Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ウォンテッドリーにおける Platform Engineering
Search
Atsushi Tanaka
April 07, 2025
Technology
800
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ウォンテッドリーにおける Platform Engineering
Platform Engineering Meetup #12
https://platformengineering.connpass.com/event/348986/
Atsushi Tanaka
April 07, 2025
More Decks by Atsushi Tanaka
See All by Atsushi Tanaka
OpenCensusと歩んだ7年間
bgpat
0
670
SREだけど社内営業組織の業務改善をしてみた
bgpat
0
870
Wantedly での Datadog 活用事例
bgpat
2
6.3k
KubernetesでDatadogを飼うならオートディスカバリーを使わないと損
bgpat
2
1.1k
マイクロサービス基盤にフルマネージドサービスではなくKubernetesを選択する理由
bgpat
12
4.6k
400万ユーザーに価値を届けるエンジニアを を支えるインフラ基盤
bgpat
3
550
Ruby製社内ツールのGo移行
bgpat
2
860
導入から5年が経って見えた Datadog APM 運用の課題
bgpat
4
1.5k
取っていてよかった Kubernetes のバックアップ
bgpat
1
990
Other Decks in Technology
See All in Technology
穢れた技術選定について
watany
16
4.8k
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
330
シンガポールで登壇してきます
yama3133
0
210
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
260
AI Driven AI Governance
pict3
0
450
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
3
920
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.3k
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
270
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
0
160
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
130
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
5.6k
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
190
Featured
See All Featured
Into the Great Unknown - MozCon
thekraken
41
2.6k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
510
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
900
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Being A Developer After 40
akosma
91
590k
What's in a price? How to price your products and services
michaelherold
247
13k
Done Done
chrislema
186
16k
Documentation Writing (for coders)
carmenintech
77
5.4k
Side Projects
sachag
455
43k
ラッコキーワード サービス紹介資料
rakko
1
3.9M
Transcript
© 2025 Wantedly, Inc. ウォンテッドリーにおける Platform Engineering Platform Engineering Meetup
#12 Apr.7 2025 - Atsushi Tanaka @bgpat
© 2025 Wantedly, Inc. ⽥中 篤志 Atsushi Tanaka 2018年にインフラエンジニアとして新卒で入社。 2024年からインフラ領域のリーダーを担当。
趣味はバイクと日本酒とスキー ウォンテッドリー株式会社 Infra Squad Leader 自己紹介 bgpat bgpat_
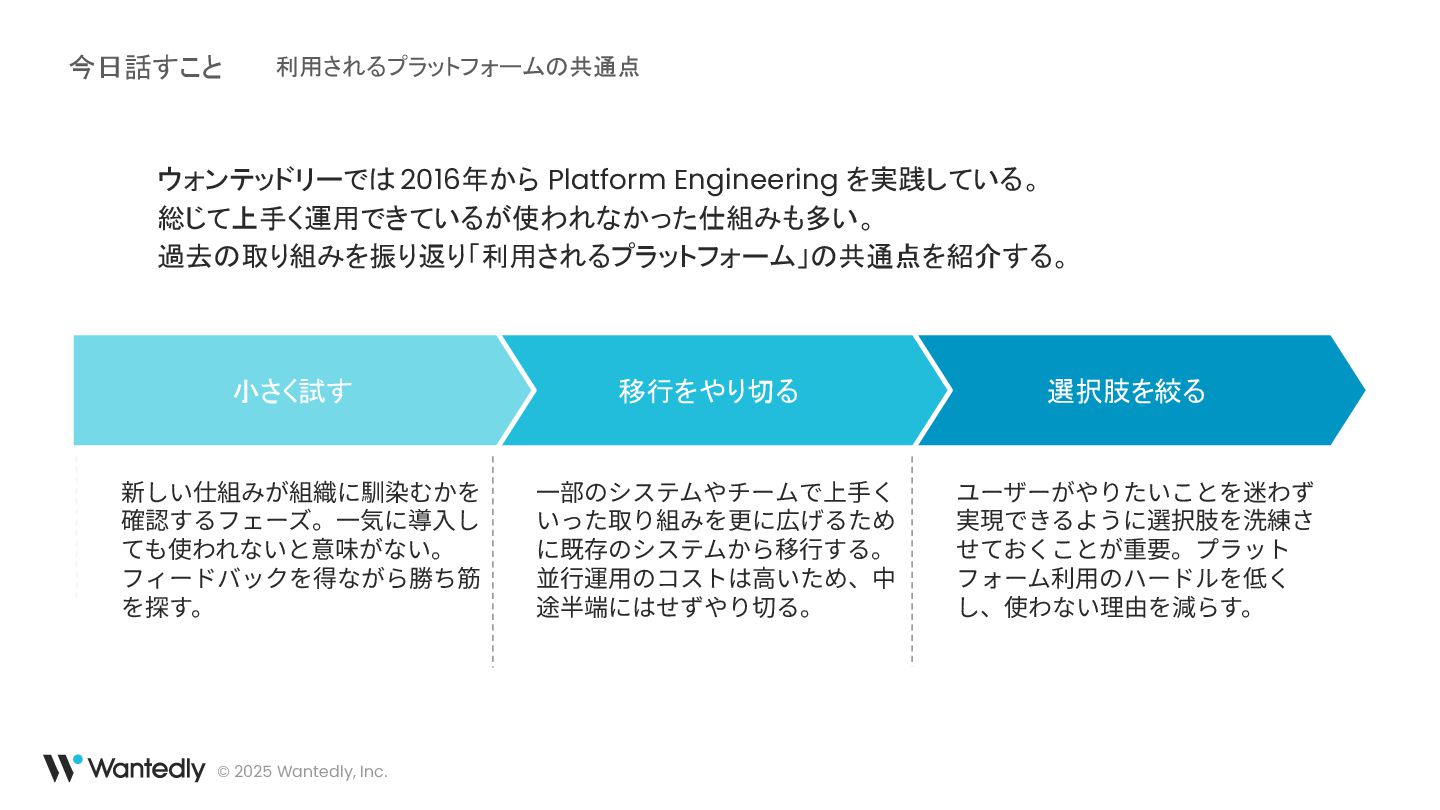
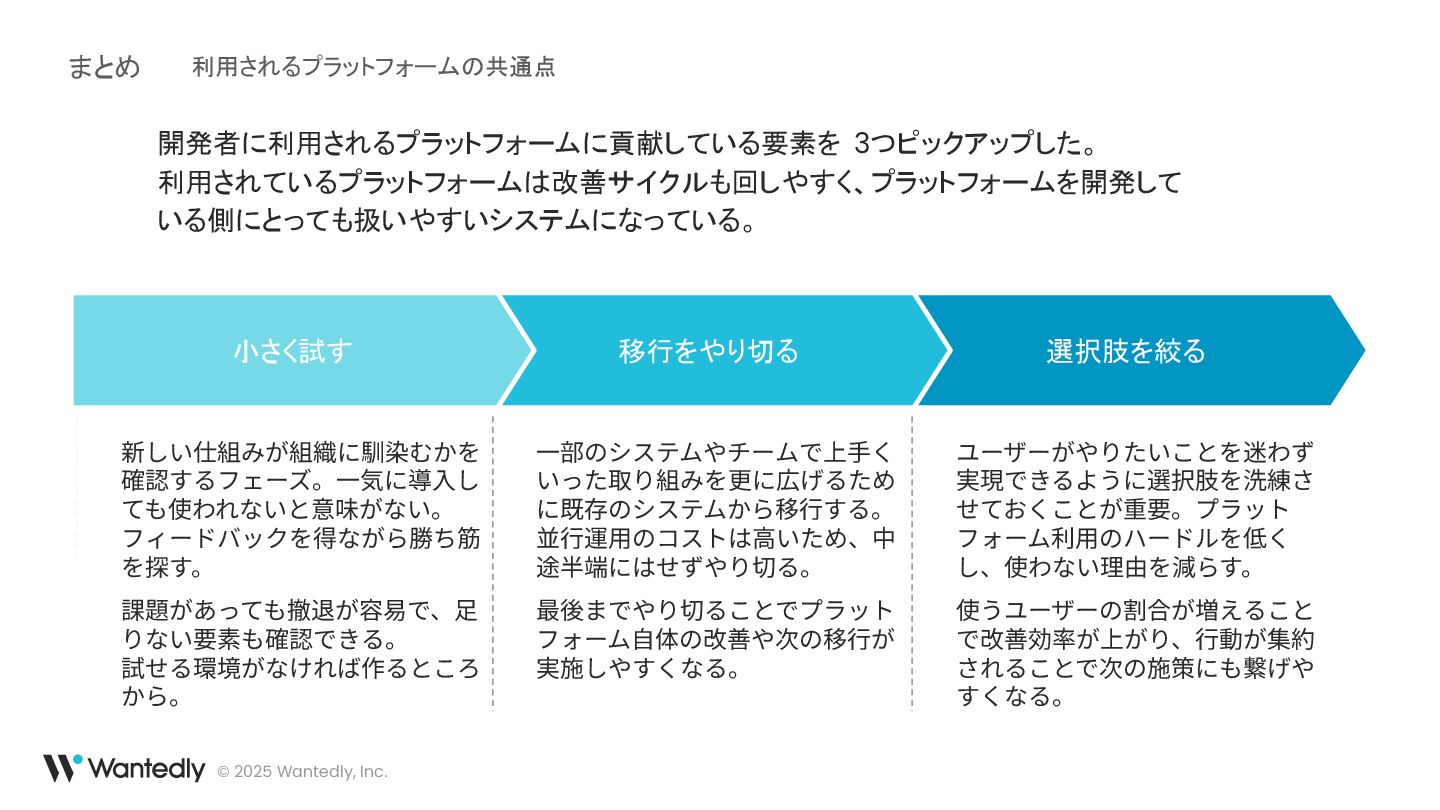
© 2025 Wantedly, Inc. 今日話すこと 選択肢を絞る 移行をやり切る 小さく試す 新しい仕組みが組織に馴染むかを 確認するフェーズ。⼀気に導⼊し
ても使われないと意味がない。 フィードバックを得ながら勝ち筋 を探す。 ユーザーがやりたいことを迷わず 実現できるように選択肢を洗練さ せておくことが重要。プラット フォーム利⽤のハードルを低く し、使わない理由を減らす。 ⼀部のシステムやチームで上⼿く いった取り組みを更に広げるため に既存のシステムから移⾏する。 並⾏運⽤のコストは⾼いため、中 途半端にはせずやり切る。 ウォンテッドリーでは 2016年から Platform Engineering を実践している。 総じて上手く運用できているが使われなかった仕組みも多い。 過去の取り組みを振り返り「利用されるプラットフォーム」の共通点を紹介する。 利用されるプラットフォームの共通点
© 2025 Wantedly, Inc. Agenda 01 ウォンテッドリーについて 02 ウォンテッドリーの開発プラットフォーム 03
成功/失敗例の紹介 04 まとめ
© 2025 Wantedly, Inc. ウォンテッドリーについて 01
© 2025 Wantedly, Inc. ミッション ウォンテッドリーは、⾃律‧共感‧挑戦のある適材適所を、 ⼀時的でも、局所的でもなく、構造的に⽣み出し続けることによって、 あらゆる⼈がシゴトに没頭し成果を上げ、その結果成⻑を実感できるような 「はたらくすべての⼈のインフラ」を構築していきます。
究極の適材適所により シゴトでココロオドル ひとをふやす
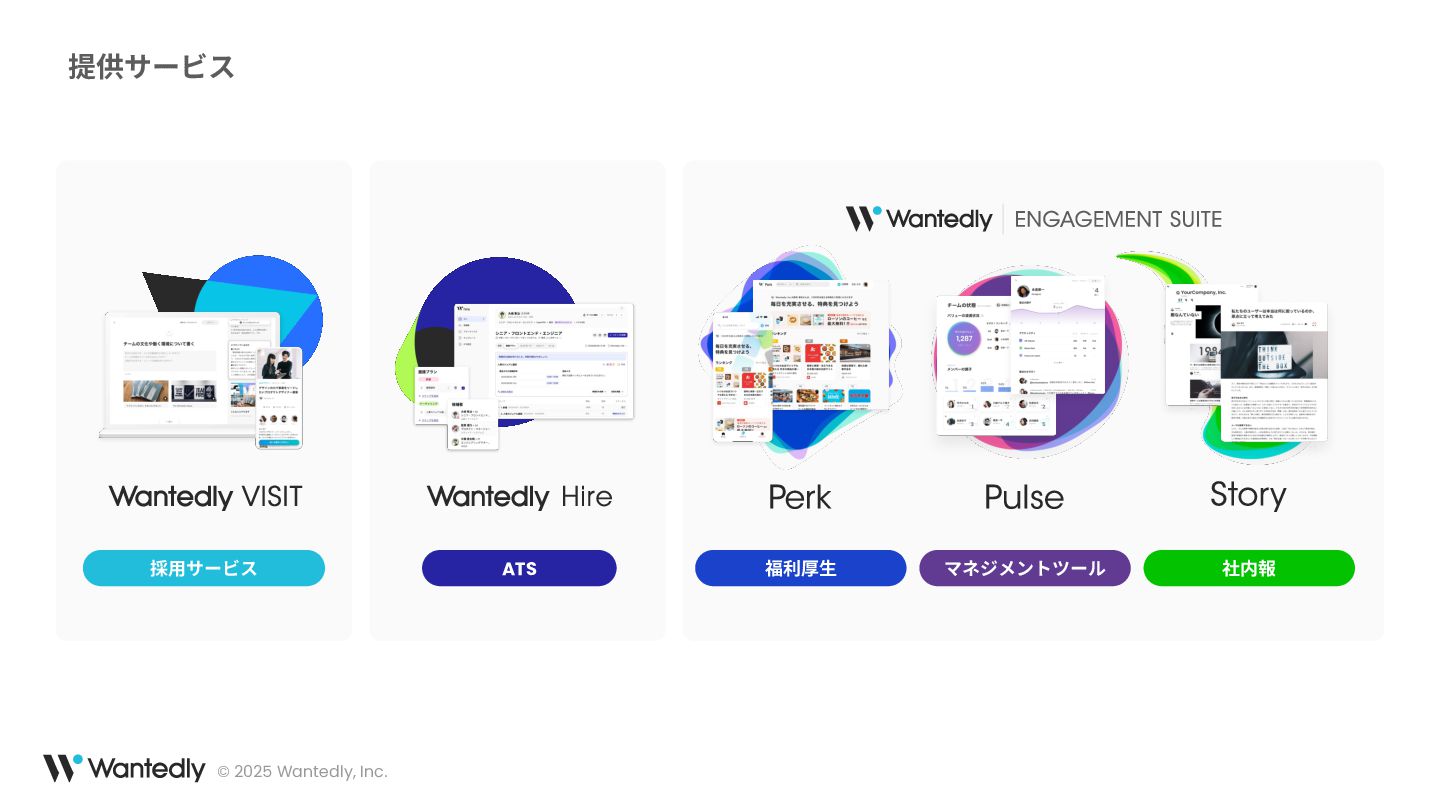
© 2025 Wantedly, Inc. 提供サービス ATS 採⽤サービス 福利厚⽣ マネジメントツール 社内報
© 2025 Wantedly, Inc. 1. 400万⼈のユーザーと4万社が利⽤ toC と toB の両⽅でサービスを展開
2. 少数精鋭 社員約120名のうちエンジニアが約50名 3. 裁量が多く⾃律的な⾏動を推奨 ≠ 与えられた仕事だけをこなす プロダクトと開発組織の特徴
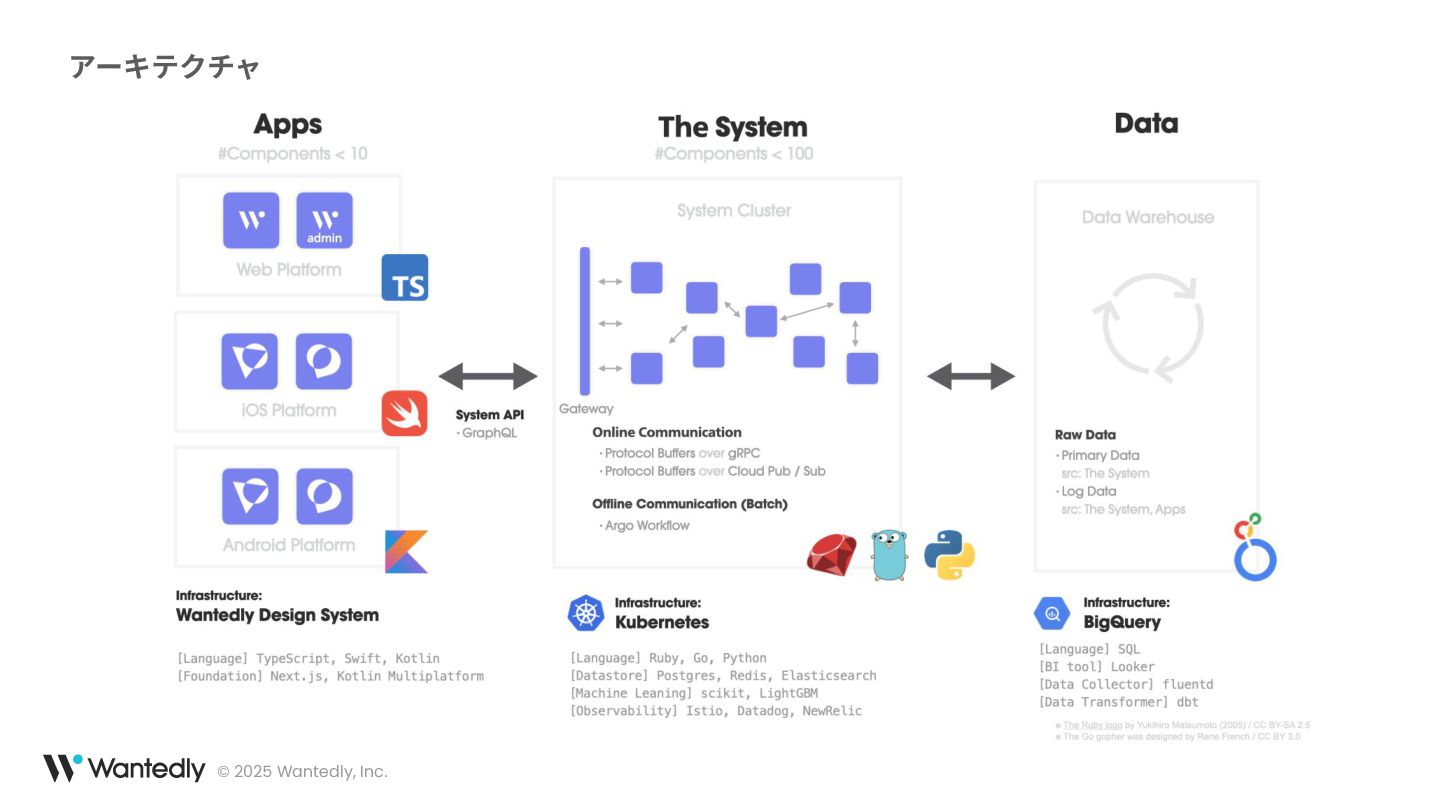
© 2025 Wantedly, Inc. アーキテクチャ
© 2025 Wantedly, Inc. Platform Engineering の取り組み 02
© 2025 Wantedly, Inc. ウォンテッドリーでは Infra Squad という チームで Platform
Engineering を実践 開発⽣産性と信頼性の両⽴を⽬指している • "強いシステム" の実現(= Site Reliability) • "スケーラブルな開発組織を⽀える Platform" の実現(= Developer Productivity) Infra Squad のミッション
© 2025 Wantedly, Inc. 2015年以前: インフラ作業がボトルネック 現在: プラットフォームを通して エンジニア⾃⾝でインフラ操作 なぜ
Platform Engineering を採用したのか エンジニアとサービスの増加 新しいエンジニアが増え新規サービスの開発が活発化 インフラ構築以外で忙しく改善タスクが回せない 依頼が来ると2〜4週間は⼿が離せなくなり運⽤改善の時間が取れない エンジニアにリソース管理を移譲 Kubernetes リソースは各マイクロサービスのリポジトリ内で管理 AWS リソースも Terraform Module を使って気軽に作成できる⼿順を⽤意 インフラエンジニアはプラットフォームの開発運⽤に専念 レビューとトラブルシューティング以外はメンテと改善活動に取り組む
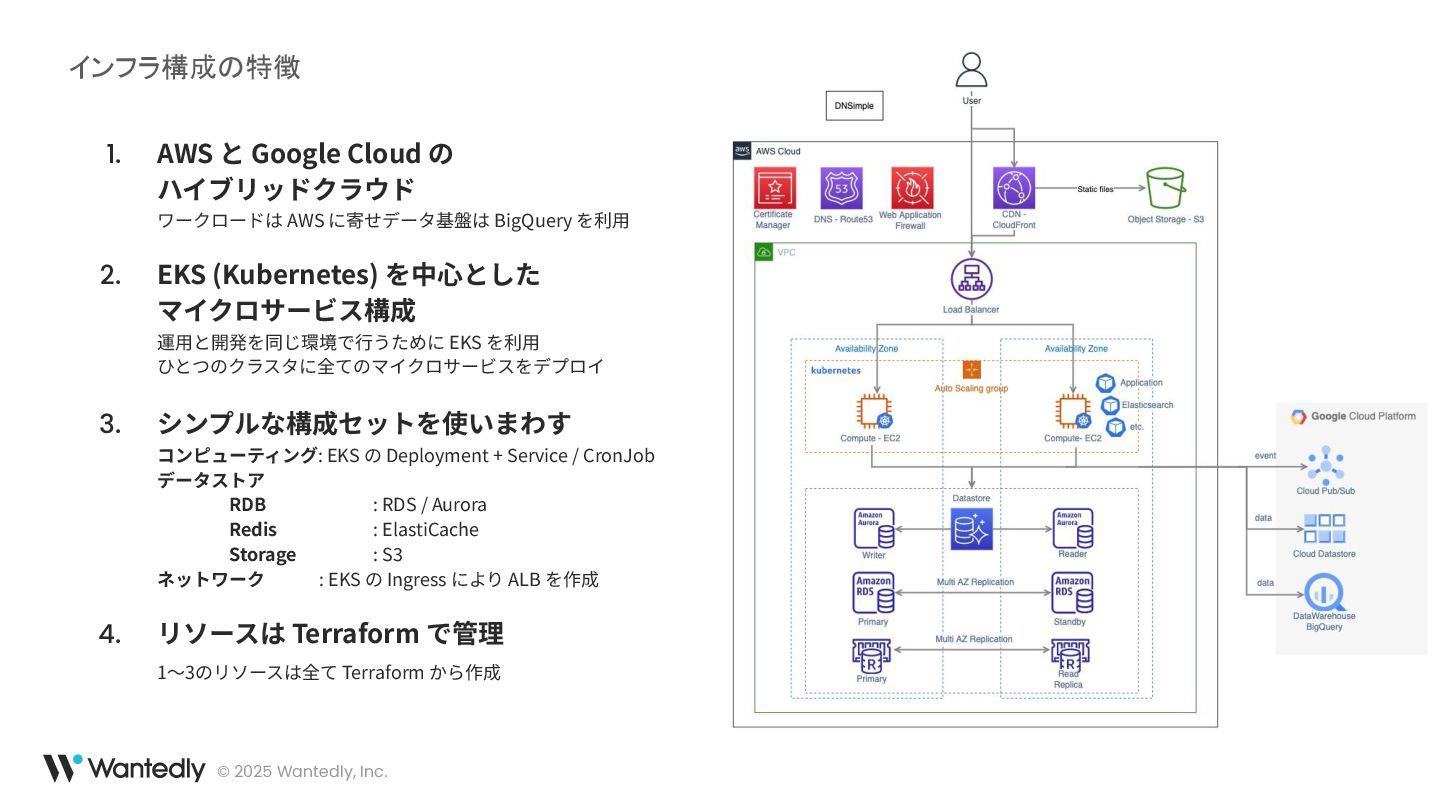
© 2025 Wantedly, Inc. 1. AWS と Google Cloud の
ハイブリッドクラウド ワークロードは AWS に寄せデータ基盤は BigQuery を利⽤ 2. EKS (Kubernetes) を中⼼とした マイクロサービス構成 運⽤と開発を同じ環境で⾏うために EKS を利⽤ ひとつのクラスタに全てのマイクロサービスをデプロイ 3. シンプルな構成セットを使いまわす コンピューティング: EKS の Deployment + Service / CronJob データストア RDB : RDS / Aurora Redis : ElastiCache Storage : S3 ネットワーク : EKS の Ingress により ALB を作成 4. リソースは Terraform で管理 1〜3のリソースは全て Terraform から作成 インフラ構成の特徴
© 2025 Wantedly, Inc. 2011/09 サービス開始 インフラは Heroku を利用
2014/?? AWS に移行 自律的なデプロイのため Docker を採用 2015/11 マイクロサービス化を検討 k8s の採用前は内製 PaaS を開発していた 2016/11 Kubernetes 本番導⼊ 一つのマイクロサービスから運用開始 当時は EC2 上にクラスタを構築 2018/01 共通ライブラリ “servicex” 誕⽣ マイクロサービスが備えるべき機能を 扱いやすい・統一的な形で提供 2018/08 全マイクロサービスの k8s 化 最後のマイクロサービス移行が完了 2020/04 kube fork による開発が開始 自分だけのクラスタで開発できる体験 初めは特定のサービスでしか利用できなかった 2021/05 PR 毎のプレビュー環境 PR に対して fork を実行する仕組みが登場 2024/12 監視サービスを Datadog に統一 役割の被っていた New Relic を廃止 ウォンテッドリーの開発プラットフォーム変遷
© 2025 Wantedly, Inc. 取り組みの事例紹介と学び 03
© 2025 Wantedly, Inc. • Kubernetes 導⼊移⾏ • kubefork 開発導⼊
• Elasticsearch 移⾏ • RDB 作成 Terraform Module • 社内共通ライブラリ “servicex” 導⼊ 今日紹介する事例
© 2025 Wantedly, Inc. • まず新規サービスに導⼊して効果を計測した ◦ 新規サービスの中でも影響の⼩さい単機能を マイクロサービスとして開発しデプロイした ◦
期待した効果があったので既存システムも移⾏ • ⼀番⼤きいマイクロサービスは移⾏完了まで4年かかった ◦ 2016, 2017年とチャレンジして失敗していた ◦ 少しずつ課題を潰して3回⽬の2018年で完了した ◦ 本番環境の前に開発/検証環境を移⾏して問題点を洗い出した • 社内の規約を作成 ◦ 例: commit 毎に git hash が tag の container image を作る 1 microservice = 1 git repository = 1 k8s namespace ◦ 構成の相談はほぼなくマイクロサービスがデプロイされる ◦ 後のプラットフォーム改善が進めやすくなっている 事例紹介 Kubernetes 導入移行
© 2025 Wantedly, Inc. • ⼀部のエンジニアから徐々に導⼊ ◦ 社内でも基盤に興味のあるエンジニアから導⼊ ◦ フィードバックを貰いながら徐々に改善を進めた
• 必要なシステムも徐々に導⼊ ◦ Istio 導⼊に失敗し検証環境を壊したことで 開発環境が誕⽣した • kubefork を使えば楽に開発できることを周知 ◦ 社内外で kubefork について伝えることに⼒を⼊れ 発表やドキュメント整備を⾏った ◦ 古い開発⽅法⽤のスクリプトやドキュメントは削除 ◦ 開発時は kubefork を使う共通認識が形成された 事例紹介 kubefork 開発導入
© 2025 Wantedly, Inc. • 検索や推薦のために Elasticsearch を活⽤ ◦ 全⽂検索や構造化データの検索は
RDB ではやりづらい • 運⽤環境を統⼀するため EC2 から k8s に載せ替え ◦ 専⽤ツールを他のマイクロサービスと同じ kube に移⾏しメンテが楽に ◦ エンジニア⾃⾝でデプロイするドキュメントも⽤意 ◦ 結果インフラはレビューするだけでデプロイ可能に • 利⽤はされているが運⽤負荷が⾼すぎる ◦ ステートを持つと Pod 削除前にデータ退避が必要になり Node ⼊れ替えに時間がかかる ◦ さらにマネージドサービスへの移⾏を検討中 ◦ 問題は多いが移⾏元は1パターンの考慮だけでよい 事例紹介 Elasticsearch 移行
© 2025 Wantedly, Inc. • RDB を Terraform から作成しやすくする Module
を開発 ◦ k8s の次に作成されることの多いリソースだったので改善 ◦ インフラがボトルネックになっていたのを解消したかった ◦ 推奨設定や監視も⾃動で⼊るようにしたかった • Module 以外の⽅法で管理されている RDB がまだ多い ◦ 既存 DB の数が多かったので後回しにした ◦ 既存 DB の移⾏はせず新しい DB 作成が楽になれば良いと考えた • ドキュメントは書いたが⾒られない ◦ そもそも RDB 作成の機会が少なく思い出してもらえない ◦ 意図に反した⽅法で RDB が作られていて困った ▪ 古い Terraform のコードをコピペして推奨設定が⼊らなかった ▪ k8s 上に野良 DB を⽴てるオリジナルの⽅法でデータ移⾏ができなかった 事例紹介 RDB 作成 Terraform Module
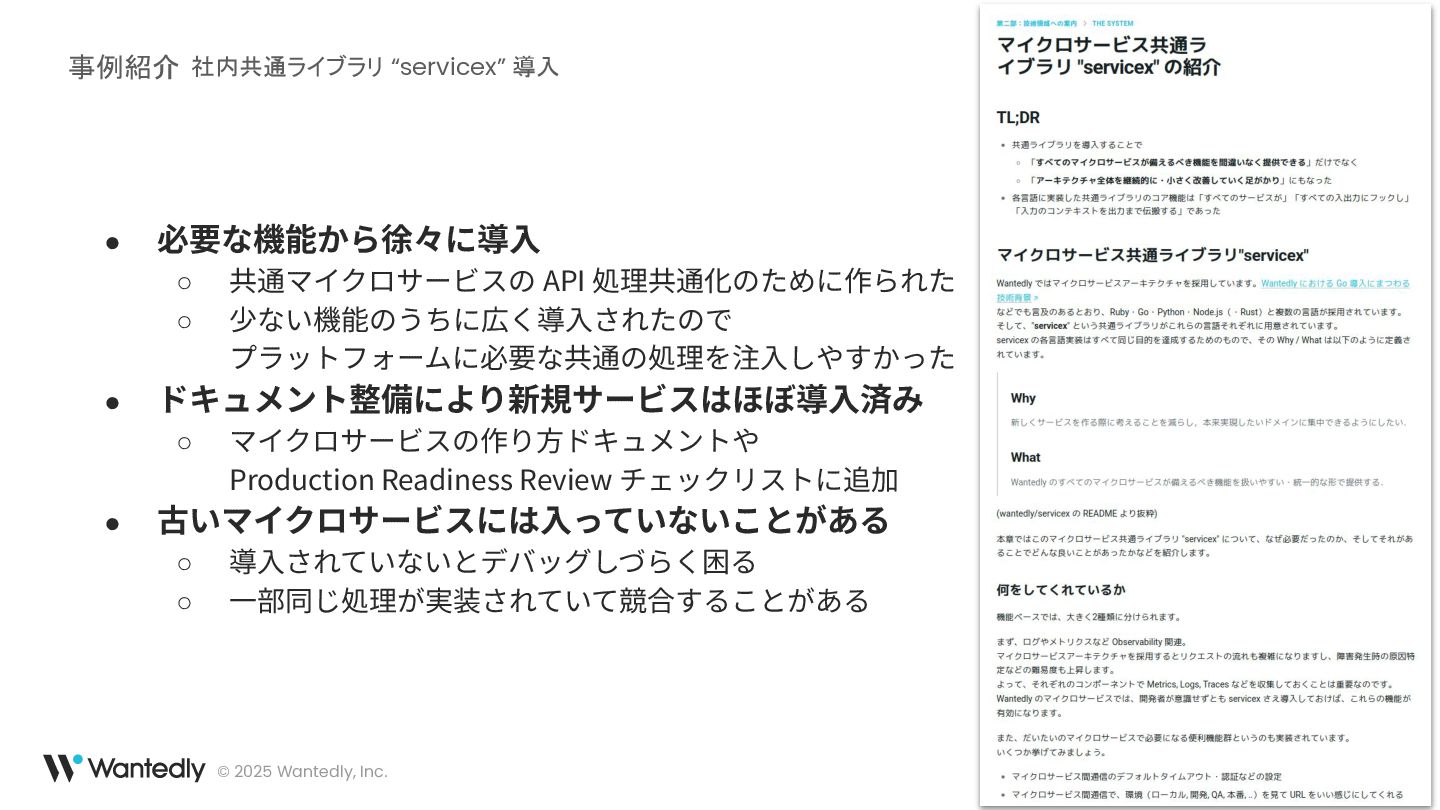
© 2025 Wantedly, Inc. • 必要な機能から徐々に導⼊ ◦ 共通マイクロサービスの API 処理共通化のために作られた
◦ 少ない機能のうちに広く導⼊されたので プラットフォームに必要な共通の処理を注⼊しやすかった • ドキュメント整備により新規サービスはほぼ導⼊済み ◦ マイクロサービスの作り⽅ドキュメントや Production Readiness Review チェックリストに追加 • 古いマイクロサービスには⼊っていないことがある ◦ 導⼊されていないとデバッグしづらく困る ◦ ⼀部同じ処理が実装されていて競合することがある 事例紹介 社内共通ライブラリ “servicex” 導入
© 2025 Wantedly, Inc. • ⼩さく試せたものの⽅が最終的に利⽤されている確率が⾼い ◦ 試せる状況にないものは環境作りから始める必要がある ◦ ⼩さく試せないものは利⽤されないリスクが⾼い
• 移⾏をやりきらないことで後で困ることが多い ◦ 既存実装がドキュメント扱いされることもある ◦ 移⾏はやれるときに完了させるべき • 導⼊と移⾏だけでなく利⽤させる仕組みも必要 ◦ 選択肢が減ることで開発スピードが上がる ◦ 規約を作るのも効果的 得られた学び
© 2025 Wantedly, Inc. まとめ 04
© 2025 Wantedly, Inc. まとめ 選択肢を絞る 移行をやり切る 小さく試す 新しい仕組みが組織に馴染むかを 確認するフェーズ。⼀気に導⼊し
ても使われないと意味がない。 フィードバックを得ながら勝ち筋 を探す。 課題があっても撤退が容易で、⾜ りない要素も確認できる。 試せる環境がなければ作るところ から。 ユーザーがやりたいことを迷わず 実現できるように選択肢を洗練さ せておくことが重要。プラット フォーム利⽤のハードルを低く し、使わない理由を減らす。 使うユーザーの割合が増えること で改善効率が上がり、⾏動が集約 されることで次の施策にも繋げや すくなる。 ⼀部のシステムやチームで上⼿く いった取り組みを更に広げるため に既存のシステムから移⾏する。 並⾏運⽤のコストは⾼いため、中 途半端にはせずやり切る。 最後までやり切ることでプラット フォーム⾃体の改善や次の移⾏が 実施しやすくなる。 開発者に利用されるプラットフォームに貢献している要素を 3つピックアップした。 利用されているプラットフォームは改善サイクルも回しやすく、プラットフォームを開発して いる側にとっても扱いやすいシステムになっている。 利用されるプラットフォームの共通点
© 2025 Wantedly, Inc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}