proceso y devuelve la respuesta R en 3ms • Enviamos el mensaje M2 al mismo proceso, devuelve nuevamente R pero esta vez tarda 6ms • Los resultados son consistentes para sucesivas mediciones del tiempo de procesamiento para M1 y M2. • Encontramos un side channel!
un análisis de seguridad de una web application seguramente notaron un timing side channel en: ◦ Login: El hash (bcrypt, pbkdf2) se calcula unicamente cuando el usuario es valido. ◦ Múltiples queries SQL (secuenciales) son ejecutadas cuando envio M1, pero no cuando envio M2. • Side channels de unos pocos milisegundos o menos son muy comunes, no siempre explotables, e imposibles de detectar “a ojo”.
de tiempo se genera al momento de comparar dos strings y depende de la cantidad de bytes en común desde el inicio • Application logic ◦ La diferencia en el tiempo de respuesta está dada por la lógica de la aplicación. def login(username, password): if not self.user_exists(username): return False return self.get_user_hash(username).check(password) if user_input.get('API_KEY') == MASTER_API_KEY: allow()
posible explotar este side channel y realizar un ataque de fuerza bruta byte-per-byte sobre el secreto. Se envían peticiones HTTP a la aplicación con API KEYs con tamaño incremental hasta que se nota un “salto” en el tiempo que toma comparar la key enviada con MASTER_API_KEY. if compare_strings(user_input.get('API_KEY'), MASTER_API_KEY): allow()
byte-per-byte: • AXXXXXXXXX • BXXXXXXXXX • CXXXXXXXXX Donde el primer byte es el que quiero descubrir y el resto es padding. Continuo probando hasta que encuentro un resultado para el cual la aplicación tarda más tiempo (compara un byte más). if compare_strings(user_input.get('API_KEY'), MASTER_API_KEY): allow()
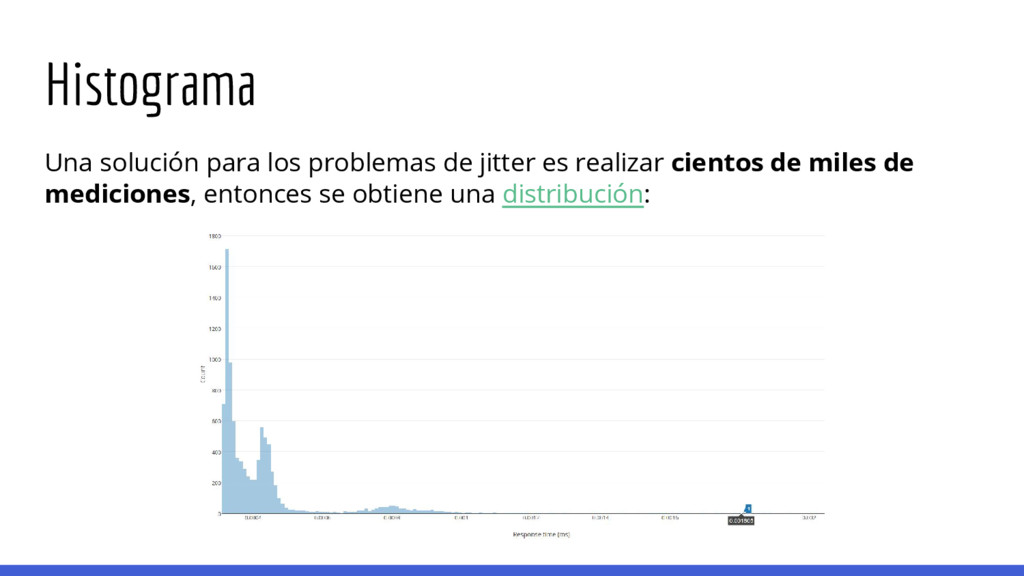
medir el tiempo de ejecución con la precisión necesaria para explotar todos los timing side channels. Fuentes de ruido en la computadora desde donde se realiza la medición: 1. Context switching 2. CPU load 3. Power save 4. WiFi (no!) 5. Conexión a Internet local (switches, routers, picos de tráfico, ISP QoS) 6. Cable => Network card Ring Buffer => IRQ => Kernel => Timestamp con precisión de milisegundos
Context switching y CPU load se soluciona utilizando isolcpus • Se deshabilita power save • Conectarse con un cable de red a Internet. Reducir lo más posible la cantidad de equipos de red entre el host e Internet. • pkill -f torrent • Compramos una placa de red que estampe tiempos en cada paquete con precisión de nanosegundos (Intel i350)
segundos el equipo remoto se encuentre con mucha carga. Si medimos un evento durante ese periodo, el resultado se verá afectado. Para reducir el efecto que tiene el CPU load remoto en nuestras mediciones lo que se hace es medir de manera entrelazada y tomar como valor de la medición la diferencia entre dos mediciones consecutivas. for _ in xrange(SAMPLES): data_point = timeit('AXXXX') - timeit('BXXXX') save(data_point)
un cloud público (AWS, DigitalOcean) es posible reducir el jitter agregado por Internet utilizando como host para realizar las mediciones un servidor en el mismo data-center que el objetivo. En algunos casos podría hasta ser posible obtener una instancia en el mismo hardware donde se ejecuta el target: “Hey, You, Get Off of My Cloud”.
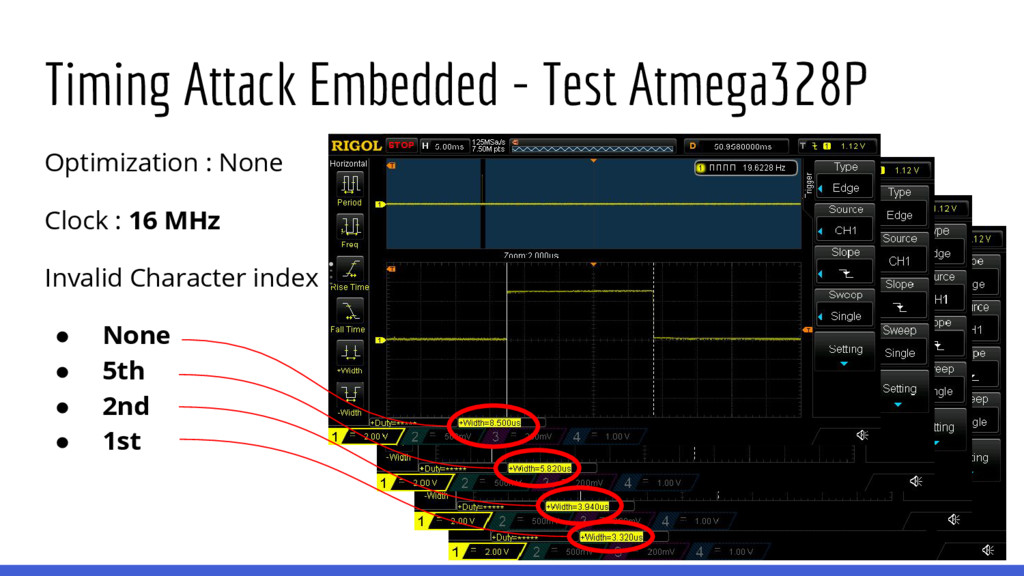
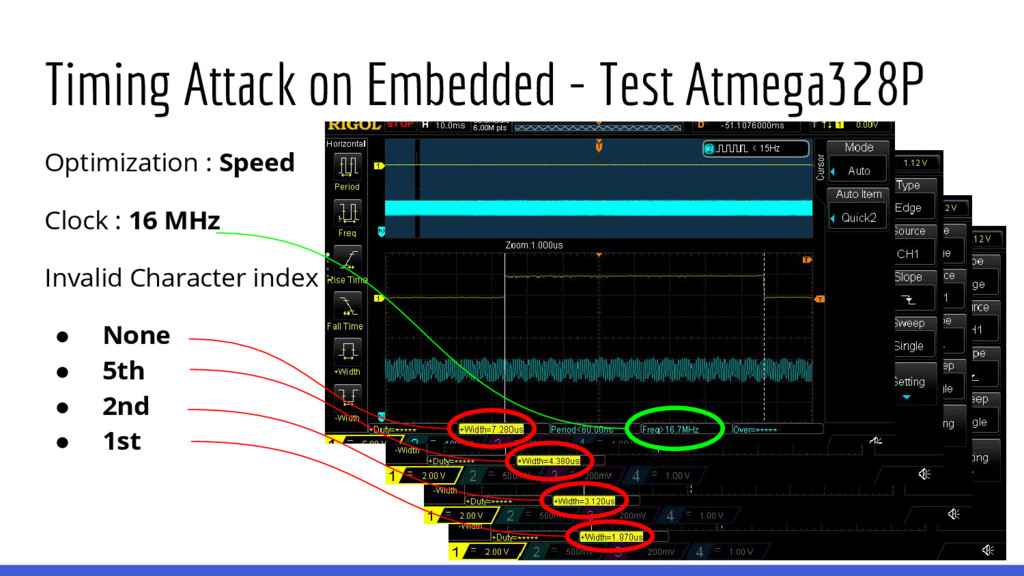
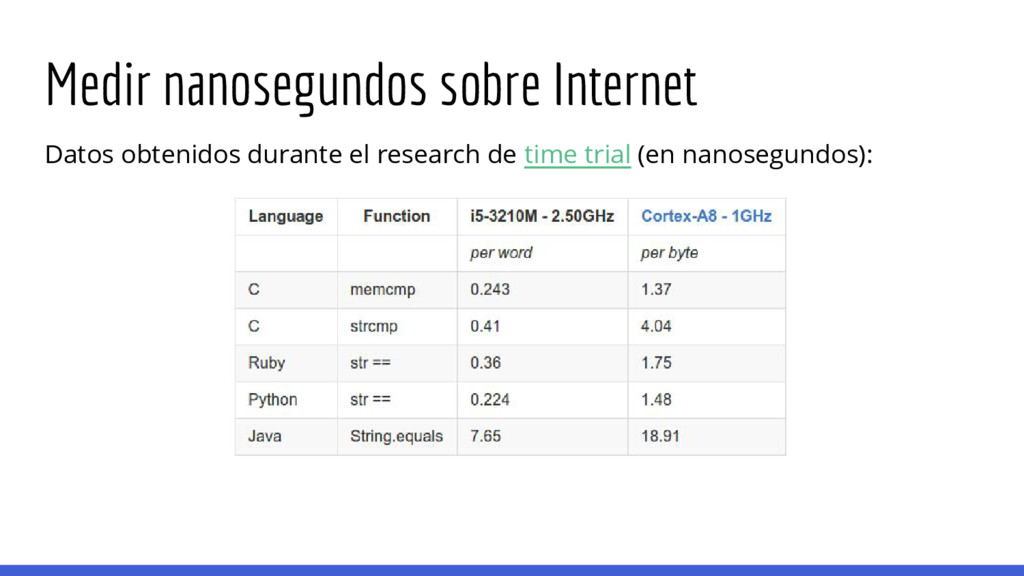
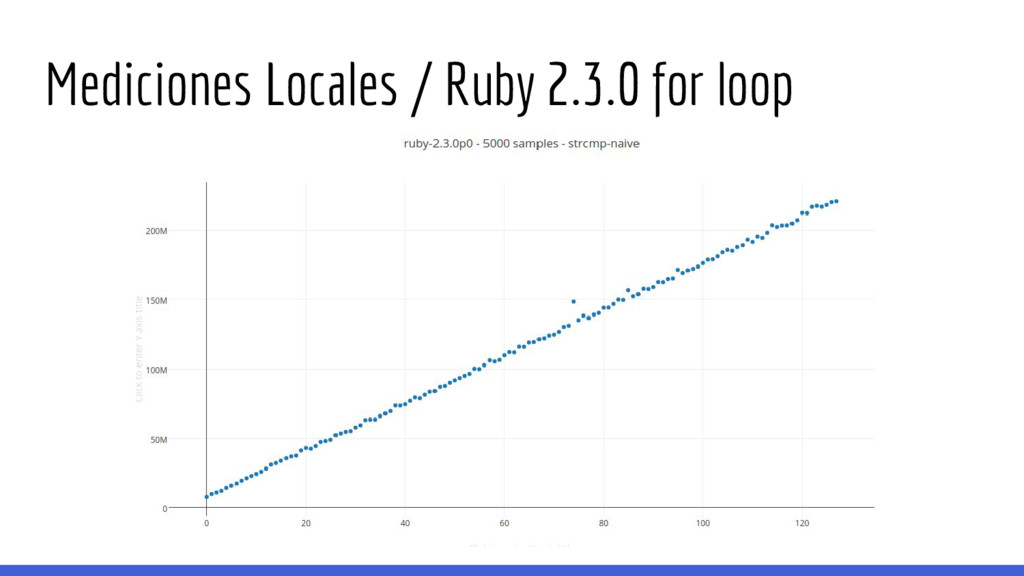
esto luego) de comparación de strings como: Los tiempos a medir son muy pequeños y la precisión con la cual es posible medirlos es reducida. def compare_strings(str_a, str_b): if len(str_a) != len(str_b): return False for i, char_a in enumerate(str_a): if str_b[i] != char_a: return False return True
suelen ser muy pequeños, se puede aplicar una técnica conocida como “mathematical amplification” (bleh!) para incrementar el tiempo a medir. No es perfecto porque incrementa la cantidad de peticiones HTTP a realizar , pero incrementa sustancialmente el intervalo de tiempo a medir. En este caso el brute-force se hace de a tres bytes: timeit('AAAXX') vs timeit('AABXXXX') ... vs timeit('ZZZXXXX')
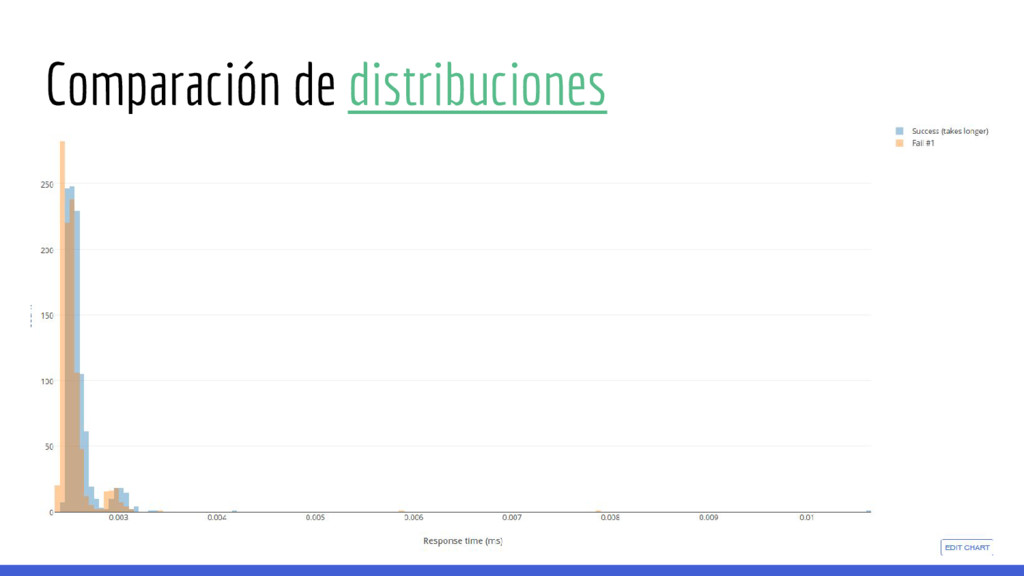
no es trivial, en general hay que tener en cuenta los siguientes componentes: • Filtros para eliminar outliers de una distribución, se suele utilizar únicamente el rango de datos menor al N% con N: {5, 10, 15, 20} • Métodos de comparación de distribuciones: ◦ Box test ◦ Midsummary ◦ Expectation-Maximization • Certeza del resultado
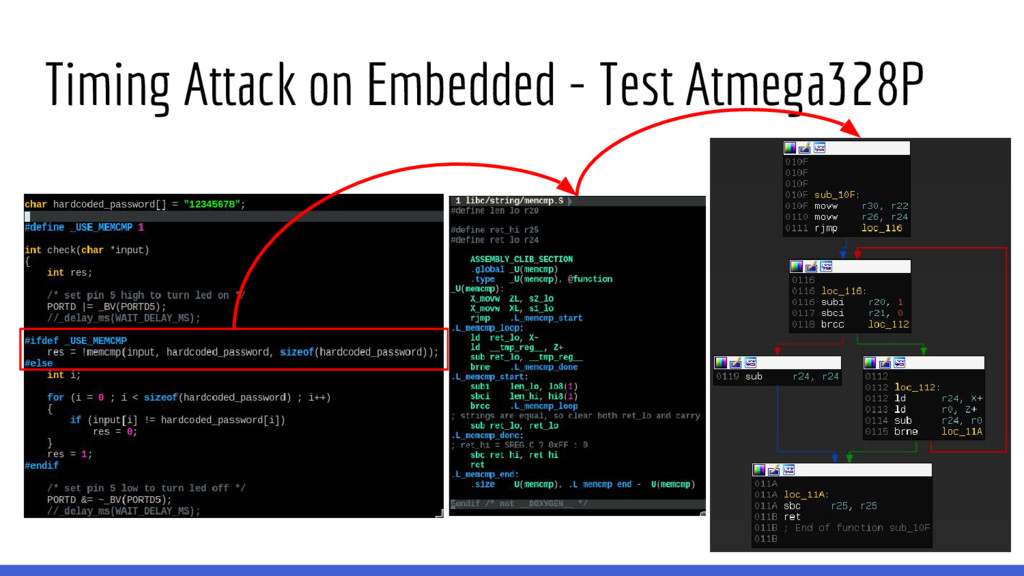
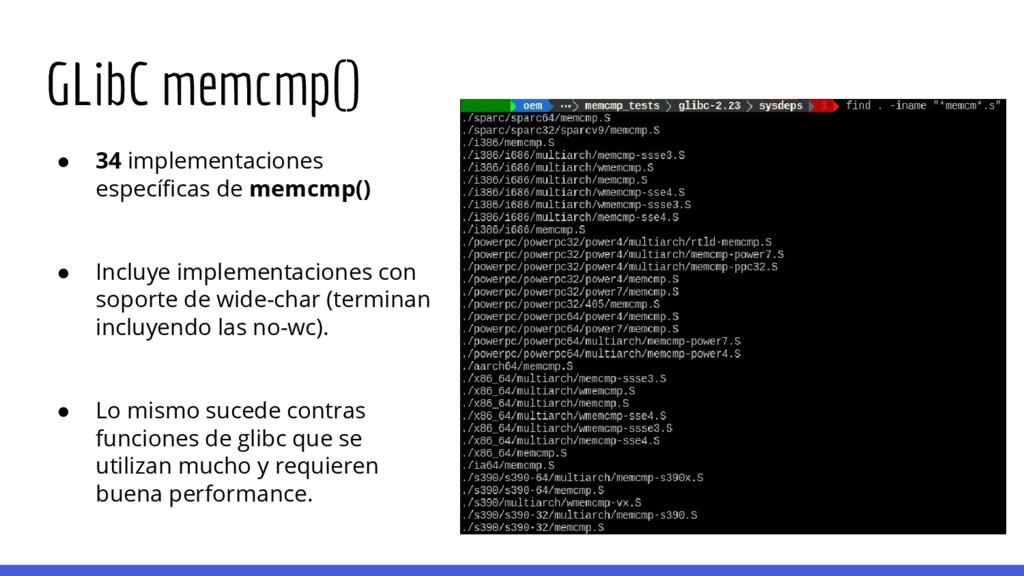
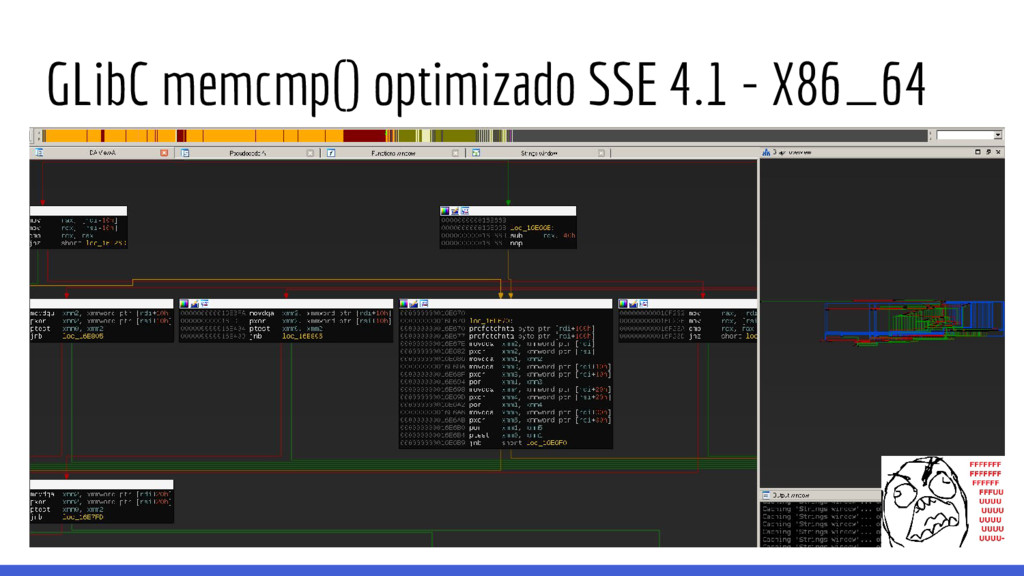
lenguajes de programación desarrollados en C terminan utilizando memcmp() de glibc para implementar la comparación de strings. memcmp() está optimizado para que las comparaciones de dos strings sean lo más rápidas posibles, si están disponibles se utilizan instrucciones de SSE para comparar secciones de memoria de 8 o 16 bytes en una sola instrucción de procesador. Entonces, no es posible realizar ataques de fuerza bruta byte-per-byte (*) en targets que utilicen glibc y sea posible utilizar alguna instrucción del CPU que compare strings en bloques.
soporte de wide-char (terminan incluyendo las no-wc). • Lo mismo sucede contras funciones de glibc que se utilizan mucho y requieren buena performance. GLibC memcmp()
128bits. • Son 1776 líneas de assembler de puro amor! • Algún hijo de puta se fue a su casa contento después de esto. GLibC memcmp() optimizado SSE 4.1 - X86_64
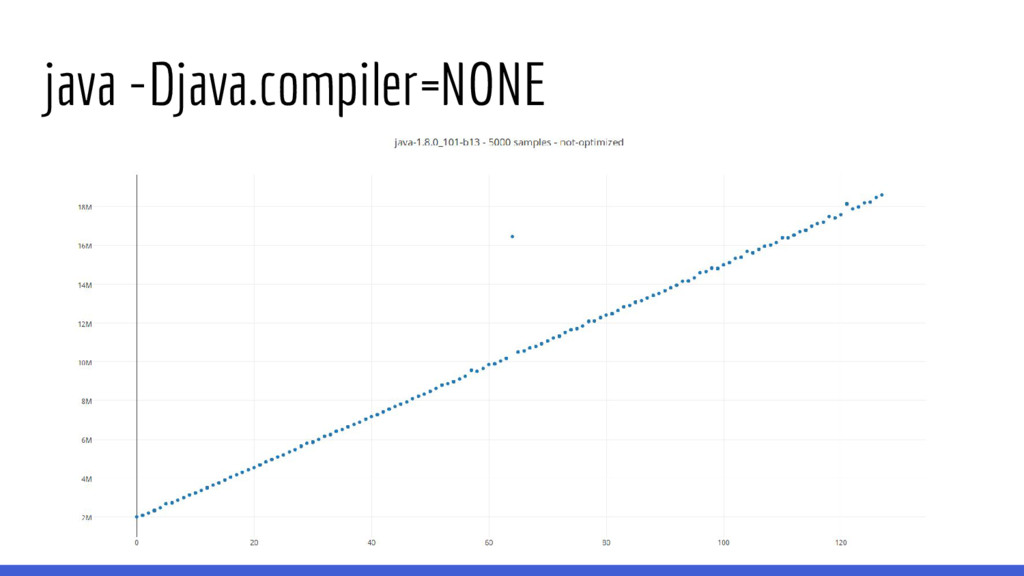
if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String) anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; Naive, pero… después las optimizaciones de la JVM deciden que es mejor ejecutar la versión optimizada de String.equals, la cual tiene optimizaciones similares a memcmp()
complejo, lo mejor es simplificarlo, y eso es lo que hizo Paul McMillan en el research que presentó hace unos años en Ekoparty donde utilizo timing attacks para obtener byte a byte la API key de una lampara HUE de Phillips. Lo que logró al atacar lámparas HUE fue: • CPU más lento, mayor tiempo en ejecutar cada instrucción • Comparacion naive de strings byte per byte • Conexión por medio de un cable de red y utilizando Intel i350
CPython no utiliza memcmp() en todos los casos: switch(kind1) { case PyUnicode_1BYTE_KIND: { switch(kind2) { case PyUnicode_1BYTE_KIND: { int cmp = memcmp(data1, data2, len); ... } case PyUnicode_2BYTE_KIND: COMPARE(Py_UCS1, Py_UCS2); break; case PyUnicode_4BYTE_KIND: COMPARE(Py_UCS1, Py_UCS4); break;
strings con diferentes byte sizes se realiza utilizando una función con un per-byte side channel: Me imagino que es posible identificar frameworks de desarrollo web python que permitan explotar esta debilidad especificando Content-Encoding en los requests. CHAR_OK = b'A'.decode('ascii') CHAR_FAIL = 'á' assert len(CHAR_OK.encode('utf-8')) != len(CHAR_FAIL.encode('utf-8')) CHAR_OK == CHAR_FAIL # naive strcmp
los lenguajes, investigar y utilizar técnicas necesarias para reducir jitter • Definir múltiples entornos de prueba y capturar millones de muestras • Probar todas las combinaciones de filtros, métodos de comparación de distribuciones y precisión para determinar cuál funciona mejor para cada entorno. • Desarrollar una aplicación que pueda atacar IoT de manera automática • Mejorar la aplicación anterior para que pueda ser utilizada contra aplicaciones reales
https://github.com/andresriancho/pico • https://github.com/andresriancho/pico-string-compare-loc al No dejen de leer las wikis de esos dos repositorios, contienen información interesante sobre el research, links a otras herramientas, etc. Help wanted
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}