Upgrading a database cluster can be a complex and time-consuming process. While there are several methods for upgrade, such as dump/restore and logical replication, pg_upgrade is a powerful tool that allows users to upgrade a cluster with acceptable and predictable downtime.
In this talk, I will explore the benefits of using pg_upgrade for major upgrades, particularly in large, high-availability (HA) clusters with multiple nodes. I will provide a list of pre- and post-upgrade checks and tasks to ensure a smooth and successful upgrade process, and describe common pitfalls and how to avoid them. Through real-world examples and case studies, I will demonstrate the scalability and efficiency of pg_upgrade+rsync approach for major upgrades, and provide tips and best practices for using those tools in various environments.
Last, but not least, I want to raise one the most important and probably at the same time undervalued issue - lost statistics and how to deal with it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
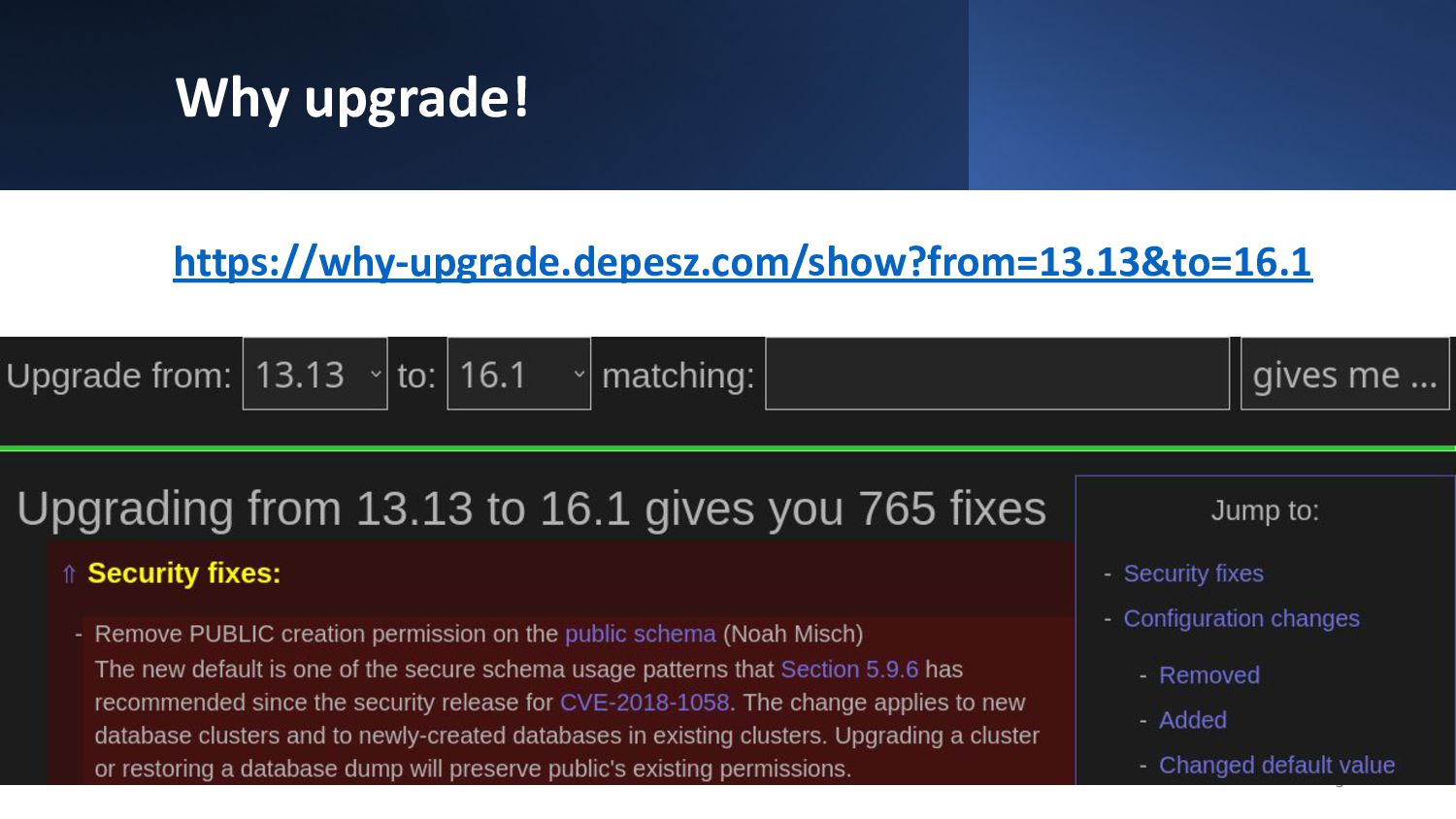{kind=link}
{kind=link}
{kind=link}
{kind=link}
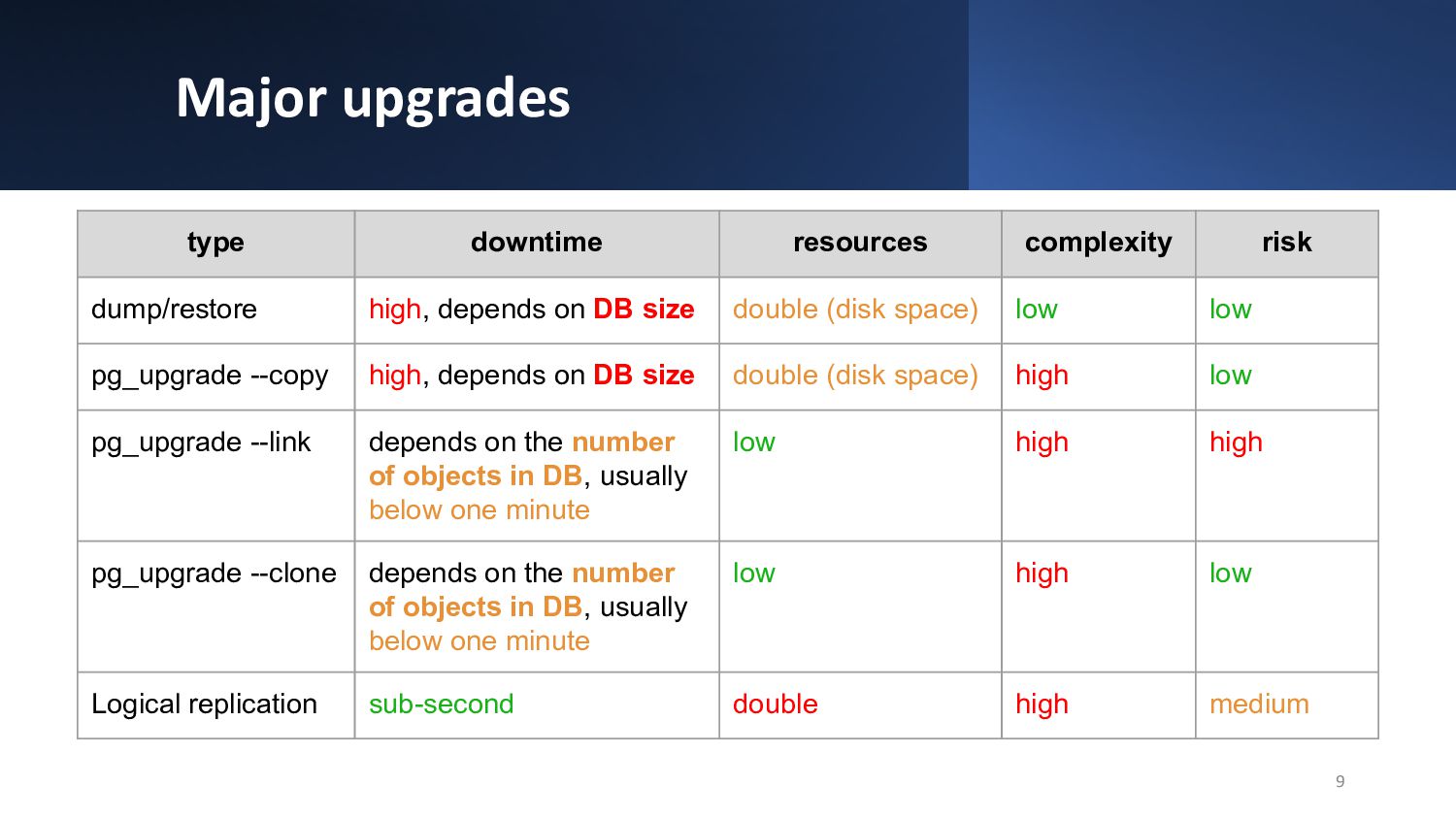{kind=link}
{kind=link}
{kind=link}
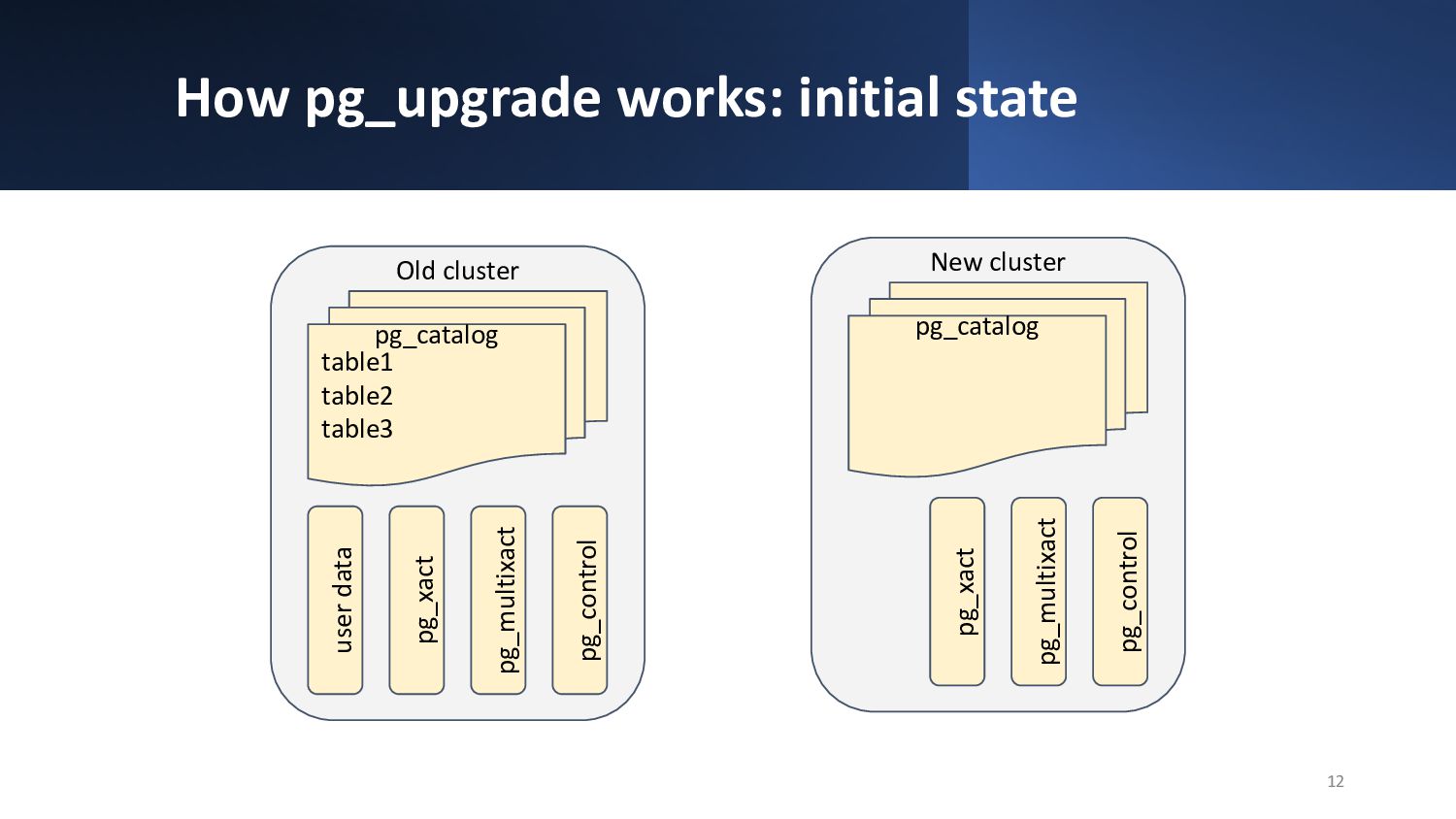{kind=link}
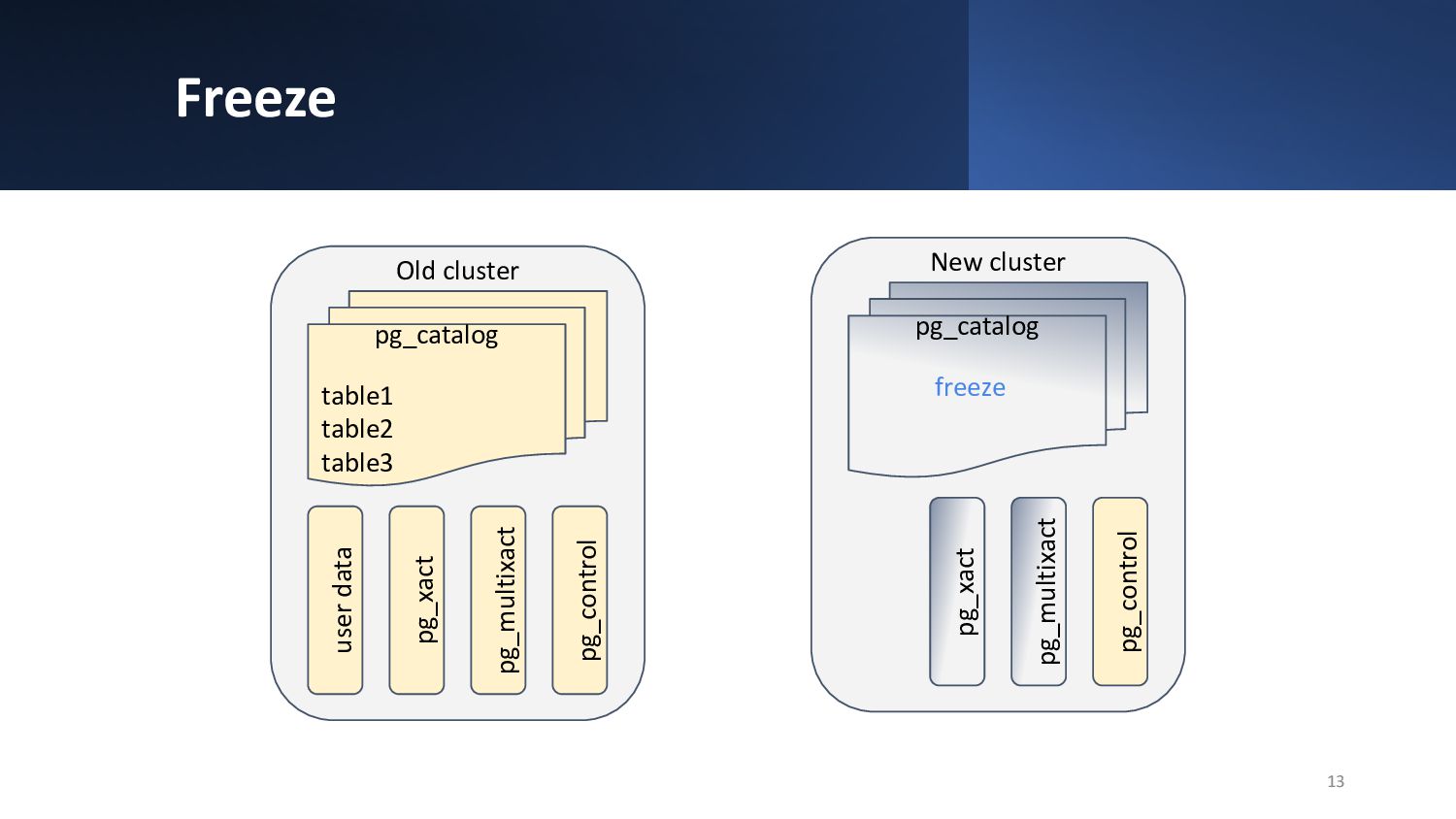{kind=link}
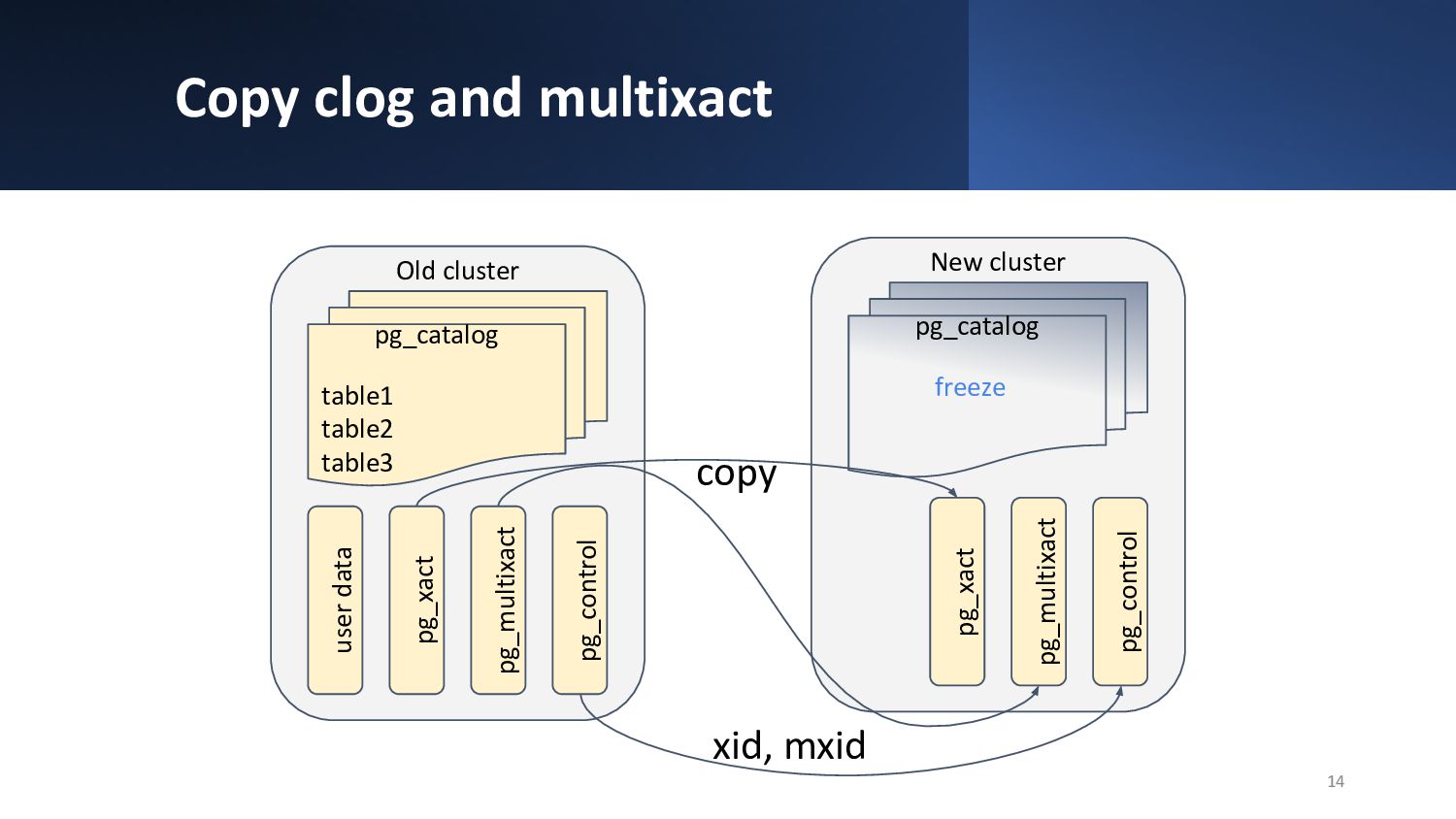{kind=link}
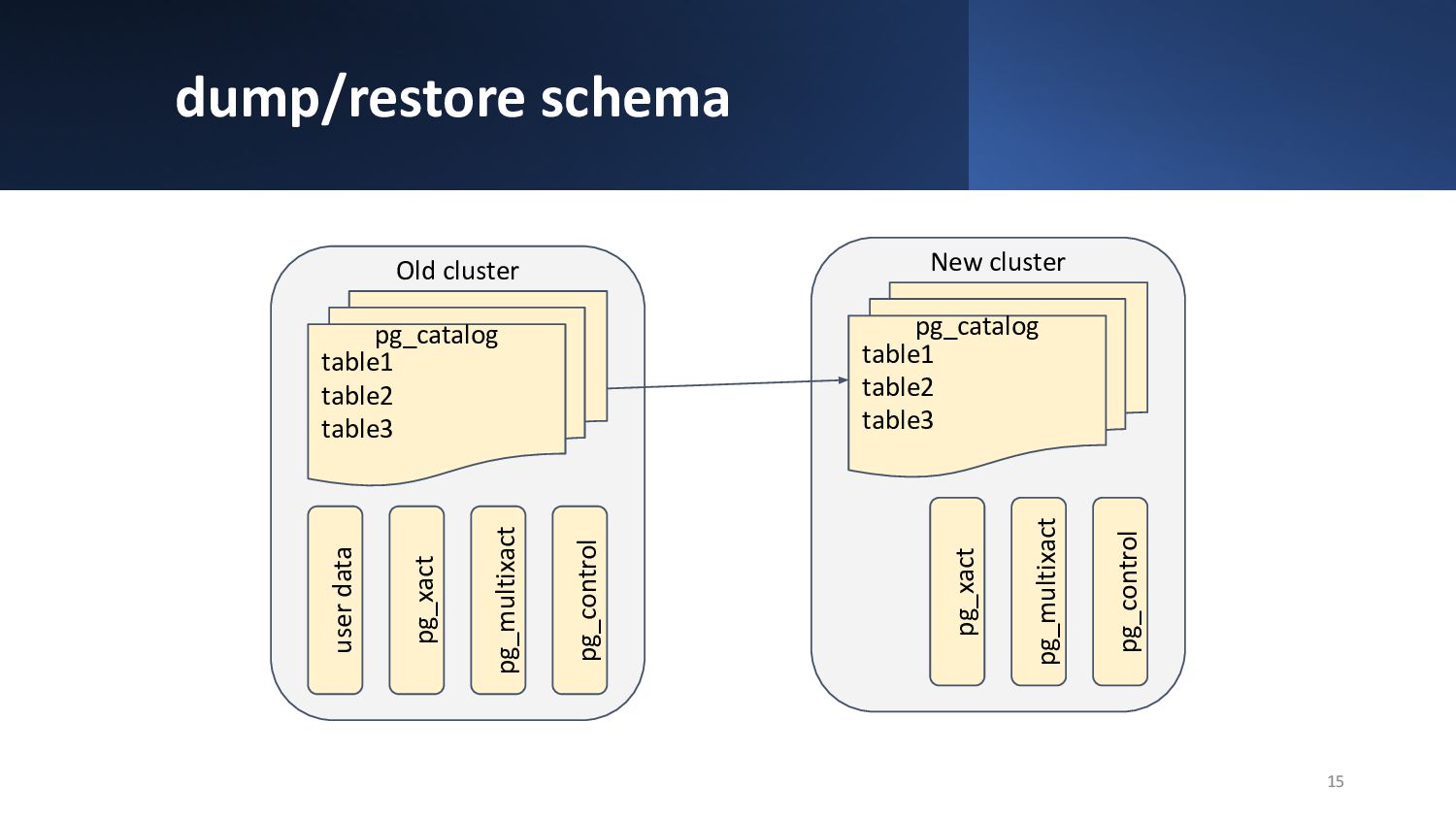{kind=link}
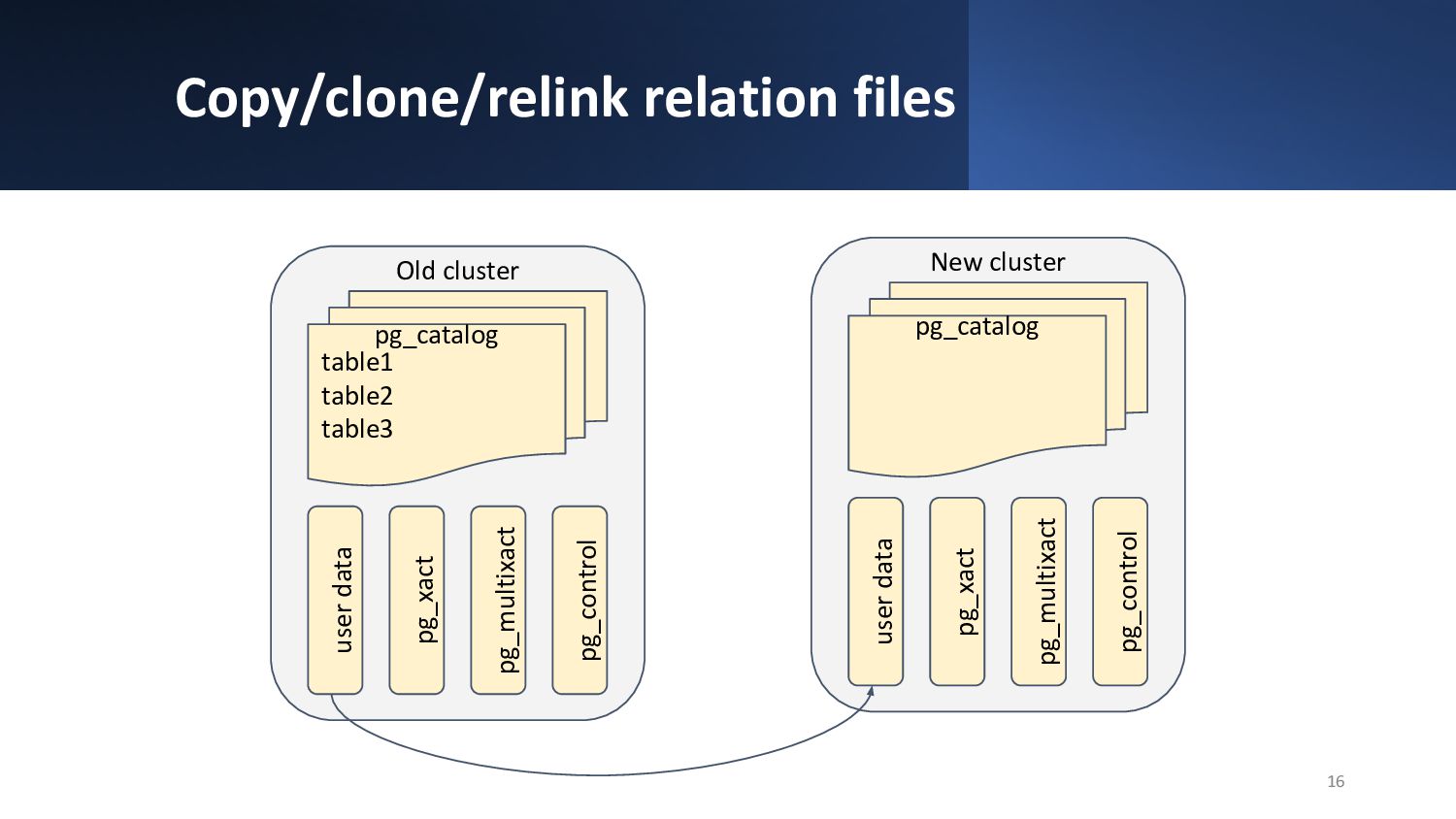{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
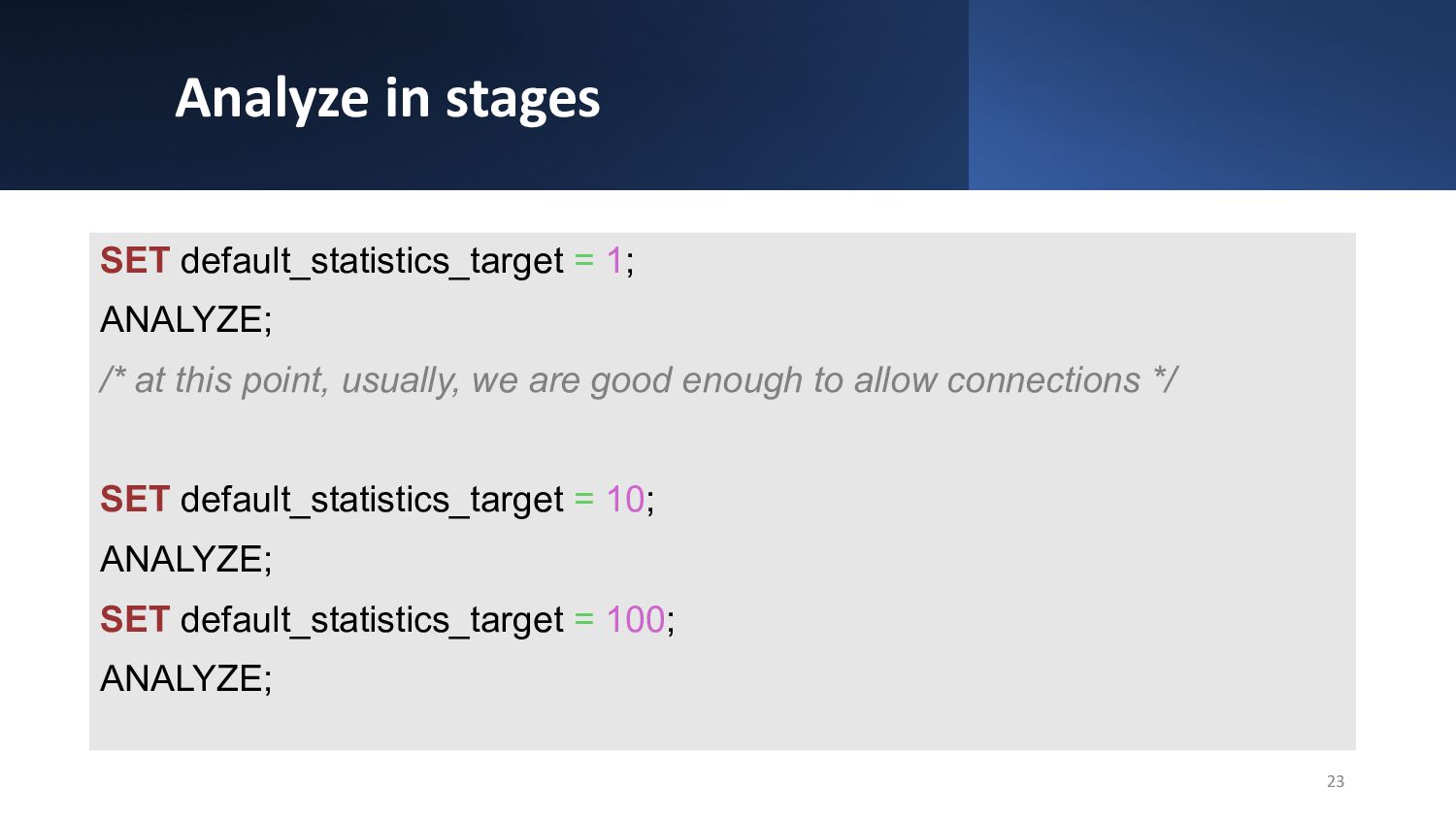{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}