『言語処理学会第31回年次大会(NLP2025)』(2025年3月10〜14日)にて発表
https://anlp.jp/nlp2025/
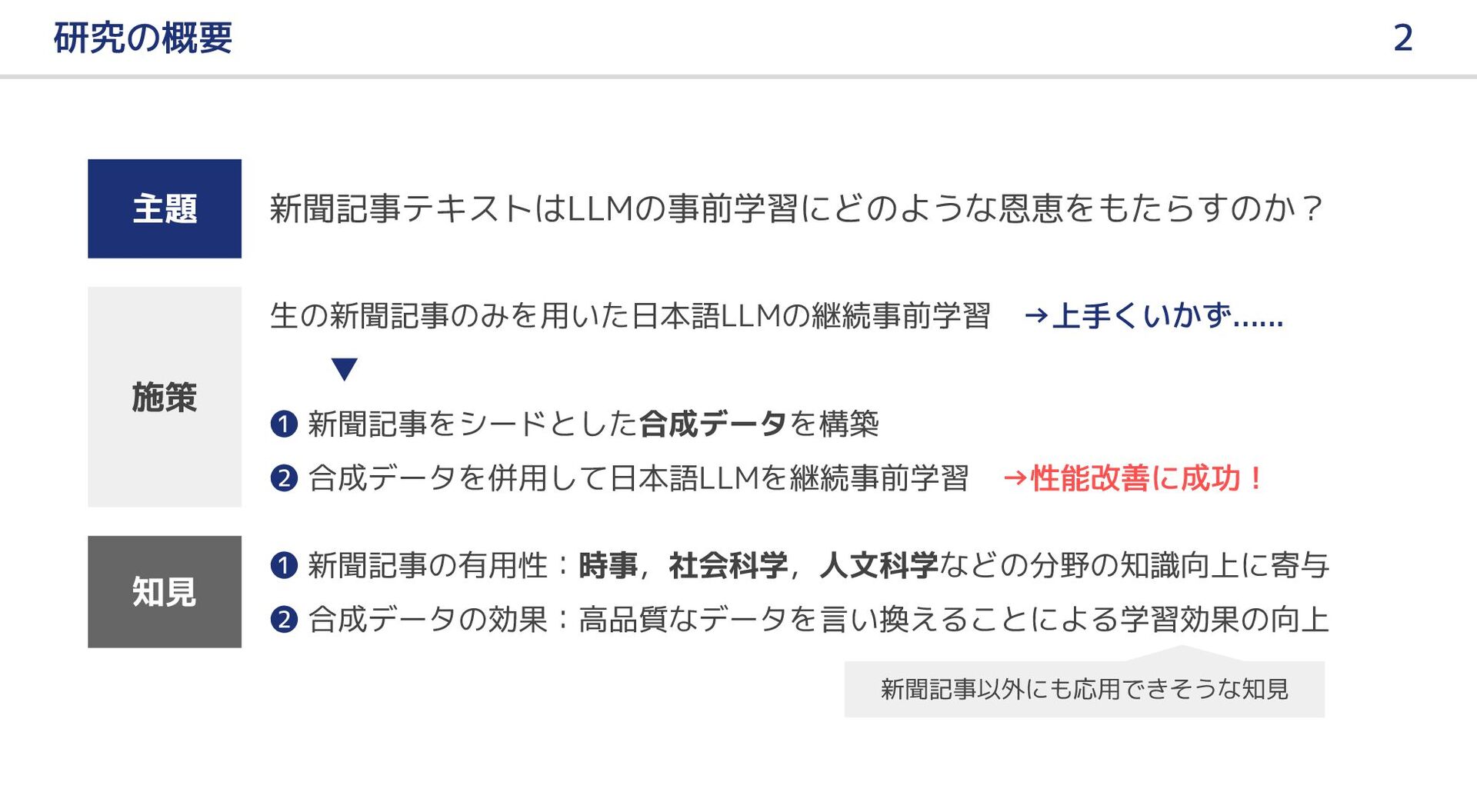
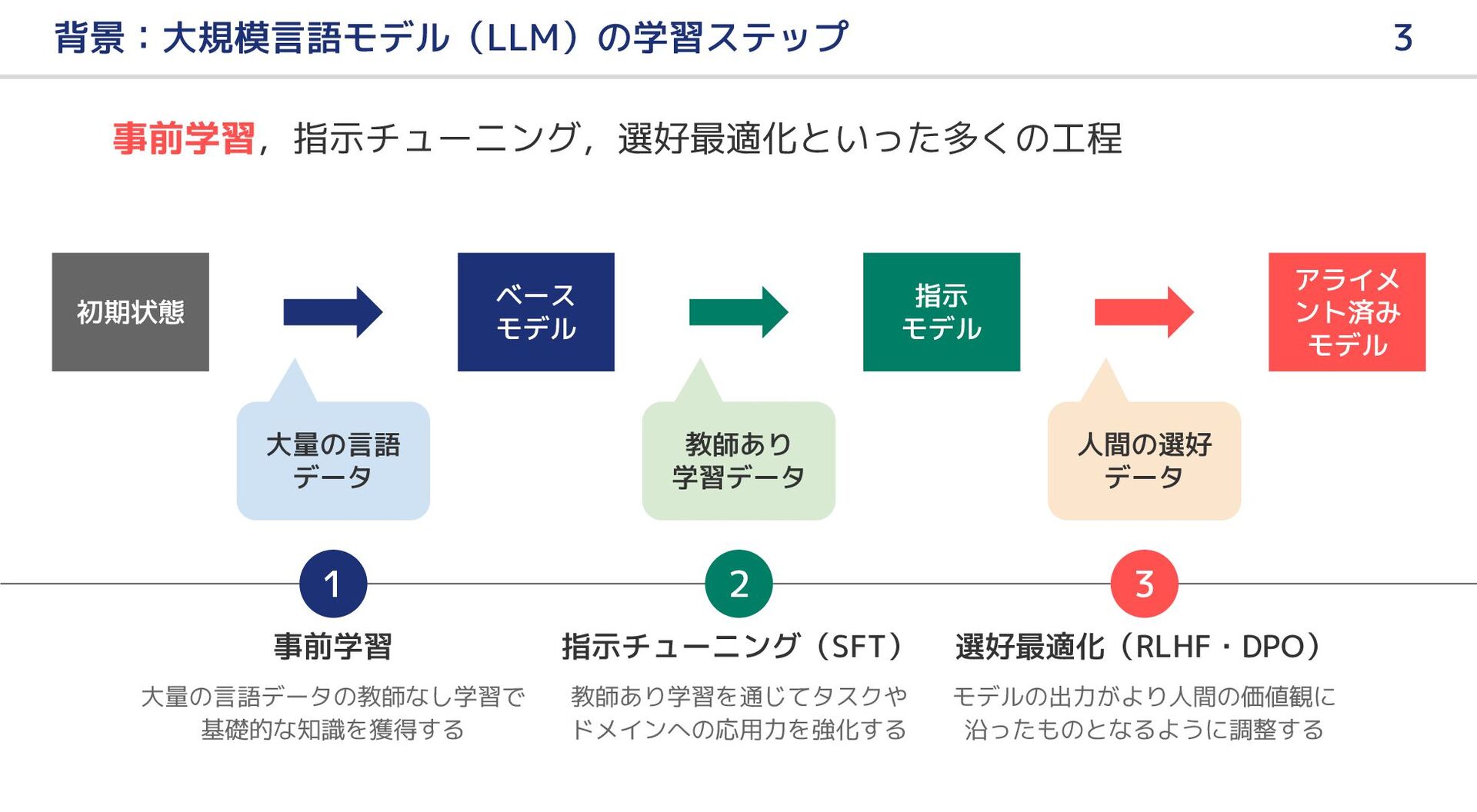
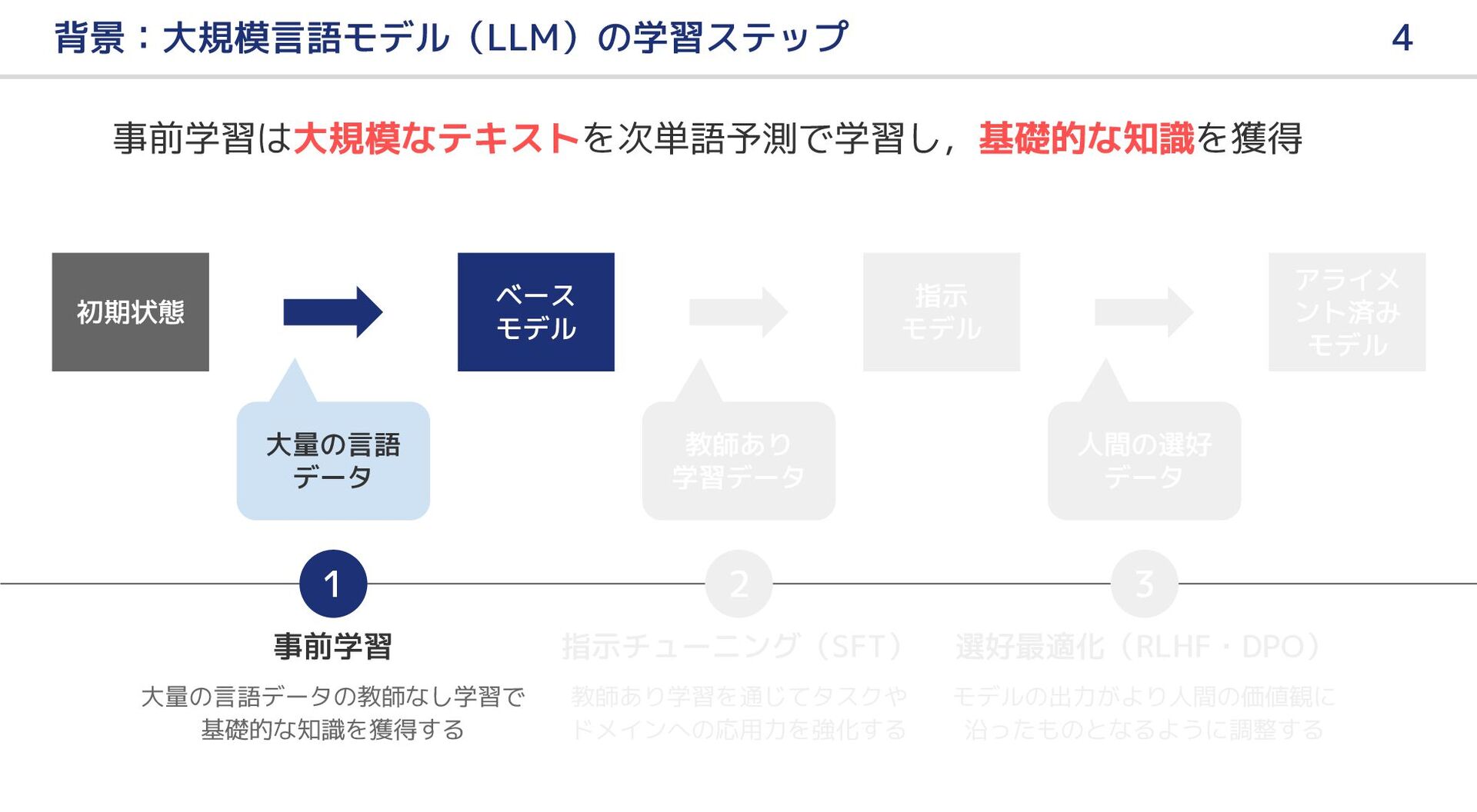
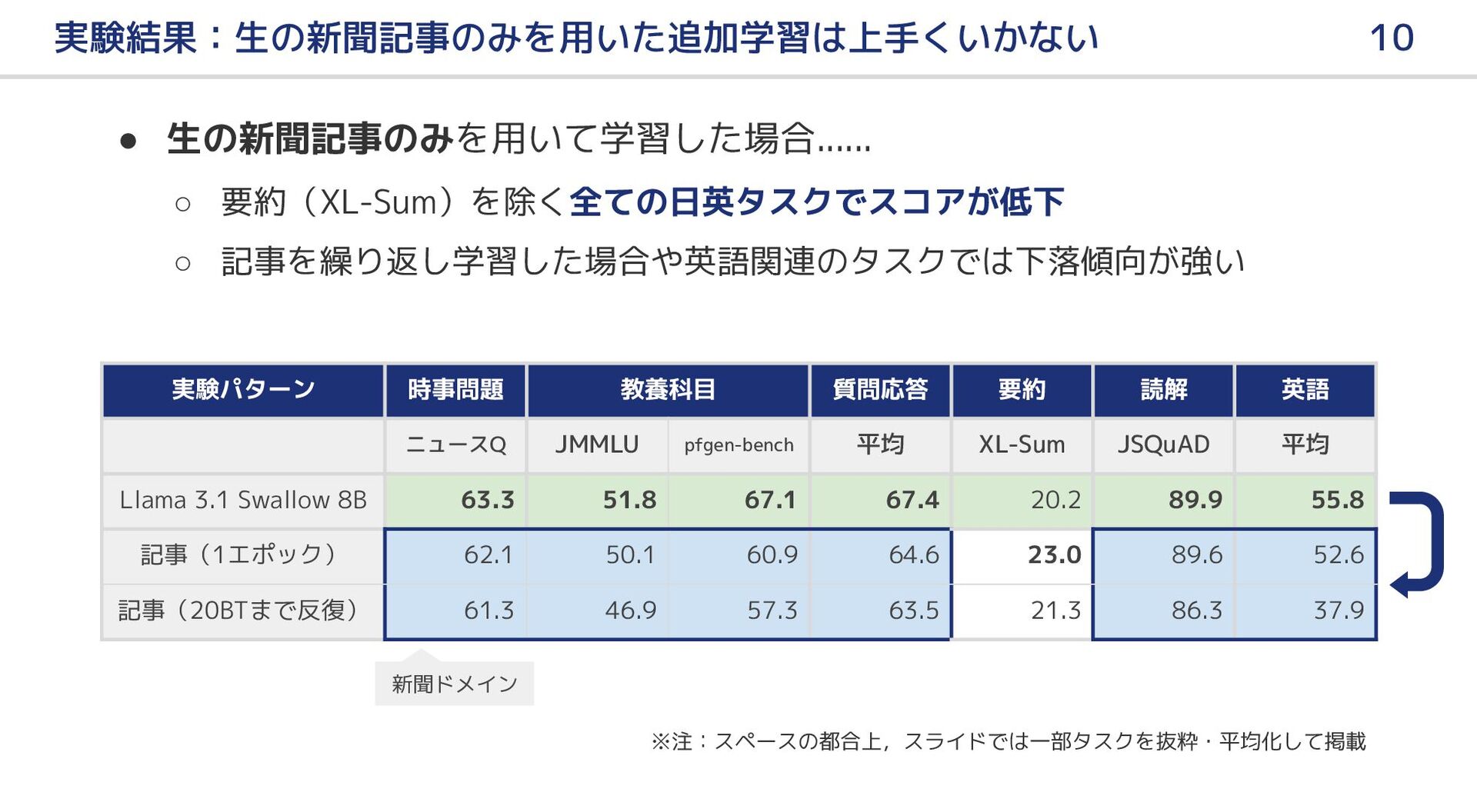
大規模言語モデル(LLM)の事前学習において新聞記事はどのような恩恵をもたらすのか?本研究では,LLM の日本語継続事前学習における新聞記事データの有用性,およびその効果を引き出すための手法について報告する.はじめに,新聞記事のみを用いて LLM の継続事前学習を行ったが,テキスト量と多様性の不足のためか,十分な効果を得ることができなかった.そこで,ドメイン適応の既存研究を参考に,新聞記事をシードとして LLM で合成データを生成し,継続事前学習のデータに追加した.実験の結果,合成データを併用することにより前述の問題を解消し,新聞記事に関連する分野を中心に,LLM の日本語能力が向上した.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![研究課題:新聞記事を用いた日本語LLMのさらなる強化 6 新聞記事を用いた継続事前学習で日本語LLMの能力はさらに向上するか? ドメイン適応に近い実験設定,新聞記事から追加の知識を獲得できるか? [1] Swallowコーパスv2: 教育的な日本語ウェブコーパスの構築(NLP2025) ベースLLM Llama 3.1](https://files.speakerdeck.com/presentations/e8897be977584fddb9b9475fe870f025/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![実験設定:新聞ドメインのタスクでの評価 9 ニュース Q [2] • 2022~2023年度の朝日新聞記事を元に作成された 3~4 択のQA集 •](https://files.speakerdeck.com/presentations/e8897be977584fddb9b9475fe870f025/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![提案手法:新聞記事をシードとしてLLMで合成データを生成する 12 既存研究[5,6]を参考に,新聞記事を元にした合成データをLLMで生成 目的:新聞記事に含まれる知識を多様な表現に変換し,LLMへの定着を促す [5] https://arxiv.org/abs/2409.07431 [6] https://arxiv.org/abs/2309.09530 LLMを用いて 記事を言い換えた](https://files.speakerdeck.com/presentations/e8897be977584fddb9b9475fe870f025/slide_11.jpg){kind=link}
{kind=link}
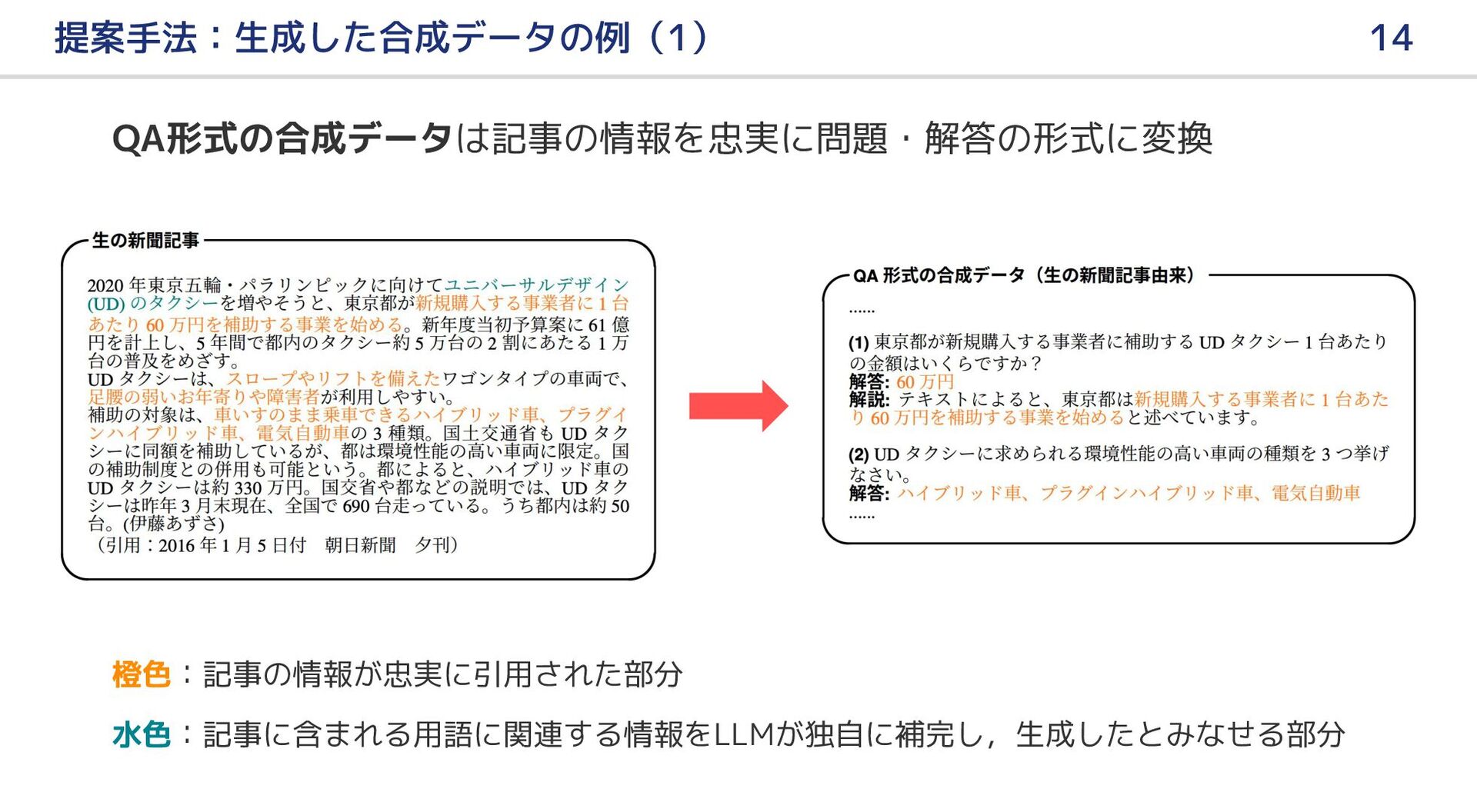{kind=link}
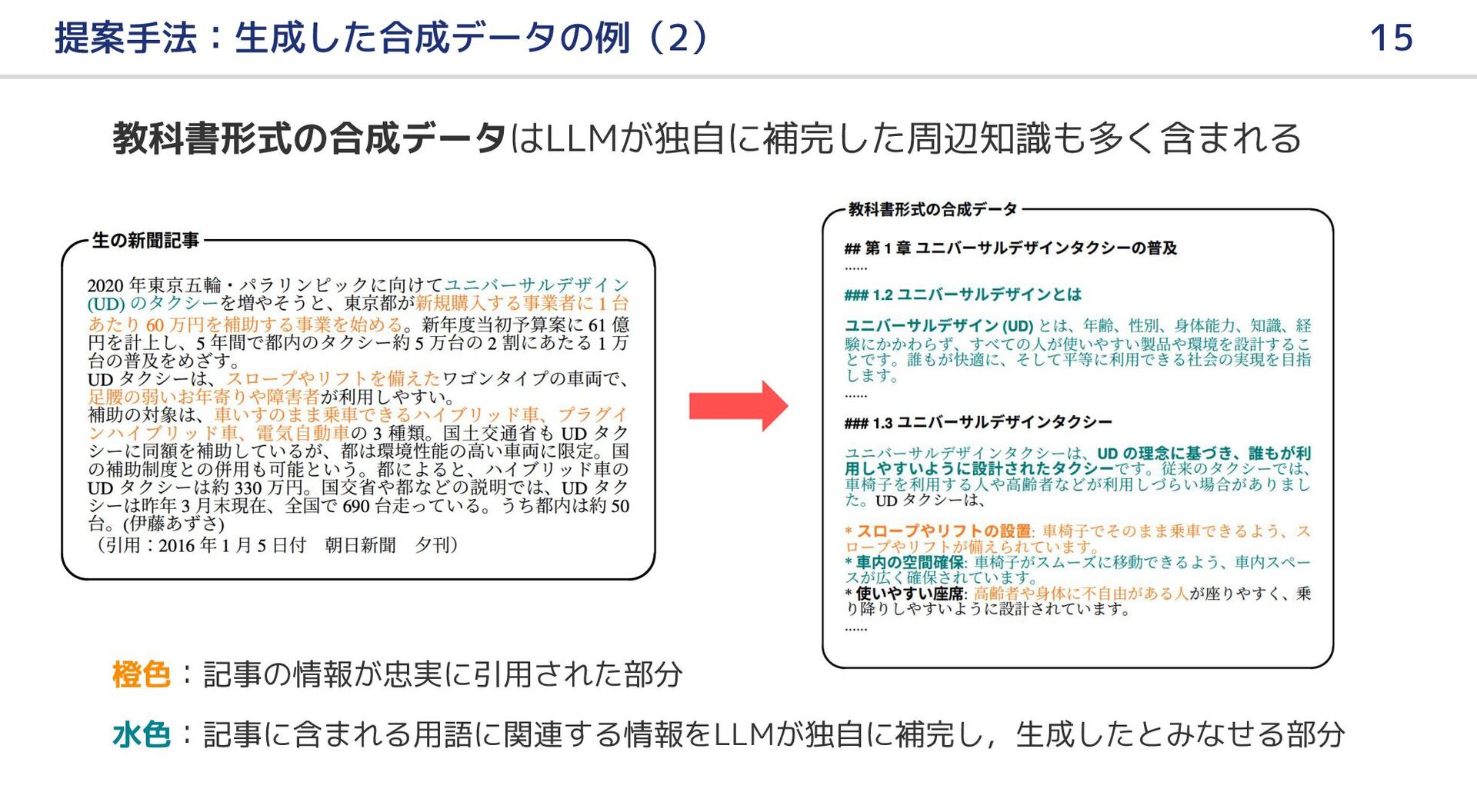{kind=link}
{kind=link}
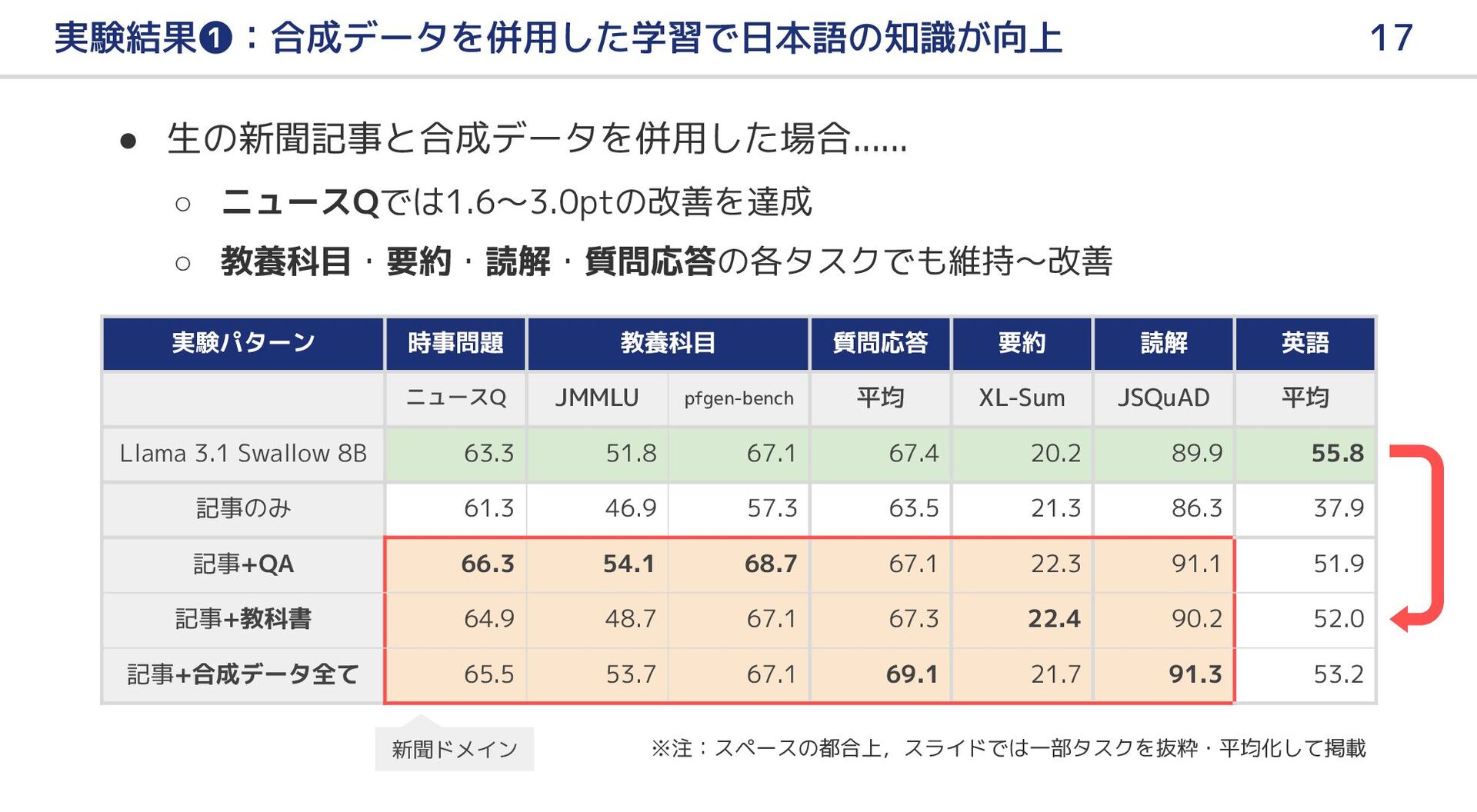{kind=link}
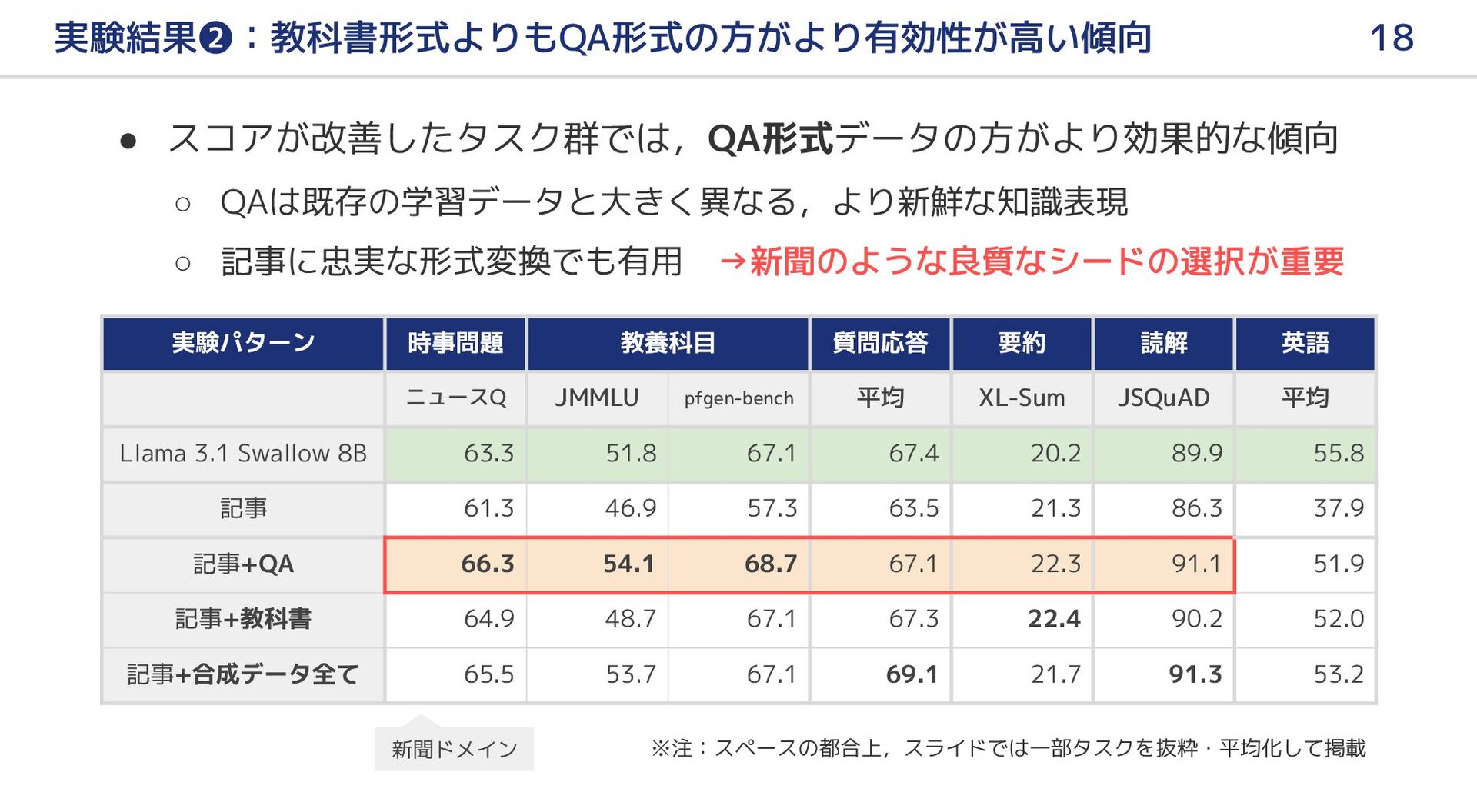{kind=link}
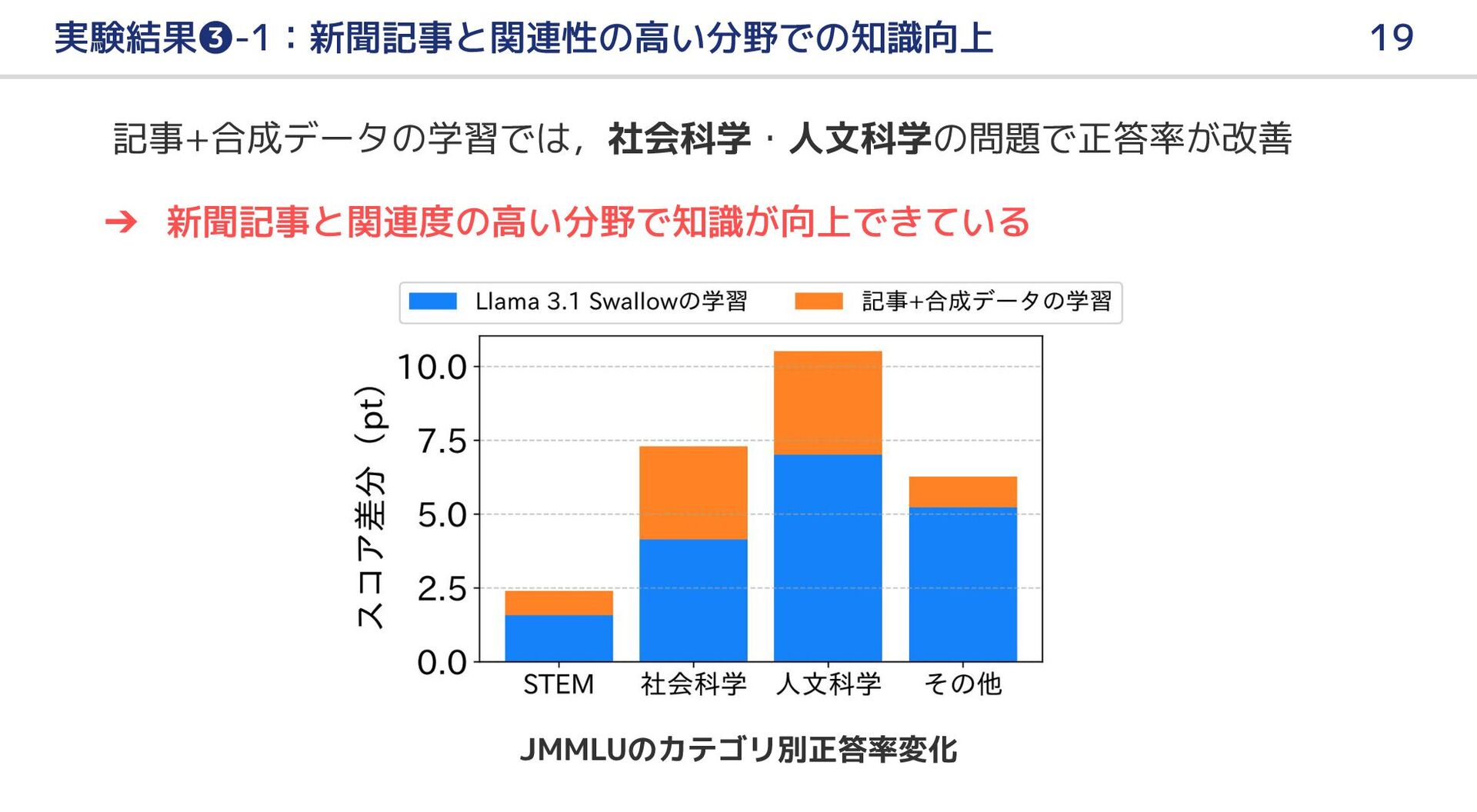{kind=link}
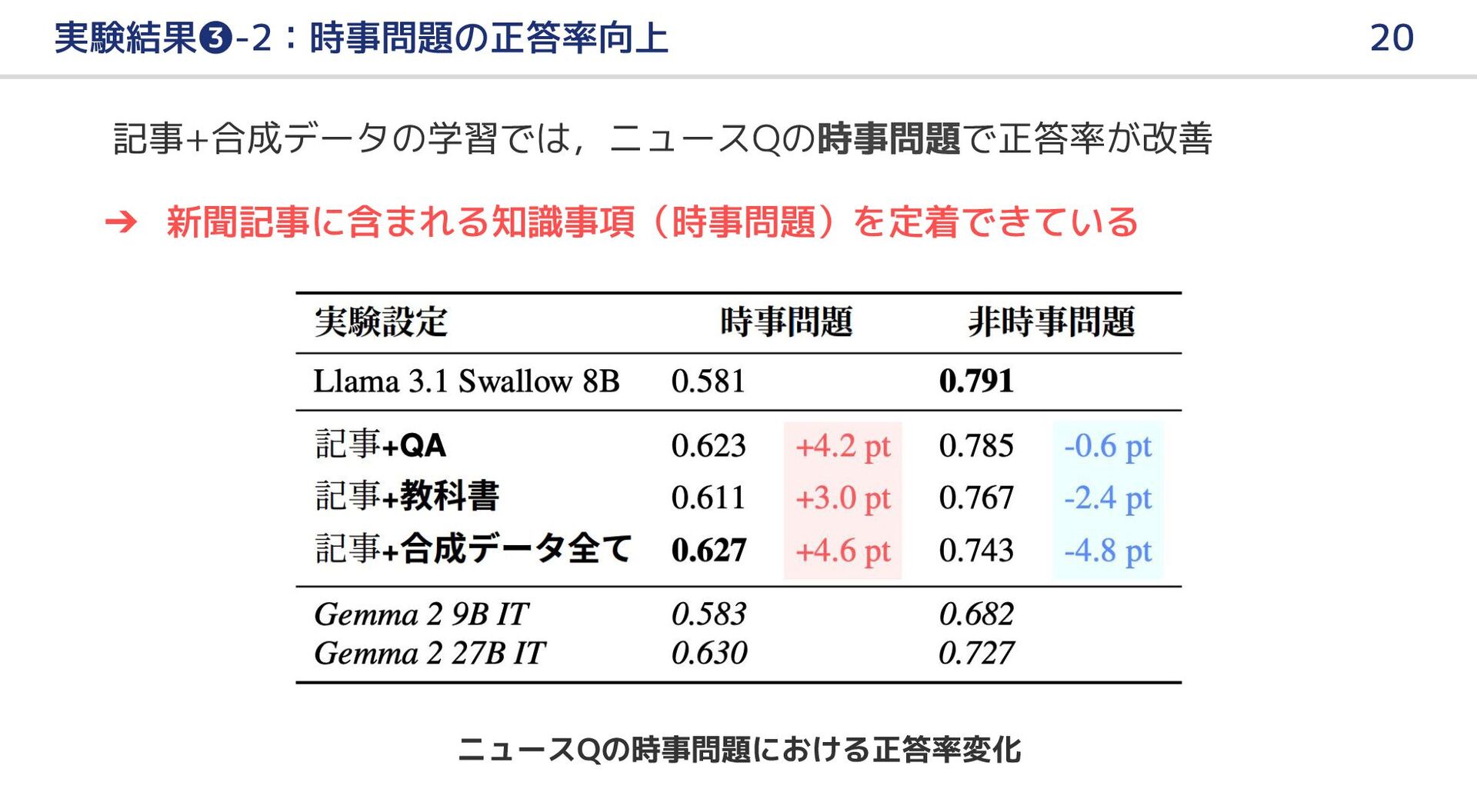{kind=link}
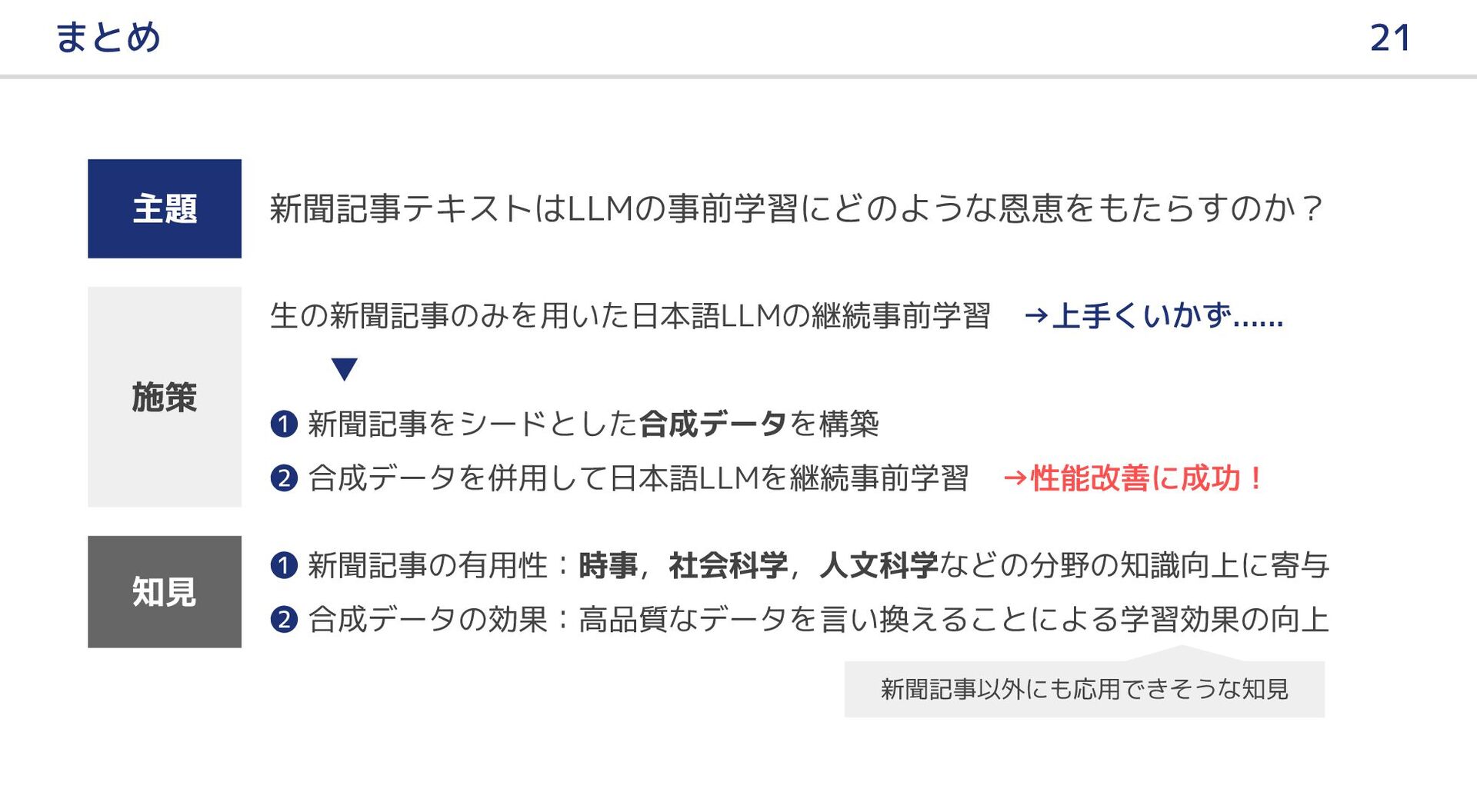{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}