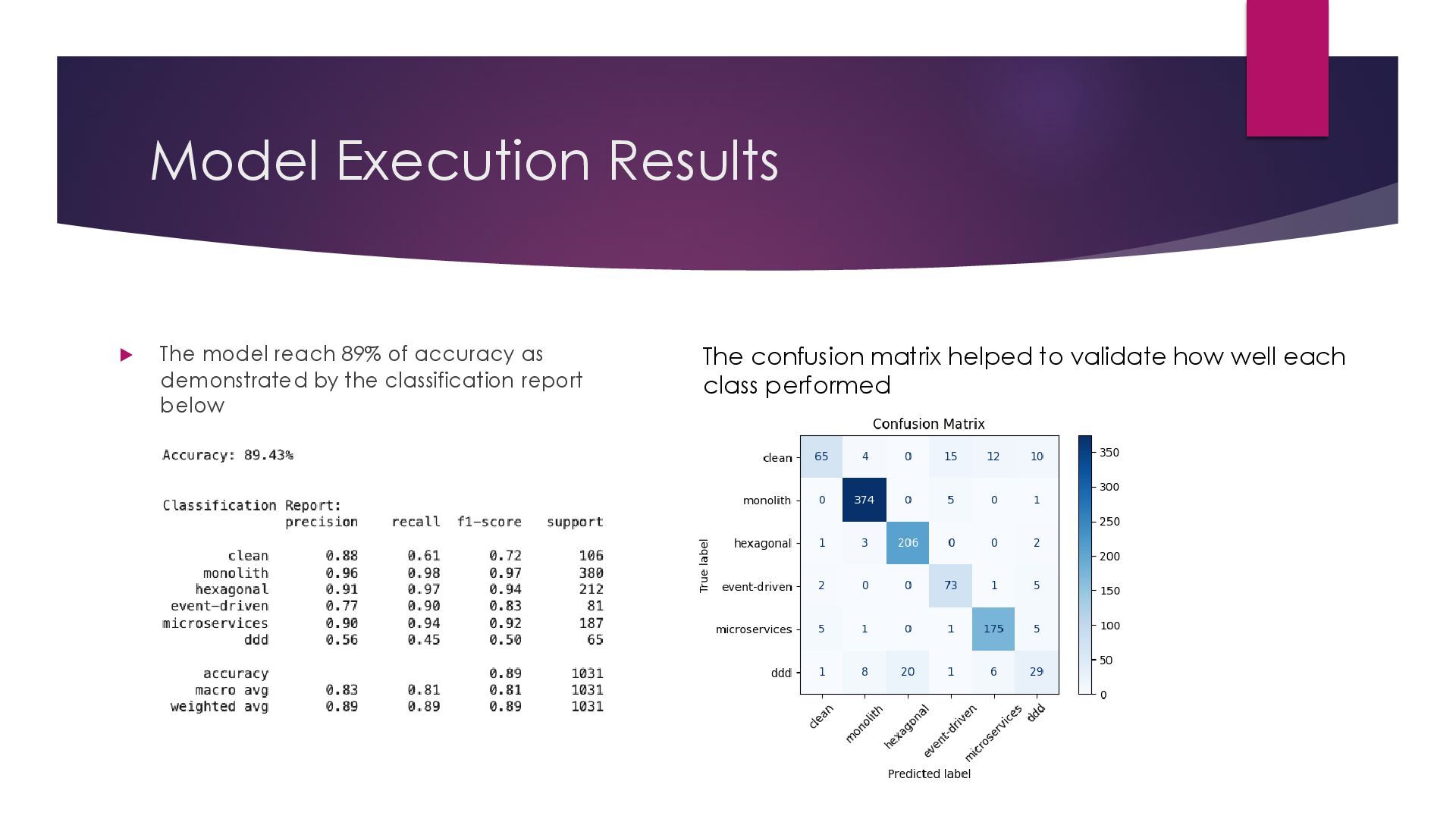
This is a presentation about my capstone project for the Mastering Neural Networks course at MITxPro. This project used my deep learning knowledge from the course applied to source code analysis to detect architectural patterns of Java applications. I used the BERT model as the basis for training my custom model using random Github repos as my dataset.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}