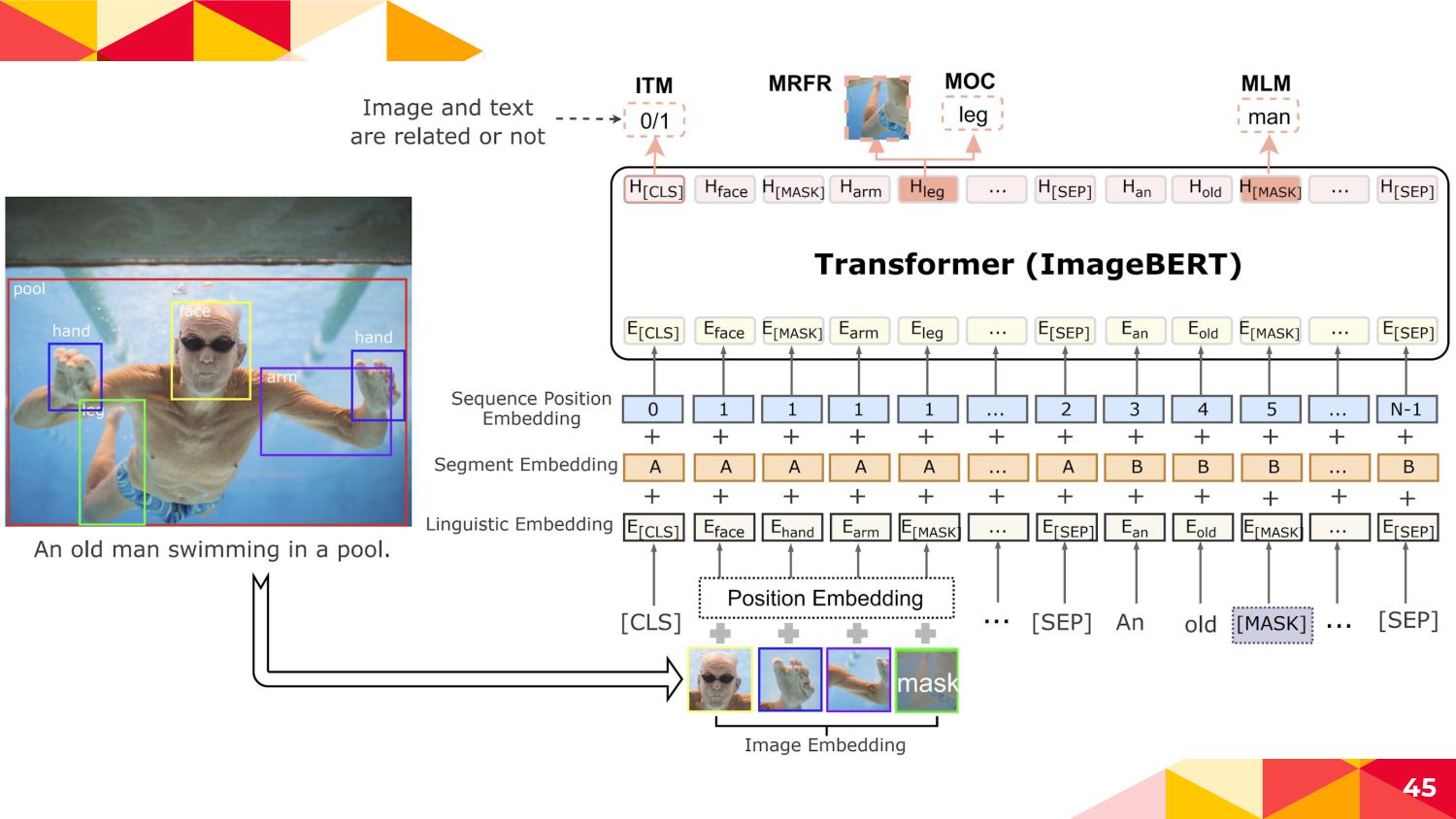
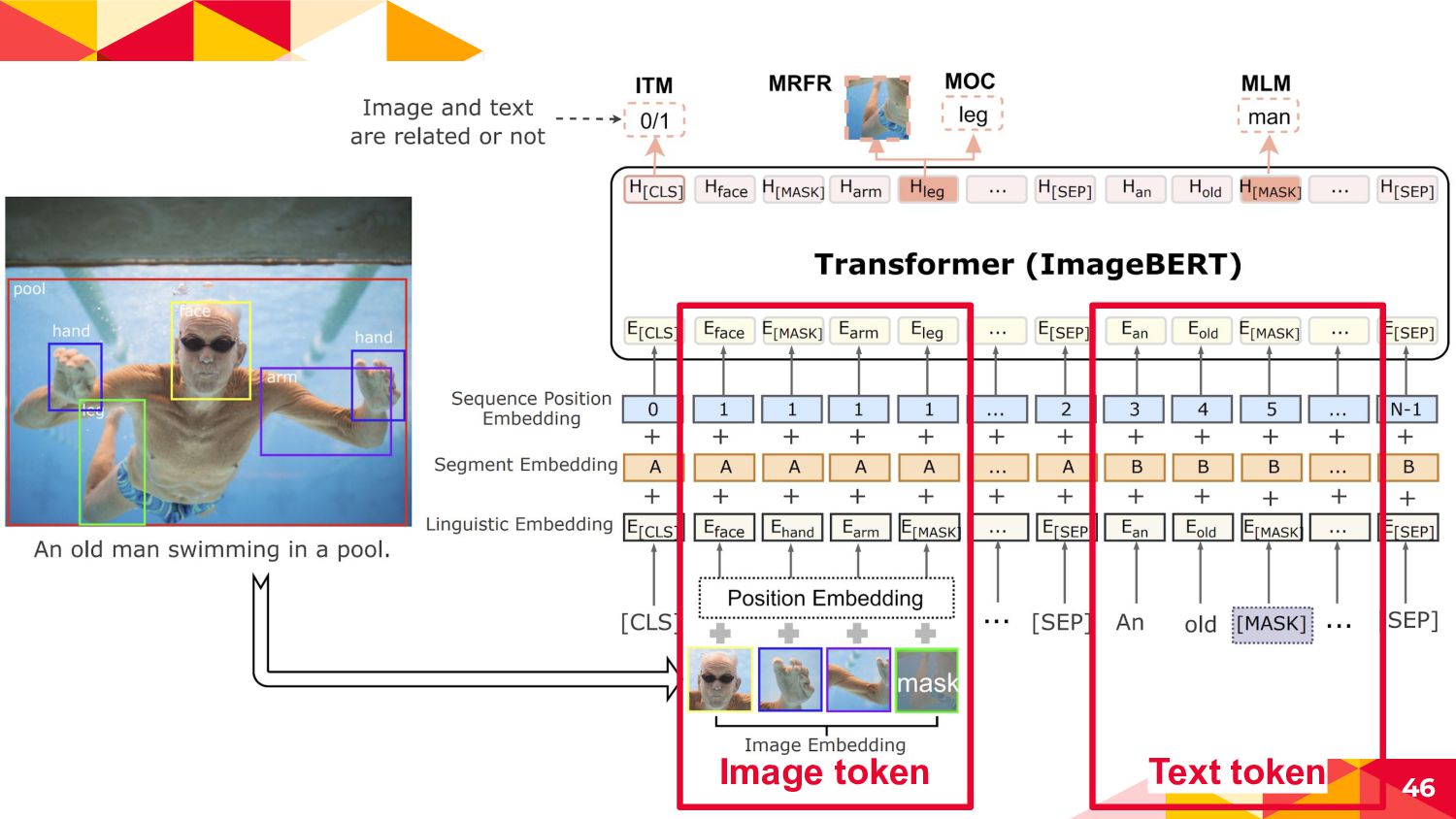
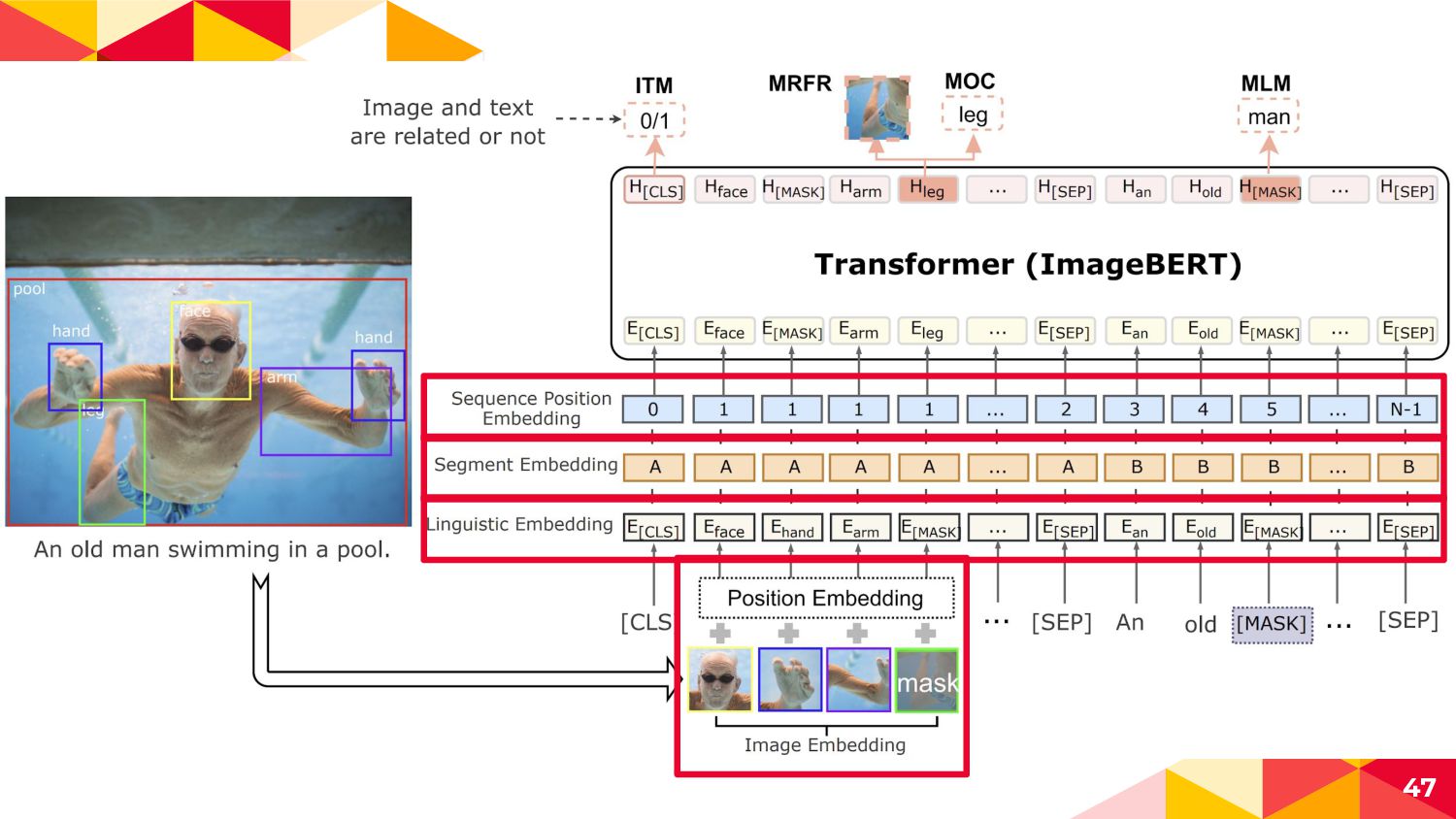
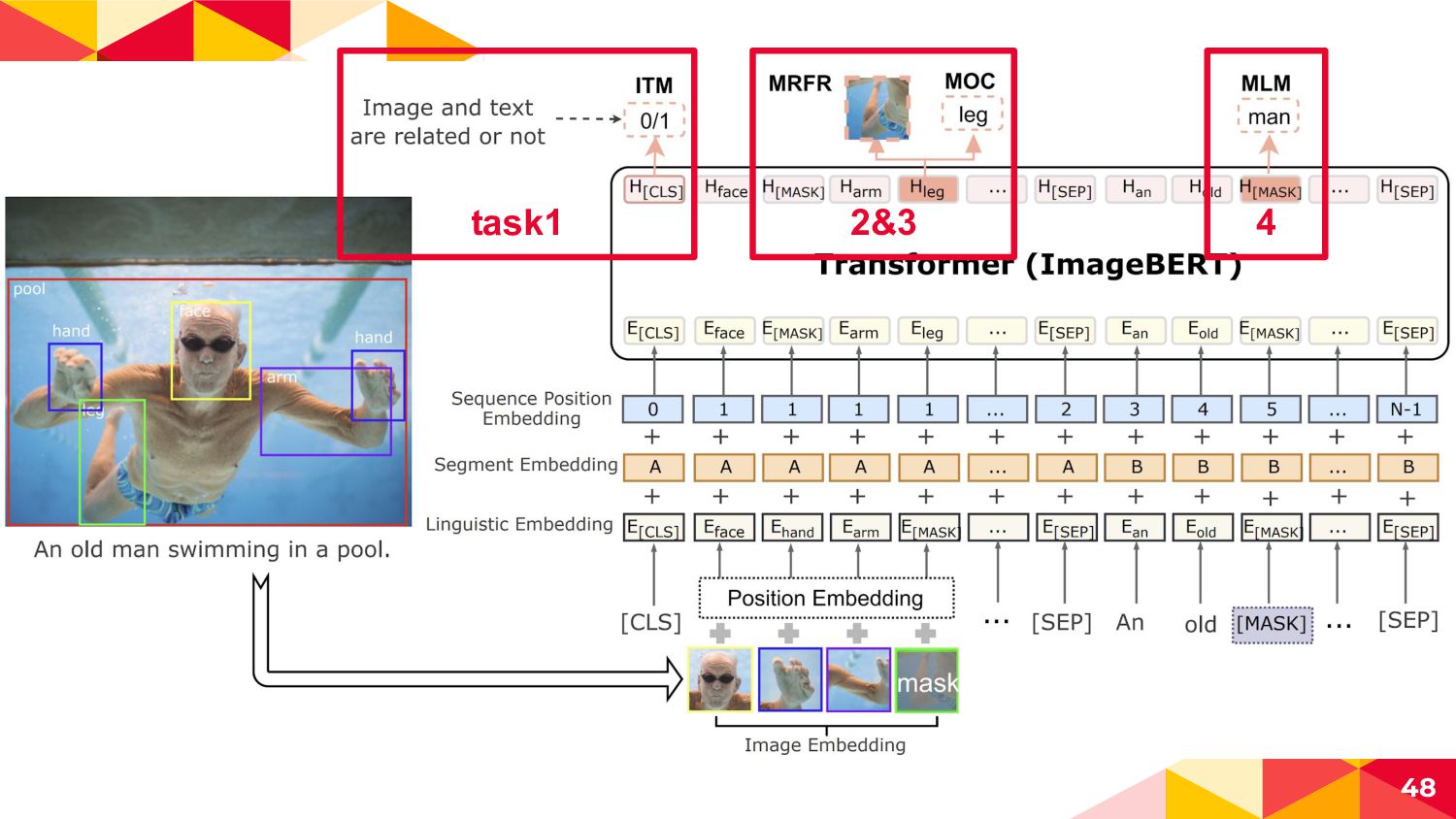
◂ An old man swimming... -> An old man [MASK]... ◂ 10%...randomなtokenにreplace ◂ An old man swimming... -> An old man old ◂ 10%...not replace ◂ my cat is cute -> my cat is cute ◂ 周辺のtokensから変換前のtokenを予測させて(穴埋め問題を解か せて)image|textの相互作用と言語表現を獲得 55
にreplace ◂ face hand arm leg -> face hand arm [MASK] ◂ 10%...not replace ◂ face hand arm leg -> face hand arm leg ◂ 周辺のtokensからMASKされたObject labelを当てて画像コンテ ンツの言語表現を獲得 56 Faster R-CNNの正解カテゴリ [MASK]の周辺tokensから得られた Transformerの出力ベクトル
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cross-modal界隈でもTransformerが流行 ◂ Transformerの発明以降、その性能から様々な応用が生まれる ◂ Model architecture ◂ BERT[10]...Transformerベースのつよ言語モデル ◂ 画像と文章それぞれ](https://files.speakerdeck.com/presentations/0d5b936da7604801801f1e7d02e9c64d/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
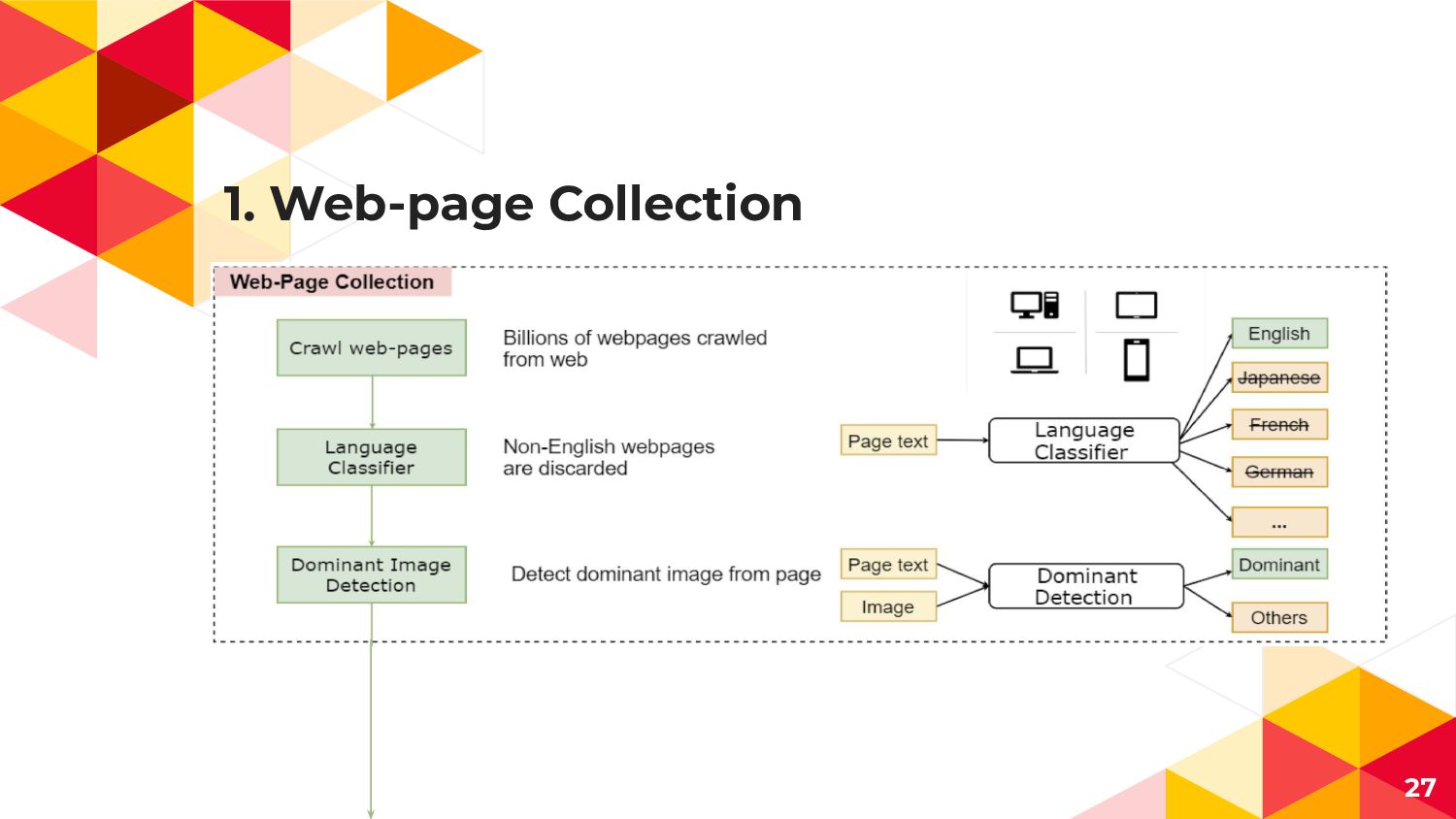
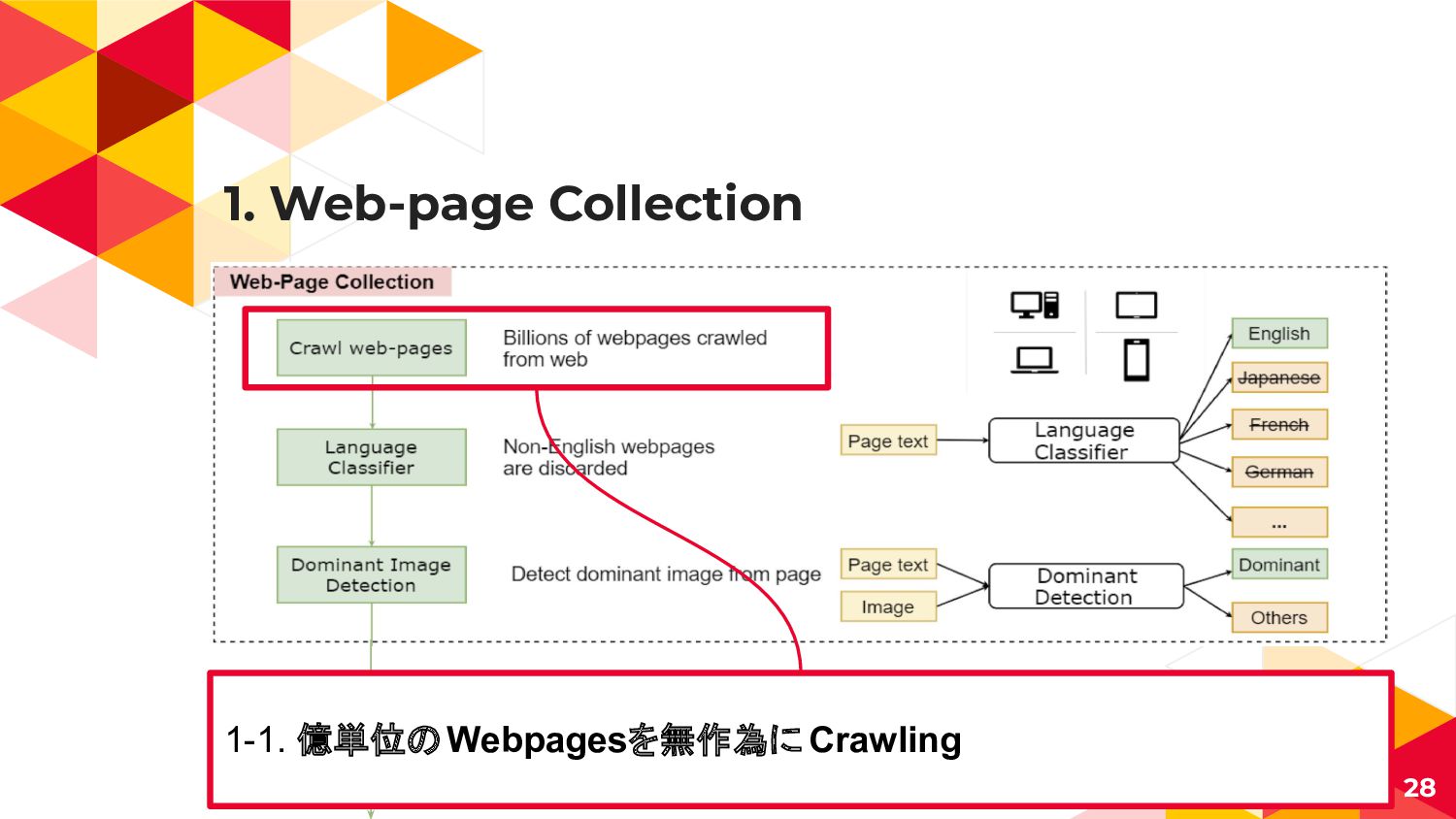
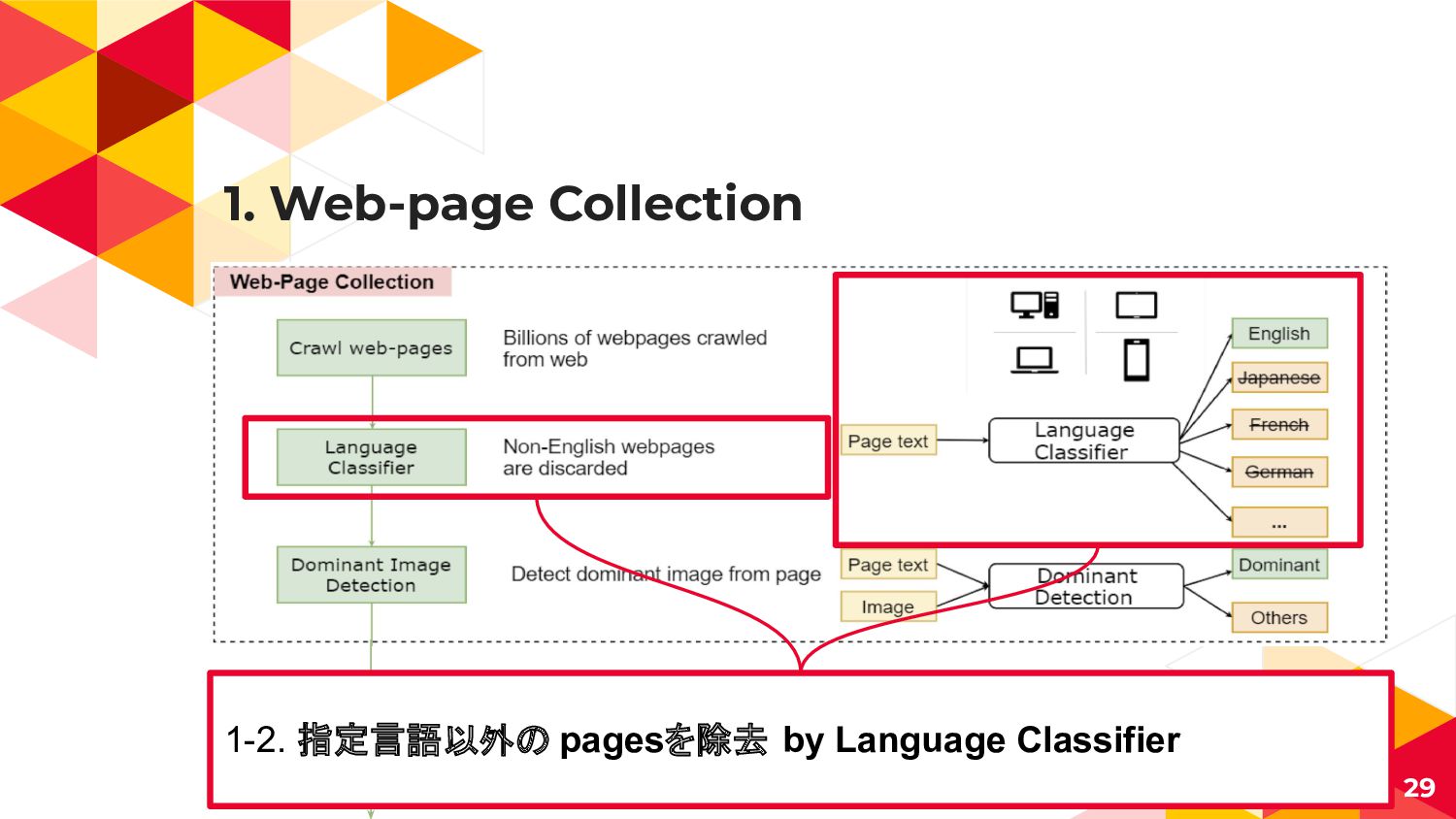
![Vision-Language Taskの課題 ◂ 大量で高品質な画像・テキストのペアデータが少ない ◂ Conceptual Captions[2] ◂ 3M Images](https://files.speakerdeck.com/presentations/0d5b936da7604801801f1e7d02e9c64d/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
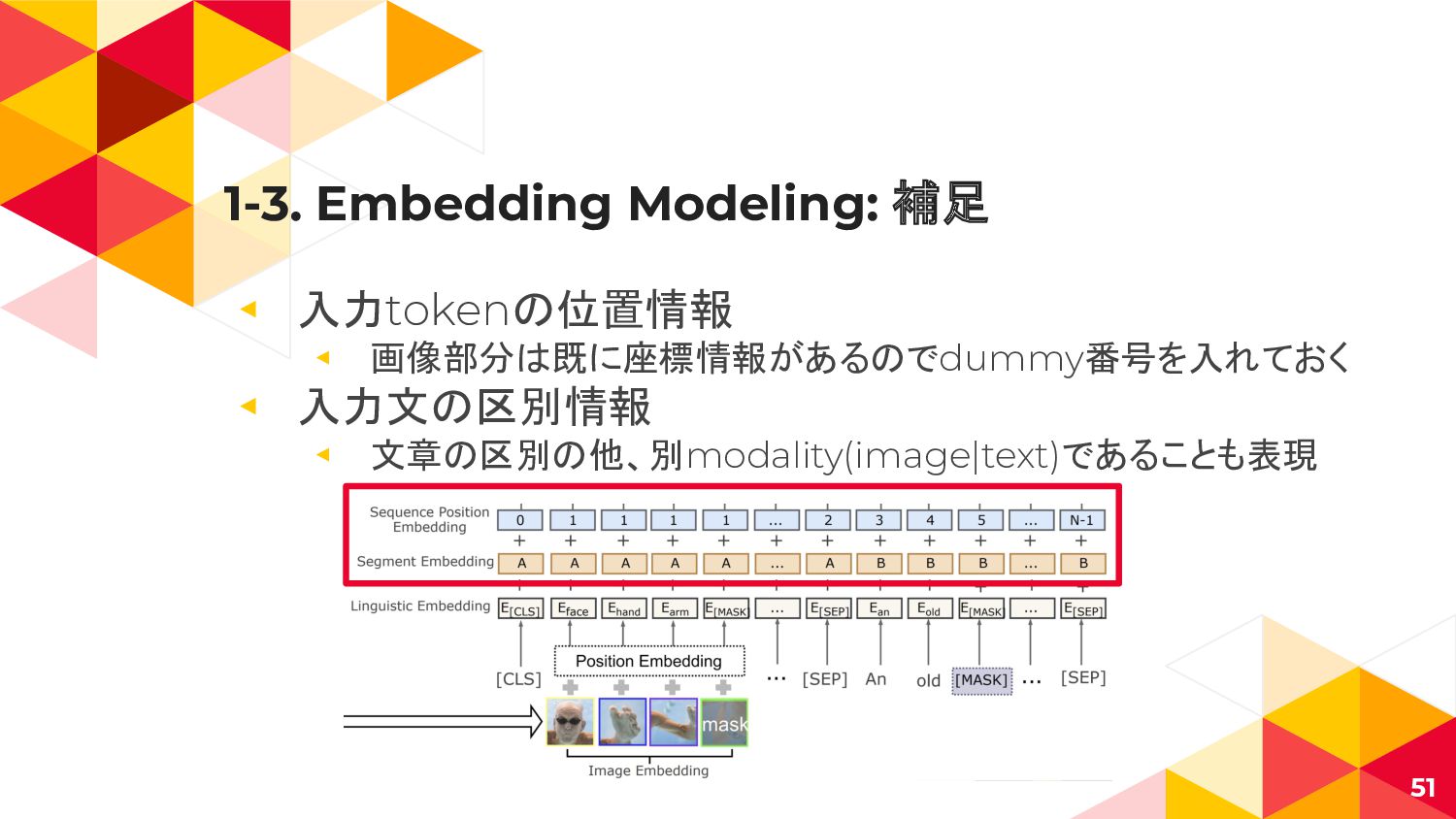{kind=link}
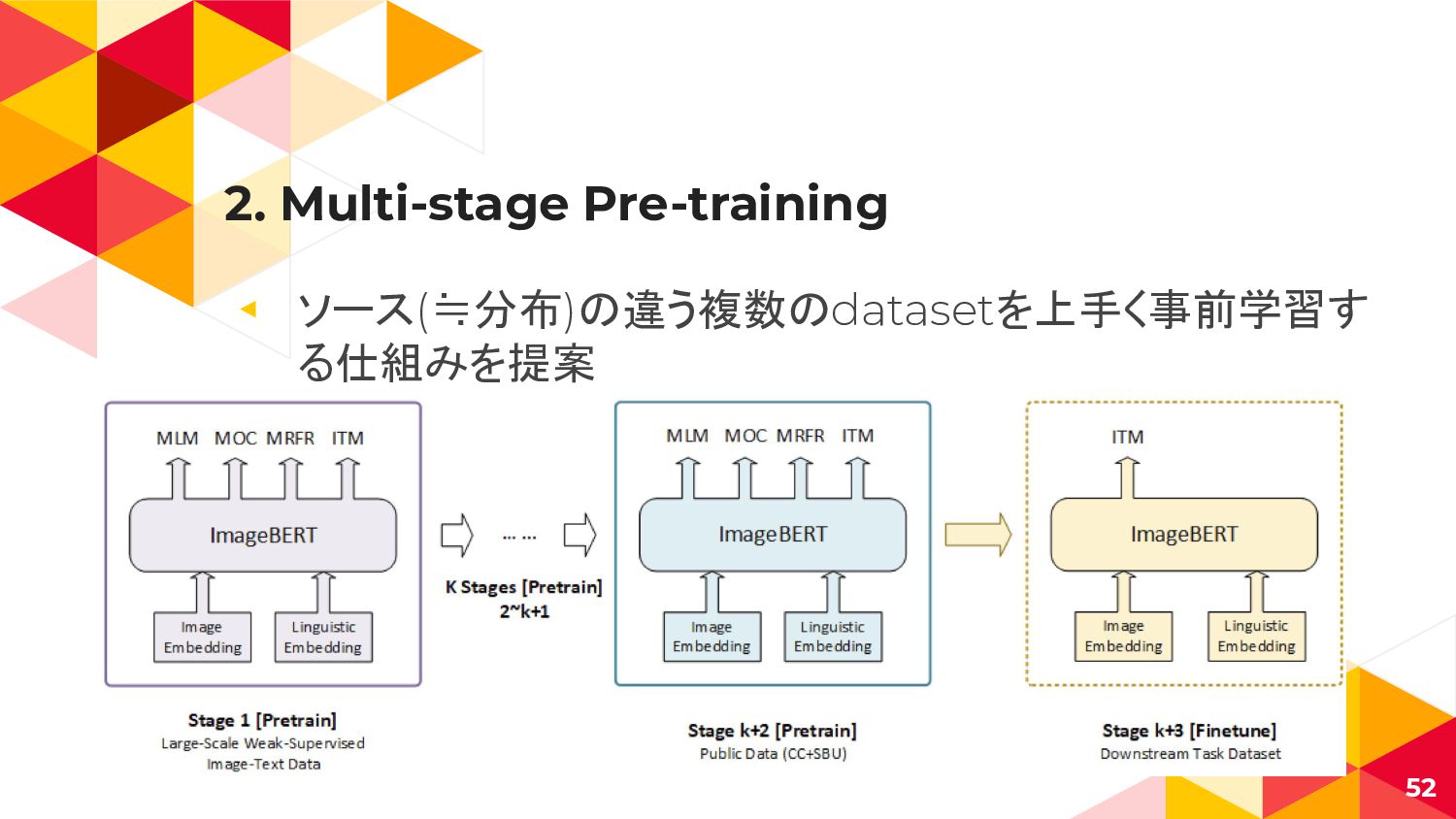{kind=link}
{kind=link}
{kind=link}
![3-1. Masked Language Modeling (MLM) ◂ 入力文のtokenの15%を以下3種に変換 ◂ 80%...[MASK] にreplace](https://files.speakerdeck.com/presentations/0d5b936da7604801801f1e7d02e9c64d/slide_51.jpg){kind=link}
![3-2. Masked Object Classification (MOC) ◂ Object tokenの15%を以下2種に変換 ◂ 90%...[MASK]](https://files.speakerdeck.com/presentations/0d5b936da7604801801f1e7d02e9c64d/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
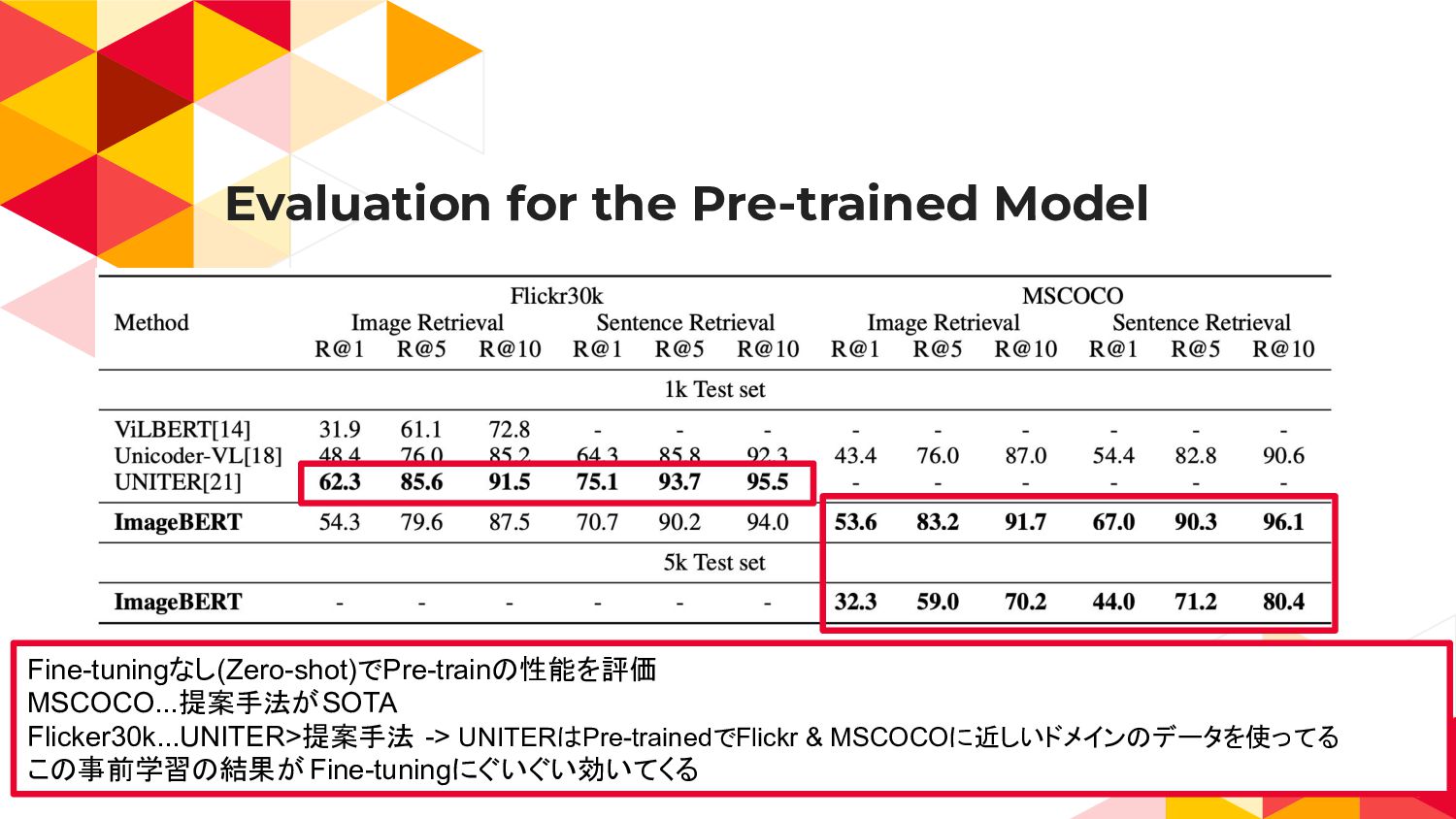{kind=link}
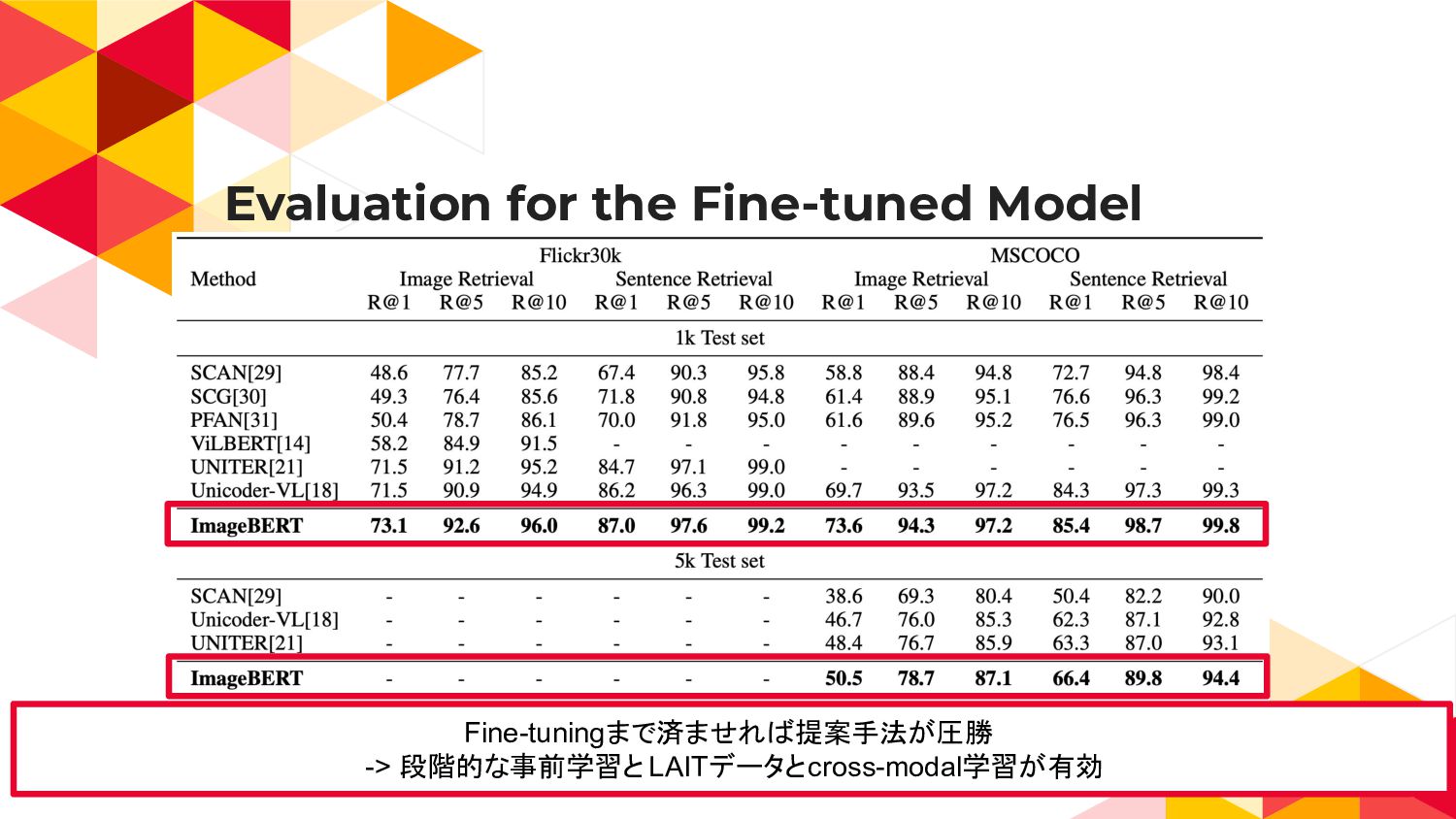{kind=link}
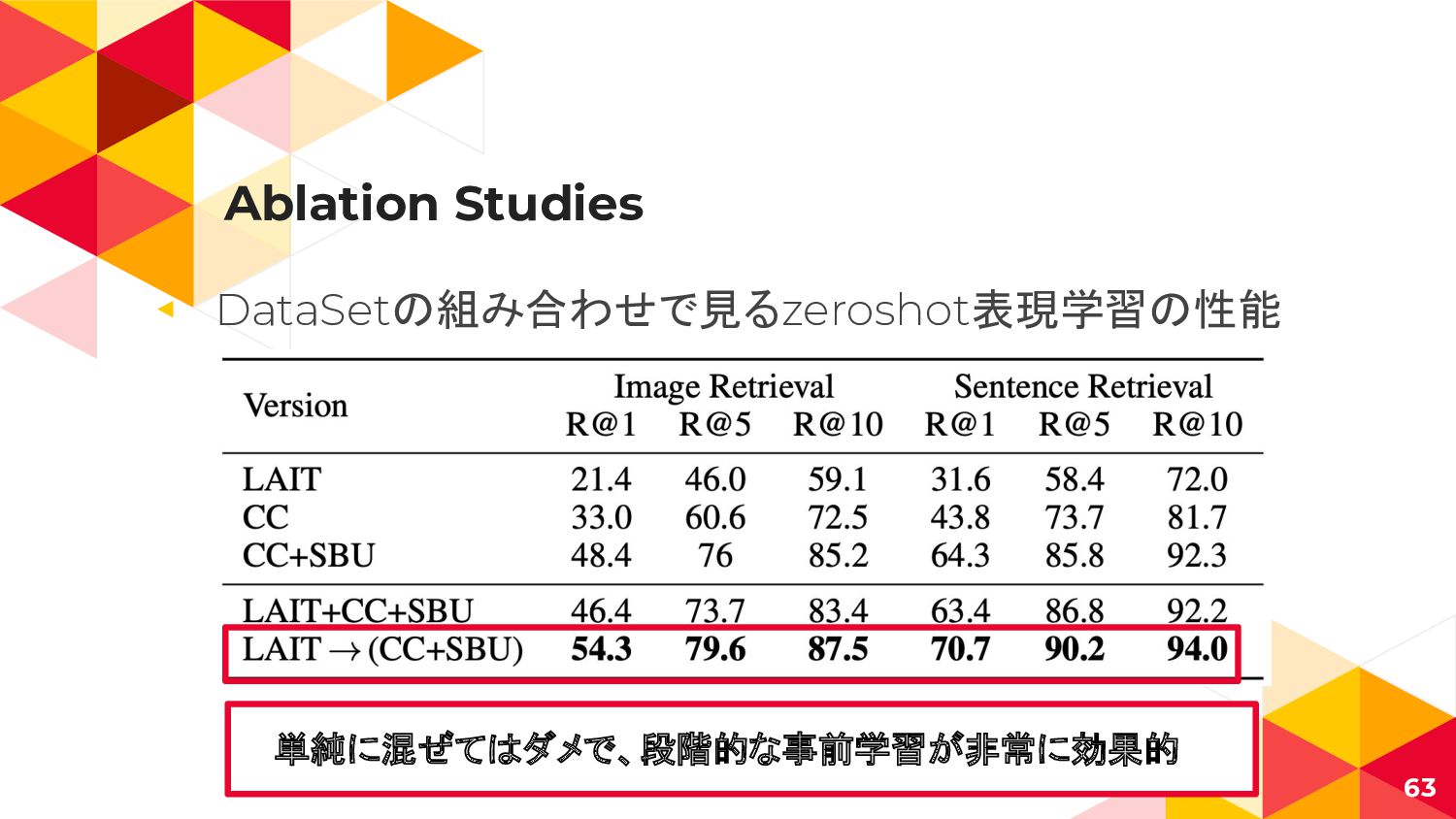{kind=link}
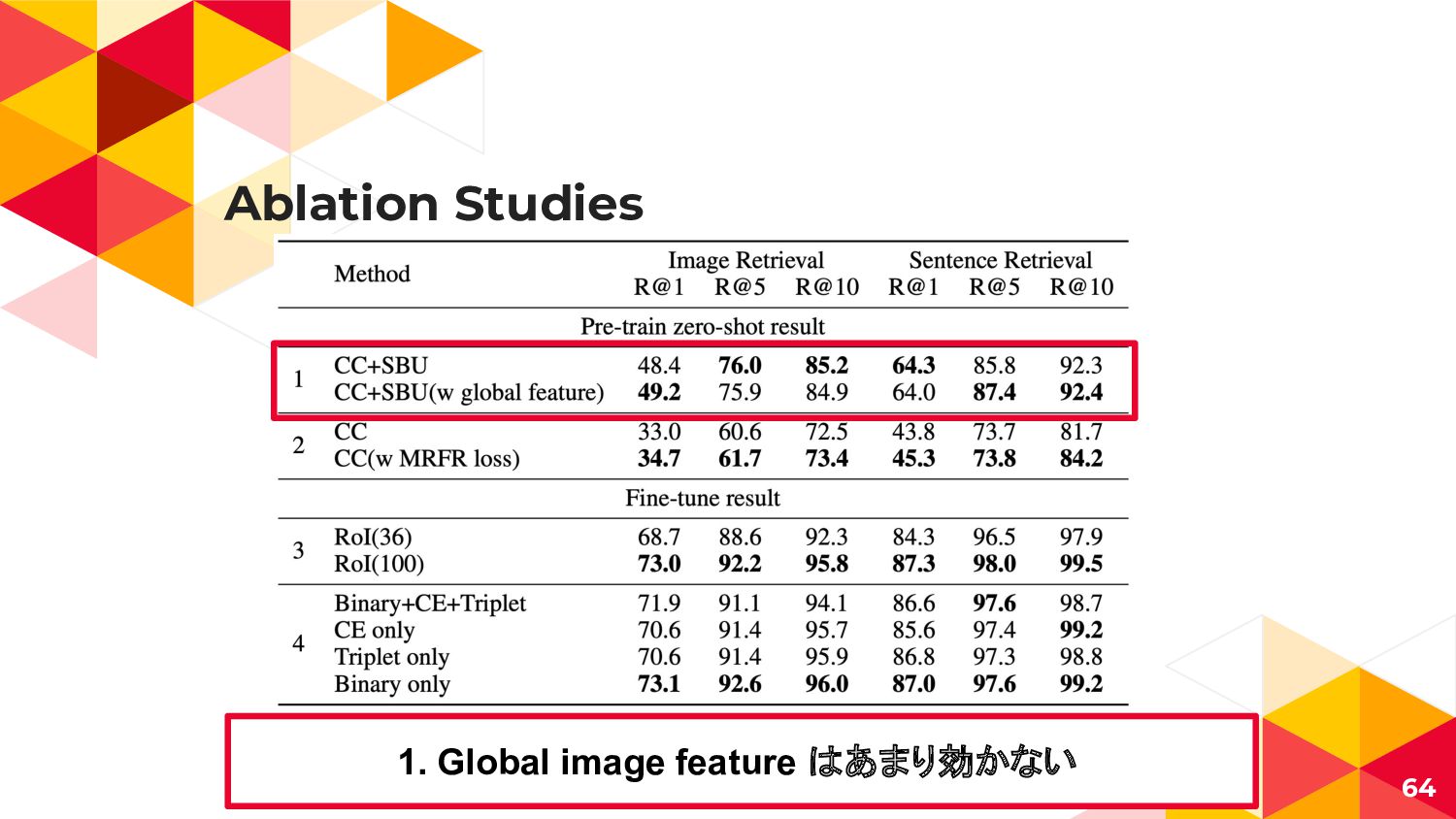{kind=link}
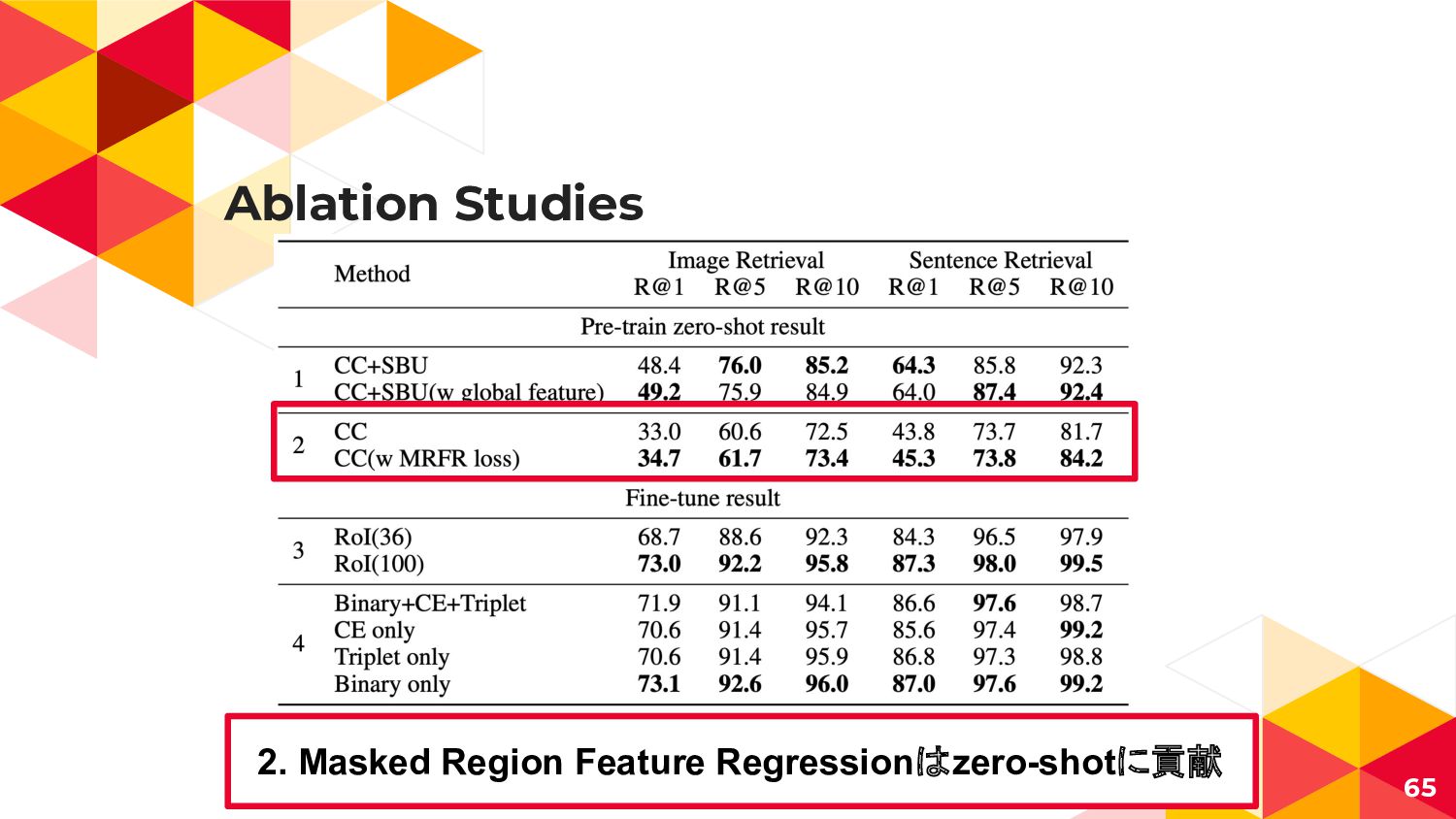{kind=link}
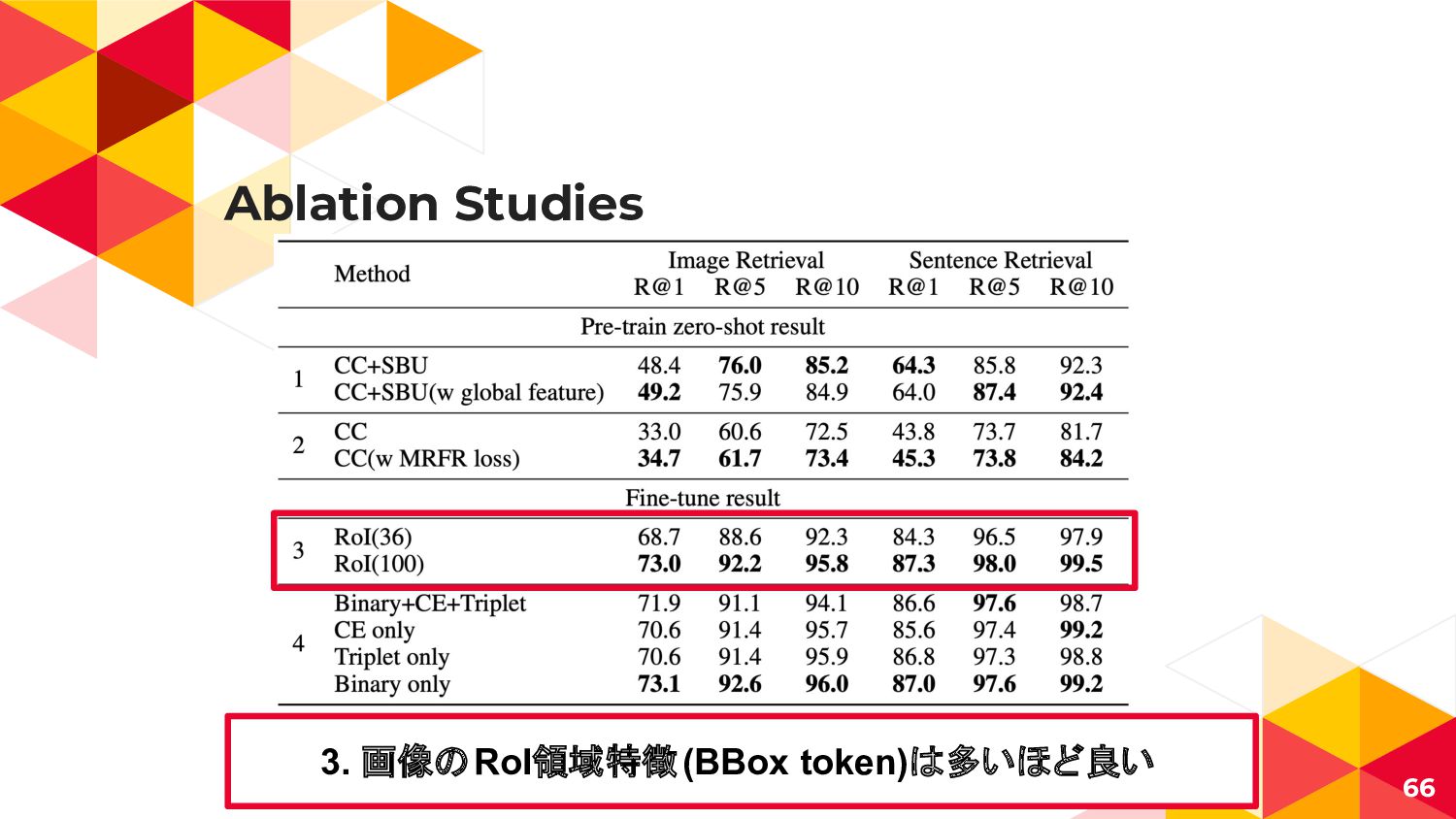{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}