『言語処理学会第31回年次大会(NLP2025)』(2025年3月10〜14日)にて発表
https://anlp.jp/nlp2025/
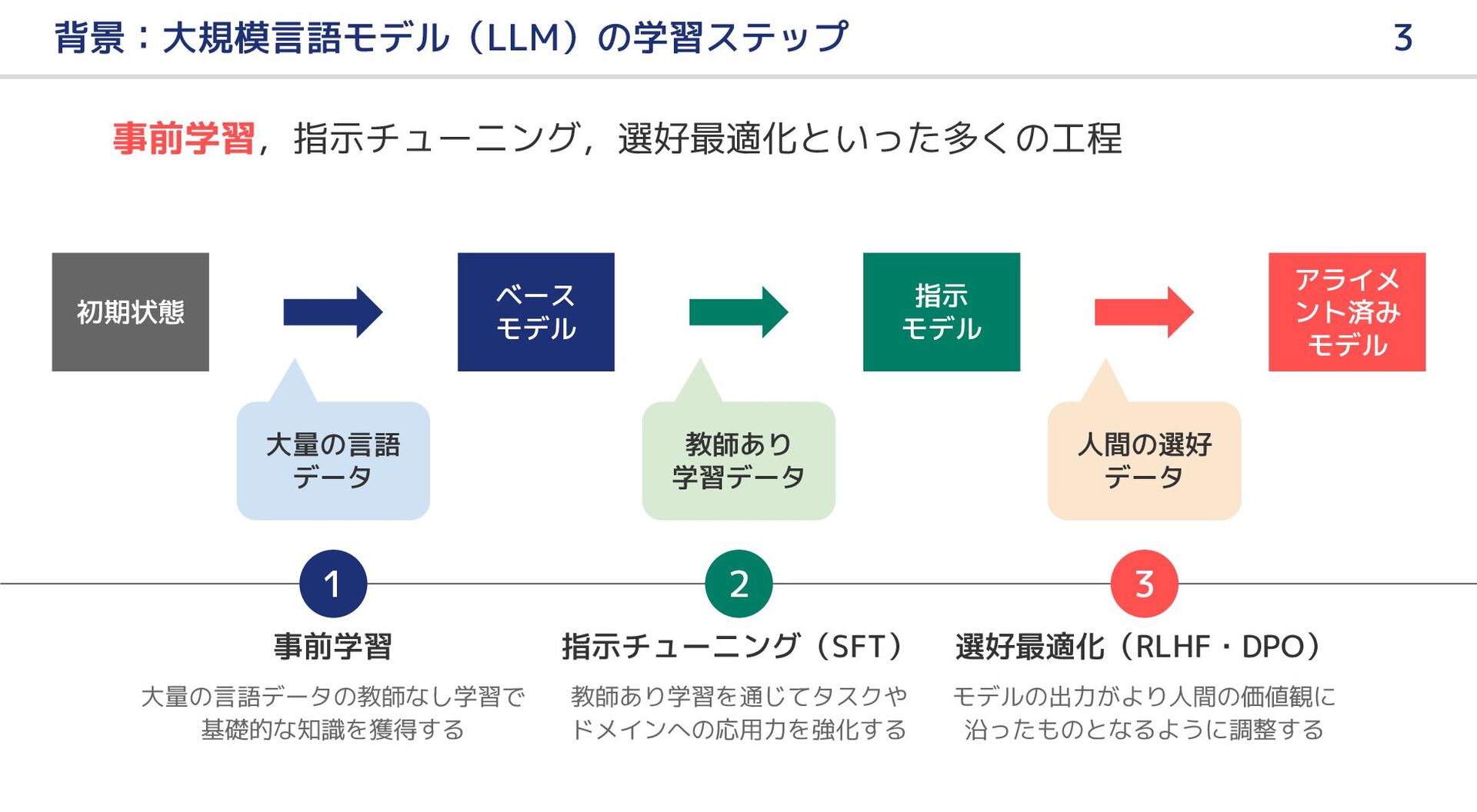
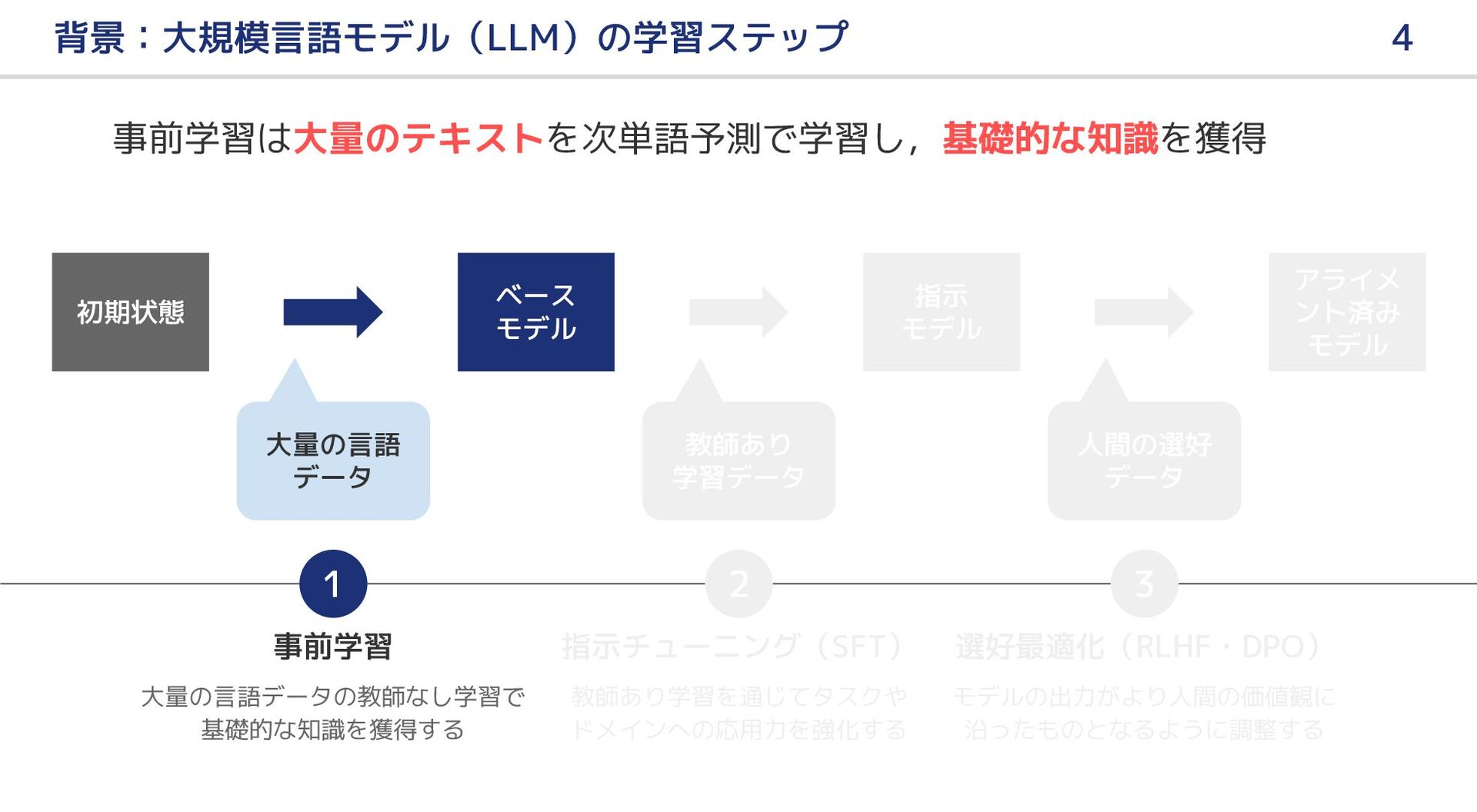
大規模言語モデル(LLM)の事前学習では,高品質なテキストを用いることが望ましい.本研究では,文書の「教育的価値」に着目した 2 種類の軽量な分類器を構築して,各文書に品質スコアを付与し,大規模日本語ウェブコーパスから高品質なテキストを抽出する手法を提案する.実験により,提案手法を適用することで,同等の学習計算規模で日本語の知識に関する LLM の能力をより効率的に向上できることを示した.また,分類器の特性比較,ヒューリスティック・ルールの調整,学習のエポック数を増やす実験などを通じて,提案手法の実用性や LLM 構築の最良慣行について検証する.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![背景:事前学習Webコーパスにおける品質フィルタリング 6 ルールに基づくフィルタリングでWebデータによる事前学習の効果が向上[1] • 直近の既存研究[2][3](英語)は,分類器による品質判定の有効性を主張 • 分類器による教育的なテキストの抽出がLLMの性能向上に貢献[2] [1] https://arxiv.org/abs/2404.17733 [2]](https://files.speakerdeck.com/presentations/821eb10847ab4c3b87cf85e9554c8f73/slide_5.jpg){kind=link}
![提案手法:日本語Webコーパスの品質フィルタリング改善 7 分類器の導入で日本語Webコーパスから教育的なテキストを厳選 [1] https://arxiv.org/abs/2404.17733 フィルタリング前の 日本語Webコーパス ルールに基づく フィルタリング 高品質(?)な](https://files.speakerdeck.com/presentations/821eb10847ab4c3b87cf85e9554c8f73/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
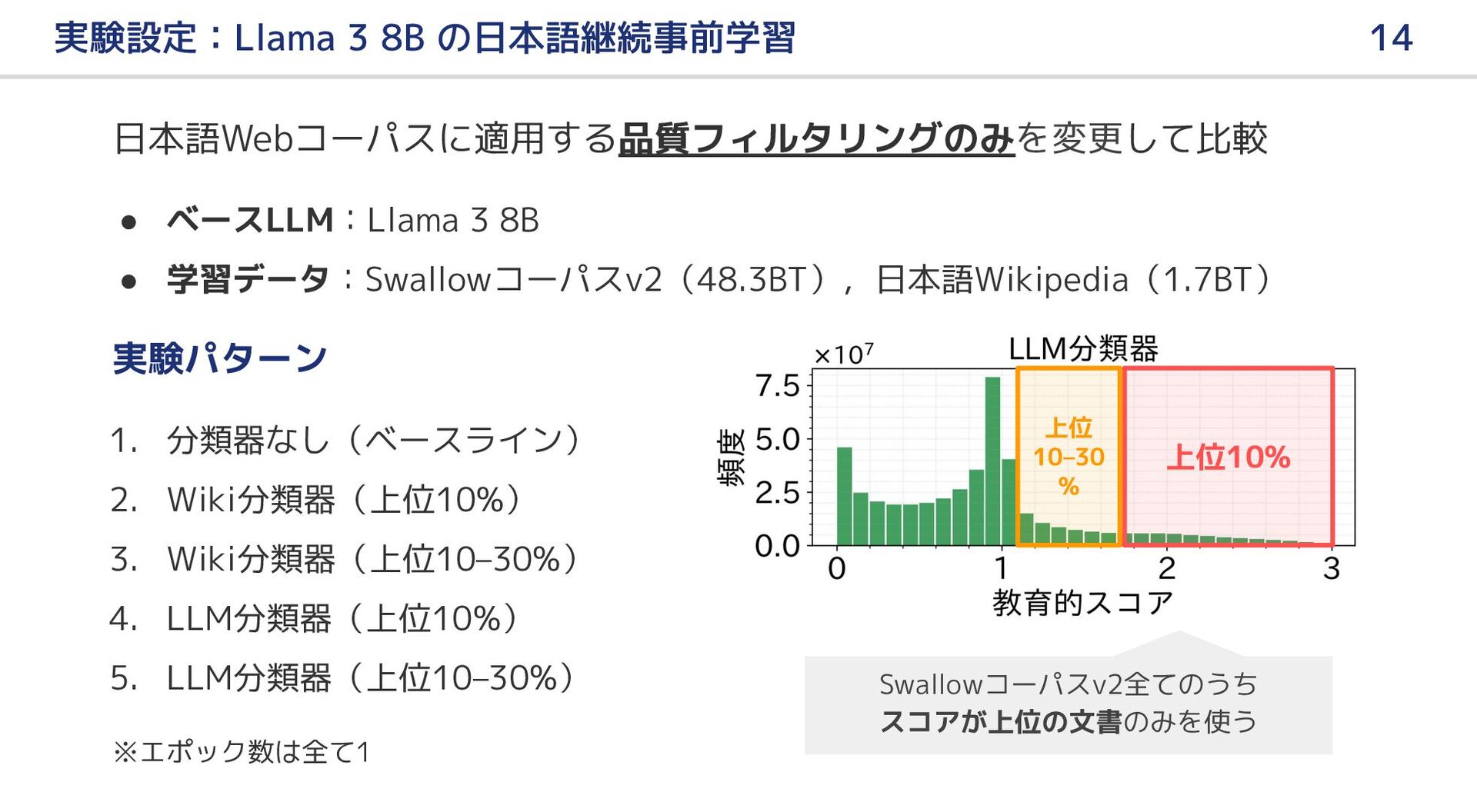{kind=link}
{kind=link}
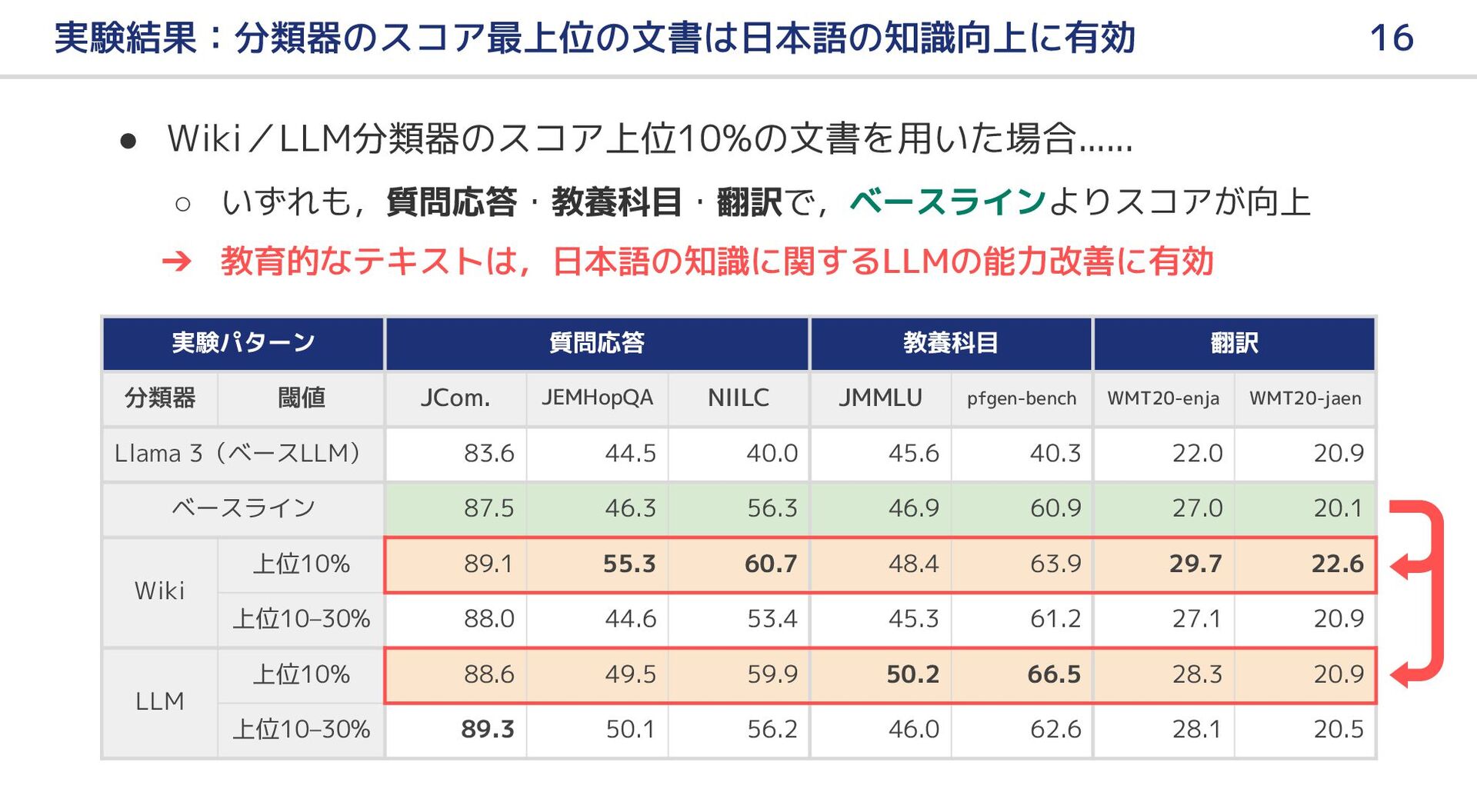{kind=link}
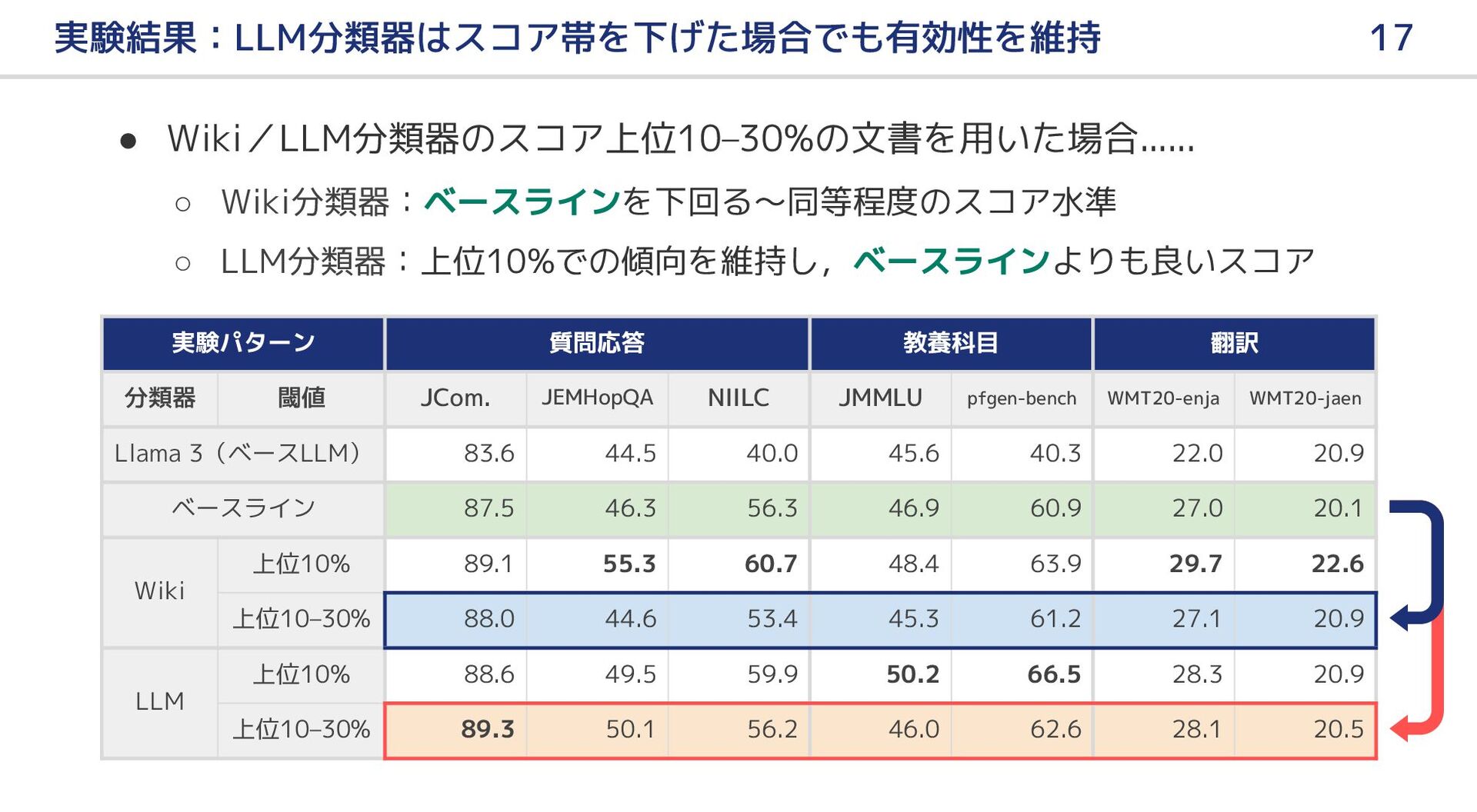{kind=link}
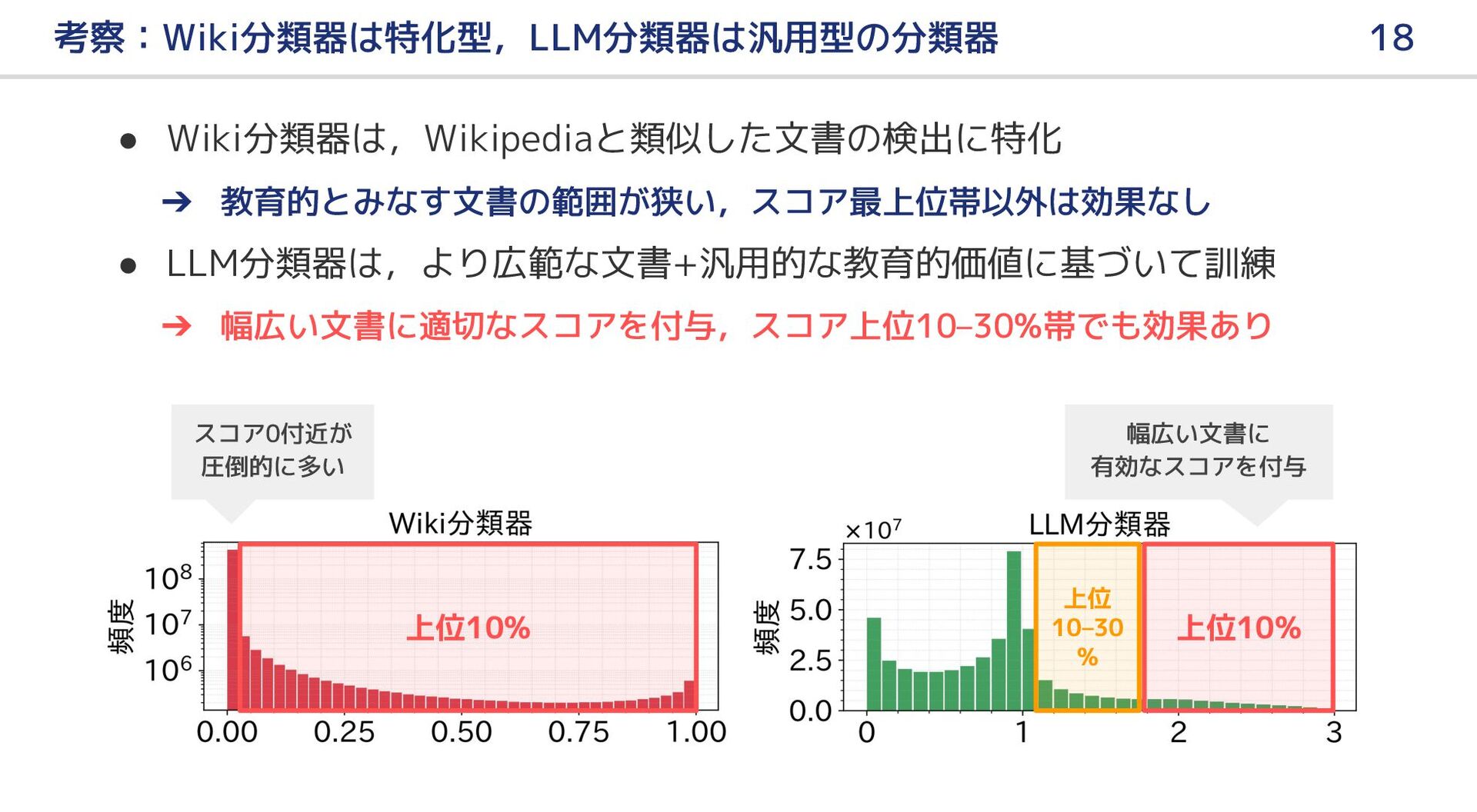{kind=link}
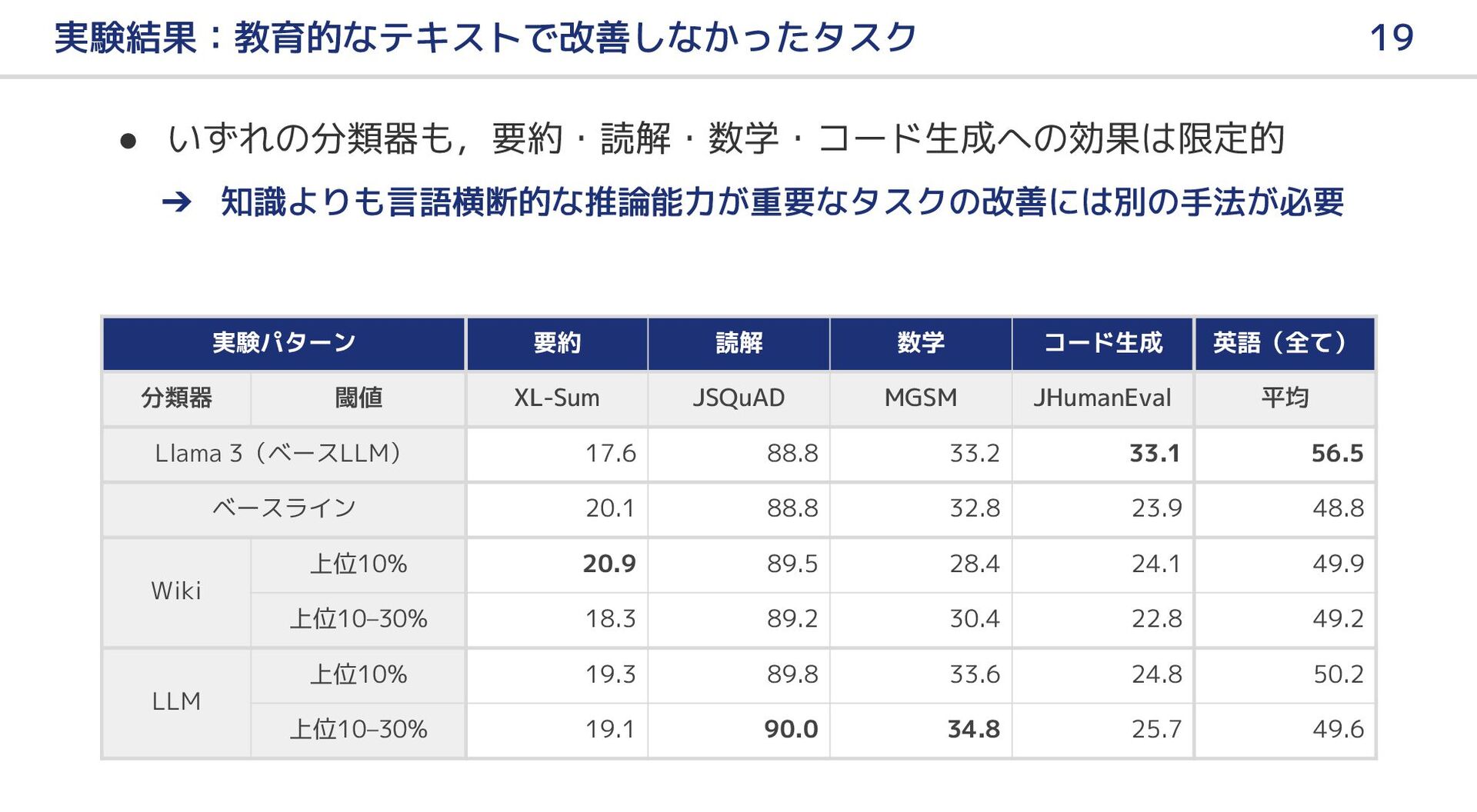{kind=link}
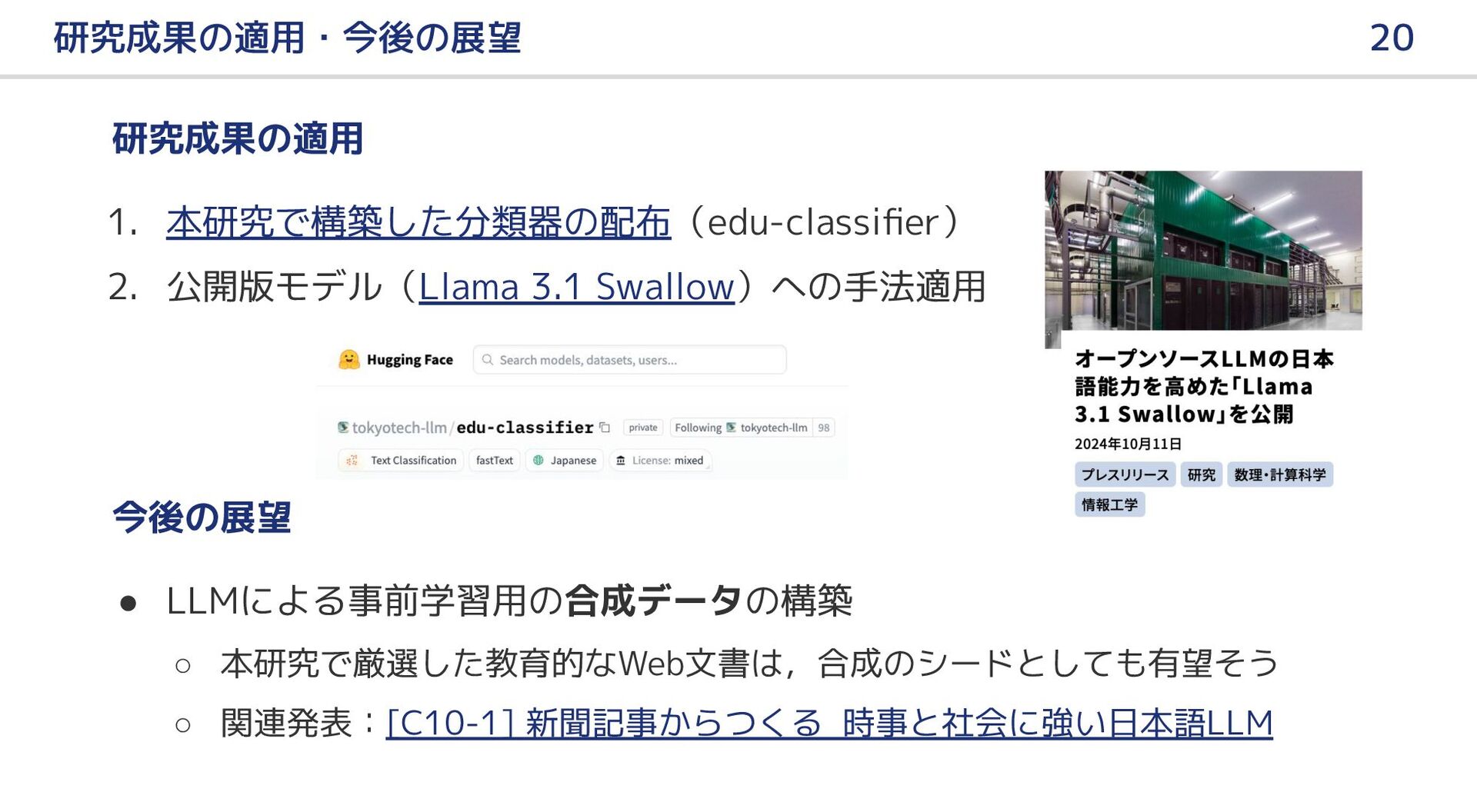{kind=link}
{kind=link}
{kind=link}
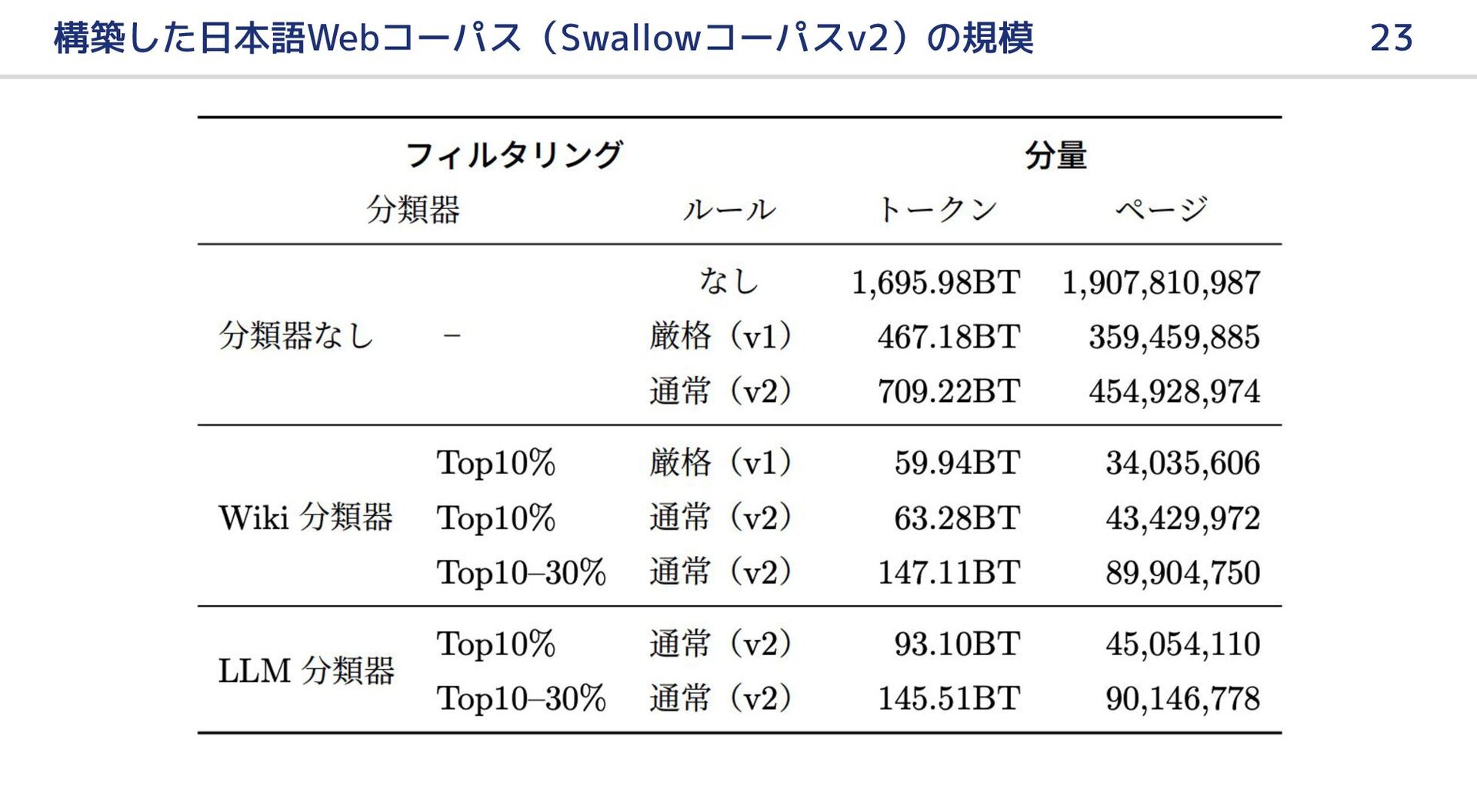{kind=link}
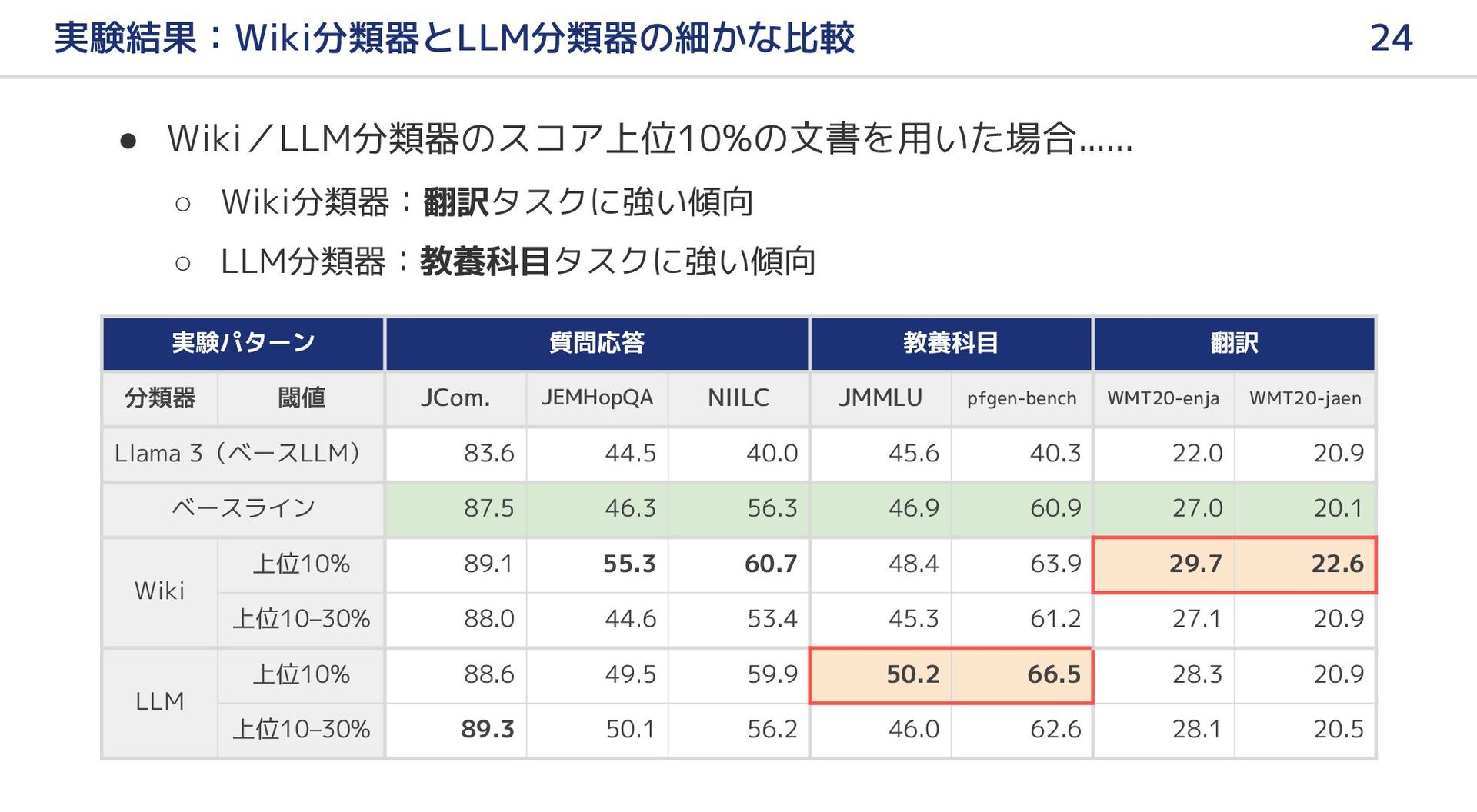{kind=link}
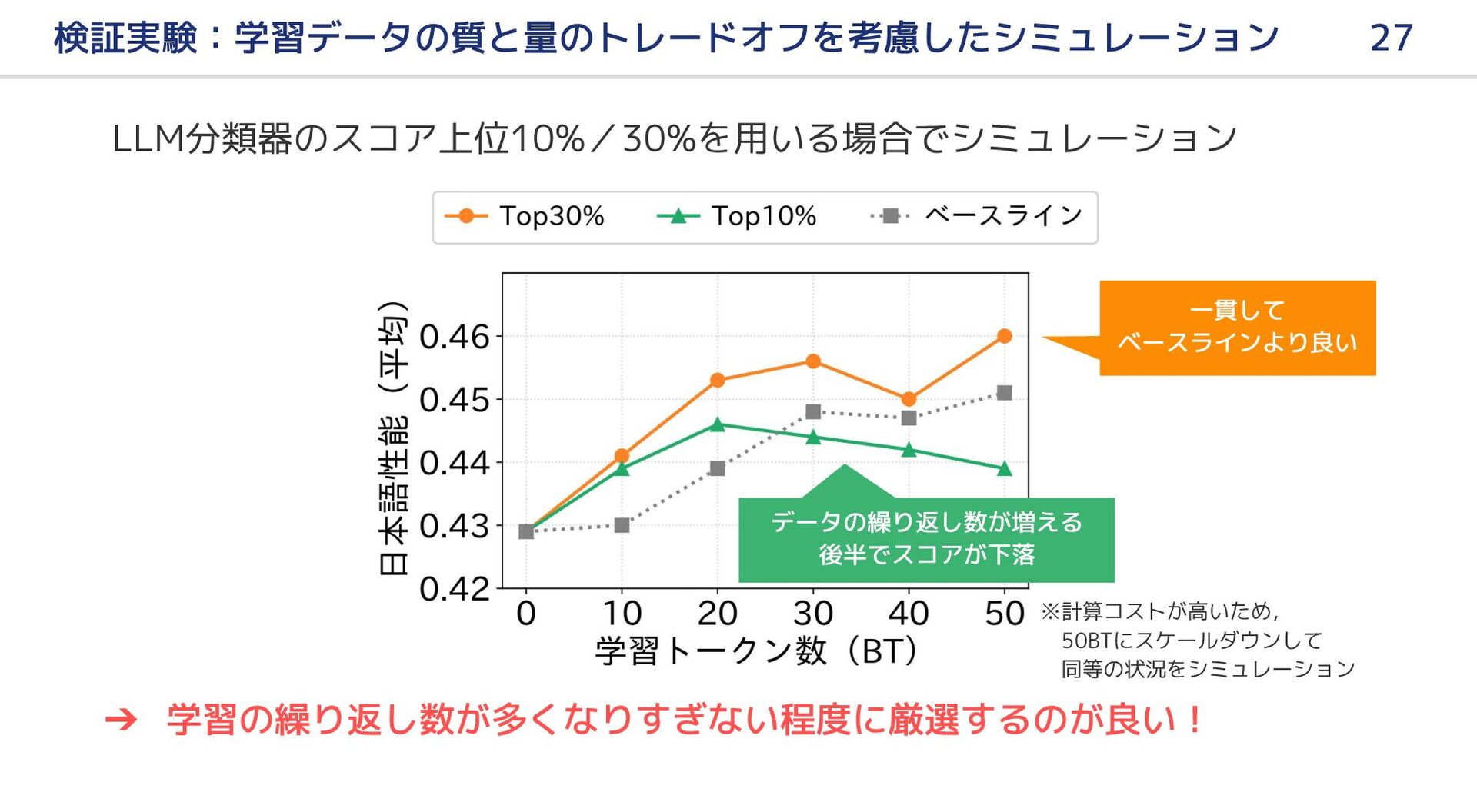
![課題:学習データの質と量のトレードオフ問題(1) 25 LLMのスケーリング則[4]を考慮すると,学習トークン量の確保も重要 ➢ 少資源の日本語では,英語よりもデータ不足に直面しやすい [4] https://arxiv.org/abs/2001.08361 50 BT 本研究の実験](https://files.speakerdeck.com/presentations/821eb10847ab4c3b87cf85e9554c8f73/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}