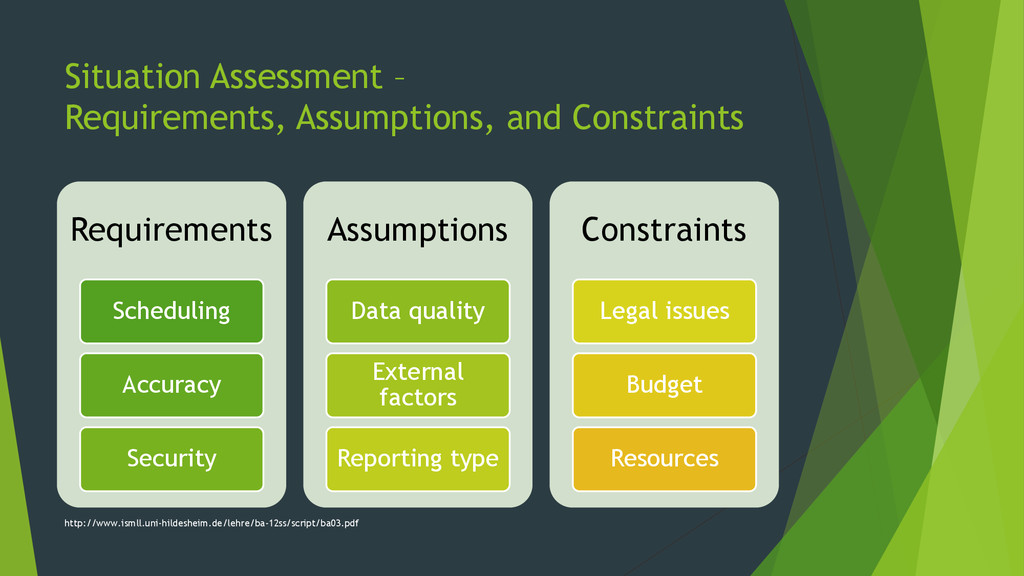{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
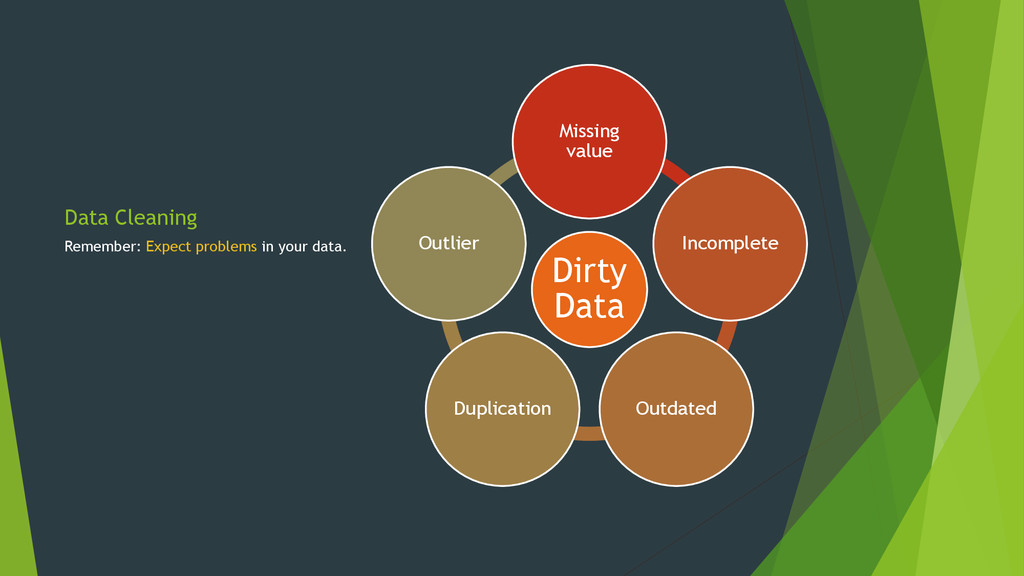{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}