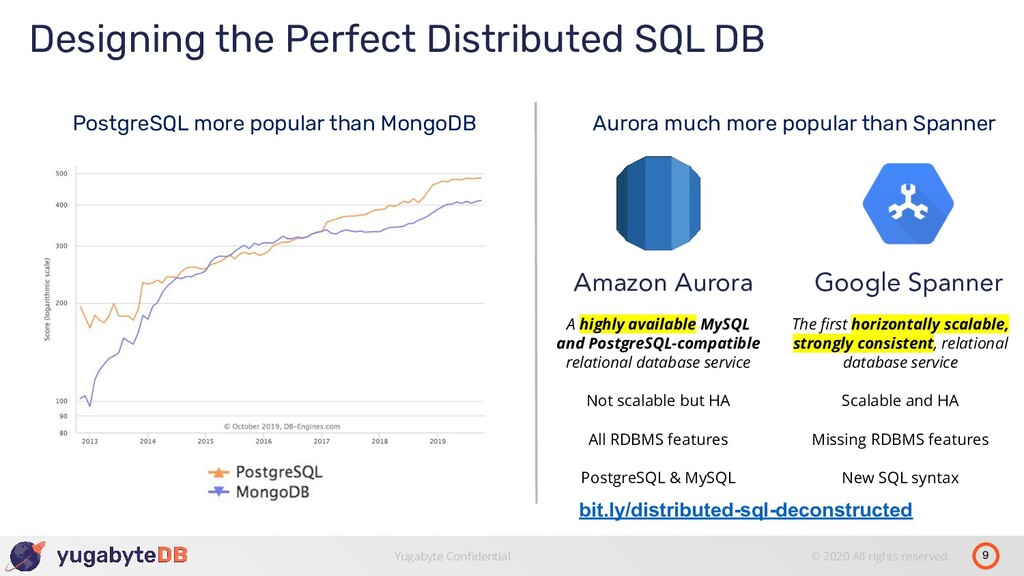
YugabyteDB, an open-source, distributed SQL database that is designed to support all PostgreSQL features with full wire-compatibility and address exactly these needs - massive scalability, high availability and geo-distribution of data. It’s unique sharding and replication architecture that makes it a perfect fit for Kubernetes-based orchestration.
In this session, we will take a look at the design goals and a hands-on demo of YugaByte DB on top of Kubernetes and how it can be deployed on multiple public clouds and across geographic regions. We will also discuss the best practices, you should employ when deploying distributed SQL databases like Yugabyte DB on Kubernetes. Topics will include best practices and strategies concerning deployment orchestration, persistent storage, scaling, and monitoring.
Bio
Amey is a Principal Data Architect at YugaByte DB with a deep passion for Data Analytics and Cloud-Native technologies. In his current role, he collaborates with Fortune 500 firms to architect their business applications with scalable microservices and geo-distributed, fault-tolerant data backend. Prior to joining YugaByte, he spent 5 years at Pivotal as Platform Data Architect and has helped enterprise customers across multiple industry verticals to extend their analytical capabilities using Pivotal/Open Source Big Data platforms. He is originally from Mumbai, India and has a Master's degree in Computer Science from the University of Pennsylvania(UPenn), Philadelphia.
Twitter: @ameybanarse
LinkedIn: linkedin.com/in/ameybanarse/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}