0.2 Small d = 0.5 Medium d = 0.8 Large r 判定 r = 0.1 Small r = 0.3 Medium r = 0.5 Large ⚫ Cohenの規準の問題点 • Cohenの基準は行動科学分野の研究を通してこれまでに得られた効果量を参考にして作成さ れた経験則であり、全ての分野において適応できるものではない • Cohenの基準で小さいとされる効果量も、分野によっては大きな意味を持つ • 研究者は、得られた効果量を現実的な文脈や研究分野ごとの文脈に位置づけることでその実 質的な意味を解釈すべきであり、Cohenの規準のようなベンチマークを機械的に当てはめて 解釈を放棄することは望ましくない
(2009) は、近年のメタ分析によって得られた効果量の値が大きくなっていること を根拠に、Cohenの基準を以下のようにプラスの方向に拡張することを提案している。 d 判定 d 判定 d < 0.1 Tiny 0.8 <= d < 1.2 Large 0.1 <= d < 0.2 Very small 1.2 <= d < 2 Very large 0.2 <= d < 0.5 Small d >= 2 Huge 0.5 <= d < 0.8 Medium
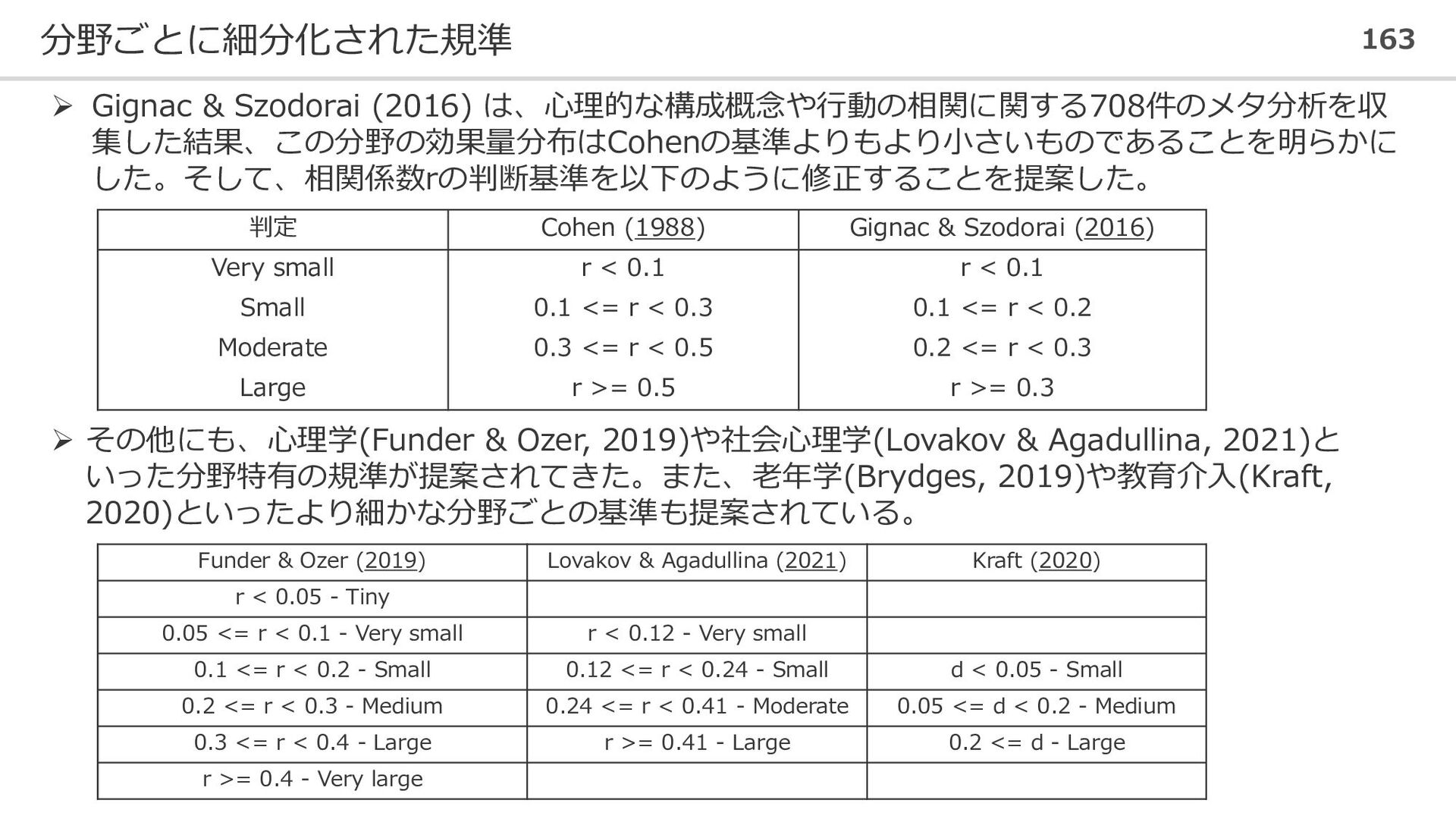
判定 Cohen (1988) Gignac & Szodorai (2016) Very small r < 0.1 r < 0.1 Small 0.1 <= r < 0.3 0.1 <= r < 0.2 Moderate 0.3 <= r < 0.5 0.2 <= r < 0.3 Large r >= 0.5 r >= 0.3 ➢ その他にも、心理学(Funder & Ozer, 2019)や社会心理学(Lovakov & Agadullina, 2021)と いった分野特有の規準が提案されてきた。また、老年学(Brydges, 2019)や教育介入(Kraft, 2020)といったより細かな分野ごとの基準も提案されている。 Funder & Ozer (2019) Lovakov & Agadullina (2021) Kraft (2020) r < 0.05 - Tiny 0.05 <= r < 0.1 - Very small r < 0.12 - Very small 0.1 <= r < 0.2 - Small 0.12 <= r < 0.24 - Small d < 0.05 - Small 0.2 <= r < 0.3 - Medium 0.24 <= r < 0.41 - Moderate 0.05 <= d < 0.2 - Medium 0.3 <= r < 0.4 - Large r >= 0.41 - Large 0.2 <= d - Large r >= 0.4 - Very large
Larry V. Hedges, Harris Cooper, Ingram Olkin, John E. Hunter, Jacob Cohen, Robert Rosenthal, Frank L. Schmidt, John E. Hunter らの貢献が大きい • 1970年代以降、教育学、心理学、医学、生態学など複数の分野でメタ分析が盛んにおこな われる ➢ Lipsey & Wilson(1993):心理・教育・行動的介入に関する302個のメタ分析の結果 を検討し,効果量の平均が0.50,標準偏差が0.29であったことを示している • 1980年代に入ると、ナラティブレビューに代わり、メタ分析やシステマティックレビュー が主流になってくる。 • 2000年代以降、論文データベースが整理されていく中でより活発にメタ分析が 行われるようになってきている • 2008年には、ジョン・ハッティによる大規模なメタ・メタ分析が実施される • 2010年には、Research Synthesis Methods が発行された
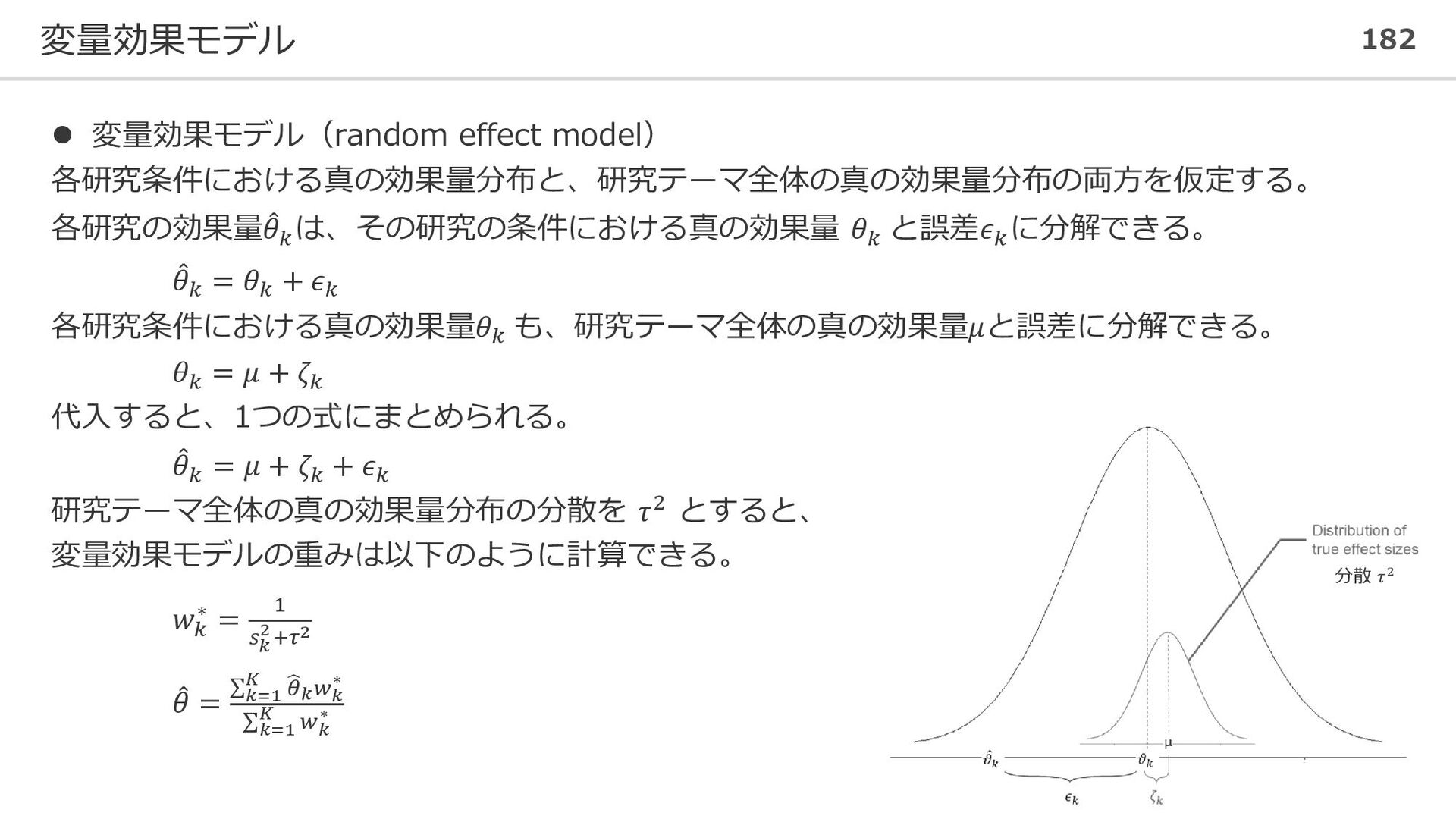
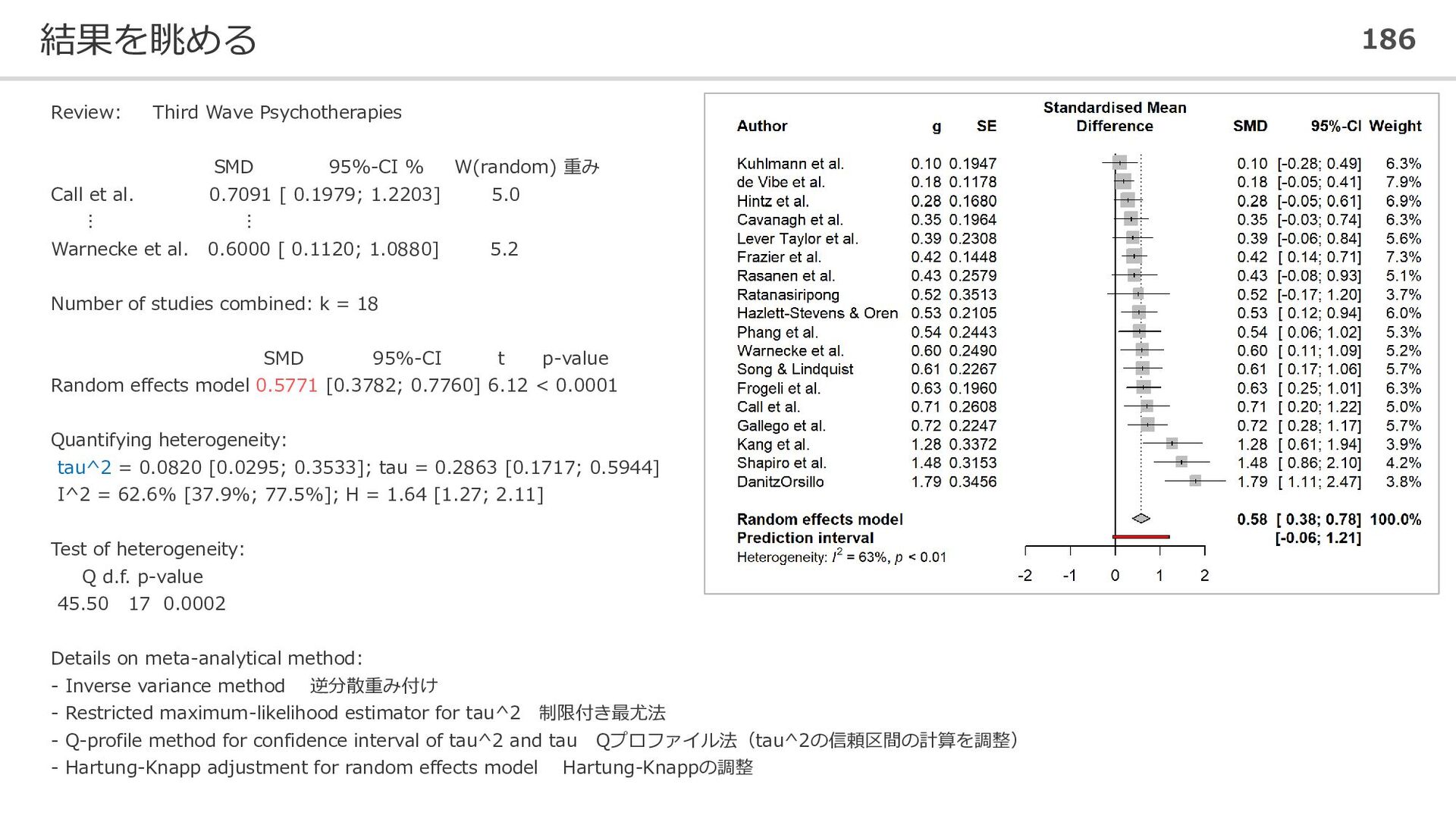
重み Call et al. 0.7091 [ 0.1979; 1.2203] 5.0 ⋮ ⋮ Warnecke et al. 0.6000 [ 0.1120; 1.0880] 5.2 Number of studies combined: k = 18 SMD 95%-CI t p-value Random effects model 0.5771 [0.3782; 0.7760] 6.12 < 0.0001 Quantifying heterogeneity: tau^2 = 0.0820 [0.0295; 0.3533]; tau = 0.2863 [0.1717; 0.5944] I^2 = 62.6% [37.9%; 77.5%]; H = 1.64 [1.27; 2.11] Test of heterogeneity: Q d.f. p-value 45.50 17 0.0002 Details on meta-analytical method: - Inverse variance method 逆分散重み付け - Restricted maximum-likelihood estimator for tau^2 制限付き最尤法 - Q-profile method for confidence interval of tau^2 and tau Qプロファイル法(tau^2の信頼区間の計算を調整) - Hartung-Knapp adjustment for random effects model Hartung-Knappの調整
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
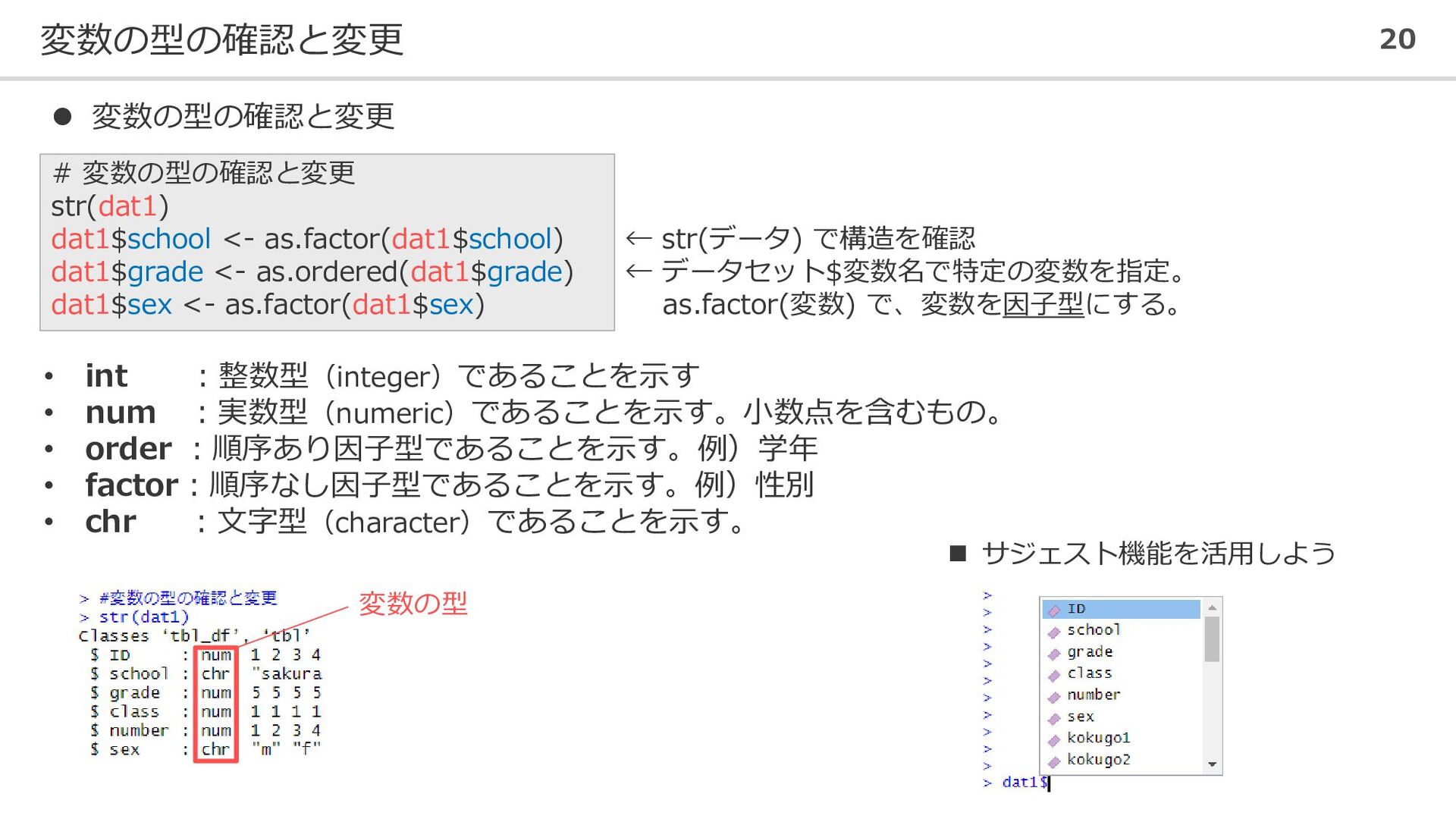
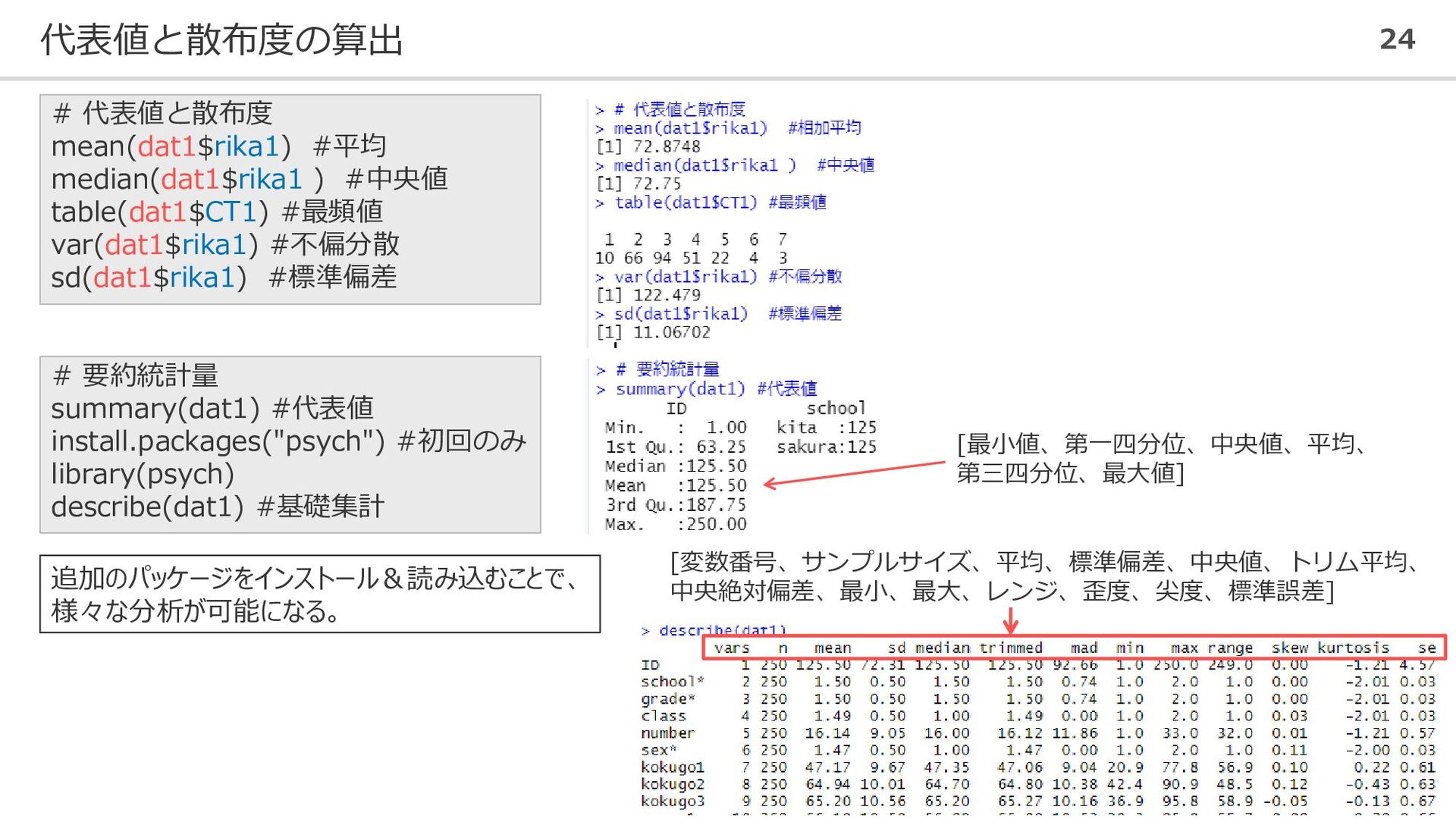
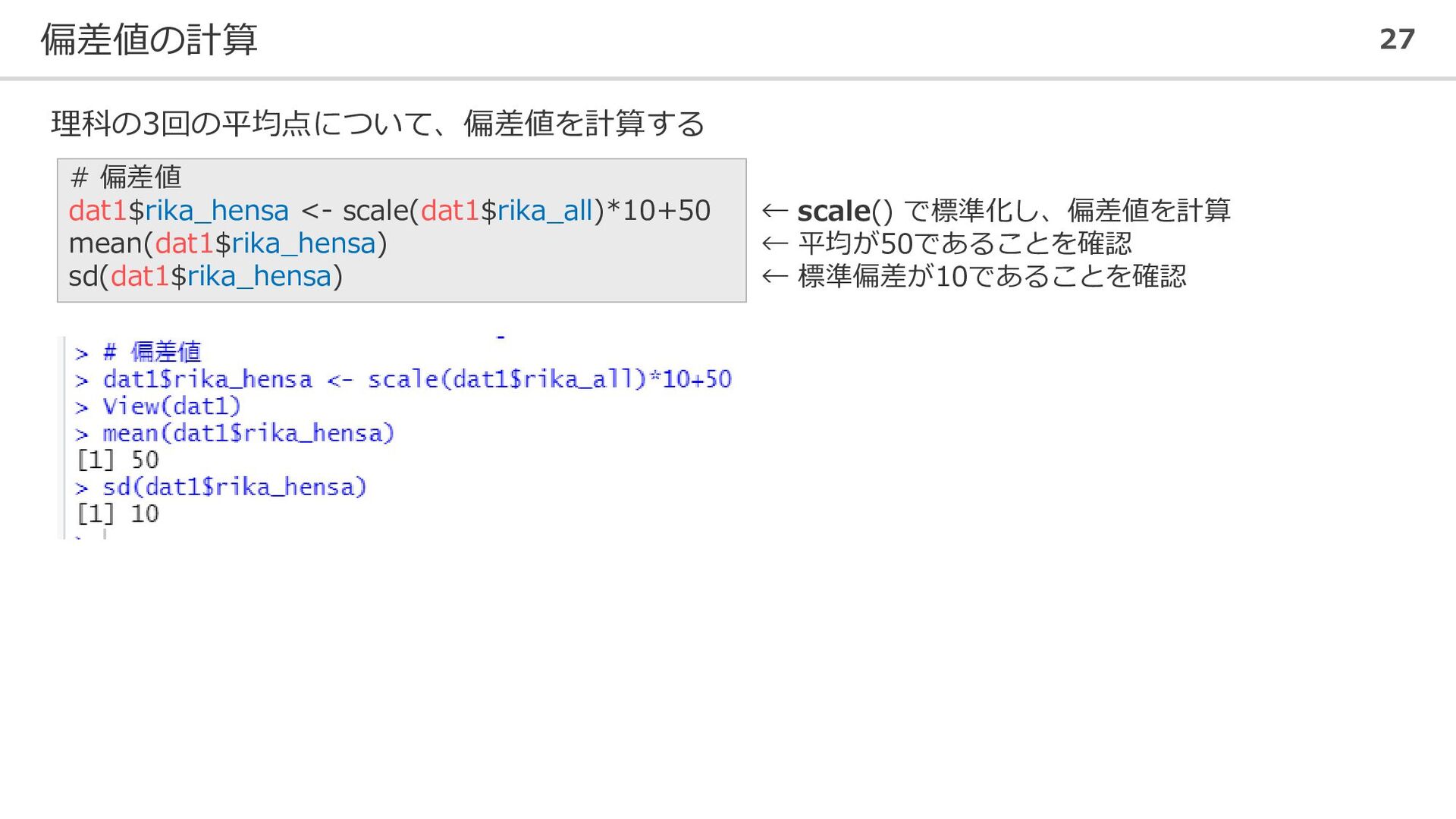
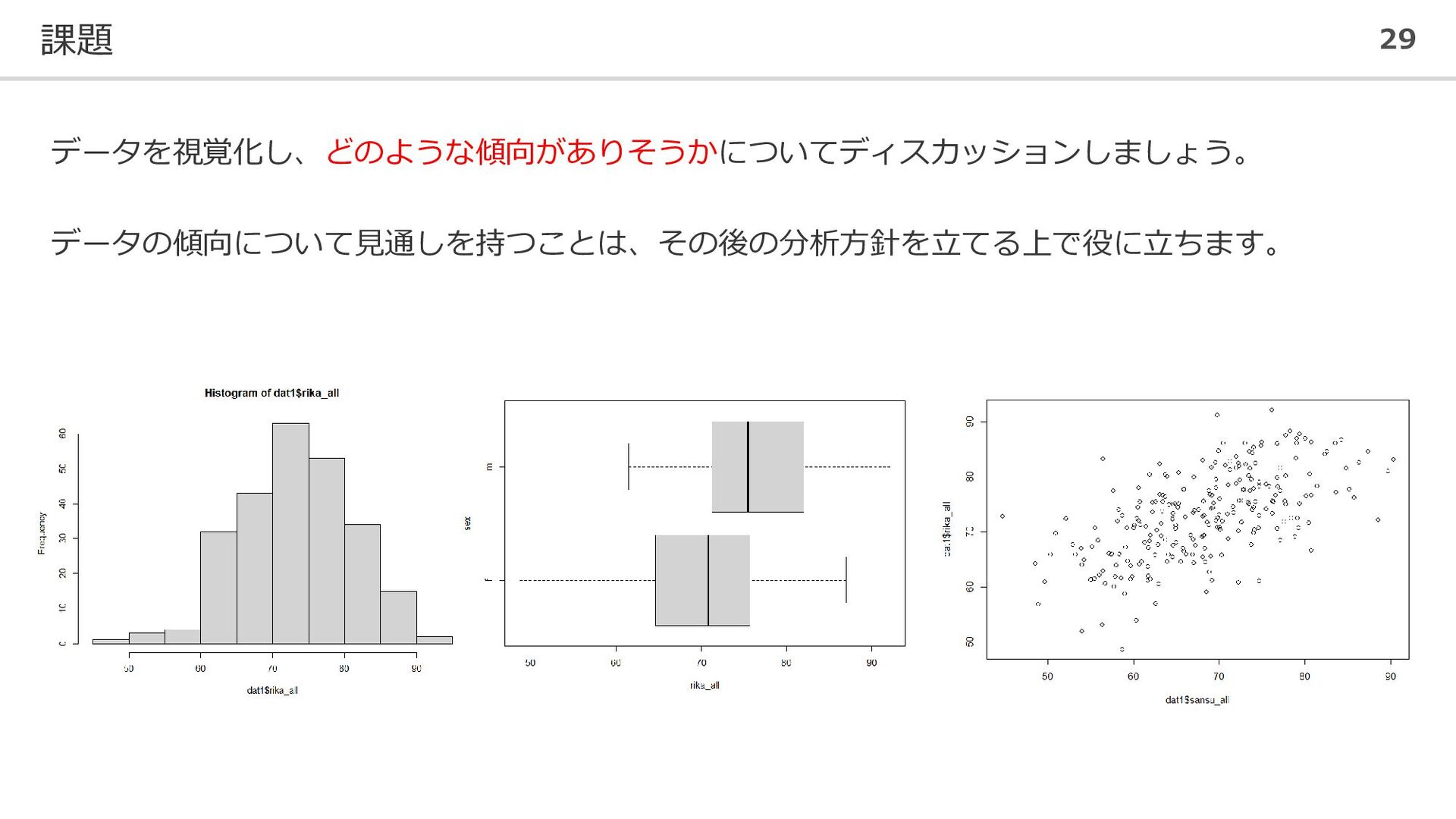
![新しい変数やデータセットの作成 25 ⚫ 各教科の3回のテストの平均を個人ごとに算出する # 新しい変数の作成 dat1$kokugo_all <- apply(dat1[,7:9], 1,](https://files.speakerdeck.com/presentations/9d922ca48bac4546beca090bf82ad204/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![復習 1. 標本分布の標準偏差を何と呼ぶでしょうか 2. 95%信頼区間について説明せよ 3. [正誤判定問題] ①有意水準αを5%に設定するということは、実際には帰無仮説が正しい(差がない)のに、 誤って帰無仮説を棄却する確率を5%以下に抑えることを意味する。 判定:](https://files.speakerdeck.com/presentations/9d922ca48bac4546beca090bf82ad204/slide_60.jpg){kind=link}
{kind=link}
![対応のないt検定(2群の平均値差) # 性別間比較 tapply(dat1$rika_all, dat1$sex, mean) #性別ごとの平均値 m.rika <- dat1$rika_all[dat1$sex=="m"]](https://files.speakerdeck.com/presentations/9d922ca48bac4546beca090bf82ad204/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![相関分析2 #カテゴリカル変数を含む相関 library(polycor) hetcor(dat1[,c("kokugo_all", "grade")], ML=T) #カテゴリカル変数を含めた相関行列 ML=最尤法 ⚫ 変数間の関連の強さは?](https://files.speakerdeck.com/presentations/9d922ca48bac4546beca090bf82ad204/slide_73.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![探索的因子分析1 #探索的因子分析##### #データの取り出し dat_CT <- dat1[,c(16:22)] #7~15行目の取り出し ⚫ 批判的思考:何を信じ、何を行うかの決定に焦点を当てた、合理的で省察的な思考(Ennis, 1987)](https://files.speakerdeck.com/presentations/9d922ca48bac4546beca090bf82ad204/slide_102.jpg){kind=link}
![探索的因子分析2 # 平行分析 dat_CT <- dat1[,c(16:22)] #7~15行目の取り出し fa.parallel(dat_CT) ⚫ 何因子構造だろう?](https://files.speakerdeck.com/presentations/9d922ca48bac4546beca090bf82ad204/slide_103.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![尺度得点との相関 # 相関の検討 dat1$CT <- rowMeans(dat1[,c(16:22)]) #指定行の平均値を変数として作成 cor(dat1$rika_all, dat1$CT) #理科と批判的思考の相関](https://files.speakerdeck.com/presentations/9d922ca48bac4546beca090bf82ad204/slide_107.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
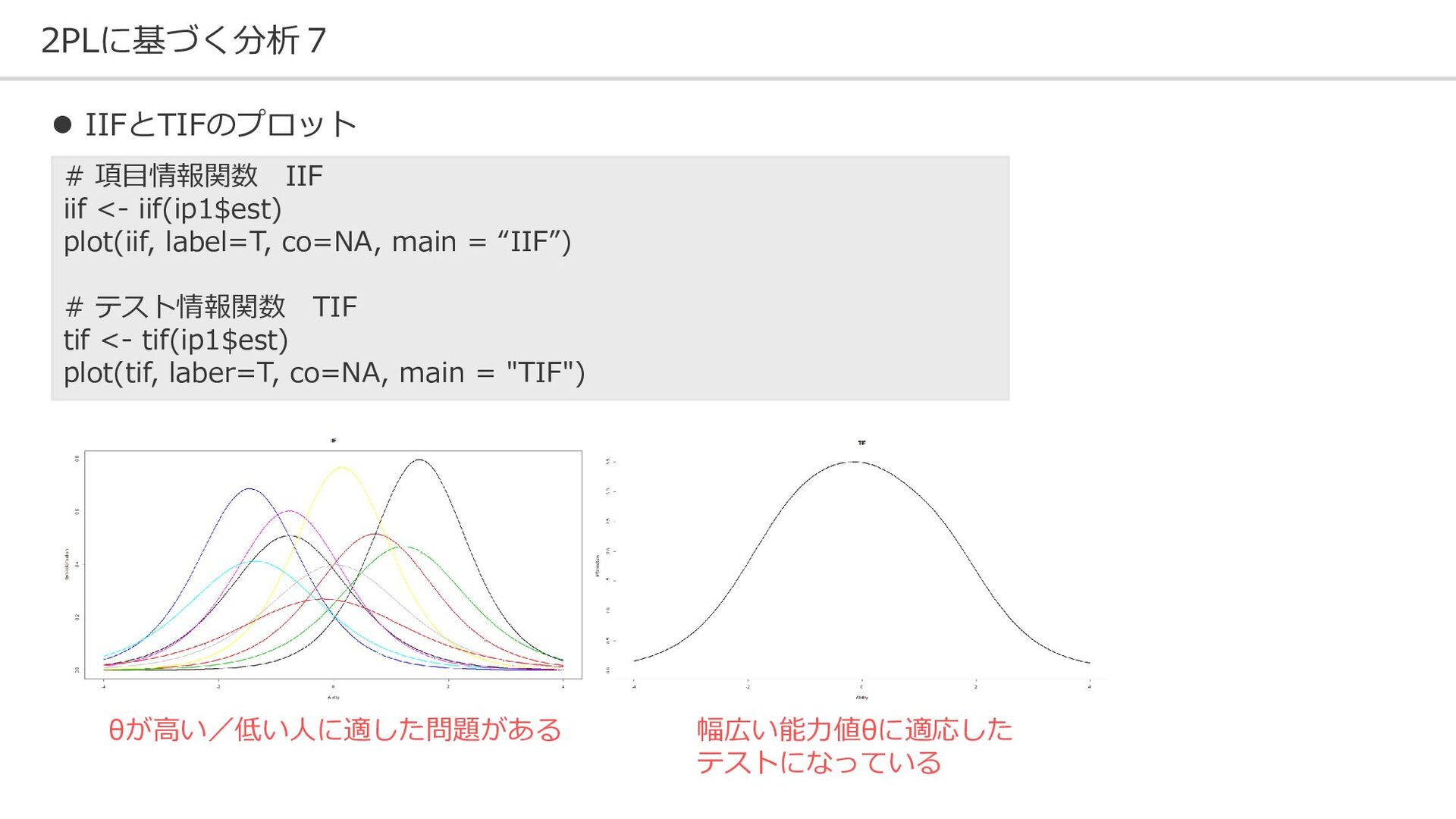{kind=link}
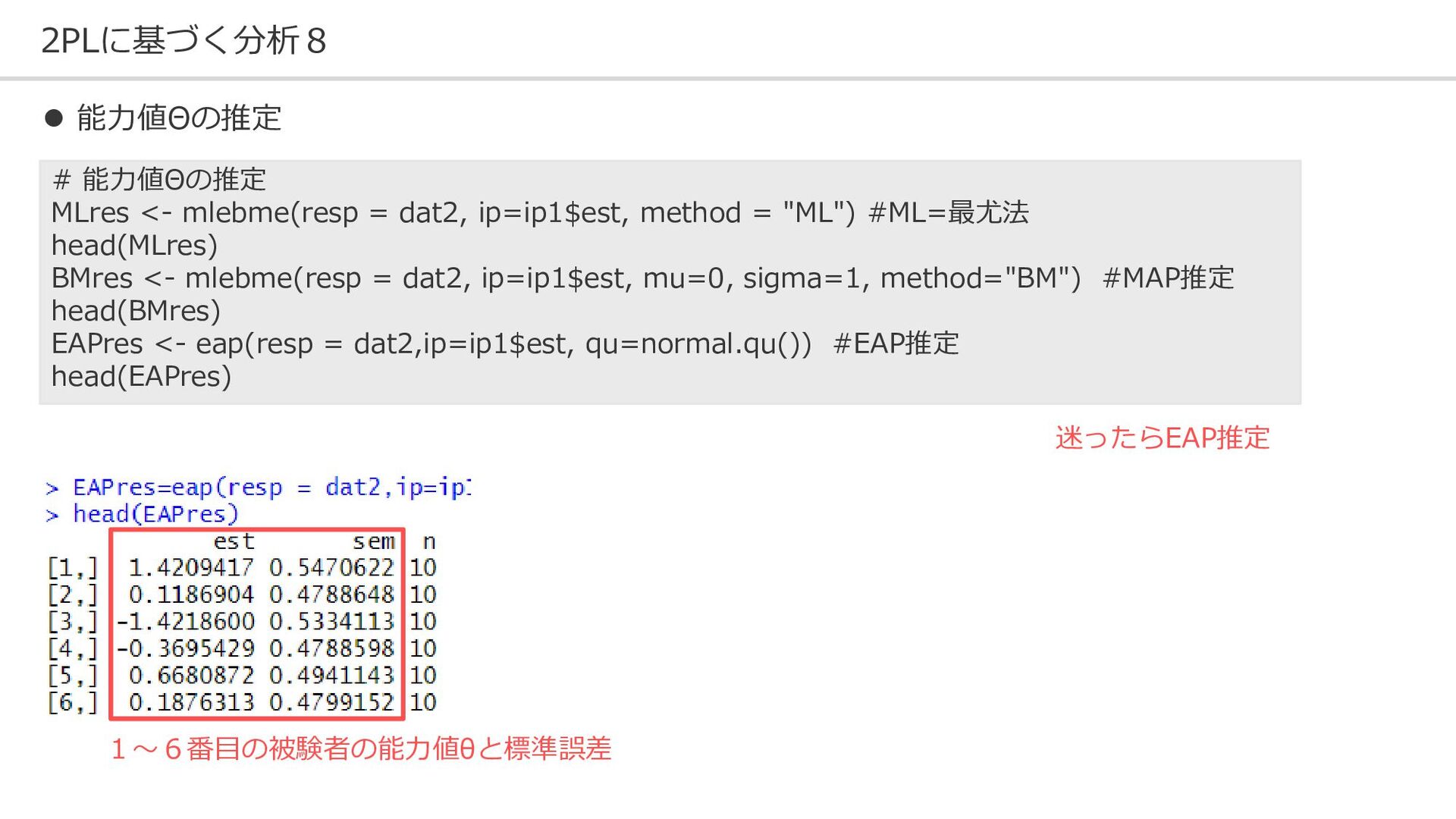{kind=link}
{kind=link}
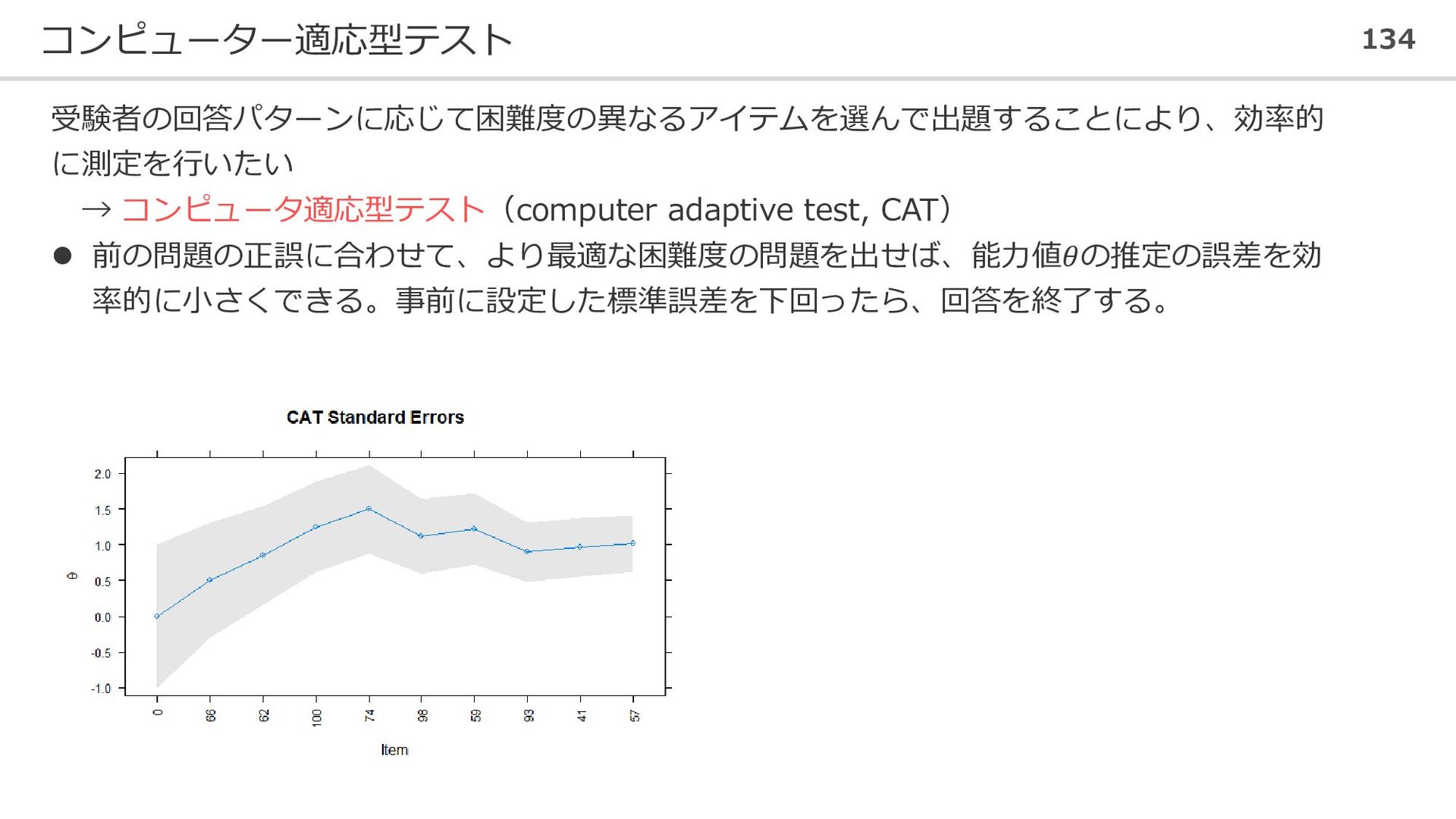{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
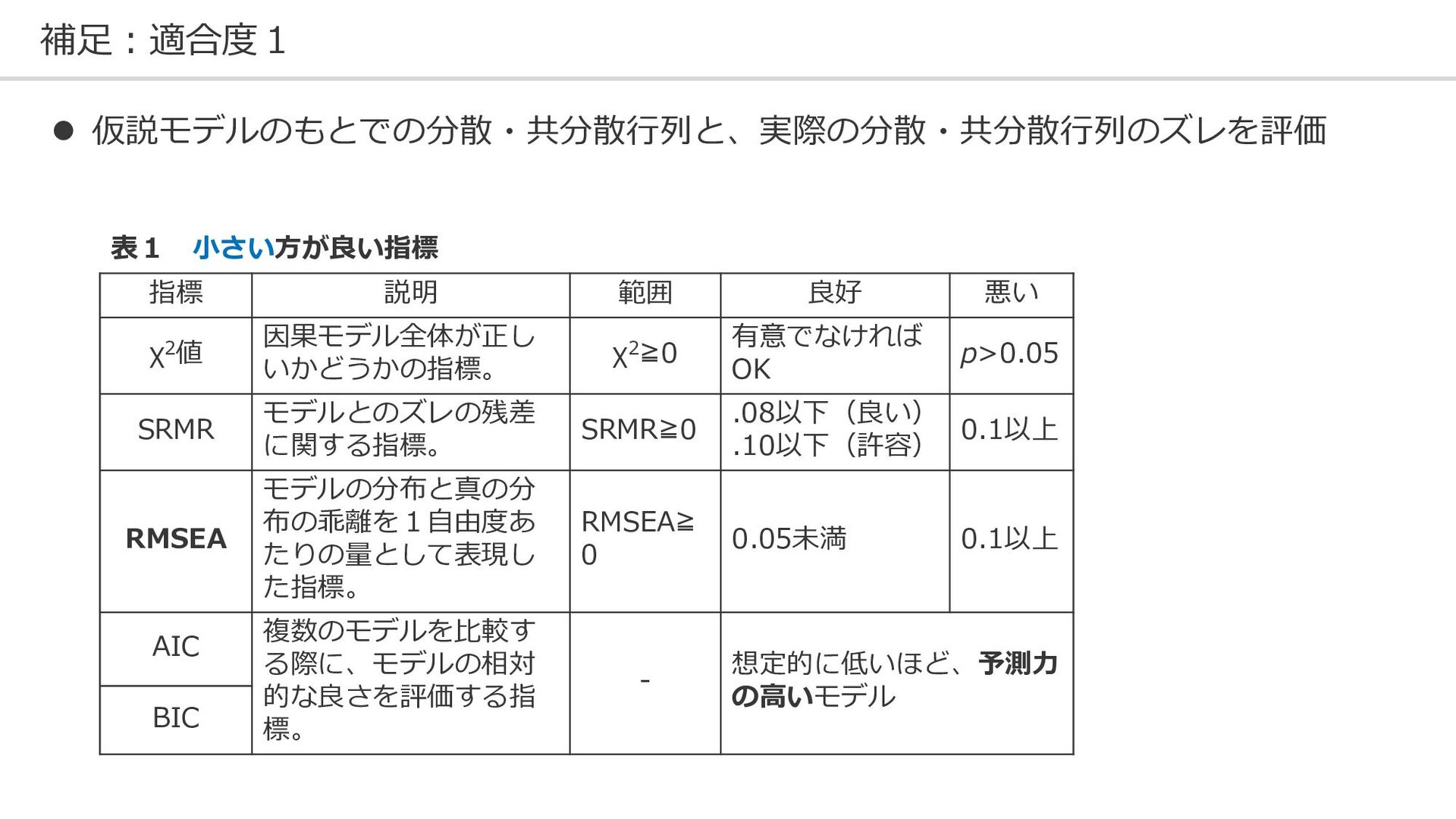{kind=link}
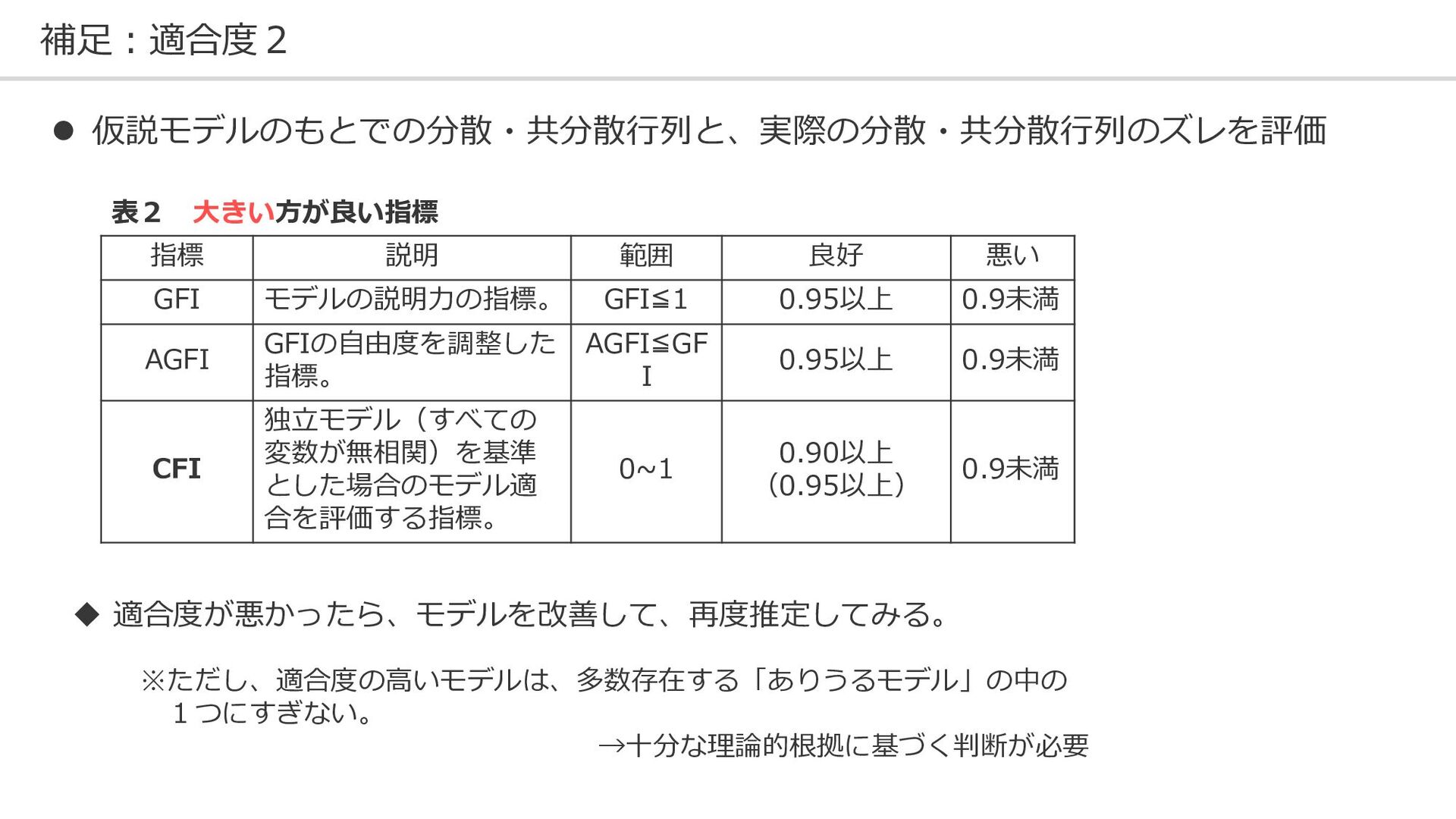{kind=link}
{kind=link}
{kind=link}
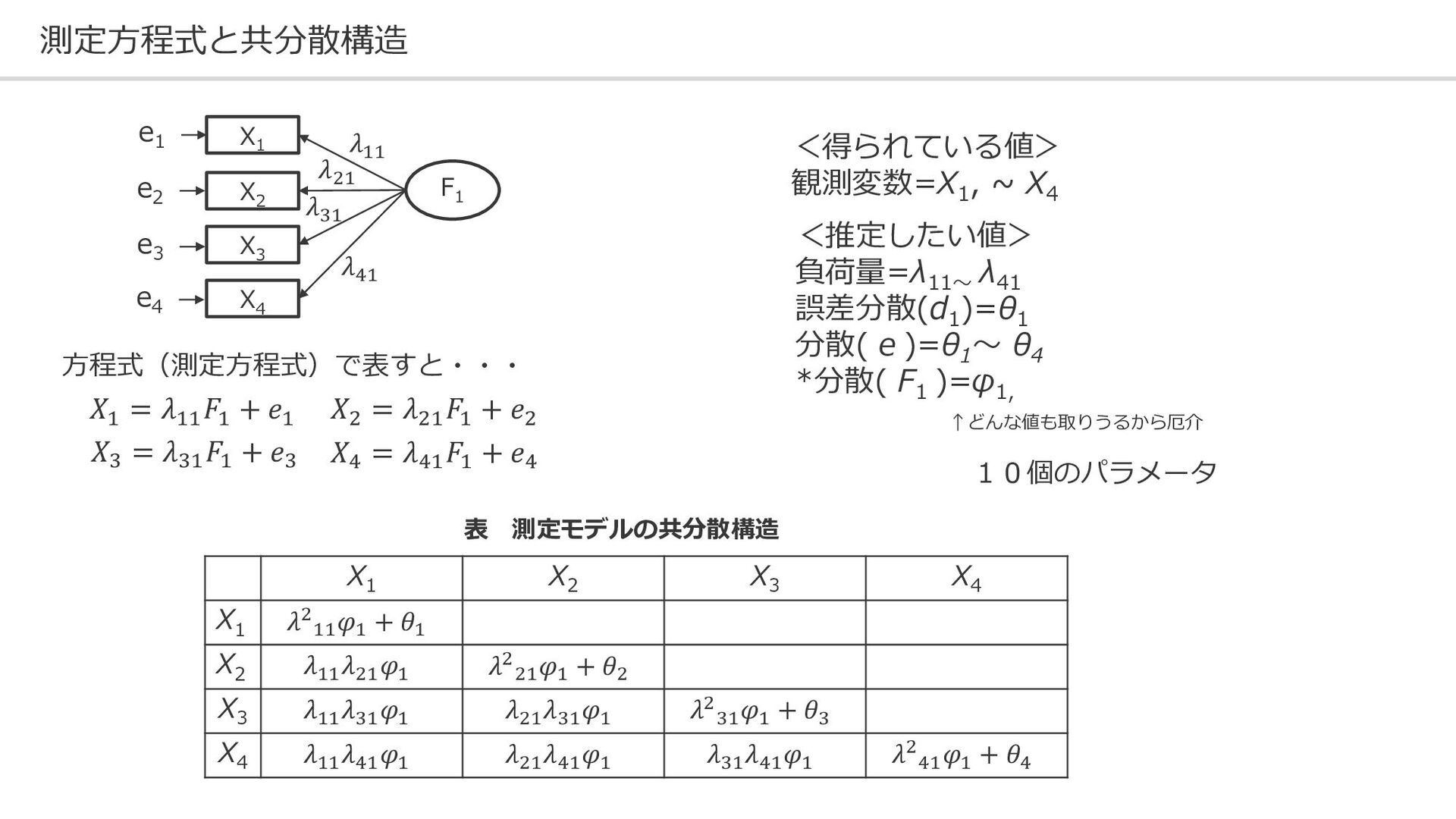{kind=link}
{kind=link}
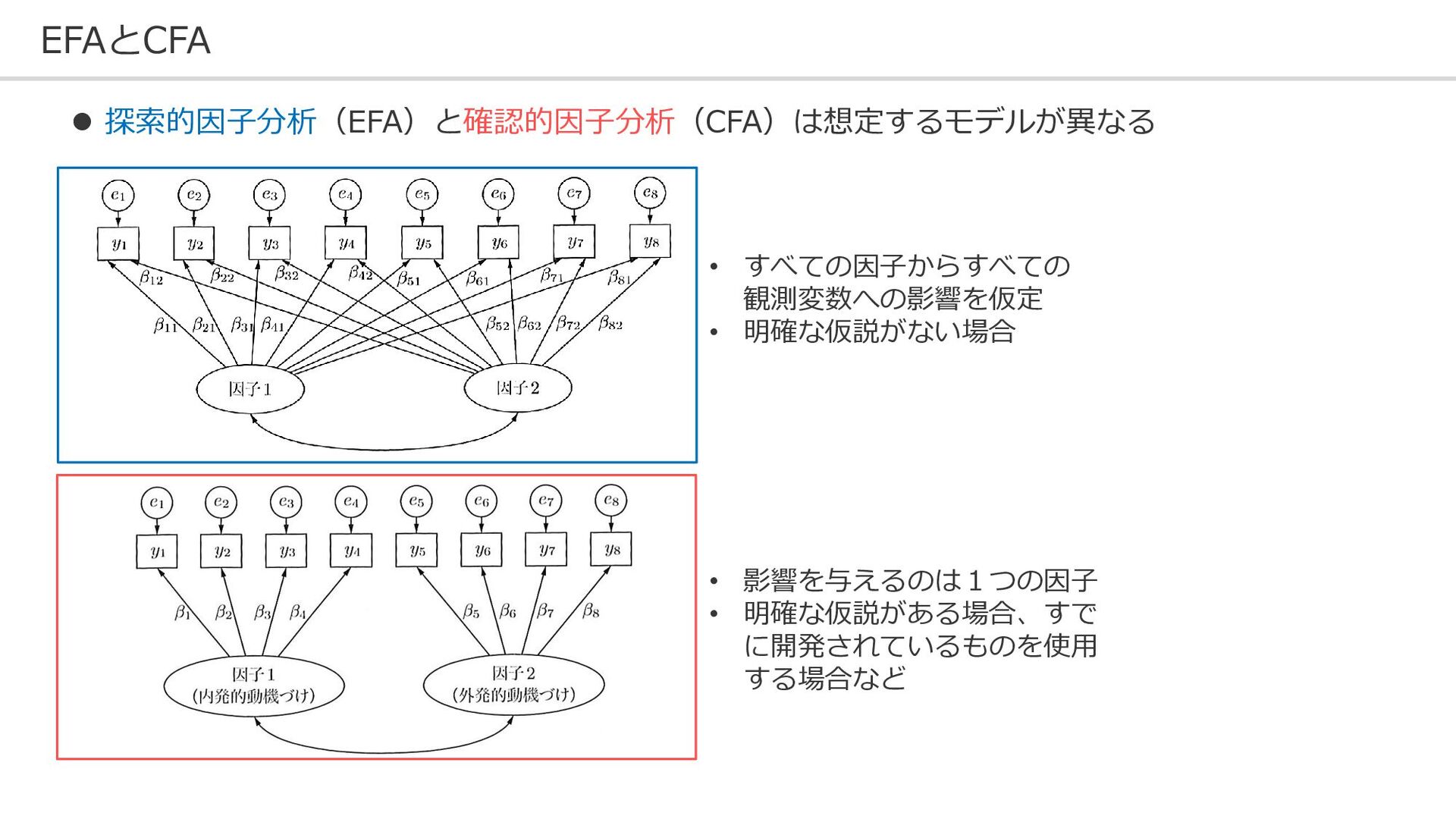{kind=link}
{kind=link}
{kind=link}
![報告例1(確認的因子分析) ◼ 先行研究の知見に基づき、批判的思考に1因子構造を想定した確認的 因子分析を行った。分析の結果、適合度指標は、CFI=1.00, TLI=1.00, RMSEA=.00(90%CI [.00, .06]), SRMR=0.03であり、 データに対するモデルの当てはまりは十分であると判断された。](https://files.speakerdeck.com/presentations/9d922ca48bac4546beca090bf82ad204/slide_202.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}